练习2-房价预测
几个比较重要的点:
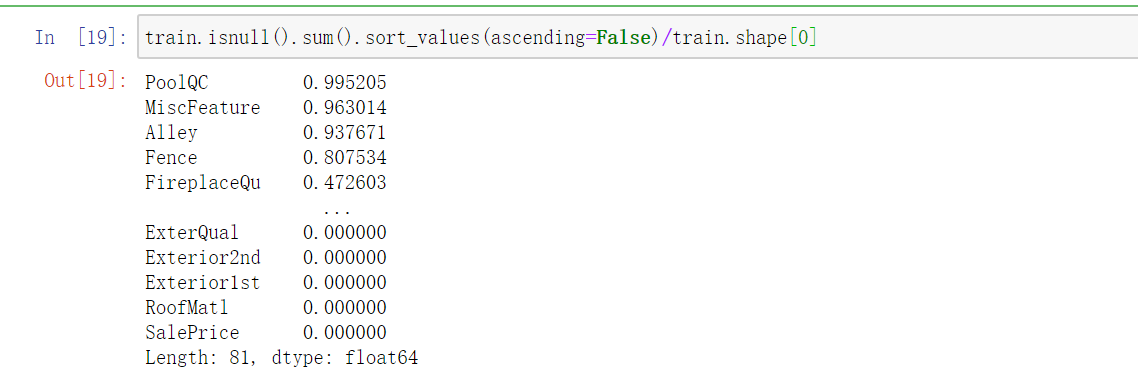
1、统计null值占比:
train.isnull().sum().sort_values(ascending=False)/train.shape[0]
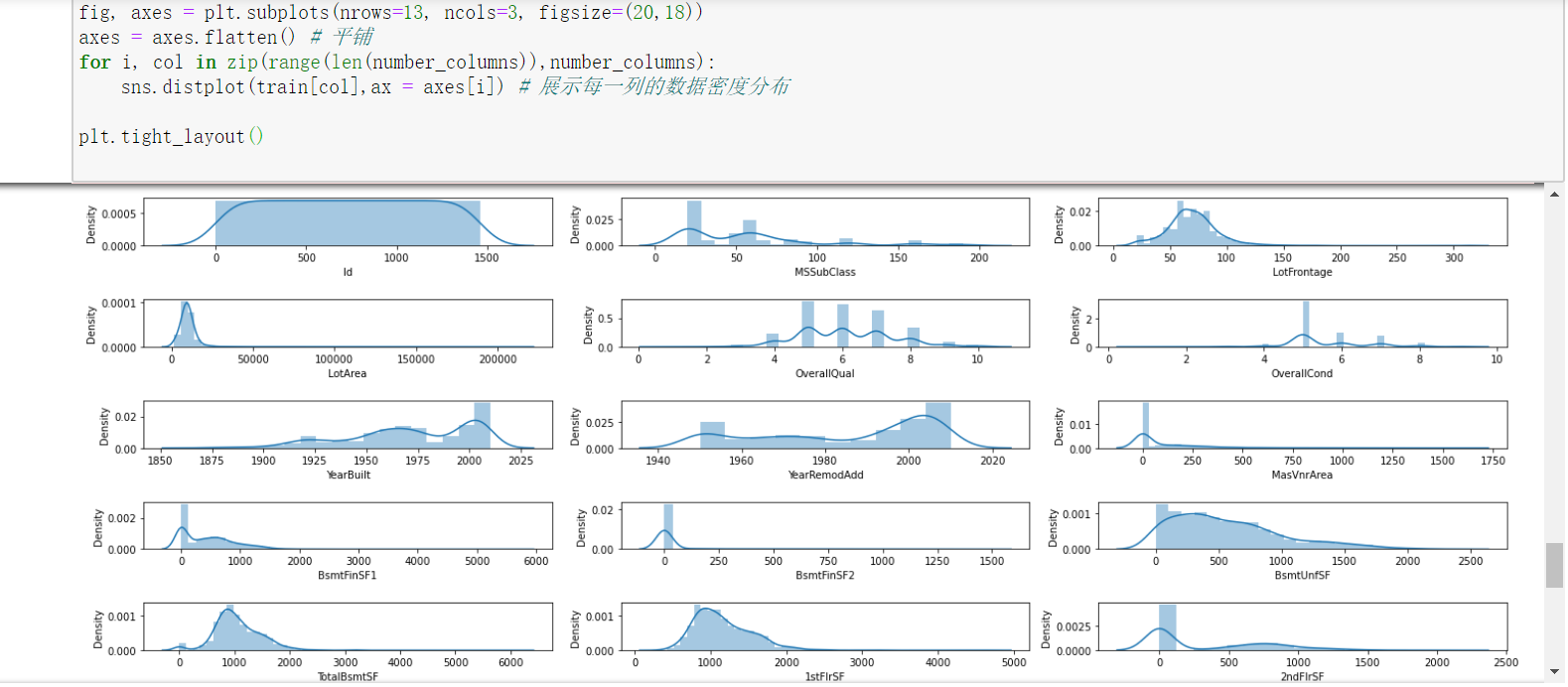
2、绘制密度分布
# 分出数据类型的列和分类类型的列
number_columns = [ col for col in train.columns if train[col].dtype != 'object']
category_columns = [ col for col in train.columns if train[col].dtype == 'object']
fig, axes = plt.subplots(nrows=13, ncols=3, figsize=(20,18))
axes = axes.flatten() # 平铺
