

1.用图与自己的话,简要描述Hadoop起源与发展阶段。
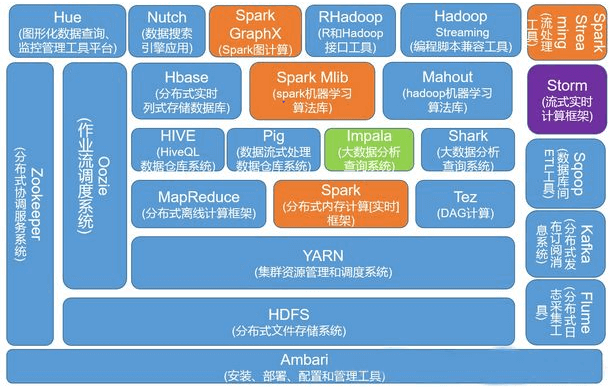
Hadoop是道格·卡丁(Doug Cutting)创建的,Hadoop起源于开源网络搜索引擎Apache Nutch,后者本身也是Lucene项目的一部分。Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
发展阶段:阶段0:Ad Hoc集群时代——标志着Hadoop的起源,集群以Ad Hoc、单用户方式建立。
阶段1:Hadoop on Demand(HOD),是进化过程中的下一个阶段,以一种通用系统的形式,在商用硬件组成的共享集群上提供和管理私有Hadoop MapReduce和HDFS实例。
阶段2:共享计算集群的黎明——始于大量Hadoop安装转向与共享HDFS实例一起的共享MapReduce集群。
阶段3:YARN的出现——用以解决以往架构的需求和缺陷
从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲
1.0版本和2.0版本,2011年11月,Hadoop 1.0.0版本正式发布,意味着可以用于商业化。但是,1.0版本中,存在一些问题:
(1)扩展性差,JobTracker负载较重,成为性能瓶颈。
(2)可靠性差,NameNode只有一个,万一挂掉,整个系统就会崩溃。
(3)仅适用MapReduce一种计算方式。
(4)资源管理的效率比较低。
所以,2012年5月,Hadoop推出了 2.0版本 。
2.0版本中,在HDFS之上,增加了YARN(资源管理框架)层。它是一个资源管理模块,为各类应用程序提供资源管理和调度。此外,2.0版本还提升了系统的安全稳定性。所以,后来行业里基本上都是使用2.0版本。目前Hadoop又进一步发展到3.X版本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号