
https://mp.weixin.qq.com/s/nlMGEhuaDUYqV6r8A4cRlA
内存分配过程中会产生两种碎片。
内部碎片:内部碎片就是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间。
外部碎片:外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域
这两个算法分配的都是连续的内存空间
- 分配算法1——伙伴系统
最开始,内存只有一个块,当我们需要分配一个固定大小的内存空间时,操作系统会一直等分内存,直到正好够我们需要分配的空间,这时所有的内存块的大小都为2的幂,而相邻的两块大小相等的内存又叫伙伴块 - 分配算法2——slab
而slab分配器是基于对象来管理的,它保证相同类型的对象归为一类(如进程描述符就是一类),每当要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免这些内碎片。slab分配器并不丢弃已分配的对象,而是释放并把它们保存在内存中。当以后又要请求新的对象时,就可以从内存直接获取而不用重复初始化。
![]()
函数malloc,kmalloc,vmalloc的区别
- kmalloc和vmalloc是分配的是内核的内存,malloc分配的是用户的内存
- kmalloc保证分配的内存在物理上是连续的,vmalloc和malloc保证的是在虚拟地址空间上的连续,
- kmalloc能分配的大小有限,vmalloc和malloc能分配的大小相对较大
- 内存只有在要被DMA访问的时候才需要物理上连续
- vmalloc比kmalloc要慢,尽管在某些情况下才需要物理上连续的内存块,但是很多内核代码都用kmalloc来获得内存,而不是vmalloc。这主要是出于性能的考虑。vmalloc函数为了把物理内存上不连续的页转换为虚拟地址空间上连续的页,必须专门建立页表项。糟糕的是,通过vmalloc获得的页必须一个个地进行映射,因为它们物理上是不连续的,这就会导致比直接内存映射大得多的TLB抖动,vmalloc仅在不得已时才会用–典型的就是为了获得大块内存时。
- kmalloc主要使用slab分配内存。
- malloc是用户态使用的内存分配接口,一般通过mmap实现。但是最终还是向buddy申请内存,因为buddy系统是管理物理内存的门户。申请到大块内存后,再像slab一样对其进行细分维护,根据用户需要返回相应内存的指针。
- 一般来说,在内核中想要分配一段连续的内存,首先向slab系统申请,如果不满足(超过两个页面,也就是8K),直接向buddy系统申请。如果还不满足(超过4M,也就是1024个页面),将无法获取到连续的物理地址。可以通过vmalloc获取虚拟地址空间连续,但物理地址不连续的更大的内存空间。
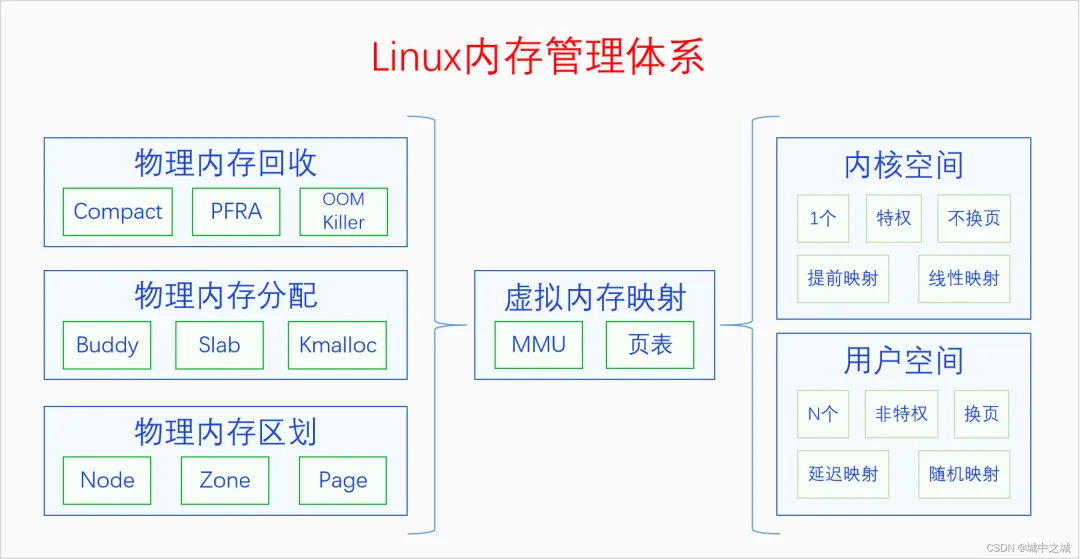
分配方式总结
物理内存的三级分配体系分别是buddy system、slab allocator和kmalloc。
伙伴系统
-
alloc_pages/__get_free_page: 以页为单位分配
-
vmalloc: 以字节为单位分配虚拟地址连续的内存块
-
slab allocator
kmalloc: 以字节为单位分配物理地址连续的内存块,它是以slab为基础的,使用slab层的general caches — 大小为2^n,名称是kmalloc-32、kmalloc-64等(在老kernel上的名称是size-32、size-64等)。物理内存有分配也有释放,但是当分配速度大于释放速度的时候,物理内存就会逐渐变得不够用了。此时我们就要进行内存回收了。内存回收首先考虑的是内存规整,也就是内存碎片整理,因为有可能我们不是可用内存不足了,而是内存太分散了,没法分配连续的内存.
