
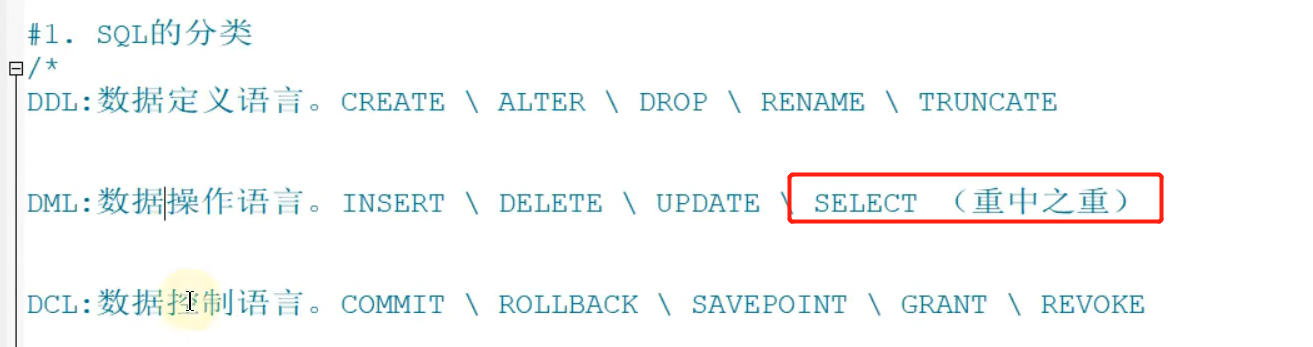
mysql入门
mysql
参考资料部分:
1.mysql官方文档:
https://dev.mysql.com/doc/refman/8.0/en/
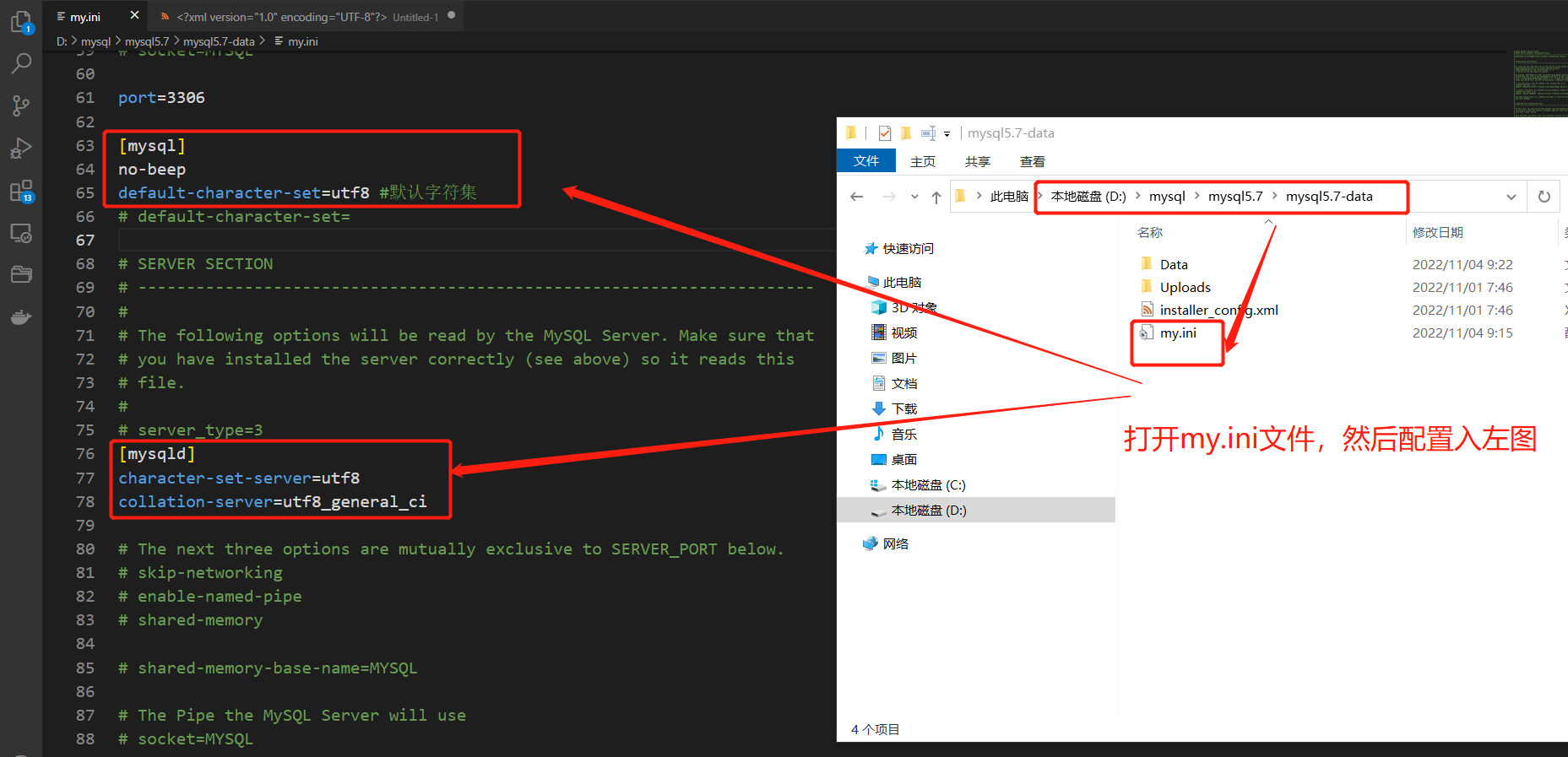
第1章 mysql环境搭建
1.关于mysql5.7版本与8.0版本的字符编码问题
由于mysql由瑞典公司开发,5版本在插入数据时无法插入中文,而8版本可以。
解决办法:

第3章
3-1 概述
学习大体框架:
3-2 SQL语言的规则与规范
1.基本规则
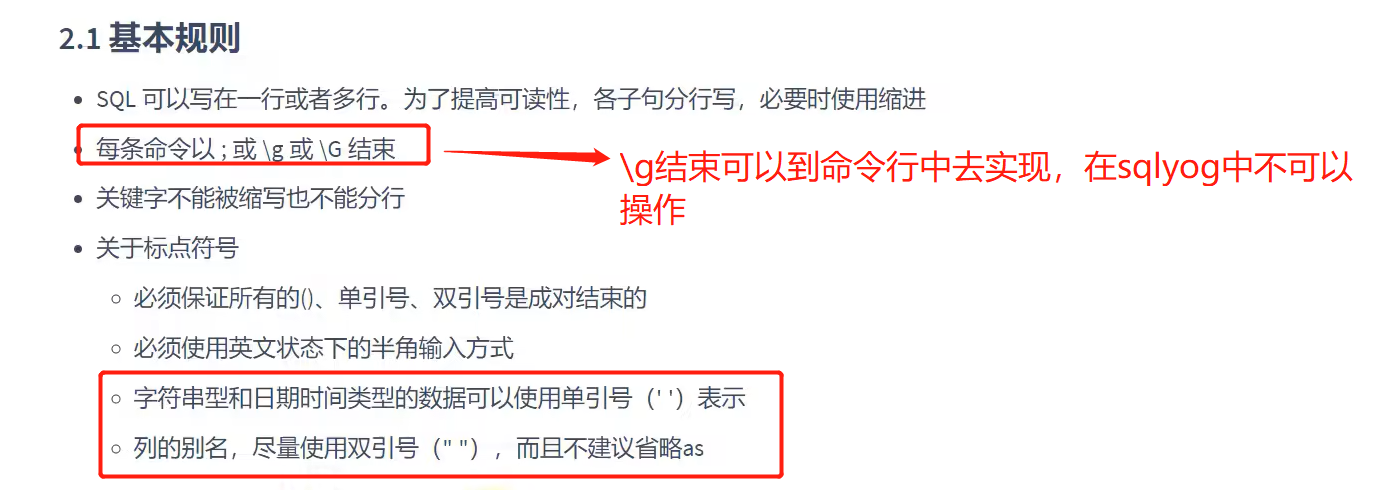
2.书写规范

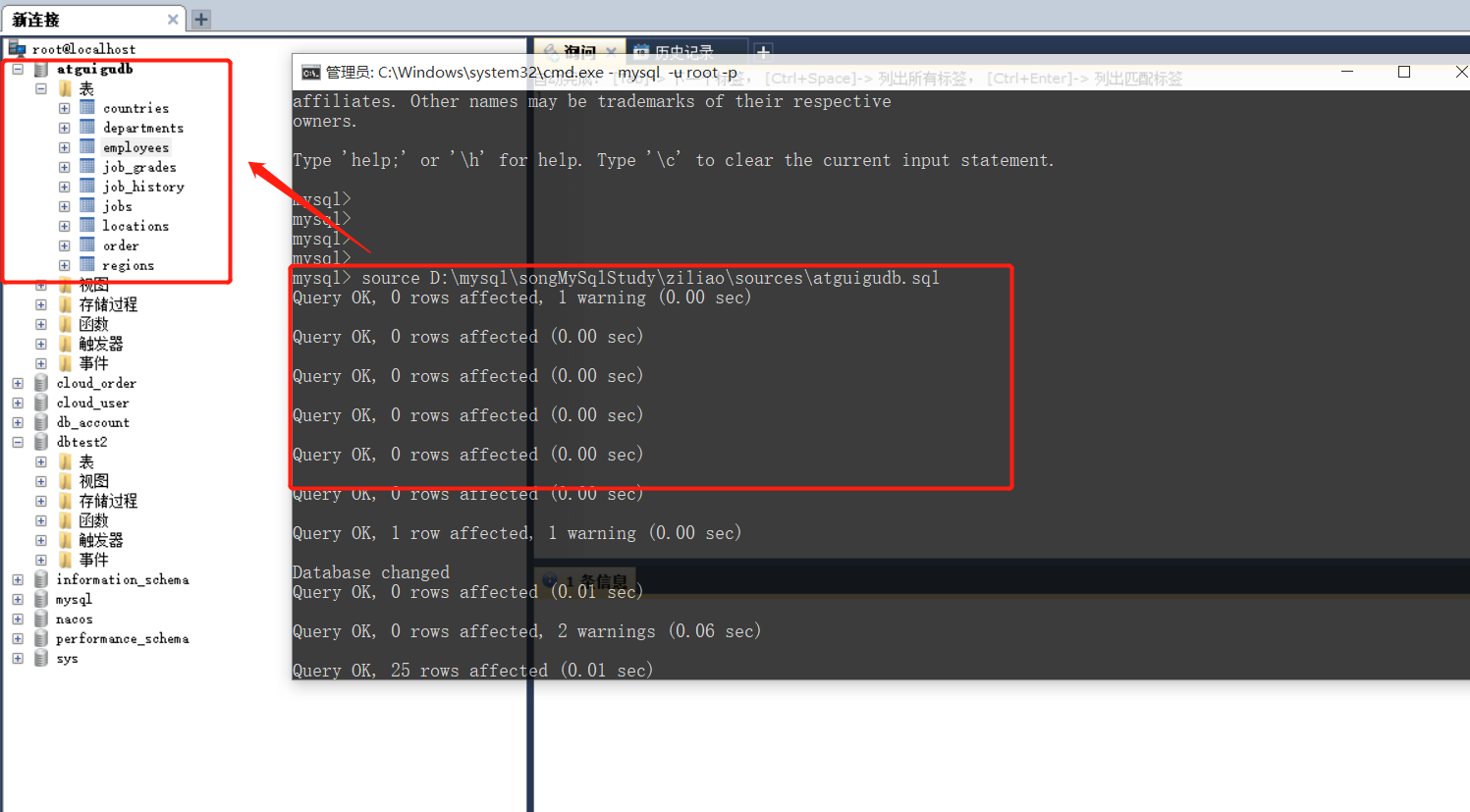
3.导入数据库sql文件的两种方式:
方式1:直接通过图形化界面导入sql文件
方式2:命令行
source sql文件的绝对路径
3-3 基本的select语句
1 起别名:
方式1:使用空格起别名
# 使用空格起别名
SELECT first_name fName FROM employees;
方式2:使用AS(alias)起别名
# 使用AS(alias)起别名
SELECT first_name AS ffName FROM employees;
方式3:使用""起别名:有特殊应用场景如下,可以避免出现歧义
# 使用""起别名:有特殊应用场景如下,可以避免出现歧义
SELECT salary*12 "total salary" FROM employees;
2.去重
# 去重 取出重复的department_id
SELECT department_id FROM employees;
SELECT DISTINCT department_id FROM employees;
# 该去重没有实际意义,比较department_id , employee_id两个字段是否相同
# 只要有一个不同,就会保留
SELECT DISTINCT department_id , employee_id FROM employees;
3.null参与运算的注意事项
注意1:只要NULL参与运算,其结果都是NULL
# null参与运算的注意事项
# 注意1:只要NULL参与运算,其结果都是NULL
SELECT salary "月工资", commission_pct "利率",salary * (1 + commission_pct) "年工资" FROM employees;
# 实际解决方案,使用单行函数
SELECT salary "月工资", commission_pct "利率",salary * (1 + IFNULL(commission_pct,0))*12 "年工资" FROM employees;
4.着重号``:解决于sql关键字冲突的问题
# 着重号``:解决于sql关键字冲突的问题
# 如下,order表与sql关键字ORDER相冲突,需要使用``区分
SELECT * FROM `ORDER`;
5.查询常数
# 查询常数
# 为查询的表数据每以行添加指定的常量
SELECT "姓名", first_name, last_name FROM employees;
6.显示表结构
# 显示表结构
DESCRIBE employees;
DESCRIBE `order`;
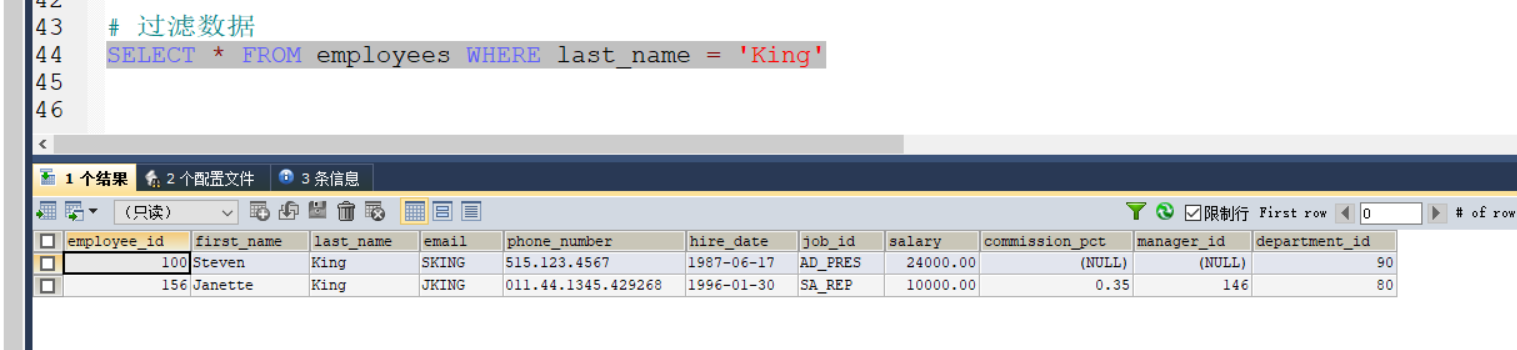
7.使用where过滤数据
注意1:mysql不严格区分大小写,Oracle执行sql语句时,严格执行ANSI制定的sql语言标准,是区分大小写的
注意2:where指定的字符串使用单引号(ANSI标准),mysql也可以使用双引号
第4章 运算符
补充:
伪表:DUAL
4-1:运算符的使用
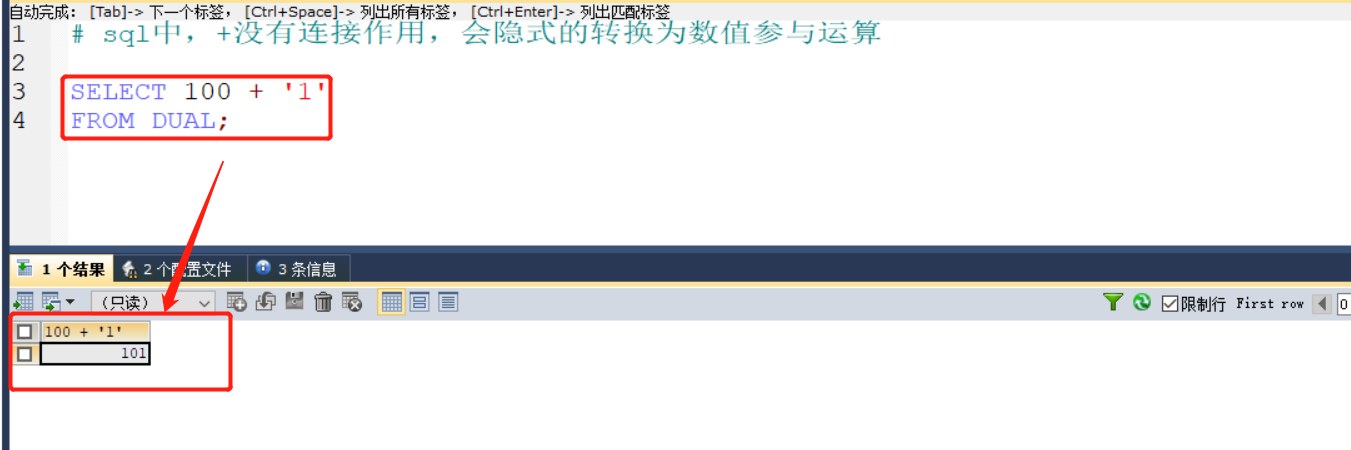
1.关于+使用
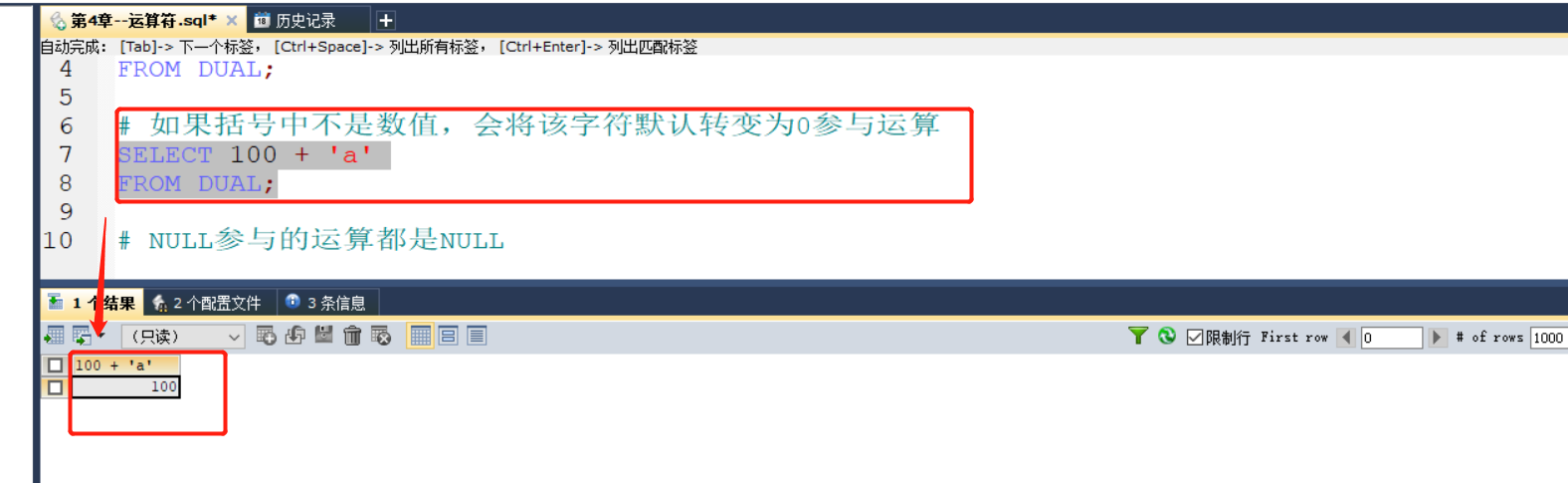
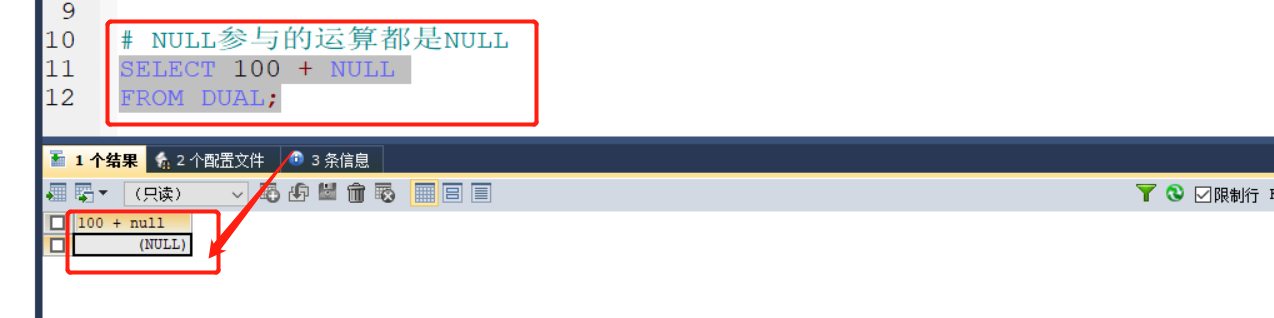
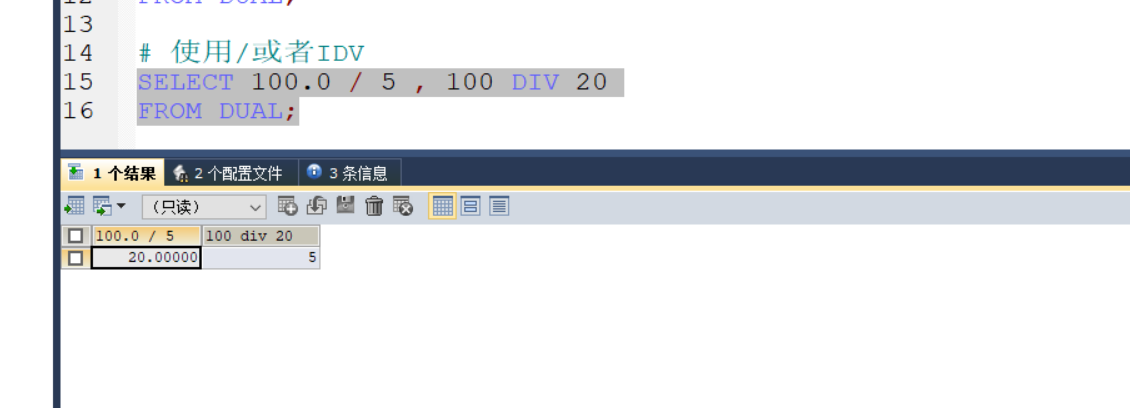
2.关于"/"
注意:
# 输出将结果为null
SELECT 100 / 0
FROM DUAL;
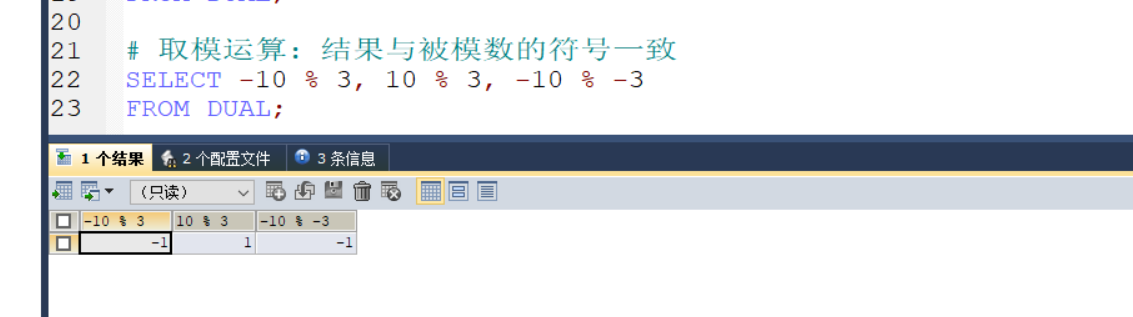
3.取模运算:
4-2 比较运算符
1:两个数值的字符串比较
1.如果等号两边的值、字符串或表达式都为字符串,则MySQL会按照字符串进行比较,其比较的 是每个字符串中字符的ANSI编码是否相等。
2:<=>:安全等于--》为NULL而生
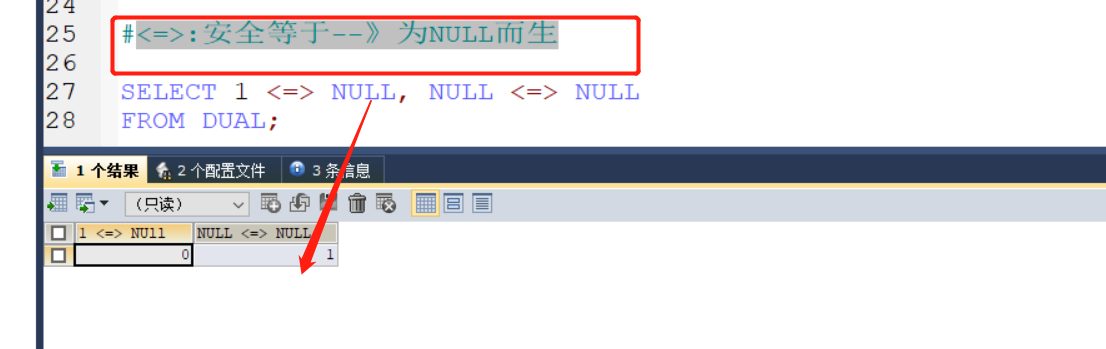
实际应用:
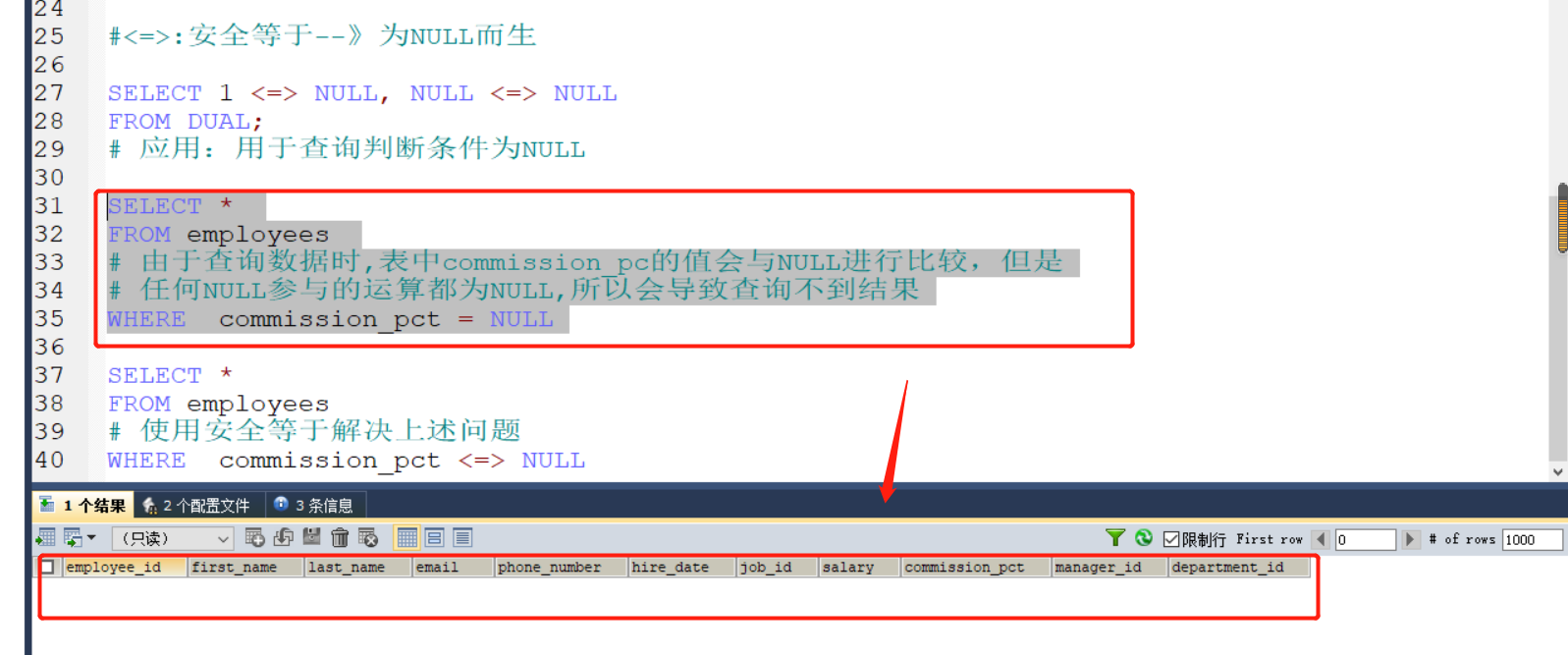
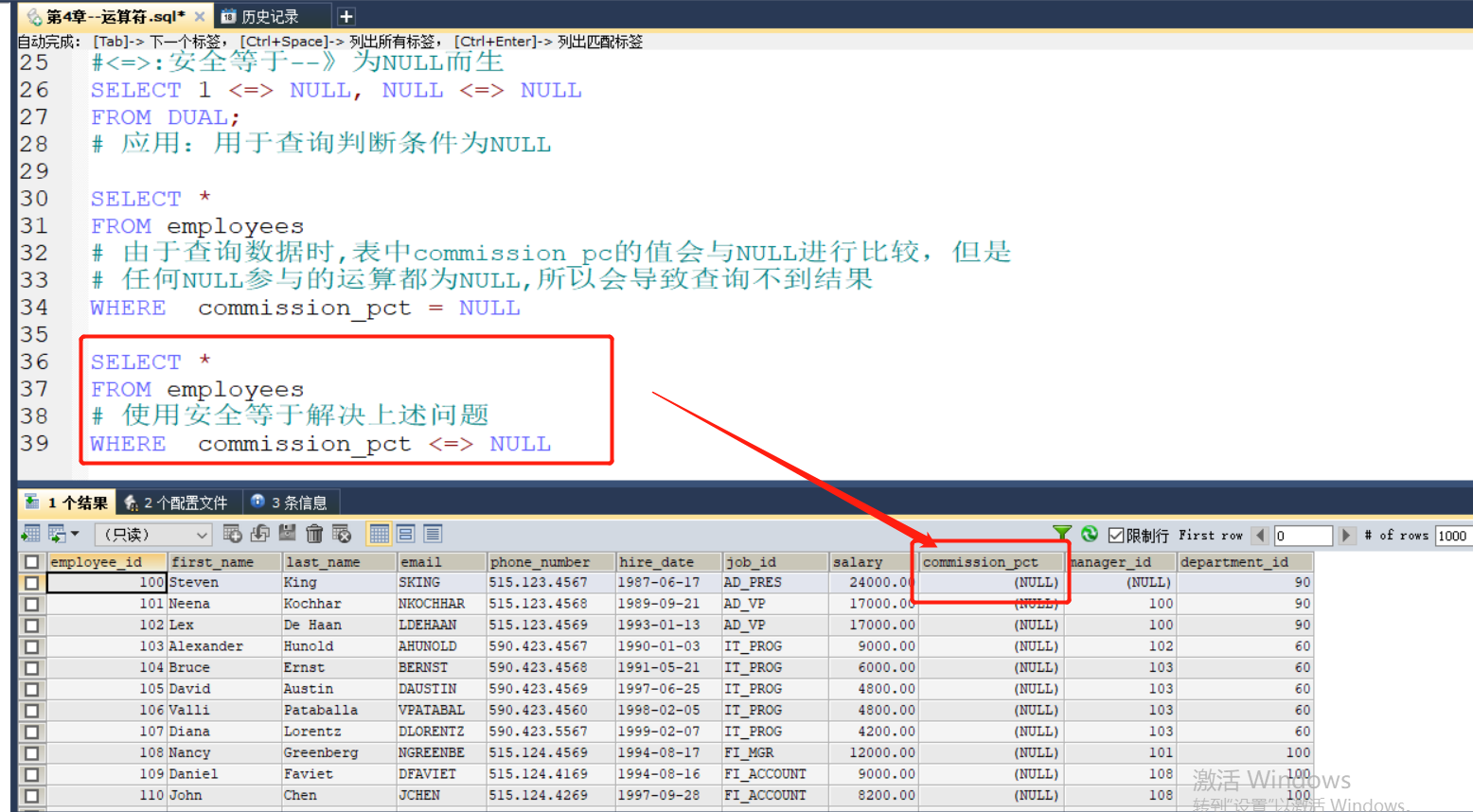
3:不等于
# 不等于
SELECT 3 != 2, 3 <> 2
FROM DUAL;
4:LEAST,GREATEST:根据ASCII码逐个字母的比较
# LEAST,GREATEST:根据ASCII码逐个字母的比较
SELECT LEAST('xu','xong'),GREATEST('xu','xong')
FROM DUAL;
5:AND,OR使用
# AND,OR使用
# AND
SELECT *
FROM employees
WHERE salary BETWEEN 6000 AND 8000;
# 与上述等价
SELECT *
FROM employees
WHERE salary >= 6000 && salary <= 8000;
# OR
SELECT *
FROM employees
WHERE salary < 6000 OR salary > 8000;
# 与上述等价
SELECT *
FROM employees
WHERE salary < 6000 || salary > 8000;
SELECT *
FROM employees
WHERE salary NOT BETWEEN 6000 AND 8000;
6. IN, NOT IN使用
# IN, NOT IN使用
# 查询工资是6000,7000,8000的员工
SELECT *
FROM employees
WHERE salary IN (6000,7000,8000);
# 等价
SELECT *
FROM employees
WHERE salary = 6000 OR salary = 7000 OR salary = 8000;
# 查询工资不是6000,7000,8000的员工
SELECT *
FROM employees
WHERE salary NOT IN (6000,7000,8000);
7.模糊查询
# 模糊查询:%代表0个,1个或多个字符
# 需求1:查询last_name中包含字符'a'且包含字符'e'的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%' AND last_name LIKE '%e%';
# 等价写法:需要考虑到a与e的相对位置
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%e%' OR last_name LIKE'%e%a%'
# 需求2:查询第2个字符是'a'的员工信息
# _:代表任意一个不确定的字符
SELECT last_name
FROM employees
WHERE last_name LIKE '_a%'
# 需求3:查询第二个字符就是下划线"_",第3个字符是'a'的员工信息
# 需要使用'\_'将'_'转义
SELECT last_name
FROM employees
WHERE last_name LIKE '_\_a%'
8.正则表达式(具体参见老师资料)
# 正则表达式,^a是以a开头,t$是以t结尾
SELECT 'abcdef' REGEXP '^a', 'iewqyt' REGEXP 't$', 'hxczlud' REGEXP 'cz'
