
今天很顺利,第一章节的作业顺利完成,拿到了奖学金,不枉我昨天打印章节练习手写题目啊,今天学习第二章节,二进制的转换,Alex生动的用了古代烽火台的例子来表示,实际上十进制--->二进制,可以先将256 128 64 32 16 8 4 2 1这几个数字写出来,之后对应的十进制数等于这9个数字任意组合相加的和,用到的数字置为1,没有用到数字置为0,即可转换为十进制数;十进制---->二进制则更简单,例如1010111,该数字为1*(2^0)+1*(2^1)+1*(2^2)+1*(2^4)+1*(2^6)=87,熟悉之后可以直接写2^0+2^1+2^2+2^4+2^6即可,因为1乘以任何数字都是该数字本身,没有意义。那么文字是否可以转换为二进制呢,当然也是可以的,文字先转换为十进制,再由十进制转换为二进制。
文字转换为十进制的过程就产生了对应关系表ASCII表。8位二进制表示一个字符,引申出8bit = 1bytes;1KB=1024B;1MB=1024KB;1GB=1024MB;1TB=1024GB。我是这样理解的1个英文字符占用8位即8bit,那么1KB最多能存1024个英文字母。但是我们发现ASCII码表中只有英文单词,所以之后就产生了GB2312表,也称国标码,是对应中文转换为二进制的,但是GB2312收录的汉字不全,且只收录了简体字,所以在1995年发布了GBK1.0,兼容GB2312,能同时表示简体字和繁体字,收入的汉字高达21003个,同时包含中日韩文字中所有的汉字,在2000年的时候又进行了升级,发布GBK18030,对GBK编码进行了扩充,收录了27484个汉字,兼容GBK和GBK2312字符集,这次升级,涵盖了少数民族文字。其实我们在GBK1.0中已经收录了繁体字了,但是台湾同胞可能是等不及了,发布了BIG5编码,支持繁体中文字符,共收录了13053个汉字,1984年实行的。为了解决每个国家不同编码间不互通的问题,ISO标准组织发布了UNICODE编码,即万国码,规定所有的字符和符号最少由16位来表示(2个字节),但是美国,英国等国家说了,我原来存一个英文字符只要一个字节,使用得挺好,现在UNICODE规定所有的字符和符号最少要由2个字节来表示,浪费了存储空间,于是又发布了UTF-8编码,是对UNICODE编码进行压缩和优化,不再使用最少两个字符,而是将所有的字符和符号进行分类,所有的英文仍然只占一个字节。Windows系统中文版默认编码是GBK,Mac OS/Linux 系统默认编码是UTF-8
在Python2中默认ASCII码,在Python3中默认UTF-8,所以在Python2中不支持中文,所有我们要声明编码,声明方式有两种,如下:
#! -*- coding:utf-8 -*-
#!encoding:utf-8
关于数据类型:
继上期的学习后,目前还需要学习的数据类型有,浮点型(float),字节型(byte),数据集(列表,字典,元祖等)
浮点型(float):
字节型(byte):
列表(list):列表是一个数据的集合,可以存放任何的数据类型,可以对集合进行增删改查,且存储的值可以重复,表达形式:L1 = [ ]
创建列表:方法一: L2 = ['a',‘b',‘c’] 方法二:L3 = list(‘c’,‘d’,‘e’)
查询列表:L4 = [‘f’,‘g’,‘h’],如果我想取列表中的值g,该如何操作呢?
