Django框架—模型层之多表查询
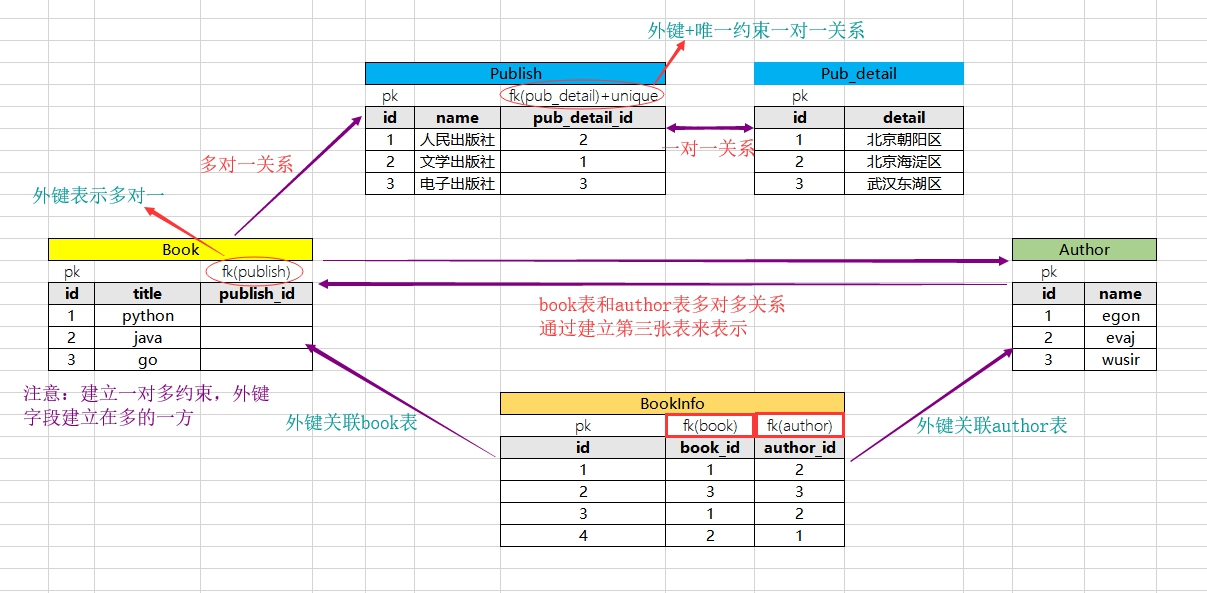
1.数据库中的表关系
在数据库中表与表之间的关系分:一对一,一对多,多对多
-
一对一的表关系通过外键+唯一约束表示
-
一对多的表关系通过外键约束来表示,一对多和多对一是相对而言的。
-
多对多的表关系通过建立第三张表设置外键来表示
2.ORM中的类关系模型
在orm中,表与表之间的关系通过类名来建立,类名中定义属性关联另一个类。
-
一对一的类关系通过OneToOneField()来建立
-
一对多的类关系通过ForeignKey()来建立
-
多对多的类关系通过ManyToManyField()来建立
orm中模型建立models.py文件


from django.db import models # Create your models here. class Author(models.Model): id = models.AutoField(primary_key=True) # 可以省略 name = models.CharField(max_length=32) age = models.IntegerField() class Publish(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=32) # 一对一关系建立,本质就是foreignkey+unique,orm中会自动给这个字段拼接一个_id。 authorDetail = models.OneToOneField(to="PublishDetail", to_field="id", on_delete=models.CASCADE) # 设置联级更新,默认选项 class PublishDetail(models.Model): id = models.AutoField(primary_key=True) telephone = models.BigIntegerField() city = models.CharField(max_length=32) class Book(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=32) price = models.DecimalField(max_digits=5,decimal_places=2) # 多对一关系,外键关联出版社表 publish = models.ForeignKey(to="Publish", to_field="id", on_delete=models.CASCADE) # 建立表之间的多对多关系 authors=models.ManyToManyField(to="Author") # mysql中需要我们手动建立第三张表,而orm中自动帮我们建立第三张表
注意
-
一对多表关系建立,外键字段建立在多的一方
-
多对多表关系中,外键会默认关联表的主键id,第三张表创建方式有多种。
-
创建多对多的authors名字,并不会在Book表中生成对应字段,而authors是用于多表查询的。
创建第三张表的方式
1.手动创建
class Book(models.Model): title = models.CharField(max_length=32) class Author(models.Model): name = models.CharField(max_length=32) # 自己创建第三张表,分别通过外键关联书和作者 class Author2Book(models.Model): author = models.ForeignKey(to="Author") book = models.ForeignKey(to="Book") class Meta: # 元类, unique_together = ("author", "book") # 这是联合为一
2.设置manytomany自动创建
class Book(models.Model): title = models.CharField(max_length=32) # 通过ORM自带的ManyToManyField自动创建第三张表 class Author(models.Model): name = models.CharField(max_length=32) books = models.ManyToManyField(to="Book", related_name="authors")
3.设置ManyToManyField并指定自行创建的表