FROM DUAL;
4-3 逻辑运算符与位运算符的比较
注意:AND运算符的优先级优先于OR
1.异或运算--XOR
# XOR
SELECT last_name, department_id, salary
FROM employees
# 该异或查询出的结果是:要么department_id = 50,salary < 6000;
# 要么department_id != 50,salary > 6000; 反正保证这两个条件不同时成立
WHERE department_id = 50 XOR salary > 6000;
第5章 排序和分页
5-1 排序:
1.排序的基本使用
# ASC-ascend:升序(默认), DESC-descend:降序
SELECT employee_id, last_name, salary
FROM employees
ORDER BY salary ASC;
SELECT employee_id, last_name, salary
FROM employees
ORDER BY salary DESC;
# 我们可以使用列的别名进行排序
SELECT employee_id, salary, salary * 12 sum_salary
FROM employees
ORDER BY sum_salary DESC;
注意别名的使用:

补充:
1.上述错误示例是由于 WHERE sum_salary > 81600,where语句是在第一步,此时并没有起别名,所以导致出错
2.where语句需要声明在order by之前,from之后
2.二级排序
# 二级排序
SELECT department_id, salary, employee_id
FROM employees
WHERE department_id IN (50,60,70)
ORDER BY department_id DESC, salary ASC;
5-2 分页
1.基本使用
# 需求1:每页显示20条记录,此时显示第1页
SELECT employee_id, last_name
FROM employees
# 第一个是偏移量为0(相对于查询的数据)
LIMIT 0,20;
# 需求2:每页显示20条记录,此时显示第2页
SELECT employee_id, last_name
FROM employees
# 第一个是偏移量为20(先对于查询的数据)
LIMIT 20,20;
# 需求3:每页显示20条记录,此时显示第3页
SELECT employee_id, last_name
FROM employees
LIMIT 40,20;
# 对以上3个需求进行公式的推导
# 需求:每页显示pageSize条记录,此时显示第pageNum页
# 公司:LIMIT (pageNum-1) * pageSize, pageSize;
# LIMIT格式:LIMIT 位置偏移量, 条目数
# LIMIT进行分页时,该语句在最后面
SELECT employee_id, last_name, salary
FROM employees
WHERE salary > 6000
ORDER BY salary DESC
# 只有偏移量为0时,才可以如下写法
LIMIT 10
2.mysql8.0新特性格式:LIMIT 条目数 OFFSET 偏移量
# mysql8.0新特性格式:LIMIT 条目数 OFFSET 偏移量
# 需求:查询employees表中32条,33条数据
SELECT employee_id, last_name, salary
FROM employees
LIMIT 2 OFFSET 31;
3.练习看一下:
# 练习:查询employees表中工资最高的员工信息
SELECT employee_id, last_name, salary
FROM employees
ORDER BY salary DESC
LIMIT 1 OFFSET 0;
4.拓展:
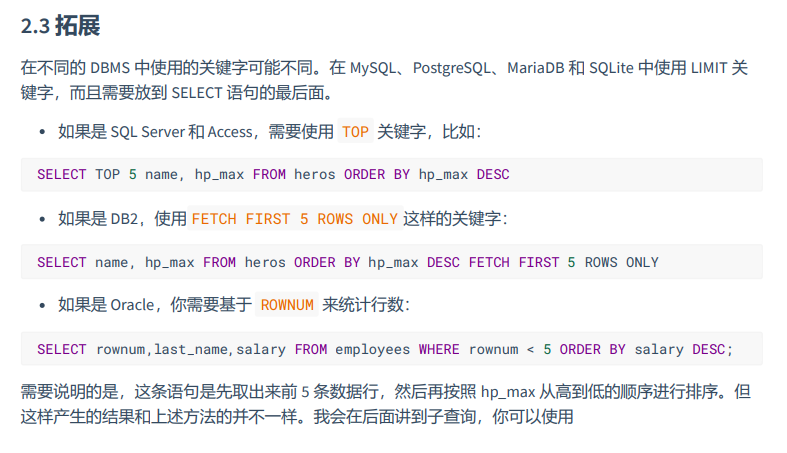
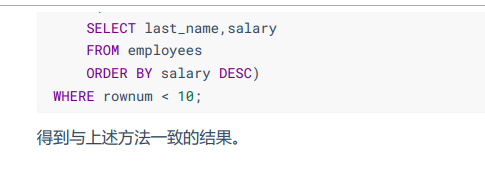
第6章 多表查询
如果将多个表连接成一张表的坏处:
1.每多连接一张表,总会连接多余的字段,造成字段冗余
2.如果将多张表连接为一张表,每连接一张表,就需要进行I/O操作,到那时加载的大多是冗余字段,频繁进行磁盘的I/O操作造成效率低下。
6-1 笛卡尔积的错误以及正确的多表查询方式
# 2.出现笛卡尔积的错误
# 出现该错误的:缺失了多表的连接条件
## 错误示例1:每一个员工都与部门匹配一遍
SELECT employee_id, department_name
FROM employees, departments; # 查询2889(107*27)条数据
## 错误示例2:
SELECT employee_id, department_name
FROM employees CROSS JOIN departments; # 查询2889(107*27)条数据
# 多表连接的正确方式:需要有连接条件
SELECT employee_id, department_name
FROM employees, departments
# 这个就是多表连接的连接条件
WHERE employees.`department_id` = departments.`department_id`; # 查询106条数据(注意:有一个员工的部门id为null)
# 如果查询的语句中的字段是表共有的字段,一定要指明是那一张表的字段
# 从sql优化的角度建议:对于查询的每一个字段,最好都指明该字段所在的表名,因为如果没有指明,还需要到两张表中去寻找该字段
SELECT employee_id, department_name,departments.`department_id`
FROM employees, departments
# 这个就是多表连接的连接条件
WHERE employees.`department_id` = departments.`department_id`;
# 可以给表起别名,一旦起了别名,mysql服务器中别名就会覆盖原来的表名,所以后序步骤只能用别名
SELECT e.employee_id, d.department_name,d.`department_id`
FROM employees e, departments d
WHERE e.`department_id` = d.`department_id`;
# 结论:如果有n个表实现多表的查询,至少需要n-1个连接条件
# 练习:查询员工的 employee_id,last_name, department_name,city
SELECT employee_id, last_name, department_name, city
FROM employees e, departments d, locations l
WHERE e.`department_id` = d.`department_id`
AND d.`location_id` = l.`location_id`
6-2 等值连接vs非等值连接,自连接 vs 非自连接,内连接 vs 外连接
注意:以上写的是等值连接
1.非等值连接
# 非等值连接的例子
SELECT *
FROM job_grades;
# 利用employees,job_grades这两张表,获取员工的的工资以及对应的工资等级
SELECT last_name, salary, grade_level
FROM employees e, job_grades j
-- where e.`salary`
-- between j.`lowest_sal`
-- and j.`highest_sal`
WHERE e.`salary` >= j.`lowest_sal`
AND e.`salary` <= j.`highest_sal`
2.自连接
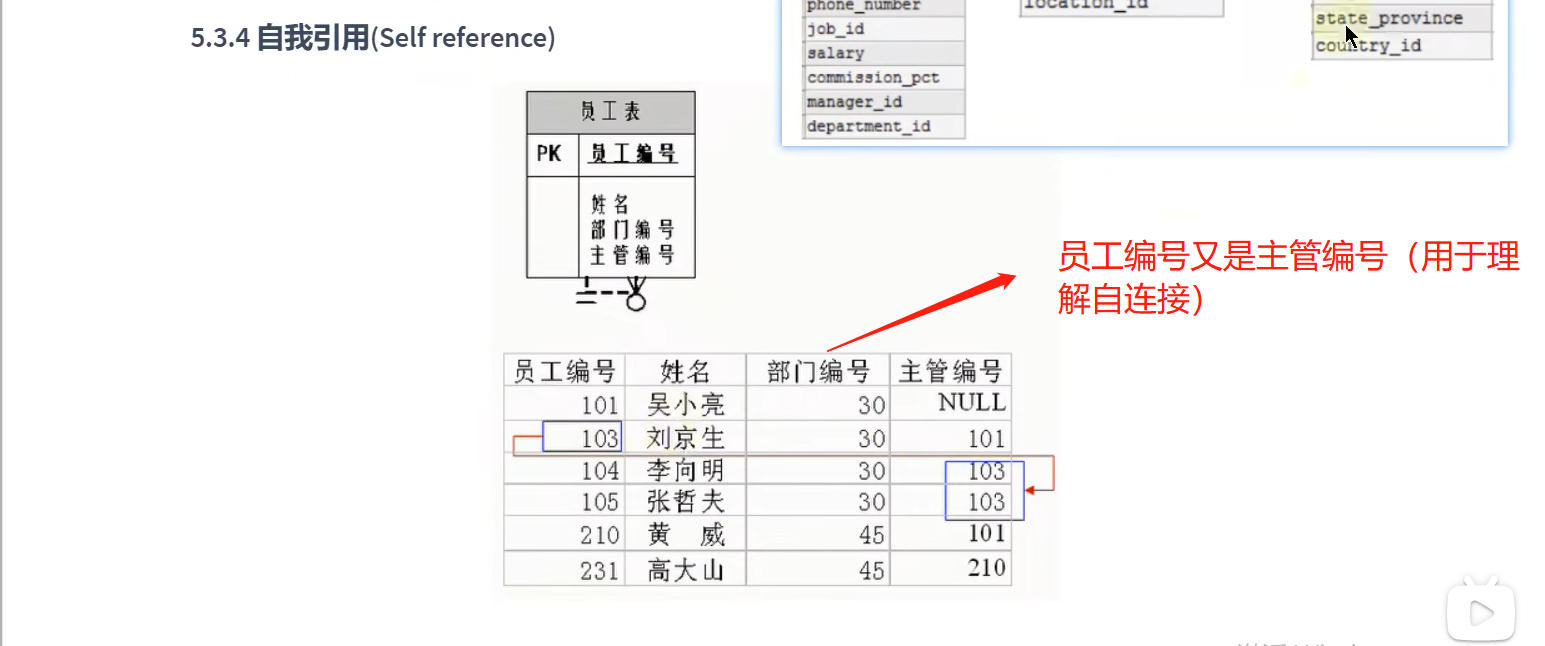
# 7.2 自连接 vs 非自连接
SELECT *
FROM employees;
