OpenAI 首款 AI 硬件是一支笔,并将研发全新音频模型架构;Pickle 预售四摄 AR 眼镜,可行性遭质疑丨日报

开发者朋友们大家好:
这里是 「RTE 开发者日报」,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的技术」、「有亮点的产品」、「有思考的文章」、「有态度的观点」、「有看点的活动」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@瓒an、@鲍勃
01有话题的技术
1、DeepSeek 开年炸场,梁文锋又发论文,提出 mHC 新方案
北京时间 1 月 1 日,DeepSeek 公布了一篇新论文,提出名为 mHC (流形约束超连接)的新架构。
据介绍,该研究旨在解决传统超连接在大规模模型训练中的不稳定性问题,同时保持其显著的性能增益。
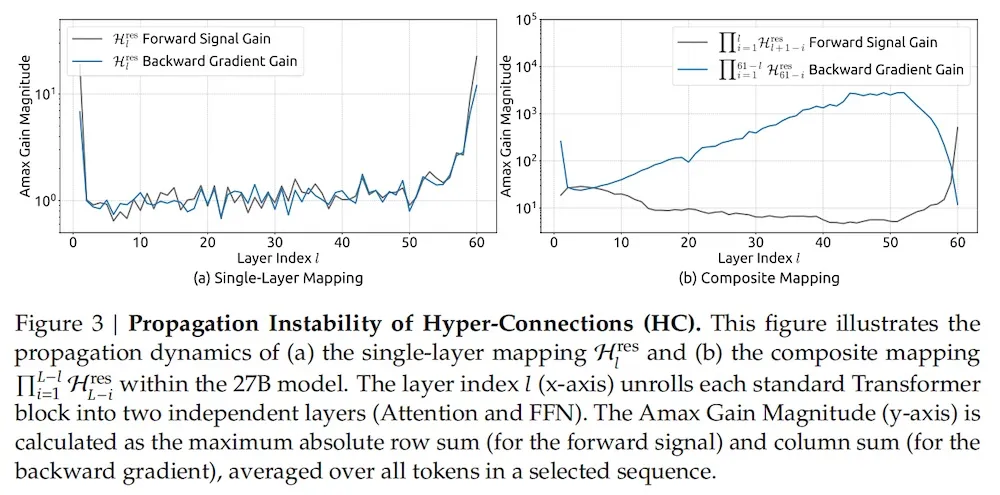
团队指出,在过去十年中,残差连接(Residual Connection)一直是深度学习架构的基石。
而近期出现的 「超连接(Hyper-Connections, HC)」 技术通过扩大残差流宽度和多样化连接模式,虽然带来了显著的性能提升,但也引入了严重的副作用——它破坏了对模型训练至关重要的 「恒等映射属性」。
这不仅导致训练过程极不稳定,限制了模型的扩展能力,还带来了额外的显存访问开销。
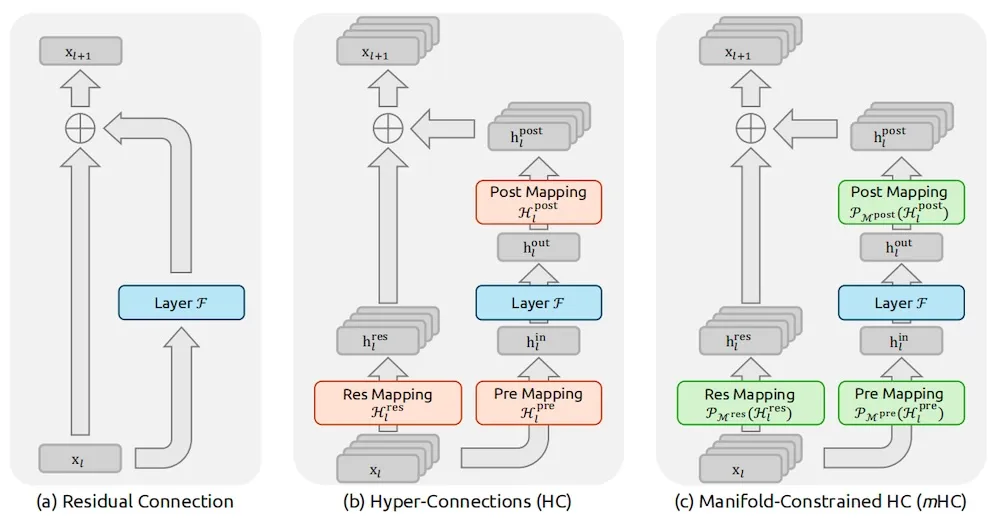
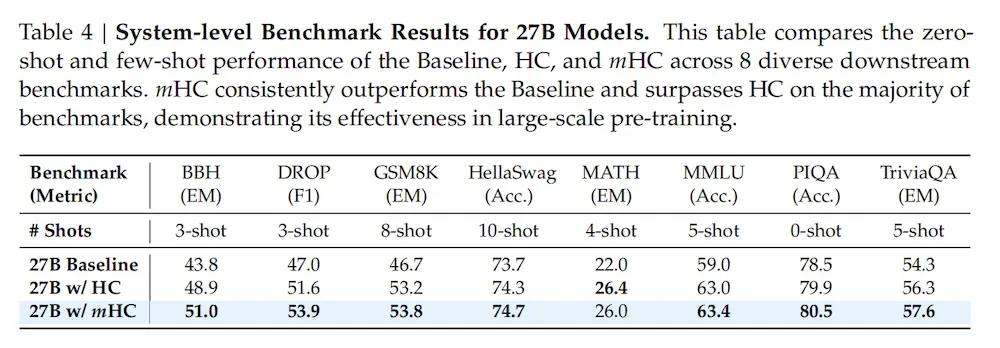
而实验数据显示,进行重构后的 mHC 在大规模训练场景下效果显著,不仅带来了实质性的性能提升,更展现出优越的可扩展性。
DeepSeek 团队认为,mHC 作为一种灵活且实用的架构扩展,将加深行业对拓扑架构设计的理解,并为基础模型的未来演进指明了新方向。
值得关注的是,该篇论文第一作者分别为 Zhenda Xie(解振达)、Yixuan Wei(韦毅轩)、Huanqi Cao。同时,DeepSeek 创始人及 CEO 梁文锋也在作者名单中。
(@APPSO、@智东西)
2、Google 「NotebookLM」测试原生「讲座」模式:支持 30 分钟单人叙事与多语言切换
Google 正在测试 「NotebookLM」 的全新音频生成模式「Lecture」,将原有的播客式双人对话转变为单人结构化叙事。该更新旨在将上传的文档转化为长达 30 分钟的深度讲座,并新增了语言选择器与特定口音选项。
-
交互架构从「对话」转向「单人叙事」:不同于现有的双人 AI 主持人播客风格,「Lecture」模式由单一 AI 主持人进行系统化讲解,侧重于跨源信息的逻辑链接与详细解释。
-
