


缺失值处理
将一些0值不合理的列以列均值填充
# 缺省值处理
features_with_zero = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']
data[features_with_zero] = data[features_with_zero].replace(0, np.nan)
# 使用均值填补NaN
data_filled = data.fillna(data.mean())
异常值处理
基于z-score统计进行异常值处理,阈值为3
from scipy import stats
threshold = 3
z_scores = np.abs(stats.zscore(data_filled))
filtered_entries = (z_scores < threshold).all(axis=1)
data_filled = data_filled[filtered_entries]
data_filled.describe()
相关性处理与按相关性序排列并完成可视化
# 计算相关系数矩阵
corr_data = train_data
corr_data["Outcome"] = target
corr_matrix = corr_data.corr()
# 获取与Outcome的相关系数
corr_outcome = corr_matrix['Outcome'].abs().sort_values(ascending=False)
corr_outcome = corr_outcome.drop('Outcome')
# 可视化相关性排序
plt.rcdefaults()
plt.figure(figsize=(10, 6))
sns.barplot(x=corr_outcome.values, y=corr_outcome.index, palette='viridis')
plt.title('sort by corr with Outcome')
plt.xlabel('abs of corr')
plt.ylabel('feature')
plt.show()

选择相关性最高的'Glucose', 'BMI',做归一化处理
# 归一化处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler_train_data_selected = scaler.fit_transform(train_data_selected)
data_scaled = pd.DataFrame(scaler_train_data_selected, columns=train_data_selected.columns)
训练逻辑回归模型并绘制散点图
标注:散点图的绘制函数由GPT完成
train_size = 0.2
x_train, x_test, y_train, y_test = train_test_split(data_scaled, target, train_size = train_size, random_state = 14)
model = LogisticRegression(max_iter=1000, solver='saga', C=0.5)
model.fit(x_train, y_train)
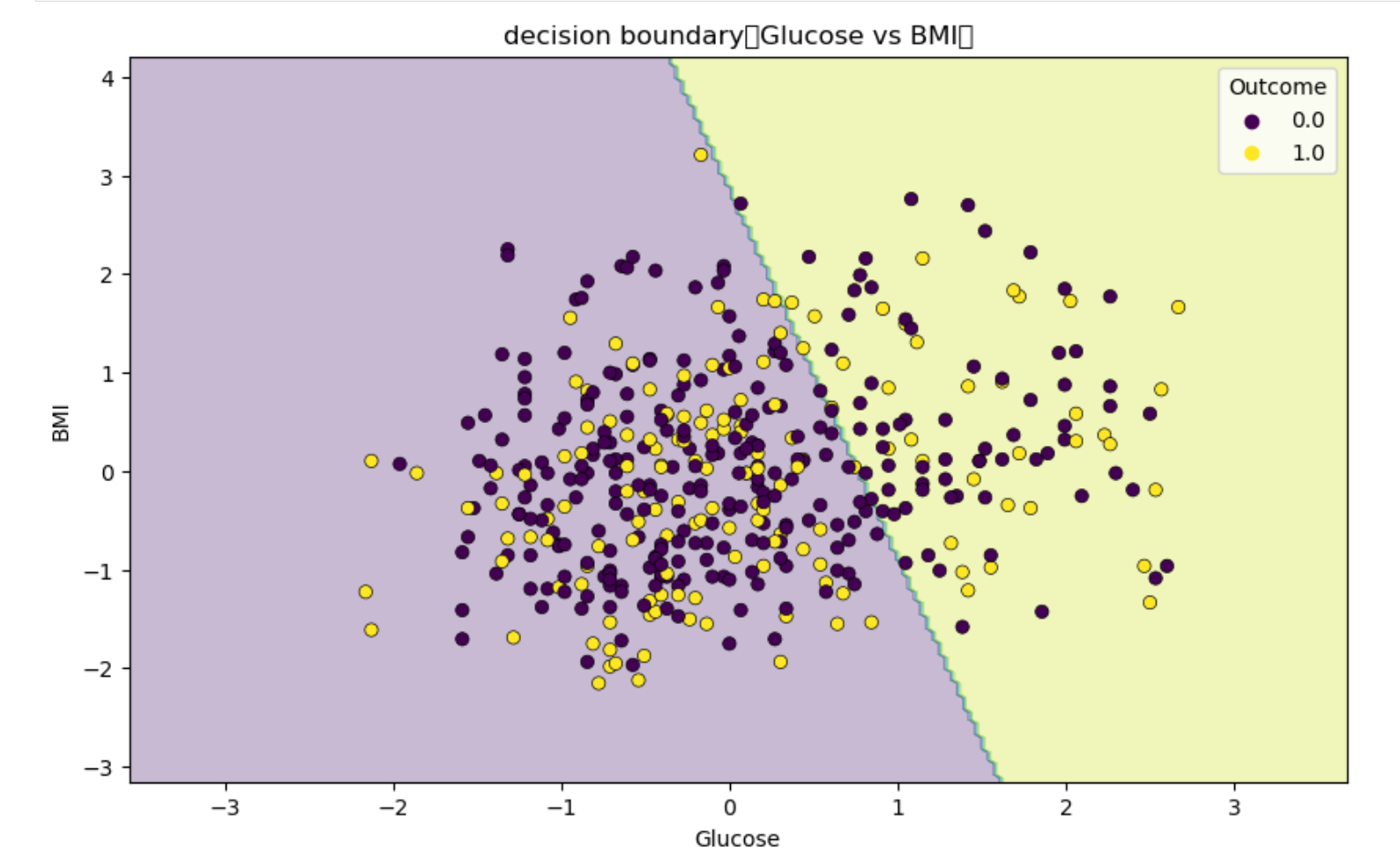
拆分训练集完成不同size的测试
test_sizes = [0.75, 0.80, 0.85]
for size in test_sizes:
X_train, X_test, Y_train, Y_test = train_test_split(data_scaled, target, train_size = size, random_state = 42)
model = LogisticRegression(max_iter = 1000, penalty='l2', solver='lbfgs', C = 0.01)
model.fit(X_train, Y_train)
Y_pred = model.predict(X_test)
acc = accuracy_score(Y_test, Y_pred)
print(f'Train size: {size}, Accuracy: {acc:.4f}')

 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号