# 需求:查询员工id,员工姓名以及对应的管理者的id,管理者的姓名
# 思路:管理者也是员工,都在employees这张表中,需要自连接进行查询
SELECT emp.employee_id, emp.last_name, emp.manager_id, m.last_name
FROM employees emp, employees m
WHERE emp.`manager_id` = m.`employee_id`
3.内连接与外连接(硬骨头)
明确概念:
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
如果是左外连接,则连接条件中左边的表也称为主表 ,右边的表称为 从表 。
如果是右外连接,则连接条件中右边的表也称为主表 ,左边的表称为 从表 。
内连接:
# 内连接
SELECT employee_id, department_name
FROM employees e, departments d
WHERE e.`department_id` = d.`department_id`;
注意:mysql不支持sql92外连接书写语法,但是Oracle支持。(有待考究)
===============以上是SQL92写法,接下来探究SQL99写法=
内连接:SQL99语法实现内连接:
## SQL99语法实现内连接:
### 需求:询员工的 employee_id,last_name, department_name,city
SELECT e.employee_id, e.last_name, d.department_name, l.city
-- from employees e inner join departments d # 也可以省略inner
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
JOIN locations l
ON d.`location_id` = l.`location_id`
外连接: SQL99语法实现外连接:
左外连接:
### 需求:查询所有员工的last_name, department_name信息
# 使用左外连接:
SELECT last_name, department_name
-- from employees e left outer join departments d
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
结果:
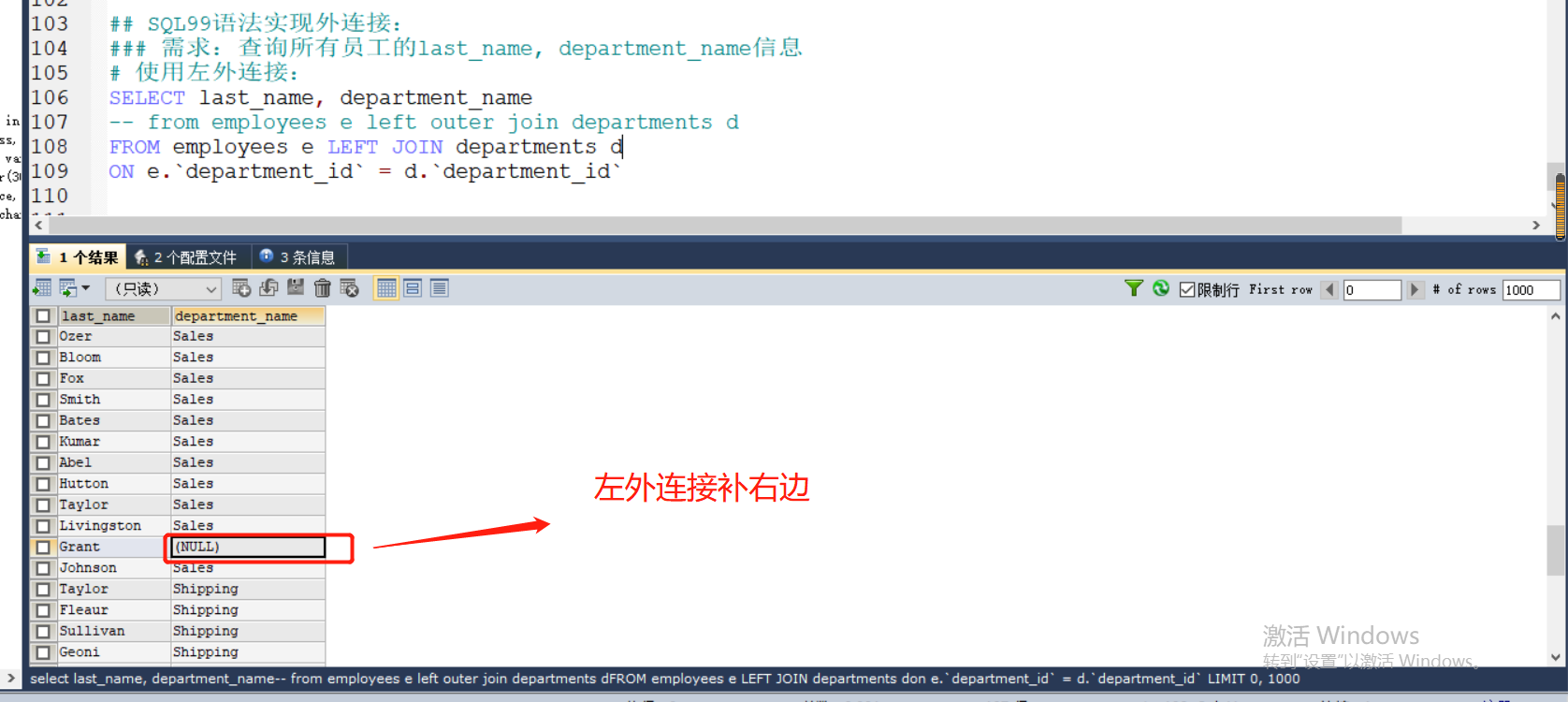
右外连接:
# 使用右外连接:右外连接保证右边字段的数据是完整的,左边对不上,补左边为空
SELECT last_name, department_name
FROM employees e RIGHT OUTER JOIN departments d
ON e.`department_id` = d.`department_id`
结果:
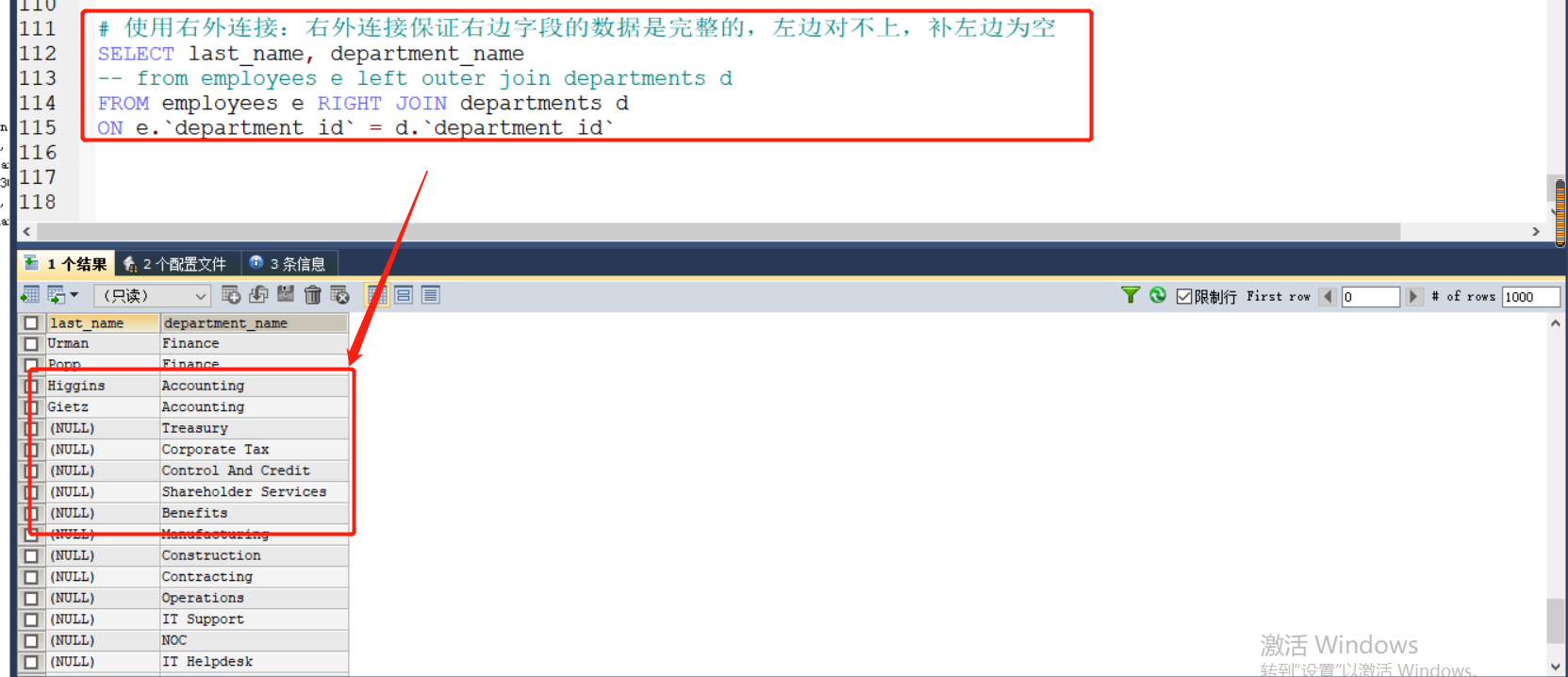
满外连接:
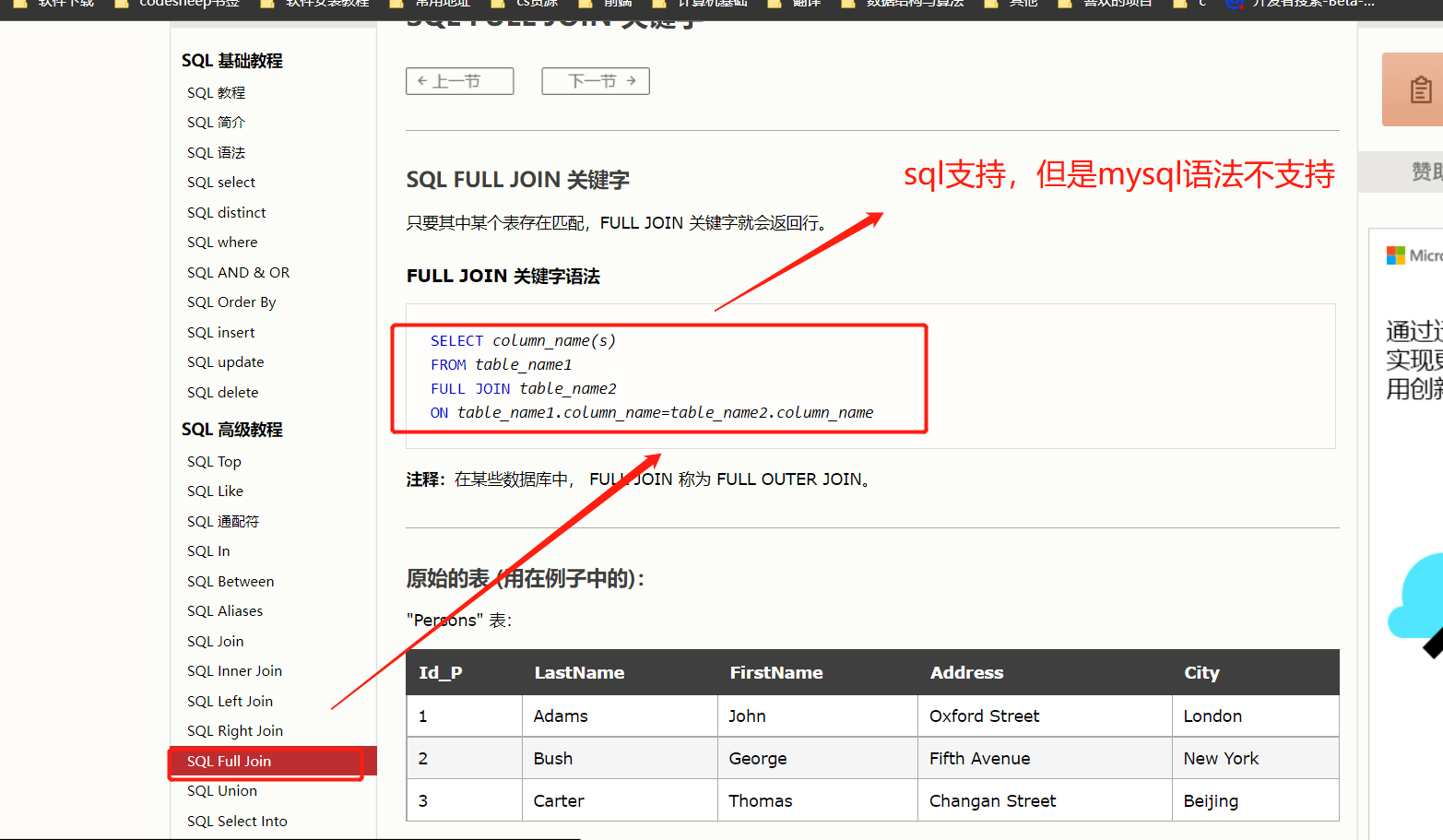
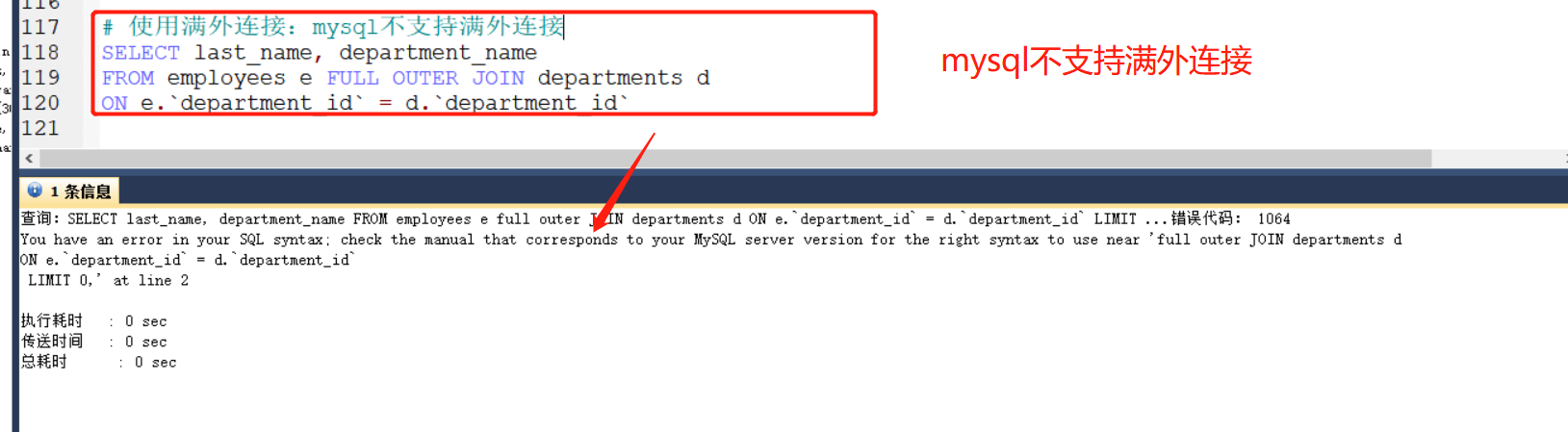
6-3 如图,7中SQL JSONS的实现
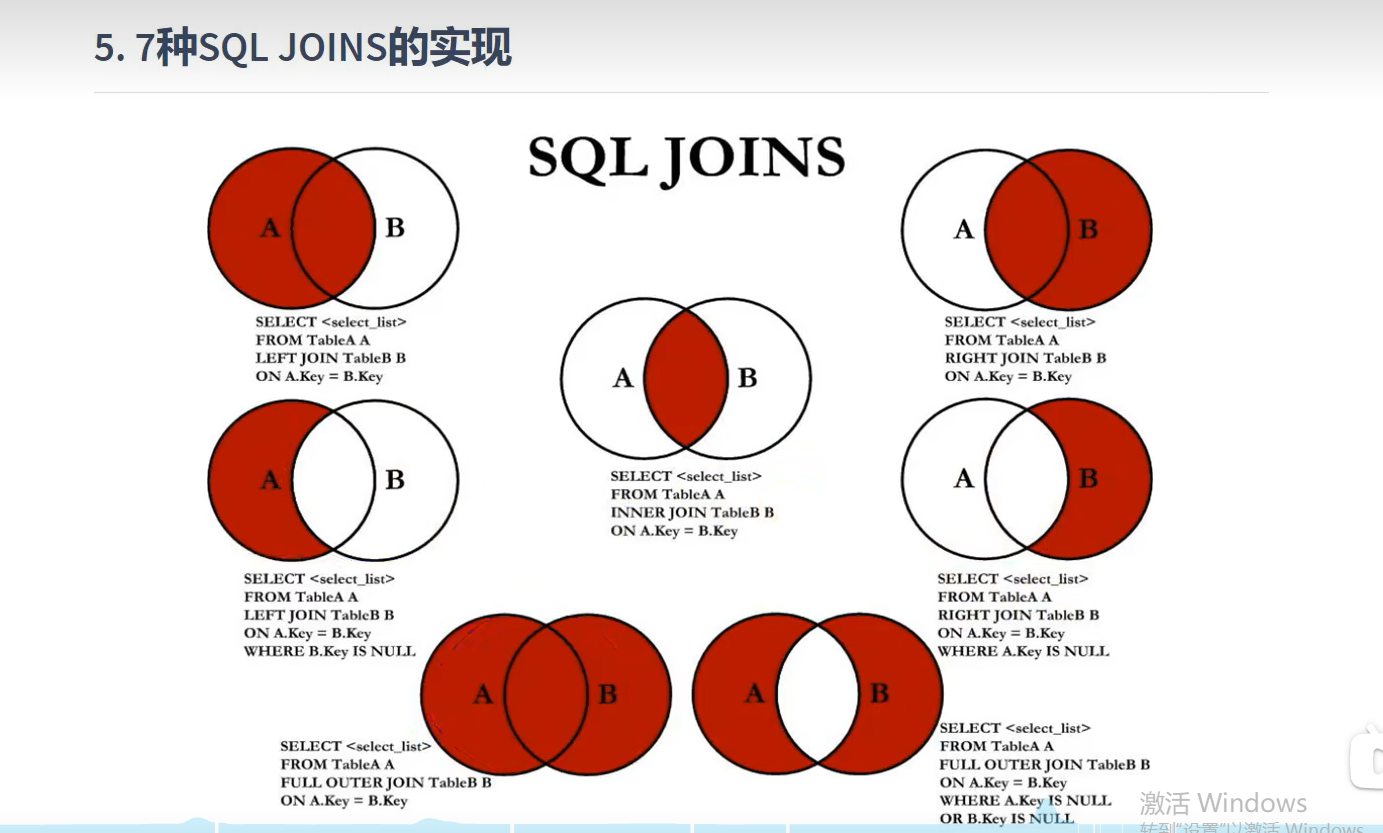
实现上图,由于mysql不支持 FULL JOIN关键字,所以无法直接实现满外连接,只能间接实现:
# 8.UNION 和 UNION ALL的使用
# UNION:会执行去重操作
# UNION ALL:不会执行去重操作
# 结论:如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复数据,
# 尽量使用UNION ALL 语句,以提高数据查询的效率
代码参考:注意下面两个表是组合而成,需要使用到UNION ALL取并集(实现以上7个图形)
# 7种JOIN的实现
## 最中间的实现:
SELECT employee_id, department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
## 左上:
SELECT employee_id, department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
## 右上图:
SELECT employee_id, department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
## 左中图
SELECT employee_id, department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL;
## 右中图
SELECT employee_id, department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
## 左下图:满外连接
### 方式1:左上图 UNION ALL 右中图
SELECT employee_id, department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
UNION ALL
SELECT employee_id, department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
### 方式2:左中图 UNION ALL 右上图
SELECT employee_id, department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id, department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
# 由下图:左中图 UNION ALL 右中图
SELECT employee_id, department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id, department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
6-4 SQL99语法的新特性1:自然连接
# SQL99语法的新特性1:自然连接
# SQL99 在 SQL92 的基础上提供了一些特殊语法,比如 NATURAL JOIN 用来表示自然连接。我们可以把
# 自然连接理解为 SQL92 中的等值连接。它会帮你自动查询两张连接表中所有相同的字段,然后进行等值
# 连接 。
SELECT employee_id, last_name, department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
AND e.`manager_id` = d.`manager_id`;
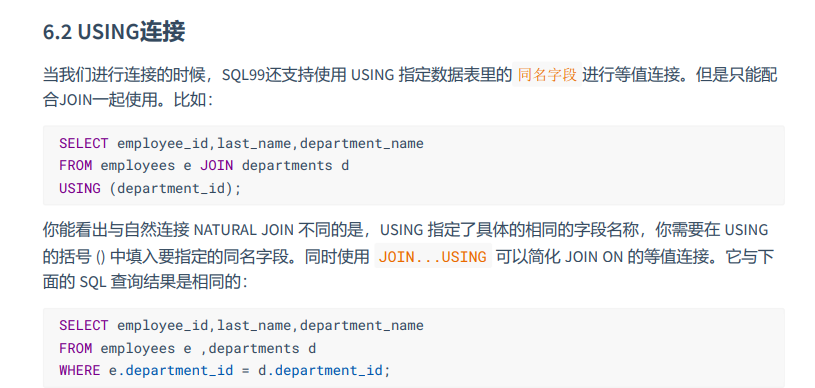
6-5 USING连接
6-6 练习
## 3.(重要):选择所有有奖金的员工的last_name, department_name, location_id, city
SELECT e.last_name, d.department_name, l.location_id, l.city
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
LEFT JOIN locations l # 因为employees表在左边,想要获取所有员工,右边的表都应该加上LEFT
ON d.`location_id` = l.`location_id`
WHERE e.commission_pct IS NOT NULL;
## (35行数据)
## 6.
SELECT emp.last_name "employees", emp.employee_id "Emp#", mgr.last_name "manager", mgr.employee_id "Mgr#"
FROM employees emp JOIN employees mgr