class Book(models.Model): title = models.CharField(max_length=32) # 自己创建第三张表,并通过ManyToManyField指定关联 class Author(models.Model): name = models.CharField(max_length=32) books = models.ManyToManyField(to="Book", through="Author2Book", through_fields=("author", "book")) # through_fields接受一个2元组('field1','field2'): # 其中field1是定义ManyToManyField的模型外键的名(author),field2是关联目标模型(book)的外键名。 class Author2Book(models.Model): author = models.ForeignKey(to="Author") book = models.ForeignKey(to="Book") class Meta: unique_together = ("author", "book")
如果我们需要在第三张关系表中存储额外的字段时,需要使用第三种方式。
创建关系的参数(了解)
1.创建一对一关系字段的参数
-
to:设置要关联的表。
-
to_field:设置要关联的字段。
-
on_delete:同ForeignKey字段
2.创建一对多字段的参数
-
to:设置要关联的表
-
to_field:设置要关联的表的字段
-
related_name: 反向操作时,使用的字段名,用于代替原反向查询时的'表名_set'。
-
related_query_name:反向查询操作时,使用的连接前缀,用于替换表名。
-
on_delete:当删除关联表中的数据时,当前表与其关联的行的行为。
3.创建多对多字段的参数
-
to:设置要关联的表
-
related_name:同ForeignKey字段。
-
related_query_name:同ForeignKey字段。
-
through:在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过 through来指定第三张表的表名。
-
through_fields:设置关联的字段。
-
db_table:默认创建第三张表时,数据库中表的名称。
4.创建表的一些元信息设置
元信息:ORM对应的类里面包含另一个Meta类,而Meta类封装了一些数据库的信息。主要字段如下
-
db_table:ORM在数据库中的表名默认是 app_类名,可以通过db_table可以重写表名。db_table = 'book_model'
-
index_together:联合索引。
-
unique_together:联合唯一索引。
-
ordering:指定默认按什么字段排序。
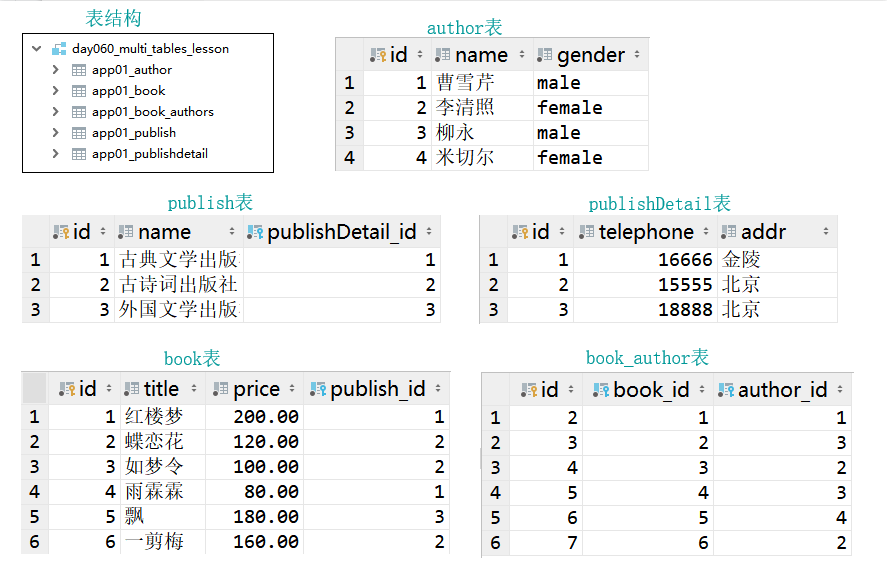
建立好的表结构
二、多表增删改
1.一对一的增删改
一对一增加
通过字段中直接添加一对一关系表中该条记录的对象,或者对象对应的id值到字段。
# 1.一对一增加记录 models.PublishDetail.objects.create( telephone=17777, addr="江苏" ) # 先在publishDetail表中增加一条记录 models.Publish.objects.create( name="人民出版社", publishDetail=models.PublishDetail.objects.get(id=4), # 直接添加一个出版社对象 # publishDetail_id=4 # 第二种写法,直接添加id值,注意两种方式的赋值对象 ) # 在publish表中新增记录
一对一修改和删除
# 2.一对一更新和删除记录 models.Publish.objects.filter(id=4).update(name="中国人民出版社") models.Publish.objects.filter(id=4).delete()
2.一对多的增删改
一对多的增加
# 1.一对多增加 publish_obj = models.Publish.objects.filter(id=2)[0] models.Book.objects.create( title="摆渡人", price=130, publish=publish_obj, # 第一种方式传对象 # publish_id=2 # 第二种方式传id(推荐) )
一对多的更新和删除
# 一对多的更新和删除 models.Book.objects.filter(id=13).update(price=150) models.Book.objects.filter(id=13).delete()
3.多对多的增删改
多对多的增加
