【Agent】MemOS 源码笔记---(4)---KV Cache
【Agent】MemOS 源码笔记---(4)---KV Cache
0x00 概要
在MemOS中,KV Cache最适合存储语义稳定且经常复用的背景信息,例如:
- 常见问题(FAQs)或特定领域知识
- 先前的对话历史
这些稳定的明文记忆项由MemScheduler模块自动识别和管理。一旦被选中,它们就会被提前转换成KV格式的表示(KVCacheItem)。这个预计算步骤以可复用的格式存储记忆的激活状态(键值对张量),允许它们在推理期间注入到模型的注意力缓存中
一旦进行转换,这些KV记忆就可以跨查询复用,而不需要对原始内容重新编码。这减少了处理和存储大量文本的计算开销,使其成为需要快速响应时间和高吞吐量的应用程序的理想选择。
0x01 原理
KVCacheMemory 是MemOS中用于存储和管理KV cache的专用记忆模块,主要用于加速大语言模型(LLMs)推理并支持有效的上下文复用。KVCacheMemory 将最近或稳定的上下文作为激活缓存保存,有助于对于会话式和生成式人工智能系统。
1.1 技术路径
若要替大模型补上记忆的缺口,如今的产业界大致踩出两条技术路径,各有利弊,也决定了产品落地的不同走向。
- 第一条路是“外挂式”的文本记忆。做法直截了当:先把对话里的关键信息提炼成可读的文字,再写进向量库或图数据库;待模型需要时,按语义相似度把它们重新召回即可。这相当于给模型配一本随身的智能记事本,写进去的是什么,以后读出来的也是什么,人类一眼就能核对、删改或增补。
- 第二条路是“内置式”的张量记忆。在模型内部新增数十亿参数,充当隐式的“记忆池”,一切信息都被压缩成高维张量存于其中。此法的好处是召回路径短,与推理过程融为一体;代价则是不可读、不可改,一旦写错,只能重新训练,无法像删改文档那样随手修正。
KVCacheMemory 看起来是介于两者之间的一条路。
KVCacheMemory 对应了激活记忆,即运行时的 KV 缓存和隐藏状态(高效率)。MemOS 使用 KVCacheMemory (最近或稳定的上下文)来加速多轮对话,高效的运行时状态缓存。适合对话中的快速重用、多轮会话。
1.2 对比
我们比对下是否带 KV Cache 的区别:
-
无KV Cache记忆
- 每个新查询都被添加到完整的提示模板中,包括背景知识。
- 模型必须在整个序列上重新计算token嵌入和注意力——即使是未更改的记忆。
-
有KV Cache记忆
- 背景知识以键值对张量的形式缓存一次。
- 对于每个查询,只对新用户输入(查询token)进行编码。
- 之前缓存的KV被直接注入到注意力机制中。
这种分离减少了预填充阶段的冗余计算,从而导致:
- 跳过背景知识的重复编码
- 更快的查询token和缓存记忆之间的注意力计算
- 降低首次token时间(Time To First Token, TTFT) 生成过程中的延迟
这种优化在以下方面特别有价值:
- 多回合聊天机器人交互
- 检索增强生成或上下文增强生成(RAG, CAG)
- 在固定文档或FAQ风格记忆上操作的助理
我们再比对下 TreeTextMemory 和 KVCacheMemory :
- TreeTextMemory 将你的长时记忆存储在图数据库(Neo4j)中。
- KVCacheMemory 将最近或稳定的上下文作为激活缓存保存。
- 二者在一个 MemCube 中协同工作,由你的
MOSPipeline 统一管理。
1.3 协同工作
MemOS 将记忆视为一个生态系统——不仅仅是静态数据,而是演进的知识。以下是三种核心记忆类型如何协同工作:
| 记忆类型 | 描述 | 何时使用 |
|---|---|---|
| 参数记忆 | 知识提炼到模型权重中 | 常青技能、稳定领域专业知识 |
| 激活记忆 | 短期 KV cache 和隐藏状态 | 对话中的快速重用、多轮会话 |
| 明文记忆 | 文本、文档、图节点或向量块 | 可搜索、可检查、演进知识 |
MemOS 让用户在生命周期循环中调度所有三种记忆类型:
-
高频的明文记忆可以提炼为参数化权重。
-
高频激活路径成为可重用的 KV 模板。
-
陈旧的参数化或激活单元可以降级为明文记忆以进行追溯。
使用 MemOS,用户的 AI 不仅仅是存储事实——它*记忆*、*理解*和*成长*。
深入理解
- 随着时间的推移,频繁使用的明文记忆可以提炼为参数化形式。
- 很少使用的权重或缓存可以降级为纯文本存储以进行审计和重新训练。
