MySQL主从复制
主从复制可以用来做数据库的实时备份,保证数据的完整性;也可以做读写分离,提升数据库系统整体的读写性能。
主从复制原理
参考资料:https://xiaolincoding.com/mysql/log/how_update.html#主从复制是怎么实现
MySQL集群的主从复制过程梳理成3个阶段:
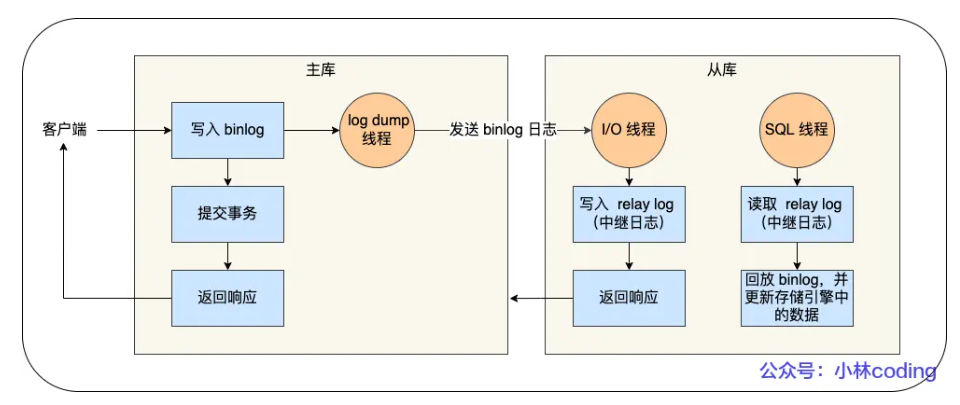
- 写入 Binlog:主库写 binlog 日志,提交事务,并更新本地存储数据。
- 同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
- 回放 Binlog:回放 binlog,并更新存储引l擎中的数据。
具体详细过程如下:
- MySQL 主库在收到客户端提交事务的请求之后,会先写入binlog,再提交事务,更新存储引擎中的数
据,事务提交完成后,返回给客户端"操作成功"的响应。 - 从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把
