
从阻塞IO到多路复用IO
第一次将总结的东西以博客的形式发出,如果有错误的地方请指出
IO
一、什么是IO
IO即是输入输出(input/ouput)
笔者的理解,IO可以分为两步:
-
等待IO事件就绪
-
数据就绪后,进行真正意义的数据迁移(读或写)
例:
-
在Linux系统中,咱们创建一个文件并写入或者读文件。
-
首先用户程序发起open系统调用,计算机运行模式由用户态转为内核态,内核在在磁盘中开辟一块空间,在文件创建成功后,可以获得一个唯一的文件描述符,该文件描述符可以由其他系统调用使用。两个程序打开文件,可以拿到不同的文件描述符,可以分别对文件描述符进行操作。
-
若我们要往文件中写入内容,咱们用户程序会发起write系统调用,把我们输入的内容复制到内核空间,内核再通过open系统调用所获得的文件描述符,将内容写入磁盘中。
-
若我们想读文件,用户进程会发起read系统调用,内核会通过open所获得的文件描述符找到文件所在的磁盘位置,将起复制进内核缓冲区,再由内核将缓冲区内容复制入用户进程空间。
-
在这个例子中,不管我们是读还是写,都是先发起open系统调用,直到文件打开或创建成功返回文件描述符,这段时间就是IO,然后我们调用read系统调用也好write系统调用也罢,也会经历一个IO。总的来说IO就是用户进程发起系统调用直到系统调用返回结果这段时间,这段时间内,用户进程会等待系统调用的结果,所以就会阻塞,这就是我们常说的进程遇到IO会阻塞会挂起的整个大概过程。
二、IO的类型
总体来说IO模型分为两个大类,同步IO和异步IO
同步IO:
-
BIO(Blocking IO)阻塞IO
-
NIO(NonBocking IO)非阻塞IO
-
多路复用型IO:select,poll,epoll
异步IO
本文主要就是讲几种同步IO模型
同步IO
一、BIO
首先我们用python写一段代码,创建一个服务端,使客户端能够通过socket与服务端相连。
#SocketServer.py
import socket
from threading import Thread
addr = ('127.0.0.1', 8090)
def task(cnn):
while True:
try:
res = cnn.recv(1024)
print(res)
except ConnectionResetError:
pass
if __name__ == '__main__':
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(addr)
server.listen(5)
while True:
cnn, addr = server.accept()
t = Thread(target=task, args=(cnn,))
t.start()
上面代码我们每新来一个连接都会创建一个线程。
strace -ff -o ~/test/pySocket python3 SocketServer.py
这条命令的作用就是跟踪python3 SocketServer.py整个运行过程中的系统调用,并且写入当前文件夹下以pySocket开头的文件中。通过这条命令有助于我们理解IO模型的整个一个过程

我们可以发现该目录下新增了一个(说明当前只有一个线程在执行)PySocket.9927文件,里面的内容就是python3 SocketServer.py执行到现在的所有系统调用。


可以看到我们所注册的端口8090处于LISTEN状态,也就是等待连接状态,就是正在等待TCP三次握手的第一次握手的状态。由上面两张图可知,文件描述符3就是处于LISTEN状态的这条流。
接下来我们执行nc localhost 8090这条命令,nc可以和任何端口建立TCP连接并发送和接收数据,这个时候我们分别看一下fd目录下和test目录下的文件以及通过netstat查看一下端口状态。



从以上三张图我们可以得知,nc已经通过三次握手与服务端建立起了连接,此时这条流中服务端正处于ESTABLISH状态,与客户端交互数据,且还打开了一个文件描述符,当客户端发来数据时,服务端就可以通过4这个文件描述符读取数据,还有就是python进程也为这个连接单独开辟了一个线程,我们的代码也是这样写的。
接下来我们尝试继续通过nc去与服务端建立新连接时,以上三个地方都会增加相应的文件或者记录。
最后我们来看看服务端的主线程和子线程发生了哪些系统调用
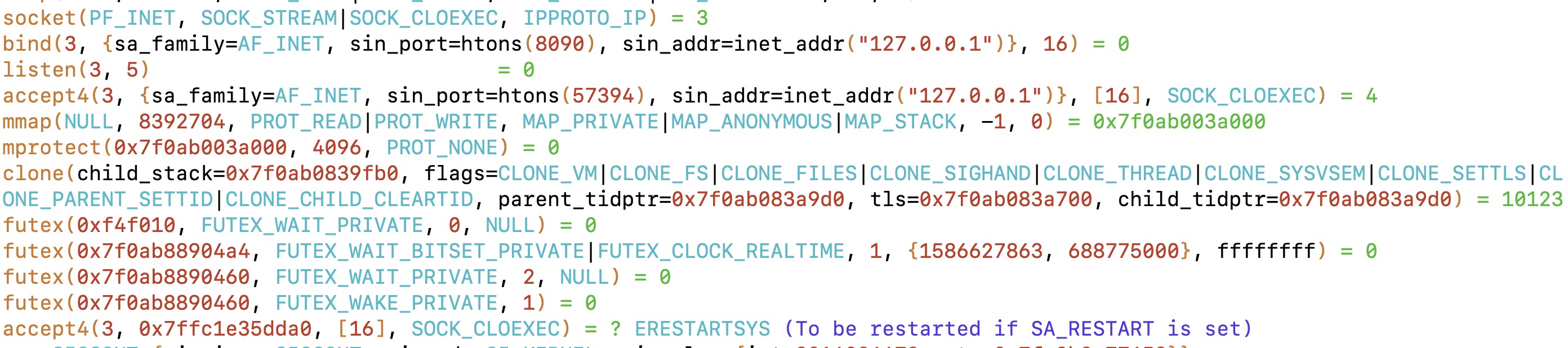

