面向对象第一单元博客作业
第一单元博客作业
迭代分析
在三次作业中,总体架构保持基本不变,分为读入、拆括号、化简三部分。
- 读入部分:在三次作业中均采用递归下降法,易于拓展。
- 拆括号部分:在每次作业中有所不同。
- 化简:第一次作业采用一个版本,二三次作业重构后采用另一个版本。
第一次作业
第一次作业的表达式架构经过了多次重构,最终确定了以下架构。
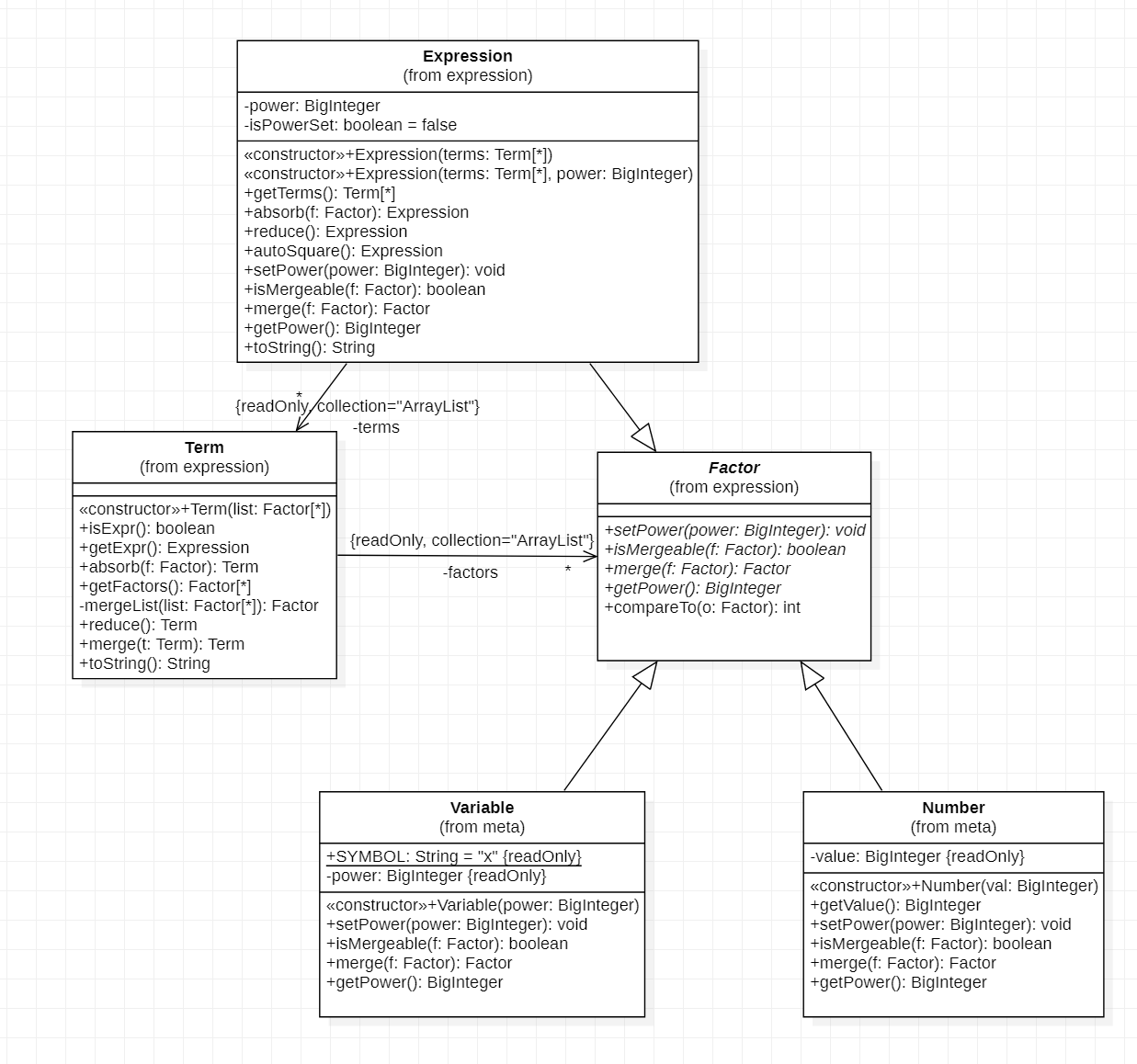
基本设计
整体的设计首先参考了第一次训练项目的结构,将因子抽象出来。
首先对因子进行抽象,设计时考虑到因子的指数,最初的设计是在抽象类中增加了成员,但因为private属性无法被子类访问,随后改为,在Factor抽象类留出了getPower()的方法,随后考虑到因子合并,留出了merge()的化简方法。对项的合并采用单独的工具类Reducer。
此处在后续应用时的抽象效果并不是很好,并没有达到上层统一调用抽象方法达到对具体因子的统一化简,设计还有所欠缺。