binlog 信息写入 relay log 的中继日志里,再返回给主库"复制成功"的响应。 - 从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中
的数据,最终实现主从的数据一致性。
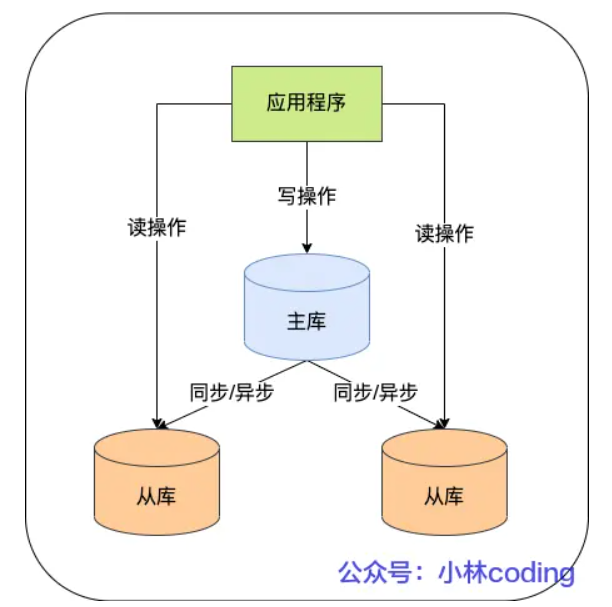
在完成主从复制之后,你就可以在写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者
锁记录,也不会影响读请求的执行。
主从复制配置
前置工作
在两台机上分别安装MySQL,相关教程可查看我的相关博客Ubuntu22.04安装MySQL8.0.35
hadoop1和hadoop2两台机上都将安装好MySQL,然后hadoop1将作为主节点,hadoop2将作为从节点。主节点提前创建用户用来进行主从连接。注意要给slave权限
