
一、索引的管理操作
1.集合默认索引 / 索引属性介绍
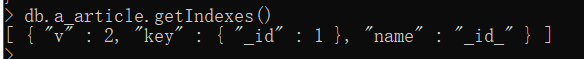
-
v: 索引版本号
-
key:索引规则
-
name:索引名称(创建时可以不指定,MongoDB会按照规则创建)
2.常用命令
-
db.a_article.getIndexes():查询集合下的所有索引
-
db.a_artilce.createIndex({articleId:1}):创建单列升序索引
-
db.a_article.createIndex({articleId:1,author:-1}):创建按聚合索引(此案例为创建文章ID升序的基础上作者降序索引)
-
db.a_article.dropIndex({title:1}): 删除标题索引
-
db.a_article.dropIndexes():删除a文章集合下的所有索引
-
db.a_article.createIndex({articleId:1},{unique:true}): 创建唯一索引
3.执行计划
-
使用小黑窗口查看执行计划(只需要在查询命令后边跟上explain方法即可)
> db.a_article.find({articleId:5}).explain()
{
"explainVersion" : "1",
"queryPlanner" : {
"namespace" : "articledb.a_article",
"indexFilterSet" : false,
"parsedQuery" : {
"articleId" : {
"$eq" : 5
}
},
"queryHash" : "F59DB225",
"planCacheKey" : "CCC3208C",
"maxIndexedOrSolutionsReached" : false,
"maxIndexedAndSolutionsReached" : false,
"maxScansToExplodeReached" : false,
"winningPlan" : {
"stage" : "FETCH",(这个状态表示是否走了索引)
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"articleId" : 1
},
"indexName" : "articleId_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"articleId" : [ ]
},
"isUnique" : true,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"articleId" : [
"[5.0, 5.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"command" : {
"find" : "a_article",
"filter" : {
"articleId" : 5
},
"$db" : "articledb"
},
"serverInfo" : {
"host" : "xiyang",
"port" : 27017,
"version" : "5.0.8",
"gitVersion" : "c87e1c23421bf79614baf500fda6622bd90f674e"
},
"serverParameters" : {
"internalQueryFacetBufferSizeBytes" : 104857600,
"internalQueryFacetMaxOutputDocSizeBytes" : 104857600,
"internalLookupStageIntermediateDocumentMaxSizeBytes" : 104857600,
"internalDocumentSourceGroupMaxMemoryBytes" : 104857600,
"internalQueryMaxBlockingSortMemoryUsageBytes" : 104857600,
"internalQueryProhibitBlockingMergeOnMongoS" : 0,
"internalQueryMaxAddToSetBytes" : 104857600,
"internalDocumentSourceSetWindowFieldsMaxMemoryBytes" : 104857600
},
"ok" : 1
}
-
state详解
COLLSCAN:全表扫描 IXSCAN:索引扫描 FETCH:根据索引去检索指定document SHARD_MERGE:将各个分片返回数据进行merge SORT:表明在内存中进行了排序 LIMIT:使用limit限制返回数 SKIP:使用skip进行跳过 IDHACK:针对_id进行查询 SHARDING_FILTER:通过mongos对分片数据进行查询 COUNT:利用db.coll.explain().count()之类进行count运算 COUNTSCAN:count不使用Index进行count时的stage返回 COUNT_SCAN:count使用了Index进行count时的stage返回 SUBPLA:未使用到索引的$or查询的stage返回 TEXT:使用全文索引进行查询时候的stage返回 PROJECTION:限定返回字段时候stage的返回
PROJECTION_COVERED:涵盖查询,映射查询的所有字段刚好都在索引里边,这时候不用去查文档了,直接返回结果
不希望看到包含如下的stage: COLLSCAN(全表扫描) SORT(使用sort但是无index)
不合理的SKIP SUBPLA(未用到index的$or) COUNTSCAN(不使用index进行count)
本文来自博客园,作者:荣慕平,转载请注明原文链接:https://www.cnblogs.com/rongmuping/articles/16260893.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号