MPK(Mirage Persistent Kernel)源码笔记(5)--- 执行引擎
MPK(Mirage Persistent Kernel)源码笔记(5)--- 执行引擎
0x00 概述
MPK 包含内置 GPU 运行时系统,可在单个 GPU 巨型内核内完整执行任务图。这使得系统能在推理过程中无需额外内核启动的情况下,实现任务执行与调度的细粒度控制,以实现高吞吐量与低延迟。
这座超级工厂能全自动运转,核心在于MPK设计了一套跑在GPU上的运行时系统。这套系统的精髓,在persistent_kernel.py(前端接口)和persistent_kernel.cuh(后端实现)里体现得淋漓尽致。
由于所有的调度和任务切换都发生在单一内核上下文内,任务间的开销极低,通常仅需 1-2 微秒,从而能够高效地执行多层、多 GPU 的 LLM 工作负载。
0x01 SM不同角色
为了实现任务执行与调度的细粒度控制,MPK 在启动时将 GPU 上所有流式多处理器(SM)静态分区为两种角色:即工作单元(Worker)和调度器(Scheduler)。工作 SM 与调度 SM 的数量在内核启动时固定配置,且总和等于物理 SM 总数,从而彻底避免动态上下文切换开销。
下图展示了 MPK 的执行时间线,其中每个矩形代表一个在工作单元上运行的任务;每个圆圈代表一个事件。当一个任务完成时,它会递增其对应触发事件的计数器。当事件计数器达到预设阈值时,该事件被视为已激活,并被加入Scheduler的事件队列。随后,Scheduler会启动所有依赖于该事件的下游任务。
这种设计实现了细粒度的软件流水线化,并允许计算与通信之间重叠,比如
- 矩阵乘法(Matmul)任务可以与来自不同层的注意力任务并行执行。
- 一旦有部分 matmul 结果可用,即可开始 Allreduce 通信。
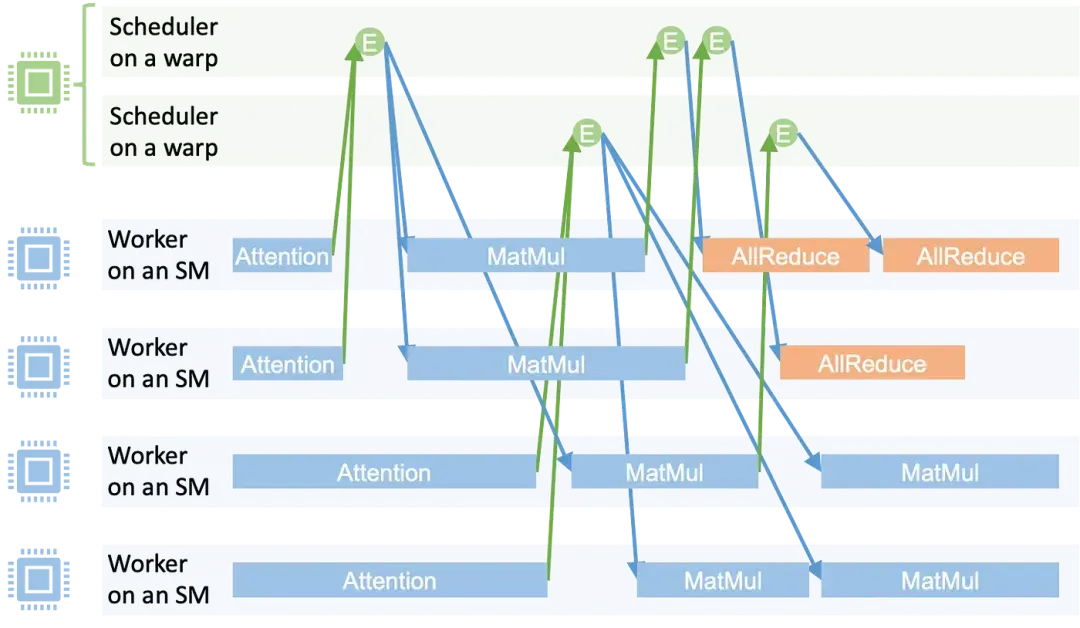
1.1 Scheduler SM
调度决策由 MPK 的分布式Scheduler处理,每个Scheduler运行于单个线程束(warp)上。由于每个流式多处理器(SM)可以容纳多个线程束,因此单 SM 最多可并发运行 4 个Scheduler。每个Scheduler维护激活事件队列,并持续执行以下操作:
- 事件出队:移除依赖已满足的激活事件(即所有前置任务均已完成)。
- 任务启动:调度依赖该激活事件的任务集。
这种分布式调度机制在实现跨 SM 可扩展执行的同时,最小化协同开销。
这些SM不负责计算,它们是GPU内部的“调度系统”。它们监控着一系列“事件”(Event)。一个事件代表一个或多个前置任务已经完成。当Scheduler监测到某个事件被触发(例如,一个矩阵乘任务完成了),它就会查询预先编译好的任务图,找到所有依赖这个事件的后续任务,然后把这些新任务的ID(TaskId)投递到工人们的任务队列里。
在persistent_kernel.cuh里,else分支就是Scheduler的逻辑。它们也是在一个while(true)循环里,不断检查sched_queues,处理激活的事件,并分派新任务。
1.2 Worker SM
这些SM是纯粹的执行单元,负责干具体的计算活,比如矩阵乘、向量加法等。每个工人SM都有一个自己的任务队列(Task Queue),它们的工作就是不断地从队列里取任务、执行、再取下一个。这在persistent_kernel.cuh的源码里体现得很清楚,if (blockIdx.x < config.num_workers)这个分支里的while(true)循环,就是工人SM执行逻辑的直接实现。
每个工作单元独占一个流式多处理器(SM),并维护专属任务队列。其执行遵循以下高效简洁的循环流程:
- 获取任务:从队列中提取下一待执行任务。
- 执行计算:运行任务(如矩阵乘法 / 注意力机制 / GPU 间数据传输)。
- 事件触发:任务完成后通知触发事件。
- 循环执行:重复上述过程。
该机制既保障了工作单元的持续满载运行,又实现了跨层和跨操作的异步任务执行。
0x02 推理引擎
persistent_kernel.cuh 是运行引擎的入口文件。
2.1 初始化
init_persistent_kernel是初始化函数,负责初始化运行时环境、各种数据结构和分配内存。具体如下:
- 参数解析和配置设置
- 接受来自调用方的参数,包括元数据张量、性能分析缓冲区、GPU rank、工作线程数、调度器数等。
- 设置全局运行时配置(global_runtime_config)的各种参数,如工作线程数、调度器数、序列长度限制等。
- 初始化NVSHMEM(如果启用)
- 初始化NVSHMEM(NVIDIA SHared Memory)环境,用于多GPU间的通信。
- 获取当前GPU ID和总GPU数量。
- 调用_init_persistent_kernel函数,该函数用于初始化所有任务和事件描述。
- 内存分配和初始化。比如
- 为所有任务(任务描述/TaskDesc)、所有事件(EventDesc)分配内存并复制数据。
- 为工作队列(worker_queue)和调度器队列(sched_queue )分配内存并复制数据。
- 为事件计数器(EventCounter)分配内存并复制数据。
- 为第一个任务分配内存并复制数据。
- 启动内核
- 调用init_kernel进行内核初始化。
- 如果使用NVSHMEM,则添加全局屏障确保所有初始化完成。
流程图如下

代码如下
// 外部C语言接口:Mirage持久化内核(MPK)的初始化函数
// 负责配置内核运行时参数、初始化分布式通信(如NVSHMEM)、分配GPU内存并加载任务/事件数据
extern "C" void init_persistent_kernel(std::vector<void *> meta_tensors,
void *profiler_buffer,
int my_rank,
int num_workers,
int num_local_schedulers,
int num_remote_schedulers,
int max_seq_length,
long long eos_token_id) {
// 断言:确保元数据张量数量为3(对应step、tokens、new_token_nums三个核心张量)
assert(meta_tensors.size() == 3);
// 将元数据张量指针转换为对应类型,赋值给全局运行时配置
global_runtime_config.step = static_cast<int *>(meta_tensors[0]); // 步骤标记张量(记录当前生成步骤)
global_runtime_config.tokens = static_cast<long long *>(meta_tensors[1]); // 生成的token序列张量
global_runtime_config.new_token_nums = static_cast<int *>(meta_tensors[2]);// 新增token数量张量
// 配置工作单元、调度器数量参数
global_runtime_config.num_workers = num_workers; // 工作单元(worker)总数
global_runtime_config.num_local_schedulers = num_local_schedulers; // 本地调度器数量
global_runtime_config.num_remote_schedulers = num_remote_schedulers; // 远程调度器数量(分布式场景)
// 配置序列生成相关参数
global_runtime_config.max_seq_length = max_seq_length; // 最大序列长度(token生成上限)
global_runtime_config.eos_token_id = eos_token_id; // 结束符token的ID
// 配置性能分析缓冲区(用于存储性能数据)
global_runtime_config.profiler_buffer = profiler_buffer;
// 计算总调度器数量(本地调度器 + 远程调度器)
int num_schedulers = num_local_schedulers + num_remote_schedulers;
// 初始化分布式通信库NVSHMEM(仅当启用USE_NVSHMEM宏时执行)
cudaSetDevice(my_rank); // 设置当前使用的GPU设备(对应分布式场景中的GPU编号)
#ifdef USE_NVSHMEM
MPI_Comm mpi_comm = MPI_COMM_WORLD; // 初始化MPI通信域(NVSHMEM依赖MPI实现分布式通信)
nvshmemx_init_attr_t attr = NVSHMEMX_INIT_ATTR_INITIALIZER; // 初始化NVSHMEM属性结构体
attr.mpi_comm = &mpi_comm; // 将MPI通信域绑定到NVSHMEM属性
nvshmemx_init_attr(NVSHMEMX_INIT_WITH_MPI_COMM, &attr); // 基于MPI通信域初始化NVSHMEM
nvshmem_barrier_all(); // 所有GPU进程同步,确保NVSHMEM初始化完成
// 获取NVSHMEM相关进程信息
int mype = nvshmem_my_pe(); // 当前GPU在NVSHMEM中的进程编号
int npes = nvshmem_n_pes(); // NVSHMEM中的总进程数(即GPU总数)
int mype_node = nvshmem_team_my_pe(NVSHMEMX_TEAM_NODE); // 当前进程在节点内的编号
// 打印进程信息(用于调试和日志记录)
printf("mype(%d) npes(%d) mype_node(%d)\n", mype, npes, mype_node);
#else
// 未启用NVSHMEM时,默认单GPU场景配置
int mype = 0; // 进程编号默认为0