0x02 定义
2.1 KV Cache的记忆结构
通过KVCacheMemory实现基于KV的记忆复用,在保持相同输出的同时,大大减少了模型大小和查询类型之间的延迟。通过将可复用记忆从明文提示转移到预先计算的KV Cache,MemOS消除了冗余的上下文编码,并实现了更快的响应时间,特别是在实时的、记忆增强的LLM应用程序中。
每个缓存被存储为一个KVCacheItem:
| 字段 | 类型 | 描述 |
|---|---|---|
kv_cache_id |
str |
缓存中的唯一ID(UUID) |
kv_cache |
DynamicCache |
实际的KV Cache(transformers) |
metadata |
dict |
元数据 (源, 抽取时间等.) |
总体逻辑如下:
-
KVCacheItem 是数据载体,KVCacheMemory 是管理多个KVCacheItem 的内存系统,对外提供操作接口。
-
KVCacheMemory 是管理多个 KVCacheItem 的内存系统(使用kv_cache_memories这个字典结构来保存),提供了CRUD操作,负责 KVCacheItem 的创建、存储、检索、合并和持久化。
-
KVCacheItem 是单个激活记忆的数据结构。继承自基础激活内存项,专门存储 LLM 的动态 KV 缓存,支持自定义元数据和关联文本记录。KVCacheItem 包含多个KVCacheRecords,KVCacheRecords存储与缓存相关的文本记忆信息。
2.2 API总结 (KVCacheMemory)
KVCacheMemory 提供了CRUD操作,用户可以直接使用。
初始化代码如下:
KVCacheMemory(config: KVCacheMemoryConfig)
核心方法如下:
| 方法 | 描述 |
|---|---|
extract(text) |
使用LLM从输入文本中提取KV Cache |
add(memories) |
添加一个或多个KVCacheItem到记忆中 |
get(memory_id) |
根据ID获取单个缓存 |
get_by_ids(ids) |
根据IDs获取多个缓存 |
get_all() |
返回所有存储的缓存 |
get_cache(cache_ids) |
从多个IDs合并并返回组合缓存 |
delete(ids) |
通过IDs删除缓存 |
delete_all() |
删除所有缓存 |
dump(dir) |
将所有缓存序列化到目录中的pickle文件 |
load(dir) |
从目录中的pickle文件加载缓存 |
from_textual_memory(mem) |
将TextualMemoryItem 转换为 KVCacheItem |
当调用dump(dir), 系统写到:
<dir>/<config.memory_filename>
该文件包含所有KV Cache的pickle字典,可以使用load(dir)重新加载。
2.3 KVCacheMemory代码
KVCacheMemory:
- 该类是基于键值缓存的激活内存存储机制,用于管理 LLM 的键值缓存(KV Cache)
- 提供了完整的键值缓存提取、添加、查询、合并、删除等功能
- 支持将文本内容转换为 KV 缓存格式,也支持与文本内存项的相互转换
- 特色是针对不同版本的 transformers 库进行了兼容处理,实现了高效的多层缓存合并操作,通过批量拼接张量提升性能

具体代码如下。
class KVCacheMemory(BaseActMemory):
"""
用于激活内存的键值缓存存储器。
这种内存类型设计用于存储和检索键值缓存。
"""
@require_python_package(
import_name="torch",
install_link="https://pytorch.org/get-started/locally/",
)
def __init__(self, config: KVCacheMemoryConfig) -> None:
"""使用配置初始化KV缓存存储器。"""
self.config = config # 存储配置信息
# 根据配置创建LLM实例,用于提取KV缓存
self.llm = LLMFactory.from_config(config.extractor_llm)
# 存储KV缓存项的字典,以ID为键
self.kv_cache_memories: dict[str, KVCacheItem] = {}
