20244116《Python程序设计》实验四报告
20244116 2024-2025《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2441
姓名: 黎心睿
学号:20244116
实验教师:王志强
实验日期:2025年5月13日
必修/选修: 公选课
1、实验要求
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
例如:编写从社交网络爬取数据,实现可视化舆情监控或者情感分析。
例如:利用公开数据集,开展图像分类、恶意软件检测等
例如:利用Python库,基于OCR技术实现自动化提取图片中数据,并填入excel中。
例如:爬取天气数据,实现自动化微信提醒
例如:利用爬虫,实现自动化下载网站视频、文件等。
例如:编写小游戏:坦克大战、贪吃蛇、扫雷等等
注:在Windows/Linux系统上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
2、实验内容
结合上课老师示范内容以及本人能力有限,本次实验我选择了利用python爬虫技术爬取豆瓣电影top250榜单。
本次实验旨在通过 Python 编程实现豆瓣电影 Top250 页面数据的爬取,具体包括电影名称、评分、评价人数三项核心信息,并将数据存储为 CSV 格式文件。通过实践,掌握网络请求、HTML 解析、反爬应对及数据存储的全流程技术,加深对课堂所学爬虫理论的理解与应用。
3、实验过程
(1) 环境搭建与库引入
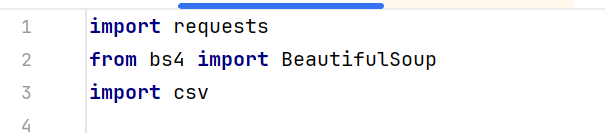
使用课堂推荐的requests库发送网络请求,BeautifulSoup结合lxml解析器解析HTML页面,提升解析效率。存储数据位CSV文件。
(2)请求头设置与反爬应对

模拟 Chrome 浏览器的User-Agent标识,通过请求头伪装浏览器绕过豆瓣的反爬机制。
(3)分页请求与页面解析

通过class属性find('ol', class_='grid_view')定位包含所有电影信息的
- 标签。
遍历每个电影条目,使用find逐层查找子标签,结合get_text(strip=True)清理文本空格。
(4)数据存储与异常处理

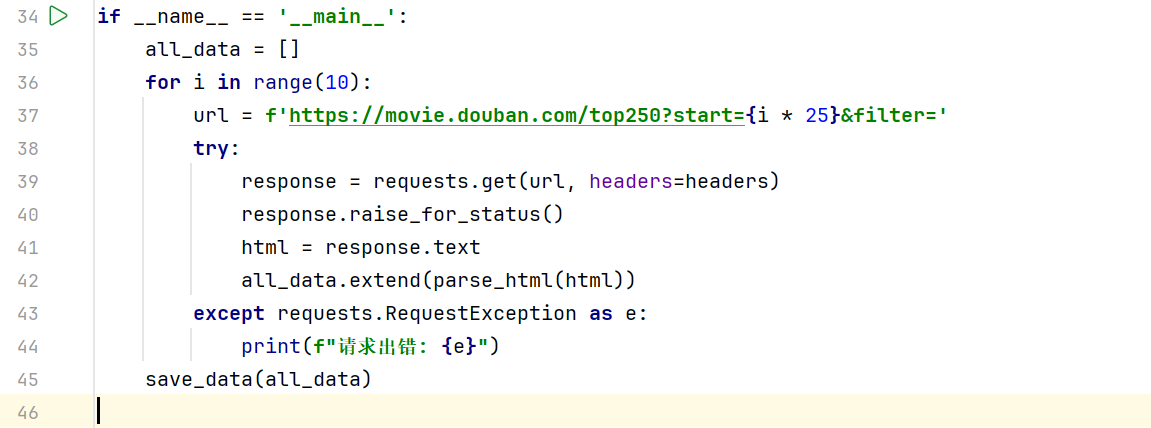
timeout=5避免请求超时阻塞程序。
raise_for_status()捕获 4xx/5xx 状态码。
4.实验结果
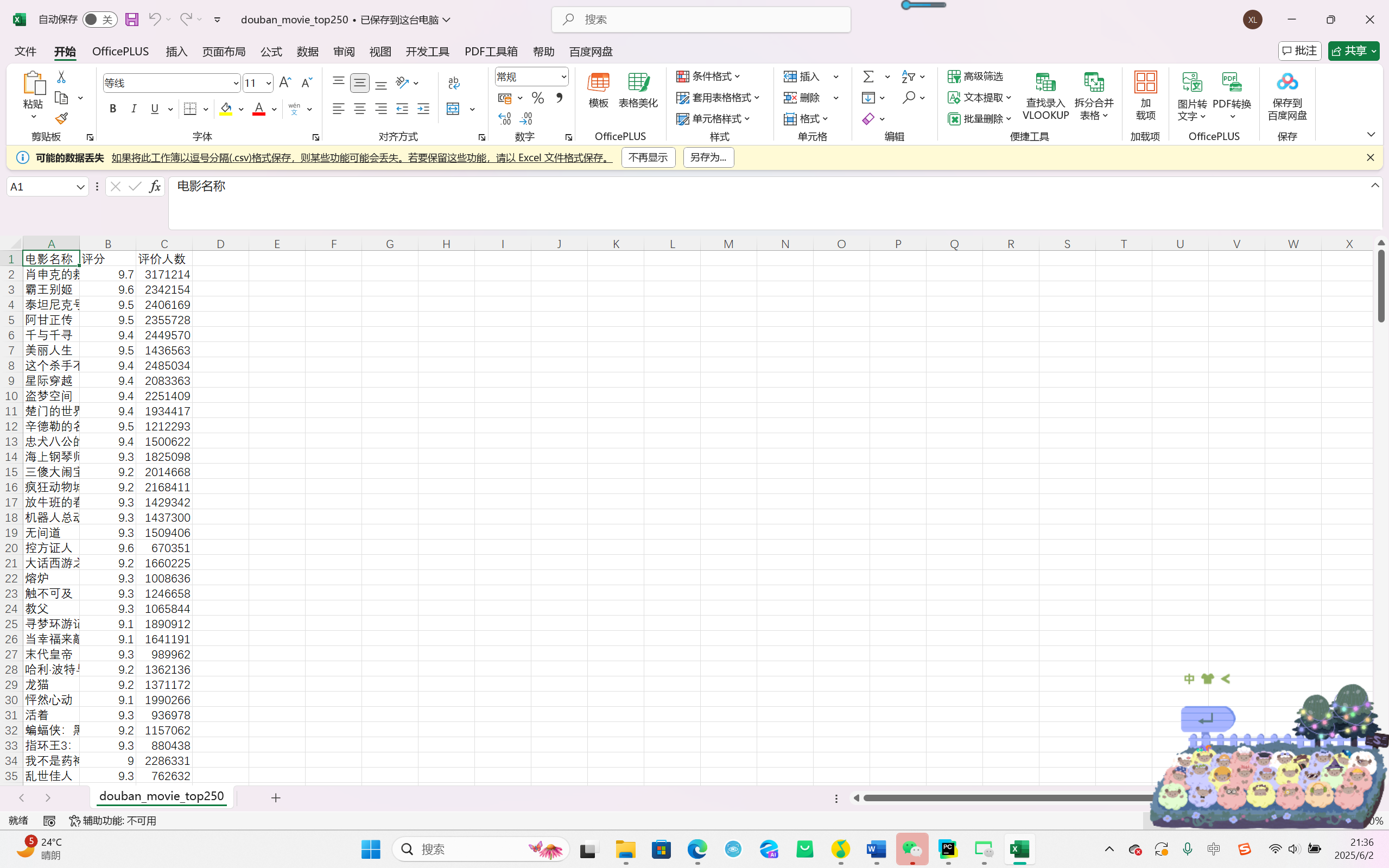
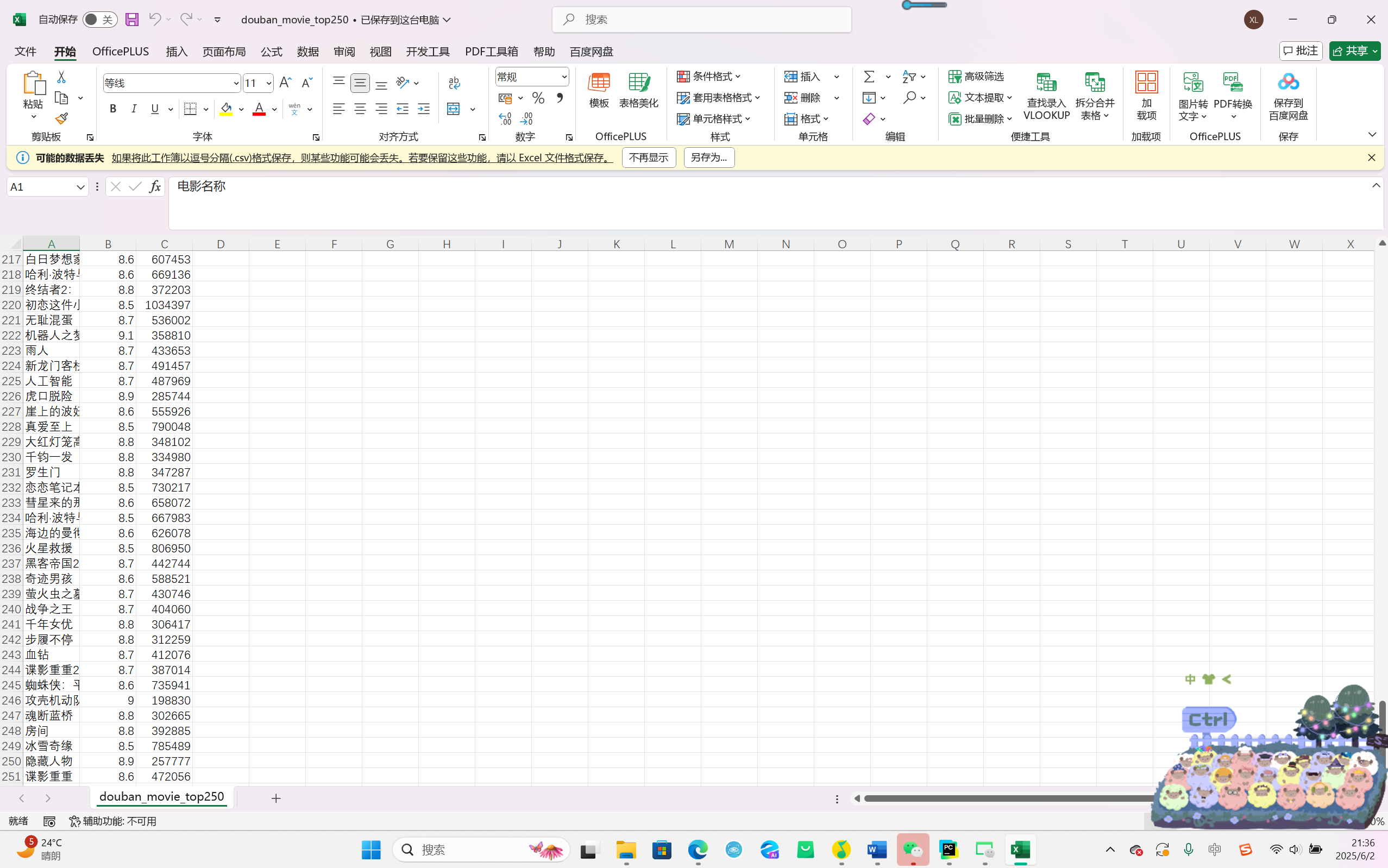
文件存储:生成douban_movie_top250.csv文件,包含 250 条电影数据。
5.实验中遇到的问题和解决过程
问题 1:请求被拒绝(403 状态码)