for i, col in zip(range(len(number_columns)),number_columns):
sns.distplot(train[col],ax = axes[i]) # 展示每一列的数据密度分布
plt.tight_layout()
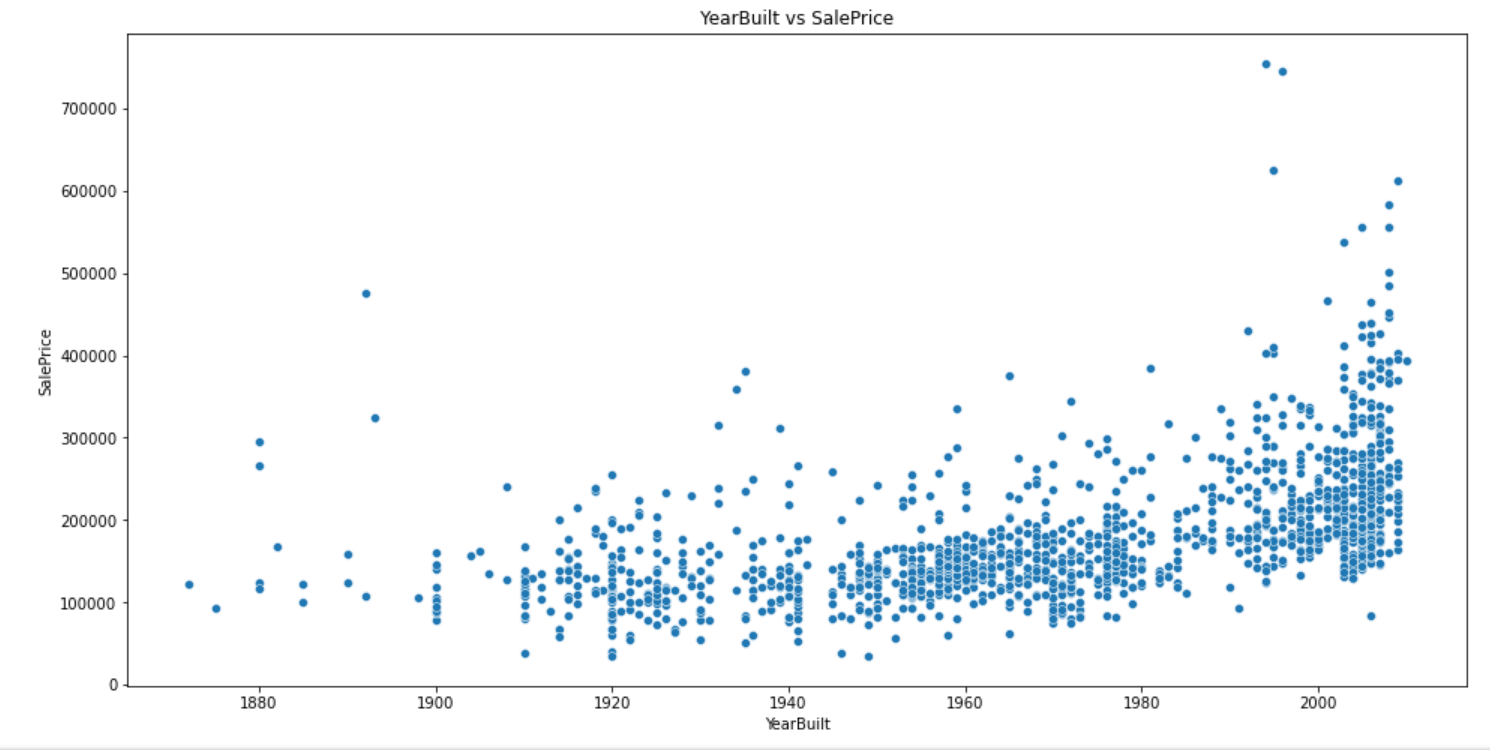
3、建造年份YearBuilt 与 售价SalePrice 的关系
plt.figure(figsize=(16,8))
plt.title("YearBuilt vs SalePrice")
sns.scatterplot(train.YearBuilt, train.SalePrice) # 散点图(横轴吗,纵轴)
plt.show()
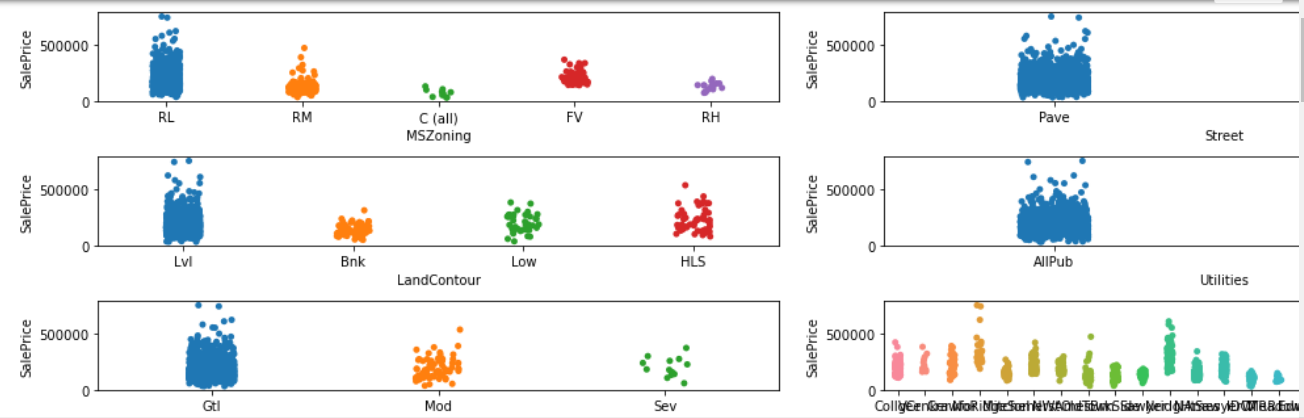
4、每个分类类型的每个值对应纵轴房价的关系
fig, axes = plt.subplots(13,3,figsize=(25,20))