多对多的添加是基于对象来操作,还需要考虑是在哪一侧添加;
- 在被关联的表中,添加数据和单表添加数据一样,model.表名.objects.create(字段值...)。
- 在有关联字段的表中,也就是关联别人的表,需要先添加一个对象,通过对象.关联字段名.add()方法来添加多对多的关联字段。
# 创建一本书对象 book_obj = models.Book.objects.create( title="摆渡人", price=120, publish_id=2 ) # 或者找到一个书本对象 book_obj = models.Book.objects.get(publish_id=2) # 找到两个作者对象(这里也可以创建新的,演示添加多个作者) author1 = models.Author.objects.get(id=1) author2 = models.Author.objects.get(id=2) # 注意:多对多添加需要用当时创建关联的属性名authors来操作 # 通过书本对象在第三张表中添加作者对象或author_id book_obj.authors.add(author1,author2) # 方式1 book_obj.authors.add(1,2) # 方式2 book_obj.authors.add(*author_list) # 方式3
多对多的更新和删除
多对多的更新和删除也是基于对象操作的,先找到一个对象,在通过对象操作在第三张表中的数据;
注意:
- 被关联的表中的行记录如果被关联,那么无法删除,修改也只能修改非关联字段的字段
- 关联的表中,数据的修改,通过对象.关联字段名.remove()/clear()/set()方法来删除。
book_obj = models.Book.objects.get(id=2) # 找到一个书本对象 # 通过book_obj对象操作对应的第三张表中数据 book_obj.authors.remove(1) # 删除book_obj对象关联数据中author_id为1的数据,这里是book_id=2的 book_obj.authors.remove(1, 3) # 删除多条(一) book_obj.authors.remove(*[1,3]) # 删除多条(二) book_obj.authors.clear() # 清除book_obj对象关联的所有数据,这里是book_id=2的 # set方法更新数据 book_obj.authors.set(['3']) # 清空所有的book_id为2的第三张表里面的所有记录,再重新给book_id为2书籍添加对应的author_id为3的记录
三.多表的查询(重难点)
1.基于对象的跨表查询
跨表查询是分组查询的基础,F和Q查询是最简单的。
查询思路是先找到某个对象,通过对象来进行正向/反向查询,注意都是基于对象来查询。
一对多的跨表查询

![]() 正向查询
正向查询
# 查询主键为1的书籍对应的出版社的名字 book_obj = models.Book.objects.filter(id=1).first() name = book_obj.publish.name print(name) # 古典文学出版社
反向查询
# 查询古诗词出版社出版的所有书籍 publish_obj = models.Publish.objects.get(name="古诗词出版社") book_list = publish_obj.book_set.all() # 查询所有古诗词出版社出版的书籍对象,返回一个queryset对象 print(book_list) # <QuerySet [<Book: 蝶恋花>, <Book: 如梦令>, <Book: 一剪梅>]> book1 = book_list.filter(title="如梦令") # 对结果直接只用filter筛选 print(book1) # <QuerySet [<Book: 如梦令>]>
一对一跨表查询

![]() 正向查询
正向查询
# 查询书本id为1的出版社地址 publish_obj = models.Publish.objects.get(id=1) print(publish_obj.publishDetail.addr) # 金陵
反向查询
# 查询出版社电话为18888对应的出版社名字 publish_obj1 = models.PublishDetail.objects.get(telephone=18888) print(publish_obj1.publish.name) # 外国文学出版社
多对多正向/反向
多对多基于对象查询,无论是正向还是反向,都有可能查询到多个结果,所以查询返回的对象是queryset对象,对其中的的对象可以再次筛选。

正向查询
