Qwen3-ASR 开源,支持 52 种语言和方言;AI 用户访谈 Trooly.AI 获近千万美元种子轮融资丨日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的技术」、「有亮点的产品」、「有思考的文章」、「有态度的观点」、「有看点的活动」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@瓒an、@鲍勃
01 有话题的技术
1、Qwen3-ASR 正式开源:包含三款模型,支持 52 种语言与方言
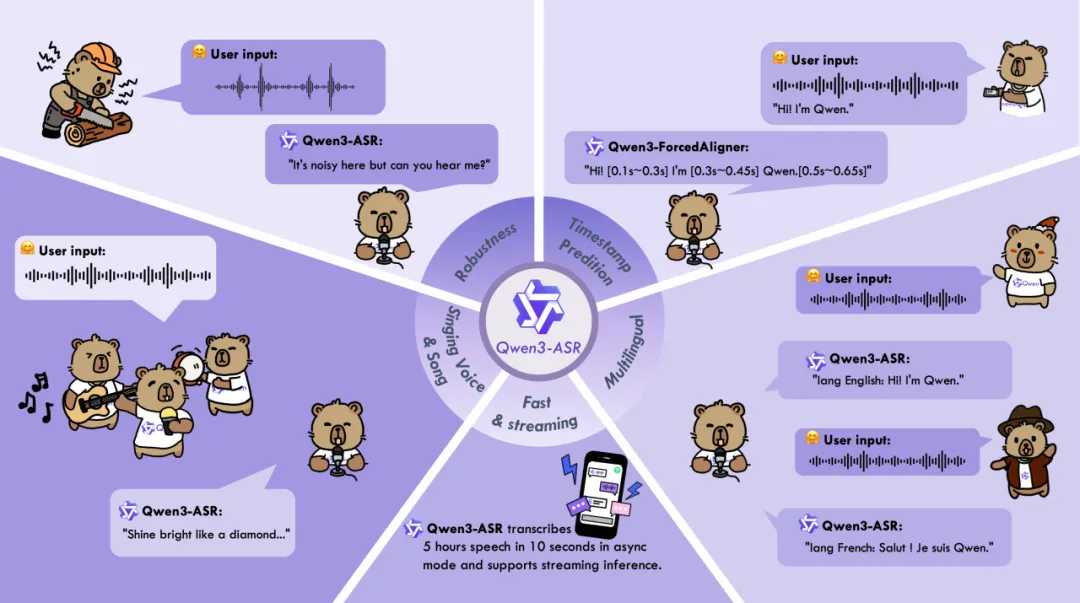
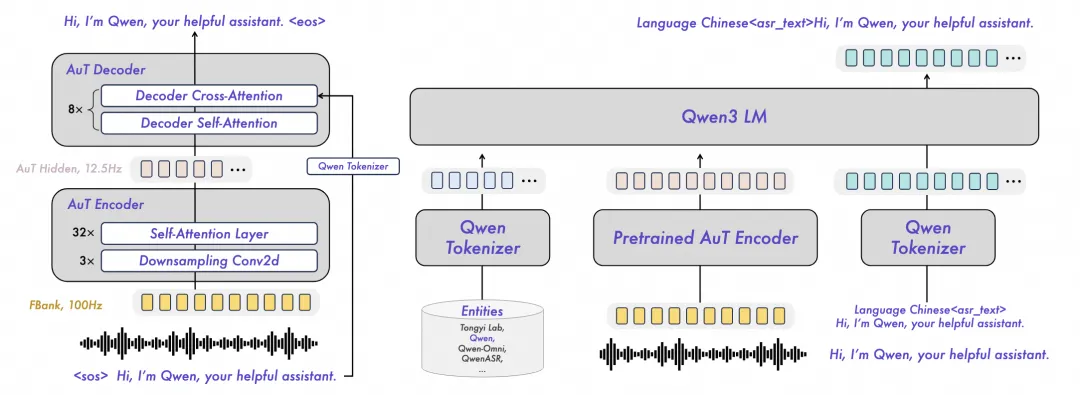
Qwen 团队正式开源 Qwen3-ASR 系列,包括两个强大且全面的语音识别模型 Qwen3-ASR-1.7B 与 Qwen3-ASR-0.6B,以及一个创新的语音强制对齐模型 Qwen3-ForcedAligner-0.6B。 Qwen3-ASR 系列的语音识别模型支持 52 个语种与方言的语种识别与语音识别。
依托预训练 AuT 语音编码器与 Qwen3-Omni 基座模型的多模态能力,Qwen3-ASR 系列实现了精准且稳定的识别效果。
其中,1.7B 模型在中文、英文及歌唱识别等场景达到 SOTA,具备复杂文本识别能力及强噪声下的稳定性;0.6B 模型兼顾性能与效率,128 并发下吞吐量达 2000 倍(10 秒处理 5 小时音频)。
两款模型均单模型支持 30 个语种及 22 个中文方言,支持流式/非流式一体化推理,最长可处理 20 分钟音频。
Qwen3-ForcedAligner-0.6B 支持 11 种语言任意位置对齐,精度超越 WhisperX 等主流模型,单并发推理 RTF 仅 0.0089。目前,全套模型权重、结构及支持 vLLM 的推理框架已全部开源。
在模型效果评估方面,Qwen3-ASR 系列在中文/英文、多语种、中文方言、歌声识别及复杂场景下均表现优异:
-
英文场景:不仅在公开基准上达到最优,在覆盖 16 个国家口音的内部测试集中,整体表现优于 GPT-4o Transcribe、Gemini 系列、Doubao ASR 系列及 Whisper-large-v3。