内存规整--页帧回收(内核空间不换页,为缓存回收;用户空间的物理内存分为文件页和匿名页。对于文件页,如果其是clean的,可以直接丢弃内容,回收其物理内存,如果其是dirty的,则会先把其内容写回到文件,然后再回收内存。对于匿名页,如果系统配置的有swap区的话,则会把其内容先写入swap区,然后再回收,如果系统没有swap区的话则不会进行回收。)--OMM KILLER(按照一定的规则选择一个进程将其杀死,然后其物理内存就被释放了。)
把进程占用的但是当前并不在使用的物理内存进行回收,并分配给新的进程来使用的过程就叫做换页。进程被换页的物理内存后面如果再被使用到的话,还会通过缺页异常再换入内存。
内核还有三个内存压缩技术zram、zswap、zcache
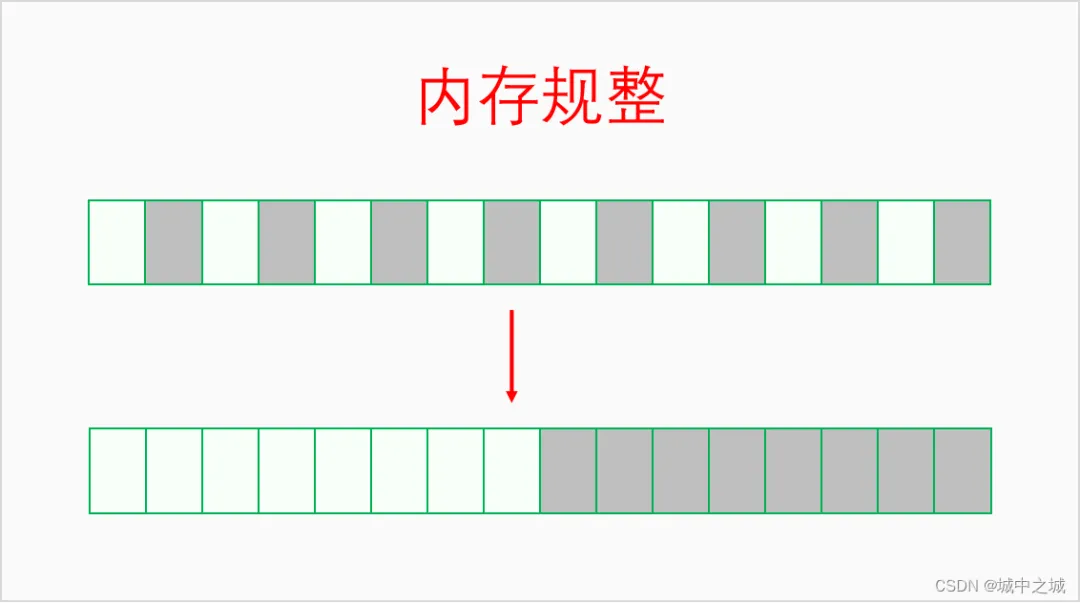
4.1 内存规整
系统运行的时间长了,内存一会儿分配一会儿释放,慢慢地可用内存就会变得很碎片化不连续。虽然总的可用内存还不少,但是却无法分配大块连续内存,此时就需要进行内存规整了。内存规整是以区域为基本单位,找到可用移动的页帧,把它们都移到同一端,然后连续可用内存的量就增大了
4.2 页帧回收
时如何选择回收哪些文件页、匿名页,不回收哪些文件页、匿名页呢,以及文件页和匿名页各回收多少比例呢?内核把所有的文件页放到两个链表上,活跃文件页和不活跃文件页,回收的时候只会回收不活跃文件页。内核把所有的匿名页也放到两个链表上,活跃匿名页和不活跃匿名页,回收的时候只会回收不活跃匿名页。有一个参数/proc/sys/vm/swappiness控制着匿名页和文件页之间的回收比例。
4.3 交换区
4.4 OOM killer
其触发点在linux-src/mm/page_alloc.c:__alloc_pages_may_oom,当使用各种方法都回收不到内存时会调用out_of_memory函数。
总共有两步,1.先选择一个要杀死的进程,2.杀死它。oom_kill_process函数的目的很简单,但是实现过程也有点复杂,这里就不展开分析了,大家可以自行去看一下代码。我们重点分析一下select_bad_process函数的逻辑,select_bad_process主要是依靠oom_score来进行进程选择的。