在第一次作业的构造中,遇到了可变对象被多引用的现象,导致了在化简中出现了错误,后重构设计所有类为不可变类。但由于时间比较仓促,以及读入阶段和构造函数的设计还比较粗糙,导致需要在构造函数外留出初始化指数的方法(后续作业版本重构了读入解决了这个问题)。
在第一次作业的拆括号与化简中,采用递归的拆括号同时化简,实现了对无限嵌套括号的支持。在此后两次作业的化简中也基本沿用本次作业的方法。
在此处对自己架构中的一些定义进行解释:
- 最简表达式 = 表达式中仅含有最简因子项,且任意两项不能合并。
- 最简项 = 最简表达式项 | 最简因子项
- 最简表达式项 = 项中仅含有一个表达式因子,且该表达式因子为最简表达式
- 最简因子项 = 项中不含表达式因子,且该项中任意两个因子都不可以实现合并
- 最简表达式因子 = 次数为
1,且该因子对应的表达式为最简表达式。
基本的化简流程为:
-
调用表达式的化简函数:该函数对表达式中的每一项进行化简,得到最简项,若为最简表达式项则提出该项中最简表达式因子中的项到本层。经过遍历后,保证本层所有项均为最简因子项(存在同类项)。最后调用
Reducer类合并同类项,返回最简表达式。 -
调用项的化简函数:首先按
