Python开发【第二篇】:基础数据类型
内容概要
- 格式化输出
- 运算符
- 编码
- 基本数据类型
- 深浅拷贝、小数据池
1、格式化输出
# %s 占位字符串. 实际上可以占位任何东西(用的最多的)
# %d 占位整数. 只能占位数字
# name = "wusir" # hobby = "打篮球" print("%s喜欢%s" % (name, hobby))
# 如果你的python是3.6以上, 此时可以使用模板字符串
# f"{变量}"
# print(f"{name}喜欢{hobby}") # 模板字符串
2、运算符
01、算数运算
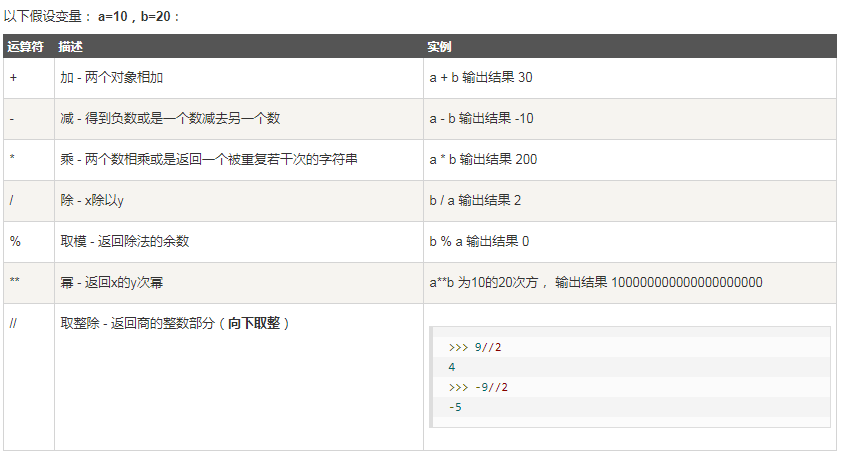
02、比较运算
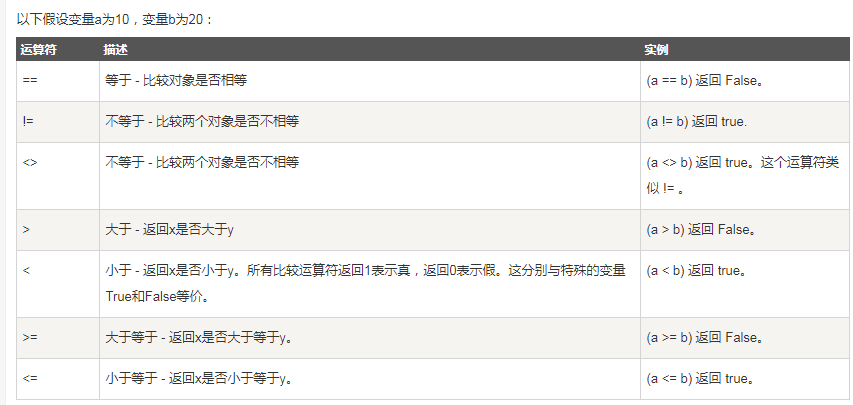
03、赋值运算
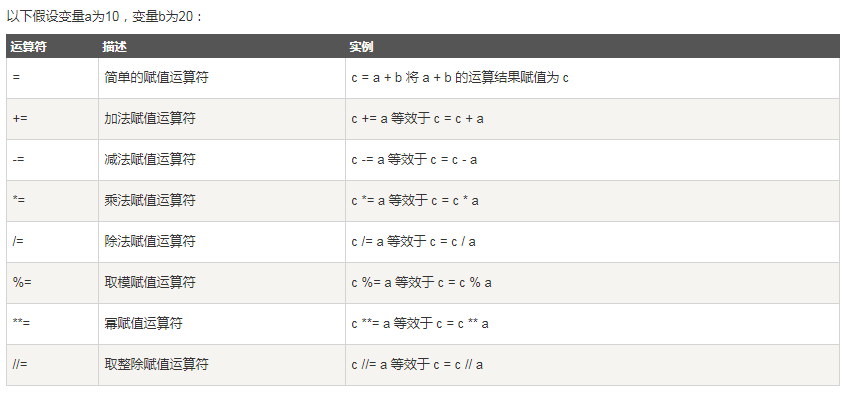
04、逻辑运算

01. and
并且, 左右两端必须同时为真, 最终的结果才能是真, 有一个是假, 结果就是假
2, or
或者, 左右两端有一个是真. 结果就是真. 全都是假, 结果才能是假
3, not
非.不. 非真既假, 非假既真
4. 优先级
如果出现混合逻辑运算. 顺序: () => not => and => or
例如:
print(not 1 > 5 and 4 < 6 or 7 > 8 and 1 < 9 or 5 > 6) True
先算 not: 1 >5:取反,为True
再算 and: True and 4 < 6 :True , 7 > 8 and 1 < 9 :False
最后 or: True or Flase or 5 > 6
结果为:True
5. a or b
如果 a 是0,结果是b
如果 a 是非0,结果就是a
print(1 or 2) # 1 print(0 or 3) # 3 print(1 or 5) # 1 print(0 or 5) # 5
#0就是假,非0就是真
6. a and b
和 or 相反 print(1 and 2) # 2 print(0 and 3) # 0 print(1 and 5) # 5 print(0 and 5) # 0
05、成员运算

例如:
s = "alex特别喜欢太白金星" if "胡辣汤" in s: print("胡辣汤在 s 变量中") else: print("胡辣汤不在 s 变量中") 胡辣汤不在 s 变量中 print("胡辣汤" in s) False print("胡辣汤" not in s) True
3、编码
01. ASCLL码
早期. 计算机是美国发明的. 普及率不高, 一般只是在美国使用. 所以. 最早的编码结构就是按照美国人的习惯来编码的. 对应数字+字母+特殊字符一共也没多少. 所以就形成了最早的编码ASCII码. 直到今天ASCII依然深深的影响着我们.
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
02. GBK国标码
随着计算机的发展. 以及普及率的提高. 流行到欧洲和亚洲. 这时ASCII码就不合适了. 比如: 中文汉字有几万个. 而ASCII最多也就256个位置. 所以ASCII不行了. 怎么办呢? 这时, 不同的国家就提出了不同的编码用来适用于各自的语言环境.比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使用计算机了.
GBK, 国标码占用2个字节. 对应ASCII码 GBK直接兼容. 因为计算机底层是用英文写的. 你不支持英文肯定不行. 而英文已经使用了ASCII码. 所以GBK要兼容ASCII.
这里GBK国标码. 前面的ASCII码部分. 由于使用两个字节. 所以对于ASCII码而言. 前9位都是0
字母A:0100 0001 # ASCII 字母A:0000 0000 0100 0001 # GBK 国标
03. Unicode 万国码
国标码的弊端: 只能中国用. 日本就垮了. 所以国标码不满足我们的使用. 这时提出了一个万国码Unicode. unicode一开始设计是每个字符两个字节. 设计完了. 发现我大中国汉字依然无法进行编码. 只能进行扩充. 扩充成32位也就是4个字节. 这回够了. 但是. 问题来了. 中国字9万多. 而unicode可以表示40多亿. 根本用不了. 太浪费了. 于是乎, 就提出了新的UTF编码.可变长度编码
UTF-8: 每个字符最少占8位. 每个字符占用的字节数不定.根据文字内容进行具体编码. 比如. 英文. 就一个字节就够了. 汉字占3个字节. 这时即满足了中文. 也满足了节约. 也是目前使用频率最高的一种编码
UTF-16: 每个字符最少占16位.