oom_score(oomkill选择规则)
-
/proc//oom_score 系统计算出来的oom_score值,只读文件,取值范围0 –- 1000,0代表never kill,1000代表aways kill,值越大,进程被选中的概率越大。
-
/proc//oom_score_adj 让用户空间调节oom_score的接口,root可读写,取值范围 -1000 --- 1000,默认为0,若为 -1000,则oom_score加上此值一定小于等于0,从而变成never kill进程。OS可以把一些关键的系统进程的oom_score_adj设为-1000,从而避免被oom kill。此值为手动调整概率补偿
oom_badness首先把unkiller的进程也就是init进程内核线程直接返回 LONG_MIN,这样它们就不会被选中而杀死了,这里看好像和前面的检测冗余了,但是实际上这个函数还被/proc//oom_score的show函数调用用来显示数值,所以还是有必要的,这里也说明了一点,oom_score的值是不保留的,每次都是即时计算。然后又把oom_score_adj为-1000的进程直接也返回LONG_MIN,这样用户空间专门设置的进程就不会被kill了。最后就是计算oom_score了,计算方法比较简单,就是此进程使用的RSS驻留内存、页表、swap之和越大,也就是此进程所用的总内存越大,oom_score的值就越大,逻辑简单直接,谁用的物理内存最多就杀谁,这样就能够回收更多的物理内存,而且使用内存最多的进程很可能是内存泄漏了,所以此算法虽然很简单,但是也很合理。
六、 虚拟内存映射
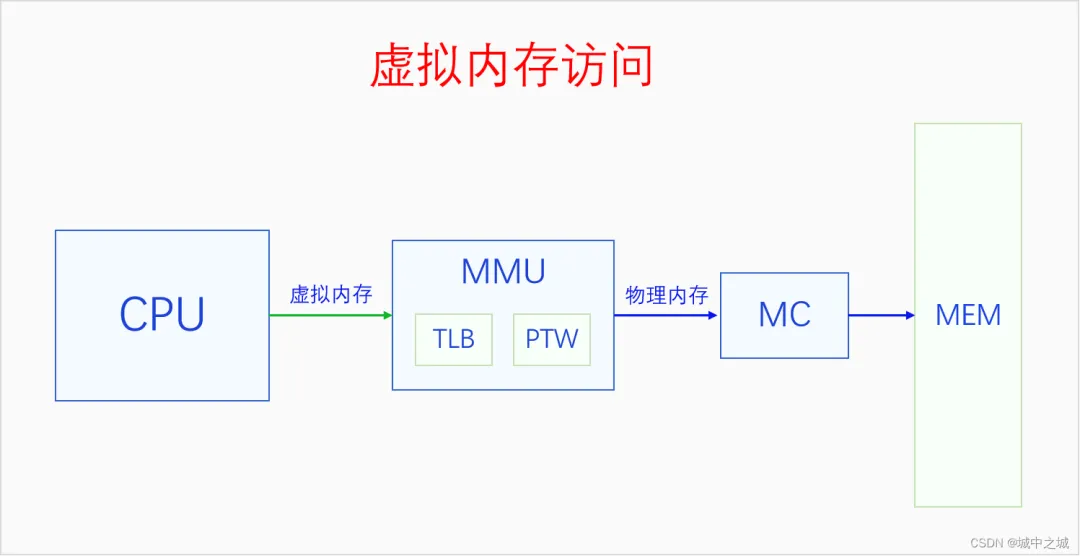
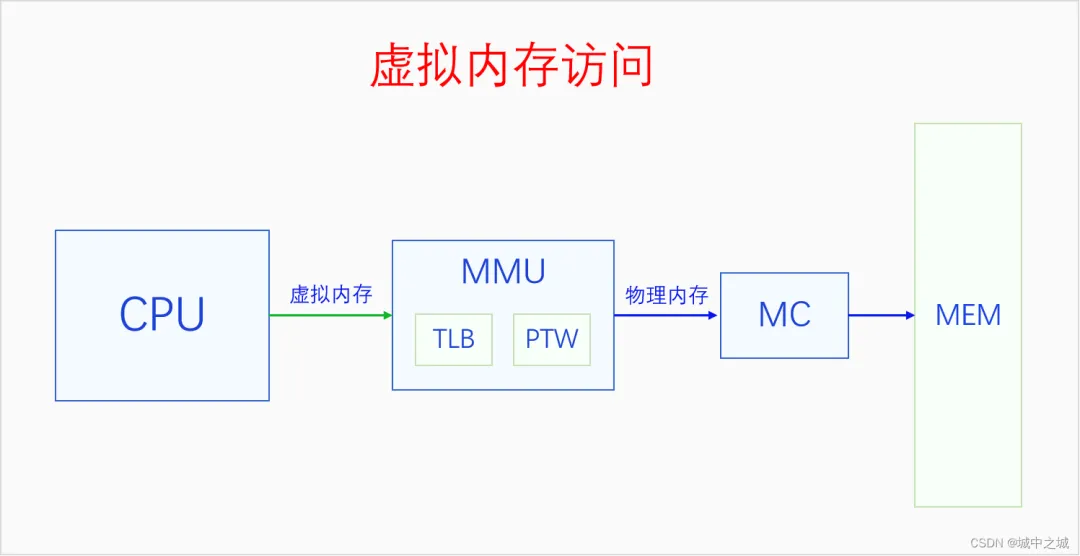