Factor的实际类型(如Variable,Number等)进行分组,随后对每一组的元素进行合并。本次作业中,合并后的每一类仅有一个因子元素。若合并后的因子元素中含有表达式因子(合并过程保证了此处的表达式因子为最简表达式因子),则将非表达式因子乘入该表达式,后调用表达式的化简函数,返回最简表达式项。否则返回最简因子项。 -
调用
Reducer类合并同类项:在本次作业中,存在合并最优解,因此采用了系数、指数二元组进行合并。 -
递归的调用以上函数,实现对不限层数括号嵌套的化简和合并。
程序度量
程序规模
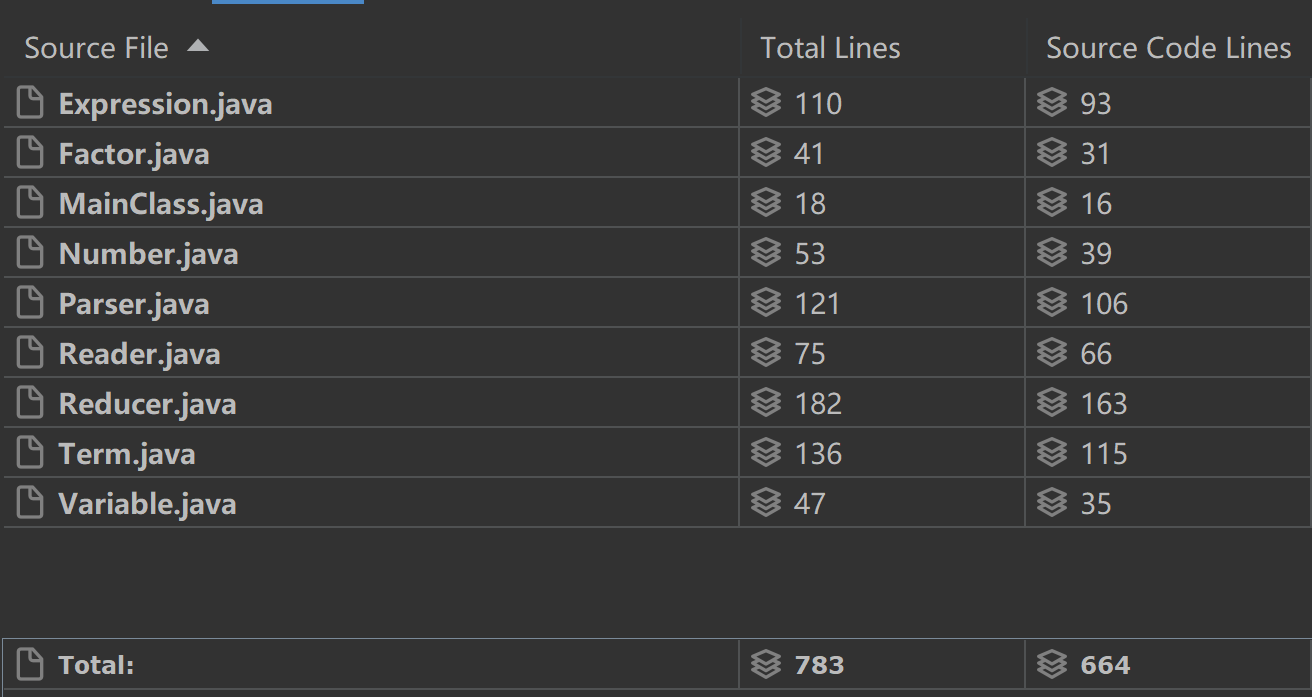
行数比较多可能是项化简的方法需要根据因子类数而更改,是本次作业设计的一个缺点。
类复杂度
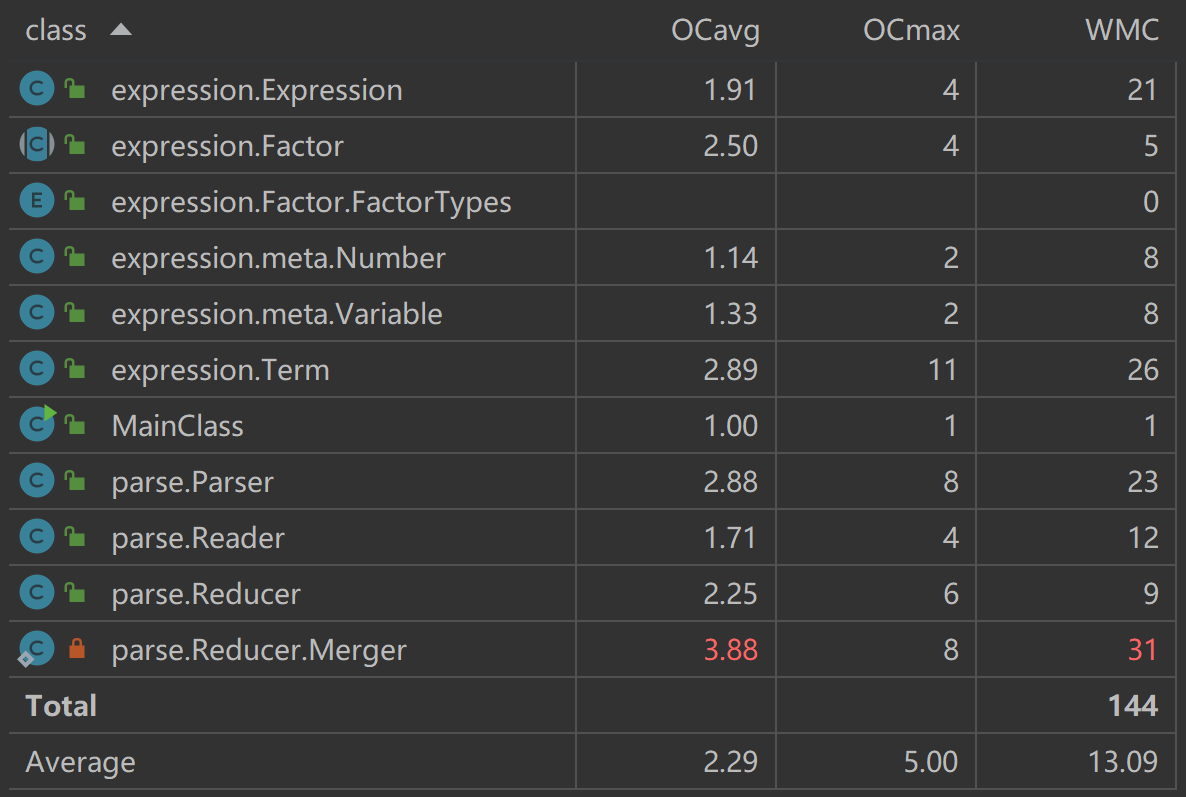
总体复杂度不是很高,复杂度较高的
Merger类是工具类Reducer用于合并同类项及优化输出功能的内部私有类(本次作业为系数与指数的二元组)。
测试
第一次作业的难度适中,经过本地随机数据测试后,自己在强测和互测中没有出现bug。在互测中,发现了他人的2个化简bug,bug原因均为采用了正则表达式无视语义进行优化输出。