GBK: 每个字符占2个字节, 16位
# 用的最多的编码就是utf-8
# 1. 英文: 8bit -> 1byte
# 2. 欧洲文字: 16bit -> 2byte
# 3. 中文: 24bit -> 3个字节 中文有9万多个
# python2.x使用的是ascii
# python3.x内存中使用的unicode, 文件存储使用:utf-8
# s = "古力娜扎" # 字符串直接就是unicode # print(s) # # 想要存储到文件中. 必须进行转换 => utf-8 或者GBK
04. 编码与解码
编码之后的数据是bytes类型的数据,还是原来的数据只是经过编码之后表现形式发生了改变而已。
bytes的表现形式:
- 英文 b'alex' 英文的表现形式和字符串没什么两样
- 中文 b'\xe4\xb8\xad' 这是一个汉字的UTF-8的bytes表现形式
# s = "lishichao" # print(s.encode("utf-8")) # 将字符串编码成UTF-8 # print(s.encode("GBK")) # 将字符串编码成GBK #结果: # b'lishichao' # 英文编码之后的结果和源字符串一致 # b'lishichao' s = "李世超" print(s.encode("utf-8")) # 将字符串编码成UTF-8 print(s.encode("GBK")) # 将字符串编码成GBK #结果: # b'\xe6\x9d\x8e\xe4\xb8\x96\xe8\xb6\x85' # 一个中文的UTF-8编码是3个字节 # b'\xc0\xee\xca\xc0\xb3\xac' # 一个GBK的中文编码是2个字节
#使用decode()来进行解码操作,吧bytes类型的数据还原回我们熟悉的字符串:
print(b'\xe6\x9d\x8e\xe4\xb8\x96\xe8\xb6\x85'.decode('UTF-8'))
print(b'\xc0\xee\xca\xc0\xb3\xac'.decode('GBK'))
编码和解码的时候都需要制定编码格式:
s = "我是文字" bs = s.encode("GBK") # 我们这样可以获取到GBK的文字 # 把GBK转换成UTF-8 # 首先先要把GBK转换成unicode. 也就是需要解码 s = bs.decode("GBK") # 解码 # 然后需要进行重新编码成UTF-8 bss = s.encode("UTF-8") # 重新编码 print(bss)
# 用什么编码,就用什么解码。
4、基本数据类型
4.1 python基本数据类型
- int ==> 整数. 主要用来进行数学运算
- str ==> 字符串, 可以保存少量数据并进行相应的操作
- bool==> 判断真假, True, False
- list==> 存储大量数据.用[ ]表示
- tuple=> 元组, 不可以发生改变 用( )表示
- dict==> 字典, 保存键值对, 一样可以保存大量数据
- set==> 集合 保存大量数据. 无序;不可以重复. 其实就是不保存value的dict
4.2 int
整数类型,主要用来数学运算,只有一个方法。
a = 3 # 二进制用11表示 print(a.bit_length()) #计算二进制长度 #结果为:2
4.3 bool
布尔值只有两个:True、Flase 主要用来条件判断。
基本数据类型之间互相转换
bool => int a = True b = False print(int(a)) print(int(b)) # 整数中 0=> False 非0 =>True #所有表示空的东西都是假 print(bool("")) print(bool("a")) print(bool(None)) #None 表示空
4.4 str
把字符连成串. 在python中用', ", ''', """引起来的内容被称为字符串.