支持 30 分钟长格式音频生成:在选择「Long」长度选项时,模型可生成约 30 分钟的连续音频会话,显著提升了针对长文档、复杂研究论文或会议记录的覆盖深度。
-
新增原生语言选择器:用户可在生成前指定音频的输出语言,不再受限于源文档语言,进一步增强了多语言环境下的研究复用性。
-
语音库扩展与口音定制:系统计划引入更多旁白选项,包括已确定的英式英语口音,预计将提升音频的听感多样性与专业化场景匹配度。
-
功能矩阵整合:该模式将作为「Audio Overview」下的并列选项,与现有的「Deep Dive」(深度解析)、「Brief」(简报)、「Critique」(评论)及「Debate」(辩论)共同构成多维度的内容转化工具集。
当前处于内部测试阶段,尚未对公众开放;英式英语旁白及部分新特性预计在 2026 年内逐步上线。
(@Business Standard)
3、元象开源 XVERSE-Ent 泛娱乐大模型:基于 MoE 热启动技术,支持单卡部署与 8K 上下文
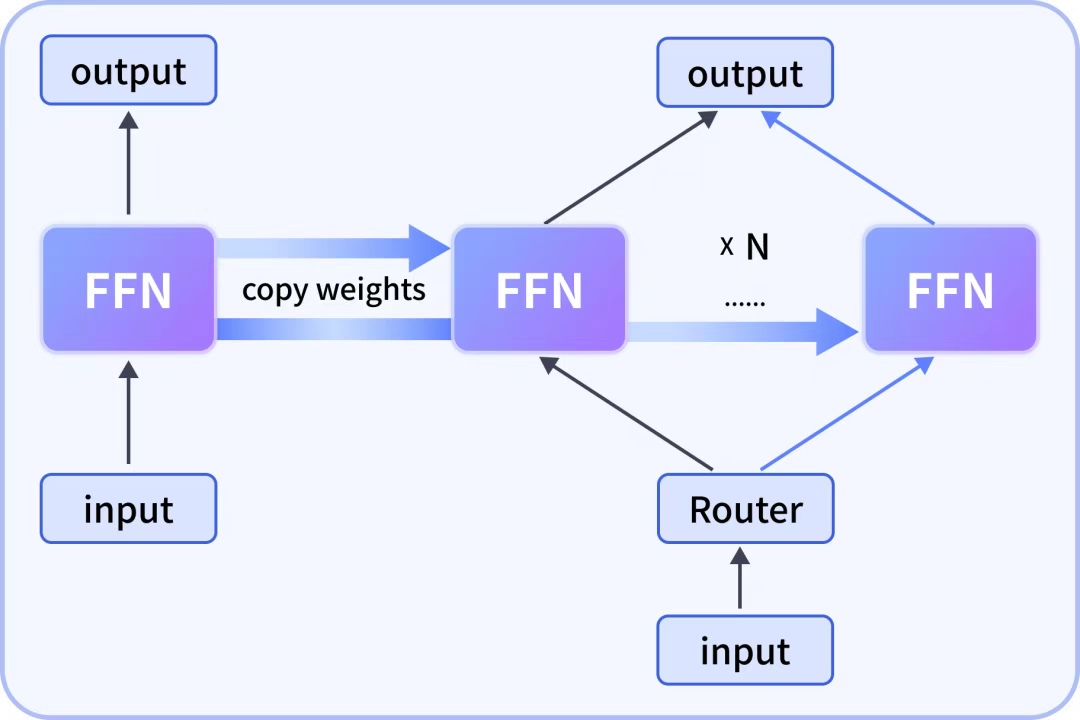

「元象」正式开源专注于泛娱乐领域的「XVERSE-Ent」中英双语模型。该模型通过 MoE 热启动与多阶段训练策略,在保持通用能力 98% 以上保留率的同时,强化了角色一致性与长剧情逻辑,旨在解决社交互动与游戏叙事中的「出戏」与「遗忘」问题。
-
MoE 热启动与 FFN 细粒度拆分:模型通过将原有 Dense 模型的 FFN 部分进行细粒度拆分(而非简单的粗粒度复制)转化为多专家子网络,复用 Attention 部分,实现从 Dense 到 MoE 架构的高效迁移。
-
双版本参数配置:
-
中文版 (A4.2B):激活参数 4.2B,总参数量 25B,基于通用底座 XVERSE-MoE-A4.2B 增强。
-
英文版 (A5.7B):激活参数 5.7B,总参数量 36B,针对英文创意写作与全球化语境优化。
-
三阶段训练策略 (S0-S2):采用 S0(能力重建)、S1(语言倾斜)、S2(领域增强)的递进式训练,在 S2 阶段引入通用与领域数据混合训练,确保专业能力不以牺牲通用逻辑为代价。
-
长数据与推理性能:支持 8k context window,经过近万亿 token 数据训练,支持云端单卡部署,优化了高并发场景下的推理成本与处理效率。
模型已在 GitHub 及 ModelScope 开源,提供 XVERSE-Ent-A4.2B 和 XVERSE-Ent-A5.7B 两个文本模态模型,支持免费下载与商用授权申请。
ModelScope:
https://modelscope.cn/models/xverse/XVERSE-Ent-A4.2B
https://modelscope.cn/models/xverse/XVERSE-Ent-A5.7B