第二次作业
第二次作业的结构基本上为第一单元的最终结构。
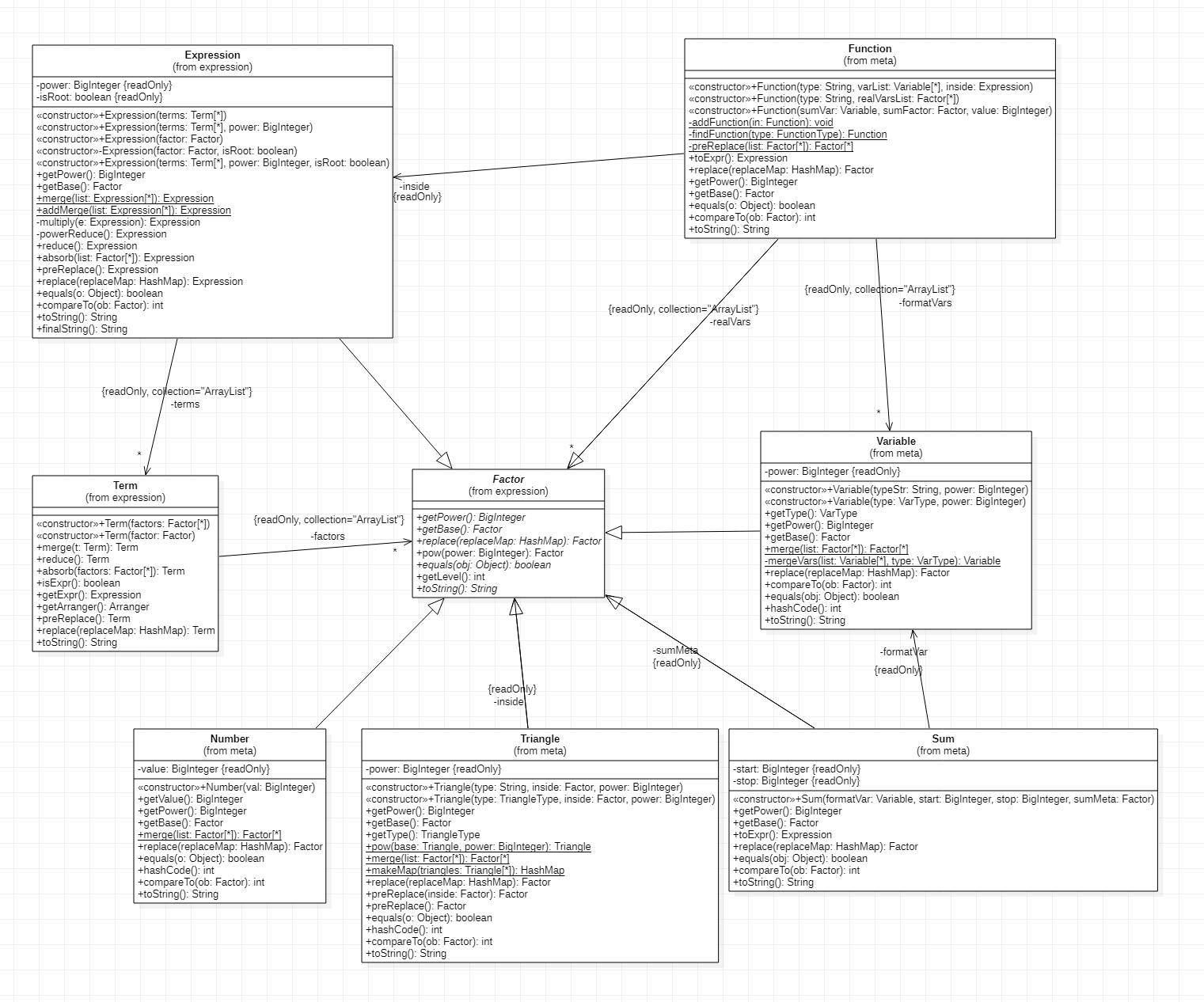
设计迭代
整体设计基本沿用第一次作业的层次设计,但进行了一定重构。
首先改变了Factor类的抽象方法,同时解决了因子的构造问题,真正实现了因子的不可变性。在Parser中也对因子的解析进行了解耦,实现每一类因子有单独的解析函数。
本次作业由于加入了自定义函数和求和函数,因此不能够沿用第一次作业的工作结构。因此设计了新的递归方法来完成对自定义函数和求和函数的预处理,从而实现预处理后可以沿用第一次作业的化简和拆括号方法。
对于新加入的预处理方法,大致的流程为:
- 表达式预处理:对表达式中的所有项进行预处理,预处理后返回的表达式保证内部没有任何求和函数和自定义函数。
- 项预处理:对项中的所有因子进行预处理,预处理后返回的项保证内部没有任何求和函数和自定义函数。
- 普通类型因子(常数、变量)预处理:返回因子本身。
- 表达式因子预处理:同表达式预处理。