应该通过索引取值,索引默认从0开始,取值g的方法如下:print(L4[1])
PS:索引值可以从左往右取,也可以从右往左取,从左往右取时索引值默认从0开始,从右往左取时索引值默认从-1开始
切片:切片是指获取列表中指定的,切片只能从左往右操作,方法如下:
L4【0:3】,取到的值是列表中索引值为0,1,2的值,不包括索引值为3的值,顾头不顾尾
获取索引值的方法:L4.index('f'),需要注意的时如果列表中有值时重复的,那么在我取索引值时,返回的索引值为第一个值的
查询数据在列表中的个数方法:L4.count['f']
在列表中跳着取值方法:L4[:1,2],这样我们就取到了列表中的第一个和最后一个值,其中的2叫步长(Stamp)
列表中的增加值操作:L4.append(5),这时L4=[‘f’,‘g’,‘h’,5],append准确来说意思为追加,默认加在列表的最后一个位置,如果我们想要在列表的指定位置中加入值呢,这时候就引申出了插入的概念
列表中的插入值操作:L4.insert(下标位置,值),插入默认插入到下标位置之前的那个位置
列表中的修改值操作:直接给你需要修改的值进行重新赋值即可,如:L4[2]=4,即将列表中第二个位置的值h修改为了4
列表中的删除值操作:有pop方法,remove方法,del方法
pop方法默认删除列表中的而最后一个值,方法为L4.pop(),并返回删除的值,