01、字符串的索引和切片
索引:
# 索引就是第几个字符, 索引从0开始 # s = "jay" # print(s[1]) #a []表示索引 # print(s[2]) #y # print(s[-1]) #y # print(s[-3]) #j
切片:
# s = "alex昨天看冯提莫直播. 刷了1w个鱼丸" s[4:8] # 默认从左到右切, 顾头不顾尾[start, end) s[-6:-2] s[8:4] #这样取不到值 s[:6] # 从头开始切, 切到6为止 s[:] # 从头到尾 # 带有步长的切片 s = "wusir喜欢和alex一起去探讨课件" print(s[3:8:2]) # 从3到8 每2个出来1个 i喜和 print(s[::2]) # 从头到尾 步长为2 # 如果步长为负数, 从右到左 print(s[::-1]) print(s[-1:-6:-2]) print(s[-3::-3])
02. 字符串相关操作:
切记, 字符串是不可变的对象, 所以任何操作对原字符串是不会有任何影响的
- 大小写转换:
1. 首字母大写


# s = "alex" # s1 = s.capitalize() # 首字母大写, 字符串是不可变的数据类型. 每次操作都会返回新字符串 # print(s) # print(s1)
2. upper() 把所有字母转化成大写
# s = "wusir" # s1 = s.upper() # print(s1) # while 1: # game = input("请输入你喜欢玩儿的游戏(请输入Exit退出程序):") # if game.upper() == "EXIT": # 忽略大小写 # break # print("你喜欢的游戏是%s" % game)
3. lower() 全部转化成小写. 对一些欧洲文字不敏感
# s = "wusir和ALEX关系不一般" # print(s.lower())
4. title() 标题, 每个单词的首字母大写
# s = "alex wusir ritian taibai nezha 女神" # print(s.title())
- 切来切去:
1. split() 字符串切割
# s = "alex_wusir_taibai" # ret = s.split("alex_wusir_taibai") # 如果切割的位置在边缘. 一定能获取到空字符串 # print(type(ret)) # <class 'list'> 列表 # print(ret)
2. replace() 字符串的替换
# s = "alex dsb, wusir xsb" # # print(s.replace("sb", "烧饼")) # print(s.replace("sb", ""))
3. strip() 去掉空白 => 脱掉空白
# # s = " 哈哈哈 哈哈哈\n\t" # \t 制表符(缩进) \n 换行 # # print(s.strip()) # 去掉左右两端的空白(必须要记住) # username = input("用户名:").strip() # password = input("密码:").strip() # if username == "alex" and password == "123": # print("登录成功了") # else: # print("登录失败")
while 1: print(input(">>>:").strip("吗呢么?")+"!") # 执行结果: 把末尾的"吗呢么?",替换成"!" >>>:你好吗 你好!
- 找来找去
s = "php是全世界最好的编程语言" # print(s.startswith("java")) # 判断这句话是否是以xxx开头 # print(s.endswith("php")) # 判断是否以xxx结尾 # s = "java, php, python, c++" # print(s.count("av")) # 计算xxx字符串中出现的次数 # s = "海王_剑姬_诺手_余小C喜欢用诺手" # print(s.find("手")) # 找的是索引 # print(s.find("胡")) # 如果不存在. 返回-1 # print(s.index("手")) # index: 索引 # print(s.index("胡")) # index如果找不到. 报错
-判断组成
# s = "abc胡辣汤壹123@#$%" # print(s.isdigit()) # 判断字符串是否由数字组成 # print(s.isalpha()) # 判断是否由文字的基本组成. # print(s.isalnum()) # 是否由数字. 字母组成, 能屏蔽特殊字符 # s = "123123壹佰贰拾伍万贰千三百四十六" # print(s.isnumeric()) # 判断是否是数字, 两, 俩
len() 求长度(字符串、列表), 内置函数
# i = 0 # while i < len(s): # 遍历字符串 # print(s[i]) # i += 1
4.5 列表和元祖
能装对象的对象叫列表. 存在的意义:存储大量的数据
列表使用[]括起来, 内部元素用逗号隔开,列表是可变数据类型。
# lst = ["张三丰", "张全蛋", "张无忌", "张国立", "张翠山", "张二嘎"] # 类表和字符串一样也有索引和切片 # print(lst[1]) # print(lst[1::2]) # 切片功能和字符串一模一样 # print(lst[-1::-2]) #
- 列表的增删改查:
添加:
01. append 追加 向列表的最后放数据
# lst = [] # list() # lst.append("手表") # lst.append("腰带") # lst.append("相机") # lst.append("陈冠希")
02. insert 插入.