-
多语种场景:最高支持 30 种语言,在 20 个主流语种上,1.7B 模型全面超越现有开源模型,取得最佳平均 WER。
-
中文与方言场景:在普通话、粤语及 22 种地区方言上整体领先,尤其在方言识别上,相比 Doubao-ASR 平均错误率降低了 20%(15.94 vs 19.85)。
-
复杂场景:面对老人/儿童语音、极低信噪比、鬼畜重复等挑战,仍能保持极低的字/词错误率;歌唱识别支持带 BGM 的整首歌中/英文转写。
此外,该系列在推理效率与对齐能力上也实现了突破。Qwen3-ASR-0.6B 模型在性能与效率间取得了平衡,无论离线或在线高并发场景,均能保持极低 RTF 与极高吞吐。配套推出的 Qwen3-ForcedAligner-0.6B 则支持 11 种语言的任意位置灵活对齐,其时间戳预测精度整体超过 WhisperX、NeMo-ForcedAligner 等主流方案。
目前,Qwen3-ASR 系列模型已在 Github、HuggingFace 和 ModelScope 上线,相关论文及阿里云百炼 API 也已同步发布。
Github:https://github.com/QwenLM/Qwen3-ASR
HuggingFace:https://huggingface.co/collections/Qwen/qwen3-asr
识别结果:
蹦出来之后,左手、右手接一个慢动作,右边再直接拉到这上面之后,直接拉到这个轮胎上,上边再接过去之后,然后上边再直接拉到这个位置了之后,右边再直接这个位置接倒过去的之后,再倒一下,然后右边再直接抓住这个上边了之后,直接从这边上边过去了之后,直接抓住这个树杈,然后这个位置直接倒到这个树杈。
识别结果:
拨号,请再说一次,请说出您要拨打的号码。幺三五八幺八八七五七。一三五八二八八八幺八八。纠正纠正。九六九。纠正纠正,不是九六。
识别结果:
Okay, Charles. It looks like we have a problem with the radio. What happened? Yeah, someone spilled water on their machine. I uh, yeah. Charles, can you hear us? Mamma mia.