int npes = 1; // 总进程数默认为1
#endif
// 配置队列长度参数(每个工作单元、调度器的队列容量)
global_runtime_config.per_worker_queue_len = 1024; // 每个工作单元队列的最大任务数
global_runtime_config.per_sched_queue_len = 1024; // 每个调度器队列的最大事件数
// 配置GPU相关参数
global_runtime_config.num_gpus = npes; // GPU总数(对应NVSHMEM的总进程数)
global_runtime_config.my_gpu_id = mype; // 当前GPU的编号
global_runtime_config.num_graphs = 1; // 内核图数量(默认1个)
global_runtime_config.split_worker_scheduler = true; // 启用工作单元与调度器分离的架构
// 声明任务、事件相关数据结构(用于存储任务描述、事件描述、初始任务列表)
std::vector<TaskDesc> all_tasks; // 所有任务的描述信息列表
std::vector<EventDesc> all_events; // 所有事件的描述信息列表(用于管理任务依赖)
std::vector<TaskId> first_tasks; // 初始任务ID列表(内核启动时首先执行的任务)
// 调用内部初始化函数,填充任务、事件、初始任务数据
_init_persistent_kernel(all_tasks, all_events, first_tasks, npes, mype);
// 初始化工作单元队列的"最后就绪任务ID"数组(GPU端内存分配)
// 每个工作单元维护两个队列(本地队列 + 远程队列),因此数组长度为2 * 工作单元数
global_runtime_config.worker_queue_last_ready_task_id =
gpu_malloc<unsigned long long int>((num_workers * 2) *
sizeof(unsigned long long int));
// 在主机端初始化该数组(初始值均为0,表示暂无就绪任务)
std::vector<unsigned long long int> host_worker_queue_last_task_id;
for (int i = 0; i < 2 * num_workers; i++) {
host_worker_queue_last_task_id.push_back(0);
}
// 将主机端数组数据拷贝到GPU端内存
cudaMemcpy(global_runtime_config.worker_queue_last_ready_task_id,
host_worker_queue_last_task_id.data(),
(num_workers * 2) * sizeof(unsigned long long int),
cudaMemcpyHostToDevice);
// 初始化调度器队列的"最后就绪事件ID"和"下一个空闲事件ID"数组(GPU端内存分配)
// 额外增加1个队列用于全局调度器,因此数组长度为 总调度器数 + 1
global_runtime_config.sched_queue_last_ready_event_id =
gpu_malloc<unsigned long long int>((num_schedulers + 1) *
sizeof(unsigned long long int));
global_runtime_config.sched_queue_next_free_event_id =
gpu_malloc<unsigned long long int>((num_schedulers + 1) *
sizeof(unsigned long long int));
// 在主机端初始化这两个数组(初始值均为0)
std::vector<unsigned long long int> host_sched_queue_last_event_id;
for (int i = 0; i < (num_schedulers + 1); i++) {
host_sched_queue_last_event_id.push_back(0);
}
// 将主机端数组数据拷贝到GPU端内存(两个数组初始值相同)
cudaMemcpy(global_runtime_config.sched_queue_last_ready_event_id,
host_sched_queue_last_event_id.data(),
(num_schedulers + 1) * sizeof(unsigned long long int),
cudaMemcpyHostToDevice);
cudaMemcpy(global_runtime_config.sched_queue_next_free_event_id,
host_sched_queue_last_event_id.data(),
(num_schedulers + 1) * sizeof(unsigned long long int),
cudaMemcpyHostToDevice);
// 初始化所有事件的计数器(GPU端内存分配)
global_runtime_config.all_event_counters =
gpu_malloc<EventCounter>(all_events.size() * sizeof(EventCounter)); // 事件触发计数器
global_runtime_config.all_event_num_triggers =
gpu_malloc<int>(all_events.size() * sizeof(int)); // 事件所需触发次数
// 在主机端初始化"事件所需触发次数"数组(从事件描述中读取对应值)
std::vector<int> host_all_event_counters;
for (size_t i = 0; i < all_events.size(); i++) {
host_all_event_counters.push_back(all_events.at(i).num_triggers);
}
// 将主机端数据拷贝到GPU端内存
cudaMemcpy(global_runtime_config.all_event_num_triggers,
host_all_event_counters.data(),
all_events.size() * sizeof(int),
cudaMemcpyHostToDevice);
// 将事件触发计数器初始化为0(所有事件初始未触发)
cudaMemset(global_runtime_config.all_event_counters,
0,
all_events.size() * sizeof(EventCounter));
// 初始化所有任务数据(将主机端任务描述拷贝到GPU端)
global_runtime_config.all_tasks =
gpu_malloc<TaskDesc>(all_tasks.size() * sizeof(TaskDesc));
cudaMemcpy(global_runtime_config.all_tasks,
all_tasks.data(),
all_tasks.size() * sizeof(TaskDesc),
cudaMemcpyHostToDevice);
// 初始化所有事件数据(将主机端事件描述拷贝到GPU端)
global_runtime_config.all_events =
gpu_malloc<EventDesc>(all_events.size() * sizeof(EventDesc));
cudaMemcpy(global_runtime_config.all_events,
all_events.data(),
all_events.size() * sizeof(EventDesc),
cudaMemcpyHostToDevice);
// 初始化工作单元队列(GPU端内存分配)
{
std::vector<TaskId *> host_worker_queues; // 主机端存储每个工作单元队列的GPU内存指针
// 为每个工作单元的两个队列分配GPU内存
for (int i = 0; i < (num_workers * 2); i++) {
TaskId *worker_queue = gpu_malloc<TaskId>(
global_runtime_config.per_worker_queue_len * sizeof(TaskId));
host_worker_queues.push_back(worker_queue);
}
// 分配GPU内存存储所有工作单元队列的指针
global_runtime_config.worker_queues =
gpu_malloc<TaskId *>((num_workers * 2) * sizeof(TaskId *));
// 将队列指针从主机端拷贝到GPU端
cudaMemcpy(global_runtime_config.worker_queues,
host_worker_queues.data(),
(num_workers * 2) * sizeof(TaskId *),
cudaMemcpyHostToDevice);
}
// 初始化调度器队列(GPU端内存分配)
{
std::vector<EventId *> host_sched_queues; // 主机端存储每个调度器队列的GPU内存指针
// 为每个调度器队列(含全局调度器队列)分配GPU内存
for (int i = 0; i < (num_schedulers + 1); i++) {
EventId *sched_queue = gpu_malloc<EventId>(