# lst = ["倚天", "射雕", "天龙", "笑傲江湖"] # lst.insert(2, "少林足球") # print(lst)
03. extend() 迭代添加(不常用)
# lst= ["小龙女", "李若彤", "阿娇", "景甜"] # lst.extend(["张三丰", "李四", "王二麻子", "李老五"]) # print(lst)
删除:
01. pop 指定索引删除,会返回删除的元素
# lst = ["李嘉诚", "马云", "马化腾", "王健林", "你"] # lst.pop(1) # print(lst)
02. remove 指定元素删除
# lst.remove("马化腾") # 删除. 指定某一个元素删除 # print(lst)
03. del
# del lst[3] # print(lst)
04. clear 清空
# lst.clear() # 清空列表
# print(lst)
修改:
# lst = ["马大帅", "乡村爱情", "刘老根", "圣水湖畔"] # lst[1] = "东北一家人" # 索引修改 # print(lst)
查询-> 用的最多的是索引
# lst = ["马大帅", "乡村爱情", "刘老根", "圣水湖畔"] # # # print(lst[3]) # # # 列表是一个可迭代对象. 可以使用for循环 # # for item in lst: # item:列表中的每一项元素 # # print(item) # # print("马大帅" in lst) # 成员判断
- 相关操作:
sort() 排序
# lst = [1,5,4,7,5,4,11,2,5,44,5,1,3,6] # # reverse: 只要看到它. 一定是反着来 # lst.sort(reverse=True) # 排序 # print(lst) # lst = ["张无忌", "赵敏", "周芷若", "小昭", "阿离"] # lst.reverse() # 列表的翻转 # print(lst)
range() 循环列表
# range可以让for循环数数 # for i in range(100): # [0, 100) 100次循环 # print(i) # for i in range(10, 20): # [10, 20) # print(i) # for i in range(10, 20, 2): # [10, 20) 每2个出1个 # print(i) # 重点: # lst = ["成功", "不要", "30岁", "做人", "思想", "学习是自己的", "找家长"] # 0-4 # # for i in range(len(lst)): # 可以拿到索引和元素 # print(i, lst[i]) # i = 0 # for item in lst: # 这个循环看不到索引 # print(i, item) # i += 1
列表的深浅拷贝
python的赋值机制
# a = 20 # b = a # print(a is b) # 判断内存地址是否一样 #True a = [1,2,3] b = a #赋值操作没有进行拷贝. 还是同一个对象 print(a is b) print(id(a)) #指向的内存地址一样 print(id(b)) #指向的同一个对象 a.append(4444) print(a) print(b)
浅拷贝
a = [1,2,3] b = a[:] # 此时对a进行了复制. 此时创建了新的列表, 浅拷贝 print(a is b) print(id(a)) print(id(b)) a.append(4444) print(a) print(b) 浅拷贝出现的问题. 解决方案:用深拷贝 a = [1,2,3, [123, 456]] b = a.copy() print(a is b) #False print(a[3] is b[3]) #只能拷贝到第一层,嵌套的列表还是同一个对象 #True a.append(4444) print(a) print(b)
深拷贝
# import copy # 导入一个copy模块 # lst = [1,2,3, [123, 456]] # lst2 = copy.deepcopy(lst) # 深度拷贝(深度克隆, 原型模式) # print(lst2) # # print(lst is lst2) # print(lst[3] is lst2[3]) # # 注意. 此时不论任何操作都不会互相的影响 # lst[3].append("胡辣汤") # print(lst) # print(lst2)
- 元祖
# 元组是不可变的列表, 又被成为只读列表
# 元组用小括号表示, 并且空元祖用tuple(), 如果元组中只有一个元素,必须在后面加逗号
# # 元组是可迭代对象
# tu = (1,) # 此时认为()是数学运算, 加了逗号就是元组 # print(type(tu)) # print(tu) # tu = ("金庸", "古龙", "黄奕", "孙晓") # for t in tu: # print(t)
4.6 字典
字典存储数据的时候. 它是根据hash值进行存储的. 字典中所有的key必须是可哈希的.
