

LangGraph & MCP - 使用LangGraph实现多智能体架构(七)
在 LangChain 体系中,LangChain 主要集成了和大语言模型交互的能力,而 LangGraph 主要实现了复杂的流程调度。将这两个能力结合起来,就可以实现一个复杂的多智能体。
一、多智能体典型的组装方式
https://langchain-ai.github.io/langgraph/concepts/multi_agent/
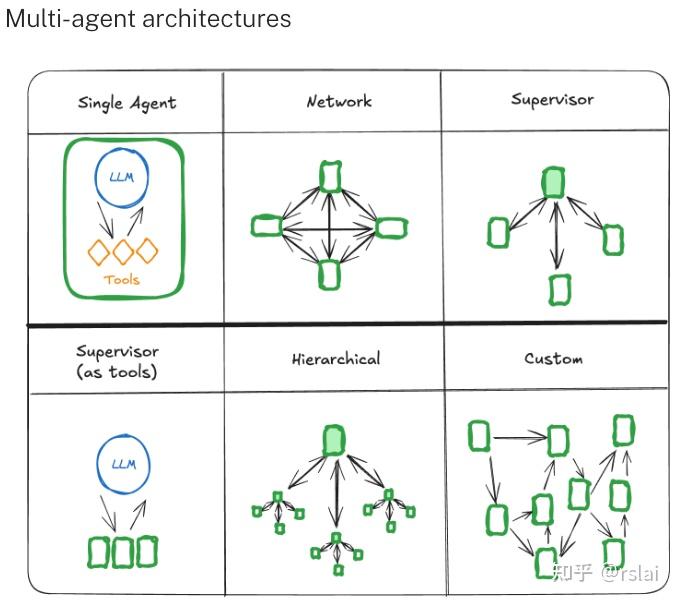
二、实现一个简单的多智能体
- 首先,通过一个 SuperVisor 节点,对用户的输入进行分类,然后根据分类结果,选择不同的 Agent 节点进行处理;
- 接下来,每个 Agent 节点,都可以使用不同的工具进行处理,最后将处理结果汇总,再返回给 SuperVisor 节点;
- 最后,SuperVisor 节点再将结果返回给用户。
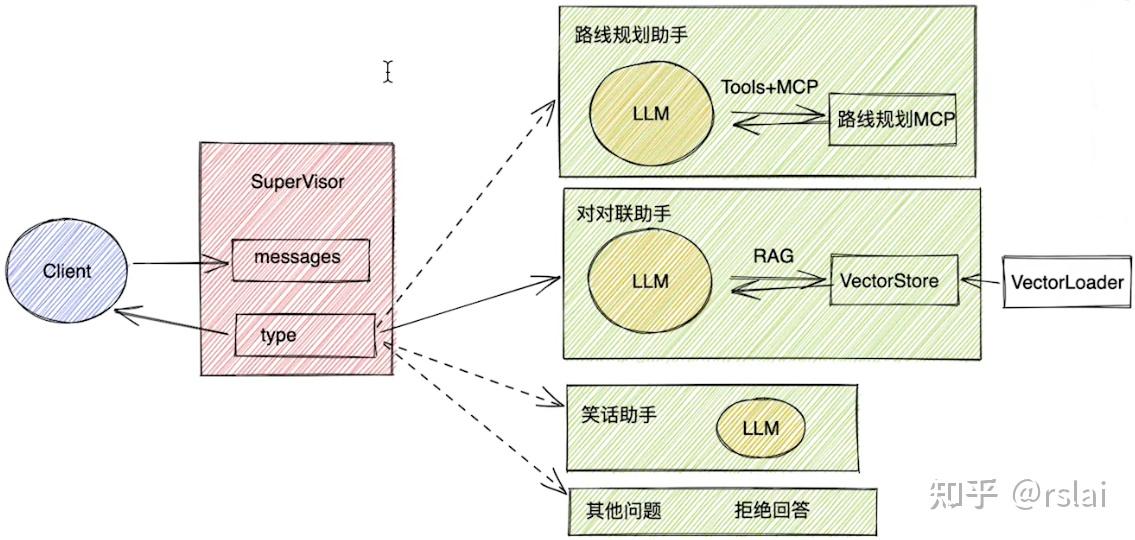
三、完成多智能体交互(不包含智能体中具体功能)
1、新建一个目录 multi_agent
2、创建文件 director.py ,并添加如下代码:
import os
from dotenv import load_dotenv
from operator import add
from tkinter import END
from typing import Annotated, TypedDict
from IPython.display import Image, display
from langchain_core.messages import AnyMessage
from langchain.schema import HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.config import get_stream_writer
from langgraph.graph import StateGraph
from langgraph.constants import START, END
from langchain_openai import ChatOpenAI
load_dotenv()
api_key = os.getenv("API_KEY", "")
base_url = os.getenv("BASE_URL", "")
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_key=api_key,
openai_api_base=base_url,
temperature=0.85,
max_tokens=8000
)
nodes = ["supervisor", "travel", "joke", "couplet", "other"]
# 配置状态
class State(TypedDict):
messages: Annotated[list[AnyMessage], add]
type: str
# 监督(仲裁)节点
def supervisor_node(state: State):
print(">>> supervisor_node")
writer = get_stream_writer()