global_runtime_config.per_sched_queue_len * sizeof(EventId));
host_sched_queues.push_back(sched_queue);
}
// 分配GPU内存存储所有调度器队列的指针
global_runtime_config.sched_queues =
gpu_malloc<EventId *>((num_schedulers + 1) * sizeof(EventId *));
// 将队列指针从主机端拷贝到GPU端
cudaMemcpy(global_runtime_config.sched_queues,
host_sched_queues.data(),
(num_schedulers + 1) * sizeof(EventId *),
cudaMemcpyHostToDevice);
}
// 初始化初始任务数据(将主机端初始任务ID拷贝到GPU端)
{
global_runtime_config.first_tasks =
gpu_malloc<TaskId>(first_tasks.size() * sizeof(TaskId));
cudaMemcpy(global_runtime_config.first_tasks,
first_tasks.data(),
first_tasks.size() * sizeof(TaskId),
cudaMemcpyHostToDevice);
}
// 启动初始化内核(GPU端执行):配置网格和线程块维度(1个block,每个block含128个thread)
init_kernel<<<dim3(1, 1, 1), dim3(128, 1, 1)>>>(global_runtime_config);
cudaDeviceSynchronize(); // 等待GPU初始化内核执行完成
#ifdef USE_NVSHMEM
nvshmem_barrier_all(); // 分布式场景下,所有GPU进程同步,确保初始化全部完成
#endif
}
2.2 启动内核
launch_persistent_kernel是启动 CUDA 内核的入口函数,具体功能如下:
- 获取设备信息。
- 获取当前GPU设备编号
- 查询设备的SM数量,用于确定grid大小。
- 根据配置选择内核启动模式
- 模式一,分离式内核(split_worker_scheduler = true),这是默认模式,分别启动两个独立的内核。
- 线程块大小:128个线程;网格大小:num_local_schedulers;执行scheduler_kernel函数。
- 线程块大小:128个线程;网格大小:num_workers,每个线程块对应一个worker;执行worker_kernel函数。
- 为所有内核设置最大动态共享内存大小为 MAX_SHARE_MEMORY_SIZE。
- 使用cudaDeviceSynchronize等待内核启动完成。
- 模式二,单一持久化内核(split_worker_scheduler = false)
- 网格大小:sm_count(使用所有的sm);线程块大小:128个线程;调用persistent_kernel函数。
- 如果使用NVSHMEM,则使用nvshmemx_collective_launch启动,否则使用标准CUDA内核启动。
- 为所有内核设置最大动态共享内存大小为 MAX_SHARE_MEMORY_SIZE。
- 使用cudaDeviceSynchronize等待内核启动完成。
- 模式一,分离式内核(split_worker_scheduler = true),这是默认模式,分别启动两个独立的内核。
流程图如下:

代码如下。
// 外部C语言接口:Mirage持久化内核(MPK)的启动函数
// 根据运行时配置的架构模式(工作单元与调度器分离/一体化),启动对应的GPU内核
extern "C" void launch_persistent_kernel() {
int device;
// 获取当前正在使用的GPU设备编号
cudaGetDevice(&device);
int sm_count;
// 获取当前GPU设备的流式多处理器(SM)数量(用于一体化内核的网格维度配置)
cudaDeviceGetAttribute(&sm_count, cudaDevAttrMultiProcessorCount, device);
// 判断是否启用"工作单元与调度器分离"的架构模式
if (global_runtime_config.split_worker_scheduler) {
// 打印日志:标识当前启动的是分离模式(工作单元内核 + 调度器内核)
printf("worker kernel & scheduler kernel\n");
// 配置并启动工作单元内核与调度器内核
// 1. 设置工作单元内核的最大动态共享内存大小(使用预定义的最大共享内存常量)
cudaFuncSetAttribute(worker_kernel,
cudaFuncAttributeMaxDynamicSharedMemorySize,
MAX_SHARE_MEMORY_SIZE);
// 2. 设置调度器内核的最大动态共享内存大小
cudaFuncSetAttribute(scheduler_kernel,
cudaFuncAttributeMaxDynamicSharedMemorySize,
MAX_SHARE_MEMORY_SIZE);
// 创建两个独立的CUDA流:分别用于工作单元内核和调度器内核的异步执行
cudaStream_t worker_stream, scheduler_stream;
cudaStreamCreate(&worker_stream); // 工作单元内核专属流
cudaStreamCreate(&scheduler_stream); // 调度器内核专属流
// 注:分离模式不支持NVSHMEM分布式通信
// 原因:nvshmemx_collective_launch会串行启动内核,阻碍工作单元与调度器内核的交互
// 启动工作单元内核
worker_kernel<<<
dim3(global_runtime_config.num_workers, 1, 1), // 网格维度:工作单元数量 × 1 × 1(每个工作单元对应一个block)
dim3(128, 1, 1), // 线程块维度:128个thread × 1 × 1
MAX_SHARE_MEMORY_SIZE /* 动态共享内存大小 */,
worker_stream /* 绑定到工作单元专属流 */
>>>(global_runtime_config); // 传入全局运行时配置作为内核参数
// 启动调度器内核
scheduler_kernel<<<
dim3(global_runtime_config.num_local_schedulers, 1, 1), // 网格维度:本地调度器数量 × 1 × 1
dim3(32, 1, 1), // 线程块维度:32个thread × 1 × 1
0 /* 调度器内核无需动态共享内存,设为0 */,
scheduler_stream /* 绑定到调度器专属流 */
>>>(global_runtime_config); // 传入全局运行时配置作为内核参数
// 等待GPU上所有内核执行完成,并检查执行错误
cudaError_t err = cudaDeviceSynchronize();
if (err != cudaSuccess) {
// 若执行出错,打印错误信息(包含具体错误描述)
printf("CUDA kernel launch error: %s\n", cudaGetErrorString(err));
}
// 销毁创建的CUDA流,释放资源
cudaStreamDestroy(worker_stream);
cudaStreamDestroy(scheduler_stream);
// 打印日志:标识持久化内核启动流程完成
printf("Finished Launch Persistent Kernel\n");
} else {
// 打印日志:标识当前启动的是一体化模式(单个持久化内核)
printf("a single persistent kernel\n");
// 配置并启动一体化持久化内核
// 设置一体化内核的最大动态共享内存大小
cudaFuncSetAttribute(persistent_kernel,
cudaFuncAttributeMaxDynamicSharedMemorySize,
MAX_SHARE_MEMORY_SIZE);
#ifdef USE_NVSHMEM
// 若启用NVSHMEM分布式通信,使用NVSHMEM的集合式启动接口(适配多GPU协同)
void *args[] = {&global_runtime_config}; // 封装内核参数(全局运行时配置)
nvshmemx_collective_launch(
(void const *)persistent_kernel, // 待启动的一体化内核函数
dim3(sm_count, 1, 1), // 网格维度:GPU的SM数量 × 1 × 1(每个SM对应一个block)
dim3(128, 1, 1), // 线程块维度:128个thread × 1 × 1
args, // 内核参数数组
MAX_SHARE_MEMORY_SIZE /* 动态共享内存大小 */,
0 /* 不绑定特定流,使用默认流 */
);
#else
// 未启用NVSHMEM时,直接启动一体化内核(单GPU场景)
persistent_kernel<<<
dim3(sm_count, 1, 1), // 网格维度:SM数量 × 1 × 1
dim3(128, 1, 1), // 线程块维度:128个thread × 1 × 1
MAX_SHARE_MEMORY_SIZE /* 动态共享内存大小 */
>>>(global_runtime_config); // 传入全局运行时配置作为内核参数
#endif
// 等待GPU内核执行完成,并检查执行错误
cudaError_t err = cudaDeviceSynchronize();