(@千问 Qwen)
2、Google 推出 LiteRT 推断框架:深度集成 NPU,实现跨平台统一高性能部署
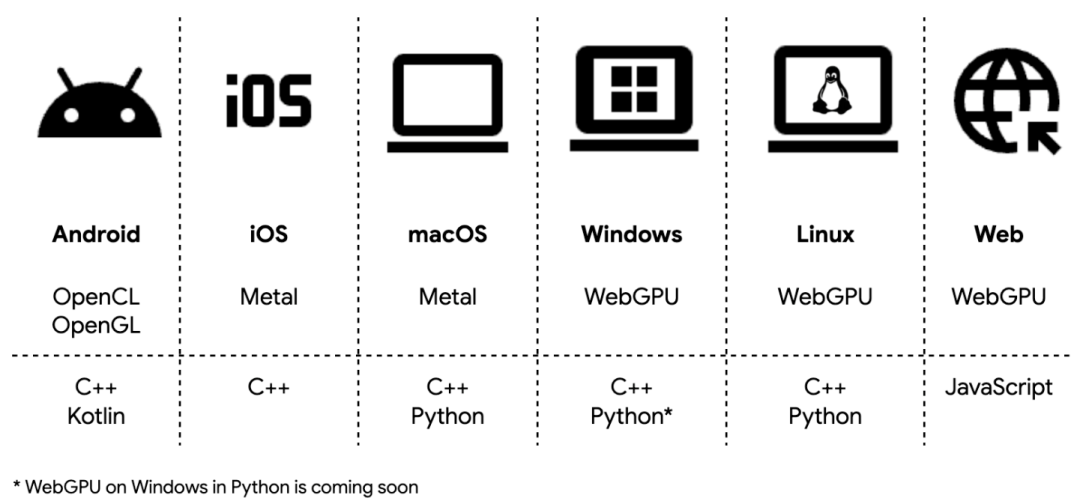
Google 正式推出继任 TensorFlow Lite 的端侧 AI 推断框架「LiteRT」。该框架完成了从经典机器学习向生成式 AI(GenAI)的架构演进,通过深度集成 NPU 加速和全新编排层,实现了跨 Android、iOS、Web 及桌面端的统一高性能部署。
-
高性能多后端加速:采用下一代 GPU 引擎 「ML Drift」,支持 OpenCL、Metal 和 WebGPU。GPU 性能较 TFLite 提升 1.4 倍,并引入异步执行与零拷贝缓冲(Zero-copy buffer)技术,端到端延迟缩减达 2 倍。
-
深度 NPU 集成方案:通过抽象层屏蔽不同 SoC 的 SDK 差异,首批支持「MediaTek」与「Qualcomm」NPU。实测 NPU 推断速度较 CPU 提升 100 倍,并提供 AOT(预编译)与 JIT(即时编译)两种部署模式以平衡启动速度与包体积。
-
GenAI 专用技术栈:新增「LiteRT-LM」编排层与「LiteRT Torch Generative API」。在 Samsung Galaxy S25 Ultra 上的基准测试显示,Gemma 3 1B 的 GPU Prefill 速度较 llama.cpp 提升 19 倍,Decode 速度提升 7 倍。
-
多框架无缝转换:支持 PyTorch、JAX 和 TensorFlow 模型一键转换为 。tflite 格式。其中 LiteRT Torch 库允许 PyTorch 基于 Transformer 的架构直接映射至优化后的底层算子,无需复杂的中间件平移。
-
全新 C++ API:引入 CompiledModel API 取代传统的 Interpreter 模式,旨在优化多线程环境下的内存复用与硬件调度效率,同时保持与存量 。tflite 模型的向后兼容。
LiteRT 现已进入生产就绪状态,全面支持主流移动端与桌面端操作系统,核心代码已在 GitHub 开源。
GitHub:https://github.com/google-ai-edge/LiteRT/issues
( @Google for Developers Blog)
3、曝阿里字节春节前后齐发旗舰模型
就在刚刚,据 The Information 援引知情人士消息称,字节和阿里均计划在二月中旬的春节假期前后发布新一代旗舰 AI 模型。
消息人士称,字节将于下月推出三款 AI 产品:新一代大语言模型 Doubao 2.0、图像生成模型 Seedream 5.0 以及视频生成模型 SeedDance 2.0。
阿里方面同样蓄势待发。据直接了解其计划的人士透露,阿里预计将在春节期间推出旗舰模型 Qwen 3.5,该模型针对复杂推理任务进行了专门优化,在数学和编码能力方面表现突出。
本月中旬,阿里官宣对千问 APP 进行重大升级,将其与电商平台、在线旅游服务以及蚂蚁集团的支付系统深度整合,力求打造一个能够协助用户完成订餐、预订旅行等实际任务的全能 AI 助手。
而据内部人士透露,阿里的目标是在 2026 年上半年将所有生态服务整合到千问 APP 中。
此外,报道还提到,阿里和字节都在进行更长远的布局,正在开发能够无缝处理文本、图像、音频、视频和代码的全能型 AI 模型。
( @APPSO)
4、数字人 Tavus 发布 tavus-skills:支持 npx 一键集成实时视频交互组件
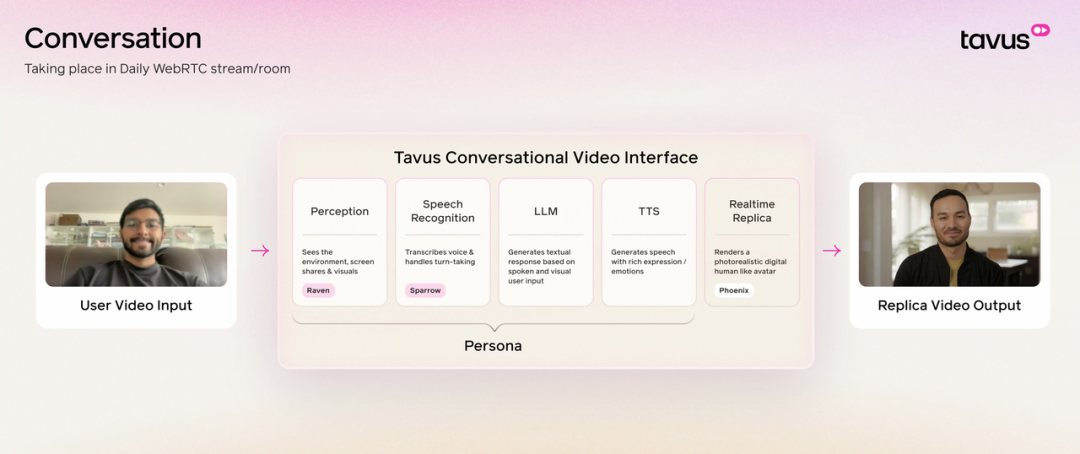