ON emp.`manager_id` = mgr.`employee_id`;
## (106行数据)
## 7.查询那些部门没有员工
### 思路:画图,部门的整个部分减去与员工有交集部分的那个范围(可以使用 e.`department_id` IS NULL),
### 剩下的就是部门没有员工的部分
SELECT department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
## (16个数据)
## 该题目也可以使用子查询解决,后面章节会讲
第7章 单行函数
7-1 数值函数使用
参见:老师pdf

7-2 字符串函数(具体参见老师资料)
# 字符串函数实际应用
## 1.CONCAT:用于连接字符串
SELECT CONCAT(emp.`last_name`, ' work for ', mgr.`last_name`) '员工为管理者工作统计'
FROM employees emp JOIN employees mgr
ON emp.`manager_id` = mgr.`employee_id`;
## 2.CONCAT_WS:使用指定字符连接字符串
SELECT CONCAT_WS('-', 'hello', 'world', 'hello', 'beijing')
FROM DUAL;
## 3.替换函数
# INSERT:mysql索引从1开始,下面语句表示从索引2开始的3个字符用5个a替换
SELECT INSERT('helloworld', 2, 3, 'aaaaa'),
# REPLACE:将字符串中ell部分直接用字符xurong替换
REPLACE('====hello===', 'hello', 'xurong')
FROM DUAL;
## 4.将字符全部转变为大写(UPPER)或小写(LOWER)
# mysql不区分大小写,Oracle区分大小写,此方法可以如下运用到Oracle中,
# 原数据为King,使用LOWER函数,即使条件是king也是可以的
SELECT last_name,salary
FROM employees
WHERE LOWER(last_name) = 'king';
## 5.截取字符串的函数
SELECT LEFT('hello', 2), RIGHT('hello',2)
FROM DUAL;
## 6.LPAD:实现右对齐效果,RPAD:实现左对齐效果
# 将工资实现右对齐,总共占10位,不足的地方补'*'
SELECT employee_id, last_name, LPAD(salary, 10,'*')
FROM employees;
## 7.NULLIF(a,b):a和b相等,返回NULL,否则返回a
SELECT employee_id,first_name, last_name,NULLIF(LENGTH(first_name),LENGTH(last_name)) "compare"
FROM employees;
7-3 日期和时间函数
### 1.获取日期和时间
SELECT CURDATE(),CURTIME(), NOW(), UTC_DATE, UTC_TIME
FROM DUAL;
### 2.日期时间戳的转换
SELECT UNIX_TIMESTAMP(),UNIX_TIMESTAMP('2022-11-13 09:17:47'),FROM_UNIXTIME(166830218)
FROM DUAL;
### 3.获取月份,星期,星期数,天数等函数
# 单独获取年月日
SELECT YEAR(CURDATE()), MONTH(CURDATE()), DAY(CURDATE())
FROM DUAL;
# 单独获取 小时,分钟,秒
SELECT HOUR(CURTIME()), MINUTE(CURTIME()), SECOND(CURTIME())
FROM DUAL;
# 返回月份,返回星期几,返回周几, 返回日期对应的季度,返回一年中的第几周,返回一年中第几天,返回日期所在月份的第几天
# 返回周几(周日是1)
SELECT MONTHNAME(CURDATE()),DAYNAME(CURDATE()), WEEKDAY(CURDATE()), QUARTER
(CURDATE()),WEEK(CURDATE()) "一年中第几周", DAYOFYEAR(CURDATE()), DAYOFMONTH(CURDATE()),DAYOFWEEK(CURDATE())
FROM DUAL;
计算时间和日期的函数:
### 4.计算时间和日期的函数
# 为现在的时间增加一个月
SELECT NOW(),
DATE_ADD(NOW(), INTERVAL 1 MONTH) "加一个月后的结果",
DATE_ADD(NOW(), INTERVAL '1_6' MINUTE_SECOND) "加1分钟,6秒的结果"
FROM DUAL;
日期的格式化与解析:
### 5. 日期的格式化与解析
# 5-1.日期的格式化:将日期根据指定的格式转变为字符串
SELECT CURDATE(),DATE_FORMAT(CURDATE(),'%Y-%M-%D'),
CURTIME(),TIME_FORMAT(CURTIME(), '%h::%i::%s'),
NOW(), DATE_FORMAT(NOW(),'%Y-%M-%D %h:%i:%s %W %w %T %r')
FROM DUAL;
# 5-2解析:格式化的逆过程
SELECT
STR_TO_DATE('2022-November-13th 10:10:04 Sunday 0 10:10:04 10:10:04 AM', '%Y-%M-%D %h:%i:%s %W %w %T %r')
FROM DUAL;
# 5-3:获取常见的日期格式
SELECT GET_FORMAT(DATE, 'USA')
FROM DUAL;
## 应用:不需要自己写日期格式化,直接使用现成的格式化
SELECT CURDATE(), DATE_FORMAT(CURDATE(),GET_FORMAT(DATE, 'USA'))
FROM DUAL;
7-4 流程控制函数
### 6.流程控制函数
# 6-1 IF(a,b,c):如果a为true,返回b,否则返回c
SELECT last_name, salary, IF(salary >= 6000, '高工资', '低工资') "details"
FROM employees;
## 应用:计算带有利息的年工资
SELECT last_name, salary, commission_pct,IF(commission_pct IS NOT NULL, commission_pct, 0) "detail",
salary * 12 *(1 + IF(commission_pct IS NOT NULL, commission_pct, 0)) "年工资"
FROM employees
ORDER BY 年工资 DESC;
# 6-2 IFNULL(a,b):看作是6-1的一种特殊情况,如果a不为空,返回a,否则返回b.(上一种情况更灵活)
SELECT last_name, salary, commission_pct,IFNULL(commission_pct, 0) "detail",
salary * 12 *(1 + IFNULL(commission_pct, 0)) "年工资"
FROM employees
ORDER BY 年工资 DESC;
# 6-3 CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 .... [ELSE resultn] END
# 类似于java中的if...else if...else if...else
SELECT last_name, salary, CASE WHEN salary >= 15000 THEN '大老板'
WHEN salary >= 10000 THEN '小老板'
WHEN salary >= 8000 THEN '打工人'
ELSE '小孩子'
END "detail"
FROM employees
ORDER BY salary DESC;