remove方法,删除列表中指定的值,方法为L4.remove(列表中的值),即L4.remove(‘h’),把列表中的值h删除
del方法,全局性的删除方法,方法为del L4[索引值],del L4[1],删除列表中索引值为1的元素,即将列表中的值g删除,不需要用变量调用
列表中的循环操作: L4 = [‘f’,‘g’,‘h’],具体如下
for i in L2:
print(i)
值得一说的是除了While循环,还有for循环,语法如下
for i in range(10):
print(i)
其中range(10)实际上就是一个列表,【0,1,2,3,4,5,6,7,8,9,10】,在python3中体现不出来,因为python3做了优化,而在python2中可以很明显的看到
while循环和for循环的区别,while循环可以死循环,for循环是有边界的,不可能死循环
列表中的排序操作: L2 = ['a',‘b',‘c’,‘z',‘s’],说到这里,列表是有序的,为什么是有序的呢,因为列表是按索引排序的,索引本来就有顺序,所以列表也是有序的
列表排序方法的语法如下:L2.sort() ,内部是按照ASCII码表的顺序进行排序的,特殊字符在最前面,其次是大写字母,小写字母
列表中的反转操作的语法如下:L2.reverse()
两个列表中的值的合并操作,语法如下:L2+L1或者是L2.extend(L1)
列表中的清空操作的语法如下:L2.clear()
列表中的复制操作的语法如下:L2.copy()
