Hackbuteer1的专栏Stay Hungry,Stay Foolish!
2012-05-09 14:09 Rollen Holt 阅读(2281) 评论(0) 收藏 举报转自:http://blog.csdn.net/Hackbuteer1/rss/list
| [原]九度互动社区IT名企招聘上机考试热身赛 | ||||
|
http://ac.jobdu.com/problem.php?id=1326 Waiting in Line
//简单模拟题
#include<iostream>
#include<cstdio>
using namespace std;
#include<memory.h>
int pt[1001],leave[1001],start[21];
int n,m,k,q;
inline bool scan_d(int &num) // 这个就是 加速的 关键了
{
char in;bool IsN=false;
in=getchar();
if(in==EOF)
return false;
while(in!='-'&&(in<'0'||in>'9')) in=getchar();
if(in=='-') { IsN=true;num=0;}
else num=in-'0';
while(in=getchar(),in>='0'&&in<='9')
{
num*=10,num+=in-'0';
}
if(IsN)
num=-num;
return true;
}
void solve()
{
int i,j,index,t,p,count=k;
int num[21],window[21][13];
memset(start,0,sizeof(start));
memset(num,0,sizeof(num));
j = index = 1;
for(i = 1 ; i <= n*m && i <= k ; ++i) //刚开始时,n个窗口都是空的,客户依次选择队伍最短的窗口
{
window[j][index] = i;
num[j]++;
j++;
if(j>n)
{
j = 1;
++index;
}
}
j = i; //刚开始的n个窗口已经都排满了客户
t = 0;
while(t <= 540)
{
++t;
for(i = 1 ; i <= n ; ++i)
{
if(num[i] > 0 && pt[ window[i][1] ] == t - start[i])
{
leave[ window[i][1] ] = t;
start[i] = t;
--count; //一个用户离开
for(p = 2 ; p <= num[i] ; ++p)
window[i][p-1] = window[i][p]; //每个窗口的第一个用户离开后,后面的客户依次往前移动
--num[i];
if(j <= k) //还有等待的客户的时候,往窗口中再增加一个
{
window[i][p-1] = j;
++num[i];
++j;
}
}//if
}//for
if(!count) //所有客户都处理完的时候,直接退出
break;
}
}
int main(void)
{
int i,j;
while(scanf("%d %d %d %d",&n,&m,&k,&q)!=EOF)
{
memset(leave,1,sizeof(leave));
for(i = 1 ; i <= k ; ++i)
scan_d(pt[i]);
solve();
for(i = 0 ; i < q ; ++i)
{
scan_d(j);
if(leave[j] > 540)
puts("Sorry");
else
printf("%02d:%02d\n",leave[j]/60+8,leave[j]%60);
}
}
return 0;
}
作者:Hackbuteer1 发表于2012-4-2 15:10:11 原文链接
阅读:227 评论:0 查看评论
|
||||
| [原]单调队列 | ||||
|
一、 什么是单调(双端)队列 单调队列:单调队列 即保持队列中的元素单调递增(或递减)的这样一个队列,可以从两头删除,只能从队尾插入。单调队列的具体作用在于,由于保持队列中的元素满足单调性,对手元素便是极小值(极大值)了。 http://poj.org/problem?id=2823
//poj-2823--单调队列
#include<iostream>
#include<cstdio>
using namespace std;
const int MAX = 1000001;
//两个单调队列
int dq1[MAX]; //一个存单调递增
int dq2[MAX]; //一个存单调递减
int a[MAX];
inline bool scan_d(int &num) // 这个就是 加速的 关键了
{
char in;bool IsN=false;
in=getchar();
if(in==EOF)
return false;
while(in!='-'&&(in<'0'||in>'9')) in=getchar();
if(in=='-') { IsN=true;num=0;}
else num=in-'0';
while(in=getchar(),in>='0'&&in<='9')
{
num*=10,num+=in-'0';
}
if(IsN)
num=-num;
return true;
}
int main(void)
{
int i,n,k,front1,front2,tail1,tail2,start,ans;
while(scanf("%d %d",&n,&k)!=EOF)
{
for(i = 0 ; i < n ; ++i)
scan_d(a[i]);
front1 = 0, tail1 = -1;
front2 = 0, tail2 = -1;
ans = start = 0;
for(i = 0 ; i < k ; ++i)
{
while(front1 <= tail1 && a[ dq1[tail1] ] <= a[i]) //当前元素大于单调递增队列的队尾元素的时候,队尾的元素依次弹出队列,直到队尾元素大于当前当前元素的时候,将当前元素插入队尾
--tail1;
dq1[ ++tail1 ] = i; //只需要记录下标即可