### 6-4 CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN 值1 .... [ELSE 值n] END
# 相当于Java的switch...case...
# 查询部门号为10,20,30的员工信息,
# 若部门号为10,则打印其工资的1.1倍,
# 20号部门,则打印其工资的1.2倍,
# 30号部门打印其工资的1.3倍数
SELECT employee_id, last_name, department_id, salary, CASE department_id WHEN 10 THEN salary * 1.1
WHEN 20 THEN salary * 1.2
WHEN 30 THEN salary * 1.3
END "detials"
FROM employees
WHERE department_id IN (10,20,30)
ORDER BY department_id ASC;
7-5 加密与解密的函数
### 加密与解密的函数
SELECT MD5("xurong"),SHA("xurong")
FROM DUAL;
7-6 mysql信息函数

7-7 其他函数补充
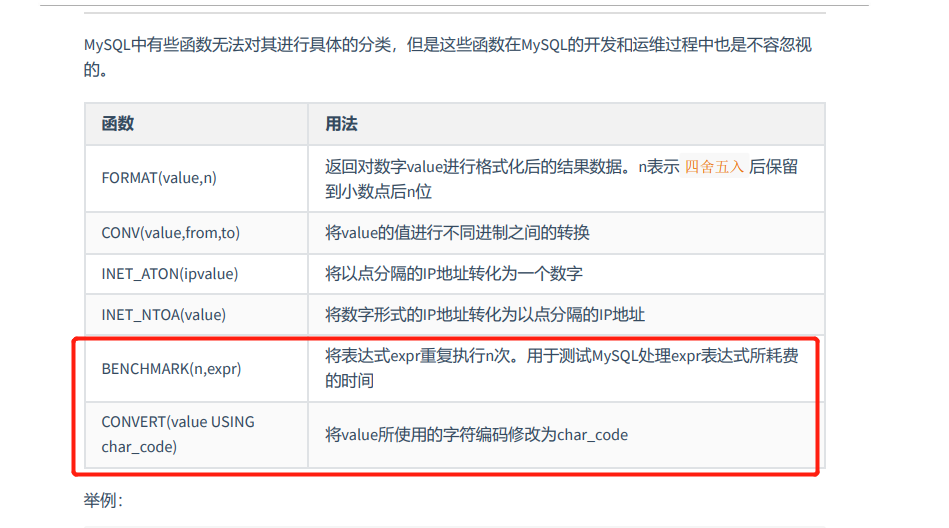
### 8.mysql其他函数补充
# 测试表达式的执行效率的函数
# BENCHMARK(n,expression):将表达式expr重复执行n次。用于测试MySQL处理expr表达式所耗费的时间
SELECT BENCHMARK(100000, MD5("xurong"))
FROM DUAL;
第8章 聚合函数
8-1 常见的几个聚合函数
### 1.常见的几个聚合函数
# 1.1:AVG(求平均值) SUM(总和)
SELECT AVG(salary) "工资平均值", SUM(salary) "总和"
FROM employees;
# 1.2 MAX / MIN:适用于数值类型,字符串类型,日期时间类型字段或变量
SELECT MAX(salary), MIN(salary)
FROM employees;
8-2 count使用和注意事项:
# 1.3 COUNT函数:
# ①:计算指定字段在查询结构中出现的个数(不包含NULL值)
SELECT COUNT(employee_id), COUNT(salary), COUNT(2 * salary), COUNT(1), COUNT(2), COUNT(*)
FROM employees;
/*
count(employee_id) count(salary) count(2 * salary) count(1) count(2) count(*)
------------------ ------------- ----------------- -------- -------- ----------
107 107 107 107 107 107
结果:
说明:
COUNT(2 * salary):只是计算salary字段在表中出现的个数,跟salary大小没有关系
COUNT(1):因为COUNT()函数是自带循环的,此时的1代表着表中的一行,COUNT(1)结果就是表中行数
COUNT(2):此时的2代表着表中的一行,表中有多少个2,反映出有多少行
*/
# ②注意:计算指定字段在表中出现的个数时,是不计算NULL值的
##如果计算表中有多少条记录,如何实现?
### 方式1:COUNT(*)
### 方式2:COUNT(1)
### 方式3:COUNT(具体字段):不一定对!--》因为如果该字段的值为NULL将不会别纳入计数范围
SELECT COUNT(commission_pct) # 35条记录(不是107,对于commission_pct为NULL的行没有纳入计数范围)
FROM employees;
SELECT commission_pct
FROM employees
WHERE commission_pct IS NOT NULL; # 35行数据
# ③ 公式:AVG = SUM / COUNT
SELECT AVG(salary), SUM(salary) / COUNT(salary),
AVG(commission_pct),SUM(commission_pct) / COUNT(commission_pct),
SUM(commission_pct) / 107
FROM employees;
/*
结果:
avg(salary) sum(salary) / count(salary) avg(commission_pct) sum(commission_pct) / count(commission_pct) sum(commission_pct) / 107
----------- --------------------------- ------------------- ----------------------------- ---------------------------
6461.682243 6461.682243 0.222857 0.222857 0.072897
说明:AVG函数在计算字段的平均时,也是默认过滤掉了字段为NULL的字段
*/
## 应用:查询公司中平均奖金率
# 错误示例: 过滤掉了commission_pct为NULL的字段,导致总的人数减少,计算平均值时不准确
SELECT AVG(commission_pct)
FROM employees;
# 正确示例:
SELECT SUM(commission_pct) / COUNT(IFNULL(commission_pct, 0)) "实际平均值"
FROM employees;
# 正确示例
SELECT AVG(IFNULL(commission_pct,0))
FROM employees;

8-3 GROUP BY使用
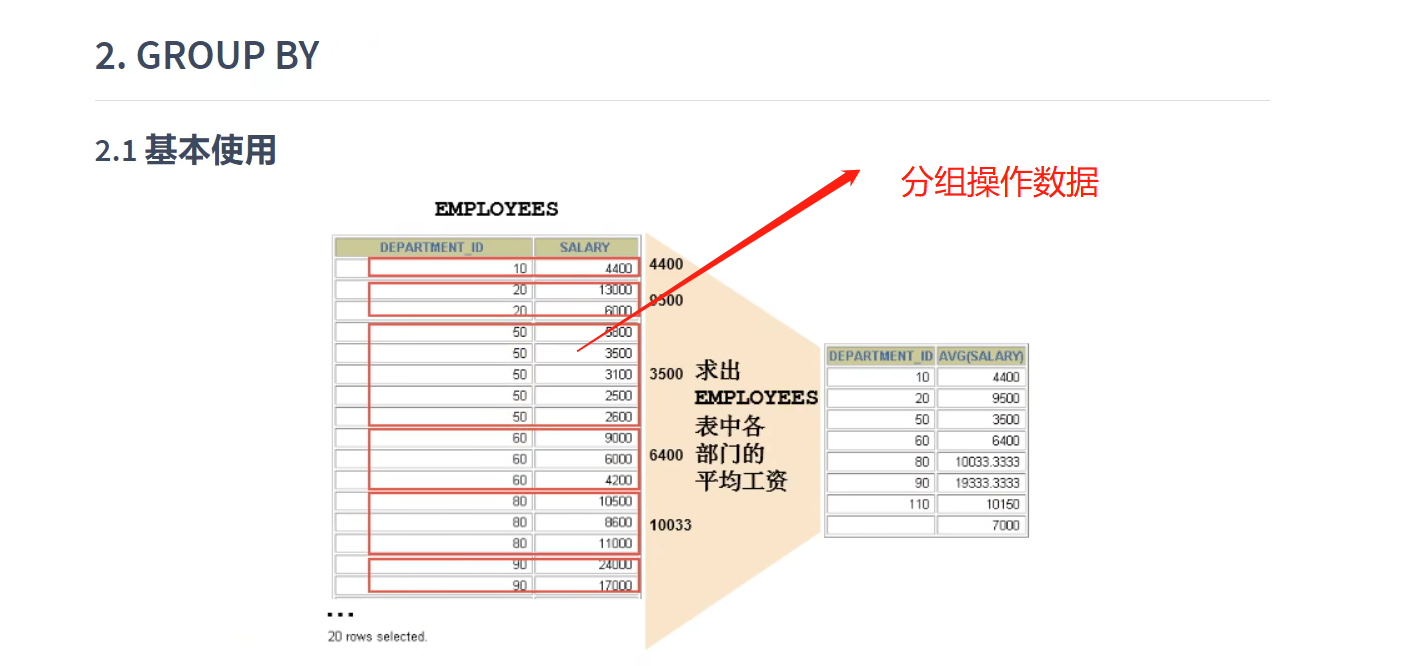
### 2.GROUP BY 的使用
# 需求1:查询各个部门的平均工资,最高工资
SELECT department_id,AVG(salary), MAX(salary)
FROM employees
GROUP BY department_id;
# 需求2: 查询各个job_id的平均工资
SELECT job_id, AVG(salary)
FROM employees
GROUP BY job_id;
# 需求3:查询各个department_id, job_id的平均工资
# 先按照部门分,后按照工种分
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id, job_id;
# 或者先按照工总分,后按照部门分也是一样(查询的数据条数一样,
# 因为只有同一个部门,同一个工种才能划分到一起)
SELECT job_id, department_id, AVG(salary)
FROM employees
GROUP BY job_id, department_id;
# 错误写法示例:mysql8.0中也会报错,放到Oracle中会报错
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id;
/*
Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column
'atguigudb.employees.job_id' which is not functionally dependent on columns in GROUP BY
clause; this is incompatible with sql_mode=only_full_group_by
报错原因:
根据部门id进行分组,只能显示一行,但是一个部门中不只只有一个工种,而没有对工种进行分类,
由此导致报错
*/
/*
避免上述问题的一个总结:
结论1:
SELECT中出现的非组函数的字段必须声明在GROUP BY中。
(通俗讲:SELECT中使用了的字段都必须声明在GROUP BY中)
反之,GROUP BY中声明的字段可以不出现在SELECT中
结论2:GROUP BY声明在FROM后面,WHERE后面,ORDER BY的前面,LIMIT前面
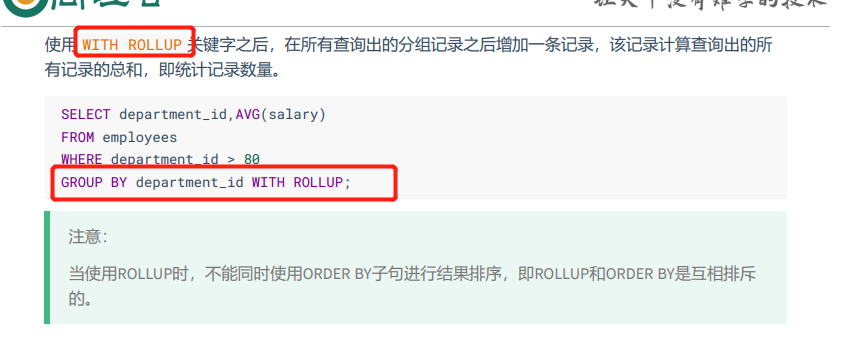
结论3:MySQL中GROUP BY中使用WITH ROLLUP
*/
补充:WITH ROLLUP使用
8-4 HAVING使用与SQL语句执行过程
### 3.HAVING的使用
# 需求:根据department_id进行分组,然后使用聚合函数筛选出每个组中最高salary > 10000的组
## 错误示例:
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
WHERE MAX(salary) > 10000;
## 正确示例:
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
/*
总结:
结论1:如果过滤条件中使用了聚合函数,则必须使用HAVING来替代WHERE.否则,报错。
结论2:HAVING必须声明在GROUP BY的后面。
结论3:开发中,我们使用HAVING的前提是SQL中使用了GROUP BY
*/
# 实际应用
## 需求:查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
#方式1:WHERE与HAVING相结合的方式(推荐使用,效率更高)
SELECT department_id, MAX(salary)
FROM employees
WHERE department_id IN (10, 20, 30, 40)
GROUP BY department_id
HAVING MAX(salary) > 10000;
# 方式2:
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id IN (10, 20, 30, 40);
/*
①结论:
当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中。
当过滤条件中没有聚合函数时,此过滤条件声明在HAVING或WHERE都可以,但是建议声明在WHERE中。
②WHERE与HAVING的对比:
1.从适用范围上讲,HAVING适用范围更广
2.如果过滤条件中没有聚合函数:使用WHERE进行过滤的执行效率高于使用HAVING进行过滤的执行条件
*/
8-5 SQL底层执行原理
写select语句的规范对比:

SQL底层执行原理:
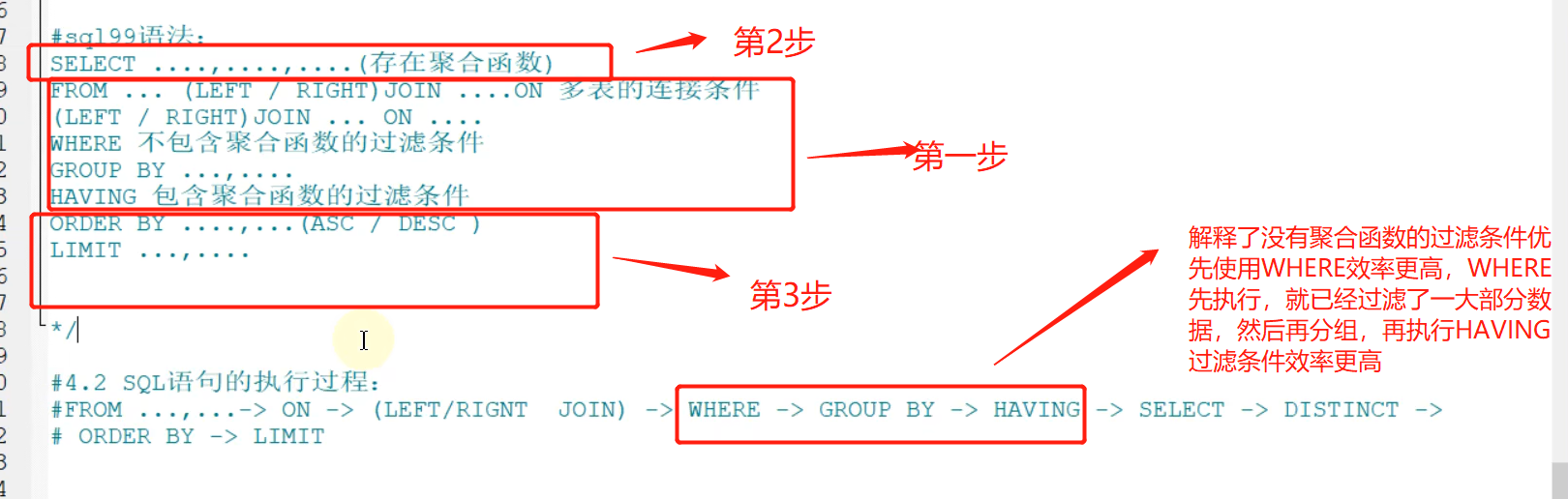
SQL底层执行原理:
SELECT是先执行FROM这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
1.首先先通过CROSSJOIN求笛卡尔积,相当于得到虚拟表vt(virtualtable)1-1;
2.通过ON进行筛选,在虚拟表vt1-1的基础上进行筛选,得到虚拟表vt1-2;
3.添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表vt1-2的基础上增加外部行,得到虚拟表vt1-3。
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。当我们拿到了查询数据表的原始数据,也就是最终的虚拟表vt1,就可以在此基础上再进行WHERE阶段。
在这个阶段中,会根据vt1表的结果进行筛选过滤,得到虚拟表vt2。
然后进入第三步和第四步,也就是 GROUP 和 HAVING 阶段。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表 vt3 和 vt4 。当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到 SELECT 和 DISTINCT阶段 。
首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表vt5-1 和 vt5-2。
当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是 ORDER BY 阶段,得到虚拟表 vt6。
最后在 vt6 的基础上,取出指定行的记录,也就是 LIMIT 阶段 ,得到最终的结果,对应的是虚拟表vt7。
当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为SQL是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的
关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序。
第9章 子查询
9-1 需求分析与问题解决:
## 需求:谁的工资比Abel高?
#方式1:先查询导Abel的工资,然后再根据工资进行过滤筛选
SELECT salary
FROM employees
WHERE last_name = 'Abel';
SELECT last_name, salary
FROM employees
WHERE salary > 11000;
# 方式2:自连接
SELECT emp2.last_name, emp2.salary
FROM employees emp1, employees emp2
-- where emp1.`last_name` = 'Abel'
-- and emp1.`salary` < emp2.`salary`;
WHERE emp1.`salary` < emp2.`salary`
AND emp1.`last_name` = 'Abel';
# 方式3:子查询
SELECT last_name, salary
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE last_name = 'Abel'
);
/*
1.子查询(内查询)在主查询之前一次执行完成。
2.子查询的结果被主查询(外查询)使用 。
3.注意事项:
子查询要包含在括号内
将子查询放在比较条件的右侧
单行操作符对应单行子查询,多行操作符对应多行子查询
4.子查询的分类:
角度1:从内查询返回的结果的条目数分类:单行子查询,多行子查询
角度2:内查询是否被执行多次分类:相关子查询,不相关子查询
eg:
相关子查询的需求:查询工资大于本部门平均工资(不同员工对应不
同部门计算平均工资的子查询需要计算多次)的员工信息。
不相关子查询的需求:查询工资大于本公司平均工资(该子查询只需要执行一次)的员工信息。
*/
9-2 单行子查询
# 4.单行子查询
### 4.1 单行操作符:= != > >= < <=
##需求1:查询工资大于149号员工工资的员工信息
#子查询步骤:①从里往外写 ②从外往里写
SELECT employee_id, last_name, salary
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE employee_id = 149
);
### 4.2 单行子查询
## 需求2:返回job_id与141号员工相同,salary比143号员工多的员工信息,job_id和工资
SELECT last_name, job_id, salary
FROM employees
WHERE job_id = (
SELECT job_id
FROM employees
WHERE employee_id = 141
)
AND salary >(
SELECT salary
FROM employees
WHERE employee_id = 143
);
## 需求3:返回公司工资最少的员工的last_name, job_id和salary
SELECT last_name, job_id, salary
FROM employees
WHERE salary = (
SELECT MIN(salary)
FROM employees
);
## 需求4:查询与141号员工的manager_id和department_id相同的其他员工的employee_id,
## manager_id,department_id
# 方式1:
SELECT employee_id, manager_id, department_id
FROM employees
WHERE manager_id = (
SELECT manager_id
FROM employees
WHERE employee_id = 141
)
AND department_id = (
SELECT department_id
FROM employees
WHERE employee_id = 141
)
# 对应需求中的"其他员工"
AND employee_id <> 141;
# 方式2:只需了解--将manager_id, department_id作为整体去进行子查询
SELECT employee_id, manager_id, department_id
FROM employees
WHERE (manager_id, department_id) = (
SELECT manager_id, department_id
FROM employees
WHERE employee_id = 141
)
# 对应需求中的"其他员工"
AND employee_id <> 141;
### 4.3 HAVING中使用子查询
## 需求5:查询最低工资大于110号部门最低工资的部门id和其最低工资
SELECT department_id, MIN(salary)
FROM employees
GROUP BY department_id
HAVING MIN(salary) > (
SELECT MIN(salary)
FROM employees
WHERE department_id = 110
);
### 4.4 case中使用子查询(凡是有不确定的地方都是用子查询)
# 显示员工的employee_id,last_name和location。其中,若员工department_id与location_id为1800
# 的department_id相同,则location为’Canada’,其余则为’USA’。
SELECT employee_id, last_name, (CASE department_id WHEN(
SELECT department_id
FROM departments
WHERE location_id = 1800
) THEN 'Canada'
ELSE 'USA'
END ) "locations"
FROM employees;
### 4.5 子查询中的空值问题
SELECT last_name, job_id
FROM employees
WHERE job_id = (
SELECT job_id
FROM employees
WHERE last_name = 'Haas');
/* 上述子查询中last_name不存在表中, 子查询结果为空,虽然最终没有结果,但是不会报错*/
### 4.6 非法使用子查询
# 错误示例
SELECT employee_id, last_name
FROM employees
WHERE salary =(
SELECT MIN(salary)
FROM employees
GROUP BY department_id);
/*
报错:Subquery returns more than 1 row
原因:子查询产生了多条数据,但是用的操作符是单行操作符,由此导致报错。
*/
9-3 多行子查询
# 5.多行子查询
## 5.1 多行子查询的操作符:IN, ANY, ALL, SOME(同ANY)
# IN:处理子查询的结果有多个
SELECT employee_id, last_name
FROM employees
WHERE salary IN (
SELECT MIN(salary)
FROM employees
GROUP BY department_id);
# ANY/ALL:
## 需求:返回其它job_id中比job_id为‘IT_PROG’部门任一工
## 资低的员工的员工号、姓名、job_id 以及salary
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ANY(
SELECT salary
FROM employees
WHERE job_id = 'IT_PROG'
);
## 需求:查询平均工资最低的部门id
# 注意:mysql中聚合函数是不能嵌套的,而Oracle中可以嵌套
# 方式1:
-- 第1步:查询平均工资
SELECT AVG(salary)
FROM employees
GROUP BY department_id;
-- 第2步:将上一步的查询结果当作一个表,为其起一个别名
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id;
-- 第3步:
-- 将avg_salary别名当作表名,并为其另外起一个别名avg_salary_new,查找出最小的平均工资,
-- 注意:使用双引号起的别名好像不能当作表进行如下操作,使用空格起的别名可以进行如下操作
SELECT MIN(avg_salary)
FROM (
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
) avg_salary_new;
-- 第4步:根据最低工资查询到最低的部门号即可
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_salary)
FROM (
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
) avg_salary_new
);
# 方式2:
SELECT department_id
FROM employees
GROUP BY department_id
# 平均工资小于等于所有的平均工资, 只有平均工资最小的才符合等于条件
HAVING AVG(salary) <= ALL(
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
);
# 5.2 空值问题
## 需求:查询不是管理者的员工
# 特别注意:子查询结果如果是空值(NULL),会导致整个查询结果为NULL,需要使用
# 过滤条件过滤掉子查询为空的结果
SELECT last_name
FROM employees
WHERE employee_id NOT IN (
SELECT manager_id
FROM employees
# where manager_id is not Null
);
9-4 关联子查询
概念:
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件 关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询
过程图示:
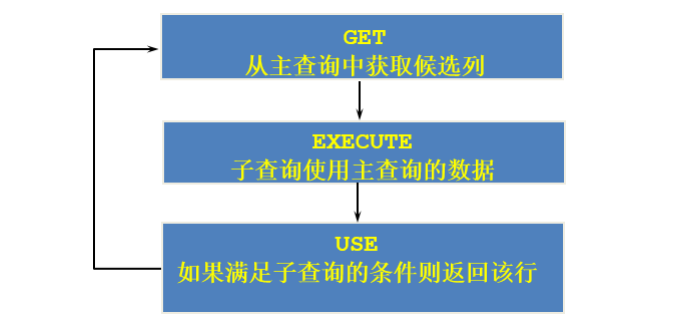 。
。
知识点总结:
# 6.相关子查询
## 不相关子查询举例
### 需求:查询员工中工资大于公司平均工资的员工的last_name,salary和department_id
SELECT last_name, salary, department_id
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);
##相关子查询
### 需求1:查询员工中工资大于本部门平均工资的员工的last_name,salary和department_id
# 方式1:
SELECT last_name, salary, department_id
FROM employees e1
WHERE salary > (
SELECT AVG(salary)
FROM employees e2
WHERE e2.department_id = e1.`department_id`
);
/*
过程分析举例:
第1步:从主查询中获取department_id(候选列) = 90
第2步:子查询中使用主查询查询到的数据department_id = 90,获取对应
90号部门的平均工资
第3步:如果主查询获取的该行数据(department_id = 90)中的salary
大于子查询获取的90号部门的平均工资,则返回该行
*/
# 方式2:在from中使用子查询
## 第1步:查出department_id, 和对应部门的平均工资,将查询到的结果作为一张表
SELECT department_id, AVG(salary) avg_salary
FROM employees
GROUP BY department_id;
## 第2步:将employees表与上表进行关联
SELECT e.`last_name`, e.`salary`, e.`department_id`
FROM employees e JOIN (
SELECT department_id, AVG(salary) avg_salary
FROM employees
GROUP BY department_id
) t_dept_avg_salary
ON e.`department_id` = t_dept_avg_salary.department_id
AND e.`salary` > t_dept_avg_salary.avg_salary;
### 需求2:查询员工的id,salary,按照department_name 排序
SELECT e.employee_id, e.salary
FROM employees e
ORDER BY(
SELECT department_name
FROM departments d
WHERE d.`department_id` = e.`department_id`
);
/*
小总结:在SELECT中,除了GROUP BY和LIMIT外,其他位置都可以声明子查询
SELECT ....,....,....(存在聚合函数)
FROM ... (LEET / RIGHT)JOIN ....ON多表的连接条件
(LEFT /RIGHT)JOIN ... ON ....
WHERE不包含聚合函数的过滤条件
GROUP BY ...,.. . .
HAVING包含聚合函数的过滤条件
ORDER BY .... , ...(ASC / DESC )
LIMIT ...,...
*/
练习1:
### 需求3:
### 若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同
### id的员工的employee_id,last_name和其job_id
# 方式1:没有使用关联查询
## 第1步:从job_history表中根据employee_id分组,统计employee_id出现的次数
SELECT COUNT(*) id_count,employee_id
FROM job_history
GROUP BY employee_id;
## 第2步:将第一步查出来的结果作为新表,根据employee_id与employees表进行连接,只需要员工数满足大于等于2即可
SELECT e.employee_id, e.last_name, e.job_id
FROM employees e JOIN (
SELECT COUNT(employee_id) id_count,employee_id
FROM job_history
GROUP BY employee_id
) id_count_emp
ON e.employee_id = id_count_emp.employee_id
WHERE id_count_emp.id_count >= 2;
# 方式2:关联查询--老师的方式
SELECT e.employee_id, e.last_name, e.job_id
FROM employees e
WHERE 2 <= (
SELECT COUNT(*)
FROM job_history j
WHERE e.`employee_id` = j.`employee_id`
);
9-4-1 EXISTS 与 NOT EXISTS关键字
#### EXISTS 与 NOT EXISTS关键字
###需求1:查询公司管理者的employee_id,last_name,job_id,department_id信息
# 方式1:
SELECT DISTINCT e1.employee_id, e1.last_name, e1.job_id, e1.department_id
FROM employees e1 JOIN employees e2
ON e1.`employee_id` = e2.`manager_id`;
# 方式2:
## 第1步:查询manager_id
SELECT DISTINCT manager_id
FROM employees;
## 第2步:将以上结果作为子查询
SELECT DISTINCT e1.employee_id, e1.last_name, e1.job_id, e1.department_id
FROM employees e1
# 管理者也是员工
WHERE e1.`employee_id` IN (
SELECT DISTINCT manager_id
FROM employees
);
# 方式3:使用exists关键子,但找到结果,就不继续往下寻找
SELECT DISTINCT e1.employee_id, e1.last_name, e1.job_id, e1.department_id
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e1.`employee_id` = e2.`manager_id`
);
/*
说明:
e1,e2是同一张表,目的是逐条找到e1.`employee_id` = e2.`manager_id`这条数据,
EXISTS,一但找到这条数据,就不继续往下寻找了,返回e1.`employee_id` = e2.`manager_id`
的结果,然后在根据结果返回所需要的目的字段的数据。
*/
#### 需求2:
#### 查询departments表中,不存在于employees表中的部门的department_id和
#### department_name
# 方式1:
SELECT d.department_id, d.department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`employee_id` IS NULL;
# 方式2:使用NOT EXISTS
SELECT department_id, department_name
FROM departments d
WHERE NOT EXISTS (
SELECT *
FROM employees e
WHERE e.`department_id` = d.`department_id`
);
/*
说明:
利用e.`department_id` = d.`department_id`条件逐条查找employeees表中的数据,
使用了NOT EXISTS关键字进行限定,直到逐条查找完成,没有一条数据满足以上条件,
那么该数据就是我们所要查找的数据
*/
9-5 子查询的练习:
#1.查询和zlotkey相同部门的员工姓名和工资
SELECT last_name, salary
FROM employees e
WHERE department_id = (
SELECT department_id
FROM employees
WHERE last_name = 'zlotkey'
);
# 34data
#2.查询工资比公司平均工资高的员工的员工号,姓名和工资
SELECT employee_id, last_name, salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);
# 51data
#3.选择工资大于所有job_id = 'SA_MAN'的员工的工资的员工的last_name,job_id,salary
SELECT last_name, job_id, salary
FROM employees
WHERE salary > ALL(
SELECT salary
FROM employees
WHERE job_id = 'SA_MAN'
);
# 3data
#4.查询和姓名中包含字母u的员工在相同部门的员工的员工号和姓名
SELECT employee_id, last_name
FROM employees
WHERE department_id IN (
SELECT DISTINCT department_id
FROM employees e
WHERE e.`last_name` LIKE '%u%'
);
# 96data
#5.查询在部门的location_id为1700的部门工作的员工的员工号
SELECT employee_id
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location_id = 1700
);
# 18data
#6.查询管理者是King的员工姓名和工资
SELECT last_name, salary
FROM employees e
WHERE manager_id IN (
SELECT employee_id
FROM employees e
WHERE e.`last_name` = 'King'
);
# 14data
#7.查询工资最低的员工信息: last_name, salary
SELECT last_name, salary
FROM employees
WHERE salary = (
SELECT MIN(salary)
FROM employees
);
# 1
#8.查询平均工资最低的部门信息
## 第1步:先找出每一个部门对应的平均工资,将查出的结果作为新表
SELECT department_id,AVG(salary)
FROM employees
GROUP BY department_id
## 第2步:找出平均工资里面最小的
SELECT MIN(avg_salary)
FROM (
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
) avg_salary_table
## 第3步:查出最低平均工资所对应的department_id
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_salary)
FROM (
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
) avg_salary_table
)
# 第4步:根据查到的department_id,找出对应的部门信息
# 方式1:
SELECT *
FROM departments
WHERE department_id = (
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_salary)
FROM (
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
) avg_salary_table
)
);
# 方式2:使用ALL关键字,平均工资小于等于平均工资,那么该平均工资一定是最小的平均工资
SELECT *
FROM departments
WHERE department_id = (
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL(
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
)
);
# 方式3:使用order by进行排序,使用limit选出第一行数据就是最小的平均工资
SELECT *
FROM departments
WHERE department_id = (
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
ORDER BY avg_salary ASC
LIMIT 1 OFFSET 0
)
);
# 方式4:多表连接
## 第1步:查询出平均工资以及所对应的department_id
SELECT department_id,AVG(salary) avg_salary
FROM employees
GROUP BY department_id
ORDER BY avg_salary
LIMIT 1 OFFSET 0
## 第2步:将上述查询结果作为新表连接departments表,查询对应的部门信息
SELECT d.*
FROM departments d JOIN (
SELECT department_id,AVG(salary) avg_salary
FROM employees
GROUP BY department_id
ORDER BY avg_salary ASC
LIMIT 1 OFFSET 0
) avg_salary_t
ON d.`department_id` = avg_salary_t.`department_id`;
#9.查询平均工资最低的部门信息和该部门的平均工资(相关子查询)
##方式1:借用第8题的方式4
SELECT d.*, avg_salary_t.avg_salary "对应部门的平均工资"
FROM departments d JOIN (
SELECT department_id,AVG(salary) avg_salary
FROM employees
GROUP BY department_id
ORDER BY avg_salary ASC
LIMIT 1 OFFSET 0
) avg_salary_t
ON d.`department_id` = avg_salary_t.`department_id`;
## 方式2:借用第8题的方式1,在SELECT语句里面写子查询
SELECT d.*,(SELECT AVG(salary) FROM employees WHERE department_id = d.`department_id`) avg_salary
FROM departments d
WHERE department_id = (
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_salary)
FROM (
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
) avg_salary_table
)
);
#10.查询平均工资最高的 job 信息
## 方式1:自己做
### 第1步:先查询平均工资最高
SELECT job_id,AVG(salary) avg_salary
FROM employees
GROUP BY job_id
ORDER BY avg_salary DESC
LIMIT 1 OFFSET 0
### 第2步:将上述查询结果作为新表,联结jobs表,从而得到查询结果
SELECT j.*
FROM jobs j JOIN (
SELECT job_id,AVG(salary) avg_salary
FROM employees
GROUP BY job_id
ORDER BY avg_salary DESC
LIMIT 1 OFFSET 0
) avg_salary_t
ON j.`job_id` = avg_salary_t.`job_id`
#11.查询平均工资高于公司平均工资的部门有哪些?
## 1.查询每一个部门的平均工资
SELECT department_id,AVG(salary) avg_salary_p
FROM employees
GROUP BY department_id
HAVING department_id IS NOT NULL
## 2.查询公司的平均工资
SELECT AVG(salary)
FROM employees
## 3.查找到对应部门的id
# 方式1:自己实现
SELECT department_id
FROM (
SELECT department_id,AVG(salary) avg_salary_p
FROM employees
GROUP BY department_id
HAVING department_id IS NOT NULL
) avg_salary_p_t
WHERE avg_salary_p_t.avg_salary_p > (
SELECT AVG(salary)
FROM employees
);
# 方式2:老师的方式
SELECT department_id
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
HAVING AVG(salary) > (
SELECT AVG(salary)
FROM employees
);
#12.查询出公司中所有 manager 的详细信息
SELECT e1.*
FROM employees e1
WHERE e1.`employee_id` IN (
SELECT manager_id
FROM employees e2
);
# 老师的方式:通常使用in的地方可以使用EXISTS代替
SELECT e1.*
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e1.`employee_id` = e2.`manager_id`
);
#13.各个部门中 最高工资中最低的 那个部门的 最低工资是多少?
