
Gazebo仿真环境中PX4无人机部署YOLOv5+DeepSort实现多目标跟踪
多目标跟踪
多目标跟踪(MOT, Multi Object Tracking)是计算机视觉领域的核心任务,旨在从视频序列中持续检测并跟踪多个目标(如行人、车辆、动物等),并为每个目标分配唯一的 ID,同时记录其运动轨迹。MOT 广泛应用于自动驾驶、视频监控、人机交互、体育分析等领域。
输入:视频帧序列(每一帧包含多个检测到的目标)
输出:每个目标的轨迹(ID + 位置 + 时间戳)
多目标跟踪的关键挑战:
目标遮挡(Occlusion):目标被其他物体遮挡后如何重新关联。
外观相似性(Similar Appearance):如何区分外观相似的目标(如穿相同衣服的行人)。
实时性(Real-Time):高帧率场景下的计算效率。
从上面部分不难看出,MOT为了能准确的识别和跟踪目标,需要连续的多帧图像作为输入,这与只需要单张图片就能完成识别的目标检测算法不同。
MOT的实现主要分为2个部分:
1、检测:使用目标检测器(如 YOLO、Faster R-CNN)逐帧检测目标。
2、跟踪:通过算法(SORT、DeepSORT)处理检测环节输出的多帧图像,推理出目标轨迹并用检测框跟踪框选目标。
YOLO和DeepSort分别是MOT两个关键步骤的经典算法
本项目的方案就是通过YOLOv5进行目标检测,并将检测结果输入DeepSort目标跟踪器,最后得出目标的跟踪结果
部署方案
部署YOLO+DeepSort算法有两种方式:
1、直接安装YOLO+DeepSort的集成版本,在Github上下载源码并安装,目前已经更新到了YOLOv8的版本,也可以选择之前的版本,Github链接如下:https://github.com/mikel-brostrom/boxmot
2、分别部署YOLO和DeepSort
因为本机已经在之前部署了YOLOv5算法并在Gazebo仿真环境的无人机上实现了目标检测,现在只需要再部署DeepSort算法,所以采用方案2
直接在终端输入pip install deep_sort_realtime安装deep_sort_realtime库
YOLOv5可以参考之前的帖子https://www.cnblogs.com/rui27/p/18806290,该帖子详细的介绍了YOLOv5的部署,并在ROS节点中接收相机图像、调用YOLO进行目标检测、发布检测结果的一系列流程。
方案1包含了一个完整的工程,若后续需要修改源码也比较方便,但是在已有YOLO的环境中容易产生环境冲突。
方案2直接下载deep_sort_realtime库,该库基于纯python实现,兼容性好,能够在无须改动已安装YOLO的情况下快速集成,且专门做过轻量化处理。
两个方案各有优劣,可以根据自己的情况选择。
YOLOv5+DeepSort实现多目标跟踪
安装deep_sort_realtime库及其依赖
pip install deep_sort_realtime
pip install onnxruntime-gpu
其中的onnxruntime-gpu可以用来查看GPU和CPU的使用情况,有助于后续的调试,检查算法是否使用了GPU加速
创建ROS节点的内容不在赘述,可以在之前的帖子里查看。
我们直接修改之前调用YOLOv5进行目标检测的节点,修改后的完整内容如下:
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import rospy
import cv2
import torch
import numpy as np
import onnxruntime as ort
import warnings
from functools import partial
from cv_bridge import CvBridge, CvBridgeError
from std_msgs.msg import Header
from geometry_msgs.msg import Twist
from sensor_msgs.msg import Image, RegionOfInterest
from yolov5_ros.msg import BoundingBox, BoundingBoxes
from deep_sort_realtime.deepsort_tracker import DeepSort
