Scala中函数与Spark的算子的区别
Scala中的部分函数和RDD中的部分算子名字一样,功能一样,用起来也差不多。但是为什么一个叫函数,一个却要叫算子,函数和算子的区别在哪,这让我有些好奇。于是查看了源码,对函数和算子进行了比较。下面以map为例。
Scala中的map函数
Scala中的map通常定义在集合类中,例如Map、List、Seq、Set。作用是对该可迭代集合的所有元素应用一个函数,从而建立一个新的可迭代集合。
Builds a new iterable collection by applying a function to all elements of this iterable collection.
注意:List属于scala.collection.immutable的子类,而Map、Seq、Set属于scala.collection的子类
map函数最底层的源码应该是scala.collection里的如下代码
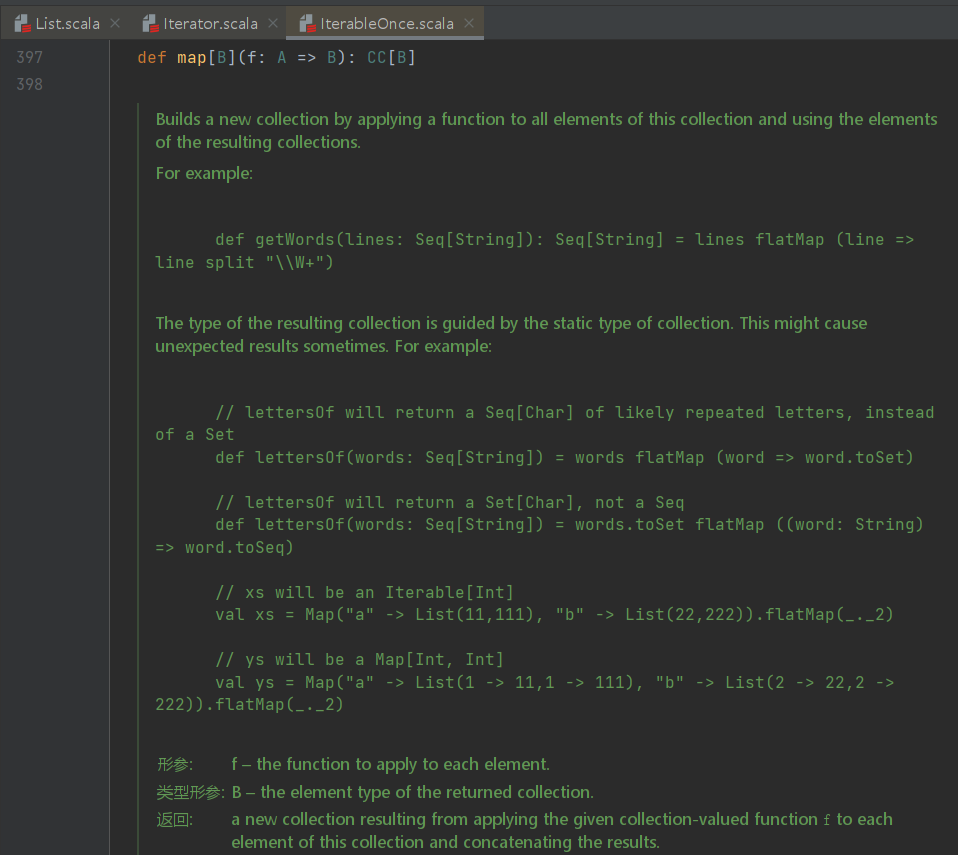
具体实现以List中的map举例
源码为
final override def map[B](f: A => B): List[B] = {
if (this eq Nil) Nil else {
val h = new ::[B](f(head), Nil)
var t: ::[B] = h
var rest = tail
while (rest ne Nil) {
val nx = new ::(f(rest.head), Nil)
t.next = nx
t = nx
rest = rest.tail
}
releaseFence()
h
}
}
List中的map重写了其父类collection.IterableOnce的map函数,定义了一个匿名函数(f:A=>B),对List中的每个元素A处理后输出B类型的List。比如List[String]经过map处理后可以变成List[Interger]
其他collection的代码可以自行查看,也可以查看Scala的官方文档
Spark中的map算子
Spark中的算子分为转换算子(Transformations (return a new RDD))和行动算子(Actions (launch a job to return a value to the user program)), 转换算子根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value 类型 。具体不再细讲,可以自行查询。
RDD中的map代码如下:
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))
}
可以看出,这里的map首先创建了一个MapPartitionsRDD并生成可迭代对象iter,然后调用了Scala的map函数处理iter。
结论
Scala里的map函数首先定义在scala.collection里,然后子类(List、Set)重写父类的函数。因为Scala里的类型是隐式的,并且查看源代码在一个子类里也只发现了一个map函数,所以Scala里的map并没有重载,而是通过定义父类,子类重写父类函数的方法实现对不同数据结构的操作。
Spark里的map是对RDD进行操作的算子,实际使用了可迭代对象来调用Scala中的map函数。算子本身的定义就是对RDD操作的函数,所以算子应该也可以被称为是函数,但是为了区分Scala中的函数,所以使用了不同的名字。
补充
Spark中的算子并非全都有同名函数,原因可以从RDD的原理上分析。
行动算子需要进行shuffle操作,在shuffle时需要按键分区,对每个分区进行操作后输出。Scala中并没有Shuffle操作,所以行动算子没有同名函数。
而转换算子是生成RDD或者将RDD转换成另外的RDD,Scala本身也有将collection转换为collection的函数,并且转换算子本身就调用了Scala的函数,所以有同名的也正常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号