while(front2 <= tail2 && a[ dq2[tail2] ] >= a[i]) //当前元素小于单调递减队列的队尾元素的时候,队尾的元素依次弹出队列,直到队尾元素小于当前当前元素的时候,将当前元素插入队尾
--tail2;
dq2[ ++tail2 ] = i; //只需要记录下标即可
}
printf("%d ",a[ dq2[ front2 ] ]);
for( ; i < n ; ++i)
{
while(front2 <= tail2 && a[ dq2[tail2] ] >= a[i])
--tail2;
dq2[ ++tail2 ] = i;
while(dq2[ front2 ] <= i - k)
++front2;
if(i != n-1)
printf("%d ",a[ dq2[ front2 ] ]);
}
printf("%d\n",a[ dq2[ front2 ] ]);
//输出最大值
printf("%d ",a[ dq1[ front1 ] ]);
for(i=k ; i < n ; ++i)
{
while(front1 <= tail1 && a[ dq1[tail1] ] <= a[i])
--tail1;
dq1[ ++tail1 ] = i;
while(dq1[ front1 ] <= i - k)
++front1;
if(i != n-1)
printf("%d ",a[ dq1[ front1 ] ]);
}
printf("%d\n",a[ dq1[ front1 ] ]);
}
return 0;
}
http://acm.hdu.edu.cn/showproblem.php?pid=3530 Subsequence
/*
题意:给出一个序列,求最长的连续子序列,使得 M<=Max-Min<=K
n <= 10^5
依次枚举剩下的N-1个元素,并且将当前未入队的第一个元素和队尾元素比较,当且仅当队列为非空并且队尾元素的值小于当前未入队的元素时,
将队尾元素删除(也就是队尾指针-1),因为当前的元素比队尾元素大,所以在区间内队尾元素不会是最大值了。
重复这个过程直到队列空或者队尾元素比当前元素大,
*/
#include<iostream>
#include<cstdio>
using namespace std;
const int MAX = 100001;
//两个单调队列
int dq1[MAX]; //一个存单调递增
int dq2[MAX]; //一个存单调递减
int a[MAX];
inline bool scan_d(int &num) // 这个就是 加速的 关键了
{
char in;bool IsN=false;
in=getchar();
if(in==EOF)
return false;
while(in!='-'&&(in<'0'||in>'9')) in=getchar();
if(in=='-') { IsN=true;num=0;}
else num=in-'0';
while(in=getchar(),in>='0'&&in<='9')
{
num*=10,num+=in-'0';
}
if(IsN)
num=-num;
return true;
}
int main(void)
{
int i,n,m,k,front1,front2,tail1,tail2,start,ans;
while(scanf("%d %d %d",&n,&m,&k) != EOF)
{
for(i = 0 ; i < n ; ++i)
scan_d(a[i]);
front1 = 0, tail1 = -1;
front2 = 0, tail2 = -1;
ans = start = 0;
for(i = 0 ; i < n ; ++i)
{
while(front1 <= tail1 && a[ dq1[tail1] ] <= a[i]) //当前元素大于单调递增队列的队尾元素的时候,队尾的元素依次弹出队列,直到队尾元素大于当前当前元素的时候,将当前元素插入队尾
--tail1;
dq1[ ++tail1 ] = i; //只需要记录下标即可
while(front2 <= tail2 && a[ dq2[tail2] ] >= a[i]) //当前元素小于单调递减队列的队尾元素的时候,队尾的元素依次弹出队列,直到队尾元素小于当前当前元素的时候,将当前元素插入队尾
--tail2;
dq2[ ++tail2 ] = i; //只需要记录下标即可
/*
Max - Min 为两个队列的队首之差
while(Max-Min>K) 看哪个的队首元素比较靠前,就把谁往后移动
*/
while(a[ dq1[front1] ] - a[ dq2[front2] ] > k)
{
if(dq1[front1] < dq2[front2] )
{
start = dq1[front1] + 1;
++front1;
}
else
{
start = dq2[front2] + 1;
++front2;
}
}
if(a[ dq1[front1] ] - a[ dq2[front2] ] >= m)
{
if(i - start +1 > ans)
ans = i - start + 1;
}
}
printf("%d\n",ans);
}
return 0;
}
作者:Hackbuteer1 发表于2012-4-3 21:54:38 原文链接
阅读:223 评论:0 查看评论
|
||||
| [原]实习生招聘笔试 | ||||
|
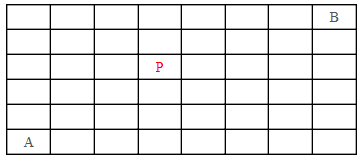
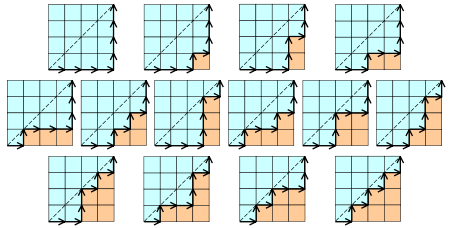
