202108170705 - kafka rebalance再平衡问题
1. 心跳机制
Kafka 的心跳是 Kafka Consumer 和 Broker 之间的健康检查,只有当 Broker Coordinator 正常时,Consumer 才会发送心跳。
Consumer 和 Rebalance 相关的 2 个配置参数:
| 参数 | 字段 |
|---|---|
| session.timeout.ms | MemberMetadata.sessionTimeoutMs |
| max.poll.interval.ms | MemberMetadata.rebalanceTimeoutMs |
| broker 端,sessionTimeoutMs 参数 | |
| broker 处理心跳的逻辑在 GroupCoordinator 类中:如果心跳超期, broker coordinator 会把消费者从 group 中移除,并触发 rebalance。 |
consumer 端:sessionTimeoutMs,rebalanceTimeoutMs 参数
- 如果客户端发现心跳超期,客户端会标记 coordinator 为不可用,并阻塞心跳线程;
- 如果超过了poll 消息的间隔超过了 rebalanceTimeoutMs,则 consumer 告知 broker 主动离开消费组,也会触发rebalance
2. rebalance
rebalance可以说是kafka为人诟病最多的一个点了。
rebalance其实就是一个协议,它规定了如何让消费者组下的所有消费者来分配topic中的每一个分区。
比如一个topic有100个分区,一个消费者组内有20个消费者,在协调者的控制下让组内每一个消费者分配到5个分区,这个分配的过程就是重平衡。
rebalance的触发条件主要有三个:
- 消费者组内成员发生变更,这个变更包括了增加和减少消费者,比如消费者宕机退出消费组
- 主题的分区数发生变更,kafka目前只支持增加分区,当增加的时候就会触发重平衡
- 订阅的主题发生变化,当消费者组使用正则表达式订阅主题,而恰好又新建了对应的主题,就会触发重平衡
3. 触发再平衡的场景
-
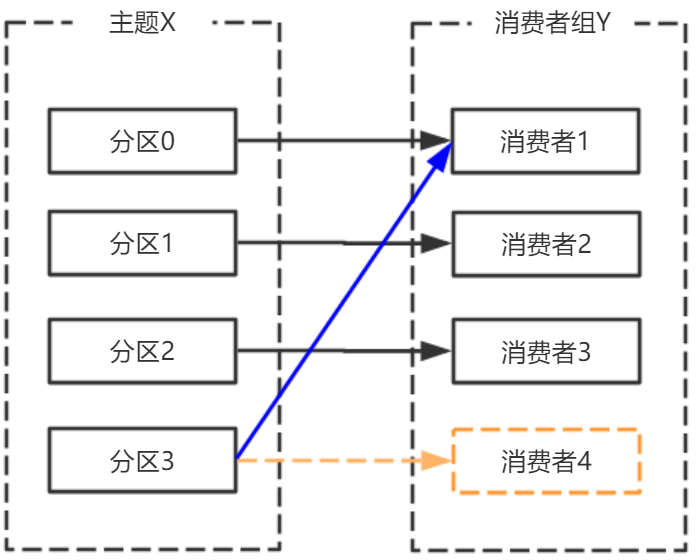
- 心跳机制监测到消费者宕机,退出消费组,触发再平衡,重新分配分区给消费者。
![]()