writer({"node": ">>> supervisor_node"})
# 根据用户的问题,对问题进行分类。分类结果保存到 state.type 中
sys_prompt = """你是一个专业的客服助手,负责对用户的问题进行分类,并将任务分给其他的 Agent 执行。
如果用户的问题是和旅游路线规划相关的,那就返回 travel。
如果用户的问题是希望讲一个笑话,那就返回 joke。
如果用户的问题是希望对一个对联,那就返回 couplet。
如果是其他的问题,返回 other。
除了这几个选项外,不要返回任何其他的内容。
"""
prompts = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": state["messages"][0]}
]
# 如果已经有 type 属性,表示问题已经由节点处理完成,就可以直接返回了
if "type" in state:
writer({"supervisor_step": f"已获得 {state['type']} 智能体处理结果"})
return {"type": END}
else:
response = llm.invoke(prompts)
typeRes = response.content
writer({"supervisor_step": f"问题分类结果:{typeRes}"})
if typeRes in nodes:
return {"type": typeRes}
else:
raise ValueError("type is not in (travel, joke, couplet, other)")
return {}
# 旅游路线规划节点
def travel_node(state: State):
print(">>> travel_node")
writer = get_stream_writer()
writer({"node": ">>> travel_node"})
return {"messages": [HumanMessage(content="travel_node")], "type": "travel"}
# 笑话节点
def joke_node(state: State):
print(">>> joke_node")
writer = get_stream_writer()
writer({"node": ">>> joke_node"})
return {"messages": [HumanMessage(content="joke_node")], "type": "joke"}
# 对联节点
def couplet_node(state: State):
print(">>> couplet_node")
writer = get_stream_writer()
writer({"node": ">>> couplet_node"})
return {"messages": [HumanMessage(content="couplet_node")], "type": "couplet"}
# 其他节点
def other_node(state: State):
print(">>> other_node")
writer = get_stream_writer()