CREATE USER 'rust'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'rust'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
修改配置文件
修改主库配置文件如下:
sudo gedit /etc/mysql/my.cnf
# 也可以通过vim修改,命令如下。
#sudo vim /etc/mysql/my.cnf
# 添加如下内容
[mysqld]
server-id = 1
log-bin=mysql-bin
binlog_format=row #这一行可省略,因为MySQL在5.7.7开始的默认值就是row了
binlog-do-db=master_try #用来主从复制的数据库。需要提前创建
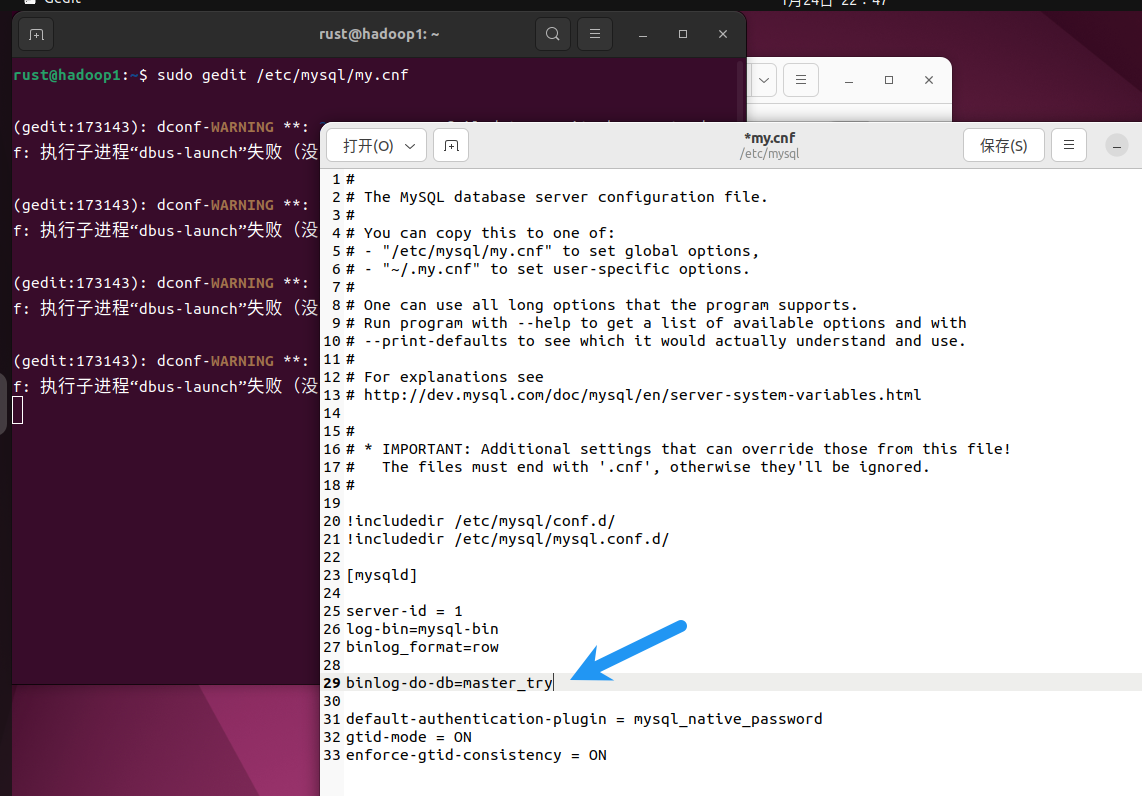
修改后保存重启生效。
sudo systemctl restart mysql
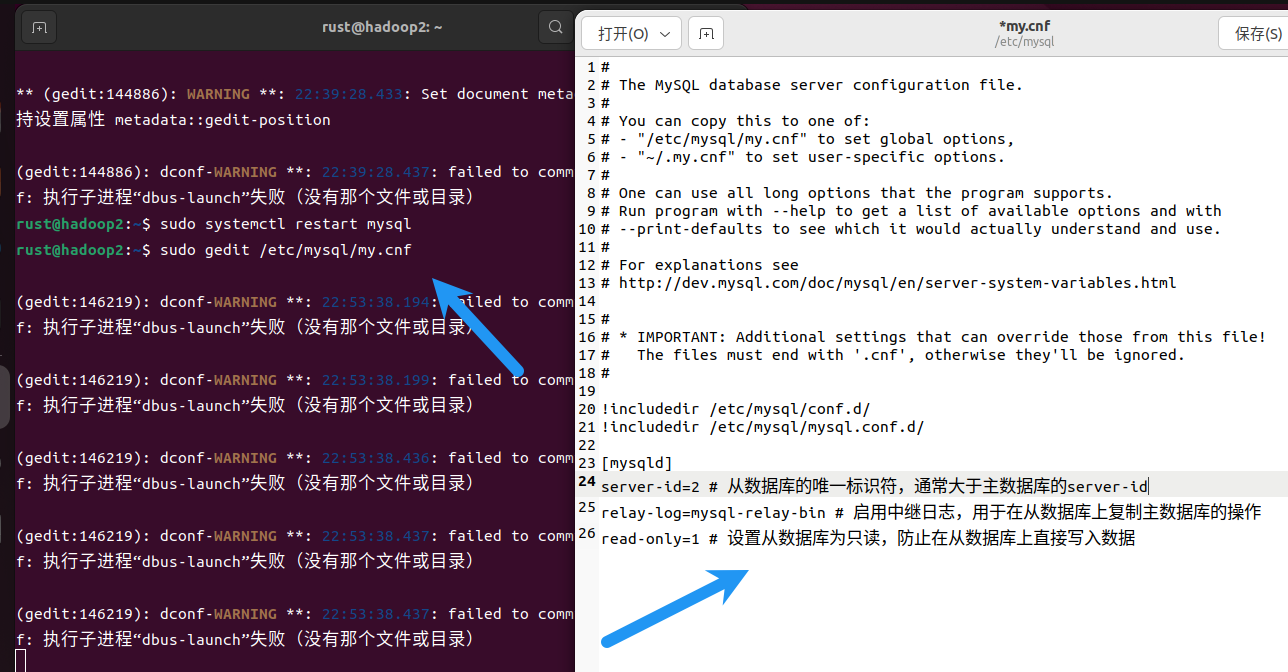