- 自定义函数预处理:先对函数表达式进行预处理(同表达式预处理),然后对表达式进行代入。
- 求和函数预处理:先将求和函数转化为若干个自定义函数的和,在使用自定义函数的预处理方法。
- 三角函数预处理:对三角函数内部的因子进行预处理。
代入操作会携带一个HashMap<Variable, Factor>,存储一个变量因子到因子的映射。代入的大致流程为:
- 表达式代入:对表达式中所有项进行代入,代入后返回的表达式为替换过形参的表达式。
- 项代入:对项中的所有因子进行代入。
- 常数因子代入:返回自身。
- 变量因子代入:若变量因子类型为形参(在
HashMap的keyset中)则返回替换后的因子。若变量因子为0次返回常数因子1,若变量因子为1次返回实参因子,若变量因子为更高次幂,使用一个表达式因子用来体现原变量的次数,表达式因子内仅有一项一个因子为实参因子。 - 三角函数因子代入:对三角函数因子内的因子进行代入。
- 函数因子(自定义/求和)代入(不合法):由于代入方法是对预处理后的自定义函数表达式进行代入,表达式中应不含函数。
化简和拆括号方法基本沿用第一次作业,拓展了三角函数因子的合并(实现Factor类的equals(),使得对内部因子相同的三角函数因子进行因子合并)