初始代码直接请求时返回403 Forbidden。未设置请求头,被豆瓣识别为爬虫
解决:添加User-Agent请求头,模拟真实浏览器行为,成功绕过反爬。
问题 2:解析时提示NoneType对象错误
运行时报错AttributeError: 'NoneType' object has no attribute 'find'。部分电影条目缺少特定标签(如未找到评分标签),导致find方法返回None。
解决:添加异常处理逻辑,对未找到的元素设置默认值:
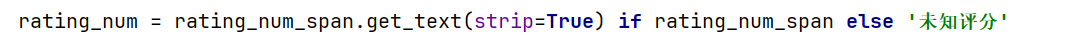
问题 3:评价人数提取为空
部分数据的评价人数字段显示为空字符串。评价人数标签的定位逻辑错误,原代码通过相邻标签查找,未考虑部分页面结构差异。
解决:改用字符串匹配直接定位包含 “人评价” 的标签:
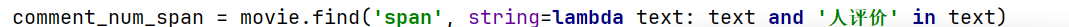
其他(感悟、思考等)
这次做豆瓣电影 Top250 的爬虫实验,对我来说真是一次从理论到实践的 “闯关”。刚开始按照课堂讲的requests库写请求,结果直接被豆瓣反爬拦下来,才意识到原来 “User-Agent” 设置这么关键,就像课堂说的 “反爬是爬虫的第一道门槛”,得把自己彻底伪装成浏览器才行。后来解析页面时,又被NoneType错误卡住,对着网页源代码找了半小时标签,才发现有些电影信息结构和预想的不一样,这才明白课堂强调 “解析要灵活适应网页变化” 的道理,必须加好异常处理,给未知情况留退路。这次实验对我来说非常有难度,也很有挑战性,但是最终成功运行代码的那一刻还是成就感满满~python技术还是很有用的!虽然本学期的Python课程已经全部结束了,但是以后我也会在空余时间,多多学习相关知识的。
作为文科生,刚开始接触 Python 时常常被代码逻辑绕晕,特别感谢老师用 “零基础友好” 的方式讲解基础知识。希望课程能继续保持 “案例驱动” 的教学模式 ,比如多结合文科常见场景(如文本分析、数据可视化报告等)设计实验,像用 Python 整理调研数据、生成图表等,让我们更直观感受到编程在专业中的实用性。但是也有些时候课程有些较难的地方我们也会跟不上,老师可适当放慢讲课速度,更加详细地讲解一下难理解的代码。
还有就是老师你上课前签到的方式对我来说真的太难了!有挺多次签到没成功的orz或许老师以后可以换一种简单一点的方式签到呢哈哈!
最后感谢老师这一学期以来的辛苦教授!
演示视频
https://v.douyin.com/RATOTbuJNZ0/ kCu:/ 09/25 e@b.NW
源代码
点击查看代码
import requests
from bs4 import BeautifulSoup
import csv
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 解析页面函数
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