def extract(self, text: str) -> KVCacheItem:
"""基于文本提取内存。
使用LLM从提供的文本中构建KV缓存。
参数:
text: 用于提取内存的输入文本
返回:
提取的内存项
"""
# 使用LLM从文本构建KV缓存
kv_cache = self.llm.build_kv_cache(text)
# 创建包含提取的缓存的KV缓存项
cache_item = KVCacheItem(
memory=kv_cache,
metadata={"source_text": text, "extracted_at": datetime.now().isoformat()},
)
return cache_item
def add(self, memories: list[KVCacheItem]) -> None:
"""将内存添加到KV缓存存储器中。
参数:
memories: 要添加的KV缓存项列表
"""
for memory in memories:
self.kv_cache_memories[memory.id] = memory
def get_cache(self, cache_ids: list[str]) -> DynamicCache | None:
"""将多个KV缓存合并为一个缓存。
参数:
cache_ids: 要合并的缓存ID列表
返回:
合并后的DynamicCache,如果未找到缓存则返回None
"""
caches_to_merge = []
for cache_id in cache_ids:
cache_item = self.kv_cache_memories.get(cache_id)
if cache_item and cache_item.memory:
caches_to_merge.append(cache_item.memory)
if not caches_to_merge:
return None
return self._concat_caches(caches_to_merge)
def get(self, memory_id: str) -> KVCacheItem | None:
"""通过ID获取内存。
参数:
memory_id: 要检索的内存ID
返回:
内存字典,如果未找到则返回None
"""
return self.kv_cache_memories.get(memory_id)
def get_by_ids(self, memory_ids: list[str]) -> list[KVCacheItem | None]:
"""通过ID列表获取多个内存。
参数:
memory_ids: 要检索的内存ID列表
返回:
内存字典列表,对于不存在的ID返回None
"""
results = []
for memory_id in memory_ids:
memory = self.get(memory_id)
results.append(memory)
return results
def get_all(self) -> list[KVCacheItem]:
"""获取所有内存。
返回:
存储器中所有KV缓存项的列表
"""
return list(self.kv_cache_memories.values())
def delete(self, memory_ids: list[str]) -> None:
"""通过ID删除内存。
参数:
memory_ids: 要删除的内存ID列表
"""
for memory_id in memory_ids:
self.kv_cache_memories.pop(memory_id, None)
def delete_all(self) -> None:
"""删除所有内存。"""
self.kv_cache_memories.clear()
def from_textual_memory(self, mem: TextualMemoryItem) -> KVCacheItem:
"""
将TextualMemoryItem转换为KVCacheItem。
此方法从文本内存中提取键值缓存。
"""
# 从文本内存内容构建KV缓存
kv_cache = self.llm.build_kv_cache(mem.memory)