字典用{}表示. 以key:value的形式进行保存数据
# dic = {"jay":"周杰伦", "wlh":"王力宏", "jj":"林俊杰"}
# print(dic)
# print(type(dic))
# # 不可变就是可哈希
# dic = {1:"呵呵", "hh":"哈哈", []:"吼吼"} # unhashable type: 'list' 列表不能是key
# print(dic)
- 字典的增删改查
# 查询
# dic = {"金庸": "扫地僧", "古龙": "天机老人", "黄奕": "alex"}
# print(dic["金庸"]) # 用的最多的是这种写法
# print(dic["李寻欢"]) # KeyError: '李寻欢' 没有这个key
# print(dic.get("李寻欢")) # 默认情况下. 如果找不到这个key, 返回None
# print(dic.get("李寻欢", "没这个人")) # 当key不存在, 返回第二个数据
# print(dic["李寻欢"])
# 添加
# dic = {} # dic["赵本山"] = "乡村爱情协奏曲" # dic[新key] = value # dic["赵本水"] = "综艺节目" # # dic["赵本山"] = "马大帅" # 替换., 修改. 当key存在了的时候. 是修改 # print(dic) # # dic.setdefault("安安") # 如果只有一个参数. value放空 # dic.setdefault("安安", "很高") # 如果有两个参数. 可以执行新增 # dic.setdefault("安安", "很瘦") # 当执行到这句话的时候. 字典中已经有了安安. 此时就不会再执行新增了 # print(dic) # setdefault执行流程: # 1.首先判断你给的key是否在字典中出现了. 如果出现了. 就不执行任何新增操作. 如果没有出现. 执行新增 # 2.不论前面是否执行了新增. 最后都会根据你给的key把value查询出来 # dic = {"安安": "班主任", "大安安":'大美女'} # ret = dic.setdefault("大安安", "大美女") # print(dic) # print(ret) # lst = [11,22,33,44,55,66,77,88,99] # ret = {} # for item in lst: # if item < 66: # if not ret.get("key1"): # ret["key1"] = [item] # else: # ret["key1"].append(item) # else: # if not ret.get("key2"): # ret["key2"] = [item] # else: # ret["key2"].append(item) # print(ret) # 难 # for item in lst: # if item < 66: # ret.setdefault("key1", []).append(item) # else: # ret.setdefault("key2", []).append(item) # print(ret)
