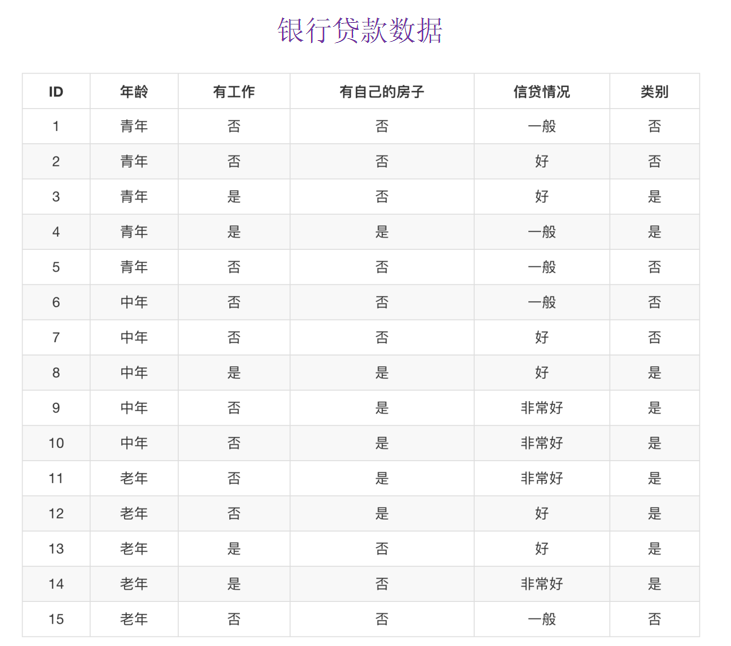
(笔记)sklearn入门 2.3 决策树
决策树零基础入门,关于基尼系数的决策树,上课无聊刷手机刷到的(
熵、信息增益、基尼系数 知乎上看到的,比较好看懂
下面都是看视频的截图和代码(
信息熵



例子:


决策树
常见决策树使用的算法
ID3
信息增益 最大的准则
C4.5
信息增益比 最大的准则
CART
回归树: 平方误差 最小
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则
sklearn决策树API

from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
# 获取数据
titan = pd.read_csv("./titanic.csv")
# 处理数据,找出特征值和目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
print(x)