数字人 Tavus 推出开发者工具集 tavus-skills,旨在通过标准化的技能模块供智能体调用,快速构建视频 AI 代理。该工具集集成了数字孪生训练、视频流生成及实时对话交互(CVI)能力,支持开发者通过 CLI 工具完成环境配置。
-
npx 模块化分发体系:支持通过 npx skills add Tavus-Engineering/tavus-skills 实现一键集成。开发者可按需拆分安装 tavus-replica(数字孪生管理)、tavus-video-gen(脚本化视频生成)等 8 个独立模块。
-
CVI 专用模型栈集成:底层原生支持 Phoenix-3 视频生成模型、Raven 视觉/音频感知模型以及 Sparrow 实时对话控制引擎,针对实时交互场景优化了响应延迟。
-
WebRTC 实时交互控制:提供 tavus-cvi-interactions 模块,支持在视频流传输中执行实时文本回显(Echo)、指令打断(Interrupt)以及动态上下文注入。
-
前端工程化支持:配套发布 @tavus/cvi-ui React 组件库与 React Hooks,深度适配 Vite 与 Next.js 框架,简化了实时视频交互界面的 UI 开发。
-
持久化 RAG 与记忆模块:通过 tavus-cvi-knowledge 模块支持文档上传与知识库构建,允许视频智能体在多次对话间保持长短期记忆。
GitHub:https://github.com/Tavus-Engineering/tavus-skills
( @GitHub)
02 有亮点的产品
1、AI-Native 用户研究平台 Trooly.AI 获王慧文、高瓴及蓝驰投资,完成近千万美元种子轮融资
据「暗涌 Waves」报道,成立仅 4 个月的 AI-Native 用户研究平台 Trooly.AI 已完成近千万美元的种子轮融资,投资方包括蓝驰创投、高瓴创投和王慧文。
与市面上常见的宏大叙事不同,Trooly.AI 专注于实现商业闭环。其核心产品面向有用户调研需求的 B 端客户,通过多模态 Voice Agent 技术,专注于 45 分钟左右的深度定性用户访谈。该平台宣称可在 10 分钟内协助用户完成研究计划的设置和发布,并在 1 天内交付完整访谈数据和专业洞察总结。
Trooly.AI 的两位创始人王震和孙皓此前均为 Zulution AI 早期成员。Zulution AI 由 TikTok 前身 Musical.ly 创始人阳陆育创办,曾推出 AIGC 角色扮演对话产品「Museland」。王震和孙皓共同经历过 AI 陪伴产品的拓荒期,但在 2025 年春,随着 AI 陪伴产品的用户交互出现边际效应递减,两人选择离开。
在探索了多种产品形态后,创始人团队意识到,在 AI 使内容生成成本趋近于零的时代,竞争壁垒在于「输入」的质量。最昂贵的资产是能为产品决策提供核心「信息增量」的真实用户故事。这一方向的确立也源于王震此前作为甲方的采购经历:传统调研耗资巨大且样本量少。团队发现,此前积累的对话技术天然适合深度定性访谈。
王震指出,相比人类访谈员带来的社交压力,受访者面对「博学且温和」的 AI 更容易敞开心扉。在 Trooly.AI 的实际案例中,AI 访谈员曾引导受访者分享隐秘且深刻的情绪。王震认为,在用户调研中,单纯的事实往往只是边角料,核心在于「用户故事」。只有通过故事感知用户与产品间的真实羁绊,才能弥合产品经理想象与现实之间的鸿沟。
针对产品效能与体验,Trooly.AI 强调以下特点:
-
效率与成本:相比传统用研流程动辄耗时一两个月,Trooly.AI 的反馈速度提升约 30 倍,成本可压至传统方式的 20%。
-
交互体验:产品界面摒弃拟人化形象,仅保留流动的声波与配色,以降低社交压力并营造宁静氛围。
-
技术逻辑:底层注入大量专家知识,Agent 能根据用户背景、情绪信号动态调整追问深度,把控交互节奏。
