(笔记sklearn入门 3.3 逻辑回归、聚类
逻辑回归是解决二分类问题的利器:
广告点击率
判断用户的性别
预测用户是否会购买给定的商品类
判断一条评论是正面的还是负面的
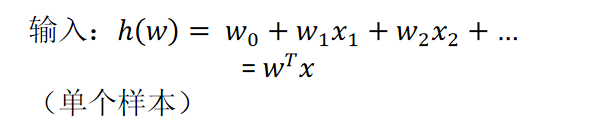
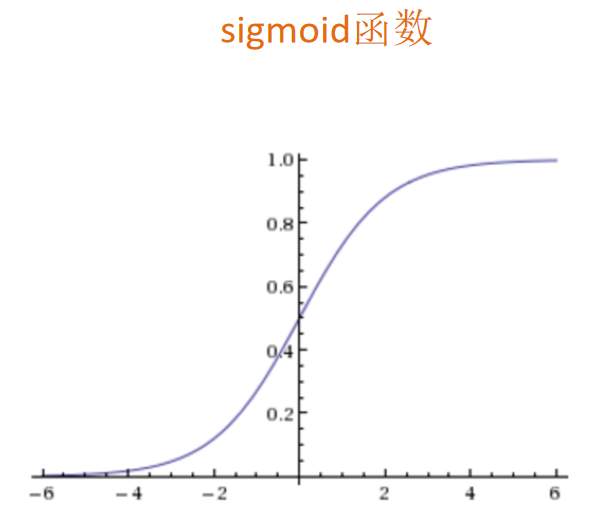
逻辑回归公式:


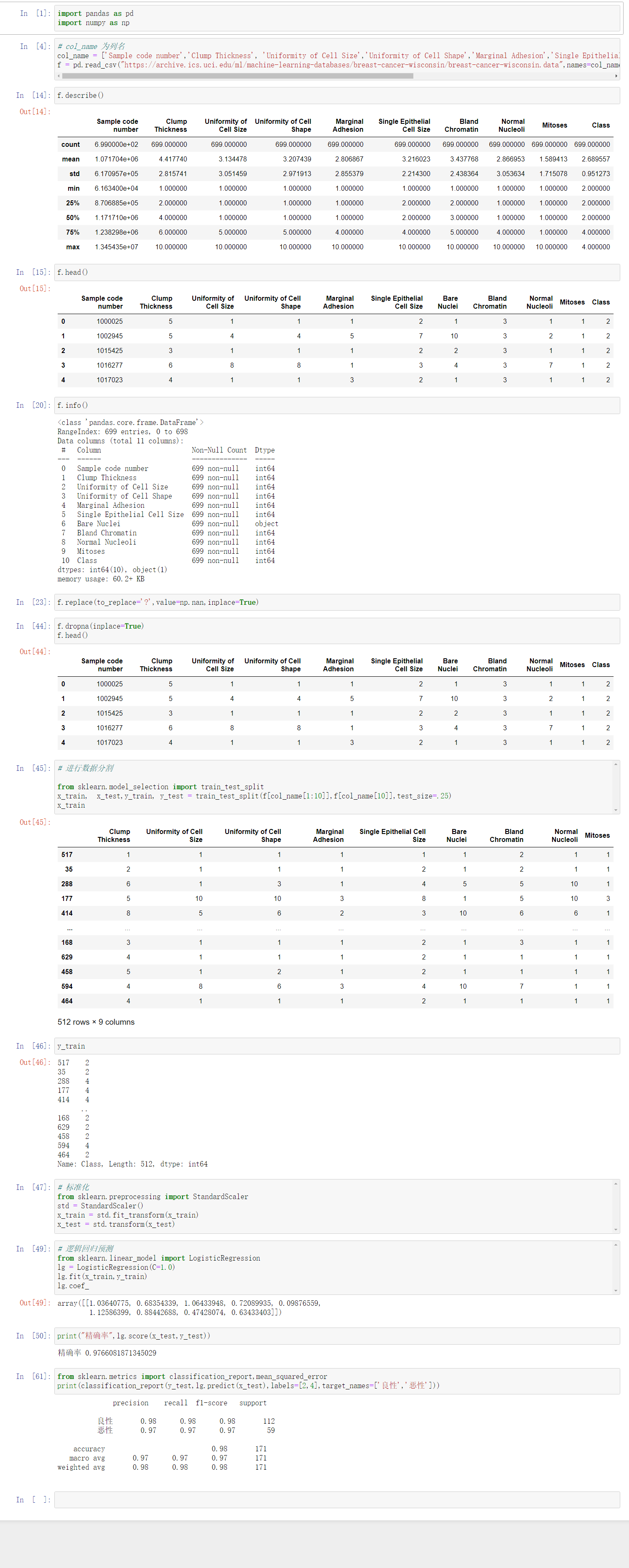
良/恶性乳腺癌肿瘤预测
API:sklearn.linear_model.LogisticRegression

import pandas as pd
import numpy as np
# col_name 为列名
col_name = ['Sample code number','Clump Thickness', 'Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class']
f = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",names=col_name)
f.replace(to_replace='?',value=np.nan,inplace=True)
f.dropna(inplace=True)
# 进行数据分割
from sklearn.model_selection import train_test_split
x_train, x_test,y_train, y_test = train_test_split(f[col_name[1:10]],f[col_name[10]],test_size=.25)
# 标准化
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 逻辑回归预测
from sklearn.linear_model import LogisticRegression
lg = LogisticRegression(C=1.0)
lg.fit(x_train,y_train)
lg.coef_
print("精确率",lg.score(x_test,y_test))