return KVCacheItem(memory=kv_cache, metadata=mem.metadata.model_dump())
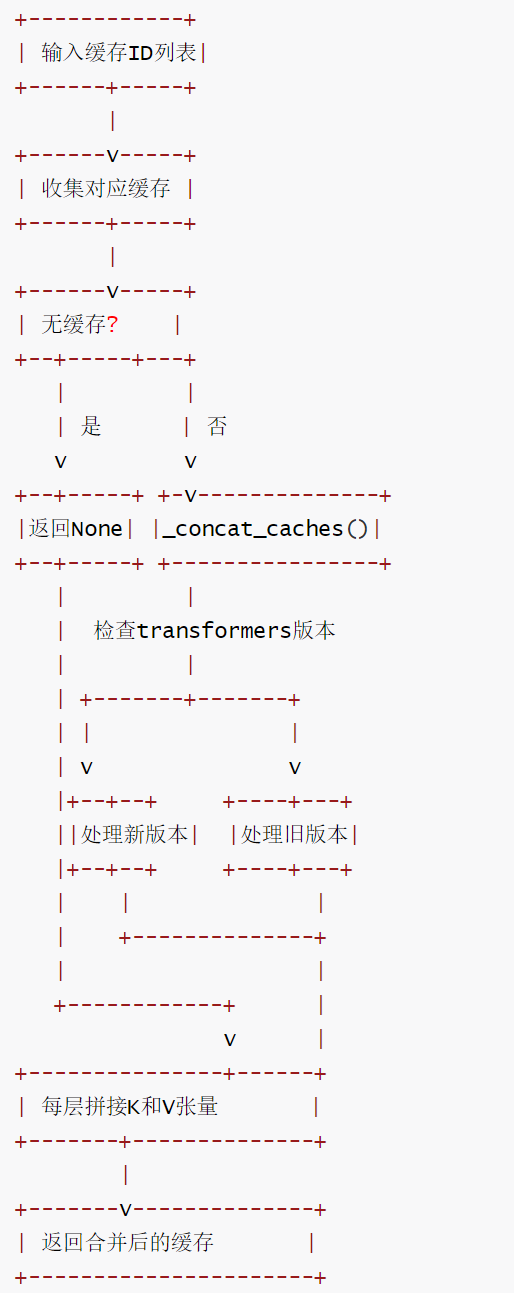
def _concat_caches(self, caches: list[DynamicCache]) -> DynamicCache:
"""
更快的拼接合并:对于每个层,收集所有缓存的张量
并每层执行一次torch.cat操作。
"""
import torch
assert caches, "至少需要一个缓存"
if len(caches) == 1:
return caches[0]
merged = DynamicCache()
num_layers = len(caches[0].key_cache)
# 处理transformers 4.54.0及以上版本的缓存结构
if Version(version("transformers")) >= Version("4.54.0"):
merged.append_new_layers(num_layers - 1)
for layer in range(num_layers):
# 收集当前层的所有K和V
keys = [c.layers[layer].keys for c in caches]
vals = [c.layers[layer].values for c in caches]
# 每层执行一次拼接
merged.layers[layer].keys = torch.cat(keys, dim=-2)
merged.layers[layer].values = torch.cat(vals, dim=-2)
# 处理旧版本transformers的缓存结构
else:
for layer in range(num_layers):
# 收集当前层的所有K和V
keys = [c.key_cache[layer] for c in caches]
vals = [c.value_cache[layer] for c in caches]
# 每层执行一次拼接
merged.key_cache.append(torch.cat(keys, dim=-2))
merged.value_cache.append(torch.cat(vals, dim=-2))
return merged
2.4 流程
几个重要的流程图总结如下:
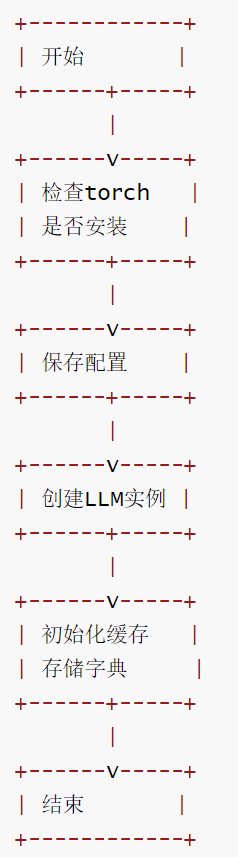
2.4.1 初始化流程
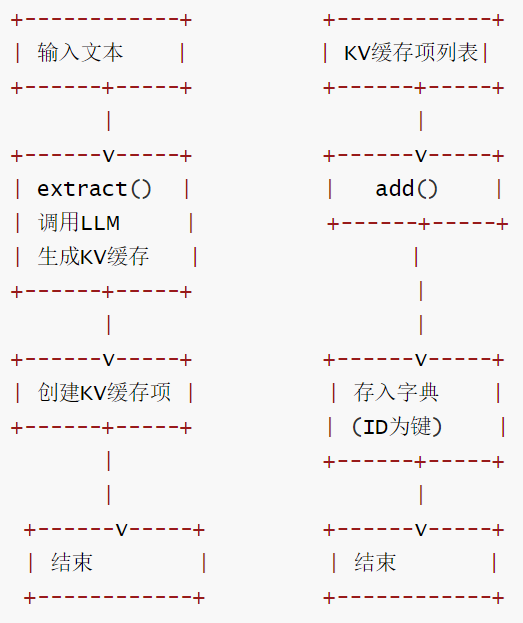
2.4.2 提取与添加流程
2.4.3 缓存合并流程
0x03 重要组件
3.1 KVCacheItem
3.1.1 定义
- 该代码定义了 MemOS 中激活内存相关的数据模型,用于标准化存储 KV 缓存及关联元数据。
- 核心是
KVCacheItem类,继承自基础激活内存项,专门存储 LLM 的动态 KV 缓存,支持自定义元数据和关联文本记录。 - 衍生类
VLLMKVCacheItem适配 vLLM 场景,将缓存存储改为提示字符串(因 vLLM 在服务端预加载 KV 缓存)。 - 特色是使用 Pydantic 模型实现数据结构化,自动生成唯一 ID,支持任意类型字段(适配 DynamicCache),同时通过
KVCacheRecords记录文本内存来源和组合信息,保证数据可追溯。
class ActivationMemoryItem(BaseModel):
"""基础激活内存项模型,定义激活内存的核心结构"""
# 内存项唯一ID,默认使用UUID4自动生成
id: str = Field(default_factory=lambda: str(uuid.uuid4()))
# 内存具体内容,支持任意类型
memory: Any
# 内存关联的元数据,默认空字典
metadata: dict = {}
class KVCacheRecords(BaseModel):
"""KV缓存关联的文本记录模型,用于追溯缓存来源"""
# 转换为激活内存的文本内存列表
text_memories: list[str] = Field(
default=[],
description="转换为激活内存的文本内存列表",
)
# 使用组装模板组合所有文本内存后的单一字符串
composed_text_memory: str = Field(