关于团队建设,王震和孙皓表示经历了从迷信「超级个体」到回归团队协作的转变。他们认为,尽管 AI 能大幅提升执行效率,但无法替代人类在审美、发散性创新与结构化逻辑上的互补。因此,Trooly.AI 倾向于组建由各维度单项顶尖人才构成的精简团队。
面对 AI 时代极其残酷的竞争环境,Trooly.AI 团队认为绝大多数无法形成有效服务的「玩具」类应用终将消亡,因此致力于在利基市场中确立生存优势。
联合创始人孙皓指出,Trooly.AI 的目标不仅仅是做一个工具,而是构建一套让「构建者」能够直达用户真实声音的价值链。王震表示,Trooly.AI 的使命是让消费者洞察直达产品决策者。团队希望帮助全球的产品构建者弥合想象偏差,减少资源浪费,从而在 AI 时代的「生物大爆发」中挖掘真需求,找到自然选择下的最优解。
报道链接:https://mp.weixin.qq.com/s/E4CJQnezo0J1PuATOQ1ZHg
官网:https://www.trooly.ai
(@暗涌 Waves)
2、曝豆包手机二代机型二季度发布

据《智能涌现》报道,字节跳动已于去年底正式启动豆包手机助手正式版项目,第二代豆包手机预计将在今年第二季度中晚期发布。
报道称,字节跳动对二代机型的市场预期显著提高,依旧延续与中兴努比亚的合作模式,由中兴负责硬件、豆包负责 AI 能力。
供应链人士称,新机在体验与权限体系上将比初代测试版更成熟。与此同时,豆包团队已与部分互联网服务提供商(打车、外卖、订票等)达成常用权限接入协议,以提升系统级 AI Agent 的可用性。
在合作策略上,豆包正与不同类型的手机厂商展开差异化谈判。对于 OPPO、vivo、荣耀等自研生态完善的大厂,合作主要集中在模型调用、输入法等模块化技术层面;
而对于传音、魅族、联想等市占率较低的厂商,则采取更激进的方案,直接在系统中内置豆包 AI 入口,并以技术授权费与 AI 服务订阅费作为商业模式。
报道还指出,豆包手机正同步推进海外布局,已与包括 vivo 在内的厂商商讨在其海外机型中搭载「豆包手机助手」,但细节仍在谈判中。
同时,字节在硬件形态上持续扩张,正在开发带显示与不带显示的两款 AI 眼镜,前者预计将在今年 Q4 发布,后者将在今年 Q1 推出。此外,字节也在研发带摄像头的 AI 耳机,试图构建多终端协同的智能硬件生态。
( @APPSO)
3、法国政府宣布 2027 年前停用 Teams 和 Zoom,全面转向自研平台 Visio
法国政府周一宣布,计划用本国自主研发的视频会议平台取代微软 Teams 和 Zoom 等美国平台,并于 2027 年前在所有政府部门全面投入使用。
此举属于法国停止使用外国(特别是美国)软件供应商并重新掌握关键数字基础设施控制权战略的一环。 目前,法国与欧洲正处于关于数字主权的关键转折点。
法国公务员与国家改革部部长 David Amiel 表示,目标是结束对非欧洲解决方案的使用,依靠强大且自主的主权工具来保证公共电子通信的安全性和机密性。
政府宣布将转而使用法国制造的视频会议平台 Visio。该平台已进行了为期一年的测试,目前拥有约 4 万名用户。
Visio 是法国「数字套件」(Suite Numérique)计划的组成部分,该计划构建了一个主权工具数字生态系统,用于替代 Gmail 和 Slack 等美国在线服务。这些工具专供公务员使用,不面向公共或私营企业。
该平台还具备由人工智能驱动的会议转录和发言人识别功能,采用了法国初创公司 Pyannote 的技术。Visio 托管在法国公司 Outscale 的主权云基础设施上,该公司是法国软件巨头达索系统(Dassault Systèmes)的子公司。
法国政府表示,切换到 Visio 能够削减许可成本,每 10 万名用户每年可节省高达 100 万欧元。