上面是子线程的系统调用,可以看到子线程调用recvfrom()去文件描述符4读取数据,然后将读取到的数据通过标准输出文件描述符1打印到了屏幕上(我们在代码中使用了Print)。
上面的从创建子线程开始就是一个典型的BIO模型,也就是说BIO就是每一个连接我们都会分配一个线程去管理,从建立连接到收到客户端所发来的消息这期间对应的线程都会阻塞,直到收到消息。显而易见的BIO的缺点就是阻塞,客户端一直不发消息服务端的子线程就会一直阻塞。所以在BIO的基础上NIO又做了一些改进
二、NIO
NIO(NonBlocking IO)顾名思义就是非阻塞IO
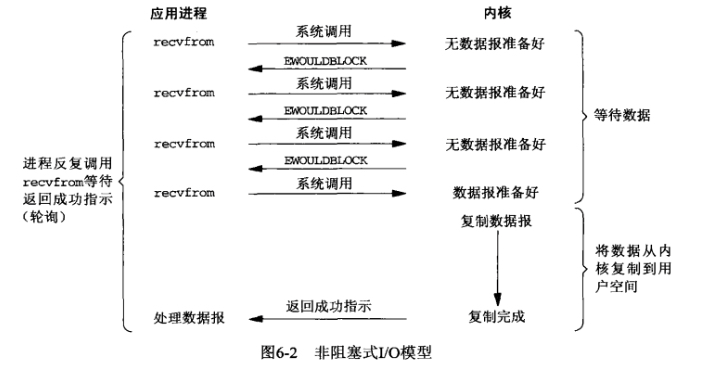
NIO的工作模式就是多个连接由一个线程去管理,具体就是多个连接到来由这个线程轮着去recevfrom()这些连接所对应的fd,如果这些文件描述符中数据未准备好,就去revcfrom()下一个,如果数据准备好了,内核就会将数据拷贝进用户进程,长此以往的这样执行下去。
NIO虽然改善了BIO阻塞的缺点,但是如果连接的客户端过多,假设有一万个客户端来连接,也就意味着我们每循环一次最起码就会调用一万次recvfrom()这个系统调用,如果客户端更多,效率也就会更低。
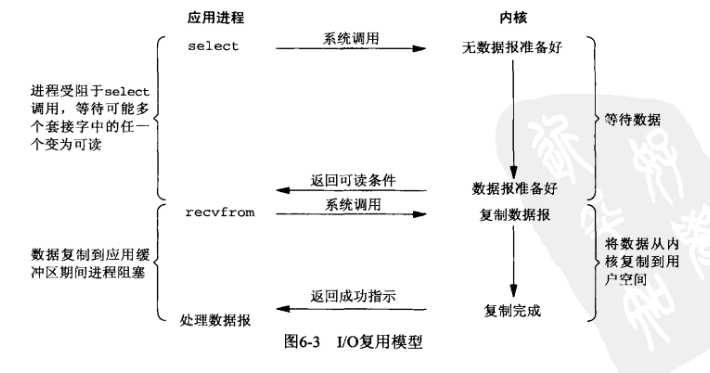
从图中我们可以看到用户进程发出select()系统调用之后,就等待内核的返回,直到内核告诉用户进程哪个文件描述符的可读可写,用户进程就会调用recvfrom()去读取对于的数据。
其实select原理上与NIO类似,但是其减少了系统调用的次数。用户进程在调用select时,会将所有已建立连接的文件描述符作为参数传入内核,内核也是轮询这些文件描述符,并且返回处于可读可写状态的文件描述符,最后用户进程就去recvfrom读取。所以select与NIO相比就是将内核外的轮询,放到内核内,以此减少系统调用的次数。
四、poll
poll与select无本质区别,只是变成了基于链表来存储文件描述符,没有最大连接数限制,其余与select大致一样
五、epoll
epoll这个模型大概的流程就是:
-
首先内核开辟一块空间新建一个红黑树用于存储需要监控的文件描述符
-
然后每新建一个连接,就会被注册进红黑树中
-
当红黑树中的文件描述符状态改变为可读写时,会被添加进一个链表中,这个链表保存的都是处于可读写状态的文件描述符
-
用户进程就会根据链表中的文件描述符调用recvfrom读取数据
具体来说,epoll有三个系统调用:
-
epoll_create:新建一个epoll实例并返回实例文件描述符
-
epoll_ctl:向epoll实例中添加删除或修改需要监听文件描述符
-
epoll_wait:直接向用户进程返回就绪文件描述符
上面有一个问题没解释清楚,就是被监听的文件描述符怎样不通过遍历,在其就绪时被添加进就绪链表中的呢?
就是每次客户端发来数据都是先到达网卡,网卡收到数据后,会将数据放入内存专门的区域中,然后会发起一个硬中断,中断cpu,让cpu去处理接收到的数据。cpu根据中断号和驱动开始回调,将网卡发来的数据写入相关文件描述符中,这时就会将该文件描述符添加进链表中。epoll的全名就是event poll,事件驱动型IO。
epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:
LT模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。
附:
文件描述符
由于Linux一切皆文件,所以每条流的IO都被抽象成文件,文件描述符就是对进程已打开的文件的索引,也就是对每条流的引用。
任何一个程序都有最基本的三个IO,标准输入、标准输出和错误输出。分别对应该进程下的三个文件描述符0,1,2。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号