## 1.每一个部门的最高工资,部门id,升序排列-->确定(最高工资中最低的 那个部门)
SELECT department_id,MAX(salary) max_salary
FROM employees
GROUP BY department_id
ORDER BY max_salary
LIMIT 1 OFFSET 0
## 2.查找出对应的department_id
SELECT department_id
FROM (
SELECT department_id,MAX(salary) max_salary
FROM employees
GROUP BY department_id
ORDER BY max_salary
LIMIT 1 OFFSET 0
) max_salary_t
## 3.根据查找出的部门id,找出该部门的最低工资
SELECT MIN(salary)
FROM employees
GROUP BY department_id
HAVING department_id = (
SELECT department_id
FROM (
SELECT department_id,MAX(salary) max_salary
FROM employees
GROUP BY department_id
ORDER BY max_salary
LIMIT 1 OFFSET 0
) max_salary_t
);
#14.查询平均工资最高的部门的 manager 的详细信息: last_name,
#department_id, email, salary
## 1.查询每个部门的平均工资,降序排列,选出最高平均工资以及对应的部门id改行数据
SELECT department_id, AVG(salary) avg_salary
FROM employees
GROUP BY department_id
ORDER BY avg_salary DESC
LIMIT 1 OFFSET 0
## 2.找出对应的department_id
SELECT avg_salary_t.`department_id`
FROM (
SELECT department_id, AVG(salary) avg_salary
FROM employees
GROUP BY department_id
ORDER BY avg_salary DESC
LIMIT 1 OFFSET 0
) avg_salary_t
## 3.根据部门id找出manager_id
SELECT DISTINCT manager_id
FROM employees
WHERE department_id = (
SELECT avg_salary_t.`department_id`
FROM (
SELECT department_id, AVG(salary) avg_salary
FROM employees
GROUP BY department_id
ORDER BY avg_salary DESC
LIMIT 1 OFFSET 0
) avg_salary_t
)
AND manager_id IS NOT NULL;
## 3.根据找出的manager_id找到所求信息
SELECT last_name, department_id, email, salary
FROM employees
WHERE manager_id IN (
SELECT DISTINCT manager_id
FROM employees
WHERE department_id = (
SELECT avg_salary_t.`department_id`
FROM (
SELECT department_id, AVG(salary) avg_salary
FROM employees
GROUP BY department_id
ORDER BY avg_salary DESC
LIMIT 1 OFFSET 0
) avg_salary_t
)
AND manager_id IS NOT NULL
);
#15. 查询部门的部门号,其中不包括job_id是"ST_CLERK"的部门号
SELECT DISTINCT d.department_id
FROM departments d
WHERE department_id NOT IN (
SELECT department_id
FROM employees
WHERE job_id = 'ST_CLERK'
);
# 改写为EXISTS
SELECT DISTINCT d.department_id
FROM departments d
WHERE NOT EXISTS(
SELECT department_id
FROM employees e
WHERE job_id = 'ST_CLERK'
AND d.`department_id` = e.`department_id`
);
#16. 选择所有没有管理者的员工的last_name
SELECT last_name
FROM employees e
WHERE e.`manager_id` IS NULL;
## 老师方式参考:
SELECT last_name
FROM employees emp
WHERE NOT EXISTS (
SELECT *
FROM employees mgr
WHERE emp.`manager_id` = mgr.`employee_id`
);
#17.查询员工号、姓名、雇用时间、工资,其中员工的管理者为 'De Haan'
SELECT e.*
FROM employees e
WHERE e.`manager_id` IN (
SELECT employee_id
FROM employees e2
WHERE e2.`last_name` = 'De Haan'
);
# 方式2:
SELECT employee_id,last_name,hire_date,salary
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e1.`manager_id` = e2.`employee_id`
AND e2.last_name = 'De Haan'
);
#18.查询各部门中工资比本部门平均工资高的员工的员工号, 姓名和工资(相关子查询)
SELECT employee_id,last_name,salary
FROM employees e
WHERE salary > (
SELECT AVG(salary)
FROM employees e2
GROUP BY department_id
HAVING e.`department_id` = e2.`department_id`
);
#19.查询每个部门下的部门人数大于 5 的部门名称(相关子查询)--不会
SELECT department_name
FROM departments d1
WHERE 5 < (
SELECT COUNT(*)
FROM employees e1
WHERE d1.`department_id` = e1.`department_id`
);
/*
思路:外面送进来一条departments数据,然后根据d1.`department_id` = e1.`department_id`
进行相关子查询过滤数据,剩下相同的部门的数据,然后统计部门数即可
*/
#20.查询每个国家下的部门个数大于 2 的国家编号(相关子查询)--不会
SELECT country_id
FROM locations l
WHERE 2 < (
SELECT COUNT(*)
FROM departments d
WHERE d.`location_id` = l.`location_id`
);
总结:
/*
总结:
①写in的位置通常可以该写为EXISTS
子查询的编写技巧:①从里往外写 ②从外往里写
如何选择?
① 如果子查询相对简单,建议从外往里写。一旦子查询结构较复杂,则建议从里往外写
② 如果是相关子查询的话,通常都是从外往里写
*/
第10章 创建和管理表
10-1 创建和管理数据库
# 第10章 创建和管理表
## 10-1 创建和管理数据库
# 注意:创建和管理数据库也是需要权限的,此时时root权限
### 1.1 创建数据库
## 方式1:
CREATE DATABASE mydb1;
SHOW DATABASES;
## 以下两条命令可以查看mysql8.0数据库默认的字符集是--utf8mb4
SHOW CREATE DATABASE mydb1;
SHOW VARIABLES LIKE 'character_%';
## 方式2:显示指明创建数据库时要使用的字符集
CREATE DATABASE mydb2 CHARACTER SET 'gbk';
## 方式3:
CREATE DATABASE IF NOT EXISTS mydb3 CHARACTER SET 'utf8';
### 1.2 管理数据库
# 查看当前连接中的数据库有那些
SHOW DATABASES;
# 切换数据库
USE mydb1;
# 查看当前数据库中保存的数据表
SHOW TABLES;
# 查看当前使用的数据库
SELECT DATABASE() FROM DUAL;
# 查看指定数据库下保存的数据表
SHOW TABLES FROM mysql;
### 1.3 修改数据库
# 更改数据库字符集
SHOW CREATE DATABASE mydb2;
ALTER DATABASE mydb2 CHARACTER SET 'utf8';
### 1.4 删除数据库
# 推荐方式
DROP DATABASE IF EXISTS mydb3;
10-2 创建数据库表
## 10-2 创建数据库表
USE atguigudb;
SHOW CREATE DATABASE atguigudb;
# 创建表方式1:
CREATE TABLE IF NOT EXISTS myemp2( # 需要用户创建表的权限
id INT,
emp_name VARCHAR(15), # 表示15个字符长度
hire_date DATE
);
## 查看表结构
DESC myemp2;
## 查看创建表的语句结构
SHOW CREATE TABLE myemp2; # 创建表时没有指明使用的字符集,则默认使用所在数据库的字符集
# 创建方式2:基于现有的employees表创建新表myemp3,数据和字段保持一致
CREATE TABLE myemp3
AS
SELECT employee_id,last_name,salary
FROM employees;
##查看myemp2表结构
DESC myemp3;
# 练习:创建一个表employees_blank,实现对employees表的复制,不包括表数据
CREATE TABLE employees_blank
AS
SELECT *
FROM employees
WHERE 1 = 2;
/*
使用1永远不可能等于2的条件过滤数据,达到只复制表的字段,并不会复制数据值
*/
10-3 修改表--ALTER TABLE
# 10-3 修改表--ALTER TABLE
DESC myemp2;
## 3-1.添加一个字段
ALTER TABLE myemp2
ADD salary DOUBLE(10,2); # double数据类型总共10位,小数点占2位
# 使用FIRST关键字将phone_number字段添加到表的第一列
ALTER TABLE myemp2
ADD phone_number VARCHAR(20) FIRST;
# 使用AFTER关键字将e_mail添加到emp_name后面
ALTER TABLE myemp2
ADD e_mail VARCHAR(45) AFTER emp_name;
## 3-2.修改一个字段:数据类型,长度,默认值
ALTER TABLE myemp2
# 修改数据类型的长度,并赋给一个默认值
MODIFY emp_name VARCHAR(20) DEFAULT "zhang3";
## 3-3 重命名一个字段,也可以包含MODIFY操作
ALTER TABLE myemp2
CHANGE salary myemp2_salary DOUBLE(12,2)
## 3.4 删除一个字段
ALTER TABLE myemp2
DROP COLUMN myemp2_salary;
## 3.5 重命名表
RENAME TABLE myemp2
TO myemp2_1;
DESC myemp2_1;
## 3.6 删除表 如果没有日志文件或备份,删除库表之后只能跑路
# 补充:表的结构,数据都删除了,并且释放了表的空间
DROP TABLE IF EXISTS myemp2_1;
#3.7清空表中的数据,但是表的结构保留
TRUNCATE TABLE myemp3;
SELECT * FROM myemp3;
DESC myemp3;
10-4 删除表
DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
注意:DROP TABLE 语句不能回滚
10-5 DCL中commit与rollback使用

验证使用DELETE关键字删除数据是可以回滚的:
#### 验证使用DELETE关键字删除数据是可以回滚的
# 1.在此之前的数据都提交
COMMIT;
# 2.创建一张从employees复制了employee_id,last_name,salary数据的表
CREATE TABLE myemp4
AS
SELECT employee_id,last_name,salary
FROM employees
# 3.查看myemp3的表数据
SELECT *
FROM myemp4;
# 4.设置自动提交为false
SET autocommit = FALSE;
# 5.删除表中的数据
DELETE FROM myemp4;
# 6.数据回滚,然后看表中数据是否恢复,实验证明已经回滚
ROLLBACK;
#### 验证使用关键字TRUNCATE删除数据是不可以回滚的
# 1.在employee_id,last_name,salary
FROM employees
# 3.查看myemp3的表数据
SELECT *
FROM myemp4;
# 4.设置自动提交为false
SET autocommit = FALSE;
# 5.删除表中的数据
TRUNCATE TABLE myemp4;
# 6.数据回滚,然后看表中数据是否恢复,数据没有恢复
ROLLBACK;
10-6 阿里MySQL命名规范以及MySQL8DDL的原子化
测试MySQL8.0D新特性:DDL的原子化:
#10-5 测试MySQL8.0D新特性:DDL的原子化
CREATE DATABASE mytest;
USE mytest;
CREATE TABLE book1(
book_id INT,
book_name VARCHAR(255)
);
SHOW TABLES;
# book2表不存在,此时DROP TABLE book1,book2;该操作语句作为一个事务具有原子性,
# book2没有删除成功,删除book1此时也会无法删除成功
/*
解释:事务原子性只限于mysql8.0,如果放在mysql5.0中,虽然以下语句删除book2不成功
但是还是会成功删除book1;在mysql8.0中,该语句本来删除了book1,但是在删除book2的时候,
发现没有book2,所以以下语句作为一个事务,具有原子性,会对刚刚删除的book1表的操作进行
回滚,从而book1没有删除。
*/
DROP TABLE book1,book2;
SHOW TABLES;
第11章 数据处理之增删改
11-1 添加数据
# 第11章 数据处理之增删改
## 0.准备工作
USE atguigudb;
CREATE TABLE IF NOT EXISTS emp1(
id INT,
`name` VARCHAR(15),
hire_date DATE,
salary DOUBLE(10,2)
);
DESC emp1;
SELECT *
FROM emp1;
## 1.添加数据
# 方式1:一条一条添加数据
## ①:没有指明添加的字段
INSERT INTO emp1
VALUES(1,'Tom','2000-12-21',3400); # 注意,该方式一定要按照字段声明的先后顺序添加
## ②指明要添加的字段(推荐)
INSERT INTO emp1(salary,hire_date,`name`,id)
VALUES
(8000,'2021-09-09','liuting',2),
(8000,'2022-08-01','zhudanni',3);
#方式2:架构查询的结果插入到表中
SELECT * FROM emp1;
INSERT INTO emp1(id,`name`,salary,hire_date)
# 查询语句
SELECT employee_id,last_name,salary,hire_date
FROM employees
WHERE department_id IN (70);
DESC emp1;
DESC employees;
/*
说明:
emp1表中要添加的数据的字段的长度不能低于employees表中查询的字段的长度。
如果emp1表中要添加的数据的字段的长度低于employees表中查询的字段的长度。
就有添加不成功的风险。
*/
11-2 更新数据:UPDATE tableName SET...WHERE
# 2.更新数据:UPDATE tableName SET...WHERE
SELECT * FROM emp1;
## 可以实现批量修改数据(不加限制条件),以及同事修改一条数据的多个字段
### 注意:更新表数据时,可能由于约束的影响导致更新失败
UPDATE emp1
SET hire_date = CURDATE(),salary = 20000
WHERE id = 1;
11-3 删除数据 DELEte from tableName where...
# 3. 删除数据 DELEte from tableName where...
SELECT * FROM emp1;
## 删除表数据时,可能由于约束的影响导致删除失败
DELETE FROM emp1
WHERE id = 204;
/*
说明:
DML操作(以上操作)默认情况下,执行完以后都会自动提交数据。
如果希望执行完以后不自动提交数据,则需要使用SET AUTOCOMMIT = FALSE
*/
11-4 MySQL8的新特性:计算列
# 4.MySQL8的新特性:计算列
USE atguigudb;
## 创建一个指定为计算列的表
CREATE TABLE test1(
a INT,
b INT,
# 设置字段c为计算列
c INT GENERATED ALWAYS AS (A + B) VIRTUAL
);
## 插入数据,即使没有对计算列字段添加数据,也会自动进行计算,然后添加数据
INSERT INTO test1(a,b)
VALUES(10,20);
SELECT * FROM test1;
/*
结果:
a b c
------ ------ --------
10 20 30
*/
UPDATE test1
SET a = 1000;
SELECT * FROM test1;
/*
结果:
a b c
------ ------ --------
1000 20 1020
*/
第12章 mysql数据类型精讲
12-1 关于字符集的说明

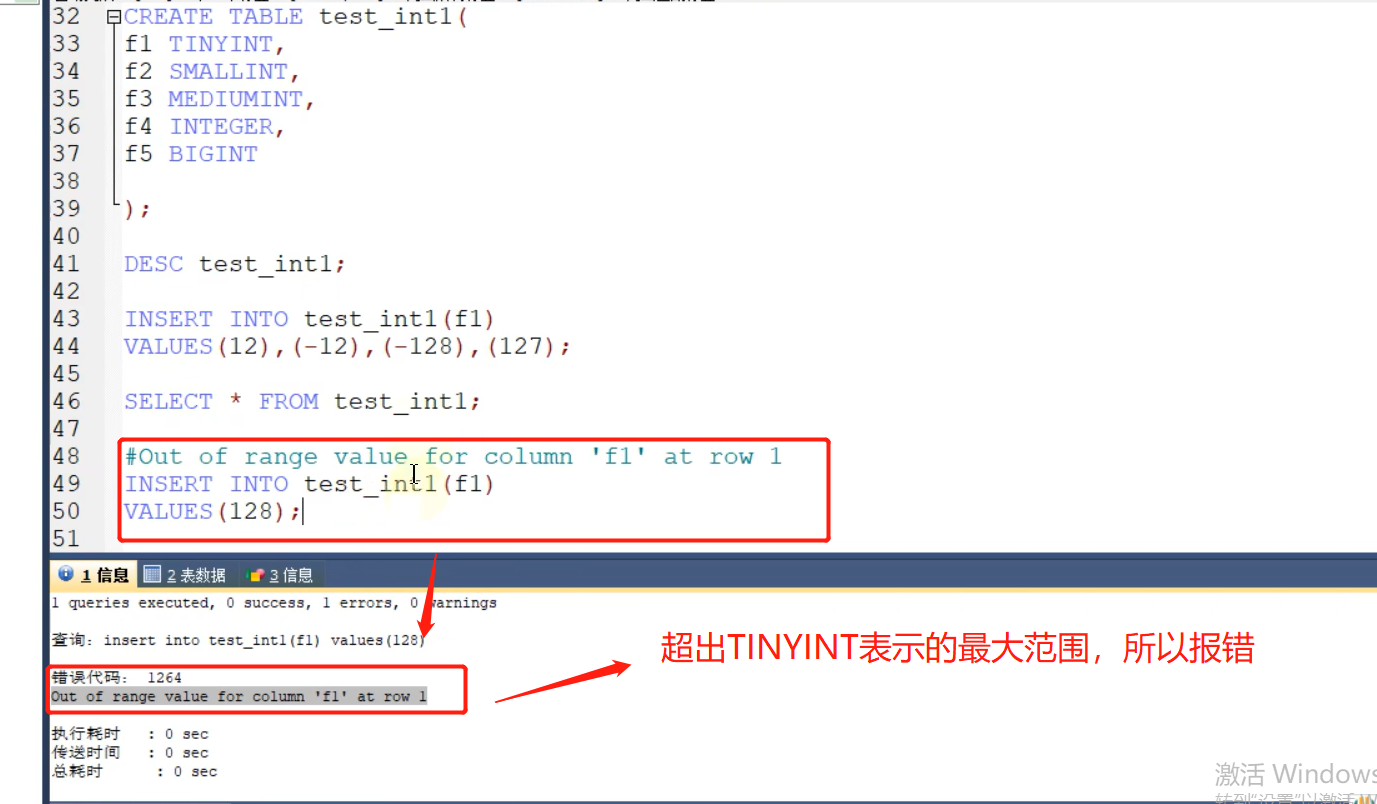
12-2 整型数据类型讲解
第13章 约束
/*
1. 基础知识
1.1 为什么需要约束? 为了保证数据的完整性!
1.2 什么叫约束?对表中字段的限制。
1.3 约束的分类:
角度1:约束的字段的个数
单列约束 vs 多列约束
角度2:约束的作用范围
列级约束:将此约束声明在对应字段的后面
表级约束:在表中所有字段都声明完,在所有字段的后面声明的约束
补充:列级约束将约束声明在一个字段的后面;表级约束,将约束声明在多个字段的后面
角度3:约束的作用(或功能)
① not null (非空约束)
② unique (唯一性约束)
③ primary key (主键约束)
④ foreign key (外键约束)
⑤ check (检查约束)
⑥ default (默认值约束)
1.4 如何添加/删除约束?
