

向量数据库Milvus
Milvus是一个分布式向量数据库,它将计算与存储相分离,在这个系统中,数据节点负责数据的持久性,并最终将数据存储在 MinIO/S3 等分布式对象存储中。查询节点负责处理搜索等计算任务,这些任务涉及批量数据和流数据的处理。
一、Milvus Docker安装
1. Windows安装Milvus Standalone
注意:windows上无法使用milvus_lite;
A. 以管理员身份运行Windows PowerShell;
B. 可以新建一个目录存储Milvus;
C. 切换到对应目录,下载安装脚本(2.6.0版本):Invoke-WebRequest https://raw.githubusercontent.com/milvus-io/milvus/refs/heads/master/scripts/standalone_embed.bat -OutFile standalone.bat
D. 运行脚本:standalone.bat start

E. 访问url:http://127.0.0.1:19530
2. Linux安装Milvus Standalone
A. 下载Milvus docker-compose文件(2.6.2版本):https://github.com/milvus-io/milvus/releases/download/v2.6.2/milvus-standalone-docker-compose.yml;
B. 启动脚本docker compose up -d,注意若镜像无法下载就更改镜像源;
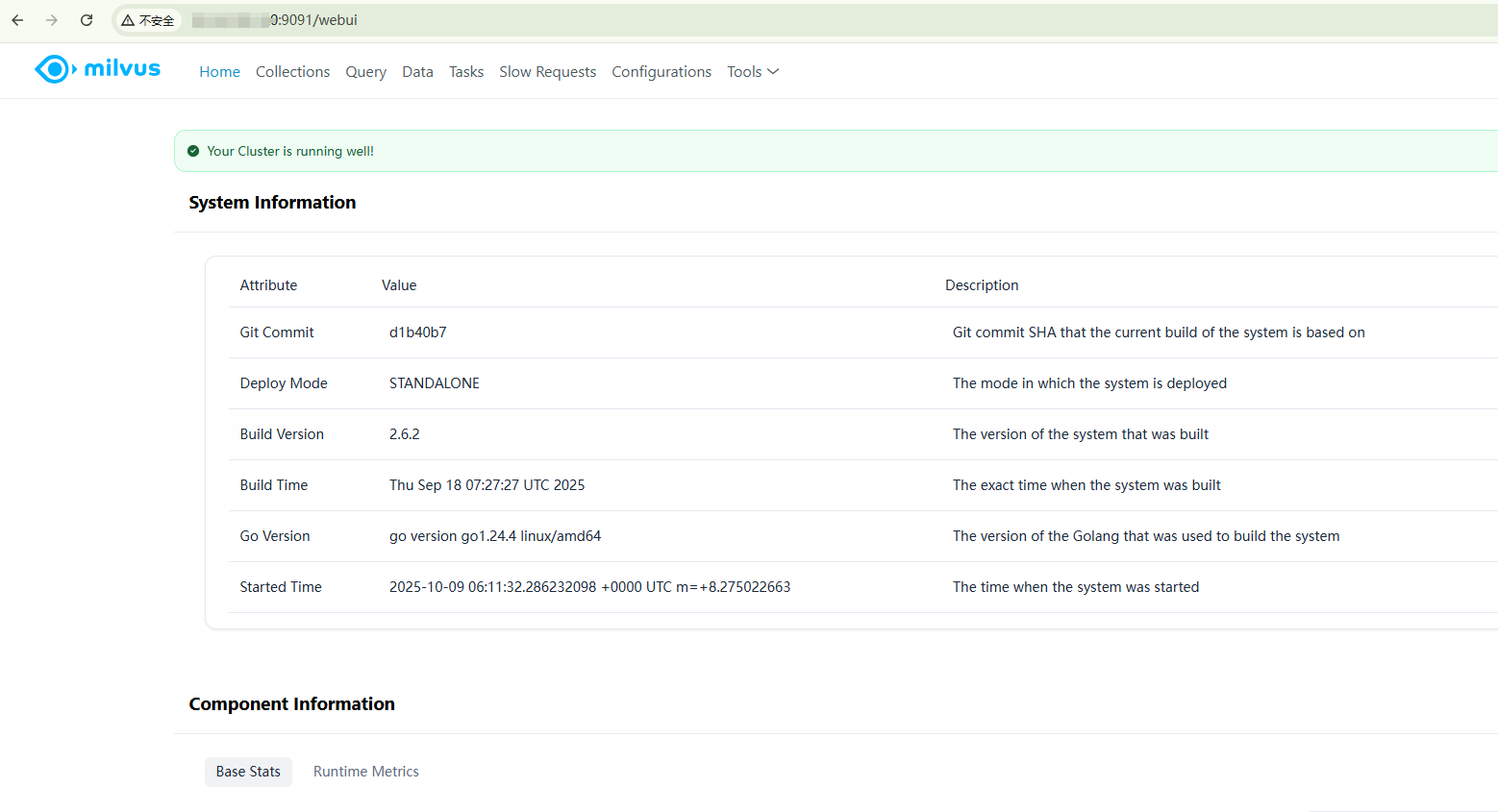
C. Milvus WebUI地址为:http://127.0.0.1:9091/webui/。
二、Attu的界面化工具
1. 下载地址:https://github.com/zilliztech/attu/releases,windows环境下载.exe文件安装;
2. 开启认证并修改密码
A. 进入容器:docker exec -it `docker ps | grep milvus-standalone | awk '{ print $1 }'` bash;
B. 进入目录并启用认证:cd configs && sed -i 's/authorizationEnabled: false/authorizationEnabled: true/' milvus.yaml;
C. 重启服务:docker restart `docker ps | grep milvus-standalone | awk '{ print $1 }'`;
D. 登录使用默认token认证:新版是TOKEN写法:root:Milvus这样才能登录成功;
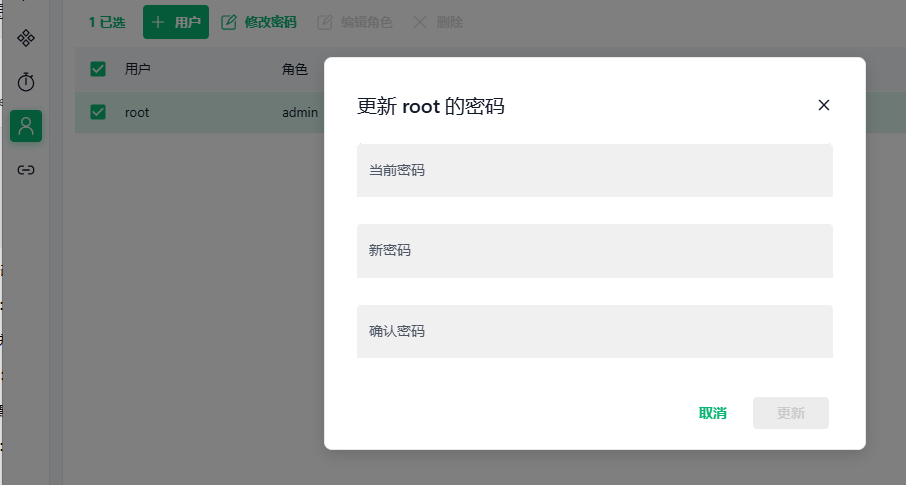
E. 修改密码:在Attu中修改root的密码,当前密码为Milvus。
三、使用
1. 数据库(DB)
A. 概念:数据库是组织和管理数据的逻辑单元,为了提高数据安全性并实现多租户,就可以创建多个数据库,为不同的应用程序或租户从逻辑上隔离数据,默认数据库是default且不可删除;
2. Schema字段
A. 主字段:Collections必须有一个主字段,以唯一标识每个实体,设置is_primary=True,数据类型只能时INT64和VARCHAR,可以自动创建ID(auto_id=True)或手动创建;
B. 字符串字段:用于存储字符串数据类型,max_length用于指定最大字节数;