1、计算表达式x6+4x4+2x3+x+1最少需要做()次乘法 A、3 B、4 C、5 D、6 第一次乘法:x^2,第二次乘法:x^4=x^2 * x^2,第三次乘法:原式=x^2 * (x^4+4x^2+2x)+x+1,每一项的系数可以使用加法来实现。。 2、给定3个int类型的正整数x,y,z,对如下4组表达式判断正确的选项() Int a1=x+y-z; int b1=x*y/z; Int a2=x-z+y; int b2=x/z*y; Int c1=x<<y>>z; int d1=x&y|z; Int c2=x>>z<<y; int d2=x|z&y; A、a1一定等于a2 B、b1一定定于b2 C、c1一定等于c2 D、d1一定等于d2 3、程序的完整编译过程分为是:预处理,编译,汇编等,如下关于编译阶段的编译优化的说法中不正确的是() A、死代码删除指的是编译过程直接抛弃掉被注释的代码; B、函数内联可以避免函数调用中压栈和退栈的开销 C、For循环的循环控制变量通常很适合调度到寄存器访问 D、强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令 4、 如下关于进程的描述不正确的是() A、进程在退出时会自动关闭自己打开的所有文件 B、进程在退出时会自动关闭自己打开的网络链接 C、进程在退出时会自动销毁自己创建的所有线程 D、进程在退出时会自动销毁自己打开的共享内存 5、 在如下8*6的矩阵中,请计算从A移动到B一共有多少种走法?要求每次只能向上挥着向右移动一格,并且不能经过P;
A、492 B、494 C、496 D、498 6、SQL语言中删除一个表的指令是() A、DROP TABLE B、DELETE TABLE C、DESTROY TABLE D、REMOVE TABLE 7、某产品团队由美术组、产品组、client程序组和server程序组4个小组构成,每次构建一套完整的版本时,需要各个组发布如下资源。美术组想客户端提供图像资源(需要10分钟),产品组向client组合server提供文字内容资源(同时进行,10分钟),server和client源代码放置在不同工作站上,其完整编译时间均为10分钟切编译过程不依赖于任何资源,client程序(不包含任何资源)在编译完毕后还需要完成对程序的统一加密过程(10分钟)。可以请问,从要完成一次版本构建(client与server的版本代码与资源齐备),至少需要多少时间() A、60分钟 B、40分钟 C、30分钟 D、20分钟
8、如下关于编译链接的说法错误的是() A、编译优化会使得编译速度变慢 B、预编译头文件可以优化程序的性能 C、静态链接会使得可执行文件偏大 D、动态链接库会使进程启动速度偏慢 9、如下关于链接的说法错误的是() A、一个静态库中不能包含两个同名全局函数的定义 B、一个动态库中不能包含两个同名全局函数的定义 C、如果两个静态库都包含一个同名全局函数,他们不能同时被链接 D、如果两个动态库都包含一个同名全局函数,他们不能同时被链接 10、排序算法的稳定是指,关键码相同的记录排序前后相对位置不发生改变,下面哪种排序算法是不稳定的() A、插入排序 B、冒泡排序 C、快速排序 D、归并排序 11、下列说法中错误的是:() A、插入排序某些情况下复杂度为O(n) B、排序二叉树元素查找的复杂度可能为O(n) C、对于有序列表的排序最快的是快速排序 D、在有序列表中通过二分查找的复杂度一定是O(n log2n) 12、在程序设计中,要对两个16K×16K的多精度浮点数二维数组进行矩阵求和时,行优先读取和列优先读取的区别是() A、没区别 B、行优先快 C、列优先快 D、2种读取方式速度为随机值,无法判断
13、字符串www.qq.com所有非空子串(两个子串如果内容相同则只算一个)个数是() A、1024 B、1018 C、55 D、50 14、TCP的关闭过程,说法正确的是() A、TIME_WAIT状态称为MSL(Maximum Segment Lifetime)等待状态 B、对一个established状态的TCP连接,在调用shutdown函数之前调用close接口,可以让主动调用的一方进入半关闭状态 C、主动发送FIN消息的连接端,收到对方回应ack之前不能发只能收,在收到对方回复ack之后不能发也不能收,进入CLOSING状态 D、在已经成功建立连接的TCP连接上,如果一端收到RST消息可以让TCP的连洁端绕过半关闭状态并允许丢失数据。 15、操作系统的一些特别端口要为特定的服务做预留,必须要root权限才能打开的端口描述正确的是() A、端口号在64512-65535之间的端口 B、所有小于1024的每个端口 C、RFC标准文档中已经声明特定服务的相关端口,例如http服务的80端口,8080端口等 D、所有端口都可以不受权限限制打开 16、图书馆有6人排队,其中3人要还同一本书,书名为《面试宝典》,另外3人要借。问求能保证另外3人借到的种类。 17、ack(3 , 3)的执行结果是多少? int ack(int m,int n)
{
if(m == 0)
return n + 1;
else if(n == 0)
return ack(m-1,1);
else
return ack(m - 1 , ack(m , n-1));
}
这个题目可以找规律的。。
18、如下SQL语句是需要列出一个论坛版面第一页(每页显示20个)的帖子(post)标题(title),并按照发布(create_time)降序排列: SELECT title FROM post( )create_time DESC( )0,20 order by limit
19、为了某项目需要,我们准备构造了一种面向对象的脚本语言,例如,对所有的整数,我们都通过Integer类型的对象来描述。在计算“1+2”时,这里的“1”,“2”和结果“3”分别为一个Integer对象。为了降低设计复杂度,我们决定让Integer对象都是只读对象,也即在计算a=a+b后,对象a引用的是一个新的对象,而非改a所指对象的值。考虑到性能问题,我们又引入两种优化方案:(1)对于数值相等的Integer对象,我们不会重复创建。例如,计算“1+1”,这里两个“1”的引用的是同一个对象——这种设计模式叫做();(2)脚本语言解析器启动时,默认创建数值范围[1,32]的32个Integer对象。现在,假设我们要计算表达式“1+2+3+…+40”,在计算过程需要创建的Integer对象个数是()。 享元模式20、甲、乙两个人在玩猜数字游戏,甲随机写了一个数字,在[1,100]区间之内,将这个数字写在了一张纸上,然后乙来猜。 答案:猜测序列是14,、27、39、50、60、69、77、84、90、95、99 一道关于动态规划的面试题——Google面试题:扔玻璃珠
#include<iostream>
using namespace std;
int dp[101] = { 0 };
void solve()
{
int i , j , k;
for(i = 2 ; i < 101 ; ++i)