CREATE TABLE时添加约束
ALTER TABLE 时增加约束、删除约束
*/
查看某一个表已有的约束:
#information_schema数据库名(系统库)
#table_constraints表名称(专门存储各个表的约束)
SELECT * FROM information_schema.table_constraints
WHERE table_name = '表名称';
13-1 非空约束
#3. not null (非空约束)
#3.1 在CREATE TABLE时添加约束
USE dbtest2;
CREATE TABLE test1(
id INT NOT NULL,
last_name VARCHAR(15) NOT NULL,
email VARCHAR(25),
salary DECIMAL(10,2)
);
#3.2 在ALTER TABLE时添加约束
SELECT * FROM test1;
DESC test1;
ALTER TABLE test1
MODIFY email VARCHAR(25) NOT NULL;
#3.3 在ALTER TABLE时删除约束,只需要去掉NOT即可
ALTER TABLE test1
MODIFY email VARCHAR(25) NULL;
补充:
1.插入数据时,检查默认值优先于检查非空约束
13-2 唯一性约束
#4. unique (唯一性约束)
#4.1 在CREATE TABLE时添加约束
## 在创建唯一约束的时候,如果不给唯一约束命名,就默认和列名相同。
CREATE TABLE test2(
id INT UNIQUE, #列级约束
last_name VARCHAR(15) ,
email VARCHAR(25),
salary DECIMAL(10,2),
#表级约束,为被UNIQUE约束的字段起一个唯一的约束名,方便以后删除
CONSTRAINT uk_test2_email UNIQUE(email)
);
DESC test2;
# 4.2 可以向声明为unique的字段上添加null值。而且可以多次添加null
INSERT INTO test2(id,last_name,email,salary)
VALUES(2,'Tom1',NULL,4600);
INSERT INTO test2(id,last_name,email,salary)
VALUES(3,'Tom2',NULL,4600);
SELECT * FROM test2;
# 4.3 在ALTER TABLE时添加约束
DESC test2;
UPDATE test2
SET salary = 5000
WHERE id = 3;
#方式1:
ALTER TABLE test2
ADD CONSTRAINT uk_test2_sal UNIQUE(salary);
#方式2:
ALTER TABLE test2
MODIFY last_name VARCHAR(15) UNIQUE;
# 4.4 复合的唯一性约束
DROP TABLE `user`;
USE dbtest2;
CREATE TABLE `user`(
id INT,
`name` VARCHAR(15),
`password` VARCHAR(25),
# 表级约束
CONSTRAINT uk_user_name_pwd UNIQUE(`name`,`password`)
);
SELECT *
FROM `user`;
INSERT INTO USER
VALUES(1,'Tom','abc');
# 可以成功
INSERT INTO USER
VALUES(1,'Tom','abcf');
/*
虽然以上两条数据的name相同,但是只要name,password复合的整体不同,就不会导致插入不成功
*/
# 4-5.删除索引
USE dbtest2;
## 1 没有指定名称的单个约束,默认约束名是字段名
CREATE TABLE t1(
id INT,
# 默认约束名为id
CONSTRAINT UNIQUE(id)
);
DESC t1;
## 2 没有指定名称的复合索引,默认约束名是复合字段的第一个字段名
USE dbtest2;
CREATE TABLE t2(
id INT,
`name` VARCHAR(10),
# 默认约束名为复合的第一个字段,也是id
CONSTRAINT UNIQUE(id,`name`)
);
DESC t2;
## 3 删除索引,根据约束名进行删除即可,没有指定约束名,根据上述两条删除约束名
ALTER TABLE t2
DROP INDEX id;
13-3 主键约束的使用
# 5.主键约束--primary key(非空(NOT NULL)且唯一(UNIQUE))
## 5-1 在create table时添加主键约束
# 一个表中最多只能有一个主键约束
USE mydb2;
CREATE TABLE test3(
# 列级约束
id INT PRIMARY KEY,
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25)
);
CREATE TABLE test4(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25),
## 表级约束:将某一个字段作为主键,没有必要为其起一个名字,虽然起了不会报错,但是最终使用的
## 主键名还是PRIMARY而不是你起的名字
-- constraint primary key(id) # 该中方式也可以
PRIMARY KEY(id)
);
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'test3';
## 5-2在ALTER TABLE时添加主键约束
CREATE TABLE test5(
# 列级约束
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25)
);
DESC test5;
### 修改表示添加主键约束
ALTER TABLE test5
ADD PRIMARY KEY(id);
## 5-3 删除主键约束(现实中根本不会删除主键)
ALTER TABLE test5
DROP PRIMARY KEY;
/*
构建表时,指定了主键,会根据主键构建B+树,然后根据B+树进行查询;
没有指定主键时,系统会默认优先选择一个非空等字段作为主键,然后构建B+树。
*/
13-4 自增长列

# 6.AUTO_INCREMENT--自增长列
/*
知识点:
1.一般将其添加到主键所在的列上,也可以添加到唯一键列上,但是一个表只能
有一个自增长列
*/
## 6.1 创建表时添加自增长列
CREATE TABLE test6(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` CHAR(20)
);
# 开发时的写法,一但主键字段声明的了自增长列,无需再为其赋值
INSERT INTO test6(`name`)
VALUES('xurong');
## 6.2修改表示添加自增长列
CREATE TABLE test7(
id INT PRIMARY KEY,
`name` CHAR(20)
);
ALTER TABLE test7
MODIFY id INT AUTO_INCREMENT;
INSERT INTO test7(`name`)
VALUES('liuting');
SELECT * FROM test7;
## 6.3 在ALTER TABLE时进行删除自增长列
ALTER TABLE test7
MODIFY id INT;
8.0新特性:


13-5 外键约束的使用

#7.foreign key(外键约束)
## 7.1 在创建CREATE TABLE时添加
## 主表和从表;父表和子表
### ①先创建主表
CREATE TABLE dept1(
dept_id INT PRIMARY KEY,
dept_name VARCHAR(15)
);
### ②再创建从表
CREATE TABLE emp1(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(15),
department_id INT,
CONSTRAINT fk_departmentId_deptId FOREIGN KEY(department_id) REFERENCES dept1(dept_id)
);
DESC dept1;
SELECT * FROM information_schema.table_constraints
WHERE table_name = 'emp1';
## 说明:必须是主表中的主键(dept_id)有部门id之后,在从表中方可根据存在的部门id
## 进行插入数据的操作;删除时必须先删除从表再删除主表,否则删除操作不会成功;如果
## 已经根据主表中存在的部门id(eg:60)在从表中插入了数据,想要更改主表中的部门id(eg
## id号从60变为40),也会导致报错,因为受外键约束影响
INSERT INTO dept1(dept_id,dept_name) VALUES(60,'apple');
INSERT INTO emp1(emp_name,department_id) VALUES('小红',60);
## 7.2 alter table时添加外键约束
CREATE TABLE dept2(
dept_id INT PRIMARY KEY,
dept_name VARCHAR(15)
);
CREATE TABLE emp2(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(15),
department_id INT
);
ALTER TABLE emp2
ADD CONSTRAINT fk_emp2_depart_id FOREIGN KEY(department_id) REFERENCES dept2(dept_id);
SELECT * FROM information_schema.`TABLE_CONSTRAINTS`
WHERE table_name = 'emp2';
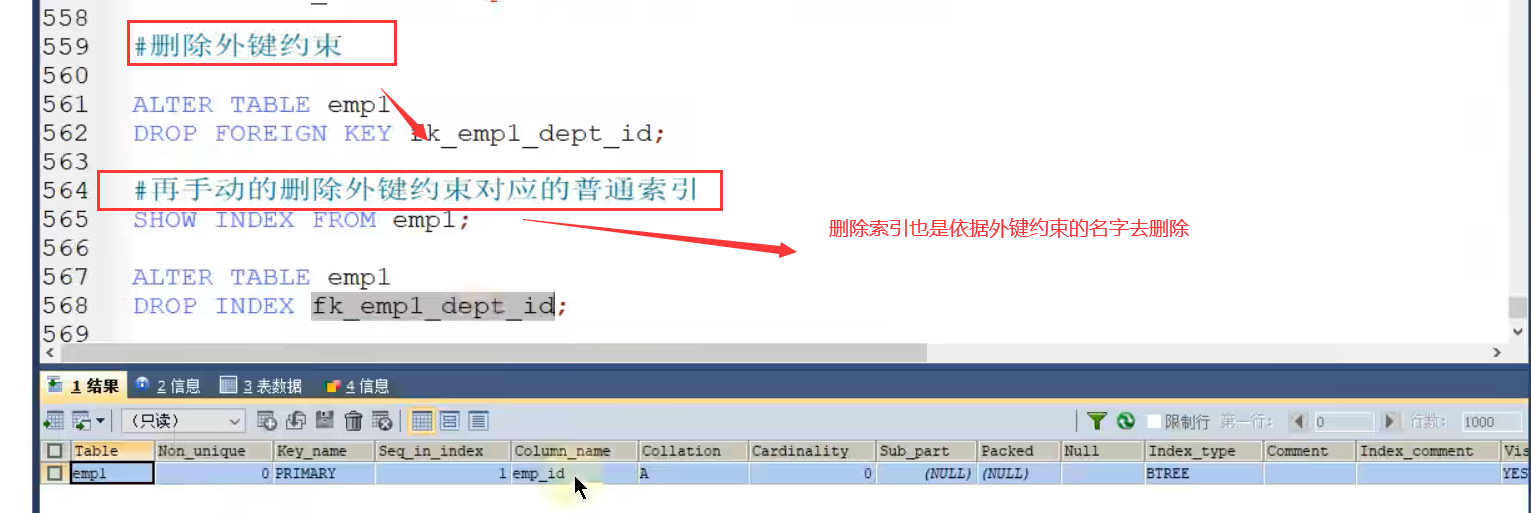
7.3 删除外键约束
开发实践:

13-6 check约束
#8.check约束:限定一个字段的数值的范围(mysql8.0,Oracle一直有此功能)
CREATE TABLE test10(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) CHECK(salary > 2000)
);
SELECT * FROM test10;
INSERT INTO test10 VALUES(1,'xurong',2500);
##报错:Check constraint 'test10_chk_1' is violated.
##原因:工资低于2000,无法进行数据的插入
INSERT INTO test10 VALUES(3,'xurong',1500);
13-7 DEFAULT 约束
# 9.DEFAULT约束
## 9.1 在CREATE TABLE添加约束
CREATE TABLE test11(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) DEFAULT 2000
);
DESC test11;
SELECT * FROM test11;
INSERT INTO test11(id,last_name,salary) VALUES (1,'Tom',3000);
INSERT INTO test11(id,last_name) VALUES (2,'Tom');
## 9.2 在ALTER TABLE时添加约束
CREATE TABLE test12(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2)
);
DESC test12;
SELECT * FROM test12;
ALTER TABLE test12
MODIFY salary DECIMAL(8,2) DEFAULT 3000
## 9.3 在ALTER TABLE时删除约束
ALTER TABLE test12
MODIFY salary DECIMAL(8,2)
13-8 面试
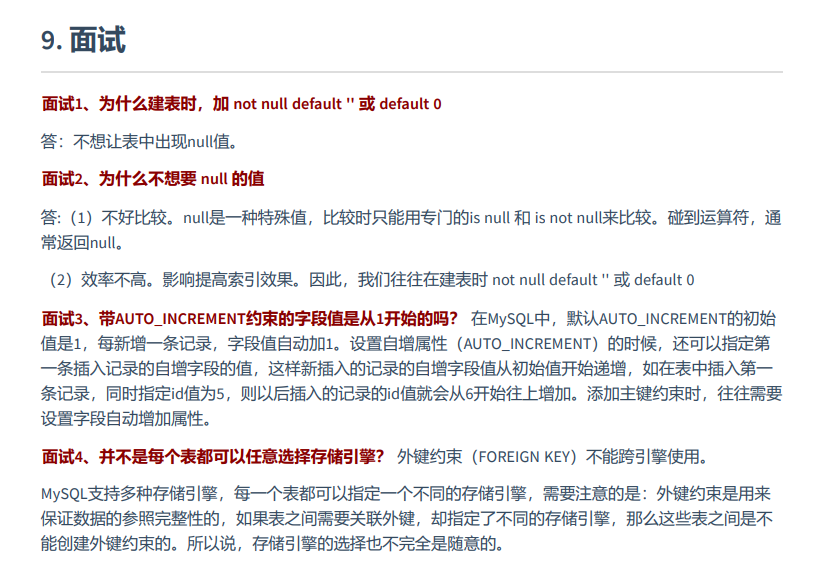
第14章 视图
# 第14章_视图(View)
/*
1. 视图的理解
① 视图,可以看做是一个虚拟表,本身是不存储数据的。
视图的本质,就可以看做是存储起来的SELECT语句
② 视图中SELECT语句中涉及到的表,称为基表
③ 针对视图做DML操作,会影响到对应的基表中的数据。反之亦然(本质还是对基表的操作)。
④ 视图本身的删除,不会导致基表中数据的删除(因为视图保存的是存储起来的select语句,删除视图就是将该语句删除)。
⑤ 视图的应用场景:针对于小型项目,不推荐使用视图。针对于大型项目,可以考虑使用视图。
⑥ 视图的优点:简化查询; 控制数据的访问
*/
CREATE DATABASE dbtest14;
USE dbtest14;
CREATE TABLE emps
AS
SELECT *
FROM atguigudb.`employees`;
CREATE TABLE depts
AS
SELECT *
FROM atguigudb.`departments`;
SELECT *
FROM emps;
DESC emps;
DESC atguigudb.`employees`;
SELECT *
FROM depts;
## 2.1 针对单表进行视图查询
# 确定视图中字段名的方式1:
CREATE VIEW vu_emp1
AS
SELECT employee_id emp1_id,last_name lname,salary # 对视图中的字段名进行重命名
FROM emps
WHERE salary > 8000;
SELECT * FROM vu_emp1;
# 确定视图中字段名的方式2:
CREATE VIEW vu_emp2(emp1_id,lname,month_salary) # 对视图中的字段名进行重命名
AS
SELECT employee_id,last_name,salary
FROM emps
WHERE salary > 10000;
SELECT * FROM vu_emp2;
# 对于使用了聚合函数的查询,由于是一个函数,需要起一个别名作为视图字段名
CREATE VIEW vu_avg_salary
AS
SELECT department_id dp_id, AVG(salary) avg_salary
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;
SELECT * FROM vu_avg_salary;
#2.2 针对于多表
CREATE VIEW vu_emp_dept
AS
SELECT e.employee_id,e.department_id,d.department_name
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
SELECT * FROM vu_emp_dept;
# 利用视图对数据进行格式化
CREATE VIEW vu_emp_dept1
AS
SELECT CONCAT(e.last_name,'(',d.department_name,')')
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
SELECT * FROM vu_emp_dept1;
#2.3 基于视图创建视图
CREATE VIEW vu_emp11
AS
SELECT emp1_id,lname # 如果基于的视图创建视图,原视图使用了别名,创建新视图时,也应该使用别名
FROM vu_emp1;
SELECT * FROM vu_emp11;
# 3. 查看视图
# 语法1:查看数据库的表对象、视图对象
SHOW TABLES;
#语法2:查看视图的结构
DESCRIBE vu_emp1;
#语法3:查看视图的属性信息
SHOW TABLE STATUS LIKE 'vu_emp1';
#语法4:查看视图的详细定义信息
SHOW CREATE VIEW vu_emp1;
# 4.更新视图中的数据
SELECT * FROM vu_emp1;
SELECT employee_id,last_name,salary
FROM emps;
### 4-1
# 跟新视图的数据,会导致基表中数据的修改(底层就只有一张基表)
## 102 De Haan 17000.00
UPDATE vu_emp1
SET salary = 20
WHERE emp1_id = 102;
# 同理,跟新基表中的数据,也会导致视图中数据的修改
## 101 Kochhar 17000.00
UPDATE emps
SET salary = 20240
WHERE employee_id = 101;
#删除视图中的数据,也会导致表中的数据的删除(一样的道理)
DELETE FROM vu_emp1
WHERE employee_id = 101;
SELECT employee_id,last_name,salary
FROM emps
WHERE employee_id = 101;
### 4-2 如果视图中的属性字段和基表中的属性字段不是一一对应的,视图更新可能会失败
SELECT * FROM vu_avg_salary;
# 跟新失败(The target table vu_avg_salary of the UPDATE is not updatable)
UPDATE vu_avg_salary
SET avg_salary = 5000
WHERE dp_id = 90;
# 删除失败(The target table vu_avg_salary of the DELETE is not updatable)
DELETE FROM vu_avg_salary
WHERE dp_id = 90;
####:
##总结:视图封装了关于sql的查询语句,主要用于查询的
# 5.修改视图
DESC vu_emp1;
# 方式1:添加字段(会覆盖原视图)
CREATE OR REPLACE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email
FROM emps
WHERE salary > 7000;
# 方式2:添加字段(会覆盖原视图)
ALTER VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email,hire_date
FROM emps;
# 6.删除视图
SHOW TABLES;
DROP VIEW vu_vag_salary1;
第15章 存储过程与存储函数
#第15章_存储过程与存储函数
#0.准备工作
CREATE DATABASE dbtest15;
USE dbtest15;
CREATE TABLE employees
AS
SELECT *
FROM atguigudb.`employees`;
CREATE TABLE departments
AS
SELECT * FROM atguigudb.`departments`;
SELECT * FROM employees;
SELECT * FROM departments;
# 1. 创建存储过程
#类型1:无参数无返回值
#举例1:创建存储过程select_all_data(),查看 employees 表的所有数据
## DELIMITER $--》表明该存储过程是使用$分隔符作为开始和结束(默认是分号,但是sql语句中可能分号导致歧义)
## DELIMITER ;--》恢复分号作为结束符(因为整个sql语句默认是使用分号作为结束符,恢复原状)
DELIMITER $
CREATE PROCEDURE select_all_datas()
BEGIN
SELECT * FROM employees;
END $
DELIMITER ;
# 2.存储过程的调用
CALL select_all_datas();
#类型2:带 OUT
#举例4:创建存储过程show_min_salary(),查看“emps”表的最低薪资值。并将最低薪资
#通过OUT参数“ms”输出
DESC employees;
DELIMITER //
CREATE PROCEDURE show_min_salary(OUT ms DOUBLE)
BEGIN
SELECT MIN(salary) INTO ms
FROM employees;
END //
DELIMITER ;
## 调用
CALL show_min_salary(@ms);
## 查看调用结果
SELECT @ms;
#类型3:带 IN
#举例5:创建存储过程show_someone_salary(),查看“emps”表的某个员工的薪资,
#并用IN参数empname输入员工姓名。
DELIMITER //
CREATE PROCEDURE show_someone_salary(IN empname VARCHAR(20))
BEGIN
SELECT salary
FROM employees
WHERE last_name = empname;
END //
DELIMITER ;
## 调用方式1:
CALL show_someone_salary('Abel');
## 调用方式2:
SET @empname := 'Abel';
CALL show_someone_salary(@empname);
#类型4:带 IN 和 OUT
#举例6:创建存储过程show_someone_salary2(),查看“emps”表的某个员工的薪资,
#并用IN参数empname输入员工姓名,用OUT参数empsalary输出员工薪资。
DELIMITER //
CREATE PROCEDURE show_someone_salary11(IN empname VARCHAR(20), OUT empsalary DOUBLE)
BEGIN
SELECT salary INTO empsalary
FROM employees
WHERE last_name = empname;
END //
DELIMITER ;
# 调用:
SET @empname := 'Abel';
CALL show_someone_salary11(@empname,@empsalary);
# 查看调用结果
SELECT @empsalary;
#类型5:带 INOUT
#举例7:创建存储过程show_mgr_name(),查询某个员工领导的姓名,并用INOUT参数“empname”输入员工姓名,
#输出领导的姓名。
DESC employees;
DELIMITER //
CREATE PROCEDURE show_mgr_name1(INOUT empname VARCHAR(25))
BEGIN
SELECT last_name INTO empname
FROM employees
WHERE employee_id = (
SELECT manager_id
FROM employees
WHERE last_name = empname
);
END //
DELIMITER ;
## 调用
SET @empname := 'Abel';
CALL show_mgr_name1(@empname);
## 查看结果
SELECT @empname
补充:
1.声明Linux上的mysql为远程对象:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.1.103' IDENTIFIED BY 'root' WITH GRANT OPTION;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号