03. 理解文件系统inode,superblock
好了,到现在为止从01. 数据在磁盘中的存储 和 02. 数据在flash的存储,我们理解了说在硬件层面上数据的存储,也理解了为了使得文件系统和底层的物理特性解耦合,我们在文件系统中设定了 "逻辑块" 的概念,并且使用 映射层 来实现从逻辑块和物理地址的映射,不论是基于磁盘还是基于flash。由此我们开始使用逻辑块的概念理解文件系统。
基本围绕的话题有
- inode - 文件系统除了存储文件的数据,inode存储文件地址,linux通过inode找到文件
- superblock - 文件系统会经常有增加删除,整个文件系统的状态如何维护,已使用空间,未使用空间等等
- 文件路径解析 - linux使用indoe找到文件地址?但日常我们都是文件路径的啊,路径和inode如何联系的
通过理解这些问题,基本了解文件系统的读写
首先就是文件系统存储的数据实际上是两个部分
-
纯数据区
- 文件真正的数据存储区,基本存储单位是block
-
元数据区
- 文件属性:磁盘中的存储位置,文件长度等信息
- 时间戳:创建时间,修改时间
- 读写权限:使用read/write系统调用时,首先进行权限检查
- 所属组,所有者
- 连接数
所以就是说当文件系统使用的时候,首先会进行格式化,就是将磁盘空间会划分成为block,而且还需要有一个 inode table 用来存储 inode 和 block 位置的映射。
inode table
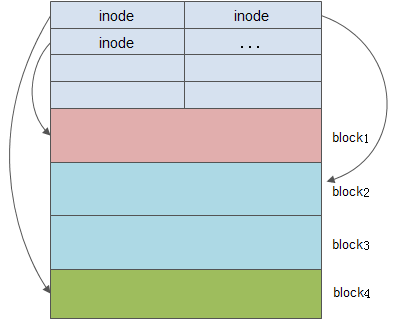
- 每一个文件都会使用一个inode结构体来描述
- 每一个inode有固定编号,和单独的存储空间
- 每一个inode大小是128/256B
很重要的一点是:Linux系统根据inode来查找文件的存储位置, 这是文件系统存储映射的基本, inode 结构是

// stat xx文件 可以在这里看到对应文件的inode
lqy@lqy:/dev$ stat fd
文件:fd -> /proc/self/fd
大小:13 块:0 IO 块大小:4096 符号链接
设备:5h/5d Inode:393 硬链接:1
权限:(0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
访问时间:2025-03-14 08:50:22.574252251 +0800
修改时间:2025-03-04 16:39:22.792999881 +0800
变更时间:2025-03-04 16:39:22.792999881 +0800
创建时间:2025-03-04 16:39:22.792999881 +0800
// df -i 可以看见对应分区的inode
lqy@lqy:/dev$ df -i
文件系统 Inodes 已用I 可用I 已用I% 挂载点
tmpfs 1702481 1403 1701078 1% /run
/dev/sda3 11763712 1028749 10734963 9% /
tmpfs 1702481 247 1702234 1% /dev/shm
tmpfs 1702481 4 1702477 1% /run/lock
tmpfs 1702481 1 1702480 1% /run/qemu
/dev/sda2 0 0 0 - /boot/efi
tmpfs 340496 237 340259 1% /run/user/1000
/dev/sr0 0 0 0 - /media/lqy/Ubuntu 22.04.3 LTS amd64
// df 看对应分区的block
lqy@lqy:/dev$ df
文件系统 1K的块 已用 可用 已用% 挂载点
tmpfs 1361988 2468 1359520 1% /run
/dev/sda3 184938756 165744196 11026164 94% /
tmpfs 6809924 55712 6754212 1% /dev/shm
tmpfs 5120 4 5116 1% /run/lock
tmpfs 6809924 0 6809924 0% /run/qemu
/dev/sda2 524252 6220 518032 2% /boot/efi
tmpfs 1361984 1740 1360244 1% /run/user/1000
/dev/sr0 4919592 4919592 0 100% /media/lqy/Ubuntu 22.04.3 LTS amd64
// df -h 看分区的大小
lqy@lqy:/dev$ df -h
文件系统 大小 已用 可用 已用% 挂载点
tmpfs 1.3G 2.5M 1.3G 1% /run
/dev/sda3 177G 159G 11G 94% /
tmpfs 6.5G 55M 6.5G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 6.5G 0 6.5G 0% /run/qemu
/dev/sda2 512M 6.1M 506M 2% /boot/efi
tmpfs 1.3G 1.7M 1.3G 1% /run/user/1000
/dev/sr0 4.7G 4.7G 0 100% /media/lqy/Ubuntu 22.04.3 LTS amd64
inode和分区大小没有直接的联系,有可以inode少,因为文件比较少,但是每一个文件都很大,那么分区剩下空间也比较少了,但是如果是一个大的文件,那它的inode也是比较大,因为inode中要存储文件的block地址信息
spuerblock
所以就是从 inode table当中我们理解了说文件系统中我们是使用inode节点来保存和空间地址的映射,那么现在我们还有一个问题,就是在整个文件系统中,因为我们会不断创建,删除等等文件,我们是如何对整个文件系统的状态进行维护的,先在还剩下多少inode?这些等等问题?
