

requests库和BeautifulSoup4库爬取新闻列表
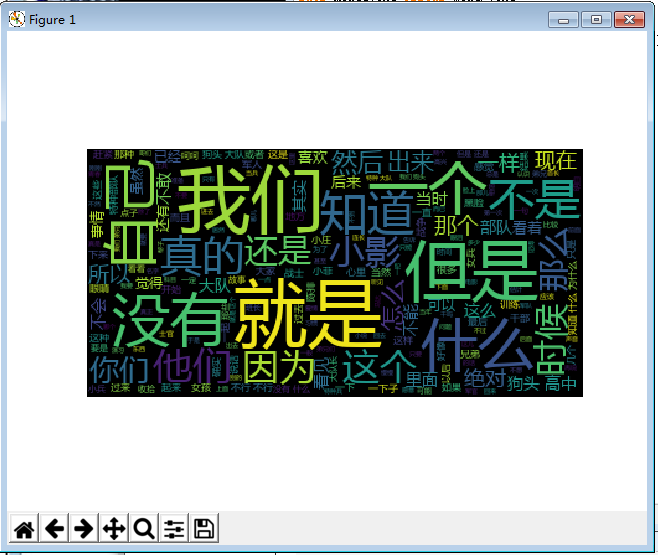
画图显示:
import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt txt = open("zuihou.txt","r",encoding='utf-8').read() wordlist = jieba.lcut(txt) wl_split=" ".join(wordlist) mywc = WordCloud().generate(wl_split) plt.imshow(mywc) plt.axis("off") plt.show()
结果:
用requests库和BeautifulSoup4库,爬取校园新闻列表的时间、标题、链接、来源、详细内容
爬虫,网页信息
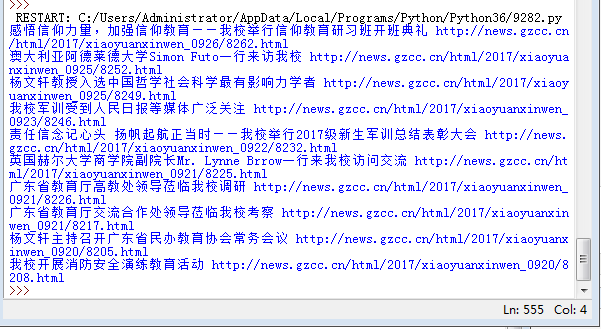
import requests from bs4 import BeautifulSoup gzccurl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/' res = requests.get(gzccurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') for news in soup.select('li'): if len(news.select('.news-list-title'))>0: title = news.select('.news-list-title')[0].text url = news.select('a')[0]['href'] print(title,url)
结果:
加上时间:
for news in soup.select('li'): if len(news.select('.news-list-title'))>0: title = news.select('.news-list-title')[0].text url = news.select('a')[0]['href'] time = news.select('.news-list-info')[0].contents[0].text print(time,title,url)
效果:

- 将其中的时间str转换成datetime类型。
- 将取得详细内容的代码包装成函数。
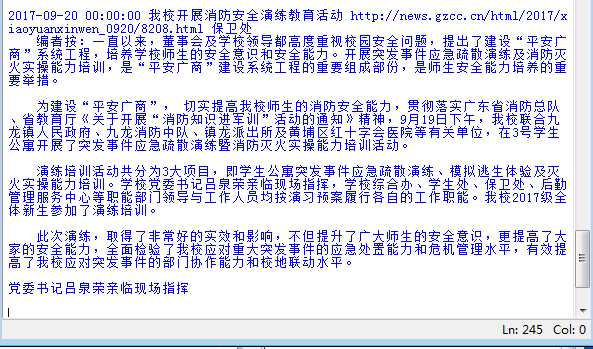
import requests from bs4 import BeautifulSoup from datetime import datetime gzccurl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/' res = requests.get(gzccurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') def getdetail(url): resd = requests.get(url) resd.encoding= 'utf-8' soupd = BeautifulSoup(resd.text,'html.parser') return(soupd.select('.show-content')[0].text) for news in soup.select('li'): if len(news.select('.news-list-title'))>0: title = news.select('.news-list-title')[0].text url = news.select('a')[0]['href'] time = news.select('.news-list-info')[0].contents[0].text dt = datetime.strptime(time,'%Y-%m-%d') source = news.select('.news-list-info')[0].contents[1].text detail = getdetail(url) print(dt,title,url,source,detail)
结果:
- 选一个自己感兴趣的主题,做类似的操作,为后面“爬取网络数据并进行文本分析”做准备。
import requests from bs4 import BeautifulSoup from datetime import datetime gzccurl = 'http://www.lbldy.com/tag/gqdy/' res = requests.get(gzccurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') def getdetail(url): resd = requests.get(url) resd.encoding= 'utf-8' soupd = BeautifulSoup(resd.text,'html.parser') return(soupd.select('.show-content')[0].text) for news in soup.select('h4'): print(news)
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号