writer({"node": ">>> other_node"})
return {"messages": [HumanMessage(content="我暂时无法回答这个问题")], "type": "other"}
# 条件路由
def routing_func(state: State):
if state["type"] == "travel":
return "travel_node"
elif state["type"] == "joke":
return "joke_node"
elif state["type"] == "couplet":
return "couplet_node"
elif state["type"] == END:
return END
else:
return "other_node"
# 构建图
builder = StateGraph(State)
# 添加节点
builder.add_node("supervisor_node", supervisor_node)
builder.add_node("travel_node", travel_node)
builder.add_node("joke_node", joke_node)
builder.add_node("couplet_node", couplet_node)
builder.add_node("other_node", other_node)
# 添加边
builder.add_edge(START, "supervisor_node")
builder.add_conditional_edges("supervisor_node", routing_func, ["travel_node", "joke_node", "couplet_node", "other_node", END])
builder.add_edge("travel_node", "supervisor_node")
builder.add_edge("joke_node", "supervisor_node")
builder.add_edge("couplet_node", "supervisor_node")
builder.add_edge("other_node", "supervisor_node")
# 编译图
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
# 执行任务的测试代码
if __name__ == "__main__":
config = {
"configurable": {
"thread_id": "1"
}
}
# 执行任务 - 旅游路线规划
for event in graph.stream({"messages": ["请帮我规划一条从天安门到颐和园的旅游路线"]}, config, stream_mode="custom"):
print(event)