# 删除
# dic = {"alex": "路飞", "wusir": "alex", "老男孩": "linux", "linux":"成全了老男孩"}
# dic.pop("alex") # 根据key删除
# print(dic)
# dic.clear()
# del dic['wusir'] # 根据key删除
# print(dic)
# 查询补充: keys(), values() , items()
dic = {"alex": "路飞", "wusir": "alex", "老男孩": "linux", "linux":"成全了老男孩"}
# print(dic.keys()) # 像列表, 不是列表, 山寨列表
# for item in dic.keys(): # 可以直接拿到每一个key
# print(item)
# print(dic[item])
# # 记这个
# for k in dic: # 字典是可迭代的. 此时拿到的k就是字典中所有的key
# print(k)
# print(dic[k])
# print(dic.values()) # 获取到所有的value.
# for v in dic.values(): # 很少用到这个
# print(v)
#
# print(dic.items())
# 直接获取到key和value的方式
# for k, v in dic.items(): # dic.items() => 打开之后是元组 => 打开是=> key, value
# print(k, "=>", v)
#解构, 解包: 把元组, 列表中的每一项拿出来赋值给前面的变量
# 要求:数据和变量要能对的上 # a, b, c = (1, 2, 3) # (1, 2) # print(a) # print(b) # dic = {"aa":"安安", "xx":"晓雪", "xr":"小茹"} # for k in dic: # print(k) # print(dic[k]) # for k, v in dic.items(): # print(k) # print(v)
# 字典的嵌套
wf = { "name": "汪峰", "age": 42, "wife": { "name":"章子怡", "age": 41, "hobby":["拍戏", "当导师.."], "assit":{ "name":"章助理", "age":18 } }, "children":[ {"name":"汪小峰1号", "age":18}, {"name":"汪小峰2号", "age":8}, {"name":"汪小峰3号", "age":2} ] } # # 查询汪峰2儿子的年龄 # print(wf['children'][1]['age']) # # 汪峰老婆的助理的年龄 # print(wf["wife"]['assit']['age']) # 给汪峰小儿子加10岁 wf['children'][2]['age'] = wf['children'][2]['age'] + 10 print(wf)
# 字典没有索引和切片
dict类方法:fromkeys
d = dict.fromkeys("周杰伦", ["昆凌"]) print(d) d['杰'].append("蔡依林") print(d) # {'周': ['昆凌'], '杰': ['昆凌'], '伦': ['昆凌']} # {'周': ['昆凌', '蔡依林'], '杰': ['昆凌', '蔡依林'], '伦': ['昆凌', '蔡依林']}
# 1. fromkeys返回新字典. 不是在原来字典的基础上干活的
# 2. 所有的key共享同一个value
fromkeys执行的效果: 把前面的那个参数的数据进行迭代. 和后面的参数组合成一个key:value. 创建一个新字典
# print(dict.fromkeys("国产动画", "白蛇,缘起")) # fromkeys的正确用法
4.7 set 集合
# set集合特点:无序不重复,内部元素必须可哈希, set集合用{}表示. 如果是空集合(set())
# s = {"胡辣汤", "灌汤包", "热干面", "牛油火锅", "乱炖", "乱炖", "乱炖", "乱炖", "乱炖", "乱炖"}
# print(s)
# 去重复 最重要
# lst = ["胡辣汤", "灌汤包", "热干面", "牛油火锅", "乱炖", "乱炖", "乱炖", "乱炖"] # # 把列表转化成set集合 # s = set(lst) # lst = list(s) # print(lst)
# 增删改查
# s = set() # s.add("张无忌") # 添加 # s.add("胡辣汤") # s.add("粘糕") # print(s) # s = {"年年有余", "炖鸡", "凉菜", "饺子", "肘子", "猪蹄子"} # # ret = s.pop() # 随机删除 # # s.remove("炖鸡") # # print(s) # # # 修改只有一个方案. 先删除,. 后添加 # s.remove("炖鸡") # s.add("锅包肉") # print(s) s = {"年年有余", "炖鸡", "凉菜", "饺子", "肘子", "猪蹄子"} for el in s: # set集合可以被迭代 print(el)
4、is 和 ==
# == 比较的是数据
# is 比较的是内存地址
# lst1 = [1,2,3] # lst2 = [1,2,3] # print(lst1 == lst2) # print(lst1 is lst2)
s1 = "alex" s2 = "alex" print(s1 is s2) # True, 原因是有小数据池进行缓存. 优化你的字符串创建过程 print(id(s1)) print(id(s2)) # String interning
# 小数据池: python会自动的对我们写的字符串, 数字, 布尔.进行缓存.
5、列表和字典的循环删除
正常循环删除
# lst = ["jay", "jj", "Jolin", "alex"] # lst.clear() 不准用clear # for item in lst: # 删不干净 # lst.remove(item)
1. 把要删除的元素记录在一个新列表中
new_lst = [] for el in lst: new_lst.append(el) for item in new_lst: # 循环新列表. 循环出来的都是要删除的内容 lst.remove(item) # 删除原来的列表中的内容 print(lst)
lst = ["金城武", "李嘉诚", "鹿晗", "韩露", "李易峰", "吴亦凡"]
删除姓李的
# 把要删除的人装新列表中
# new_list = [] # for item in lst: # if item.startswith("李"): # new_list.append(item) # # # 循环新列表. 删除老列表 # for item in new_list: # lst.remove(item) # # print(lst)
字典删除一样的操作
dic = {"jay":"呵呵", "jj":"哈哈", "Jolin":"吼吼"}
new_lst = []
#字典在迭代中,不能改变大小
for k in dic:
dic["哈哈哈"] = "呵呵"
dic.pop(k) # dictionary changed size during iteration
new_lst.append(k)
#循环列表,去删除字典
for k in new_lst:
dic.pop(k)
print(dic)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号