# 查询红楼梦的作者是谁 book_obj = models.Book.objects.filter(title="红楼梦").first() # 多对多查询可能是多个对象,所以用all取所有,获得queryset对象。 print(book_obj.authors.all().first().name) # 曹雪芹
反向查询
# 李清照写了那些书 author_obj = models.Author.objects.filter(name="李清照")[0] book_list = author_obj.book_set.all() print(book_list) # <QuerySet [<Book: 如梦令>, <Book: 一剪梅>]>
Django也提供了一种直观而高效的方式查询(lookups)中表示关联关系,能够自动确认SQL中的Join联系。
在orm中连表查询使用两个下划线来连接模型(model)间关联字段的名字,直到最终连接到你想要的model。
基于双下划线的查询记住一句话:正向查询按关联字段名,反向查询按表名小写用来告诉ORM引擎join哪张表。
-
一对一、一对多、多对多都是一个写法。
-
表写在前和写在后没有区别,本质是通过join来实现的。
一对多查询
-
正向连表:关联的属性名__字段
-
反向连表:关联类名小写__字段
1.查询"古典文学出版社出版"的所有书籍名字和价格
# 正向连表:按关联属性名__字段 result1 = models.Book.objects.filter(publish__name="古典文学出版社").values("title","price") print(result1) # <QuerySet [{'title': '红楼梦', 'price': Decimal('200.00')}, {'title': '雨霖霖', 'price': Decimal('80.00')}]> # 反向连表:按类名小写__字段 result2 = models.Publish.objects.filter(name="古典文学出版社").values("book__title","book__price") print(result2) # <QuerySet [{'book__title': '红楼梦', 'book__price': Decimal('200.00')}, {'book__title': '雨霖霖', 'book__price': Decimal('80.00')}]>
这个例子中,对book表来说,出版社名字需要正向跨表,所以是 publish__name,对于publish表来说,书名和书的价格都需要反向跨表查询,所以是 book__title, book_price。
一对一查询
-
正向连表:关联的属性名__字段
-
反向连表:关联类名小写__字段
2.查询"古诗词出版社"的电话号码
# 正向连表:按关联属性名__字段 result1 = models.Publish.objects.filter(name="古诗词出版社").values("publishDetail__telephone") print(result1) # <QuerySet [{'publishDetail__telephone': 15555}]> # 反向:按类名小写__字段 result2 = models.PublishDetail.objects.filter(publish__name="古诗词出版社").values("telephone") print(result2) # <QuerySet [{'telephone': 15555}]>
多对多查询
-
正向连表:关联的属性名__字段
-
反向连表:关联类名小写__字段
3.查询作者"柳永"出版的所有书的名字
# 正向连表:按关联属性名__字段 result1 = models.Book.objects.filter(authors__name="柳永").values("title") print(result1) # <QuerySet [{'title': '蝶恋花'}, {'title': '雨霖霖'}]> # 反向:按类名小写__字段 result2 = models.Author.objects.filter(name="柳永").values("book__title") print(result2) # <QuerySet [{'book__title': '蝶恋花'}, {'book__title': '雨霖霖'}]>
related_name别名
反向查询时,如果初始化模型时的关联字段中定义了related_name ,反向查询时需要使用related_name替换类名,不能再使用类名小写,例如