# # 执行任务 - 笑话
# for event in graph.stream({"messages": ["给我讲一个郭德纲的笑话"]}, config, stream_mode="custom"):
# print(event)
# # 执行任务 - 对联
# for event in graph.stream({"messages": ["请帮我对“你好”进行对联"]}, config, stream_mode="custom"):
# print(event)
# # 执行任务 - 其他
# res = graph.invoke({"messages": ["今天天气如何?"]}, config, stream_mode="values")
# print(res["messages"][-1].content)
# image_data = graph.get_graph().draw_mermaid_png()
# with open("graph.png", "wb") as f:
# f.write(image_data)
# display(Image(image_data))
运行后如下图:
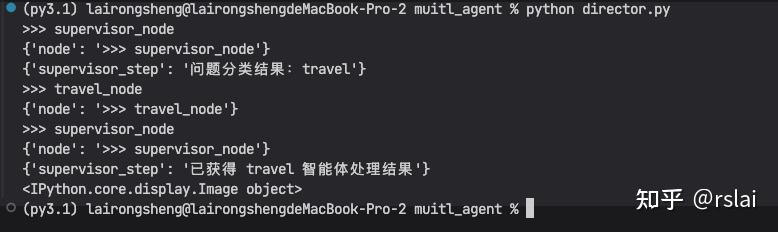
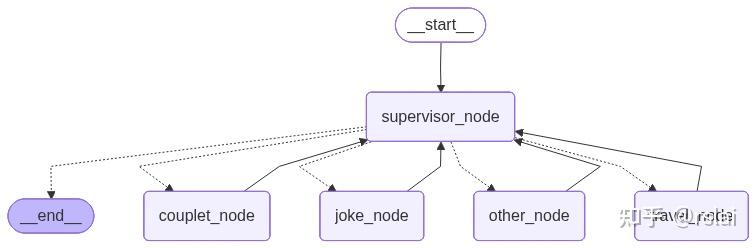
生成 graph 图后如下:
源代码:https://pan.baidu.com/s/1sSkzpoGivYnNOv52CuLpXA?pwd=dzn8 提取码: dzn8
四、实现笑话助手(调用大模型)
在刚才的代码中,找到 joke_node ,替换成如下代码:
# 笑话节点
def joke_node(state: State):
print(">>> joke_node")
writer = get_stream_writer()
writer({"node": ">>> joke_node"})
sys_prompt = "你是一个笑话大师,根据用户的问题,写一个不超过100个字的笑话。"
prompts = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": state["messages"][0]}
]
response = llm.invoke(prompts)
return {"messages": [AIMessage(content=response.content)], "type": "joke"}
第二将 stream_mode="custom" 改为 stream_mode="values"
运行后结果如下:

源代码:https://pan.baidu.com/s/1lSDwCI-S_rn3yo8E4PMWLw?pwd=usix 提取码: usix
五、实现路线规划助手(调用MCP)
在刚才的代码中,找到 travel_node_async ,替换成如下代码:
# 异步的旅游路线规划节点
async def travel_node_async(state: State):
print(">>> travel_node")
writer = get_stream_writer()
writer({"node": ">>> travel_node"})
sys_prompt = "你是一个专业的旅行规划助手,根据用户的问题,生成一个旅游路线规划。请用中文回答,并返回一个不超过100个字的规划。"
prompts = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": state["messages"][0]}
]
client = MultiServerMCPClient(
{
"server": {