对于合并同类项,本次作业进行重构,加入了Arranger类,进行基于因子equals()的合并同类项。Arranger类的结构为项系数BigInteger,项变量组HashMap<Factor, BigInteger>记录了项中变量因子的Base(基本项如x,sin(..)代表可合并为幂函数的因子的底数)和Power次数。在合并中使用HashMap<HashMap<>, BigInteger>记录项和项的系数进行合并。
在合并同类项后进行了一些优化:
- 基于
sin(x)**2 + cos(x)**2 = 1的优化,两项优化为另一项。 - 优化
sin(-x) = -sin(x),cos(-x) = cos(x)。 - 优化了
sin(0) = 0,cos(0) = 1。
由于精力和能力有限,没有做其他优化。当然在上述的优化中有一些问题例如优化后的式子还可以继续化简等,在强测中也发现了0*x没有被优化掉、优化后的式子又可以进行合并同类项的问题,导致强测的性能成绩不是很理想。
程序度量
程序规模
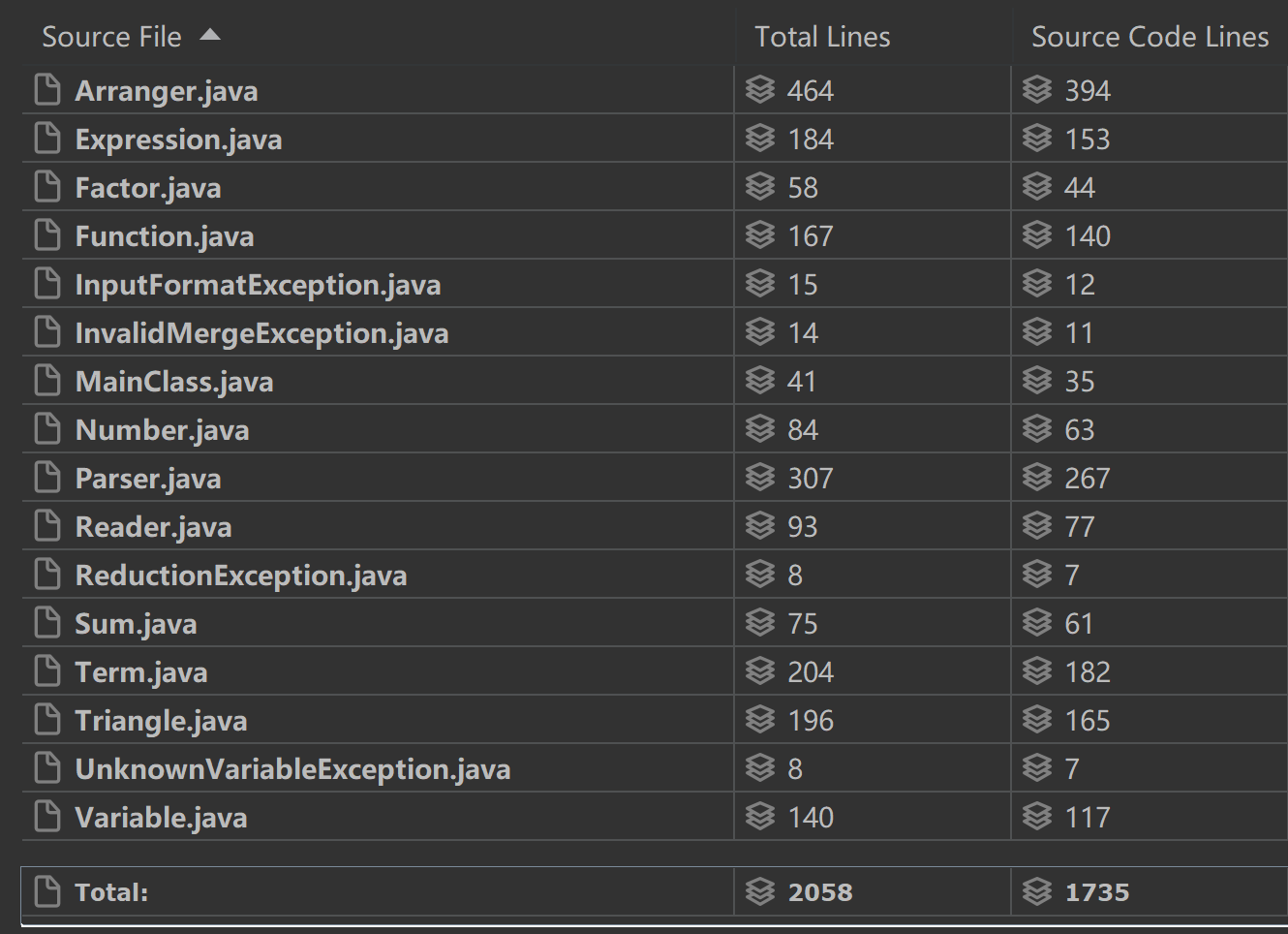
由于优化和重构,导致行数较多。
类复杂度
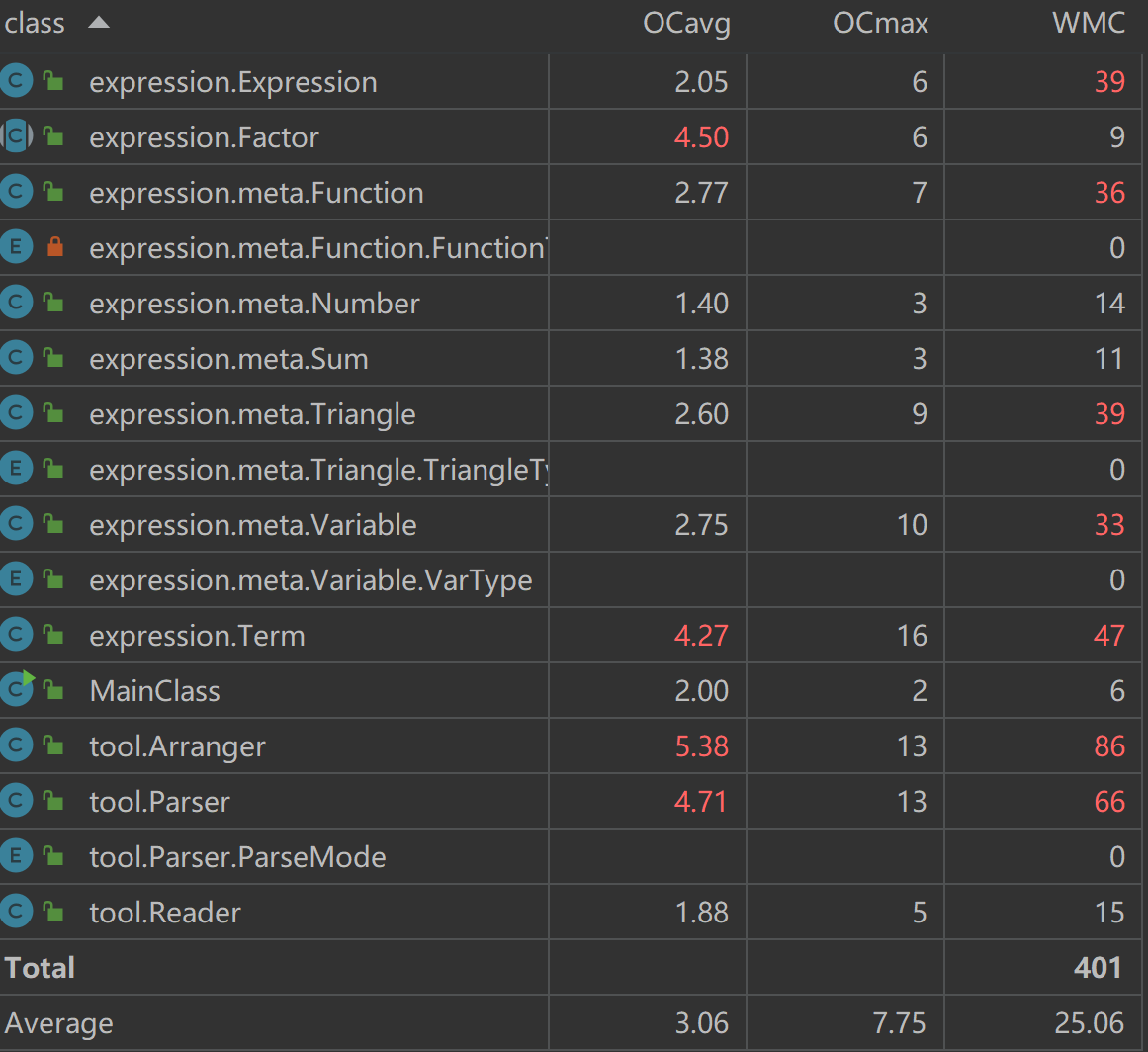
猜想是可能由于递归较多导致了复杂度较高。
测试
经过本地随机数据测试和同学互相测试后,自己在强测和互测中没有出现bug。在互测中,发现了他人的1个优化bug和1个解析bug,bug原因为无法解析带次数的三角因子和sin(-x)**2优化后的符号错误。
第三次作业
第三次作业由于离散作业堆积,没有太多时间进行,结构同第二次作业。懒
设计迭代
第三次作业的设计去掉了第二次作业的优化2、3(不适配新的三角嵌套),其它部分与第二次相同,没有进行修改。
修复了第二次作业中优化后仍然能合并但没有合并的bug。
程序度量
程序规模
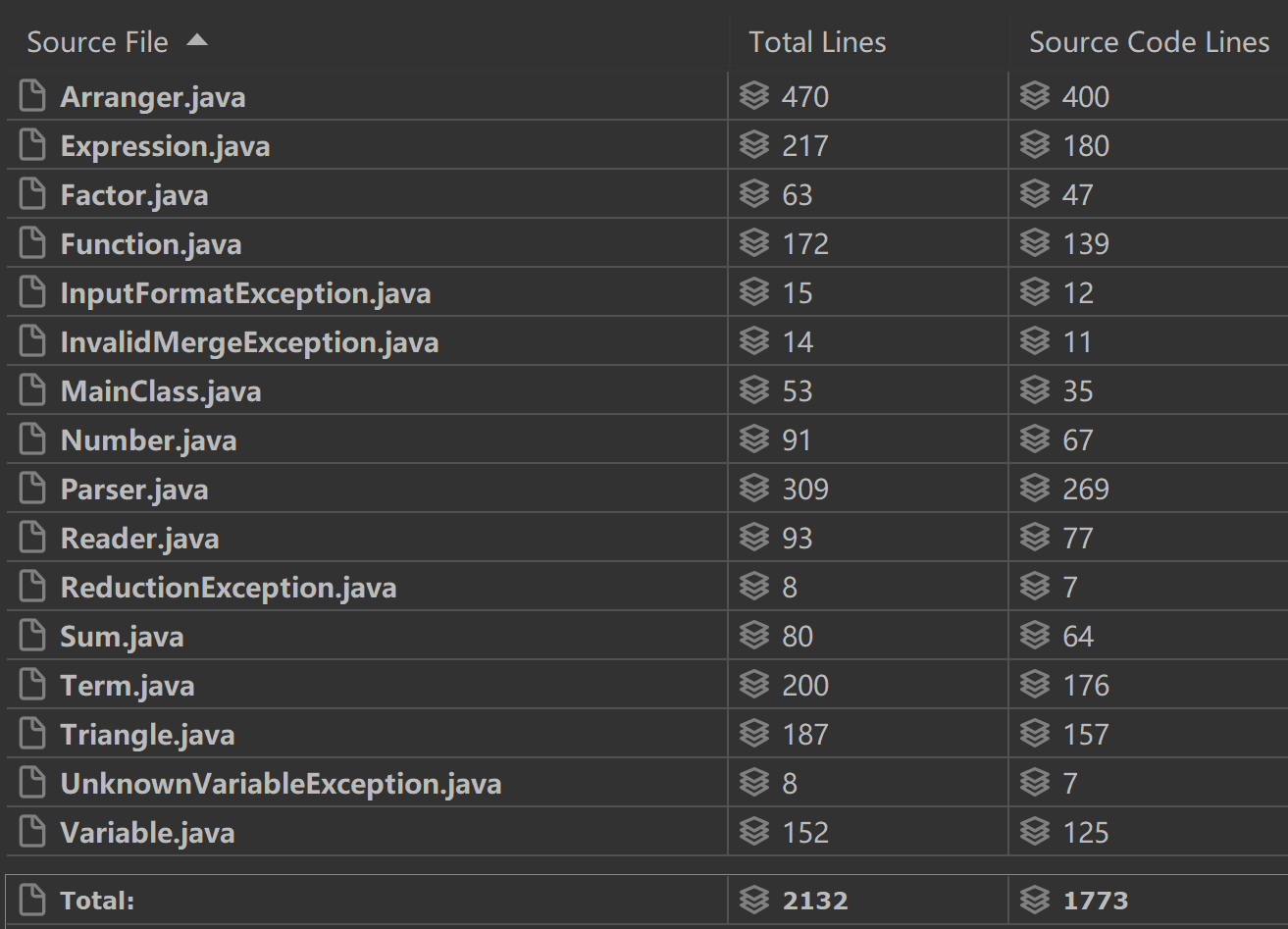
类复杂度
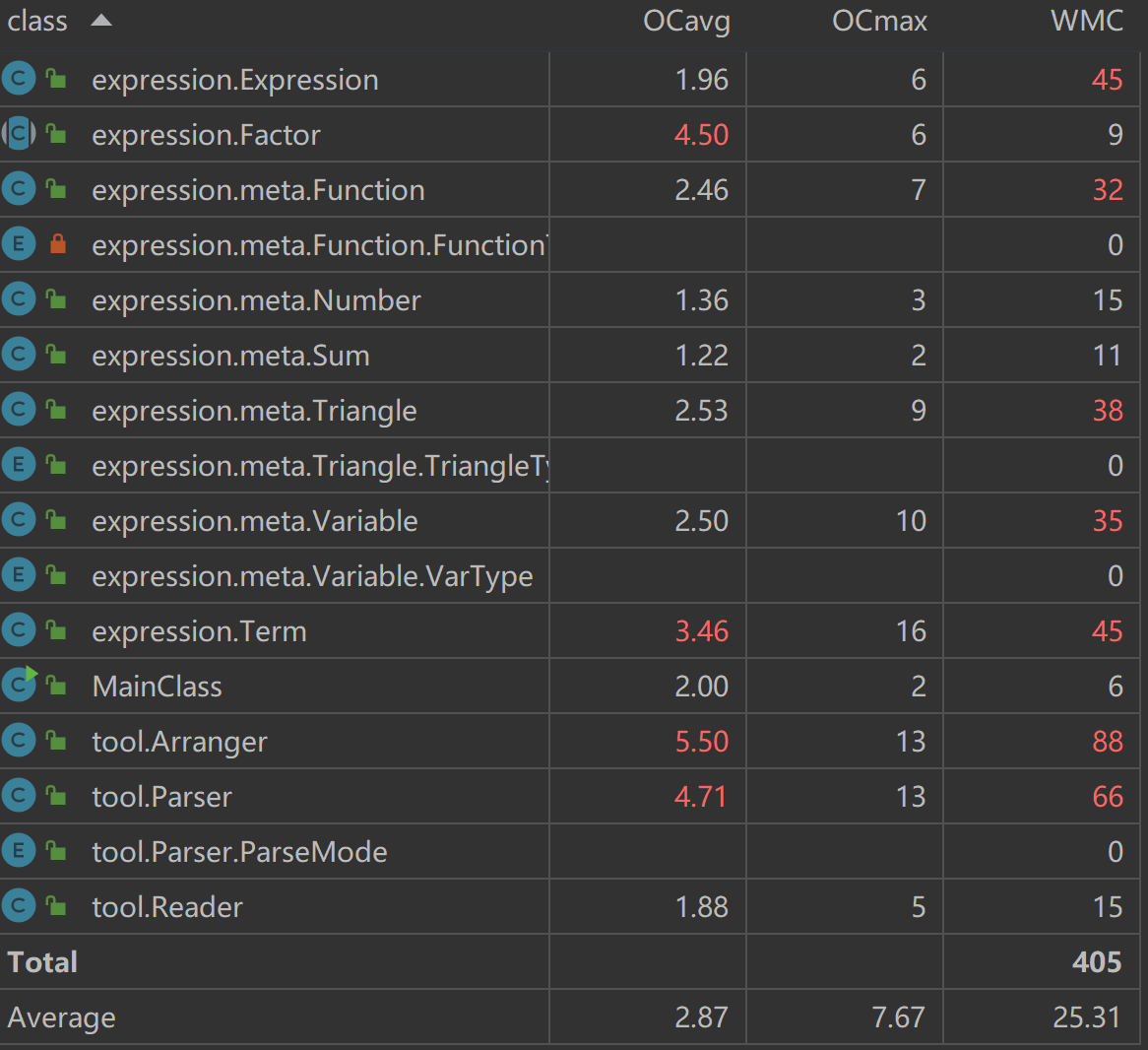
测试
经过本地随机数据测试和同学互相测试后,自己在强测和互测中没有出现bug,由于没有优化,基本仅得到了正确性的分数。在互测中,发现了他人bug如下:
- 求和函数不支持大整数。
- 求和函数的因子解析不支持多层嵌套表达式因子。
- 函数调用不支持带符号的次数。
心得体会
自动化测试与互测
本单元的互测基本是拿自己的随机数据对所有人进行自动化测试,没有很仔细的去阅读他人代码,如果后续单元有时间还是应该多看他人代码。争取不偷懒
数据生成

本单元的数据生成器完全根据形式化表述进行生成,同时根据官方声明中的cost进行限制。实际测试中并未限制cost,出现的问题通过人工缩减样例以发现bug并提交hack用例。
自动化测试
自动化测试采用多用户同时测试,在开始测试时生成用户对象的列表,在测试中可以选择对拍模式或sympy标准对比模式,同时记录每个用户的错误样例列表、性能值、或运行时异常。最终通过输出的评测记录内容查看结果。
其它
本单元的作业使我熟悉了各种容器的使用,初步体验了迭代开发中重构的“乐趣”。
还有十分重要的一点,先设计再写代码!先设计再写代码!先设计再写代码!否则会白费许多精力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号