{
dp[i] = i;
for(j = 1 ; j < i ; ++j)
{
k = (j>=(1 + dp[i-j])) ? j : (1 + dp[i-j]);
if(dp[i] > k)
dp[i] = k;
}
}
}
int main(void)
{
dp[0] = 0 , dp[1] = 1;
solve();
printf("%d\n",dp[100]);
return 0;
}
输出结果为14。也就是说,最好的方式只要试14次就能够得出结果了。答案是先从14楼开始抛第一次;如果没碎,再从27楼抛第二次;如果还没碎,再从39楼抛第三次;如果还没碎,再从50楼抛第四次;如此,每次间隔的楼层少一层。这样,任何一次抛棋子碎时,都能确保最多抛14次可以找出临界楼层。 证明如下: 1、第一次抛棋子的楼层:最优的选择必然是间隔最大的楼层。比如,第一次如果在m层抛下棋子,以后再抛棋子时两次楼层的间隔必然不大于m层(大家可以自己用反证法简单证明) 2、从第二次抛棋子的间隔楼层最优的选择必然比第一次间隔少一层,第三次的楼层间隔比第二次间隔少一层,如此,以后每次抛棋子楼层间隔比上一次间隔少一层。(大家不妨自己证明一下) 3、所以,设n是第一次抛棋子的最佳楼层,则n即为满足下列不等式的最小自然数: 不等式如下: 1+2+3+...+(n-1)+n >= 100 由上式可得出n=14 即最优的策略是先从第14层抛下,最多抛14次肯定能找出临界楼层。
21、给定一个数组a[N],我们希望构造数组b[N],其中b[i]=a[0]*a[1]*...*a[N-1]/a[i]。在构造过程:
/*
思路:进行3趟扫描
第一趟从左到右对A进行累乘,结果保存在B数组中,b[i] = b[i-1]*a[i-1];
第二趟从右到左对A进行累乘,结果写入A中,a[i]=a[i+1]*a[i];
第三趟从左到右,然后B数组对应位置的元素等于其前一个位置的元素与A中其后一个位置的元素的乘积。b[i] = a[i+1] * b[i-1]
*/
void makeArray(int a[],int b[],int len)
{
int i;
b[0] = 1;
for(i = 1 ; i < len ; ++i)
b[i] = b[i-1] * a[i-1]; // b[0] = 1 , b[i] = a[0]*a[1]*...*a[i-1]
a[len - 1] = a[len - 1]^a[len - 2]; //不使用中间变量,通过位运算来交换两个变量
a[len - 2] = a[len - 1]^a[len - 2];
a[len - 1] = a[len - 1]^a[len - 2];
for(i = len - 3 ; i >= 0 ; --i)
{
a[len - 1] = a[i + 1] * a[len - 1];
a[i] = a[i]^a[len - 1]; //交换两个变量
a[len - 1] = a[i]^a[len - 1];
a[i] = a[i]^a[len - 1];
}
a[len - 1 ] = 1; //a[len - 1 ] = 1 , a[i] = a[i+1]*a[i+2]*...*a[len-1]
for(i = 0 ; i < len ; ++i)
b[i] = a[i] * b[i];
}
方法二:
//方法二,保持a数组不变
void makeArray(int a[],int b[],int len)
{
int i;
b[0] = 1;
for(i = 1 ; i < len ; ++i)
{
b[0] *= a[i-1];
b[i] = b[0]; // b[i] = a[0]*a[1]*...*a[i-1]
}
b[0] = 1;
for(i = len - 2 ; i > 0 ; --i)
{
b[0] *= a[i+1]; // b[0] = a[i+1]*a[i+2]...*a[len-1]
b[i] *= b[0]; // b[i] = a[0]*a[1]*...*a[i-1]*a[i+1]*...*a[len-1]
}
b[0] *= a[1];
}
方法三:
void makeArray(int a[],int b[],int len)
{
int i;
b[0] = 1;
for(i = 1 ; i < len ; ++i)
{
b[i] = b[i-1] * a[i-1]; // b[i] = a[0]*a[1]*...*a[i-1]
}
b[0] = a[len - 1];
for(i = len - 2 ; i > 0 ; --i)
{
b[i] *= b[0]; // b[i] = a[0]*a[1]*...*a[i-1]*a[i+1]*...*a[len-1]
b[0] *= a[i]; // b[0] = a[i+1]*a[i+2]...*a[len-1]
}
}
22、20世纪60年代,美国心理学家米尔格兰姆设计了一个连锁信件实验。米尔格兰姆把信随即发送给住在美国各城市的一部分居民,信中写有一个波士顿股票经纪人的名字,并要求每名收信人把这封信寄给自己认为是比较接近这名股票经纪人的朋友。这位朋友收到信后再把信寄给他认为更接近这名股票经纪人的朋友。最终,大部分信件都寄到了这名股票经纪人手中,每封信平均经受6.2词到达。于是,米尔格兰姆提出六度分割理论,认为世界上任意两个人之间建立联系最多只需要6个人。
假设QQ号大概有10亿个注册用户,存储在一千台机器上的关系数据库中,每台机器存储一百万个用户及其的好友信息,假设用户的平均好友个数大约为25人左右。 第一问:请你设计一个方案,尽可能快的计算存储任意两个QQ号之间是否六度(好友是1度)可达,并得出这两位用户六度可达的话,最短是几度可达。 第二问:我们希望得到平均每个用户的n度好友个数,以增加对用户更多的了解,现在如果每台机器一秒钟可以返回一千条查询结果,那么在10天的时间内,利用给出的硬件条件,可以统计出用户的最多几度好友个数?如果希望得到更高的平均n度好友个数,可以怎样改进方案? 23、段页式虚拟存储管理方案的特点。 作者:Hackbuteer1 发表于2012-4-8 22:35:48 原文链接
阅读:1674 评论:21 查看评论
|
||||
| [原]2011Google校园招聘笔试题 | ||||
|