if (err != cudaSuccess) {
// 若执行出错,打印错误信息
printf("CUDA kernel launch error: %s\n", cudaGetErrorString(err));
}
// 打印日志:标识持久化内核启动流程完成
printf("Finished Launch Persistent Kernel\n");
}
}
persistent_kernel、worker_kernel、scheduler_kernel的函数如下:
__global__ void persistent_kernel(RuntimeConfig config) {
persistent_checker(config);
if (blockIdx.x < config.num_workers) {
execute_worker(config);
} else {
execute_scheduler(config, -(4 * config.num_workers));
}
}
__global__ void worker_kernel(RuntimeConfig config) {
worker_checker(config);
execute_worker(config);
}
__global__ void scheduler_kernel(RuntimeConfig config) {
scheduler_checker(config);
execute_scheduler(config, 0);
}
2.3 Scheduler 实现
2.3.1 功能
execute_scheduler是 CUDA 内核中负责任务调度的核心函数,主要功能如下:
-
初始化和设置调度器
- 每个线程块处理4个调度器(int warp_thread_id = threadIdx.x % 32 / warp_id < 4)
- 依据调度器ID确定负责的工作节点范围。
- 区分本地调度器(处理本地任务)和远程调度器(处理跨GPU任务)的不同处理逻辑。这允许系统依据实际硬件环境和应用需求灵活调整调度器的数量和分工。
-
事件队列处理循环
函数进入一个无限循环,持续处理事件队列中的事件。
- 轮询调度队列,获取待处理的事件。
- 使用原子操作确保队列同步。
- 支持多个调度队列(本地和全局)。
-
事件分类处理。
依据事件类型进行不同处理。
- 终止事件
- 向所有工作节点发送终止任务。
- 结束调度器运行。
- 任务图结束事件 EVENT_END_OF_TASK_GRAPH。
- 调用prepare_next_batch检查是否继续下一批处理。
- 如果需要终止,则调用 terminate_schedulers
- 否则为下一次迭代启动新的任务图。
- 依赖任务事件 EVENT_LAUNCH_DEPENDENT_TASKS
- 增加迭代次数。
- 将任务分割给多个本地调度器,只有本地调度器才可以处理这类事件。
- 按照工作节点数量进行任务分组。
- 按照轮询方式将任务分配给工作节点。分配算法如下:
- 计算每轮需要的任务数量:e.last_task_id - e.first_task_id + config.num_workers - 1) / config.num_workers。
- 对每个工作节点进行迭代分配:
- 位置索引 = e.first_task_id + i * config.num_workers + j
- 如果索引在有效范围内,则分配给对应的工作节点。
- 使用next_worker变量实现轮询机制。
- 大规模任务事件 EVENT_LAUNCH_MASSIVE_TASKS
- 将任务分割给多个本地调度器,只有本地调度器才可以处理这类事件。
- 按照顺序将任务分发给对应的不同的工作节点,具体是使用get_first_last_ids来为每个调度器分配任务子集。
- 通过将大量任务均匀分配给所有本地调度器来实现负载均衡。每个调度器只处理分配给它的任务范围。
- 普通事件任务 EVENT_LAUNCH_TASKS
- 直接将任务分配给工作节点
- 使用轮询方式确保负载均衡
- 终止事件
2.3.2 流程
流程图如下。

2.3.3 要点
需要注意的地方如下:
-
任务分发机制
- 使用轮询方式将任务分发给工作节点。
- 维护每个工作节点的下一个可用任务位置。
- 使用原子操作确保线程安全的任务队列更新。
-
同步和可见性保证
- 使用 relaxed 和 accuire / release 语义确保内存操作的正确顺序。
- 通过原子操作维护队列状态。
- 支持NVSHMEM的跨GPU通信
-
任务间的依赖关系
-
通过任务描述符中的 dependent_event字段建立任务间的依赖关系。
-
在执行任务前检查依赖是否满足。
-
使用计数机制确保依赖任务按照正确顺序执行。
-
任务索引计算:size_t position_index = e.first_task_id + i * config.num_workers + j; 通过这种方式,系统可以将连续的任务按顺序分配给不同的工作单元。
-
处理依赖任务时,会
- 迭代编号更新。增加iteration_num,表示进入新的迭代
- 轮询分配:依赖任务通过轮询方式分配给工作队列,确保任务在worker之间均匀分布。
- 本地调度器专用:依赖任务只能由本地调度器处理,远程调度器不处理这种任务。
- 在execute_worker 中,系统会检查任务的依赖关系。当一个任务完成时,会触发相应事件,具备依赖关系的任务会放入广播队列中处理。
-
-
每个线程块处理4个调度器
-
int warp_thread_id = threadIdx.x % 32; --- 128 / 32 = 4,每个warp对应一个调度器实例。每个调度器由足够的线程资源(32个),这样可以:充分利用硬件资源,将调度器均匀分布在多个线程块中,避免单点瓶颈;避免过多调度器并行导致资源竞争;简化调度器的同步和通信。
-
在 persistent_checker 中,有
assert(num_schedulers % 4 == 0); assert(gridDim.x == config.num_workers + num_schedulers / 4);这说明,如果有 N 个调度器,就需要 N/4个线程块来处理,每个线程块处理4个调度器。假设12个调度器,则需要3个线程块来处理所有调度器。线程块0处理调度器03,线程块1处理调度器47。
-
只有warp中第一个线程(warp_thread_id == 0)实际执行调度器策略,其它线程处于空闲状态(可能未来会扩展或者执行辅助任务)。
-
-
远程调度器:
- 使用场景
- 多GPU环境中的跨GPU通信任务。当系统配置多个GPU时,需要使用远程调度器处理GPU间的通信任务。尤其是处理ALLREDUCE等操作。
- NVSHEMEM相关任务。比如处理TASK_NVSHMEM_COPY任务时,需要远程调度器。这些任务需要在不同GPU之间复制数据。
- 负责
- 协调不同GPU之间的任务执行顺序
- 处理跨GPU的数据传输
- 确保全局唯一性。
- 使用场景
通过get_first_last_ids将工作负载划分给不同的调度器。
__device__ __forceinline__ void
get_first_last_ids(unsigned long long int num_elements,
unsigned long long int num_workers,
unsigned long long int my_id,
unsigned long long int *my_first_element,
unsigned long long int *my_last_element) {
unsigned long long int num_elements_per_worker = num_elements / num_workers;
unsigned long long int reminder = num_elements % num_workers;
if (my_id < reminder) {
*my_first_element = (num_elements_per_worker + 1) * my_id;
*my_last_element = *my_first_element + num_elements_per_worker + 1;
} else {
*my_first_element = num_elements_per_worker * my_id + reminder;
*my_last_element = *my_first_element + num_elements_per_worker;
}
}
2.3.4 代码
// 设备端函数:执行调度器逻辑(每个线程块仅有一个warp参与,需注意同步限制)
// 功能:从调度器队列读取事件,解析事件类型并生成对应的任务,分配至工作单元队列
__device__ void execute_scheduler(RuntimeConfig config, int offset) {
// 计算总调度器数量(本地调度器 + 远程调度器)
int num_schedulers =
config.num_local_schedulers + config.num_remote_schedulers;
// 计算当前线程在warp内的ID(0-31,因每个线程块仅一个warp,简化同步逻辑)
int warp_thread_id = threadIdx.x % 32;
// 以下逻辑禁止使用__syncthreads(),避免跨warp同步导致的效率损失
// 仅warp内ID为0的线程执行调度核心逻辑(单线程负责调度决策,减少资源竞争)
if (warp_thread_id == 0) {
// 计算当前调度器的全局ID(偏移量+块索引,区分不同调度器实例)
int sched_id = blockIdx.x + offset;
// 初始化调度器队列相关参数
int num_sched_queues = 1; // 调度器需处理的队列数量(初始为1)
size_t iteration_num = 0; // 当前迭代次数(用于任务ID生成)
