(笔记)sklearn入门 3.2 过拟合与欠拟合、岭回归、模型的保存与加载
过拟合与欠拟合
欠拟合(欠配):训练样本的一般特性尚未学好,通常是由于学习能力低下而造成的。
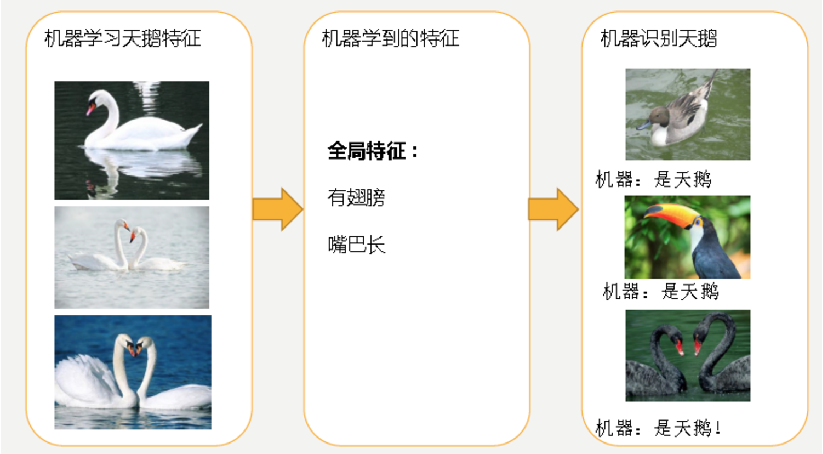
过拟合(过配):最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学习到了。
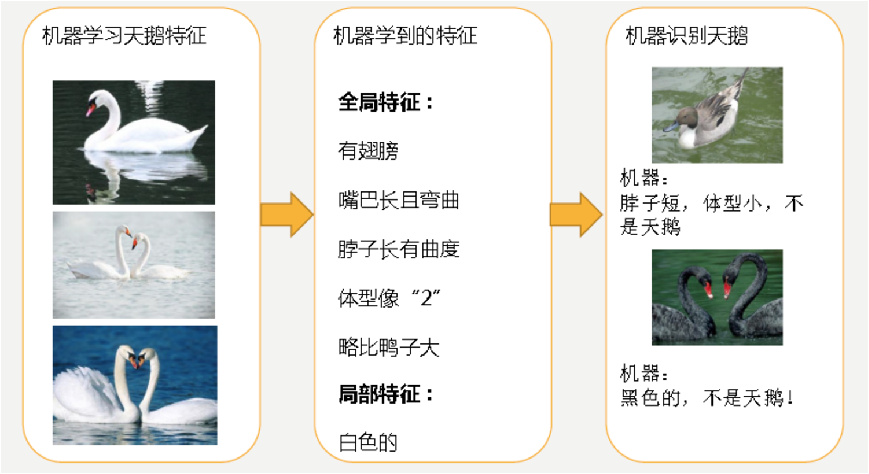
一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
一个假设在训练数据上不能获得更好的拟合, 但是在训练数据外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
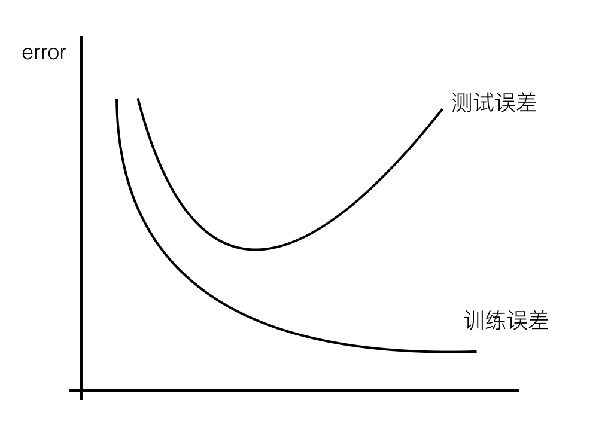
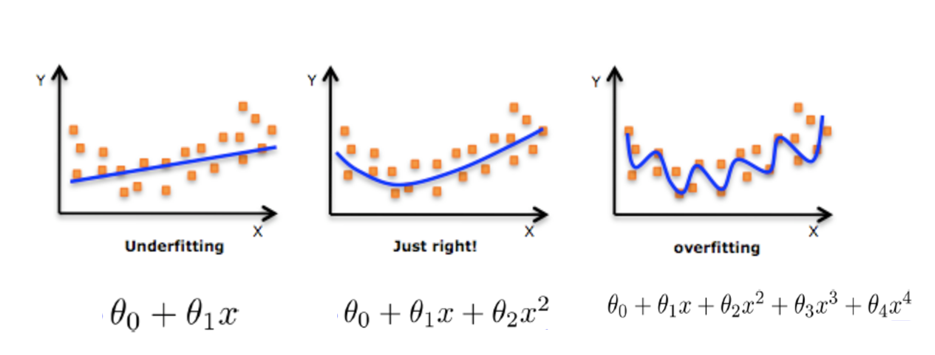
欠拟合原因以及解决办法:
原因:学习到数据的特征过少
解决办法:增加数据的特征数量
过拟合原因以及解决办法:
原因:
原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点
解决办法:
进行特征选择,消除关联性大的特征(很难做)
交叉验证(让所有数据都有过训练)
正则化(了解)
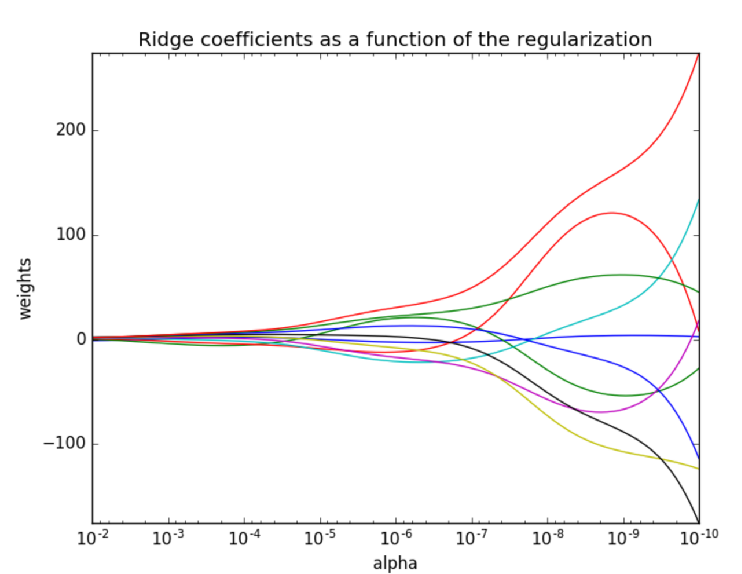
L2正则化:
L2正则化的作用:可以使得W的每个元素都很小,都接近于0
优点:越小的参数说明模型越简单,越简单的模型则越不
容易产生过拟合现象

带有正则化的线性回归-Ridge 岭回归
岭回归:回归得到的回归系数更符合实际,更可靠。另外,能让估计参数的波动范围变小,变的更稳定。在存在病态数据偏多的研究中有较大的实用价值。
API : sklearn.linear_model.Ridge

代码和线性回归最后预测的流程完全一致,就不写了
保存与读取模型
...
...
...
sgd = SGDRegressor()
sgd.fit(x_train,y_train)
import joblib # 现在不需要从sklearn导入了
# 保存模型
joblib.dump(sgd,"./test.pkl") # 传入fit好的模型,以及保存路径
# 读取模型
sgd = joblib.load("./test.pkl") # 返回estimator

 浙公网安备 33010602011771号
浙公网安备 33010602011771号