修改从库配置文件如下:
[mysqld]
server-id=2 # 从数据库的唯一标识符,通常大于主数据库的server-id
relay-log=mysql-relay-bin # 启用中继日志,用于在从数据库上复制主数据库的操作
read-only=1 # 设置从数据库为只读,防止在从数据库上直接写入数据
enforce_gtid_consistency = ON
gtid_mode = ON
登录从库,连接到主库
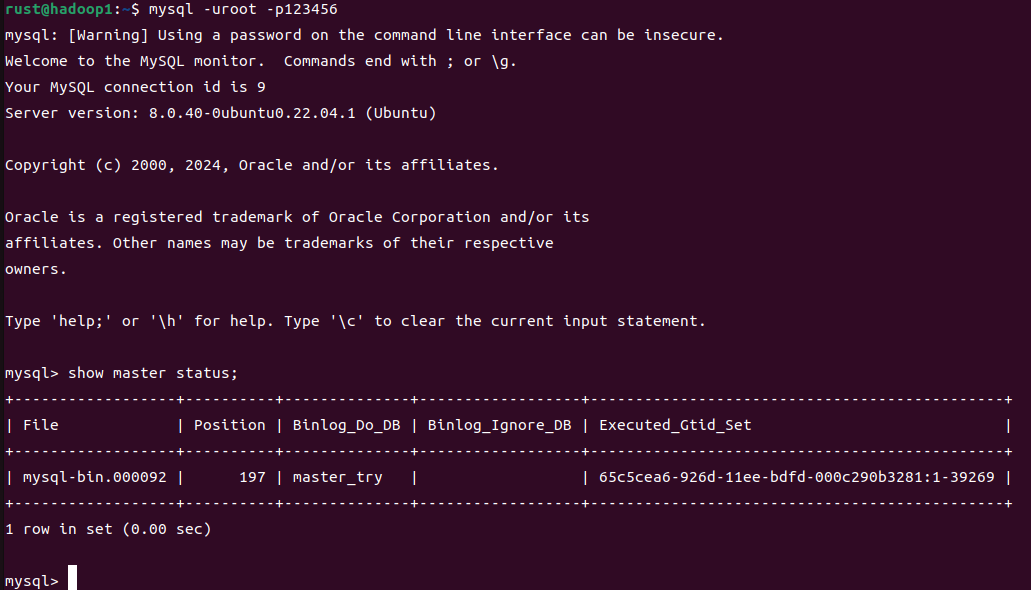
登录主库,查看所需信息:
mysql -uroot -p
show master status;
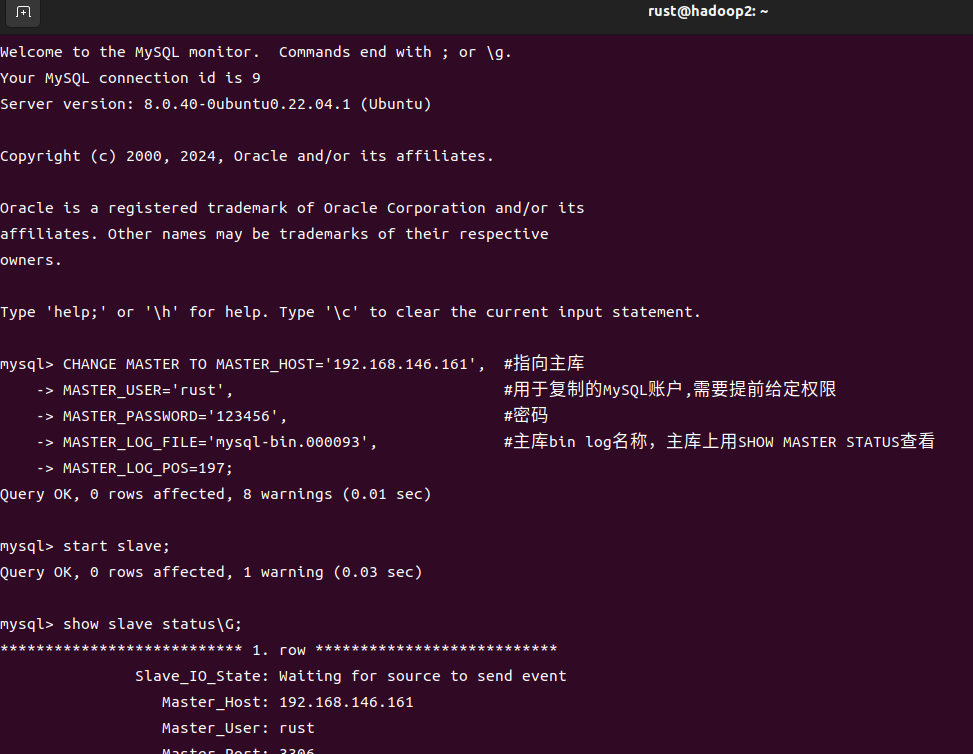
登录从库
mysql -uroot -p #登录mysql
CHANGE MASTER TO MASTER_HOST='192.168.146.161', #指向主库
MASTER_USER='rust', #用于复制的MySQL账户,需要提前给定权限