1、已知两个数字为1~30之间的数字,甲知道两数之和,乙知道两数之积,甲问乙:“你知道是哪两个数吗?”乙说:“不知道”。乙问甲:“你知道是哪两个数吗?”甲说:“也不知道”。于是,乙说:“那我知道了”,随后甲也说:“那我也知道了”,这两个数是什么? 答:1和4 或者1和7 2、一个环形公路,上面有N个站点,A1, ..., AN,其中Ai和Ai+1之间的距离为Di,AN和A1之间的距离为D0。
const int N = 10;
int D[N];
int A1toX[N];
void Preprocess()
{
srand(time(0));
for (int i = 0; i < N; ++i)
{
D[i] = (rand()/(RAND_MAX+1.0)) * N;
}
A1toX[1] = D[1]; //from A1 to A2
for (int i = 2; i < N; ++i)
{
A1toX[i] = A1toX[i-1] + D[i]; //distance from A1 to each point
}
A1toX[0] = A1toX[N-1] + D[0]; // total length
}
int distance(int i, int j)
{
int di = (i == 0) ? 0 : A1toX[i-1];
int dj = (j ==0) ? 0 : A1toX[j-1];
int dist = abs(di - dj);
return dist > A1toX[0]/2 ? A1toX[0] - dist : dist;
}
int main(void)
{
Preprocess();
for (int i = 0; i <N; ++i)
{
cout<<D[i]<<" ";
}
cout<<endl;
for (int i = 1; i <= N; ++i)
{
cout<<"distance from A1 to A"<<i<<": "<<distance(1, i)<<endl;
}
return 0;
}
3、 一个字符串,压缩其中的连续空格为1个后,对其中的每个字串逆序打印出来。比如"abc efg hij"打印为"cba gfe jih"。
#include<iostream>
#include<cstdio>
#include<stack>
#include<string>
using namespace std;
string reverse(string str)
{
stack<char> stk;
int len = str.length();
string ret = "";
for (int p = 0, q = 0;p < len;)
{
if (str[p] == ' ')
{
ret.append(1,' ');
for (q = p; q < len && str[q] == ' '; q++)
{}
p = q;
}
else
{
for (q = p; q < len && str[q] != ' '; q++)
{
stk.push(str[q]);
}
while(!stk.empty())
{
ret.append(1,stk.top());
stk.pop();
}
p = q;
}
}
return ret;
}
int main(void)
{
string s = "abc def ghi";
cout<<reverse(s).c_str()<<endl;
return 0;
}
4、将一个较大的钱,不超过1000000(10^6)的人民币,兑换成数量不限的100、50、10、5、2、1的组合,请问共有多少种组合呢?(完全背包)(其它选择题考的是有关:操作系统、树、概率题、最大生成树有关的题,另外听老梦说,谷歌不给人霸笔的机会。)。
作者:Hackbuteer1 发表于2012-4-9 21:21:26 原文链接
阅读:415 评论:0 查看评论
|
||||
| [原]微软2012暑期实习生校园招聘笔试题 | ||||
| 1、Suppose that a selection sort of 80 items has completed 32 iterations of the main loop. How many items are now guaranteed to be in their final spot (never to be moved again)? A、16 B、31 C、32 D、39 E、40 2、Which synchronization mechanism(s) is/are used to avoid race conditions among processes/threads in operating system? A、Mutex B、Mailbox C、Semaphore D、Local procedure call 3、There is a sequence of n numbers 1,2,3,...,n and a stack which can keep m numbers at most. Push the n numbers into the stack following the sequence and pop out randomly . Suppose n is 2 and m is 3,the output sequence may be 1,2 or 2,1,so we get 2 different sequences . Suppose n is 7,and m is 5,please choose the output sequence of the stack. A、1,2,3,4,5,6,7 B、7,6,5,4,3,2,1 C、5,6,4,3,7,2,1 D、1,7,6,5,4,3,2 E、3,2,1,7,5,6,4 4、Which is the result of binary number 01011001 after multiplying by 0111001 and adding 1101110? A、0001010000111111 B、0101011101110011 C、0011010000110101 转化为10进制操作以后,再转化为二进制就可以了。 5、What is output if you compile and execute the following c code?