from sklearn.metrics import classification_report,mean_squared_error
print(classification_report(y_test,lg.predict(x_test),labels=[2,4],target_names=['良性','恶性']))
聚类
非监督学习(unsupervised learning)主要方法:k-means
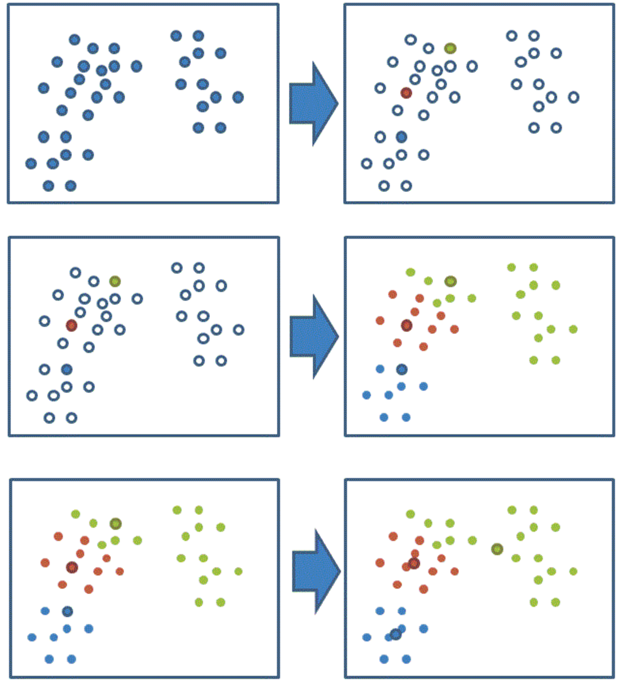
步骤:
1、随机设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类
中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平
均值)
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行
第二步过程
from sklearn.decomposition import PCA
import numpy as np
import pandas as pd
'''
prior = pd.read_csv(r"D:\Python\机器学习代码和资料\instacart-market-basket-analysis\order_products__prior.csv")
products = pd.read_csv(r"D:\Python\机器学习代码和资料\instacart-market-basket-analysis\products.csv")
orders = pd.read_csv(r"D:\Python\机器学习代码和资料\instacart-market-basket-analysis\orders.csv")
aisles = pd.read_csv(r"D:\Python\机器学习代码和资料\instacart-market-basket-analysis\aisles.csv")
# 合并四张表到一张表
_mg = pd.merge(pd.merge(prior,products,on=['product_id', 'product_id']),orders,on=['order_id','order_id'])
mt = pd.merge(_mg,aisles,on=['aisle_id','aisle_id'])
