spark数据倾斜与解决方法
一、数据倾斜
数据倾斜一般发生在对数据进行重新划分以及聚合的处理过程中。执行Spark作业时,数据倾斜一般发生在shuffle过程中,因为Spark的shuffle过程需要进行数据的重新划分处理。在执行shuffle过程中,Spark需要将各个节点上相同key的数据拉取到某个处理节点的task中进行处理,如对事实数据按照某个维度key进行聚合或者join等含shuffle操作。在此过程中,如果各个key对应的数据量相差较大,存在某一个或者几个key对应的数据量特别大,就是发生了数据倾斜。例如一个聚合作业中,大部分key对应100条数据,但是少数个别key却对应了100万条左右的数据,那么执行时若一个task处理一个key对应的数据,则大部分task很快(如1秒钟)完成,个别task要处理100万条数据,需要花费较多的时间(如1个小时)完成。而整个Spark作业的运行速度是由运行时间最长的task决定的,这里整个作业的运行时间变得很长,不能充分利用Spark的并行能力,极大地影响作业的处理性能。
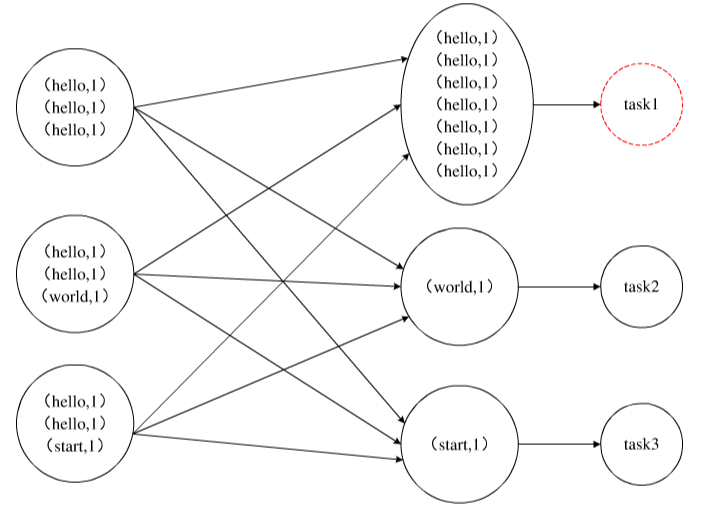
如图,是一个简单的数据倾斜示意图,在shuffle过程中对数据按照key进行重新划分后,其中一个key(hello)对应的数据量远大于其他key(world,start)的数据量,从而出现了数据倾斜。这就导致后续的处理任务中,task1的运行时间肯定远远高于其他的task2、task3的运行时间。该Spark作业的运行时间也由task1的运行时间决定。因此,在处理过程中出现数据倾斜时,Spark作业的运行会非常缓慢,无法体现出Spark处理大数据的高效并行优势,甚至可能因为某些task处理的数据量过大导致内存溢出,使得整个作业无法正常执行。
二、数据倾斜的现象
数据倾斜发生后现现象会有两种情况:
1、大部份的Task执行的时候会很快,当发生数据倾斜后的task会执行很长时间。
2、有时候数据倾斜直接报OOM即:JVM Out Of Memory内存溢出的错误。
三、解决方法
(1)过滤倾斜key优化法
如果在Spark作业中发生数据倾斜时,能够确定只有少数个别的key数据量倾斜较大,而它们又对计算结果影响不大,我们可以采用这种方法。针对发生倾斜的key,预先直接过滤掉它们,使得后面的计算能够高效地快速完成。
(2)提升shuffle操作的并行度优化法
在Spark的操作算子中,有一些常用的操作算子会触发shuffle操作,如reduceByKey、aggregateByKey、groupByKey、cogroup、join、repartition等。Spark作业中出现数据倾斜时,很可能就是我们的开发代码中使用的这些算子的计算过程造成的。因为这些算子的执行会触发shuffle过程,进而引起数据的重新划分,导致数据倾斜的产生。默认情况下,我们不会考虑shuffle操作的并行度分配,而是交由Spark控制。但是Spark的默认shuffle并行度(即shuffle read task的数量)为200,这对于很多场景都有点过小。在出现数据倾斜时,我们可以显式提高shuffle操作的并行度,以缓解某些一般的数据倾斜情况。