publish = ForeignKey(Blog, related_name='bookList') # 定义类模型时,关联字段中定义related_name属性
例子:查询"古典文学出版社"出版过的所有书籍的名字与价格(一对多)
result=models.Publish.objects.filter(name="古典出版社").values("bookList__title","bookList__price") # 注意反向连表时用的是related_name,而不是类名小写(publish) # 结果:<QuerySet [{'book__title': '红楼梦', 'book__price': Decimal('200.00')}, {'book__title': '雨霖霖', 'book__price': Decimal('80.00')}]>
聚合查询效果等同于原生sql语句中的聚合函数。使用需要先导入聚合函数
语法结构:由queryset类型调用
from django.db.models import Avg,Max,Min,Count queryset对象.aggregate(*args, **kwargs)
注意点:
-
aggregate()一般是QuerySet的一个终止语句,返回的是含键值对的字典。
-
返回字典的键是字段和聚合函数名自动生成,需要为聚合的值指定一个名称。
1.查询"古典文学出版社"出版的所有书的平均价格
result = models.Book.objects.filter(publish__name="古典文学出版社").aggregate(avg_price=Avg("price")) print(result) # {'avg_price': 140.0} 显示的是命名后的字段
2.查询多个聚合函数结果
result = models.Book.objects.aggregate(max_price=Max("price"),min_price=Max("price"),num=Count(1)) # 查询所有书籍的最大价格、最低价格、以及数量 print(result) # {'max_price': Decimal('200.00'), 'min_price': Decimal('200.00'), 'num': 6}
4.分组查询
orm中的分组查询对应原生sql中的group by,依据字段对数据分组。
分组依据的字段可以是多个,表示联合分组,也就是两个字段同时相同才算一组。
语法结构:由QuerySet对象调用
QuerySet.values("分组依据字段1",...).annotate("分组后需要统计的数据")
注意:
-
values()函数在这里表示分组依据的字段,可以多个。
-
annotate里面一般写聚合函数,如果不写,那么单纯分组没有任何意义。
-
聚合函数使用必须有别名
单表分组查询
1.查询每个出版社对应的id和出版书籍的数量
-
原生sql语句写法
select publish_id,count(1) from book group by publish_id
-
orm中查询语句,返回QuerySet类型
result = models.Book.objects.values("publish_id").annotate(num=Count(1)) print(result) # <QuerySet [{'publish_id': 1, 'num': 2}, {'publish_id': 2, 'num': 3}, {'publish_id': 3, 'num': 1}]>
连表分组查询
2.查询每个出版社名字以及所有出版书籍的平均价格
-
原生sql语句
select name,avg(price) from app01_book inner join app01_publish on app01_book.publish_id = app01_publish.id group by app01_book.publish_id; --使用连表后分组查询相应字段
-
orm中查询语句
result = models.Book.objects.values("publish__name").annotate(avg_price=Avg("price")) print(result) # <QuerySet [{'publish__name': '古典文学出版社', 'avg_price': 140.0}, {'publish__name': '古诗词出版社', 'avg_price': 126.666667}, {'publish__name': '外国文学出版社', 'avg_price': 180.0}]>
显示分组和聚合函数外的其他字段
1.显示其他指定字段:对分组后结果.values(指定字段名1,...)