void main()
{
int i = 11;
int const *p = &i;
p++;
printf("%d",*p);
}
A、11B、12 C、Garbage value D、Compile error E、None of above 6、Which of following C++ code is correct ? C A、 int f()
{
int *a = new int(3);
return *a;
}
B、
int *f()
{
int a[3] = {1,2,3};
return a;
}
C、
vector<int> f()
{
vector<int> v(3);
return v;
}
D、
void f(int *ret)
{
int a[3] = {1,2,3};
ret = a;
return ;
}
E、None of above 7、Given that the 180-degree rotated image of a 5-digit number is another 5-digit number and the difference between the numbers is 78633, what is the original 5-digit number? A、We can create a binary tree from given inorder and preorder traversal sequences. B、We can create a binary tree from given preorder and postorder traversal sequences. C、For an almost sorted array,Insertion sort can be more effective than Quciksort. D、Suppose T(n) is the runtime of resolving a problem with n elements, T(n)=O(1) if n=1; T(n)=2*T(n/2)+O(n) if n>1; so T(n) is O(nlgn) E、None of above 9、Which of the following statements are true? A、Insertion sort and bubble sort are not efficient for large data sets. B、Qucik sort makes O(n^2) comparisons in the worst case. C、There is an array :7,6,5,4,3,2,1. If using selection sort (ascending),the number of swap operations is 6 D、Heap sort uses two heap operations:insertion and root deletion (插入、堆调整) E、None of above 10、Assume both x and y are integers,which one of the followings returns the minimum of the two integers? A、y^((x^y) & -(x<y)) B、y^(x^y) C、x^(x^y) D、(x^y)^(y^x) E、None of above x<y的时候,-(x<y)即-1的补码形式就是全1(111111),(x^y)&-(x<y)== x^y。x>y的时候,-(x<y)即0的补码形式就是全0(000000),(x^y)&-(x<y)== 0 11、The Orchid Pavilion(兰亭集序) is well known as the top of “行书”in history of Chinese literature. The most fascinating sentence is "Well I know it is a lie to say that life and death is the same thing, and that longevity and early death make no difference Alas!"(固知一死生为虚诞,齐彭殇为妄作).By counting the characters of the whole content (in Chinese version),the result should be 391(including punctuation). For these characters written to a text file,please select the possible file size without any data corrupt.A、782 bytes in UTF-16 encoding B、784 bytes in UTF-16 encoding C、1173 bytes in UTF-8 encoding D、1176 bytes in UTF-8 encoding E、None of above 12、Fill the blanks inside class definition
class Test
{
public:
____ int a;
____ int b;
public:
Test::Test(int _a , int _b) : a( _a )
{
b = _b;
}
};
int Test::b;
int main(void)
{
Test t1(0 , 0) , t2(1 , 1);
t1.b = 10;
t2.b = 20;
printf("%u %u %u %u",t1.a , t1.b , t2.a , t2.b);
return 0;
}
Running result : 0 20 1 20
A、static/const B、const/static C、--/static D、conststatic/static E、None of above A、11 B、12 C、13 D、14 14、In C++,which of the following keyword(s)can be used on both a variable and a function? A、static B、virtual C、extern D、inline E、const 15、What is the result of the following program? char *f(char *str , char ch)
{
char *it1 = str;
char *it2 = str;
while(*it2 != '\0')
{
while(*it2 == ch)
{
it2++;
}
*it1++ = *it2++;
}
return str;
}
int main(void)
{
char *a = new char[10];
strcpy(a , "abcdcccd");
cout<<f(a,'c');
return 0;
}
A、abdcccdB、abdd C、abcc D、abddcccd E、Access violation 16、Consider the following definition of a recursive function,power,that will perform exponentiation.
int power(int b , int e)
{
if(e == 0)
return 1;
if(e % 2 == 0)
return power(b*b , e/2);
else
return b * power(b*b , e/2);
}
Asymptotically(渐进地) in terms of the exponent e,the number of calls to power that occur as a result of the call power(b,e) isA、logarithmic B、linear C、quadratic D、exponential 17、Assume a full deck of cards has 52 cards,2 blacks suits (spade and club) and 2 red suits(diamond and heart). If you are given a full deck,and a half deck(with 1 red suit and 1 black suit),what is the possibility for each one getting 2 red cards if taking 2 cards? A、1/2 1/2 B、25/102 12/50 C、50/51 24/25 D、25/51 12/25 E、25/51 1/2 18、There is a stack and a sequence of n numbers(i.e. 1,2,3,...,n), Push the n numbers into the stack following the sequence and pop out randomly . How many different sequences of the n numbers we may get? Suppose n is 2 , the output sequence may 1,2 or 2,1, so wo get 2 different sequences . A、C_2n^n B、C_2n^n - C_2n^(n+1) C、((2n)!)/(n+1)n!n! D、n! E、None of above 19、Longest Increasing Subsequence(LIS) means a sequence containing some elements in another sequence by the same order, and the values of elements keeps increasing. For example, LIS of {2,1,4,2,3,7,4,6} is {1,2,3,4,6}, and its LIS length is 5. Considering an array with N elements , what is the lowest time and space complexity to get the length of LIS? A、Time : N^2 , Space : N^2 B、Time : N^2 , Space : N C、Time : NlogN , Space : N D、Time : N , Space : N E、Time : N , Space : C 20、What is the output of the following piece of C++ code ?