- 心跳机制监测到消费者宕机,退出消费组,触发再平衡,重新分配分区给消费者。
-
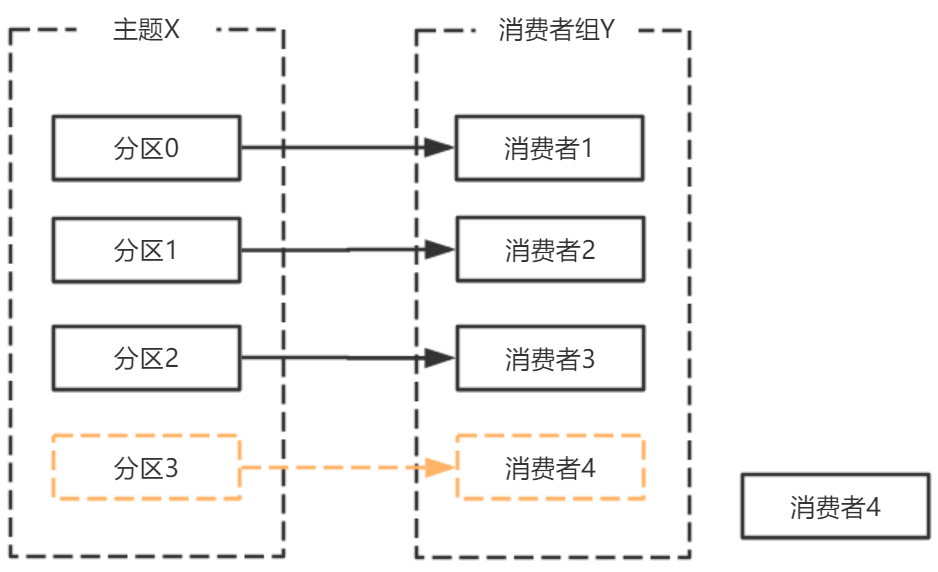
- broker宕机,主题X的分区3宕机,此时分区3没有Leader副本,触发再平衡,消费者4没有对应的主题分区,则消费者4闲置。
![]()
- broker宕机,主题X的分区3宕机,此时分区3没有Leader副本,触发再平衡,消费者4没有对应的主题分区,则消费者4闲置。
-
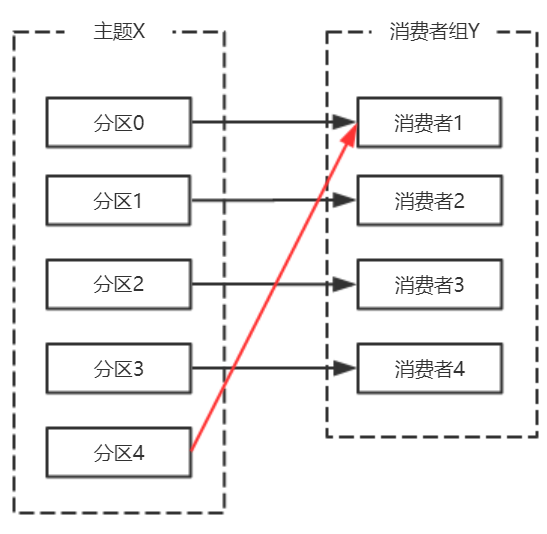
- 主题增加分区,需要主题分区和消费组进行再均衡。
![]()
- 主题增加分区,需要主题分区和消费组进行再均衡。
-
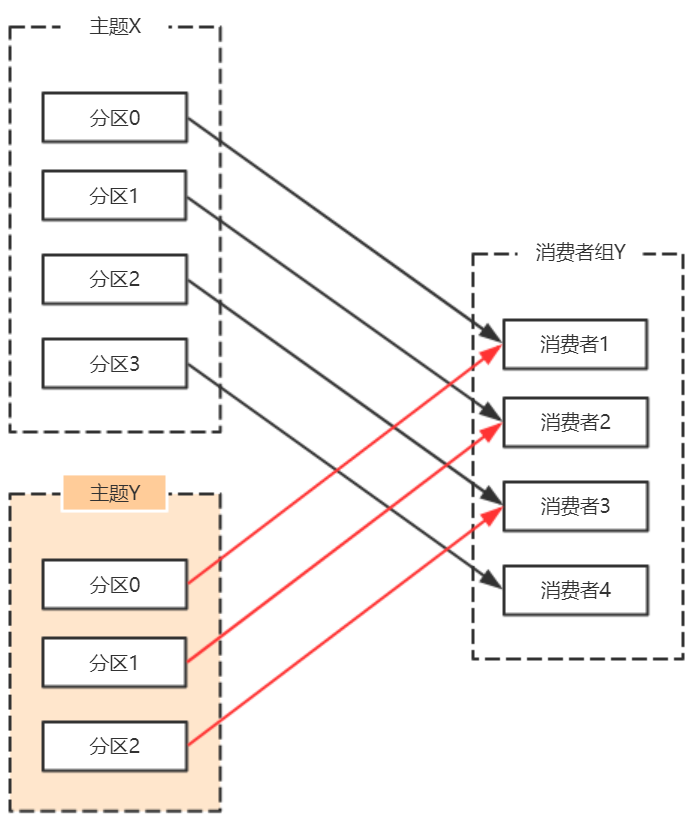
- 由于使用正则表达式订阅主题,当增加的主题匹配正则表达式的时候,也要进行再均衡。
![]()
- 由于使用正则表达式订阅主题,当增加的主题匹配正则表达式的时候,也要进行再均衡。
-
- poll() 两次调用的时间间隔比配置的 max.poll.interval.ms 长
internals.ConsumerCoordinator: Auto-commit of offsets {LOC_MSG_SIGNAL_KAFUKA-0=OffsetAndMetadata{offset=277796667828, metadata=''}} failed for group kafka2hbase_imsi_86: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
internals.ConsumerCoordinator:自动提交偏移量 {LOC_MSG_SIGNAL_KAFUKA-0=OffsetAndMetadata{offset=277796667828, metadata=''}} 组 kafka2hbase_imsi_86 失败:提交无法完成,因为该组已经重新平衡并将分区分配给另一个成员。 这意味着对 poll() 的后续调用之间的时间比配置的 max.poll.interval.ms 长,这通常意味着轮询循环花费了太多时间处理消息。
您可以通过增加会话超时或通过使用 max.poll.records 减少 poll() 中返回的批处理的最大大小来解决此问题。
-
- 增加消费者?
4. 避免rebalance