C. 数字字段:用于存储数值的标量字段;
D. JSON字段:
E. 动态字段:$meta字段实现的
F. 数组字段:
G. 稠密向量:数据类型必须vector类型,必须用dim指定向量的维数;
H. mmap_enabled:内存映射(Mmap)可实现对磁盘上大型文件的直接内存访问,使 Milvus 可以在内存和硬盘中同时存储索引和数据;
3. 集合(Collections)
A. 加载与释放(load&release)
加载:是在集合中进行相似性搜索和查询的前提,它会将索引文件和所有字段的原始数据加载到内存中,以便快速响应搜索和查询,当然也可以只加载集合中某个分区,甚至是某个字段;
释放:搜索和查询是内存密集型操作,为节约成本,建议释放当前不使用的 Collection;
B. 一致性级别(consistency_level)
强一致性(Strong Consistency):保证读取操作总是返回最新写入的数据,在写入操作完成后,后续的读取请求立即能看到该写入的结果;
最终一致性(Eventually Consistency):系统不保证读取操作能立即返回最新的数据,但保证在没有新的写入操作的情况下,经过一段时间后,所有副本的数据会最终达到一致状态;
有界一致性 (Bounded Consistency):这是默认值,介于强一致性和最终一致性之间,系统保证读取操作返回的数据不会比最新数据“旧”超过一个可接受的时间或版本范围;
会话一致性 (Session Consistency):保证在一个特定的客户端会话(session)内,读取操作能看到该会话内之前写入的数据,但可能看不到其他会话的写入;
C. 分区(partition)
定义:分区是一个 Collection 的子集,每个分区与其父集合共享相同的数据结构,但只包含集合中的一个数据子集,默认分区名为default;
创建分区:动态分区需要通过代码定时实现创建,以月份为例,下一个月份来临时还需要自己创建分区;
D. 别名(alias)
属性:一个别名一次只能指向一个 Collections;
作用:为集合(Collection)或分区(Partition)提供一个人性化、不依赖内部ID的固定访问入口,这在数据管理和应用开发中非常实用;
流程:在处理请求时,会首先检查是否存在提供名称的 Collection,如果不存在,它就会检查该名称是否是某个 Collection 的别名;
4. 索引(Index)
4.1 稠密向量索引:
4.2 稀疏向量索引:
5. 搜索(Search)
5.1. 搜索算法
A. ANN(近似近邻)搜索:以记录向量嵌入排序顺序的索引文件为基础,根据接收到的搜索请求中携带的查询向量查找向量嵌入子集,将查询向量与子群中的向量进行比较,并返回最相似的结果;
B. 过滤搜索:ANN 搜索能找到与指定向量嵌入最相似的向量嵌入,但是搜索结果不一定总是正确的。您可以在搜索请求中包含过滤条件,这样 Milvus 就会在进行 ANN 搜索前进行元数据过滤,将搜索范围从整个 Collections 缩小到只搜索符合指定过滤条件的实体;
5.2. 查询:除 ANN 搜索外,Milvus 还支持通过查询过滤元数据
5.3. 度量类型
A. COSING(默认值):COSING距离越大,表示相似度越高;
B. IP:IP距离越大,表示相似度越高;
C. L2:L2距离越小,表示相似度越高;
可参考:Milvus官方文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号