movie_list = soup.find('ol', class_='grid_view').find_all('li')
data = []
for movie in movie_list:
title = movie.find('div', class_='hd').find('span', class_='title').get_text(strip=True)
rating_num_span = movie.find('span', class_='rating_num')
rating_num = rating_num_span.get_text(strip=True) if rating_num_span else '未知评分'
comment_num_span = movie.find('span', string=lambda text: text and '人评价' in text)
comment_num = comment_num_span.get_text(strip=True).rstrip('人评价') if comment_num_span else '未知评价人数'
data.append([title, rating_num, comment_num])
return data
# 保存数据函数
def save_data(data):
with open('douban_movie_top250.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['电影名称', '评分', '评价人数'])
writer.writerows(data)
if __name__ == '__main__':
all_data = []
for i in range(10):
url = f'https://movie.douban.com/top250?start={i * 25}&filter='
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
html = response.text
all_data.extend(parse_html(html))
except requests.RequestException as e:
print(f"请求出错: {e}")
save_data(all_data)
点击查看代码
import requests
from bs4 import BeautifulSoup
import csv
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 解析页面函数
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
movie_list = soup.find('ol', class_='grid_view').find_all('li')
data = []
for movie in movie_list:
title_elem = movie.find('div', class_='hd').find('span', class_='title')
title = title_elem.get_text(strip=True) if title_elem else '未知名称'
rating_num_span = movie.find('span', class_='rating_num')
rating_num = rating_num_span.get_text(strip=True) if rating_num_span else '未知评分'
comment_num_span = movie.find('span', string=lambda text: text and '人评价' in text)
comment_num = comment_num_span.get_text(strip=True).rstrip('人评价') if comment_num_span else '未知评价人数'
data.append([title, rating_num, comment_num])
return data
# 保存数据函数
def save_data(data):
with open('douban_movie_top250.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['电影名称', '评分', '评价人数'])
writer.writerows(data)
if __name__ == '__main__':
all_data = []
for i in range(10):
url = f'https://movie.douban.com/top250?start={i * 25}&filter='
try:
print(f"正在爬取第{i + 1}页...")
response = requests.get(url, headers=headers)
response.raise_for_status()
html = response.text
page_data = parse_html(html)
all_data.extend(page_data)
print(f"第{i + 1}页爬取完成,获取{len(page_data)}条数据")
except requests.RequestException as e:
print(f"第{i + 1}页爬取失败: {e}")
save_data(all_data)
print("所有数据爬取完成并保存!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号