result = models.Book.objects.values("publish__name").annotate(max_price=Max("price")).values("publish__name","publish__id") print(result) # <QuerySet [{'publish__name': '古典文学出版社', 'publish__id': 1}, {'publish__name': '古诗词出版社', 'publish__id': 2}, {'publish__name': '外国文学出版社', 'publish__id': 3}]>
2.显示所有字段:对分组后的结果.values()
result = models.Book.objects.values("publish__name").annotate(max_price=Max("price")).values() print(result) # <QuerySet [{'id': 1, 'title': '红楼梦', 'price': Decimal('200.00'), 'publish_id': 1, 'max_price': Decimal('200.00')}, {'id': 4, 'title': '雨霖霖', 'price': Decimal('80.00'), 'publish_id': 1, 'max_price': Decimal('80.00')}, {'id': 2, 'title': '蝶恋花', 'price': Decimal('120.00'), 'publish_id': 2, 'max_price': Decimal('120.00')}, {'id': 3, 'title': '如梦令', 'price': Decimal('100.00'), 'publish_id': 2, 'max_price': Decimal('100.00')}, {'id': 6, 'title': '一剪梅', 'price': Decimal('160.00'), 'publish_id': 2, 'max_price': Decimal('160.00')}, {'id': 5, 'title': '飘', 'price': Decimal('180.00'), 'publish_id': 3, 'max_price': Decimal('180.00')}]>
orm中实现group_concat聚合函数
1.创建Concat类
from django.db.models import Aggregate, CharField class Concat(Aggregate): """ORM用来分组显示其他字段 相当于group_concat""" function = 'GROUP_CONCAT' template = '%(function)s(%(distinct)s%(expressions)s)' def __init__(self, expression, distinct=False, **extra): super(Concat, self).__init__( expression, distinct='DISTINCT ' if distinct else '', output_field=CharField(), **extra )
2、模型管理器查询
result = models.Book.objects.values("authors__id").annotate(book_name=Concat("title")) print(result) # <QuerySet [{'authors__id': 1, 'book_name': '红楼梦'}, {'authors__id': 2, 'book_name': '如梦令,一剪梅'}, {'authors__id': 3, 'book_name': '雨霖霖,蝶恋花'}, {'authors__id': 4, 'book_name': '飘'}]>
5.F/Q查询
F/Q用来补充查询中一些细节,使用方法如下:
from django.db.models import F,Q
F查询
F查询一般用于同一行数据中的两列数据(字段)的比较和筛选,然后对筛选的结果进行相应处理。
-
F查询语句
1.查找好评数大于点赞数量的所有书籍
前提在书籍中增加两个字段,comments和likes字段,添加相应数据。
class(models.Model): comments = models.IntegerField(default=20) likes = models.IntegerField(default=20) # book类中增加两个字段,默认为20,然后对表中自行进行修改数据
查询语句写法
result = models.Book.objects.filter(comments__gt=F('likes')) print(result)
-
F查询更新语句
2.将"古典文学出版社"的所有书籍的价格增加10元
models.Book.objects.filter(publish__name="古典文学出版社").update(price=F("price")+10) # 数据表中古典文学出版社也就是publish_id为1的书籍价格全部增加了10
Q查询
filter() 等方法中的关键字参数查询之间逻辑是"and",也就是与运算。 如果你需要执行更复杂的查询(例如or语句),你可以使用Q 对象。
-
Q对象的获取:将一个条件使用Q()包裹,就可以得到一个条件的Q对象
Q(title__startswith='红楼')
-
Q对象支持&(与)、|(或)、~(非)操作符组合使用。
1.查询作者是"李清照"或者是"柳永"的所有书籍