因此,引入了superblock, 使用superblock
- 记录整个文件的信息
- 一个inode和block的大小
- inode使用情况:已使用数量,未使用数量
- block使用情况:已使用数量,未使用数量
- 文件系统挂载情况
- 文件系统挂载时间,最后一次写入数据,检验磁盘的时间
- 当文件系统挂载时,这部分信息会加载到内存中,并常驻内存
所以首先是磁盘会进行格式化
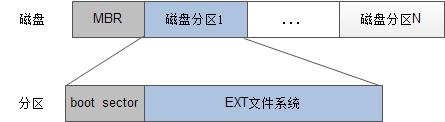
分为物理格式化和逻辑格式化
- 物理格式化:将磁盘分区:MBR中存放分区信息,开机代码
- 逻辑格式化:在磁盘上安装文件系统,将磁盘分为不同block,不同区段
然后在文件系统的逻辑格式化中,有不同区段
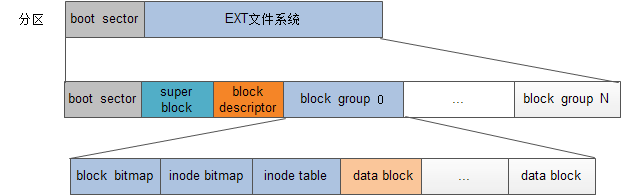
- boot sector: 引导扇区
- superblock:记录文件系统的整体信息,inode和block信息
- block group
- 每个block group都有一个group description,就是在block Descriptor中存储了N个block group的地址
- block bitmap: 记录block的使用情况
- inode bitmap: 记录inode的使用情况
- inode table, data block
然后就是在内存中,会加载superblock和inode的信息,从而在内存中维护一个文件系统的状态
额,反正整个的逻辑图是:
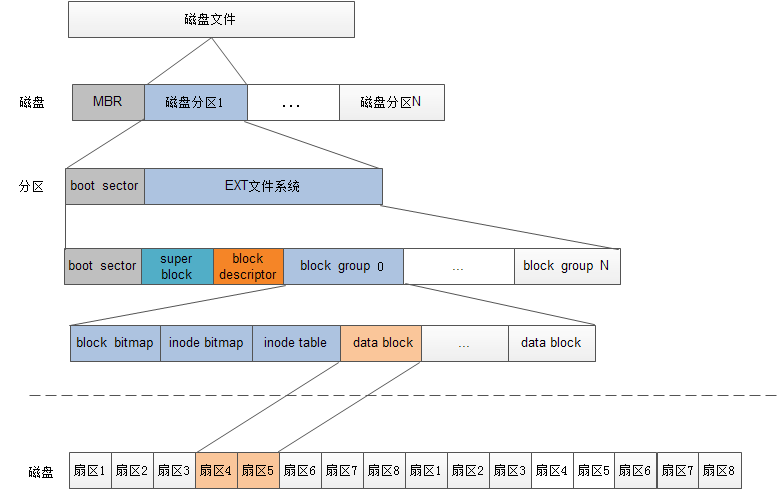
目录与目录项
知道了对应的磁盘化格式化之后,知道了文件系统对文件的存储,也知道了在文件系统中使用 superblock 维护对整个分区的状态,使用 inode 保持数据的地址。但是在我们的使用中我们会发现,我们都是使用文件名或者目录名来保持和数据地址的映射,但是在inode结构中并没有保存文件名部分,是如何实现这样的映射关系的?
