pandas学习 几个案例
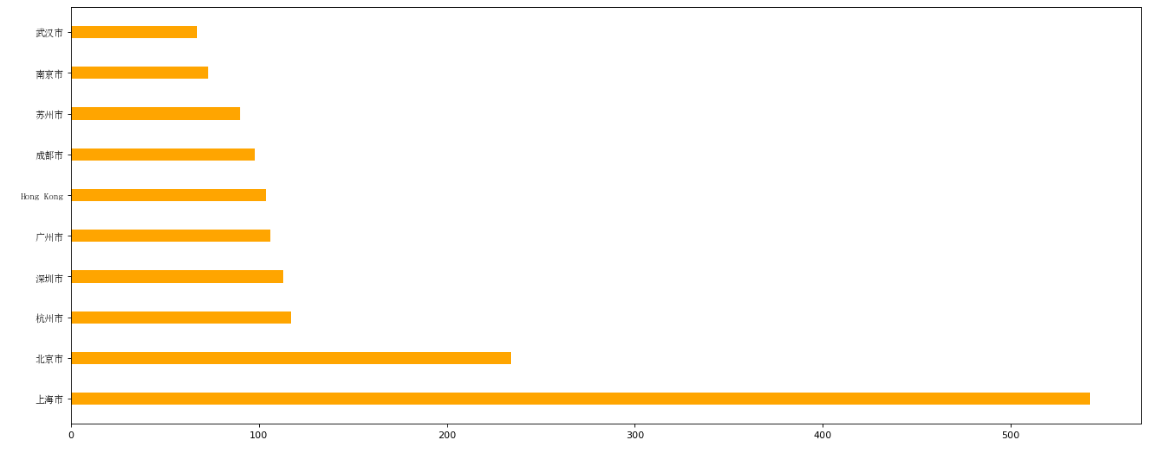
展示中国每个城市星巴克的店铺数量
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
file_path = "D:\Python\DataAnalysis-master\DataAnalysis-master\day05\code\starbucks_store_worldwide.csv"
#设置字体
my_font = font_manager.FontProperties(fname=r"C:\Windows\Fonts\SimSun.ttc")
df = pd.read_csv(file_path)
df = df[df["Country"]=="CN"]
# 聚合筛选排序
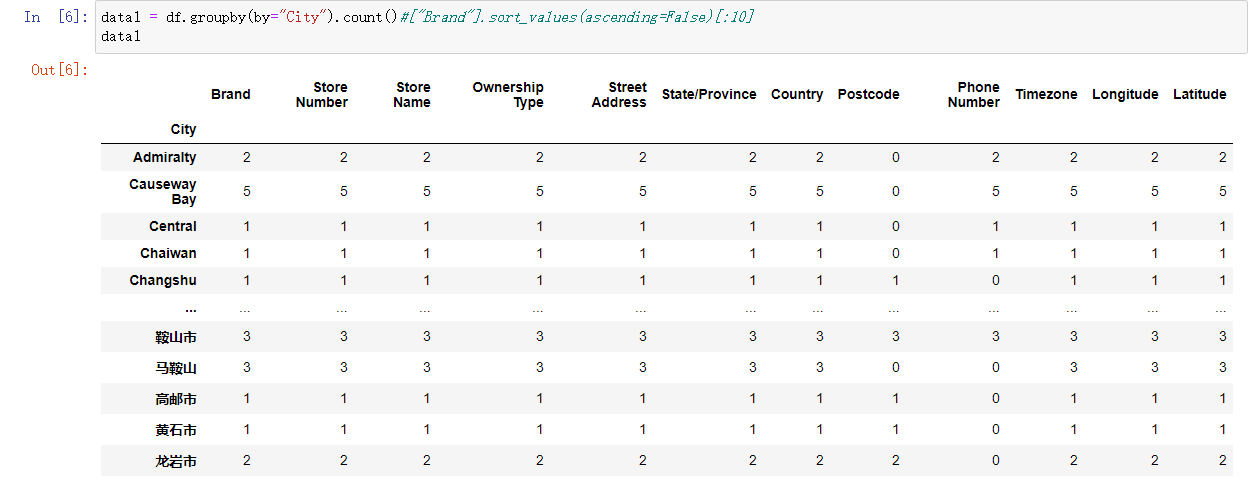
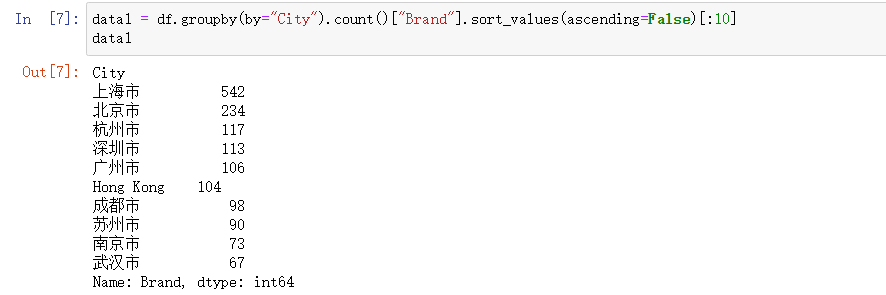
data1 = df.groupby(by="City").count()["Brand"].sort_values(ascending=False)[:10]
_x = data1.index
_y = data1.values
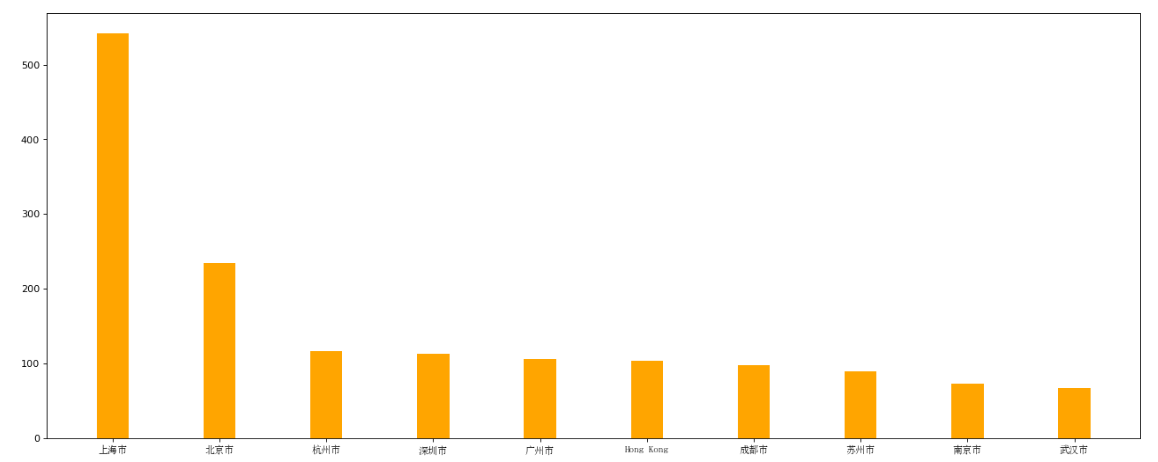
#画图1
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y,width=0.3,color="orange")