MASTER_PASSWORD='123456', #密码
MASTER_LOG_FILE='mysql-bin.000093', #主库bin log名称,主库上用SHOW MASTER STATUS查看
MASTER_LOG_POS=197; #主库bin log位置,主库上用SHOW MASTER STATUS查看
START SLAVE; #启动从库进程
SHOW SLAVE STATUS\G; #显示进程状态
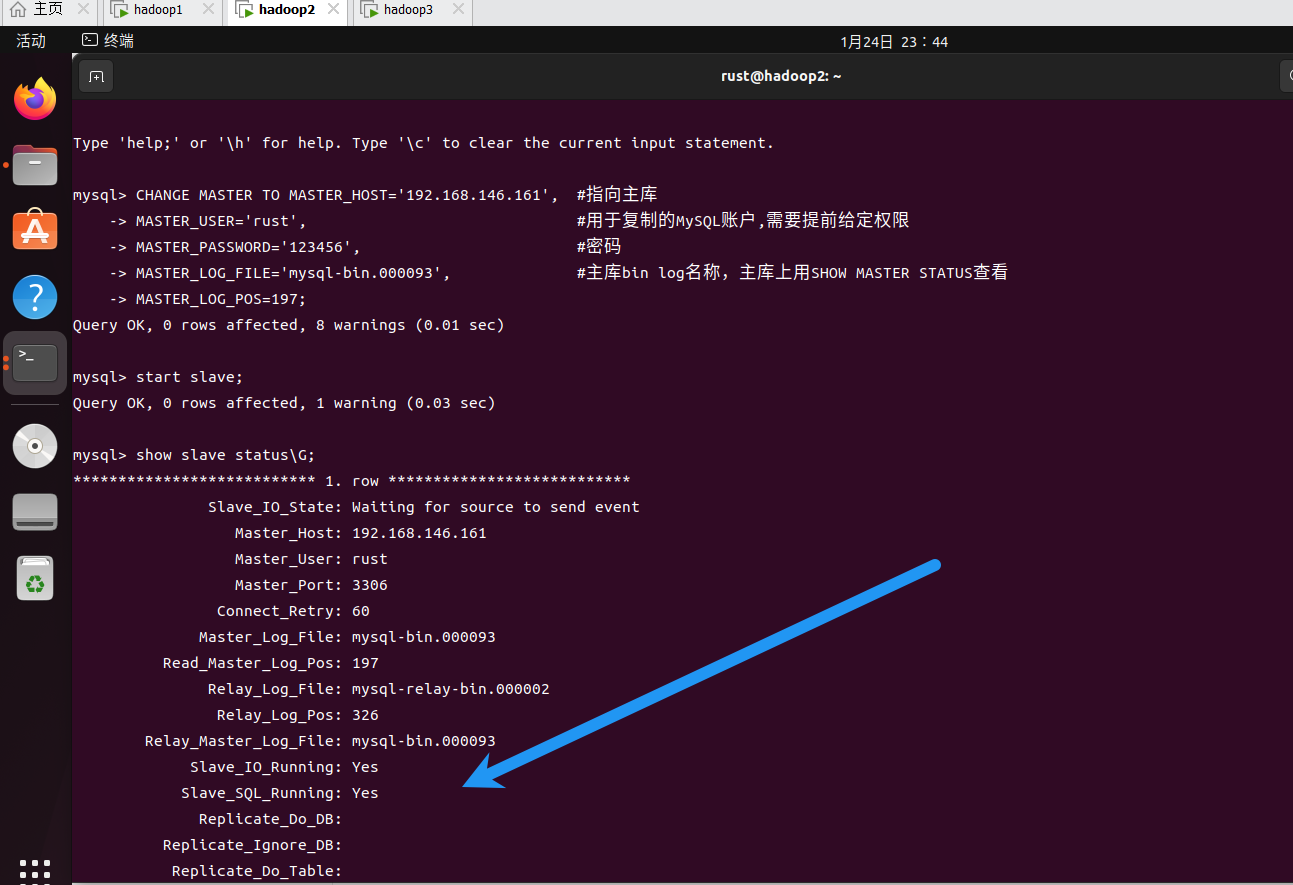
注意这里一定要出现两个Yes才行。
测试
登录主库,建表插入如下数据。
use master_try;
create table student(
`id` int auto_increment primary key,
`name` varchar(50),
`age` int
);
insert into student(id,`name`,age) values ('1','姬丝秀忒·雅赛劳拉莉昂·刃下心','598');