如果L2=[1,3,5,6,7],L3=L2,那么L3=[1,3,5,6,7],如果将L2中索引值为1的值修改为4,那么会不会影响L3呢
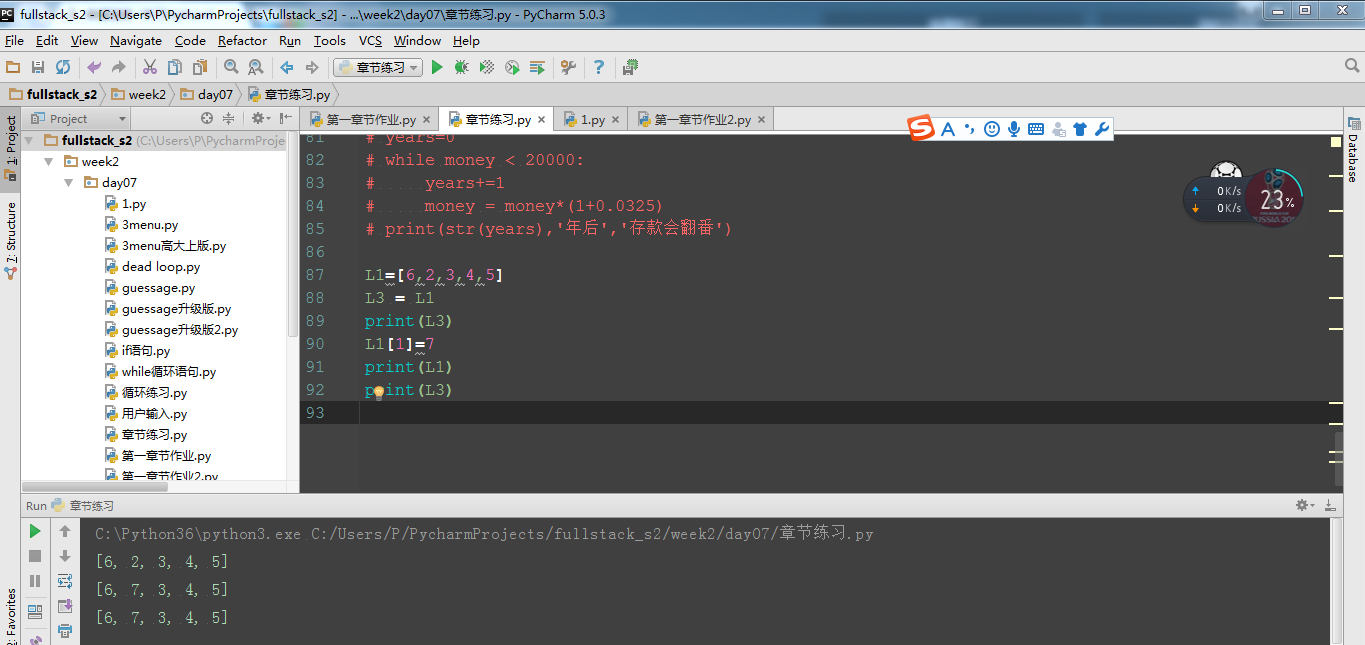
可以清楚的看到L3列表中的值修改了,是会对L4列表造成影响的,所以也说明了L4不是指向L3的值的,而是指向L3的,这一点和变量不同
那么如果使用了copy方法会发生什么变化呢,不妨看一下:
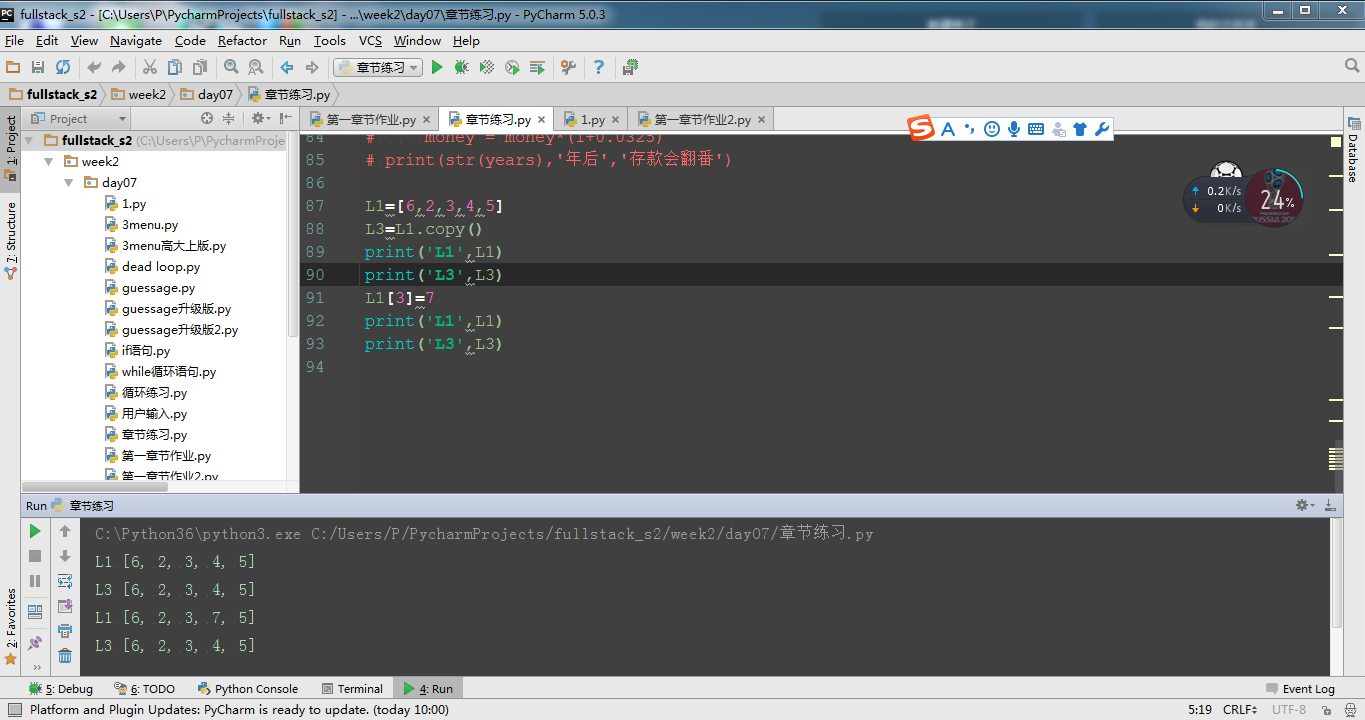
可以清楚的看到,copy之后的L3列表原先为【6,2,3,4,5】,在L1列表中的值发生变化时,L3l列表中的值仍然是【6,2,3,45】,并未受到影响
小知识:enumerate(枚举方法),可以同时打印索引值和元素
查询变量的内存地址:id(变量名)
python中的深浅copy: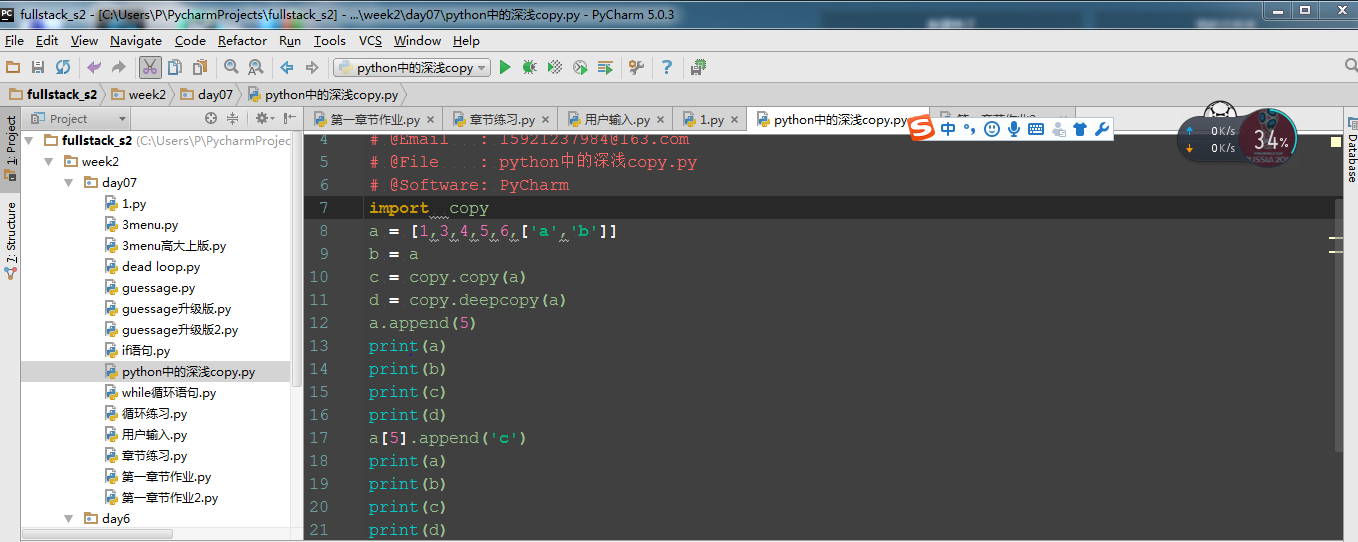
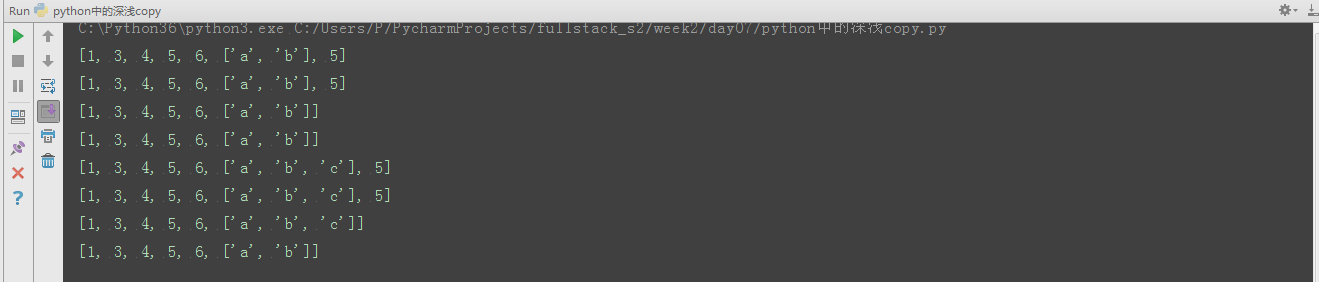
可以从如上两幅图中看到:
1.在列表外层添加元素时, 浅拷贝c不会随原列表a变化而变化;内层list添加元素时,浅拷贝c才会变化。
2.无论原列表a如何变化,深拷贝d都保持不变。
3.赋值对象随着原列表一起变化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号