from threadpoolctl import threadpool_limits
class Yolov5Param:
def __init__(self):
# load local repository(YoloV5:v6.0)
# 指定yolov5的源码路径,位于/home/rui27/yolov5/
yolov5_path = rospy.get_param('/yolov5_path', '')
# 指定yolov5的权重文件路径,位于/home/rui27/yolov5/yolov5s.pt
weight_path = rospy.get_param('~weight_path', '')
# yolov5的某个参数,这里不深究了
conf = rospy.get_param('~conf', '0.5')
# 使用pytorch加载yolov5模型,torch.hub.load会从/home/rui27/yolov5/中找名为hubconf.py的文件
# hubconf.py文件包含了模型的加载代码,负责指定加载哪个模型
self.model = torch.hub.load(yolov5_path, 'custom', path=weight_path, source='local')
# 一个参数,用来决定使用cpu还是gpu,这里我们使用gpu
if (rospy.get_param('/use_cpu', 'false')):
self.model.cpu()
else:
self.model.cuda()
self.model.conf = conf
# 初始化DeepSort
self.tracker = DeepSort(
max_age=15, # 最多允许丢失目标的帧数,超出就会删除该检测框以及相应的轨迹
max_iou_distance=1.0, # 预测框和目标框的最大距离,超过该距离则判断丢失目标,该参数越高越不容易丢失目标,但是会容易导致误匹配
max_cosine_distance=0.2, # 行人重识别(ReID)的最大余弦距离,超过该阈值则判断丢失目标,该参数越高越不容易丢失目标,但是稳定性会降低
n_init=3, # 连续检测到一定次数,才确认生成检测框和对应的轨迹
embedder="mobilenet", # 使用的模型,mobilenet是适用于无人机等移动机器人的轻量化模型
half=True, # 使用半精度浮点数(FP16)加速推理,需要使用GPU
bgr=True, # 输入图像是否采用BGR格式,该格式是OpenCV的默认格式
embedder_gpu=True, # 是否使用GPU
nn_budget=100 # 限制历史样本数量,加快匹配速度
)
# 打印GPU和CUDA的使用情况,检查yolov5和deepsort是否使用gpu加速
print("Available providers:", ort.get_available_providers())
print("CUDA Available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("Using GPU:", torch.cuda.get_device_name(0))
# target publishers
# BoundingBoxes是本样例自定义的消息类型,用来记录识别到的目标
# 使用/yolov5/targets topic发布出去
self.target_pub = rospy.Publisher("/yolov5/targets", BoundingBoxes, queue_size=1)
def image_cb(msg, cv_bridge, yolov5_param, color_classes, image_pub):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
# 将Opencv图像转换numpy数组形式,数据类型是uint8(0~255)
# numpy提供了大量的操作数组的函数,可以方便高效地进行图像处理
cv_image = cv_bridge.imgmsg_to_cv2(msg, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except (CvBridgeError, e):