"url": "http://127.0.0.1:3002/mcp_atlas", # 服务器地址,需要根据 MCP Server 配置修改
"transport": "streamable_http"
}
}
)
tools = await client.get_tools()
agent = create_react_agent(model=llm, tools=tools)
# 使用异步调用
response = await agent.ainvoke({"messages": prompts})
for message in response["messages"]:
print(message)
writer({"travel_step": response["messages"][-1].content})
return {"messages": [AIMessage(content=response["messages"][-1].content)], "type": "travel"}
# 包装成同步函数供 LangGraph 使用
def travel_node(state: State):
return asyncio.run(travel_node_async(state))
由于 MCP 是异步调用,所有增加了 travel_node_async 方法,然后在 travel_node 中包装成同步函数供 LangGraph 使用。
再找到 执行任务 - 旅游路线规划 将其修改为,如下代码:
# # 执行任务 - 旅游路线规划
# for event in graph.stream({"messages": ["请帮我规划一条从天安门到颐和园的旅游路线"]}, config, stream_mode="custom"):
# print(event)
# 执行任务 - 其他
res = graph.invoke({"messages": ["请帮我规划一条从天安门到颐和园的旅游路线"]}, config, stream_mode="values")
print(res["messages"][-1].content)
使用如下命令启动 MCP server,mcp_server.py 代码在下面网盘中
python mcp_server.py
重新运行 python director.py 后结果如下:
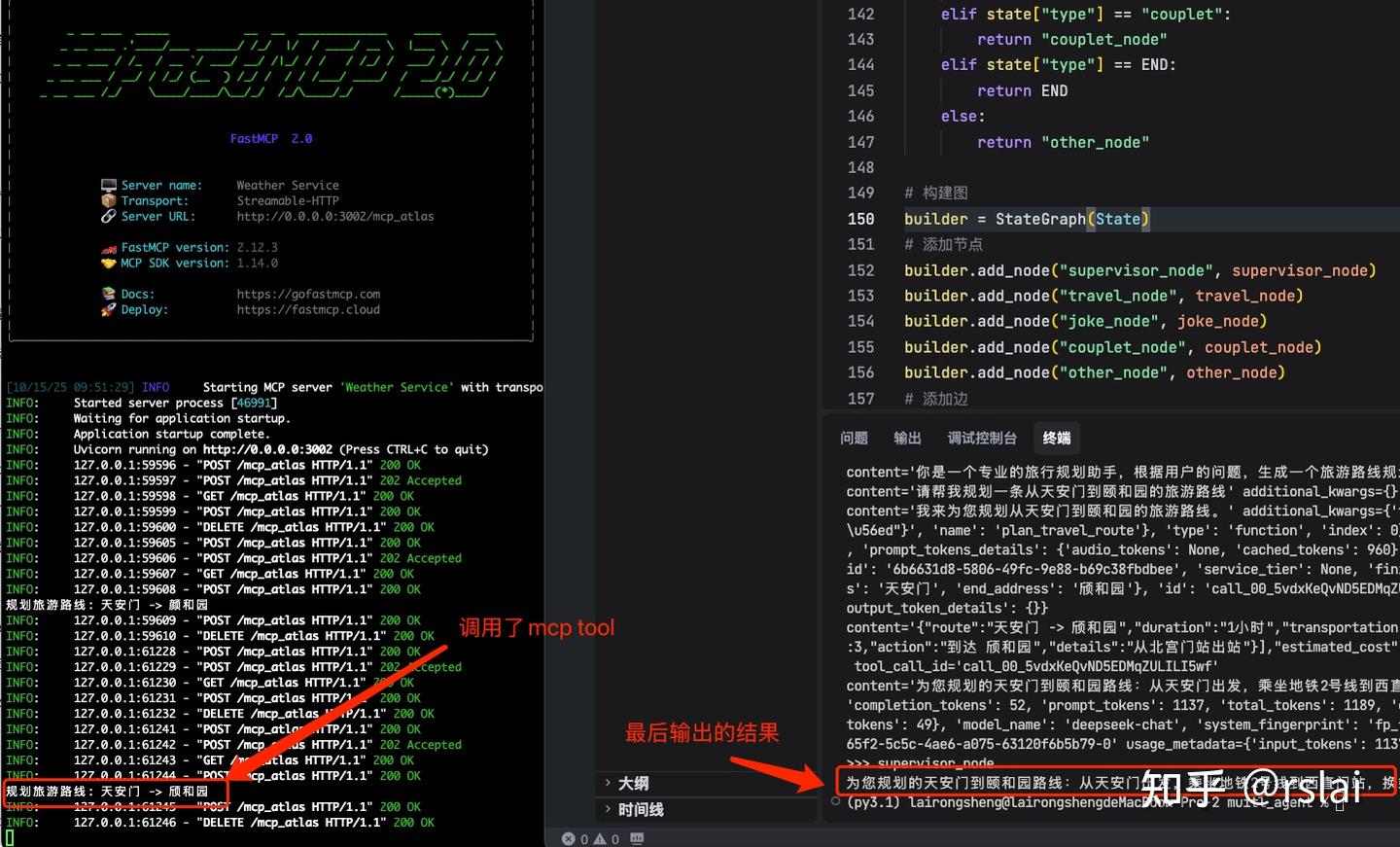
源代码: https://pan.baidu.com/s/1dw5JA5fVbAyj4r3xf4AlgQ?pwd=wy83 提取码: wy83
六、实现对联助手(调用RAG)
RAG 业务逻辑,先去找一些参考资料,将其向量化后保存到向量数据库中。当用户提出问题时,先去向量数据库中找相关的条目,然后将找到的信息一起发给大语言模型,大语言模型参考这些找到的数据再给出相应的答案。
6.1、下载对联数据集
后续要用这个对联数据集来做知识库,后续会将其存入向量数据库。
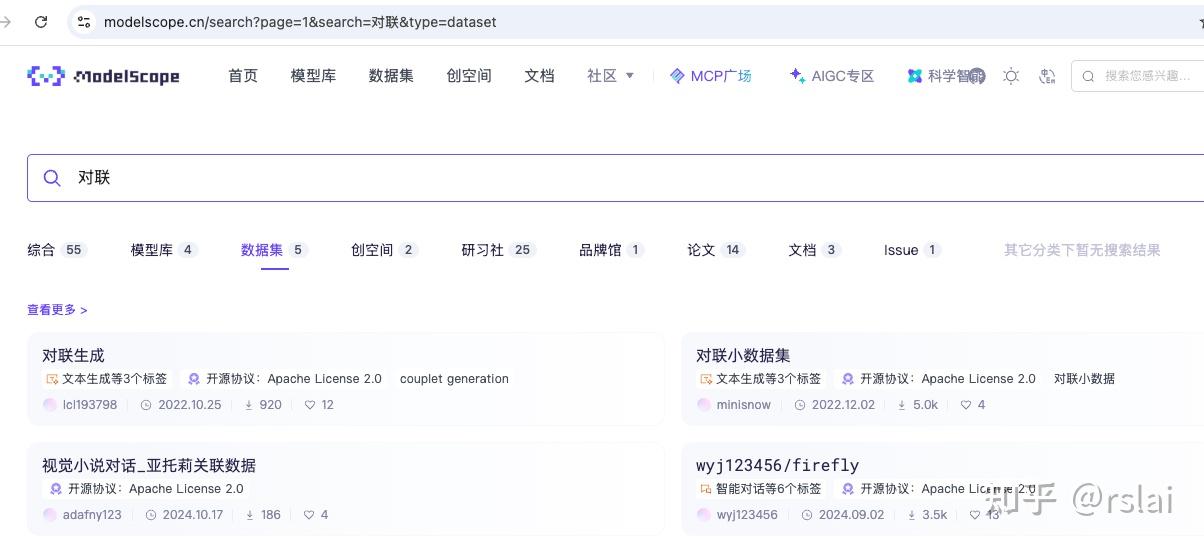
访问 https://modelscope.cn/ 搜索对联,如下图
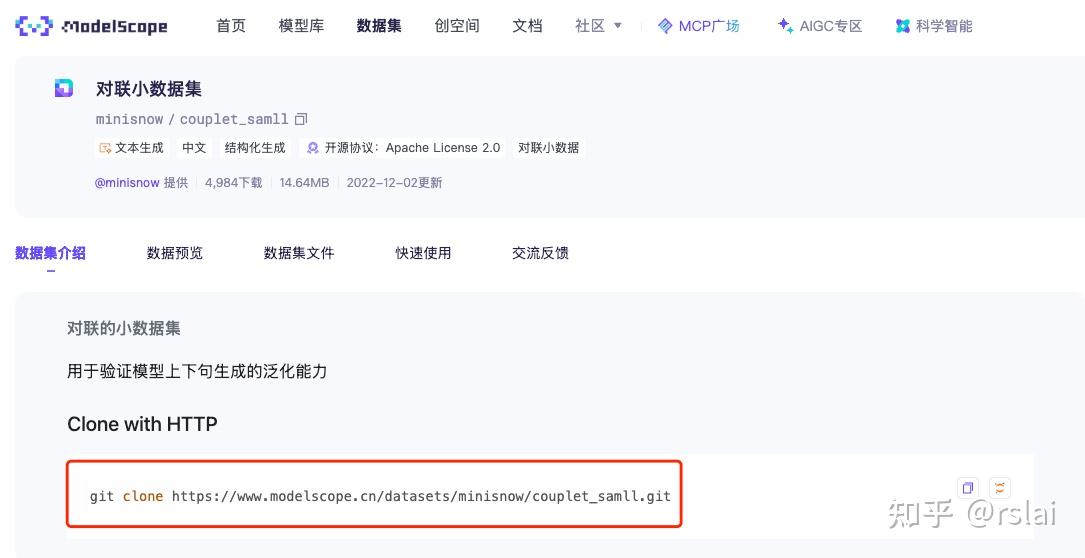
如下图,根据提示下载数据集