这种方法需要在使用shuffle类算子时,自己指定并行参数。在开发中我们可以对使用到的shuffle类算子预先传入一个并行参数,如aggregateByKey(1000),显式设置该算子执行时shuffle read task的数量为1000,增加实际执行的并行度到1000。这样增加shuffle read task的数量后,可以让原本分配给一个task的多个key数据重新划分给多个task,通过提高并行度再次分散数据,从而减少每个task的处理数据量,有效缓解和减轻数据倾斜的影响。
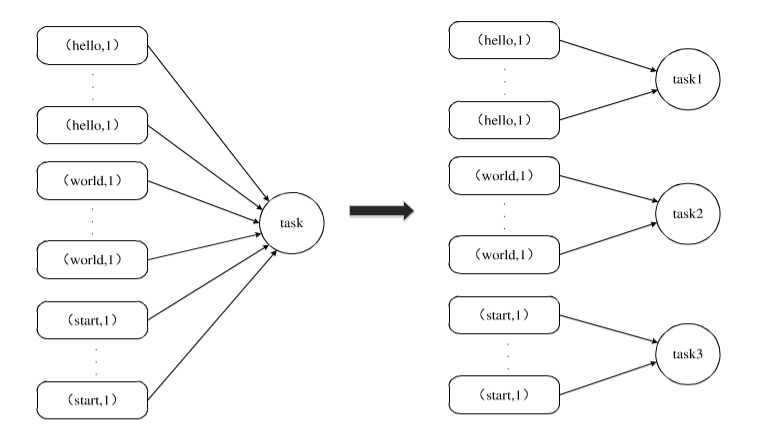
上图展示了一个并行度优化的简单情形。如图所示,由于低并行度发生数据倾斜问题时,在提高了shuffle操作的并行度之后,之前由一个task处理的数据量被重新分散到不同的多个task(task1、task2、task3)中进行处理,这样原来的各个task每次处理的数据量减少很多,从而缓解了存在的数据倾斜问题,能够明显提高处理速度。
显式提高shuffle操作的并行度的方法也是一种易于实现的优化方法。这种方法可以有效缓解数据量较大而并行度较低的数据倾斜问题,但是它并不能彻底根除倾斜问题。如果数据倾斜的原因是某些(个)key数据量较大,则这时提高并行度并不能改善数据倾斜的低性能。同样的这种方法适用场景也很有限,只适用于一些普通场景。
(3)两阶段聚合优化法
在Spark执行作业中,涉及聚合操作时往往会比较容易出现数据倾斜现象。如果在Spark作业执行聚合类操作算子如reduceByKey、aggregateByKey等的过程中,发生数据倾斜时,即出现某些key要聚合的数据量较大的情况下,我们可以采用两阶段聚合优化方法,先将相同的数据打乱成不同的局部数据,进行局部聚合后再统一合并聚合。

上图所示,两阶段聚合方法的第一阶段进行数据的拆分与局部聚合,先给每个待聚合的key附加一个随机前缀,如10以内的随机数,此时原先一样的key数据就扩充成了多个不一样的key’数据。例如图中原先的数据(hello,1)、(hello,1)、(hello,1)、(hello,1)、(hello,1)、(hello,1)经过这样的处理后变为(1_hello,1)、(1_hello,1)、(2_hello,1)、(2_hello,1)、(10_hello,1)、(10_hello,1);然后对处理后的数据执行相应的reduceByKey等聚合操作,进行局部聚合,得到局部聚合结果如(1_hello,2)、(2_hello,2)、(10_hello,2)。第二阶段进行局部数据的合并与聚合,先去除聚合好后的局部数据中各个key’ 的前缀,得到原先的key数据,再次进行全局聚合操作,得到最终的聚合结果。如图中先将局聚合数据(1_hello,2)、(2_hello,2)、(10_hello,2)去除前面添加的前缀变成(hello,2)、(hello,2)、(hello,2),然后再进行一次全局聚合得到最终结果(hello,6)。
