


前言
正则表达式是什么应该不用过多介绍,每位程序员应该都知道,正则表达式描述的是一种规则,符合这种限定规则的字符串我们认为它某种满足条件的,是我们所需的。在正则表达式中,主要有两种字符,一种描述的是普通的字符,另一种描述的是元字符。其中元字符是整个正则表达式的核心,并由它完成规则的制定工作。
本篇文章主要从Java这门程序设计语言的角度理解正则表达式的应用,主要涉及以下内容:
•基本正则表达式的理论基础
•Java中用于正则表达式匹配的类
•几种常用的正则表达式使用实例
一、正则表达式的理论基础
1、普通字符的表示
我们说正则表达式主要由普通字符和元字符组成,那么我们首先先看看普通字符该如何表示。大部分普通字符由字符本身即可表示,例如:'s','i','n','g','l','e'等。除此之外,也有一些特殊的表示方式。
- 以/0开头,后面紧跟1-3位数字,表示的是一个八进制数。这个数的十进制值对应于ASCII编码中的相应字符。
- 以/x或者/X开头,后面紧跟两位字符,表示的是一个十六进制的数。该数的十进制的值对应于ASCII编码中相应的字符。
- 以/u开头,后面紧跟四位字符,表示一个Unicode编号。该编号对应于Unicode字符集中的一个具体字符。
- 另外还有一些元字符,虽然它们具有特殊的含义,但是往往在某种特殊情况下,需要将这些元字符当做普通字符使用,我们使用 '/'+元字符,表示转移该元字符,此后该元字符将表示一个普通字符。例如:'//','/^',它们分别表示的是 '/'和 '^',不再具有特殊含义了。下面我们开始逐渐介绍正则表达式语法中的元字符的特殊含义。
2、字符组匹配单个字符
我们用一对中括号([.....])表示字符组,整个字符组中会有多个字符位列其中,该字符组表示的含义是:匹配任意一个字符,该字符是位列字符组中的。例如: [single]匹配的是字符's','i','n','g','l','e'中的任意一个字符。以上我们简单介绍了字符组的基本概念以及它所能匹配的内容,其实有时候为了表述连续的字符,我们会结合元字符 '-' 一起来操作字符组。例如:[0123456789],匹配的是0到9之间的任意一个数字,对于这种情况我们可以选择这样来简化操作:[0-9]。其实两者表述的含义是一样的,为了简化起见,如果遇到连续的字符表述,可以选择使用元字符来简化。同样的还有[a-z],它匹配任意一个小写字母。对于元字符 '-' 还需要说明一点的是:该字符只有出现在两个字符之间才具有特殊含义,单独出现在字符组的所有字符之前或者之后只能表述普通字符 '-' 。下面介绍有关字符组的一些其他相关的元字符。
元字符 '^' 表示排除的意思,和元字符 '-' 类似,只有放在所有字符的最前面才具有特殊含义,否则只能表示普通字符。例如: [^1234] ,该字符组匹配一个字符,但是不是1或2或3或4。当然, [c^yy] ,匹配的是四个普通字符,'c','^','y','y'。此外,需要注意一点的是,除了以上介绍的几种元字符必须置放于指定位置上才能起作用以外,其余所有元字符在字符组中统统被视作普通字符,不再具有特殊含义。
除此之外,字符组还支持嵌套使用。例如: [0-9[a-z]] ,该字符组匹配一个数字或者一个字母。我们也可以使用&&加强限定规则。例如: [0-9&&[^0123]] ,该字符组匹配的是0到9之间任意一个数字,但是该数字不能是0到3中任意一个,也就是只能匹配4到9之间任意一个数字。最后和字符组有关的内容还是涉及一个预定义字符组,所谓预定义字符组就是对字符组的适当封装,对于一些简单的组合使用简介的调用方式。例如:
•\d:等同于字符组 [0-9],表示任意一个数字字符
•\w:较为常见,等同于字符组[0-9a-zA-Z],表示任意一个world(单词字符)
•\s:等同于[ \t\n\x0B\f\r] ,匹配的是一个空格字符(space)
当然,它们也有相对应的大写形式,但是表示的意思却是截然相反的。
•\D:等同于[^0-9] ,表示一个任意非数字字符
•\W:等同于[^0-9a-zA-Z] ,表示任意一个非单词字符,往往会是一些特殊符号
•\S:等同于[^\t\n\x0B\f\r] ,匹配一个任意非空格的字符
3、用于指定字符多次出现的量词
所谓的量词主要是三个元字符,它们主要用于指定量词前面的字符在匹配时可以多次出现,具体区别接下来会介绍。首先我们需要知道,这三个元字符是:+ ,*, ?。下面描述它们各自作用及相互之间的区别:
•+:该元字符指定位于元字符前面的普通字符可以出现一次或者多次。例如:se+cyy这个正则表达式,字符secyy,seeeecyy都是可以匹配的,但是scyy是不能匹配的,前面的字符是必须出现的。
•*:该元字符指定位于元字符前面的普通字符可以出现零次或多次。例如:
se*cyy
对于该正则表达式而言,secyy,seecyy都是可匹配的,并且scyy也是可以匹配的。这就是和元字符 + 的简单区别。
•?:该元字符指定位于元字符前面的普通字符可以出现也可以不出现,但是不能多次出现。例如:se?cyy,对于该正则表达式,secyy,scyy等都是可匹配的,但是seeeecyy则是不能匹配的。它指定你前面的一个字符要么出现,要么不出现,不允许多次出现。
在这里我们要申明一个误区,这里的三个元字符量词作用的是紧邻该元字符前面的一个字符,并不是作用与元字符前面所有的字符,这里是需要注意的,包括笔者当初也都是误以为此的。
以上我们介绍了简单量词的概念,但是它们只能用于表示模糊的次数。可以出现多次,但是多次是多少却没有定论。对于要求字符出现精确次数的情况,我们可以使用通用量词来解决。{m,n}是通用量词的最基本形式,它指定前面的字符出现的次数在m到n之间。
看几个例子:
•se{0,10}cyy:其中e可以出现0-10次
•se{9}cyy:其中e必须出现9次
•se{0,}cyy:其中e可以出现0-无穷大次,等同于se*cyy。
4、分组划分组别
在介绍分组之前,无论是使用量词还是字符组都是针对的一个字符。而分组针对的就是一串字符,我们也可以对分组使用量词,控制该分组出现的次数。我们使用()括号表示分组,例如:
|
1
|
sing(le)de(cyy |
其中le和cyy分别是一个分组,对于一个完整的正则表达式,从头开始,每个分组都是有编号的,按照出现的次序,以1为基数递增。至于为什么要有编号,下文说。对于分组我们依然是可以使用量词控制其出现次数的,例如:
|
1
2
|
sing(le)+cccc:在该正则表达式中,分组le可以出现一次或者多次sing(le)*cccc:在该正则表达式中,分组le可以出现零次或者多次 |
结合元字符 '| ',可以实现和字符组一样的功效,例如:
|
1
|
(happy|cyy|single) |
该正则表达式可以匹配三个字符子串,happy,cyy,single。但是这里需要注意的是,元字符 | 如果用于字符组中就不再具有特殊含义,将会被作为普通字符来匹配。(这一点其实在介绍字符组的时候已经强调过)