axes = axes.flatten()
for i, col in enumerate(category_columns):
sns.stripplot(x=col,y='SalePrice',data=train, ax=axes[i])
plt.tight_layout()
plt.show()
5、空缺值处理
# 拆中法:对于数值类型取中位数,分类类型取None
for col in train_nan_num:
train[col].fillna(train[col].median(),inplace=True)
for col in train_nan_cat:
train[col].fillna('None',inplace=True)
for col in test_nan_num:
test[col].fillna(test[col].median(),inplace=True)
for col in test_nan_cat:
test[col].fillna('None',inplace=True)
6、先用基模型(默认参数)测试误差
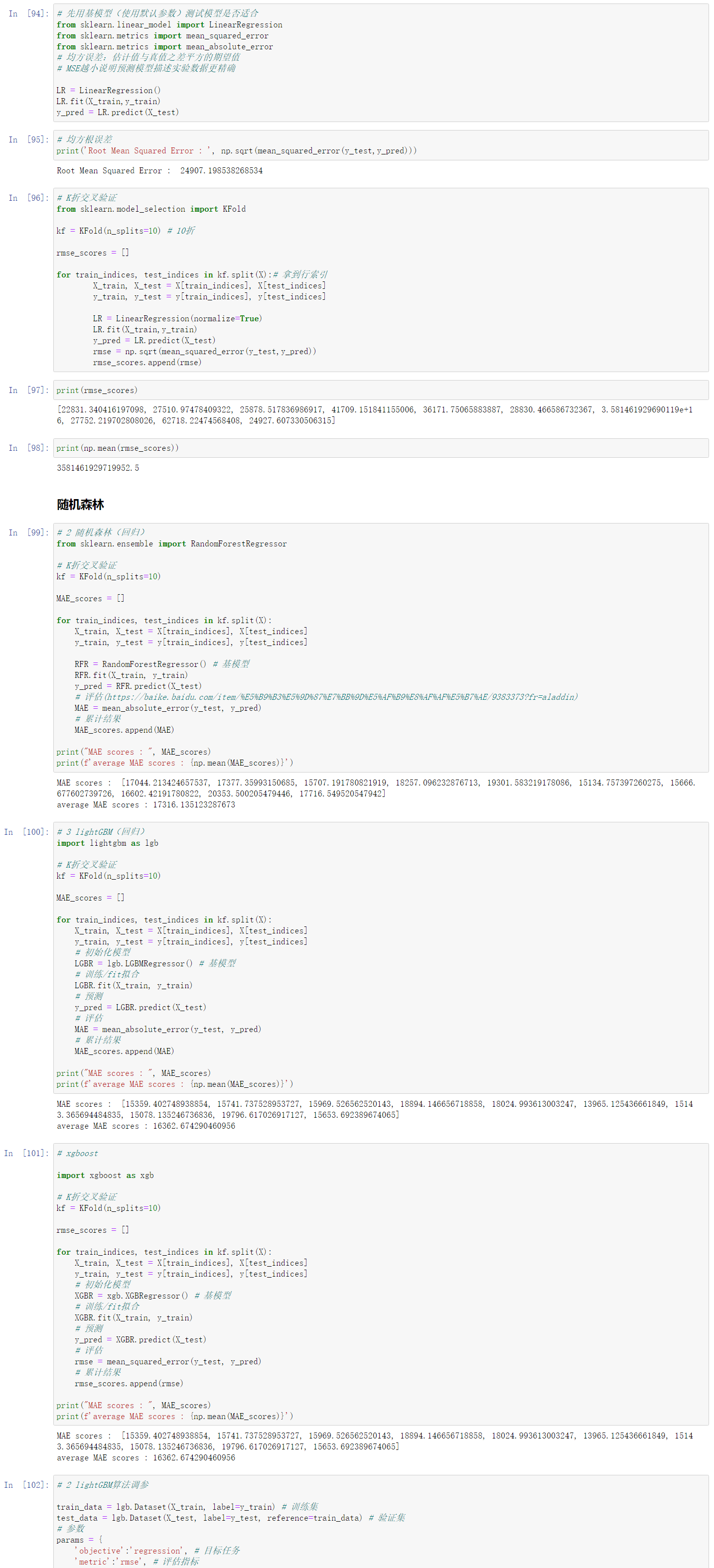
7、lightGBM调参
# 2 lightGBM算法调参
train_data = lgb.Dataset(X_train, label=y_train) # 训练集
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data) # 验证集
# 参数
params = {
'objective':'regression', # 目标任务
'metric':'rmse', # 评估指标
'learning_rate':0.1, # 学习率
'max_depth':15, # 树的深度
'num_leaves':20, # 叶子数
}
# 创建模型对象
model = lgb.train(params=params,
train_set=train_data,
num_boost_round=300,