EventId *sched_queues[2]; // 调度器需监听的事件队列指针(最多2个)
int sched_queue_ids[2]; // 队列对应的全局ID
// 绑定当前调度器的专属队列
sched_queues[0] = config.sched_queues[sched_id];
sched_queue_ids[0] = sched_id;
// 用于记录当前调度器管理的工作单元ID范围
unsigned long long int my_first_worker, my_last_worker;
// 区分本地调度器与远程调度器的逻辑
if (sched_id < config.num_local_schedulers) {
// 本地调度器额外处理全局队列的事件(多队列监听)
sched_queues[num_sched_queues] = config.sched_queues[num_schedulers];
sched_queue_ids[num_sched_queues] = num_schedulers;
num_sched_queues++; // 队列数量增至2
// 计算本地调度器管理的工作单元ID范围(从总工作单元中分配)
get_first_last_ids(config.num_workers,
config.num_local_schedulers,
sched_id,
&my_first_worker,
&my_last_worker);
} else {
// 远程调度器管理的工作单元ID范围(偏移总工作单元数,避免与本地冲突)
get_first_last_ids(config.num_workers,
config.num_remote_schedulers,
sched_id - config.num_local_schedulers, // 远程调度器的本地索引
&my_first_worker,
&my_last_worker);
// 远程工作单元ID从总工作单元数开始编号
my_first_worker += config.num_workers;
my_last_worker += config.num_workers;
}
// 调试日志:打印调度器ID及管理的工作单元范围(仅MPK_ENABLE_VERBOSE启用时)
#ifdef MPK_ENABLE_VERBOSE
printf("[SCHD] sched_id(%d) first_worker(%llu) last_worker(%llu)\n",
sched_id,
my_first_worker,
my_last_worker);
#endif
// 初始化队列位置跟踪变量:当前处理位置与最新事件位置(支持2个队列)
size_t cur_event_pos[2], last_event_pos[2];
for (int i = 0; i < 2; i++) {
cur_event_pos[i] = 0; // 当前已处理的事件索引
last_event_pos[i] = 0; // 队列中最新的事件索引
}
// 记录每个工作单元队列的下一个空闲位置(避免原子操作开销,本地缓存)
size_t worker_queue_next_free_task_pos[MAX_WORKER_PER_SCHEDULER];
for (int i = 0; i < MAX_WORKER_PER_SCHEDULER; i++) {
worker_queue_next_free_task_pos[i] = 0;
}
// 特殊初始化:ID为0的调度器首个工作单元的队列起始位置设为1
if (sched_id == 0) {
worker_queue_next_free_task_pos[0] = 1;
}
// 任务分配的工作单元迭代变量(轮询分配时使用)
int next_worker = my_first_worker;
// 当前监听的队列索引(初始为0)
int queue_idx = 0;
// 调度主循环(持续运行,直至收到终止事件)
while (true) {
// 等待队列中有新事件:循环检查当前队列是否有未处理事件
while (cur_event_pos[queue_idx] == last_event_pos[queue_idx]) {
// 使用acquire语义读取最新的事件位置(确保数据可见性)
last_event_pos[queue_idx] = ld_acquire_gpu_u64(
&config
.sched_queue_last_ready_event_id[sched_queue_ids[queue_idx]]);
// 若当前队列有新事件,退出等待;否则切换到下一个队列
if (cur_event_pos[queue_idx] < last_event_pos[queue_idx]) {
break;
} else {
queue_idx = (queue_idx == num_sched_queues - 1) ? 0 : queue_idx + 1;
}
// 短暂休眠(10纳秒),避免空循环占用过多资源
__nanosleep(10);
}
// 断言:确保调度器队列未溢出(当前位置+队列长度需大于最新事件位置)
assert(cur_event_pos[queue_idx] + config.per_sched_queue_len >
last_event_pos[queue_idx]);
// 读取当前待处理的事件ID(使用relaxed语义,平衡性能与可见性)
EventId event_id = ld_relaxed_gpu_u64(
&sched_queues[queue_idx]
[cur_event_pos[queue_idx] % config.per_sched_queue_len]);
// 获取事件描述信息
EventDesc e = config.all_events[event_id];
// 检查是否为终止事件(退出调度循环)
if (is_termination_event(event_id, e)) {
// 若为本地调度器,向其管理的所有工作单元发送终止任务(ID=0)
if (sched_id < config.num_local_schedulers) {
for (int i = my_first_worker; i < my_last_worker; i++) {
// 获取工作单元队列的下一个空闲位置
size_t last_task_id =
worker_queue_next_free_task_pos[i - my_first_worker]++;
// 写入终止任务ID(0)
st_relaxed_gpu_u64(
&config.worker_queues[i][last_task_id %
config.per_worker_queue_len],
0);
// 使用release语义更新工作单元队列的最新就绪任务ID(确保任务可见)
atom_add_release_gpu_u64(&config.worker_queue_last_ready_task_id[i],
1);
}
}
// 退出调度器
return;
}
// 处理"任务图结束"事件(EVENT_END_OF_TASK_GRAPH)
if (e.event_type == EVENT_END_OF_TASK_GRAPH) {
#ifdef MPK_ENABLE_VERBOSE
printf("[SCHD] END_OF_TASK_GRAPH\n");
#endif
// 检查是否需要准备下一批次任务
if (!prepare_next_batch(config)) {
// 无需继续,终止所有调度器
terminate_schedulers(config);
} else {
// 为下一次迭代启动"任务图开始"任务(ID=1)
size_t last_task_id =
worker_queue_next_free_task_pos[next_worker - my_first_worker]++;
// 计算任务ID(迭代次数+任务索引)并写入工作单元队列
st_relaxed_gpu_u64(
&config.worker_queues[next_worker]
[last_task_id % config.per_worker_queue_len],
compute_task_id(iteration_num + 1, 1 /*begin_task_graph*/));
// 更新工作单元队列的最新就绪任务ID
atom_add_release_gpu_u64(
&config.worker_queue_last_ready_task_id[next_worker], 1);
#ifdef MPK_ENABLE_VERBOSE
// 打印调试信息:GPU ID、调度器ID、迭代次数、任务索引、工作单元ID等
printf("[%d][SCHD]EVENT_END_OF_TASK_GRAPH schd_id(%d) "
"iter_num(%llu) task_idx(1) "
"worker_id(%d) "
"worker_last_ready_pos(%llu)\n",
config.my_gpu_id,
sched_id,
iteration_num + 1,
next_worker,
last_task_id + 1);
#endif
// 轮询切换到下一个工作单元
next_worker = (next_worker == my_last_worker - 1) ? my_first_worker
: next_worker + 1;
}
}
// 处理"启动依赖任务"事件(EVENT_LAUNCH_DEPENDENT_TASKS)
else if (e.event_type == EVENT_LAUNCH_DEPENDENT_TASKS) {
// 迭代次数递增(标识新一批任务)
iteration_num = iteration_num + 1;
// 断言:该事件仅由本地调度器处理