下面解决一个上文遗留问题,分组的编号到底有什么作用。为分组编号其实是为了重新捕获和使用分组,每个分组按照出现的次序从1开始递增,我们使用 +分组编号进行引用。
例如:
|
1
|
<(\w+)>(.*)</\1>:该正则表达式等效于:<(\w+)>(.*)</\w+> |
(\w+)表示任意个字符(字母或数字),(.*)表示任意的符号,\1则引用了分组(\w+)。所以在这里,html中所有非单标签元素都是能匹配的。当然,如果我们不想使用默认的编号来引用分组,我们其实也是可以在定义分组的时候为分组命名。为分组命名的语法格式为: (?<name>X) ,引用分组的语法格式为: \k<name> 。例如:
|
1
|
<(?<num1>a)>(.*)</\k<num1>>:等效于:<a>(.*)</a> |
上述正则表达式定义了一个名为num1的分组,并后续进行了引用。下面介绍正则表达式的最后一块理论基础,边界匹配。
5、边界匹配
以上我们所介绍的所有内容主要还是针对单个字符或者多个字符组成的分组,我们可以限制他们的出现次数以及出现位置等。但是其实在正则表达式中,我们也是可以限制边界必须满足某种条件的。主要涉及的元字符有:^, $, \A, \Z, \z和\b。
首先看元字符 ^ ,在字符组中,该元字符表示否定的意思,此处匹配正则表达式首部位置边界。例如: ^abc匹配一个以abc开头的字符串。
元字符 $匹配的字符串的尾部边界,它规定被匹配的字符串必须以什么结束。例如:
|
1
|
abc$:dabc,abc,abc/n都是可匹配的 |
实际上,如果被匹配字符串是以指定字符结尾或者指定字符之后跟换行符,都是可匹配的。此处需要注意尾部边界匹配时的表述格式。(不同于首部匹配)
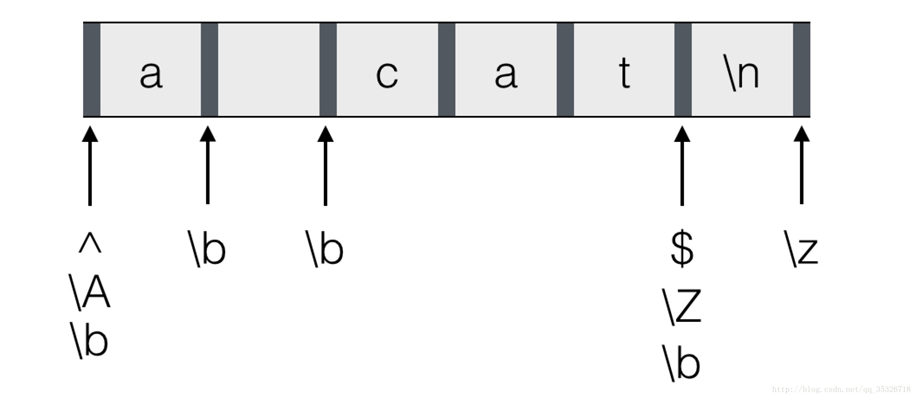
\b匹配的是单词边界,所谓的单词边界指的就是:当一边是字符,一边是非字符的时候,此处即为单词边界。也就是单词结束的那个位置。还有一些边界,例如:\A,\b,\Z等,各自匹配的边界如下图所示;
当然,对于边界匹配最通用的一种方式就是环视。它不局限于整个表达式的开头和结尾,它可以出现在表达式中的任何位置,既可以向前匹配,也可以向后匹配。主要分为以下四种情况:
•肯定顺序环视:它要求表达式的右边字符串必须满足某种约定,语法(?=....) 。例如:single(?=cyy) ,字符e的右边即为边界并且要求必须为cyy,所以该表达式只能匹配singlecyy。
•否定顺序环视:它要求表达式的右边字符串必须不能满足某种约定,和上一中情况是相反的,语法格式为:(?!...)。
•肯定逆序环视:它要求表达式的左边必须满足某种约束,语法格式为:(?<=...) 。
•否定逆序环视:它要求表达式的左边必须不能满足某种约束,语法格式为:(?<!...) 。(此处为了消除!在MarkDown编辑器中的特殊样式,加了空格,望读者注意)
虽然看起来有四种不同的环视类型,但是实际上分为两种,一种是向左看,一种是向右看。以上有关正则表达式的基本内容大致介绍完结,下面主要看看如何在Java中验证我们上述的这些理论。
引用只为学习使用
引用地址:https://www.jb51.net/article/118773.htm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号