开启分页内存机制之后,CPU访问一切内存都要通过虚拟内存地址访问,CPU把虚拟内存地址发送给MMU,MMU把虚拟内存地址转换为物理内存地址,然后再用物理内存地址通过MC(内存控制器)访问内存。MMU里面有两个部件,TLB和PTW。TLB可以意译地址转换缓存器,它是缓存虚拟地址解析结果的地方。PTW可以意译为虚拟地址解析器,它负责解析页表,把虚拟地址转换为物理地址,然后再送去MC进行访问。同时其转换结果也会被送去TLB进行缓存,下次再访问相同虚拟地址的时候就不用再去解析了,可以直接用缓存的结果。
- 页表
虚拟地址映射的基本单位是页面不是字节,一个虚拟内存的页面会被映射到一个物理页帧上。MMU把虚拟地址转换为物理地址的方法是通过查找页表。一个页表的大小也是一个页面,4K大小,页表的内容可以看做是页表项的数组,一个页表项是一个物理地址,指向一个物理页帧,在32位系统上,物理地址是32位也就是4个字节,所以一个页表有4K/4=1024项,每一项指向一个物理页帧,大小是4K,所以一个页表可以表达4M的虚拟内存,要想表达4G的虚拟内存空间,需要有1024个页表才行,每个页表4K,一共需要4M的物理内存。
4M的物理内存看起来好像不大,但是每个进程都需要有4M的物理内存做页表,如果有100个进程,那就需要有400M物理内存,这就太浪费物理内存了,而且大部分时候, 一个进程的大部分虚拟内存空间并没有使用。为此我们可以采取两级页表的方法来进行虚拟内存映射。在多级页表体系中,最后一级页表还叫页表,其它的页表叫做页目录,但是我们有时候也会都叫做页表。 对于两级页表体系,一级页表还是一个页面,4K大小,每个页表项还是4个字节,一共有1024项,一级页表的页表项是二级页表的物理地址,指向二级页表,二级页表的内容和前面一样。一级页表只有一个,4K,有1024项,指向1024个二级页表,一个一级页表项也就是一个二级页表可以表达4M虚拟内存,一级页表总共能表达4G虚拟内存,此时所有页表占用的物理内存是4M加4K。看起来使用二级页表好像还多用了4K内存,但是在大多数情况下,很多二级页表都用不上,所以不用分配内存。如果一个进程只用了8M物理内存,那么它只需要一个一级页表和两个二级页表就行了,一级页表中只需要使用两项指向两个二级页表,两个二级页表填充满,就可以表达8M虚拟内存映射了,此时总共用了3个页表,12K物理内存,页表的内存占用大大减少了。
102410244=4g
是否每个进程都会分配 4KB 一级页 + 4MB 的二级页表?