print(e)
# 实例化BoundingBoxes,存储本次识别到的所有目标信息
bounding_boxes = BoundingBoxes()
bounding_boxes.header = msg.header
# 将BGR图像转换为RGB图像, 给yolov5,其返回识别到的目标信息
rgb_image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = yolov5_param.model(rgb_image)
# 使用pandas读取yolov5返回的识别结果,简单易用,但是运算速度慢
# boxs = results.pandas().xyxy[0].values
# detections = []
# boxs = [box for box in boxs if str(box[-1]) == 'person']
# for box in boxs:
# x1, y1, x2, y2, conf, cls_name = box[0], box[1], box[2], box[3], box[4], box[-1]
# w, h = x2 - x1, y2 - y1
# detections.append(([x1, y1, w, h], conf, cls_name)) # DeepSORT 接收 xywh 格式
# 直接用numpy进行数据的读取效率更高
boxs = results.xyxy[0].cpu().numpy()
detections = []
for box in boxs:
x1, y1, x2, y2, conf, cls_id = box[:6]
cls_name = yolov5_param.model.names[int(cls_id)]
# 只识别处理person,剔除其他物体,提高检测和跟踪的运行速度
if cls_name != 'person':
continue
w, h = x2 - x1, y2 - y1
detections.append(([x1, y1, w, h], conf, cls_name)) # DeepSORT 接收 xywh 格式
# 限制update时只使用一个线程,防止CPU占用率过高,影响GPU加速
with threadpool_limits(limits=1, user_api='blas'):
tracks = yolov5_param.tracker.update_tracks(detections, frame=frame)
for track in tracks:
if not track.is_confirmed():
continue
track_id = track.track_id
ltrb = track.to_ltrb() # (x1, y1, x2, y2)
cls_name = track.get_det_class() # 需要 deep_sort_realtime >= 1.3
color = color_classes.get(cls_name, np.random.randint(0, 255, 3))
color_classes[cls_name] = color
# 画框 + ID
cv2.rectangle(cv_image, (int(ltrb[0]), int(ltrb[1])), (int(ltrb[2]), int(ltrb[3])),
(int(color[0]), int(color[1]), int(color[2])), 2)
cv2.putText(cv_image, f'{cls_name} ID:{track_id}', (int(ltrb[0]), int(ltrb[1]) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 2)
# 处理并存储识别 + 跟踪结果
bounding_box = BoundingBox()
bounding_box.probability = 1.0 # track没有置信度,设为1
bounding_box.xmin = int(ltrb[0])
bounding_box.ymin = int(ltrb[1])
bounding_box.xmax = int(ltrb[2])