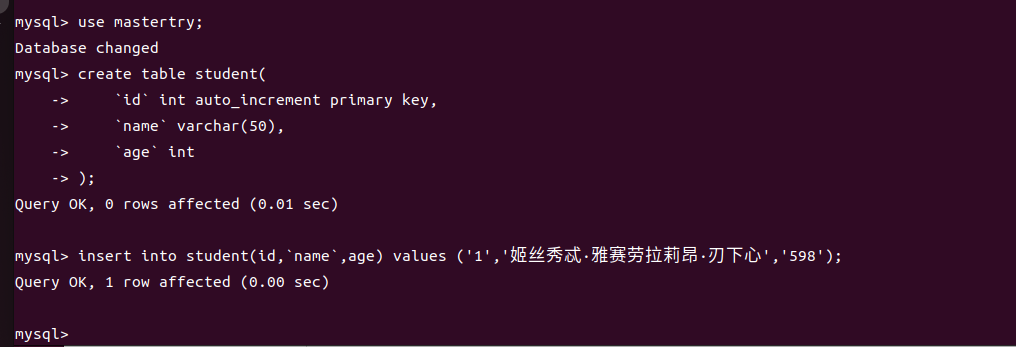
登录从库,查看建表及插入情况。
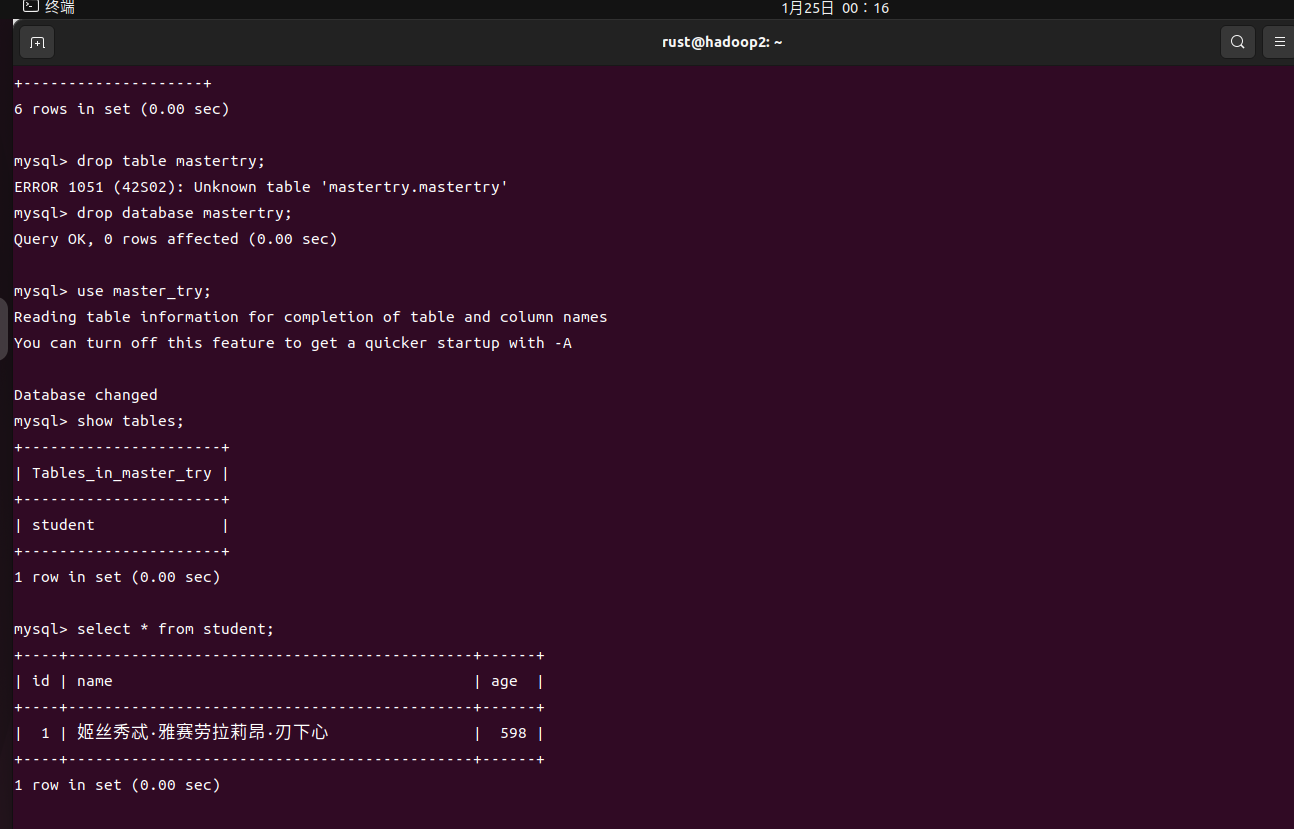
同步成功,完成主从复制搭建。
踩坑与备注
slave_io_running:no
这是因为从库连接主库填写的信息有误,比如log_file和pos。补救方法,在从库执行如下命令:
stop slave;
reset slave all;
#再执行一遍正确的连接主库命令
从库show slave status\G;正常,但查看不到主库数据
这种是主库建的数据库和主库配置文件开启的数据库不同导致的,也就是说主库没有建立配置文件里的数据库。
(我呆得不行,主库配置文件里写的master_try,结果我建表转眼就建成mastertry。查不到数据我还以为是权限的问题,走了好多弯路)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号