early_stopping_rounds=30,
valid_names=['test'],
valid_sets=[test_data])
score = model.best_score['test']['rmse']

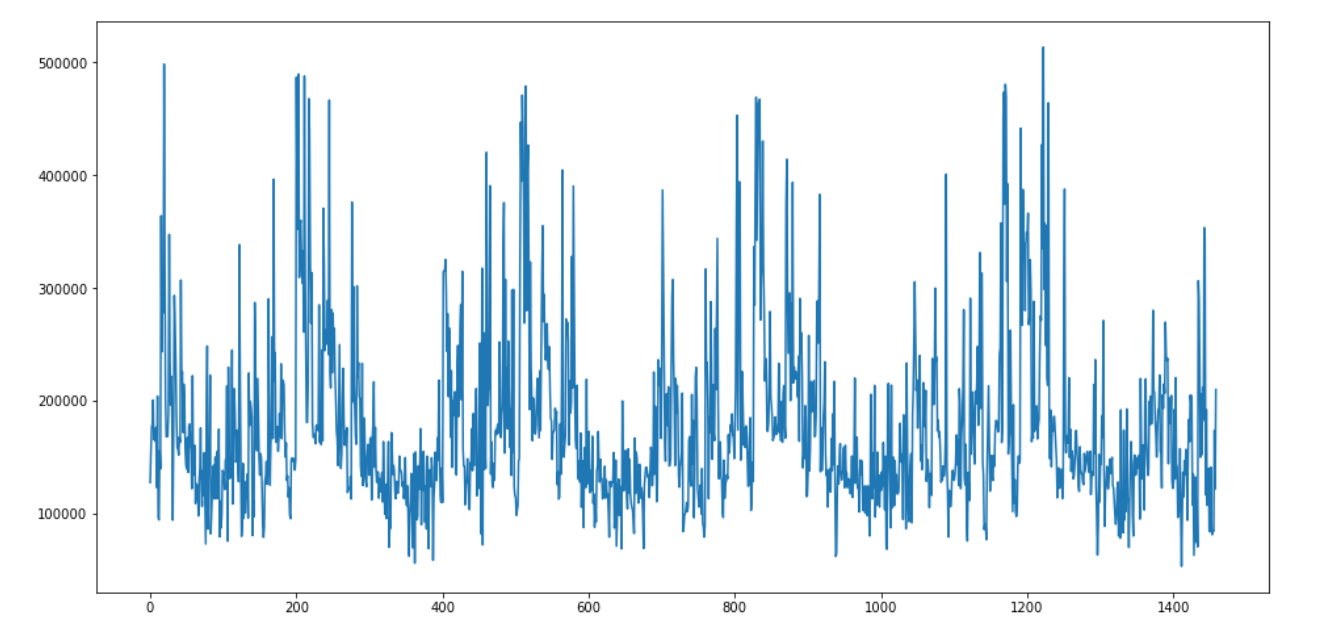
8、预测与保存
test_pred = model.predict(test.drop('Id',axis=1).values)
result_df2 = pd.DataFrame(columns=['SalePrice'])
result_df2['SalePrice'] = test_pred
result_df2['SalePrice'].plot(figsize=(16,8))
result_df2.to_csv('LGBR_model2.csv', index=None, header=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号