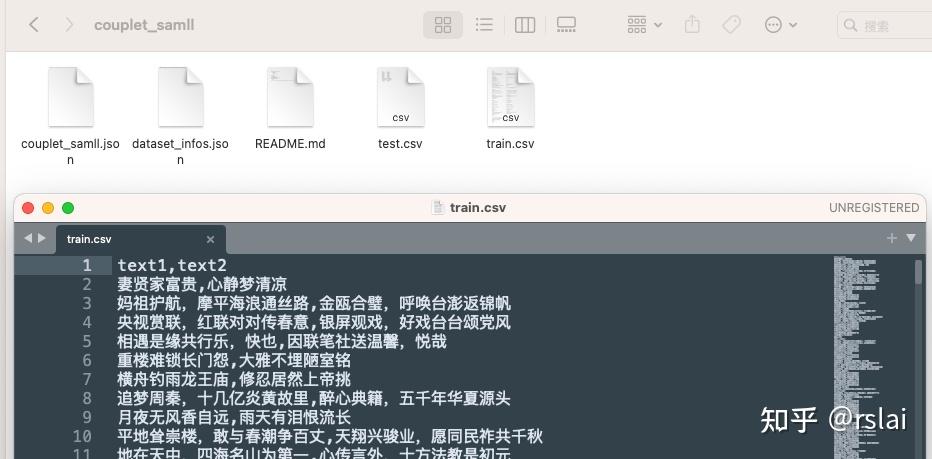
下载成功后,可以打开数据集文件(train.csv)看一下,内容如下。
在代码目录中创建 resource 目录,将刚才看的数据集文件 train.csv 复制到此目录中。
6.2、安装向量数据库
LangGraph 支持很多种向量数据库,这里为了简单安装的是 Redis 向量数据库。
docker 安装命令如下:(注意需要想方法上网)
docker run -p 6397:6397 redis/redis-stack-server:latest
安装成功后可以再安装一个 Redis 图形工具,例如:RDM
6.3、将数据集保存到向量数据库中
在 resource 目录中创建文件 couplet_loader.py ,并添加如下代码:
# 把对联数据保存到 Redis 向量数据库中
import os
import redis
from langchain_community.embeddings import OllamaEmbeddings
# 使用 OllamaEmbeddings
embedding_model = OllamaEmbeddings(
model="bge-m3:latest",
base_url="http://172.31.12.104:11434" # 自定义服务器地址
)
# 保存向量数据库
redis_url = "redis://localhost:6379"
redis_client = redis.from_url(redis_url)
print(redis_client.ping()) # 测试连接 返回 True 表示连接成功
from langchain_redis import RedisConfig, RedisVectorStore
config = RedisConfig(
index_name="couplet",
redis_url=redis_url,
)
vector_store = RedisVectorStore(embeddings=embedding_model, config=config)
# 按行读取 train.csv 文件
lines = []
with open("../resource/train.csv", "r", encoding="utf-8") as file:
for line in file:
print(line)
lines.append(line.strip())
# 把 lines 中的文本添加到向量数据库中
vector_store.add_texts(lines)
运行完成后,显示如下图:
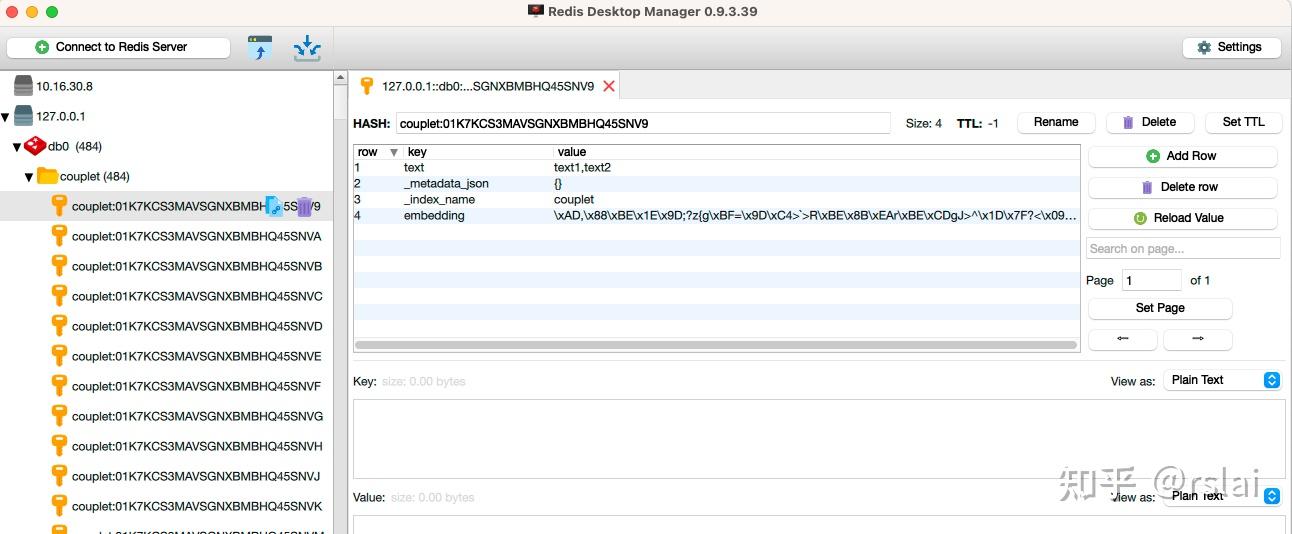
在 RDM 中查看,如下图:(由于这个数据集有14M,所以存入的时间较长多等下)
6.3、修改智能体代码
打开 director.py 文件,找到 couplet_node 替换成如下代码:
# 对联节点
def couplet_node(state: State):
print(">>> couplet_node")
writer = get_stream_writer()
writer({"node": ">>> couplet_node"})
# 用户输入的内容
query = state["messages"][0]