default="",
description="使用组装模板将所有文本内存组合成的单一字符串",
)
# 提交时间(用于调度消息),默认使用UTC当前时间
timestamp: datetime = Field(
default_factory=datetime.utcnow, description="调度消息的提交时间"
)
class KVCacheItem(ActivationMemoryItem):
"""KV缓存内存项模型,专门存储键值缓存数据"""
# 缓存项唯一ID,默认使用UUID4自动生成(覆盖父类字段)
id: str = Field(default_factory=lambda: str(uuid.uuid4()))
# 存储KV键值对的动态缓存,默认初始化空DynamicCache
memory: DynamicCache = Field(
default_factory=DynamicCache,
description="用于在内存中存储键值对的动态缓存",
)
# 与KV缓存项关联的元数据,默认空字典(覆盖父类字段)
metadata: dict = Field(
default_factory=dict, description="与KV缓存项关联的元数据"
)
# 配置模型以允许任意类型字段(支持DynamicCache作为字段类型)
model_config = ConfigDict(arbitrary_types_allowed=True)
# 关联的文本记录,默认初始化空KVCacheRecords
records: KVCacheRecords = KVCacheRecords()
class VLLMKVCacheItem(KVCacheItem):
"""
vLLM专用KV缓存项模型,存储提示字符串而非DynamicCache对象。
原因是vLLM通过预加载在服务端处理KV缓存。
"""
# 重写memory字段,存储提示字符串而非DynamicCache(适配vLLM)
memory: str = Field(
default="",
description="用于在vLLM服务端预加载KV缓存的提示字符串",
)
3.1.2 关联
KVCacheItem 和 KVCacheMemory 是互相联系的。KVCacheItem 是数据单元/单个记忆单元,KVCacheMemory 是管理系统/激活记忆的存储系统。
-
KVCacheMemory 是管理多个 KVCacheItem 的内存系统,提供了完整的CRUD(创建、存储、检索、合并和持久化)操作。
-
KVCacheMemory 中有self.kv_cache_memories: dict[str, KVCacheItem] = {}。
-
KVCacheRecords 是 KVCacheItem 的一部分,为 KVCacheItem 提供了重要的元数据支持,使得系统可以有效管理和跟踪KV Cache 的状态变化。

3.2 build_kv_cache
KVCacheMemory 会使用LLM把文本构建成KV Cache,或者说是构建成KV 向量。
self.llm = LLMFactory.from_config(config.extractor_llm)
kv_cache = self.llm.build_kv_cache(text)
HFLLM类是基于 Hugging Face Transformers 的 LLM 封装,支持缓存增强生成(CAG)和采样功能。
- 核心能力是将多种格式的输入(字符串、字符串列表、聊天消息列表)转换为标准 KV 缓存,为后续生成任务提供上下文加速。
- 内置温度、Top-K、Top-P 等采样策略的日志处理器,支持灵活的生成配置。
- 特色是自动适配模型和分词器初始化,支持多种输入格式标准化,通过单次前向传播高效构建 KV 缓存。

初始化流程如下:
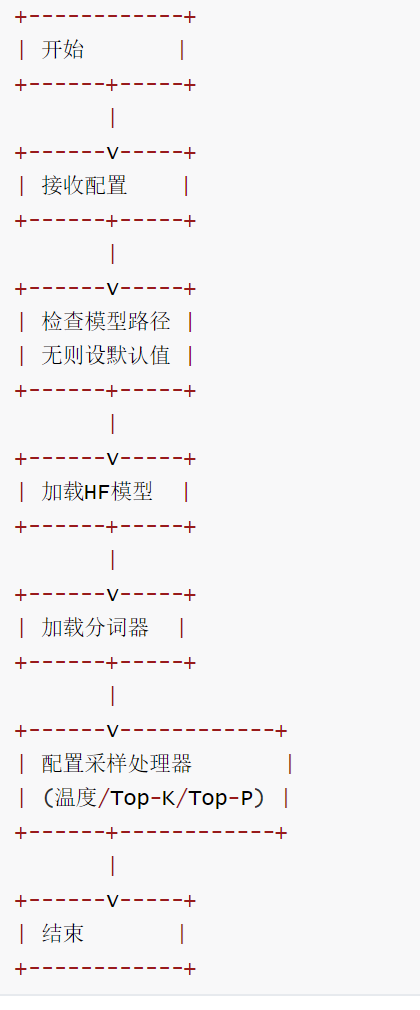
build_kv_cache()流程如下:

具体代码如下:
class HFLLM(BaseLLM):
"""
HFLLM:支持缓存增强生成(CAG)和采样的Transformers LLM类。
"""
def __init__(self, config: HFLLMConfig):
"""
初始化HFLLM模型和分词器,并设置用于采样的日志处理器。
"""
self.config = config # 存储模型配置信息
