SparkStreaming使用socket
参考:https://www.bilibili.com/video/BV11A411L7CK?p=188&vd_source=2db7c64d895a2907954a5b8725db55d5
终端打印大量日志影响结果查看可以看我首页的博客解决。
踩坑如下:
1.socket编程不会,写socket发送数据查了很多资料才写出来
2.Windows没有netcat命令,但是MACOS和Ubuntu有,所以理所当然的想到用虚拟机的端口来收集数据和输入数据,事实上这个想法确实没有问题,分别做的话是能正常实现的,但是这也为后续的错误埋下了大坑。想当然的把socket当成kafka用(producer和consumer),是我踩坑的一大原因。
3.被教程误导,socket发送数据到端口,但是不知道socket有服务器和客户端之分,发送数据和处理数据的都是客户端,导致发送端可以和nc -lk
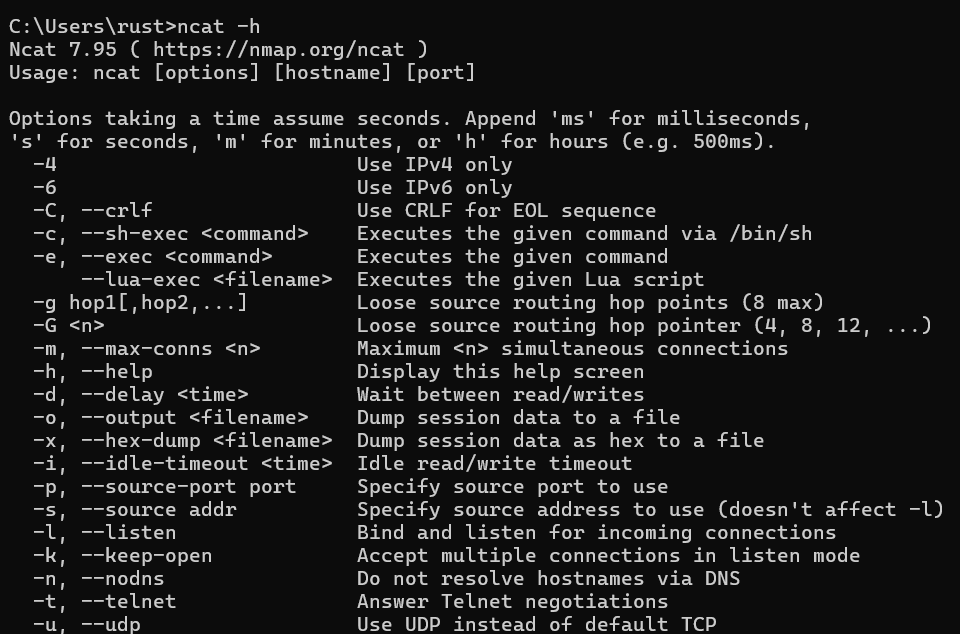
Windows安装netcat
下载链接: https://nmap.org/download.html#windows
下载的是一个exe包,点击exe包一路next即可完成安装。
端口同时接收数据和计算数据时使用命令监听会无法访问,即启动socket数据发送程序和SparkStreaming数据计算程序后无法监听。但是监听命令可以用来分别调试两个程序。
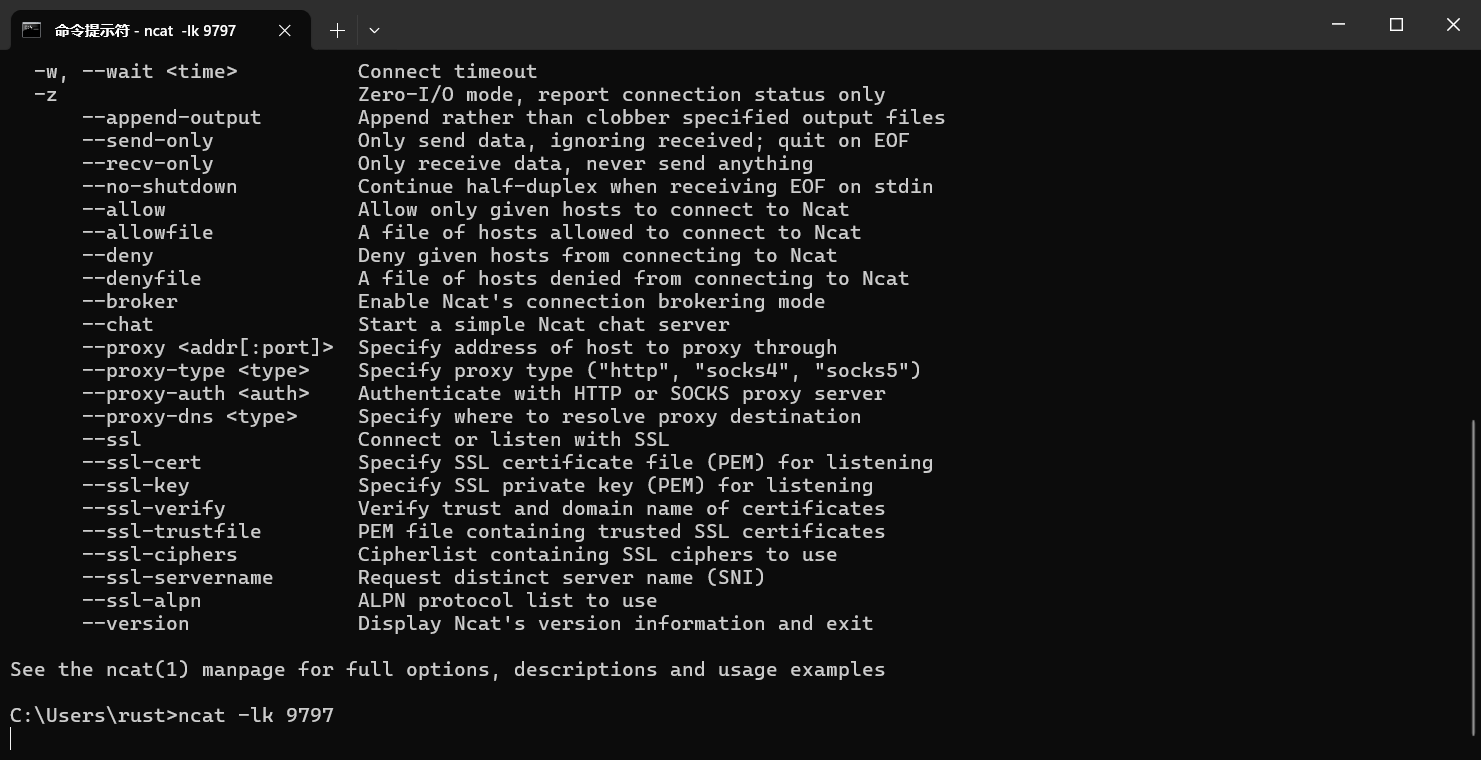
注意:Windows的netcat命令与Ubuntu和MacOS都不一样。Windows的命令是 ncat -lk <Port>,参数的意思可以通过ncat -h查看。
SparkStreaming socket编程
题目:1)写一个应用程序利用套接字每隔2秒生成20条大学主页用户访问日志(可以自定义内容),数据形式如下:“系统时间戳,位置城市,用户ID+姓名,访问大学主页”。其中城市自定义 9个,用户ID 10个,大学主页 7个。
2)写第二个程序每隔2秒不断获取套接字产生的数据,并将词频统计结果打印出来。
导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.3.2</version>
</dependency>
package SparkStreaming1
import java.io.{BufferedWriter, IOException, OutputStreamWriter}
import java.net.ServerSocket
import scala.util.Random
object task11 {
def main(args: Array[String]): Unit = {
// 定义城市和用户ID
val cities = Seq("杭州", "南京", "长沙", "天津", "北京", "上海", "成都", "广州", "深圳")
val userIds = Seq("0:阿良良木历", "1:忍野忍", "2:战场原黑仪", "3:羽川翼", "4:八九寺真宵",
"5:神原骏河", "6:千石抚子", "7:阿良良木火怜", "8:阿良良木月火", "9:姬丝秀忒·雅赛劳拉莉昂·刃下心")
val universityUrls = Seq("www.nju.edu.cn", "www.ustc.edu.cn",