# mt.to_csv(r"D:\Python\机器学习代码和资料\instacart-market-basket-analysis\mt.csv")
'''
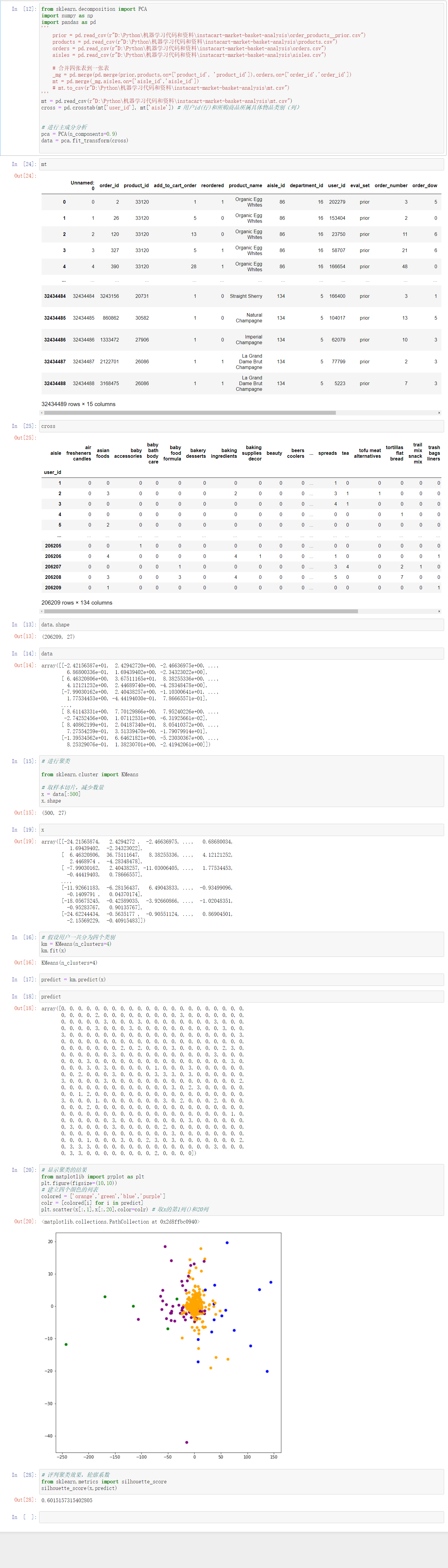
mt = pd.read_csv(r"D:\Python\机器学习代码和资料\instacart-market-basket-analysis\mt.csv")
cross = pd.crosstab(mt['user_id'], mt['aisle']) # 用户id(行)和所购商品所属具体物品类别(列)
# 进行主成分分析
pca = PCA(n_components=0.9)
data = pca.fit_transform(cross)
# 进行聚类
from sklearn.cluster import KMeans
# 取样本切片,减少数量
x = data[:500]
# 假设用户一共分为四个类别
km = KMeans(n_clusters=4)
km.fit(x)
predict = km.predict(x)
# 显示聚类的结果
from matplotlib import pyplot as plt
plt.figure(figsize=(10,10))
# 建立四个颜色的列表
colored = ['orange','green','blue','purple']
colr = [colored[i] for i in predict]
plt.scatter(x[:,1],x[:,20],color=colr) # 取x的第1列()和20列
# 评判聚类效果,轮廓系数
from sklearn.metrics import silhouette_score
silhouette_score(x,predict)

如果sc_i 小于0,说明a_i 的平均距离大于最近的其他簇。
聚类效果不好
如果sc_i 越大,说明a_i 的平均距离小于最近的其他簇。
聚类效果好
轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优


 浙公网安备 33010602011771号
浙公网安备 33010602011771号