** 回答:**
不一定,只有一级页表一定分配,二级页表按需分配!每个二级页表含1024项=1024*4k=4MB的虚拟内存
项目:分配情况 原因
一级页表 每个进程创建时分配,大小为 4KB用于记录所有二级页表的地址
二级页表 按需分配,每访问一个新区域才分配对应页表 节省内存空间(稀疏映射)
举个例子:
某个进程刚启动,只用了 8MB 的代码 + 堆栈
那么只会分配一级页表(4KB) + 对应几个二级页表(最多 2 个)
在64位系统上,一个页面还是4K大小,一个页表还是一个页面,但是由于物理地址是64位的,所以一个页表项变成了8个字节,一个页表就只有512个页表项了,这样一个页表就只能表达2M虚拟内存了。寻址512个页表项只需要9位就够了。在x86 64上,虚拟地址有64位,但是64位的地址空间实在是太大了,所以我们只需要用其中一部分就行了。x86 64上有两种虚拟地址位数可选,48位和57位,分别对应着四级页表和五级页表。为啥是四级页表和五级页表呢?因为48=9+9+9+12,57=9+9+9+9+12,12可以寻址一个页面内的每一个字节,9可以寻址一级页表中的512个页表项。
Linux内核最多支持五级页表,在五级页表体系中,每一级页表分别叫做PGD、P4D、PUD、PMD、PTE。如果页表不够五级的,从第二级开始依次去掉一级。
下面我们来看一下x86的页表项格式。图片这是32位的页表项格式,其中12-31位是物理地址。
P,此页表项是否有效,1代表有效,0代表无效,为0时其它字段无意义。
R/W,0代表只读,1代表可读写。
U/S,0代表内核页表,1代表用户页面。
PWT,Page-level write-through
PCD,Page-level cache disable
A,Accessed; indicates whether software has accessed the page