#include<iostream>
using namespace std;
struct Item
{
char c;
Item *next;
};
Item *Routine1(Item *x)
{
Item *prev = NULL,
*curr = x;
while(curr)
{
Item *next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
return prev;
}
void Routine2(Item *x)
{
Item *curr = x;
while(curr)
{
cout<<curr->c<<" ";
curr = curr->next;
}
}
int main(void)
{
Item *x,
d = {'d' , NULL},
c = {'c' , &d},
b = {'b' , &c},
a = {'a' , &b};
x = Routine1( &a );
Routine2( x );
return 0;
}
A、 c b a d B、 b a d c C、 d b c a D、 a b c d E、 d c b a
作者:Hackbuteer1 发表于2012-4-9 22:20:22 原文链接
阅读:1095 评论:13 查看评论
|
||||
| [原]Catalan数——卡特兰数 | ||||
| Catalan数——卡特兰数 今天阿里淘宝笔试中碰到两道组合数学题,感觉非常亲切,但是笔试中失踪推导不出来 后来查了下,原来是Catalan数。悲剧啊,现在整理一下 一、Catalan数的定义令h(1)=1,Catalan数满足递归式:h(n) = h(1)*h(n-1) + h(2)*h(n-2) + ... + h(n-1)h(1),n>=2该递推关系的解为:h(n) = C(2n-2,n-1)/n,n=1,2,3,...(其中C(2n-2,n-1)表示2n-2个中取n-1个的组合数) 问题描述: 12个高矮不同的人,排成两排,每排必须是从矮到高排列,而且第二排比对应的第一排的人高,问排列方式有多少种? 这个笔试题,很YD,因为把某个递推关系隐藏得很深。 问题分析: 我们先把这12个人从低到高排列,然后,选择6个人排在第一排,那么剩下的6个肯定是在第二排. 用0表示对应的人在第一排,用1表示对应的人在第二排,那么含有6个0,6个1的序列,就对应一种方案. 比如000000111111就对应着 第一排:0 1 2 3 4 5 第二排:6 7 8 9 10 11 010101010101就对应着 第一排:0 2 4 6 8 10 第二排:1 3 5 7 9 11 问题转换为,这样的满足条件的01序列有多少个。 观察1的出现,我们考虑这一个出现能不能放在第二排,显然,在这个1之前出现的那些0,1对应的人 要么是在这个1左边,要么是在这个1前面。而肯定要有一个0的,在这个1前面,统计在这个1之前的0和1的个数。 也就是要求,0的个数大于1的个数。 OK,问题已经解决。 如果把0看成入栈操作,1看成出栈操作,就是说给定6个元素,合法的入栈出栈序列有多少个。 这就是catalan数,这里只是用于栈,等价地描述还有,二叉树的枚举、多边形分成三角形的个数、圆括弧插入公式中的方法数,其通项是c(2n, n)/(n+1). 在<<计算机程序设计艺术>>,第三版,Donald E.Knuth著,苏运霖译,第一卷,508页,给出了证明: 问题大意是用S表示入栈,X表示出栈,那么合法的序列有多少个(S的个数为n) 显然有c(2n, n)个含S,X各n个的序列,剩下的是计算不允许的序列数(它包含正确个数的S和X,但是违背其它条件). 在任何不允许的序列中,定出使得X的个数超过S的个数的第一个X的位置。然后在导致并包括这个X的部分序列中,以S代替所有的X并以X代表所有的S。结果是一个有(n+1)个S和(n-1)个X的序列。反过来,对一垢一种类型的每个序列,我们都能逆转这个过程,而且找出导致它的前一种类型的不允许序列。例如XXSXSSSXXSSS必然来自SSXSXXXXXSSS。这个对应说明,不允许的序列的个数是c(2n, n-1),因此an = c(2n, n) - c(2n, n-1)。 验证:其中F表示前排,B表示后排,在枚举出前排的人之后,对应的就是后排的人了,然后再验证是不是满足后面的比前面对应的人高的要求。
#include <iostream>
using namespace std;
int bit_cnt(int n)
{
int result = 0;
for (; n; n &= n-1, ++result);
return result;
}
int main(void)
{
int F[6], B[6];
int i,j,k,state,ok,ans = 0;
for (state = 0; state < (1 << 12); ++state)
{
if (bit_cnt(state) == 6)
{
i = j = 0;
for (int k = 0; k < 12; ++k)
{
if(state&(1<<k))
F[i++] = k;
else
B[j++] = k;
}
ok = 1;
for (k = 0; k < 6; ++k)
{
if (B[k] < F[k])
{
ok = 0;
break;
}
}
ans += ok;
}
}
cout << ans << endl;
return 0;
}
结果:132 而c(12, 6)/7 = 12*11*10*9*8*7/(7*6*5*4*3*2) = 132 注意:c(2n, n)/(n+1) = c(2n, n) - c(2n, n-1)估计出题的人也读过<<计算机程序艺术>>吧。 PS: 另一个很YD的问题: 有编号为1到n(n可以很大,不妨在这里假定可以达到10亿)的若干个格子,从左到右排列。 在某些格子中有一个棋子,不妨设第xi格有棋子(1<=i<=k, 1<=k<=n) 每次一个人可以把一个棋子往左移若干步,但是不能跨越其它棋子,也要保证每个格子至多只有一个棋子。 两个人轮流移动,移动不了的为输,问先手是不是有必胜策略。 三、Catalan数的典型应用: 1、括号化问题。矩阵链乘: P=A1×A2×A3×……×An,依据乘法结合律,不改变其顺序,只用括号表示成对的乘积,试问有几种括号化的方案? 一个有n个X和n个Y组成的字串,且所有的部分字串皆满足X的个数大于等于Y的个数。以下为长度为6的dyck words: 类似:在圆上选择2n个点,将这些点成对连接起来使得所得到的n条线段不相交的方法数?
类似:有2n个人排成一行进入剧场。入场费5元。其中只有n个人有一张5元钞票,另外n人只有10元钞票,剧院无其它钞票,问有多少中方法使得只要有10元的人买票,售票处就有5元的钞票找零?(将持5元者到达视作将5元入栈,持10元者到达视作使栈中某5元出栈) 类似:一位大城市的律师在他住所以北n个街区和以东n个街区处工作,每天她走2n个街区去上班。如果他从不穿越(但可以碰到)从家到办公室的对角线,那么有多少条可能的道路?
