K近邻算法核心函数详解
#用于分类的输入测试样本是inX,输入的训练样本集为dataSet, #标签向量为 labels ,最后的参数 k 表示用于选择最近邻居的数目,其中标签向量的元素数目和矩阵 dataSet 的行数相同。 def classify0(inX,dataSet,labels,k): dataSetSize = dataSet.shape[0] # 获取 数组 形状的 第一个 参数 a=[[1,2],[1,2],[1,2]] a.shape = [3,2] a.shape[0] = 3 diffMat = tile(inX,(dataSetSize,1)) - dataSet # tile 代表了inX,复制为dataSetSize行,1列的数组 sqDiffMat = diffMat**2 # 平方 sqDistances = sqDiffMat.sum(axis = 1) # axis 等于 1 是将 矩阵的每一行 相加 distances = sqDistance**0.5 # 开方 sortedDistIndicies = distances.argsort() # 从小到大 排列 classCount = {} for i in range(k): # 求出来 最低距离 的 labels结果,存放在classCount 中 voteIlabel = labels[sortedDistIndicies[i]] #取出前k个元素的类别 classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 #存到字典里面去 sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1),reverse =True) #用键来排序 return sortedClassCount[0][0] #取键
用断点来查看程序执行过程:

第一轮过后:classCount内开始有数据了
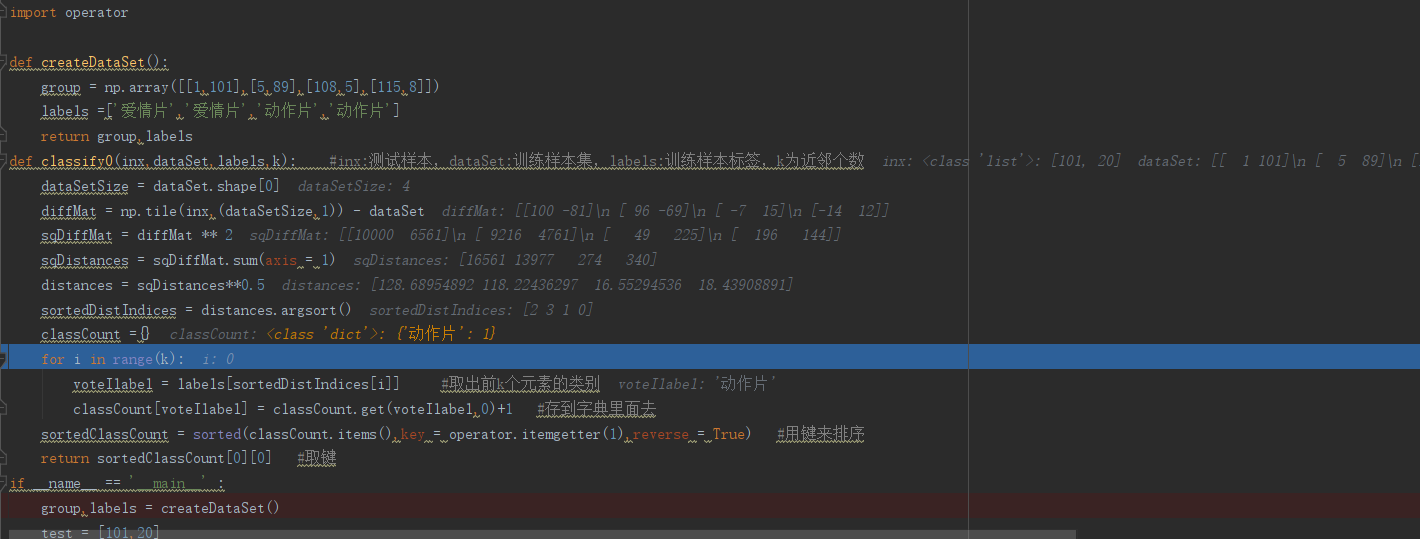
最终结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号