book_list = models.Book.objects.filter(Q(authors__name="李清照")|Q(authors__name="柳永")) print(book_list) # <QuerySet [<Book: 如梦令>, <Book: 一剪梅>, <Book: 蝶恋花>, <Book: 雨霖霖>]>
-
Q对象条件可以与正常的条件混合使用,且Q对象的查询条件必须写在正常条件之前
2.查询作者是"李清照"或者"曹雪芹"且书籍价格大于120的书籍
book_list = models.Book.objects.filter(Q(authors__name="李清照")|Q(authors__name="曹雪芹"),price__gt=120) print(book_list) # <QuerySet [<Book: 红楼梦>, <Book: 一剪梅>]>
四、orm执行原生sql语句
orm模型查询能够帮我们方便的查询大部分数据的场景,但是仍然有很多场景orm模型查询api无法满足,或者效率满足不了使用,这个时候我们可以执行原生的sql语句。
Django中提供了两种方式执行原生sql语句:
-
使用raw()方法,执行原生sql语句
-
避开模型层,执行之定义的sql语句
1.raw方法执行原生sql
raw()管理器方法用于执行原生的sql语句,并返回模型的实例;
-
raw方法的执行对象是任意一张表的objects管理器
-
raw()方法语句查询必须带主键
返回对象是一个django.db.models.query.RawQuerySet 实例,可以像QuerySet一样迭代获取对象实例。
ret = models.Book.objects.raw("select id,title from app01_book") # 表名Book可以是任意表,没有影响 print(ret) # <RawQuerySet: select title from app01_book> for obj in ret: # 遍历获取实例对象 print(obj.id, obj.title) # 通过对象属性取值 # 1 红楼梦 # 2 蝶恋花 # 3 如梦令 # 4 雨霖霖 # 5 飘 # 6 一剪梅
可以通过translations参数,指定把一个查询的字段名替换成字典中字段名对应的值,通过值来取得该字段的数据。
d = {'price':'haha'} # 定义一个字典,使用haha替换表中字段price
ret = models.Book.objects.raw("select * from app01_book",translations=d) # 将字段price翻译成haha
print(ret) # <RawQuerySet: select title from app01_book>
for obj in ret:
print(obj.id, obj.title, obj.haha) # 通过haha取到price字段的数值
# 1 红楼梦 210.00
# 2 蝶恋花 120.00
# 3 如梦令 100.00
# 4 雨霖霖 90.00
# 5 飘 180.00
# 6 一剪梅 160.00
raw()还可以接受参数,避免自己拼接字符串,出现sql注入。
d = {'price': 'haha'} # 定义一个字典,使用haha替换表中字段price
ret = models.Book.objects.raw("select * from app01_book where price>%s", translations=d, params=[120, ]) # 使用params参数传递参数给sql语句
print(ret) # <RawQuerySet: select title from app01_book>
for obj in ret:
print(obj.id, obj.title, obj.haha) # 通过haha取到price字段的数值
# 1 红楼梦 210.00
# 5 飘 180.00
# 6 一剪梅 160.00
2.直接执行自定义SQL语句
有时候raw()方法并不十分好用,很多情况下我们不需要将查询结果映射成模型,或者我们需要执行DELETE、 INSERT以及UPDATE操作。
在这些情况下,我们可以直接访问数据库,完全避开模型层。
Django中直接提供了pymysql和数据库连接的接口,就类似pymysql中connect方法得到的链接管道,然后使用这个连接操作数据库。
from django.db import connection, connections cursor = connection.cursor() # 或者 cursor = connections["default"].cursor() 获取与数据库的连接管道 cursor.execute("select id,title from app01_book where price > %s",[120,]) ret = cursor.fetchall() print(ret) # ((1, '红楼梦'), (5, '飘'), (6, '一剪梅'))
五、python脚本调用Django环境
外部文件(脚本)如果想要使用django项目的环境来运行,比如使用项目中的models文件,必须先加载django项目的环境配置;这里的外部文件也必须在django项目下。
加载django环境只需要在文件开头配置如下:
import os if __name__ == '__main__': import django os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings") # 设置Django环境 django.setup() # 启动Django环境 from app01 import models #引入也要写在上面三句之后 books = models.Book.objects.all() print(books)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号