Github:
https://github.com/xverse-ai/XVERSE-Ent
(@魔搭 ModelScope 社区)
02有亮点的产品
1、OpenAI 首款 AI 硬件曝光:竟是一支笔,并将配套推出全新音频模型架构
据博主智慧皮卡丘从供应链渠道获知的消息,OpenAI 与前苹果首席设计官 Jony Ive 合作的硬件项目内部代号「Gumdrop」(软糖)。
目前供应商评估阶段同步推进三个项目,其中一个明确指向笔形态,一个则是便携音频设备。
更详细的爆料信息勾勒出这样一个产品画像:
-
这是一款笔形设备,深度整合 AI 能力,旨在成为继 iPhone 和 MacBook 之后的「第三核心设备」。
-
它身形小巧,轻量便携,尺寸与 iPod Shuffle 相仿,可轻松放入口袋或挂在胸前。
-
它集成了麦克风和摄像头,以感知和理解用户所处的环境。
-
其核心功能之一是,能够将手写笔记直接转化为文本,并即时上传至 ChatGPT。
-
OpenAI 的首款消费级硬件设备预计将在 2026 至 2027 年间发布。
而据 The Information 报道,OpenAI 不只是想推出单款产品,而是通过一系列产品进行生态闭环。知情人士透露,OpenAI 还考虑过智能眼镜、无屏智能音箱在内的想法。
报道还指出,为了这款能发声、能交流的 AI 硬件,OpenAI 目前正在改进自家的 AI 音频模型。
OpenAI 正在开发一种全新的音频模型架构,计划于 2026 年第一季度推出,旨在支持一款能像伙伴一样为用户提供建议、帮助达成目标的语音设备。
过去两个月,OpenAI 整合了多个工程、产品和研究团队,因为研究人员认为当前的音频模型在准确性和速度上均落后于文本模型。
新的音频模型架构将带来更自然、更具情感的声音,提供更准确、深入的回答,并实现与用户同时说话、更好地处理打断——这对于一款能主动帮助用户的伙伴式 AI 至关重要。
这项努力由今年夏天从 Character.AI 聘请的语音 AI 研究员 Kundan Kumar 领导,Ben Newhouse(曾帮助重建 OpenAI 音频 AI 基础设施)和 Jackie Shannon(多模态 ChatGPT 产品经理)共同参与。
(@APPSO、@三次方 AIRX)
2、全球首款视觉 AI 网球机器人 Tenniix 亮相 CES 2026:支持语音交互与自适应训练,699 美元起
1 月 3 日消息,全球首款基于视觉的 AI 网球机器人 Tenniix 宣布将于 CES 2026 正式亮相,展示其智能追踪、自适应学习及拟人化对打能力。**
据介绍,Tenniix 是一款融合人工智能、语音控制与先进机器人技术的网球训练设备,可作为响应灵敏的智能训练伙伴。