其实一个基本的原理都是通过inode建立和对应数据地址的映射,实际上是,目录本质也是一个文件,有自己的inode,在inode中将其标志为目录,而其也会有data block存储这个目录的数据
目录的数据本质上就是一个表格,由若干个目录项组成(文件名和inode编号)。一个目录下面可以有多个文件
- 文件名和文件对应的inode
- 多个子目录:目录名和对应inode
- 多个子目录构成树状的文件系统结构
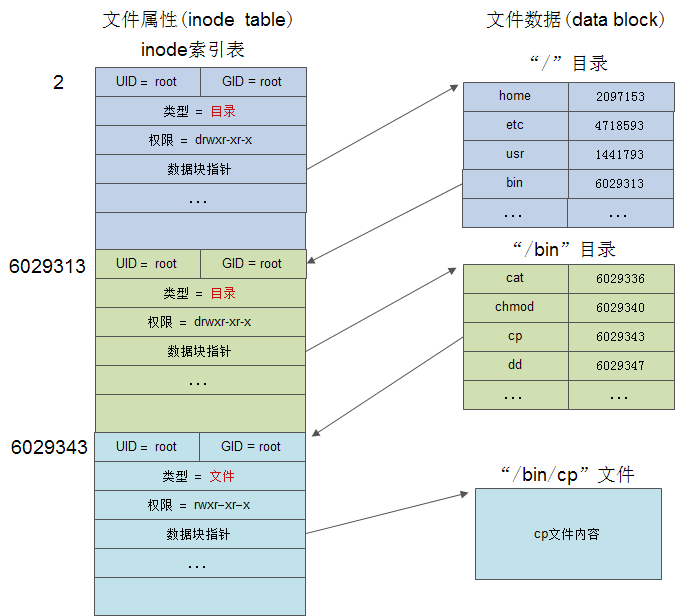
以上就是一个访问"/bin/cp"文件,首先是对应的"/"目录,这个一般是inode=2的部分,然后我们通过它的inode找到对应的data block,找到对应子目录的inode,然后递归就可以找到对应文件的inode,从而映射到对应位置
根目录“/”的inode编号为2,那么inode编号为1的文件是什么?
- 一般是VFS,Linux的虚拟文件系统
好,不觉得还是怪怪的吗,就是就算说我知道了目录实际本质也是一个文件,我们可以查找目录项得到对应的inode项,奇怪的就是,当我们使用文件路径的时候,我们传递的是类似\bin\cp\xxx.txt类似的一个 字符串,他是一个字符串啊,就算是绝对路径,以根开始的路径它也只是一个字符串,那第一个开始的inode,第一个要找的目录,要去读的目录的data block在哪?Linux 如何从一个字符串找到 inode?
文件路径解析
于是,对于绝对路径:获取根目录的 inode,根目录 / 的 inode 号(在 ext4 中一般是 2)。
操作系统内部会维护 超级块(Superblock),其中存储了根目录的 inode 号。他会从对应的超级块中得到
对于相对路径:操作系统需要依赖 当前工作目录(CWD, Current Working Directory) 来解析,它的关键点就是,每个进程都有一个当前工作目录的 inode,这个信息存储在 进程控制块(PCB, Process Control Block) 里。系统调用 getcwd() 可以获取当前目录,它实际上是查找 CWD 的 inode 并转换成路径字符串。当解析 user/file.txt 时,系统会从 CWD inode 开始,像解析绝对路径一样逐级解析。
要理解在文件系统上有操作系统。
至此我们了解了文件系统需要的基本的概念,如何存储,存储什么,如何解析路径等等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号