assert(sched_id < config.num_local_schedulers);
// 按工作单元数量拆分任务范围,轮询分配给管理的工作单元
for (size_t i = 0;
i < (e.last_task_id - e.first_task_id + config.num_workers - 1) /
config.num_workers;
i++) {
for (size_t j = my_first_worker; j < my_last_worker; j++) {
// 计算当前任务在全局范围内的索引
size_t position_index =
e.first_task_id + i * config.num_workers + j;
// 仅处理范围内的任务
if (position_index < e.last_task_id) {
// 获取工作单元队列的下一个空闲位置
size_t last_task_id =
worker_queue_next_free_task_pos[next_worker -
my_first_worker]++;
// 计算任务ID并写入工作单元队列
st_relaxed_gpu_u64(
&config
.worker_queues[next_worker][last_task_id %
config.per_worker_queue_len],
compute_task_id(iteration_num, position_index));
// 更新工作单元队列的最新就绪任务ID
atom_add_release_gpu_u64(
&config.worker_queue_last_ready_task_id[next_worker], 1);
// 轮询切换到下一个工作单元
next_worker = (next_worker == my_last_worker - 1)
? my_first_worker
: next_worker + 1;
}
}
}
}
// 处理其他类型事件(如EVENT_LAUNCH_MASSIVE_TASKS)
else {
// 初始化当前调度器需处理的任务范围
TaskId my_first_task = e.first_task_id, my_last_task = e.last_task_id;
// 若为"启动大规模任务"事件,按本地调度器数量拆分任务范围
if (e.event_type == EVENT_LAUNCH_MASSIVE_TASKS) {
assert(sched_id < config.num_local_schedulers); // 仅本地调度器处理
// 计算当前调度器负责的子任务范围
get_first_last_ids(e.last_task_id - e.first_task_id,
config.num_local_schedulers,
sched_id,
&my_first_task,
&my_last_task);
// 映射到全局任务ID范围
my_first_task += e.first_task_id;
my_last_task += e.first_task_id;
}
// 遍历任务范围,将任务分配给工作单元(轮询策略)
for (size_t i = my_first_task; i < my_last_task; i++) {
// 获取工作单元队列的下一个空闲位置
size_t last_task_id =
worker_queue_next_free_task_pos[next_worker - my_first_worker]++;
// 计算任务ID并写入工作单元队列
st_relaxed_gpu_u64(
&config.worker_queues[next_worker]
[last_task_id % config.per_worker_queue_len],
compute_task_id(iteration_num, i));
// 更新工作单元队列的最新就绪任务ID
atom_add_release_gpu_u64(
&config.worker_queue_last_ready_task_id[next_worker], 1);
// 轮询切换到下一个工作单元
next_worker = (next_worker == my_last_worker - 1) ? my_first_worker
: next_worker + 1;
}
}
// 移动到下一个事件
cur_event_pos[queue_idx] += 1;
}
}
}
2.4 Worker实现
execute_worker 是 Mirage 持久化内核(MPK)中工作单元的核心设备端函数,运行于 GPU 线程块上,负责任务的获取、依赖检查、执行及后续事件触发,是 MPK 内核中实际承载计算任务的核心组件。其流程逻辑可分为五大核心阶段,形成 “任务获取 — 数据准备 — 依赖等待 — 任务执行 — 事件触发” 的完整闭环:
2.4.1 功能
每个block对应一个worker。execute_worker函数负责从任务队列中获取任务并执行,主要功能如下:
-
初始化和设置。
函数首先初始化线程块内的共享内存(存储任务 ID 和任务描述),并根据当前工作单元 ID 绑定对应的本地任务队列;在多 GPU 场景下,额外绑定远程队列以接收跨 GPU 任务。同时完成性能分析器的初始化(若启用),为后续任务执行监控做好准备。此阶段的核心目标是建立工作单元与任务队列的关联,明确任务来源。
-
任务获取循环。
任务获取。会等待任务队列中有可用任务;使用原子操作确保线程安全;从共享内存中加载任务描述。
仅线程块内第 0 个线程执行任务获取逻辑:通过轮询监听本地 / 远程队列,使用 acquire 语义读取队列的最新就绪任务位置,若队列无新任务则短暂休眠并切换队列;若有新任务则读取任务 ID,并通过共享内存同步给线程块内其他线程。随后,线程块内线程并行将任务描述从全局内存拷贝到共享内存(提升访问效率),并通过线程块同步确保数据拷贝完成。
函数主体是无限循环,持续从任务队列中获取任务。其中,线程0(threadIdx.x == 0)负责协调,其它线程协助数据加载。
while(true) { // 获取下一个任务。 // 执行任务 // 触发事件 } -
任务依赖检查阶段
任务依赖检查。检查任务是否有依赖事件,如果有依赖,则等待依赖事件完成足够的触发次数;使用事件计步器进行同步。
仅第 0 个线程检查当前任务是否存在依赖事件:若存在有效依赖事件,计算该任务所需的事件触发次数,循环等待直至事件触发次数满足需求(使用 acquire 语义读取事件计数器,确保数据可见性)。此阶段通过精准的依赖管理,保证任务执行的顺序正确性,避免因数据未就绪导致的计算错误。
-
任务执行
根据任务类型执行差异化逻辑:
- 终止任务TASK_TERMINATE:直接退出工作单元循环,结束执行;
- 任务图开始任务TASK_BEGIN_TASK_GRAPH:无实际计算逻辑,仅作为流程标记;
- NVSHMEM 拷贝任务TASK_NVSHMEM_COPY:调用分布式通信接口完成跨 GPU 数据传输,并触发远程事件信号;
- 归约任务TASK_REDUCE:调用专用归约内核,处理多 GPU 场景下的二维归约计算;
- 其他任务:通过通用任务执行函数_execute_task(task_desc, config);
-
事件触发与队列更新阶段
任务执行完成后,仅第 0 个线程触发对应的事件:
- 本地事件:原子累加事件计数器,若触发次数达到当前迭代需求,将事件加入调度器队列(大规模任务事件加入全局队列,其他事件随机分配给本地调度器),并通过 CAS 操作更新调度器队列的就绪状态;
- 远程事件:依赖 NVSHMEM 拷贝任务在数据传输时自动触发信号,此处仅打印调试日志。
2.4.2 流程
流程图如下:

2.4.3 代码
execute_worker
execute_worker的代码如下。
// 设备端函数:执行工作单元逻辑(Worker)
// 功能:从工作单元队列读取任务,处理任务依赖,执行具体任务逻辑,并触发后续事件
__device__ void execute_worker(RuntimeConfig config) {
// 共享内存变量:存储当前待执行的任务ID和任务描述(线程块内线程共享)
__shared__ TaskId cur_task_id;
__shared__ TaskDesc task_desc;
// 性能分析相关初始化(仅MPK_ENABLE_PROFILING宏启用时执行)
#ifdef MPK_ENABLE_PROFILING
PROFILER_CLOSURE_PARAMS_DECL; // 声明性能分析闭包参数
// 初始化性能分析器:传入缓冲区指针、GPU ID等参数,仅线程块内第0个线程执行初始化
PROFILER_INIT(static_cast<uint64_t *>(config.profiler_buffer),
0,
1,
(threadIdx.x % 128 == 0));
#endif
// 当前工作单元的ID(由线程块索引blockIdx.x标识,每个工作单元对应一个线程块)
int worker_id = blockIdx.x;
// 共享内存变量:存储工作单元队列指针及对应的队列ID(支持本地和远程队列)
__shared__ TaskId *worker_queues[2];
__shared__ int worker_queue_ids[2];
// 获取当前工作单元的本地队列指针
TaskId *local_worker_queue = config.worker_queues[worker_id];
worker_queues[0] = local_worker_queue;
worker_queue_ids[0] = worker_id;
int num_worker_queues = 1; // 工作单元队列数量(初始为1个本地队列)
// 多GPU场景下,额外绑定远程队列(用于接收其他GPU的任务)
if (config.num_gpus > 1) {
TaskId *remote_worker_queue =