D,Dirty; indicates whether software has written to the page
PAT,If the PAT is supported, indirectly determines the memory type used to access the page
G,Global; determines whether the translation is global
64位系统的页表项格式和这个是一样的,只不过是物理地址扩展到了硬件支持的最高物理地址位数。
6.2 虚拟内存解析(MMU)
MMU是通过遍历页表把虚拟地址转换为物理地址的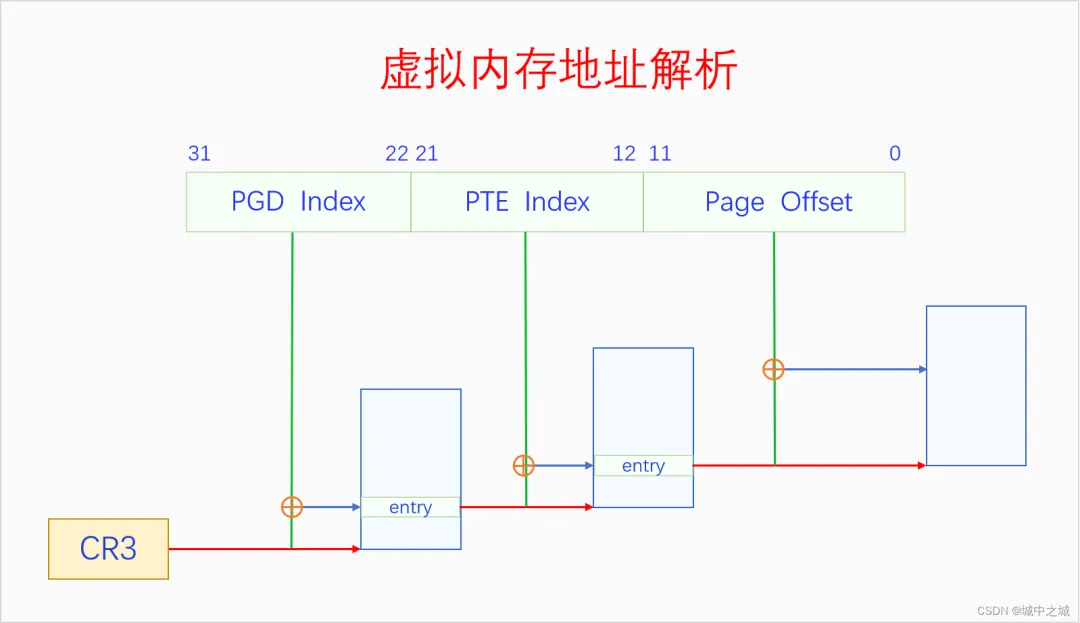
6.3 缺页异常
MMU在解析虚拟内存时如果发现了读写错误或者权限错误或者页表项无效,就会触发缺页异常让内核来处理。
缺页异常首先从CR2寄存器中读取发生异常的虚拟内存地址。然后根据此地址是在内核空间还是在用户空间,分别调用do_kern_addr_fault和do_user_addr_fault来处理。使用vmalloc时会出现内核空间的缺页异常。用户空间地址的缺页异常在做完各种检测处理之后会调用所有架构都通用的函数handle_mm_fault来处理。
七、虚拟内存空间
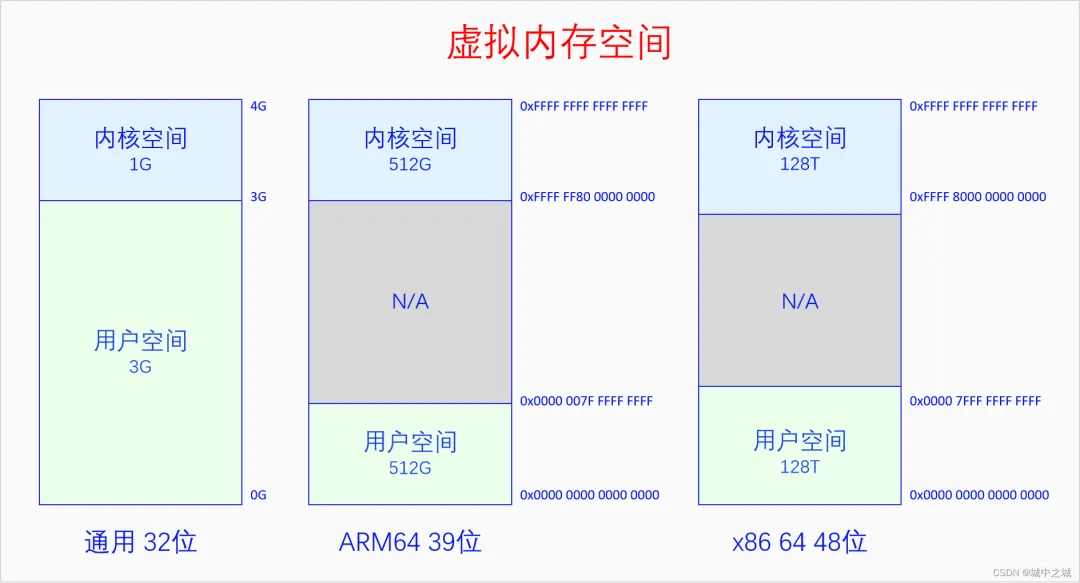
在32位系统上默认是内核占据上面1G虚拟空间,进程占据下面3G虚拟空间,有config选项可以选择其它比列,所有CPU架构都是如此。在64位系统上,由于64位的地址空间实在是太大了,Linux并没有使用全部的虚拟内存空间,而是只使用其中一部分位数。使用的方法是把用户空间的高位补0,内核空间的高位补1,这样从64位地址空间的角度来看就是只使用了两段,中间留空,方便以后往中间扩展。