plt.xticks(range(len(_x)),_x,fontproperties=my_font)
plt.show()
#画图2
plt.figure(figsize=(20,8),dpi=80)
plt.barh(range(len(_x)),_y,height=0.3,color="orange")
plt.yticks(range(len(_x)),_x,fontproperties=my_font)
plt.show()
groupby之后的df:
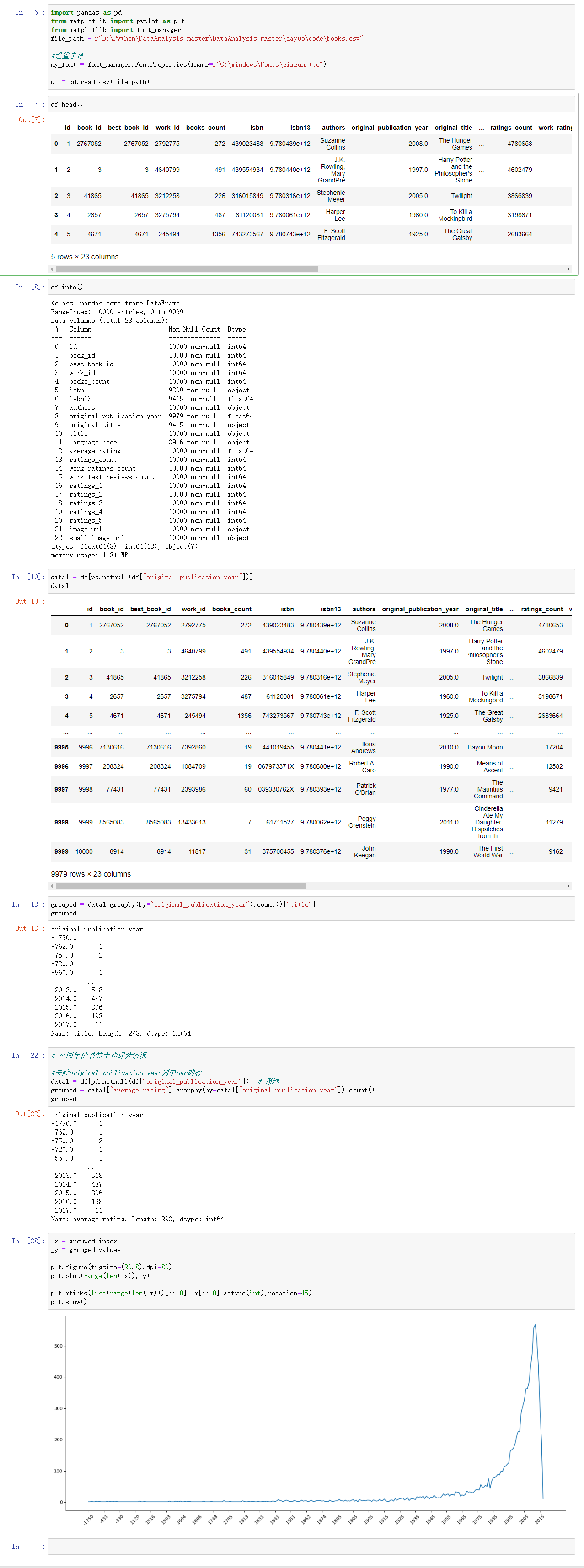
统计不同年份书的平均评分情况
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
file_path = r"D:\Python\DataAnalysis-master\DataAnalysis-master\day05\code\books.csv"
#设置字体
my_font = font_manager.FontProperties(fname=r"C:\Windows\Fonts\SimSun.ttc")
df = pd.read_csv(file_path)
df.head()
df.info()
data1 = df[pd.notnull(df["original_publication_year"])]
data1
grouped = data1.groupby(by="original_publication_year").count()["title"]