"www.zju.edu.cn", "www.fudan.edu.cn", "www.tsinghua.edu.cn", "www.pku.edu.cn", "www.scu.edu.cn")
try {
// 创建一个 socket 连接
// val socket = new Socket("hadoop3", 9765)
val socketServer = new ServerSocket(9765)
val client = socketServer.accept()
println("连接!")
val out = new BufferedWriter(new OutputStreamWriter(client.getOutputStream))
//val in = new BufferedReader(new InputStreamReader(client.getInputStream))
while (true){
for (_ <- 1 to 20) {
// 发送多条数据
val currentTime = System.currentTimeMillis()
val city = cities(Random.nextInt(cities.length))
val userId = userIds(Random.nextInt(userIds.length))
val universityUrl = universityUrls(Random.nextInt(universityUrls.length))
val logLine = s"$currentTime $city $userId $universityUrl"
out.write(logLine + "\n") // 添加换行符以区分消息
out.flush() // 确保数据被发送出去
println(logLine)
}
Thread.sleep(2000) // 休眠2秒,模拟连续发送
}
// 关闭 socket
out.close()
// socket.close()
client.close()
} catch {
case e: IOException =>
e.printStackTrace()
}
}
}
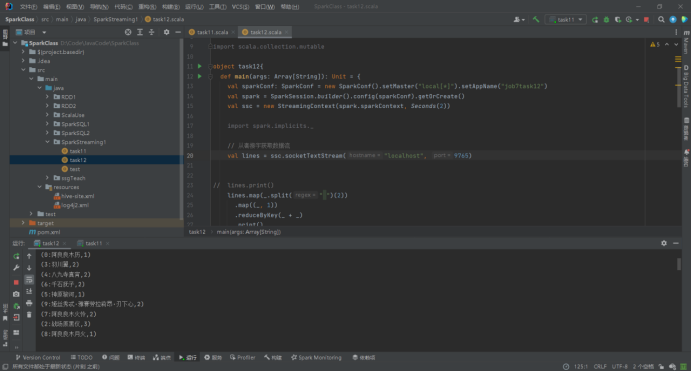
package SparkStreaming1
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
object task12{
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("job7task12")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val ssc = new StreamingContext(spark.sparkContext, Seconds(2))
// 从套接字获取数据流
val lines = ssc.socketTextStream("localhost", 9765)
lines.map(_.split(" ")(2))
.map((_, 1))
.reduceByKey(_ + _)
.print()
ssc.start()
ssc.awaitTermination()
}
}
启动时需要先启动数据计算程序,再启动数据发送程序。
成功运行截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号