其采用双重视觉 AI 系统,可实时追踪球员位置与网球轨迹,自主移动至最佳击球点,从而模拟更接近真实比赛的对拉场景。球员可通过自然语音指挥设备在训练过程中直接调整发球方式、模式或难度。
Tenniix 还能够基于大量击球数据进行持续学习,对球员技术水平进行评估,并据此提供逐步进阶、贴近实战的个性化训练方案;其目标是在不同水平阶段,为球员提供与自身能力相匹配的训练体验。
在功能设计上,Tenniix 支持超过 1000 种专业训练,并可根据球员水平动态匹配。设备配备可移动底座与混合追踪系统,支持全场范围内的真实训练。Tenniix 通过实时数据反馈,为球员提供可参考的表现指标,同时采用模块化设计,使用户能够从入门阶段逐步升级至更高阶训练,循序渐进地提升战术能力。
在核心技术方面,Tenniix 采用双重定位机制,将球员视觉追踪与球体追踪相结合,实现厘米级精度的数据捕捉。该系统可记录每一次落点与移动轨迹,从而实现更具响应性的互动,模拟真实比赛环境下的对抗节奏。
在销售方面,Tenniix AI 网球机器人已通过官方渠道发售,基础版起售价为 699 美元(现汇率约合 4894 元人民币),Pro 版为 999 美元(现汇率约合 6994 元人民币),Ultra 版为 1599 美元(现汇率约合 11194 元人民币)。该产品面向全球市场销售。
(@IT 之家、@极客公园)
3、Hyper AI 发布 Audio Glasses:支持端侧录音转写与 AI 摘要,扩展 Capture 多模态版本

Tracup 旗下品牌「Hyper AI」推出 Audio Glasses 智能音频眼镜,采用「录音优先」的端侧 AI 策略。该设备通过集成高保真麦克风与端侧算法,实现会议、通话及日常对话的自动化转写、翻译与智能摘要生成,旨在替代传统的手动笔记流程。
-
端侧自动化交互方案: 硬件采用「展开即开机」逻辑,通过长按镜腿手势触发录音。设备定位为独立运行的端侧录音协处理器,无需依赖手机实时操作即可完成音频捕获。
-
多模态数据同步: 除基础音频版外,同步公开的 Capture 版本支持照片与视频拍摄,并能将音频内容与视觉背景进行时间轴对齐,实现多模态记录的同步索引。
-
AI 转写与摘要流水线: 支持实时转写与后期处理两种模式。通过配套 App,利用 LLM 对捕获的原始音频进行多语言翻译及结构化摘要提取,并支持全文本搜索。
-
声学降噪与隐私设计: 硬件集成了高灵敏度麦克风阵列与 AI 降噪算法以提升噪声环境下的采样准确率;设有物理录音指示灯,确保录音动作对周边透明。
目前已在 Kickstarter 开启众筹。全系列产品(包括 Audio、Capture 及 Sports 款)计划在 CES 2026 展出。
(@USA TODAY)
4、Pickle Inc. 开启「Pickle 1」智能眼镜预订:宣称集成四摄阵列与主动式 AI 智能体,硬件可行性遭质疑