config.worker_queues[worker_id + config.num_workers];
worker_queues[num_worker_queues] = remote_worker_queue;
worker_queue_ids[num_worker_queues] = worker_id + config.num_workers;
num_worker_queues++; // 队列数量增至2(本地+远程)
}
// 记录每个队列当前处理的任务位置(线程私有变量)
size_t cur_task_pos[2];
// 共享内存变量:记录每个队列最新的任务位置(线程块内同步)
__shared__ size_t last_task_pos[2];
// 初始化当前任务位置为0
for (int i = 0; i < 2; i++) {
cur_task_pos[i] = 0;
}
// 仅线程块内第0个线程初始化最新任务位置为0
if (threadIdx.x == 0) {
for (int i = 0; i < 2; i++) {
last_task_pos[i] = 0;
}
}
// 当前监听的队列索引(初始为0)
int queue_idx = 0;
#ifdef MPK_ENABLE_PROFILING
size_t task_counter = 0; // 任务计数器(用于性能分析事件标记)
#endif
// 工作单元主循环(持续读取并执行任务,直至收到终止任务)
while (true) {
// 阶段1:从任务队列获取下一个任务(仅第0个线程执行,避免多线程竞争)
if (threadIdx.x == 0) {
// 等待队列中有新任务:循环检查当前队列是否有未处理任务
while (cur_task_pos[queue_idx] == last_task_pos[queue_idx]) {
// 使用acquire语义读取队列最新就绪任务位置(确保数据可见性)
last_task_pos[queue_idx] = ld_acquire_gpu_u64(
&config
.worker_queue_last_ready_task_id[worker_queue_ids[queue_idx]]);
// 若当前队列有新任务则退出等待,否则切换到下一个队列
if (cur_task_pos[queue_idx] < last_task_pos[queue_idx]) {
break;
} else {
queue_idx = (queue_idx == num_worker_queues - 1) ? 0 : queue_idx + 1;
}
// 短暂休眠(10纳秒),避免空循环占用过多GPU资源
__nanosleep(10);
}
// 断言:确保工作单元队列未溢出
assert(cur_task_pos[queue_idx] + config.per_worker_queue_len >
last_task_pos[queue_idx]);
// 读取当前待执行的任务ID(使用relaxed语义平衡性能与可见性)
cur_task_id = ld_relaxed_gpu_u64(
&worker_queues[queue_idx][cur_task_pos[queue_idx] %
config.per_worker_queue_len]);
}
// 线程块内同步:确保第0个线程读取任务ID后,其他线程再继续执行
__syncthreads();
// 阶段2:将任务描述从全局内存拷贝到共享内存(线程块内并行拷贝,提升访问效率)
// 转换任务描述的内存指针类型(按int粒度拷贝,适配线程并行)
int *smem_as_int = reinterpret_cast<int *>(&task_desc);
int const *dmem_as_int = reinterpret_cast<int *>(
config.all_tasks + get_task_position_index(cur_task_id));
// 线程块内线程分工拷贝:每个线程负责部分数据,步长为线程块大小
for (int i = threadIdx.x; i * sizeof(int) < sizeof(TaskDesc);
i += blockDim.x) {
smem_as_int[i] = dmem_as_int[i];
}
// 线程块内同步:确保任务描述拷贝完成后,再执行后续逻辑
__syncthreads();
// 阶段3:检查并等待任务依赖的事件完成(仅第0个线程执行)
if (threadIdx.x == 0) {
// 若任务存在依赖事件(非无效事件ID)
if (task_desc.dependent_event != EVENT_INVALID_ID) {
// 等待依赖事件触发足够次数
EventId event_id = task_desc.dependent_event;
assert(!is_nvshmem_event(event_id)); // 断言:非NVSHMEM远程事件
assert(get_event_gpu_id(event_id) == config.my_gpu_id); // 断言:事件属于当前GPU
size_t event_index = get_event_position_index(event_id); // 获取事件全局索引
// 计算当前任务所需的事件触发次数(总触发次数 × 任务迭代次数)
EventCounter needed_counts =
static_cast<EventCounter>(
config.all_event_num_triggers[event_index]) *
get_task_iteration_num(cur_task_id);
EventCounter actual_counts = 0;
// 循环等待,直至事件触发次数满足需求
while (actual_counts < needed_counts) {
actual_counts =
ld_acquire_gpu_u64(&config.all_event_counters[event_index]);
__nanosleep(10);
}
}
}
// 线程块内同步:确保依赖事件处理完成后,所有线程同步执行任务
__syncthreads();
// 性能分析:记录任务执行开始(非终止任务才记录)
#ifdef MPK_ENABLE_PROFILING
if (task_desc.task_type != TASK_TERMINATE) {
PROFILER_EVENT_START(task_desc.task_type, task_counter);
}
#endif
// 阶段4:执行具体任务(根据任务类型分支处理)
if (task_desc.task_type == TASK_TERMINATE) {
// 终止任务:退出工作单元循环
return;
} else if (task_desc.task_type == TASK_BEGIN_TASK_GRAPH) {
// 任务图开始任务:无实际执行逻辑(仅作为流程标记)
} else if (task_desc.task_type == TASK_NVSHMEM_COPY) {
// NVSHMEM拷贝任务(仅启用USE_NVSHMEM时执行,用于多GPU数据传输)
#ifdef USE_NVSHMEM
// 计算拷贝数据的字节大小(基于输入张量维度)
size_t size_in_bytes = 2;
for (int i = 0; i < task_desc.inputs[0].num_dims; i++) {
size_in_bytes *= task_desc.inputs[0].dim[i];
}
size_t event_index = get_event_position_index(task_desc.trigger_event); // 触发事件索引
int gpu_id = static_cast<int>(get_event_gpu_id(task_desc.trigger_event)); // 目标GPU ID
assert(gpu_id < config.num_gpus); // 断言:目标GPU ID有效
assert(gpu_id != config.my_gpu_id); // 断言:目标为远程GPU
// 调用NVSHMEM接口执行块拷贝,并触发事件信号
nvshmemx_putmem_signal_block(
task_desc.outputs[0].base_ptr, // 目标地址(远程GPU)
task_desc.inputs[0].base_ptr, // 源地址(本地GPU)
size_in_bytes, // 拷贝字节数
reinterpret_cast<uint64_t *>(&config.all_event_counters[event_index]), // 事件计数器
1 /*信号值*/,
NVSHMEM_SIGNAL_ADD, // 信号操作类型(累加)
gpu_id // 目标GPU ID
);
#endif
} else if (task_desc.task_type == TASK_REDUCE) {
// 归约任务:支持二维归约,输入缓冲区包含多GPU维度
assert(task_desc.inputs[0].num_dims == 2); // 断言:输入1为2维张量
assert(task_desc.inputs[1].num_dims == 3); // 断言:输入2为3维张量(含GPU维度)
// 调用归约内核执行计算(数据类型为bfloat16)
kernel::reduction_kernel<bfloat16>(
task_desc.inputs[0].base_ptr, // 输入1数据指针
task_desc.inputs[1].base_ptr, // 输入2数据指针
task_desc.outputs[0].base_ptr, // 输出数据指针
config.num_gpus, // GPU总数
config.my_gpu_id, // 当前GPU ID