中间留空的是非法内存空间,不能使用。具体使用多少位,高位如何补0,不同架构的选择是不同的。ARM64在4K页面大小的情况下有39位和48位两种虚拟地址空间的选择。X86 64有48位和57位两种虚拟地址空间的选择。ARM64是内核空间和用户空间都有这么多的地址空间,x86 64是内核空间和用户空间平分这么多的地址空间,上图中的大小也可以反应出这一点。
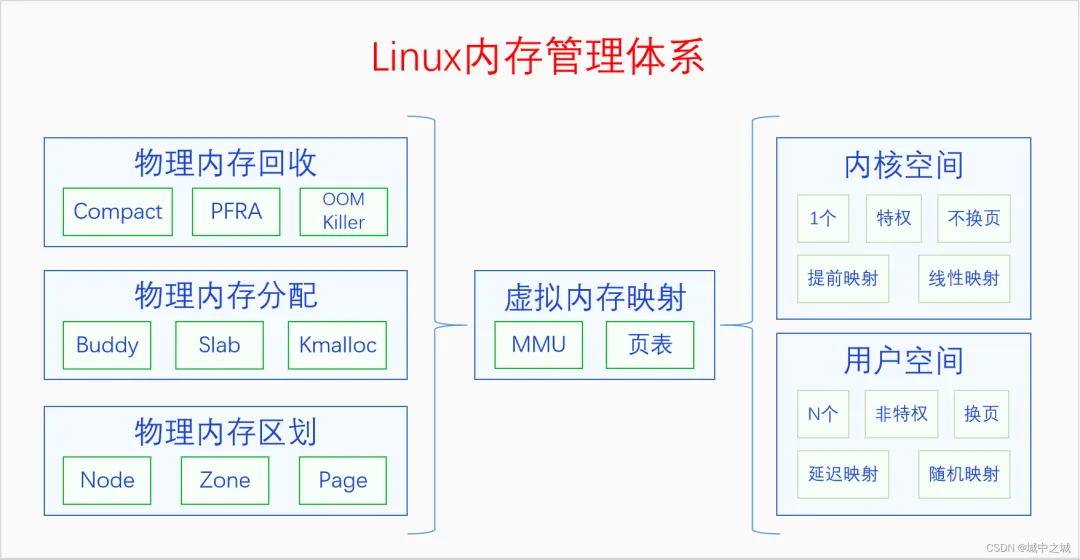
总结:首先要强调的一点是,这么多的东西,都是在内核里进行管理的,内核是可以操作这一切的。但是对进程来说这些基本都是透明的,进程只能看到自己的虚拟内存空间,只能在自己空间里分配虚拟内存,其它的,进程什么也看不见、管不着。
目前绝大部分的操作系统采用的内存管理模式都是以分页内存为基础的虚拟内存机制。虚拟内存机制的中心是MMU和页表,MMU是需要硬件提供的,页表是需要软件来操作的。虚拟内存左边连着物理内存管理,右边连着虚拟内存空间,左边和右边有着复杂的关系。物理内存管理中,首先是对物理内存的三级区划,然后是对物理内存的三级分配体系,最后是物理内存的回收。虚拟内存空间中,首先可以分为内核空间和用户空间,两者在很多方面都有着显著的不同。内核空间是内核运行的地方,只有一份,永久存在,有特权,而且其内存映射是提前映射、线性映射,不会换页。用户空间是进程运行的地方,有N份,随着进程的诞生而创建、进程的死亡而销毁。用户空间中虚拟内存的分配和物理内存的分配是分开的,进程只能分配虚拟内存,物理内存的分配是在进程运行过程中动态且透明地分配的。用户空间的物理内存可以分为文件页和匿名页,页帧回收的主要逻辑就是围绕文件页和匿名页展开的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号