Pickle Inc. 宣布推出 AI 驱动的 AR 智能眼镜「Pickle 1」,旨在通过集成传感器与人工智能实现环境感知与行为预测。由于其宣称的硬件规格与极简形态存在物理特性上的显著矛盾,该产品目前正面临行业专家的真实性质疑。
-
主动式 AI 智能体集成:利用内置摄像头、麦克风及传感器阵列采集数据,宣称具备「记忆」与「预测」能力,可根据用户生活习惯实时推送信息叠加与交互建议。
-
高集成度硬件规格争议:官方声称在集成 4 颗摄像头、计算单元及电池的情况下,整机重量低于 Xreal 等行业领先品牌的同类无电池型号(Xreal One),硬件可行性遭技术圈质疑。
-
AR 显示交互:预热视频展示了类似「钢铁侠」Jarvis 的高精度、动态增强现实界面,宣称其显示技术领先于目前 Meta 和 Xreal 的量产方案。
已开启预订(押金 200 美元),预计 2026 年 Q2 发货。
(@Mashable SEA)
03有态度的观点
1、黄仁勋对谈联想董事长,将联合发布「革命性服务器」
1 月 3 日,联想集团公布了一段该公司董事长杨元庆与英伟达首席执行官黄仁勋对谈的视频。两位全球科技巨头掌舵人对 AI 未来演进趋势做出了预判,并首次披露了两家企业的合作规模。
黄仁勋与杨元庆认为下一阶段人工智能发展将会展现出两大明显趋势:其一是企业级 AI 将成为核心战场,混合式 AI 是关键突破点;其二是 AI 将全面渗透至实体经济各领域,带来巨大的市场机遇。
黄仁勋认为,人工智能正在从「生成式 AI」向「代理式 AI」演进,实现了推理能力和解决问题能力的双重突破,这为 AI 落地应用带来了更多可能性。下一阶段的核心趋势将聚焦企业级市场,具体表现为公有云模型与企业定制化开源模型的深度融合。
值得一提的是,这与联想集团正在推进的混合式 AI 战略一致。
黄仁勋对联想集团的战略方向充分认可,他认为混合式 AI 并非简单的技术叠加,而是需要强大的企业级服务器作为硬件支撑,而这正是联想的优势所在。
黄仁勋预判,混合式企业智能将融合应用到全球产业的各行各业中——高性能计算机、人工智能云、AI 工厂、工业制造、物流机器人等实体产业场景,联想与英伟达将在携手覆盖上述所有场景。
二人在谈话中披露,英伟达正在与联想集团联合打造基于 RTX Pro 的联想企业级 AI 系统,英伟达将为这一项目提供这家公司技术最为先进的芯片。
黄仁勋称「这是一款革命性的服务器,已经迫不及待要推出这一产品并向企业级市场规模化推广。」
(@APPSO)


阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

作者提示:个人观点,仅供参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号