python文件
文本文件和二进制文件
文本文件:(.txt,word不是),单纯只存储文本,默认为unicode字符集(采用两个字节表示一个字符)
二进制文件:把数据内容用“字节”进行存储,必须使用专用软件解码。(mp3、mp4、jpg、doc等)
创建文件对象 open() 和 写入 write() writelines()
f = open(r"path","mode") # r之后就不用把路径\\转义
mode有以下几种:

文本文件的写入一般就是三个步骤:
1、创建文件对象
2、写入数据
3、关闭文件对象
write()只能传入字符串,writelines()可以传入字符串和字符串列表
f = open(r"path","mode", encoding='utf-8') # 创建文件对象,用utf-8编码
s = "要写入的字符串"
strlist = [要写入的字符串列表,它是顺序遍历写入]
f.write(s) or writelines(s or strlist)
f.close() # 关闭文件流
close()关闭文件流
由于文件底层是操作系统控制,所以我们打开的文件对象必须显式调用close()方法关闭文件对象。当调用close()方法时,首先会把缓冲区数据写入文件,再关闭文件,释放文件对象。
#一个标准规范的文件操作
try:
f = open(r"path",'mode',encoding='编码')
strlist = [要写入的字符串列表]
w.writelines(strlist)
except BaseException as e:
print(e)
finally: # 资源必须是要关闭的
f.close()
with 语句(上下文管理器)
with关键字(上下文管理器)可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,并且可以在代码块执行完毕后自动还原该代码块时的现场。
strlist = [要写入的字符串列表]
with open(r"path",'mode',encoding='编码') as f:
f.writelines(strlist)
文本文件的读取

with open(r"path","r",encoding='utf-8') as f:
print(f.read(4)) # 读取一个文件前4个字符
#通过for遍历文件对象
for i in f: # 每一个字符串i都以换行符结尾(每次读1行)
print(i)
enumerate函数
简要来说,一般用来生成把列表标号后的临时对象
具体来说:enumerate生成一个枚举对象。它是一个迭代器,就像一个生成器。迭代一次之后就清空了
a = ['やじゅうせんぱい\n','远野后辈\n','KMR\n']
b = list(enumerate(a)) # list会迭代清空对象,要用b接收
for id,vue in b:
print(id,vue)
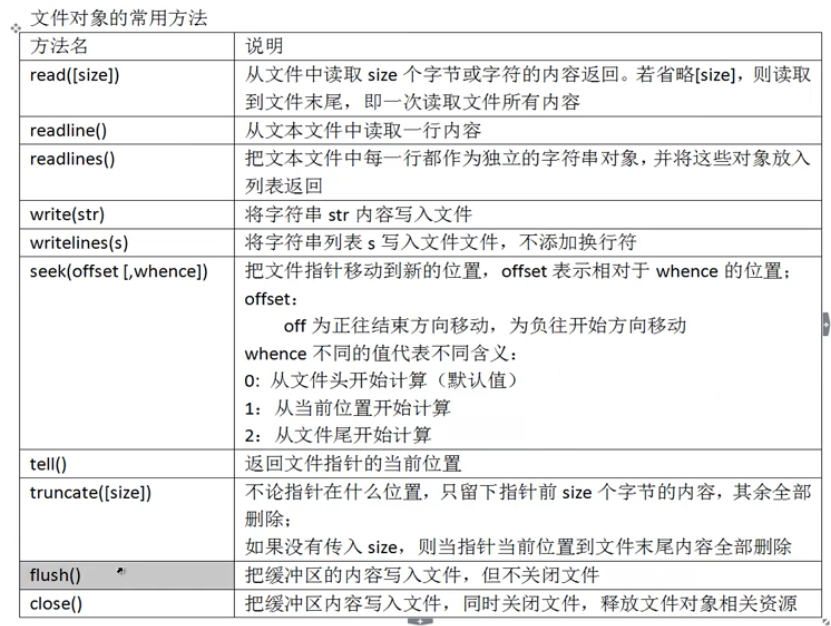
一些文件操作的常用方法
CSV基本操作
import csv # 导入csv模块
# 读取
with open(r"path\xxx.csv","r",encoding='')as f:
a_csv = csv.reader(f) # 这也是个类似生成器的对象,list()之后也会清空
# print(list(a_csv)) # 以行为单位转为list
for row in a_csv: # 遍历
print(row)
# 写入
with open(r"path\xxx.csv","w",encoding='')as f:
a_csv = csv.writer(f) # 写对象
a_csv.writerow(list) # 将列表写为1行
l = [['x','y','z'],['x','y','z'],['x','y','z']]
a_csv.writerows(l) # 遍历列表,把列表里的每个列表存为1行
os模块
以下所有的path指文件绝对路径,或者文件的相对路径(包含文件名)
调用
os.system可以直接调用系统的命令和打开可执行文件
import os
os.system("notepad.exe")# 调用记事本
os.system("regedit") # 调用注册表
os.system("ping www.baidu.com") # ping
os.startfile(r"path\xxx.exe") # 直接调用可执行文件
文件和目录操作
os.path模块可以实现很多对文件和目录的操作