grouped
# 不同年份书的平均评分情况
#去除original_publication_year列中nan的行
data1 = df[pd.notnull(df["original_publication_year"])] # 筛选
grouped = data1["average_rating"].groupby(by=data1["original_publication_year"]).count()
grouped
_x = grouped.index
_y = grouped.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(list(range(len(_x)))[::10],_x[::10].astype(int),rotation=45)
plt.show()
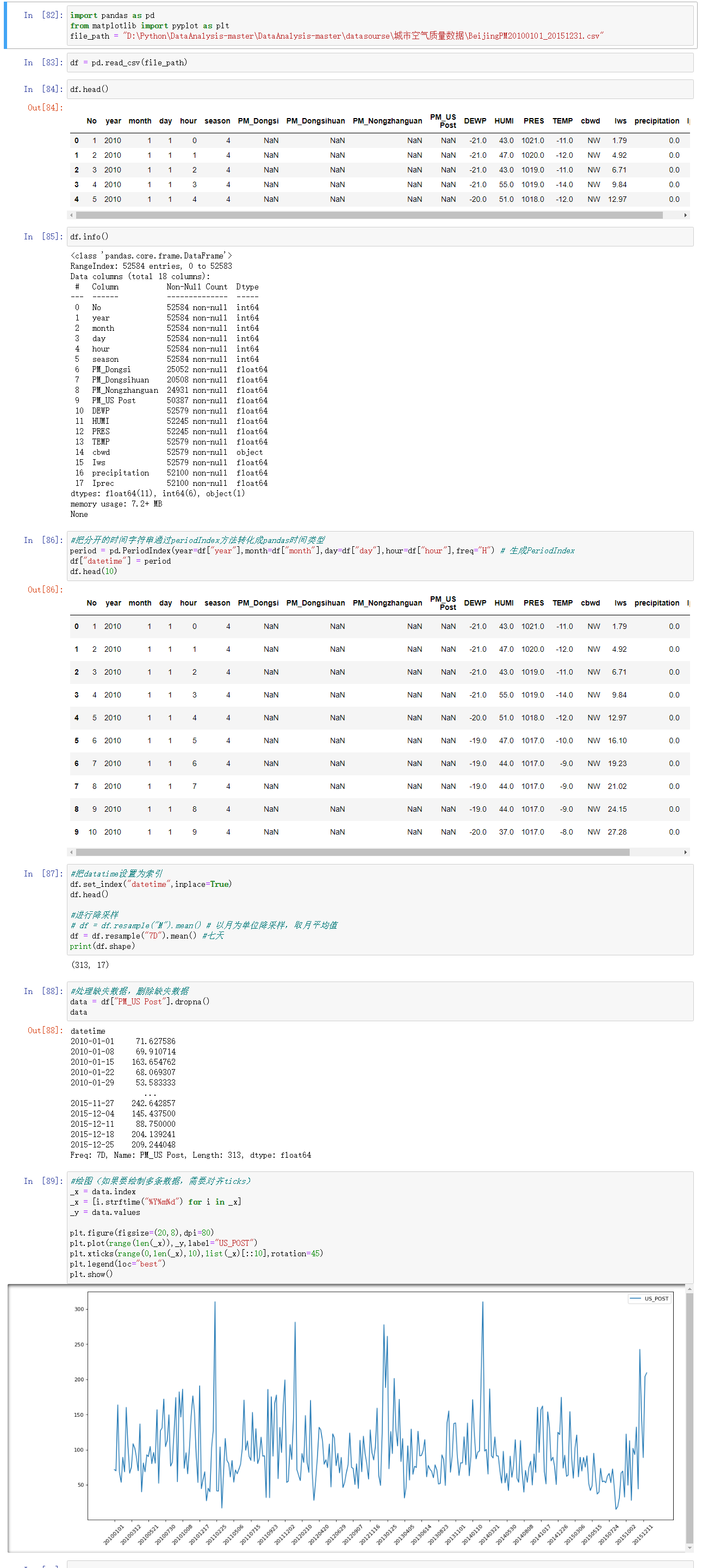
PM2.5监测数据统计
import pandas as pd
from matplotlib import pyplot as plt
file_path = "D:\Python\DataAnalysis-master\DataAnalysis-master\datasourse\城市空气质量数据\BeijingPM20100101_20151231.csv"
df = pd.read_csv(file_path)
df.head()
df.info()
#把分开的时间字符串通过periodIndex方法转化成pandas时间类型
period = pd.PeriodIndex(year=df["year"],month=df["month"],day=df["day"],hour=df["hour"],freq="H") # 生成PeriodIndex
df["datetime"] = period
df.head(10)
#把datatime设置为索引
df.set_index("datetime",inplace=True)
df.head()
#进行降采样
# df = df.resample("M").mean() # 以月为单位降采样,取月平均值
df = df.resample("7D").mean() #七天
print(df.shape)
#处理缺失数据,删除缺失数据
data = df["PM_US Post"].dropna()
data
#绘图(如果要绘制多条数据,需要对齐ticks)
_x = data.index
_x = [i.strftime("%Y%m%d") for i in _x]
_y = data.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y,label="US_POST")
plt.xticks(range(0,len(_x),10),list(_x)[::10],rotation=45)
plt.legend(loc="best")
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号