# 如果未指定模型,使用默认模型
if not self.config.model_name_or_path:
self.config.model_name_or_path = "Qwen/Qwen3-1.7B"
# 初始化Hugging Face模型
self.model = AutoModelForCausalLM.from_pretrained(
self.config.model_name_or_path, torch_dtype="auto", device_map="auto"
)
# 初始化分词器,启用快速分词模式
self.tokenizer = AutoTokenizer.from_pretrained(
self.config.model_name_or_path, use_fast=True
)
# 初始化用于采样的日志处理器列表
processors = []
# 温度调节:控制生成的随机性,非1.0时添加
if getattr(self.config, "temperature", 1.0) != 1.0:
processors.append(TemperatureLogitsWarper(self.config.temperature))
# Top-K采样:限制仅从概率最高的K个token中选择,K>0时添加
if getattr(self.config, "top_k", 0) > 0:
processors.append(TopKLogitsWarper(self.config.top_k))
# Top-P采样:限制仅从累积概率达P的token子集选择,0<P<1时添加
if 0.0 < getattr(self.config, "top_p", 1.0) < 1.0:
processors.append(TopPLogitsWarper(self.config.top_p))
# 组合所有日志处理器
self.logits_processors = LogitsProcessorList(processors)
def build_kv_cache(self, messages: Union[str, List[str], List[Dict[str, str]]]) -> DynamicCache:
"""
通过单次前向传播从聊天消息构建KV缓存。
支持以下输入类型:
- str:用作系统提示词。
- list[str]:拼接后用作系统提示词。
- list[dict]:直接用作聊天消息(需包含"role"和"content"键)。
消息始终会转换为标准聊天模板格式。
异常:
ValueError:如果模板处理后的提示词为空。
返回:
DynamicCache:构建完成的KV缓存对象。
"""
import torch
# 处理多种输入类型,统一转换为标准聊天消息格式
if isinstance(messages, str):
# 字符串输入转为系统提示词格式
messages = [
{
"role": "system",
"content": f"Below is some information about the user.\n{messages}",
}
]
elif isinstance(messages, list) and messages and isinstance(messages[0], str):
# 字符串列表输入拼接后转为系统提示词
messages = [
{
"role": "system",
"content": f"Below is some information about the user.\n{' '.join(messages)}",
}
]
# 应用聊天模板生成完整提示词(不添加生成提示,不分词)
prompt = self.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=False
)
# 对提示词进行分词,转换为模型输入格式
inputs = self.tokenizer(prompt, return_tensors="pt")
# 将输入ID移至模型所在设备,转换为长整型
inputs["input_ids"] = inputs["input_ids"].to(self.model.device, dtype=torch.long)
# 获取序列长度
seq_len = inputs["input_ids"].size(-1)