#获取文件和文件夹的相关信息
import os
print(os.name) # windows->nt linux and unix ->posix
print(os.sep) # 分隔符,windows->| linux and unix->/
print(repr(os.linesep)) # 换行符
print(os.stat(r"filename")) # 文件信息
os.mkdir("path") # 创建目录
print(os.getcwd()) # 获取当前工作目录
os.chdir(r"path") # 改变工作目录
os.rmdir(r"path") # 删除目录
os.removedirs("path")# 删除多级空目录
'''
注意,这个路径包含的所有文件夹(输入相对路径时只会删它的子目录,而不会删相对路径的上级目录)
都会被尝试删除,从叶子向上遍历,直到某个目录不为空时结束
'''
os.makedirs("../xx/xx") # ../上级目录
print(os.listdir("path")) # 列出当前目录中的文件及子目录
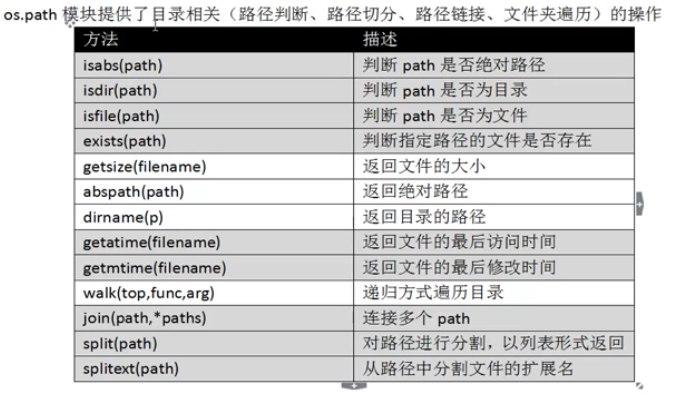
os.path
import os
path = os.getcwd()
# 输出工作目录中的文件名列表
file_list = os.listdir()
for filename in file_list:
if filename.endswith("py"):
print(filename)
print(path)
print(os.path.split(path)) # 返回分割后路径列表
print(os.path.join("C:\\","Documents","114514")) # 拼接路径

shutil(拷贝和压缩)
import shutil
shutil.copyfile("filepath you want to copy","new filepath") # 拷贝文件
shutil.copytree("dirpath","newdirname",ignore=shutil.ignore_patterns("*.txt","*.py")) # 新目录需要不存在,ignore里的是不需要的文件
shutile.make_archive("zippath","zip","filepath") # 压缩文件
# 压缩多个文件
z1 = zipfile.ZipFile("filename.zip","w")
z1.write("file1")
z1.write("file2")
z1.close

 浙公网安备 33010602011771号
浙公网安备 33010602011771号