在此之前,去年发生的美国云服务中断事件引发了欧洲对过度依赖美国信息技术基础设施的质疑。Amiel 指出,这一战略突显了在地缘政治紧张局势加剧以及对外国监控或服务中断的担忧中,法国对数字主权的承诺。
(@Euronews Next )
03 Real-Time AI Demo
1、当乐高遇上 AR 眼镜:开发者利用 Gemini 赋予积木实时声效与交互
开发者 Stijn Spanhove 与 Pavlo 在 Snap Spectacles 上构建了一个概念验证(POC),探索了继 LEGO Smart Bricks 之后,将乐高积木与 AR 眼镜相结合的交互形态。
在该演示中,系统利用 Gemini 模型视觉识别用户搭建的任何乐高作品,即时生成独一无二的音效,并支持用户直接用手进行抓取与互动。
例如,摇晃一架飞机模型时会听到引擎的轰鸣,挥舞一条龙时则伴随着咆哮声。对于每一个不同的拼搭作品,系统都能做出差异化的反应。
开发者提出了一种进一步融合的设想:将 LEGO Smart Play 积木内部的物理传感器、AR 技术以及环绕的生成式 AI 结合在一起。这种组合有望打造出一个既能从内部物理感应做出反应,又能通过眼镜在视觉上「活过来」的乐高城市。
正如开发者所言,这一切并非科幻构想,所有必要的技术组件目前均已存在,该项目展示了这些技术整合后的潜力。
( @stspanho@X)
04 有态度的观点
1、OpenAI 董事长:Vibe Coding 不是终局,AI Agent 才是软件未来
据《商业内幕》报道,OpenAI 董事长 Bret Taylor 近日在《Big Technology Podcast》节目中表示,「Vibe Coding」将继续存在,但它并非软件行业的最终形态。
Taylor 在节目中指出,依赖自然语言快速生成应用的方式会逐渐变得寻常,而真正的变革来自 AI Agent 对软件结构的重塑。
Taylor 认为,当前围绕「如何更快用 Vibe Coding 做出一个应用」的讨论忽略了关键问题。
他表示,未来的软件形态将不再依赖传统的仪表盘、网页表单或独立应用,而是由可执行任务的 AI Agent 取代。
我们会把任务交给 Agent,它们会直接对数据库执行操作。关键在于,这些 Agent 是谁来做,你是买现成的,还是自己构建。
他同时指出,AI 虽然显著降低了软件开发成本,但并未解决维护难题,也未消除错误风险,因此大多数企业仍倾向于购买成熟方案,以将维护成本分摊给更多客户。
关于 Vibe Coding 的局限性,Google CEO Sundar Pichai 去年在《Google for Developers》播客中表示,这种方式让编码更轻松,也让非技术用户能创建简单应用。
不过,他也指出 AI 生成的代码仍可能冗长、结构不佳或存在错误。他在 Google 母公司 Alphabet 去年 4 月的财报电话会上透露,Google 超过 30% 的新代码由 AI 生成,高于 2024 年 10 月的 25%。
Anthropic 工程师 Boris Cherny 也在去年 12 月的《The Peterman Podcast》中指出,Vibe Coding 更适合原型或一次性代码,而不适用于企业核心系统。
有时候你需要可维护的代码,需要对每一行都非常谨慎。
( @APPSO)


阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么
写在最后:
我们欢迎更多的小伙伴参与**「RTE 开发者日报」**内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

作者提示: 个人观点,仅供参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号