bounding_box.ymax = int(ltrb[3])
bounding_box.num = len(tracks)
bounding_box.Class = cls_name
bounding_boxes.bounding_boxes.append(bounding_box)
# 发布目标数据,topic为:/yolov5/targets
# 可以使用命令查看:rotopic echo /yolov5/targets
yolov5_param.target_pub.publish(bounding_boxes)
# 将标识了识别目标的图像转换成ROS消息并发布
image_pub.publish(cv_bridge.cv2_to_imgmsg(cv_image, "bgr8"))
def main():
warnings.simplefilter("ignore", category=FutureWarning)
rospy.init_node("detect_ros")
rospy.loginfo("starting detect_ros node")
bridge = CvBridge()
yolov5_param = Yolov5Param()
color_classes = {}
image_pub = rospy.Publisher("/yolov5/detection_image", Image, queue_size=1)
bind_image_cb = partial(image_cb, cv_bridge=bridge, yolov5_param=yolov5_param, color_classes=color_classes, image_pub=image_pub)
rospy.Subscriber("/camera/color/image_raw", Image, bind_image_cb)
rospy.spin()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
代码中已经有了很详细的注释,接下来再对部分与DeepSort相关的重要代码单独讲解
# 初始化DeepSort
self.tracker = DeepSort(
max_age=15, # 最多允许丢失目标的帧数,超出就会删除该检测框以及相应的轨迹
max_iou_distance=1.0, # 预测框和目标框的最大距离,超过该距离则判断丢失目标,该参数越高越不容易丢失目标,但是会容易导致误匹配
max_cosine_distance=0.2, # 行人重识别(ReID)的最大余弦距离,超过该阈值则判断丢失目标,该参数越高越不容易丢失目标,但是稳定性会降低
n_init=3, # 连续检测到一定次数,才确认生成检测框和对应的轨迹
embedder="mobilenet", # 使用的模型,mobilenet是适用于无人机等移动机器人的轻量化模型
half=True, # 使用半精度浮点数(FP16)加速推理,需要使用GPU
bgr=True, # 输入图像是否采用BGR格式,该格式是OpenCV的默认格式
embedder_gpu=True, # 是否使用GPU
nn_budget=100 # 限制历史样本数量,加快匹配速度
)
该段代码用于进行DeepSort的初始化,其中的参数会影响目标跟踪的结果,如max_age过大会出现识别框"残影",max_iou_distance和max_cosine_distance设置不好会导致目标容易丢失、频繁切换ID等问题
其他的一些参数主要用于提高DeepSort的推理速度,无人机等移动机器人对轻量化的需求较大
boxs = results.xyxy[0].cpu().numpy()
detections = []
for box in boxs:
x1, y1, x2, y2, conf, cls_id = box[:6]
cls_name = yolov5_param.model.names[int(cls_id)]
# 只识别处理person,剔除其他物体,提高检测和跟踪的运行速度
if cls_name != 'person':
continue
w, h = x2 - x1, y2 - y1
detections.append(([x1, y1, w, h], conf, cls_name)) # DeepSORT 接收 xywh 格式