# 使用 OllamaEmbeddings
embedding_model = OllamaEmbeddings(
model="bge-m3:latest",
base_url="http://172.31.12.104:11434" # 自定义服务器地址
)
# 保存向量数据库
redis_url = "redis://localhost:6379"
redis_client = redis.from_url(redis_url)
print(redis_client.ping()) # 测试连接 返回 True 表示连接成功
from langchain_redis import RedisConfig, RedisVectorStore
config = RedisConfig(
index_name="couplet",
redis_url=redis_url,
)
vector_store = RedisVectorStore(embeddings=embedding_model, config=config)
# 从向量库中召回
samples = []
scored_results = vector_store.similarity_search_with_score(query, k=10)
for doc, score in scored_results:
samples.append(doc.page_content)
# 构建提示词
prompt_template = ChatPromptTemplate.from_messages([
("system", f"""
你是一个专业的对联大师,你的任务是根据用户给出的上联设计下联。
回答时,可以参考下面的参考对联。
参考对联:
{samples}
请用中文回答问题。
"""),
("user", "{text}")
])
prompts = prompt_template.invoke({"samples": samples, "text": query})
writer({"couplet_step": prompts})
response = llm.invoke(prompts)
return {"messages": [AIMessage(content=response.content)], "type": "couplet"}
再找到 执行任务 - 对联 替换为如下代码:
# # 执行任务 - 对联
# for event in graph.stream({"messages": ["给我对一个对联,上联是: 金榜题名时"]}, config, stream_mode="custom"):
# print(event)
# # 执行任务 - 对联
res = graph.invoke({"messages": ["给我对一个对联,上联是: 金榜题名时"]}, config, stream_mode="values")
print(res["messages"][-1].content)
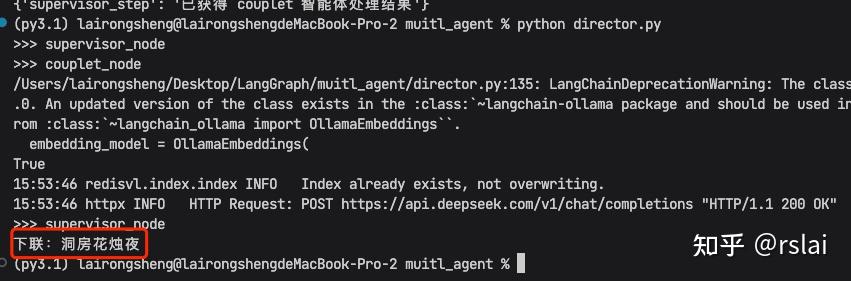
运行代码,如下图:
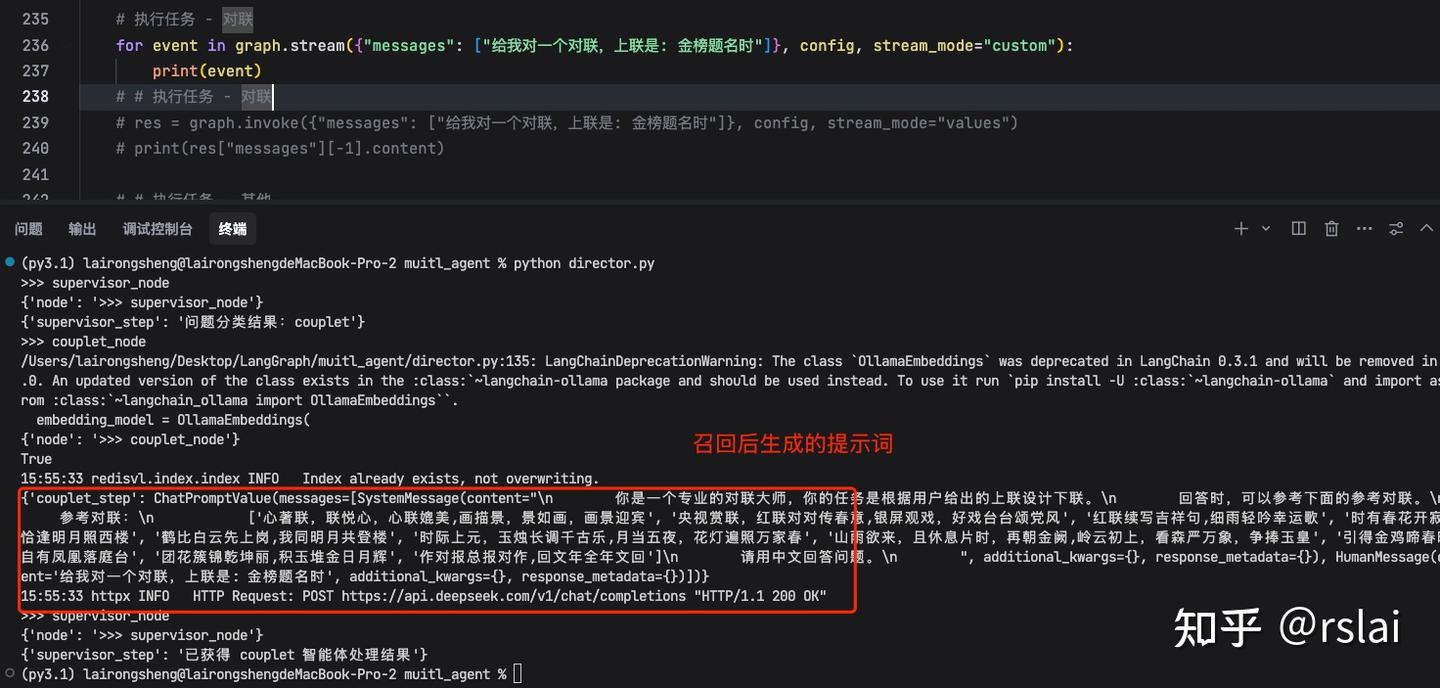
如果想看提示词和调用过程,将上面注释打开再将下面注释后重新运行,如下图:
源代码: https://pan.baidu.com/s/1edjggBDFzYWX9_eUk7R3cw?pwd=hq5b 提取码: hq5b
七、将以上多智能体封装成一个 service
创建 director_service.py 文件,添加如下代码:
import random
from director import graph
config = {
"configurable": {
"thread_id": random.randint(1, 10000)
}
}
# query = "给我讲一个关于郭德纲的笑话"
query = "给我对一个对联,上联是: 金榜题名时"
res = graph.invoke(
{"messages": [query]},
config,
stream_mode="values"
)
print(res["messages"][-1].content)
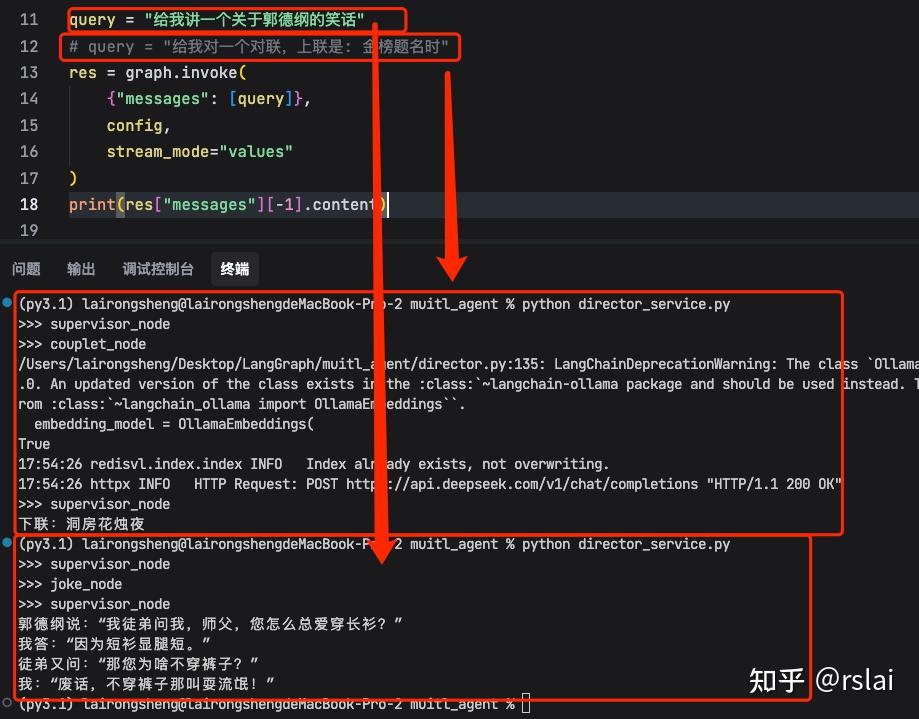
运行后如下图:
源代码:https://pan.baidu.com/s/1igxlJ8-vvS5dp56ZxYsj2g?pwd=6yi3 提取码: 6yi3
八、将以上多智能体封装成一个 web 页面
创建 director_fe.py 文件,添加如下代码:
# grdio 前端
import gradio as gr
import random
from director import graph
def process_input(text):
config = {
"configurable": {
"thread_id": random.randint(1, 10000)
}
}
result = graph.invoke({"messages": [text]}, config, stream_mode="values")
return result["messages"][-1].content
with gr.Blocks() as demo:
gr.Markdown("# LangGraph Multi-Agent")
with gr.Row():
with gr.Column():
gr.Markdown("## 可以问路线规划,对对联,讲笑话,快来试试吧。")
input_text = gr.Textbox(label="问题*", placeholder="请输入你的问题", value="讲一个关于郭德纲的笑话")
btn_start = gr.Button("Start", variant="primary")
with gr.Column():
output_text = gr.Textbox(label="Output")
btn_start.click(fn=process_input, inputs=[input_text], outputs=[output_text])
demo.launch()
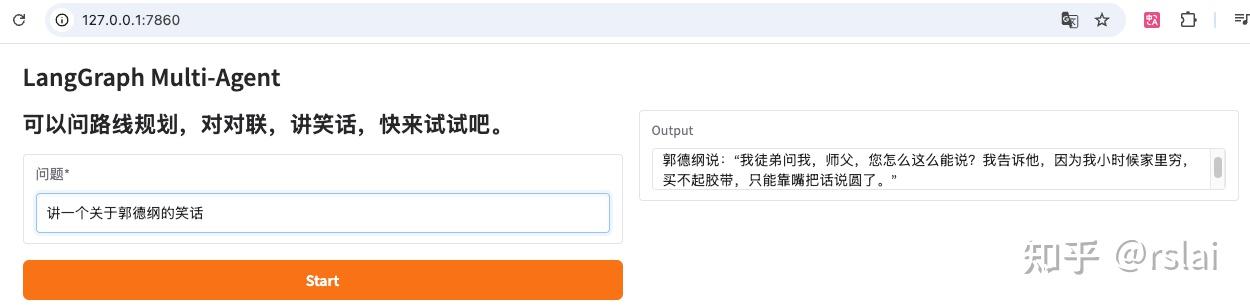
运行成功后,如下图:

浏览器中访问,上图地址。
输入问题后,点击 start 按钮,如下图:
源代码:https://pan.baidu.com/s/1G9ZdxOQbi0rFZN-BYF5vXw?pwd=9xwg 提取码: 9xwg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号