为什么说重平衡为人诟病呢?
因为重平衡过程中,消费者无法从kafka消费消息,这对kafka的TPS影响极大,而如果kafka集内节点较多,比如数百个,那重平衡可能会耗时极多。数分钟到数小时都有可能,而这段时间kafka基本处于不可用状态。所以在实际环境中,应该尽量避免重平衡发生。
- 避免重平衡
要说完全避免重平衡,是不可能,因为你无法完全保证消费者不会故障。而消费者故障其实也是最常见的引发重平衡的地方,所以我们需要保证尽力避免消费者故障。
而其他几种触发重平衡的方式,增加分区,或是增加订阅的主题,抑或是增加消费者,更多的是主动控制。
如果消费者真正挂掉了,就没办法了,但实际中,会有一些情况,kafka错误地认为一个正常的消费者已经挂掉了,我们要的就是避免这样的情况出现。
首先要知道哪些情况会出现错误判断挂掉的情况。
在分布式系统中,通常是通过心跳来维持分布式系统的,kafka也不例外。
在分布式系统中,由于网络问题你不清楚没接收到心跳,是因为对方真正挂了还是只是因为负载过重没来得及发生心跳或是网络堵塞。所以一般会约定一个时间,超时即判定对方挂了。
而在kafka消费者场景中,session.timout.ms参数就是规定这个超时时间是多少。
还有一个参数,heartbeat.interval.ms,这个参数控制发送心跳的频率,频率越高越不容易被误判,但也会消耗更多资源。
此外,还有最后一个参数,max.poll.interval.ms,消费者poll数据后,需要一些处理,再进行拉取。如果两次拉取时间间隔超过这个参数设置的值,那么消费者就会被踢出消费者组。也就是说,拉取,然后处理,这个处理的时间不能超过 max.poll.interval.ms 这个参数的值。这个参数的默认值是5分钟,而如果消费者接收到数据后会执行耗时的操作,则应该将其设置得大一些。
- 三个参数
session.timout.ms控制心跳超时时间,
heartbeat.interval.ms控制心跳发送频率,
max.poll.interval.ms控制poll的间隔。
这里给出一个相对较为合理的配置,如下:
session.timout.ms:设置为6s
heartbeat.interval.ms:设置2s
max.poll.interval.ms:推荐为消费者处理消息最长耗时再加1分钟

 浙公网安备 33010602011771号
浙公网安备 33010602011771号