# 检查提示词是否为空
if seq_len == 0:
raise ValueError(
"聊天模板处理后的提示词为空,无法构建KV缓存。请检查你的消息输入。"
)
# 初始化动态KV缓存
kv = DynamicCache()
# 关闭梯度计算,执行前向传播构建缓存
with torch.no_grad():
self.model(**inputs, use_cache=True, past_key_values=kv)
# 截取有效长度的缓存(去除可能的冗余部分)
for i, (k, v) in enumerate(zip(kv.key_cache, kv.value_cache, strict=False)):
kv.key_cache[i] = k[:, :, :seq_len, :]
kv.value_cache[i] = v[:, :, :seq_len, :]
return kv
0x04 示例
4.1 何时使用:
-
你想要短期工作记忆以加快多轮对话速度。
-
适合聊天机器人会话加速或提示复用。
-
最适合缓存隐藏状态 / KV 对。
4.2 关键点:
- 用 KVCacheMemory,不含显式明文记忆。
-
演示提取 → 添加 → 合并 → 获取 → 删除。
-
展示如何导出/加载 KV cache。
以下是KV Cache的使用示例。
from memos.configs.memory import MemoryConfigFactory
from memos.memories.factory import MemoryFactory
# 为 KVCacheMemory(HuggingFace 后端)创建配置
config = MemoryConfigFactory(
backend="kv_cache",
config={
"extractor_llm": {
"backend": "huggingface",
"config": {
"model_name_or_path": "Qwen/Qwen3-0.6B",
"max_tokens": 32,
"add_generation_prompt": True,
"remove_think_prefix": True,
},
},
},
)
# 实例化 KVCacheMemory
kv_mem = MemoryFactory.from_config(config)
# 提取一个 KVCacheItem(DynamicCache)
prompt = [
{"role": "user", "content": "What is MemOS?"},
{"role": "assistant", "content": "MemOS is a memory operating system for LLMs."},
]
print("===== Extract KVCacheItem =====")
cache_item = kv_mem.extract(prompt)
print(cache_item)
# 将缓存添加到内存中
kv_mem.add([cache_item])
print("All caches:", kv_mem.get_all())
# 通过 ID 获取
retrieved = kv_mem.get(cache_item.id)
print("Retrieved:", retrieved)
# 合并缓存(模拟多轮对话)
item2 = kv_mem.extract([{"role": "user", "content": "Tell me a joke."}])
kv_mem.add([item2])
merged = kv_mem.get_cache([cache_item.id, item2.id])
print("Merged cache:", merged)
# 删除其中一个
kv_mem.delete([cache_item.id])
print("After delete:", kv_mem.get_all())
# 导出和加载缓存
kv_mem.dump("tmp/kv_mem")
print("Dumped to tmp/kv_mem")
kv_mem.delete_all()
kv_mem.load("tmp/kv_mem")
print("Loaded caches:", kv_mem.get_all())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号