# 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 分割数据集到训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行处理(特征工程)特征-》类别-》one_hot编码
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient="records"))
print(x_train)
# 用决策树进行预测
dec = DecisionTreeClassifier()
dec.fit(x_train, y_train)
# 预测准确率
print("预测的准确率:", dec.score(x_test, y_test))
# 导出决策树的结构
export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
# 随机森林进行预测 (超参数调优)
# rf = RandomForestClassifier()
# param = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
# # 网格搜索与交叉验证
# gc = GridSearchCV(rf, param_grid=param, cv=2)
# gc.fit(x_train, y_train)
# print("准确率:", gc.score(x_test, y_test))
# print("查看选择的参数模型:", gc.best_params_)
保存决策树.dot
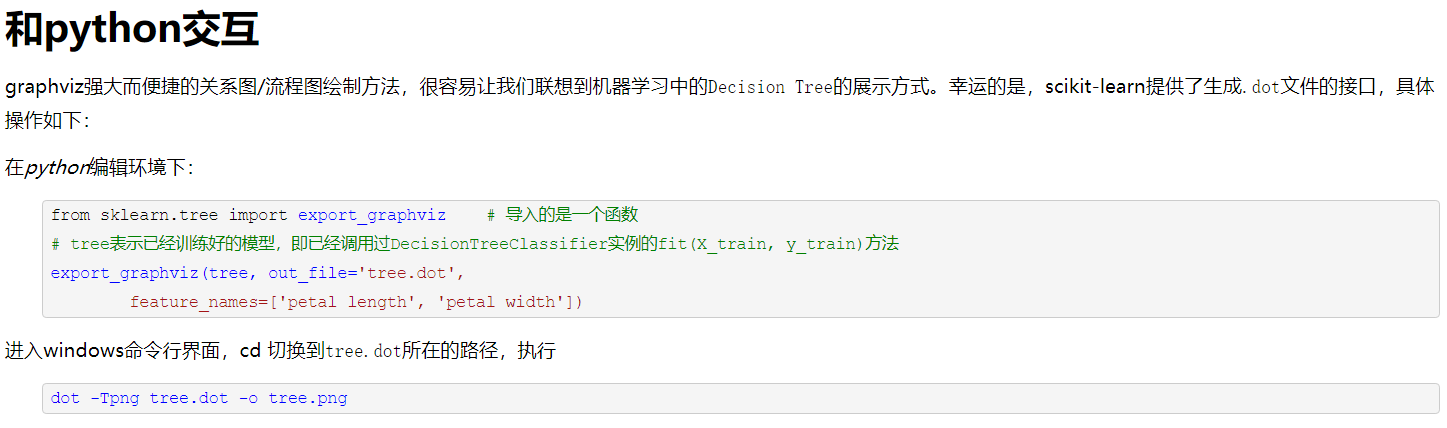 (source)
(source)
很大一张图(又是显示不了中文的一天)
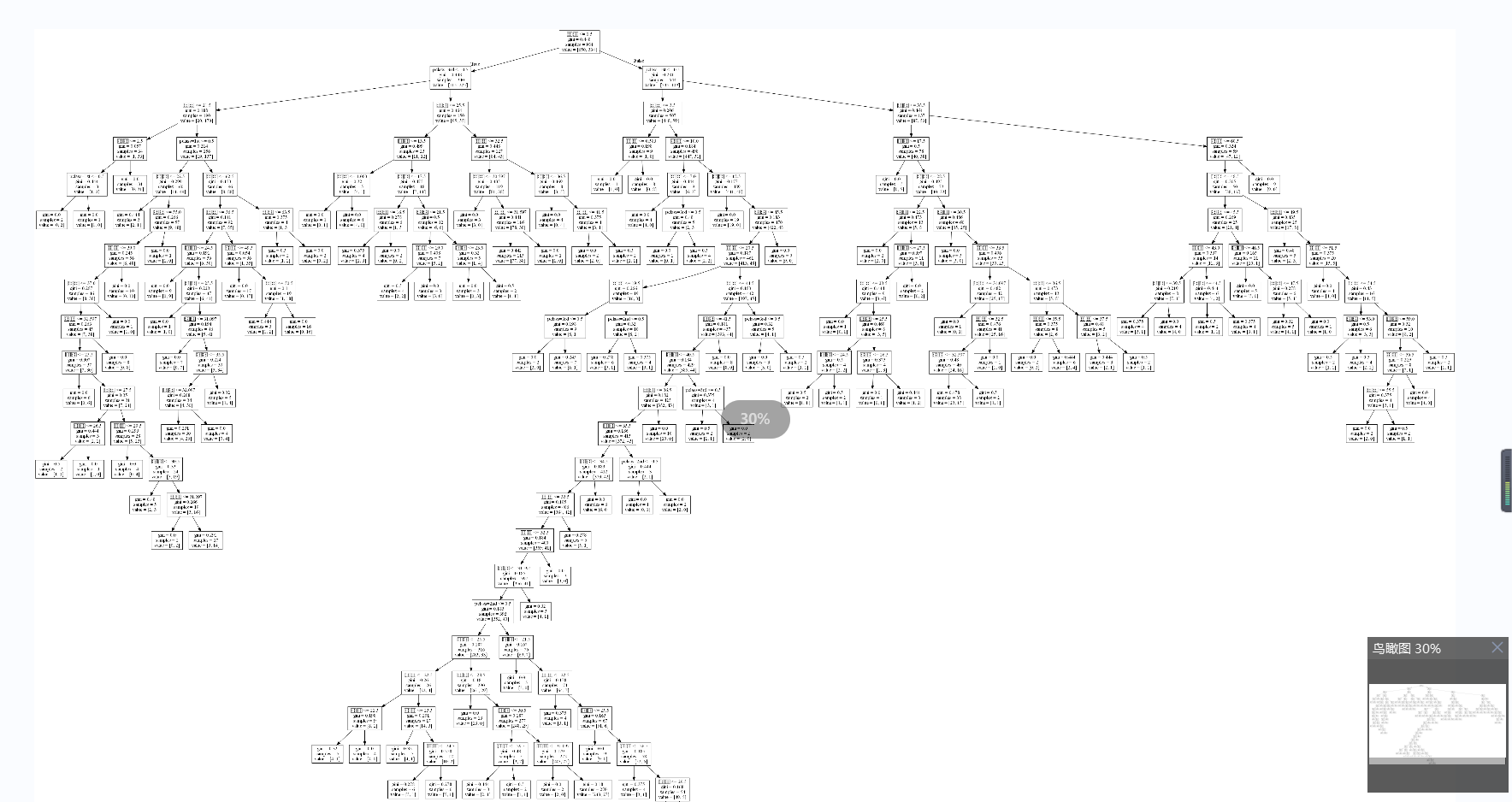
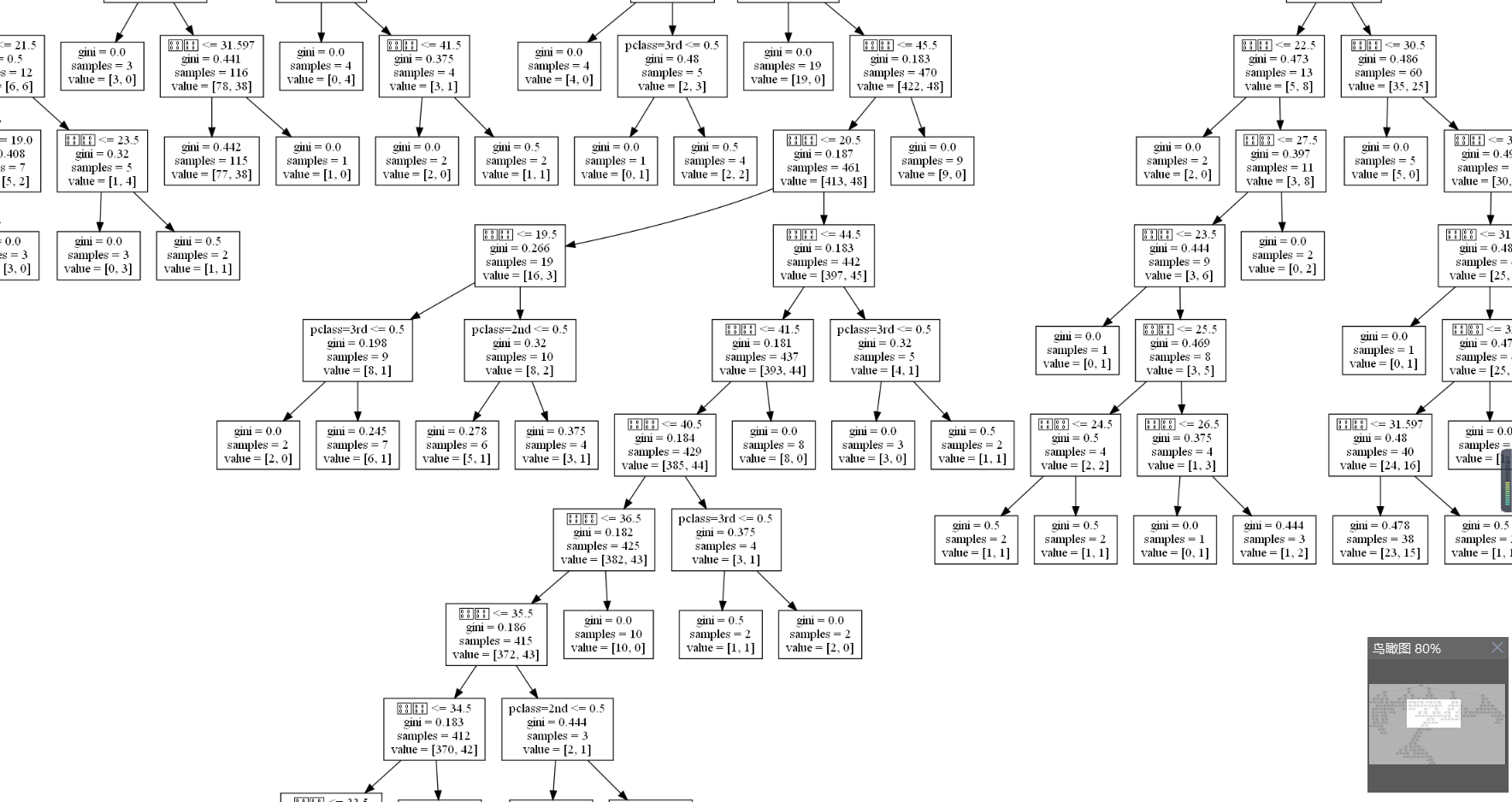
随机森林建立多个决策树的过程:
基于bootstrap抽样



 浙公网安备 33010602011771号
浙公网安备 33010602011771号