task_desc.inputs[0].dim[0], // 输入1维度0大小
task_desc.inputs[0].dim[1], // 输入1维度1大小
task_desc.inputs[0].stride[0]); // 输入1维度0步长
} else {
// 其他类型任务:调用通用任务执行函数
#ifdef MPK_ENABLE_VERBOSE
// 调试日志:仅第0个线程块的第0个线程打印任务执行信息
if (threadIdx.x == 0 && blockIdx.x == 0) {
printf("[worker] _execute_task EXECUTE_TASK %d\n", task_desc.task_type);
}
#endif
_execute_task(task_desc, config);
}
// 线程块内同步:确保任务执行完成后,再处理后续事件触发逻辑
__syncthreads();
// 性能分析:记录任务执行结束
#ifdef MPK_ENABLE_PROFILING
if (task_desc.task_type != TASK_TERMINATE) {
PROFILER_EVENT_END(task_desc.task_type, task_counter++);
}
#endif
// 阶段5:任务执行完成后,触发对应的事件(仅第0个线程执行)
if (threadIdx.x == 0) {
EventId event_id = task_desc.trigger_event; // 任务对应的触发事件ID
size_t event_index = get_event_position_index(event_id); // 事件全局索引
// 分支1:处理本地事件(非NVSHMEM事件)
if (!is_nvshmem_event(event_id)) {
size_t gpu_id = get_event_gpu_id(event_id);
assert(gpu_id == config.my_gpu_id); // 断言:事件属于当前GPU
// 原子操作累加事件计数器(使用release语义确保可见性)
EventCounter count = atom_add_release_gpu_u64(
&config.all_event_counters[event_index], 1);
int num_triggers = config.all_event_num_triggers[event_index]; // 事件总需触发次数
// 若事件触发次数达到当前迭代所需总量,将事件加入调度器队列
if ((count + 1) == static_cast<EventCounter>(num_triggers) *
get_task_iteration_num(cur_task_id)) {
#ifdef MPK_ENABLE_PROFILING
PROFILER_EVENT_START(TASK_SCHD_EVENTS, task_counter); // 记录调度事件开始
#endif
EventDesc event_desc = config.all_events[event_index]; // 获取事件描述
// 空事件不做处理,其他事件加入调度器队列
if (event_desc.event_type != EVENT_EMPTY) {
bool use_bcast_queue = false;
// 大规模任务、依赖任务事件使用全局广播队列
if (event_desc.event_type == EVENT_LAUNCH_MASSIVE_TASKS ||
event_desc.event_type == EVENT_LAUNCH_DEPENDENT_TASKS) {
use_bcast_queue = true;
}
// 确定事件对应的调度器ID
int sched_id =
use_bcast_queue
? config.num_local_schedulers + config.num_remote_schedulers // 全局调度器
: get_rand_sched_id(event_index,
worker_id,
config.num_workers,
config.num_local_schedulers); // 随机分配本地调度器
// 原子操作获取调度器队列的下一个空闲位置
size_t last_event_pos = atom_add_release_gpu_u64(
&config.sched_queue_next_free_event_id[sched_id], 1);
// 将事件索引写入调度器队列
st_relaxed_gpu_u64(
&config.sched_queues[sched_id][last_event_pos %
config.per_sched_queue_len],
event_index);
// 使用CAS操作更新调度器队列的最新就绪事件ID(确保原子性)
size_t old;
do {
old = atom_cas_release_gpu_u64(
&config.sched_queue_last_ready_event_id[sched_id],
last_event_pos,
last_event_pos + 1);
} while (old != last_event_pos);
}
#ifdef MPK_ENABLE_PROFILING
PROFILER_EVENT_END(TASK_SCHD_EVENTS, task_counter++); // 记录调度事件结束
#endif
}
} else {
// 分支2:处理NVSHMEM远程事件(仅NVSHMEM拷贝任务触发)
assert(task_desc.task_type == TASK_NVSHMEM_COPY); // 断言:任务类型为NVSHMEM拷贝
// 注:NVSHMEM拷贝任务在数据传输时已触发信号计数器,此处无需额外操作
}
// 移动到当前队列的下一个任务位置
cur_task_pos[queue_idx] += 1;
}
}
}
_execute_task
_execute_task 代码定义在print_task_graph中,此处从task.second[variant_id]获取可以执行代码。具体如下:
code.e("__device__ __forceinline__");
code.e("void _execute_task(TaskDesc const& task_desc,");
code.e(" RuntimeConfig const &runtime_config) {");
TaskRegister *task_register = TaskRegister::get_instance();
bool first_task = true;
for (auto const &task : task_register->all_task_variants) {
for (size_t variant_id = 0; variant_id < task.second.size(); variant_id++) {
std::string cond = first_task ? "if" : "else if";
assert(task_type_to_name.find(task.first) != task_type_to_name.end());
code.e("$ (task_desc.task_type == $ && task_desc.variant_id == $) {",
cond,
task_type_to_name[task.first],
variant_id);
code.e("$", task.second[variant_id]);
code.e("}");
first_task = false;
}
}
code.e("}");
2.5 并发执行
总体并发策略如下:
-
工作线程与调度线程分离。
-
任务流水线:计算任务和通信任务可以流水线执行,当一个任务在等待通信完成时,其它任务可以继续执行计算。
-
事件驱动:通过事件机制实现任务间的依赖管理,不需要阻塞等待。
__device__ __forceinline__ bool is_nvshmem_event(EventId event_id) { return (event_id & EVENT_NVSHMEM_TAG) > 0; } -
多队列管理:使用多个工作队列和调度队列来管理不同类型的任务。
-
异步通信:利用NVSHMEM的异步通信能力,在执行计算的同时进行数据传输。任务为TASK_NVSHMEM_COPY。
这种设计允许计算任务和通信操作重叠执行,从而提高总体执行效率。
流程如下:
- 初始化阶段:通过NVSHMEM初始化多GPU环境。
- 任务分发:调度器将大型任务分片分配给不同GPU。
- 本地计算:每个GPU处理分配给自己的数据分片。
- 跨GPU通信:使用NVSHMEM进行数据同步和通信。
- 结果规约:通过TASK_REDUCE任务合并各个GPU的计算结果。
0xFF 参考
如何评价CMU将LLM转化为巨型内核的Mirage Persistent Kernel(MPK)工作?
Mirage: A Multi-Level Superoptimizer for Tensor Programs 简记 尘伊光
OSDI2025论文笔记:Mirage: A Multi-Level Superoptimizer for Tensor Programs 画饼充饥
Mirage: A Compiler for High-Performance Tensor Programs on GPUs
https://mirage-project.readthedocs.io/en/latest/mugraph.html
https://mirage-project.readthedocs.io/en/latest/transpiler.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号