两阶段聚优化方法通过将原本相同的key先附加随机前缀的方式,变成多个不同的key’,以达到分散倾斜数据的目的。这种方法可以让原本被一个task负责的大量数据分散开到多个task中执行局部聚合,进而解决单个task处理数据量过多的问题;然后在局部聚合的基础上,再次进行全局聚合,得到最终结果。虽然这样做使得原本只需一步的聚合操作变为两步聚合操作,但是却有效地减轻了由于数据倾斜带来的性能影响,反而能够加速整个聚合作业的执行速度。
此方法非常适合于由于聚合类的shuffle操作导致的数据倾斜,可以大幅度缓解聚合算子的数据倾斜,迅速提升Spark作业的整体性能。但是该优化方法仅仅适用于聚合类的数据倾斜问题,适用范围也相对较窄,不适用其他情况的数据倾斜处理。
(4)转化join优化法
此优化方法适用于针对RDD的join操作,而且join操作中两个RDD或者表的数据量相差较大,即其中一个RDD或者表的数据量相对比较小,这时我们可以考虑此种方法。例如事实表连接小量的维度表进行代理键查找替换的过程,就是一个大表join小表的情形。若进行连接计算的一个RDD数据量相对较小,完全可以先缓存在内存中时,我们可以将较小的RDD中的数据存到一个Broadcast变量(即广播变量)中,先广播到各个节点中,即在每个节点的内存中缓存一份;之后对另外一个较大的RDD(数据)执行一个map类算子,在该map函数内,从本节点的Broadcast变量中获取较小的RDD的全量数据,与当前RDD的各条数据进行比对连接,进而实现预期的join操作。其基本过程如图,将原来的RDD1 join RDD2的task通过将RDD1作为广播变量变成了只需要RDD1 map RDD2的task执行,避免了join算子的执行,从而消除了原先join过程中数据倾斜的出现。
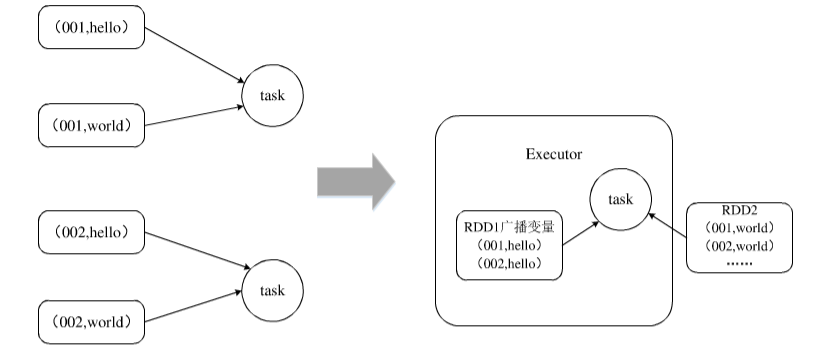
这种方法的主要思路是不使用直接的join算子实现连接,而是根据连接表的特点使用广播变量(Broadcast)和map类算子实现实际的join操作效果,不用经过shuffle过程,从而有效规避join的shuffle操作,彻底避免此过程中数据倾斜的发生。因而,这种优化方法对join操作导致的数据倾斜问题有较好的优化效果,因为它避免了shuffle过程的出现,即从根本上避免了数据倾斜的产生。当然该方法也仅适用于一个大表join一个小表的情况,不适用于两个大表join的情况,因为如果广播出去的RDD数据量较大时,广播过程也会有很大的开销,甚至有可能发生内存溢出,反而降低整体的性能。
三、总结
在实际的Spark作业中,如果发现有数据倾斜现象,很多情况下,可以根据具体的业务场景和发生原因使用上述方法优化作业的执行性能。但是如果要处理的数据倾斜场景较为复杂时,可能需要组合使用上述多种方法,这时我们要能够根据自己的实际情况,考虑不同的思路,灵活地运用多种方法,解决自己的数据倾斜问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号