该段程序负责将YOLOv5输出的结果转换为DeepSort需要的类型,用于后续输入DeepSort
并且在提取过程中剔除除了行人以外的其他物体,本方案只需要识别行人并跟踪,剔除其他物体可以减小DeepSort和后续跟踪程序的压力,提高运算速度
这段程序中的boxs = results.xyxy[0].cpu().numpy()语句将YOLOv5的结果提取为numpy数组形式,也可以使用其他形式(如pandas),但是numpy将数据以统一的数组格式保存,数据的处理效率更高。
使用pandas读取yolov5返回的识别结果,简单易用,但是运算速度慢
boxs = results.pandas().xyxy[0].values
detections = []
boxs = [box for box in boxs if str(box[-1]) == 'person']
for box in boxs:
x1, y1, x2, y2, conf, cls_name = box[0], box[1], box[2], box[3], box[4], box[-1]
w, h = x2 - x1, y2 - y1
detections.append(([x1, y1, w, h], conf, cls_name)) # DeepSORT 接收 xywh 格式
上面是另一种读取YOLO数据的方式,通过pandas读取出的标签能直接以字符串形式存储,方便进行处理,但是也造成了处理速度慢
# 限制update时只使用一个线程,防止CPU占用率过高,影响GPU加速
with threadpool_limits(limits=1, user_api='blas'):
tracks = yolov5_param.tracker.update_tracks(detections, frame=frame)
限制CPU这条指令的时候只使用一个线程,一段看起来很莫名其妙的代码。
通常情况下我们会认为更多的CPU线程才能或得更快的速度,在无人机跟踪这种对实时性要求高的平台上,更应该多核开工。
况且对数据的处理都一般会由CPU进行运算,而我们在GPU进行YOLO和DeepSort的推理,一般认为该数据处理的部分不会影响到YOLO和DeepSort的运行速度。
下面从调试中遇到的问题一步一步分析。
我们可以注释掉with threadpool_limits(limits=1, user_api='blas'):这条命令,直接运行代码。
目标跟踪产生强烈延迟,且不停出现跟丢、目标ID切换等现象。
终端显示我们此时已经使用了GPU进行加速,这是我们查看GPU和CPU的占用率,在终端输入以下两条指令
watch -n 1 nvidia-smi
top
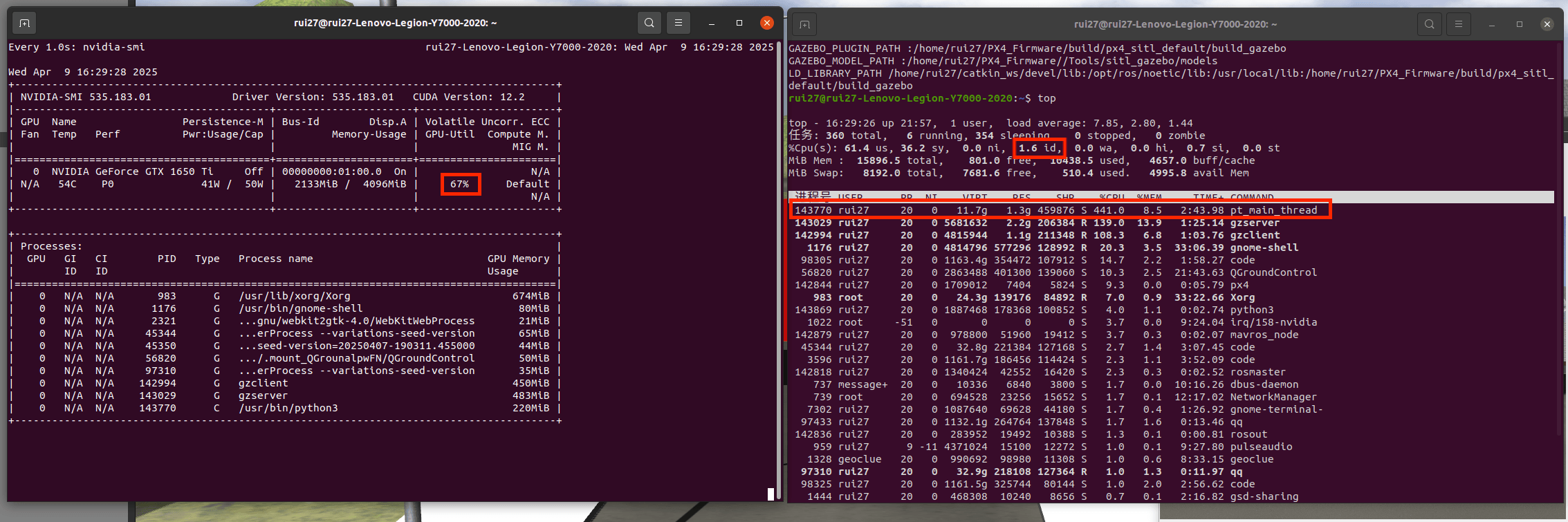
图中左边的67%表示GPU占用率67%,右边的1.6id表示CPU空闲率仅有1.6%,下方显示python线程占据了大量的CPU运算空间。
而之前仅运行YOLO的GPU占用率都能达到80%左右,在增加了DeepSort后反而降低了。这是因为在执行tracks = yolov5_param.tracker.update_tracks(detections, frame=frame)这条指令的时候需要调用numpy库在处理数据,numpy会默认开启多线程,导致CPU占用率几乎达到100%
YOLO和DeepSort虽然主要依靠GPU计算推理,但是GPU的工作也需要依赖CPU进行指令调度、数据准备、数据拷贝等,但是CPU这时完全被numpy的数据处理占用,没有多余的线程来调度GPU,GPU等不到数据或命令(数据饿死),这就导致了GPU占用率反而降低。
旱的旱死,涝的涝死,整体运行速度反而降低。
接下来取消注释,限制tracks = yolov5_param.tracker.update_tracks(detections, frame=frame)指令单核运行,再此运行代码,并查看GPU和CPU的占用率
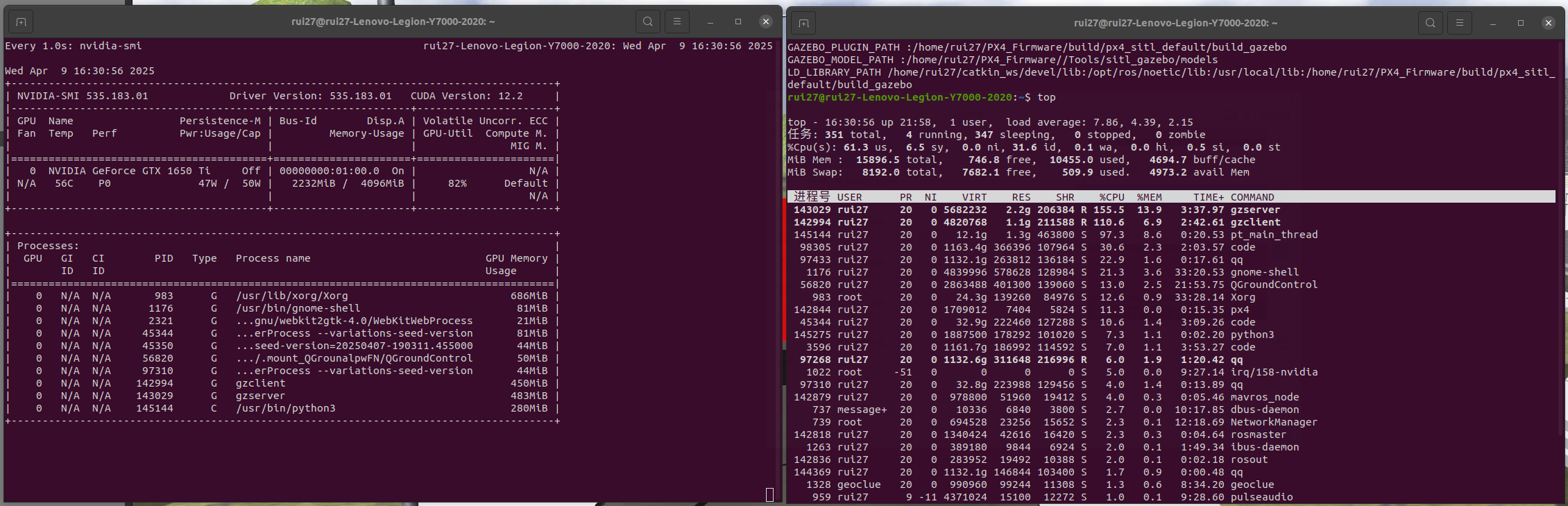
这时CPU占用率下降,GPU占用率提高
观察rivz中显示的识别图像,对目标的跟踪也更加及时流畅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号