4、给顶节点组成二叉树的问题。
在2n位二进制数中填入n个1的方案数为c(2n,n),不填1的其余n位自动填0。从中减去不符合要求(由左而右扫描,0的累计数大于1的累计数)的方案数即为所求。给定N个节点,能构成多少种形状不同的二叉树? (一定是二叉树!先去一个点作为顶点,然后左边依次可以取0至N-1个相对应的,右边是N-1到0个,两两配对相乘,就是h(0)*h(n-1) + h(2)*h(n-2) + ...... + h(n-1)h(0)=h(n)) (能构成h(N)个)  不符合要求的数的特征是由左而右扫描时,必然在某一奇数位2m+1位上首先出现m+1个0的累计数和m个1的累计数,此后的2(n-m)-1位上有n-m个 1和n-m-1个0。如若把后面这2(n-m)-1位上的0和1互换,使之成为n-m个0和n-m-1个1,结果得1个由n+1个0和n-1个1组成的2n位数,即一个不合要求的数对应于一个由n+1个0和n-1个1组成的排列。 反过来,任何一个由n+1个0和n-1个1组成的2n位二进制数,由于0的个数多2个,2n为偶数,故必在某一个奇数位上出现0的累计数超过1的累计数。同样在后面部分0和1互换,使之成为由n个0和n个1组成的2n位数,即n+1个0和n-1个1组成的2n位数必对应一个不符合要求的数。 因而不合要求的2n位数与n+1个0,n-1个1组成的排列一一对应。 显然,不符合要求的方案数为c(2n,n+1)。由此得出输出序列的总数目=c(2n,n)-c(2n,n+1)=1/(n+1)*c(2n,n)。 (这个公式的下标是从h(0)=1开始的) 作者:Hackbuteer1 发表于2012-4-11 16:40:40 原文链接
阅读:365 评论:4 查看评论
|
||||
| [原]迅雷2012校园招聘笔试题 | ||||
| 1、微机中1K字节表示的二进制位数是() A、1000 B、0X1000 C、1024 D、0X1024 2、设C语言中,一个int型数据在内存中占2个字节,则unsigned int 型数据的取值范围为() A、0--- 255 B、0--- 32767 C、0--- 65535 D、0--- 2147483647 3、在C语言中,要求运算数必须是整型的运算符是() A、/ B、++ C、|= D、% 4、下面程序段的运行结果是()
char c[5] = {'a','b','\0','c','\0'};
printf("%s",c);
A、'a"b' B、ab C、ab_c D、ab_c_ (其中_表示空格) 5、下列关于数组的初始化正确的是() A、 char str[2] = {"a","b"} B、 char str[2][3] = {"a","b"} C、 char str[2][3] = {{'a','b'},{'e','f'},{'g','h'}} D、 char str[] = {"a","b"} 6、判断字符串a和b是否相等,应当使用() A、if(a==b) B、if(a=b) C、if(strcpy(a,b)) D、if(strcmp(a,b)) 7、一直inta[3][4];则下列能表示a[1][2]元素值的是() A、*(*(a+1)+2) B、*(a+1+2) C、(&a[0]+1)[2] D、*(a[0]+1) 8、若希望当A的值为奇数时,表达式的值为真,A的值为偶数时,表达式的值为假,则以下不能满足要求的表达式是() A、A%2==1 B、!(A%2==0) C、!(A%2) D、A%2 9、以下哪项可以用来释放 p = malloc() 分配的内存() A、free(p) B、delete p C、delete []p D、sizeof p 10、下列有关静态成员函数的描述中,正确的是() A、静态数据成员可以再类体内初始化 B、静态数据成员不可以被类对象调用 C、静态数据成员不受private控制符作用 D、静态数据成员可以直接用类名调用 11、按e1、e2、e3、e4的次序进栈(中间可能有出栈操作,例如e1进栈后出栈,e2再进栈),则可能的出栈序列是() A、e3、e1、e4、e2 B、e2、e4、e3、e1 C、e3、e4、e1、e2 D、任意序列 12、某二叉树结点的中序序列为A、B、C、D、E、F、G,后序序列为B、D、C、A、F、G、E,该二叉树对应的树林包括多少棵树()
int main(void)
{
char a[]={"programming"},b[]={"language"};
char *p1,*p2;
int i;
p1=a,p2=b;
for(i=0;i<7;i++)
{
if(*(p1+i)==*(p2+i))
printf("%c",*(p1+i));
}
return 0;
}
A、gm B、rg C、or D、ga18、若有以下程序段:
int a[]={4,0,2,3,1},i,j,t;
for(i=1;i<5;i++)
{
t=a[i];
j=i-1;
while(j>=0 && t>a[j])
{
a[j+1]=a[j];
j--;
}
a[j+1]=t;
}
A、对数组a进行插入排序(升序)B、对数组a进行插入排序(降序) C、对数组a进行选择排序(升序) D、对数组a进行选择排序(降序) 19、以下程序的输出结果是()
#define P 3
int F(int x)
{
return (P*x*x);
}
void main()
{
printf("%d\n",F(3+5));
}
A、49B、192 C、29 D、77 20、以下代码中,A的构造函数和析构函数分别执行了几次() A *pa = new A[10]; A、1、1 B、10、10 C、1、10 D、10、1
struct stu
{
union
{
char b[5];
int bh[2];
}class;
char xm[8];
float cj;
}xc;
A、16 B、18 C、20 D、2223、设二叉树根结点的层次为0,一棵深度(高度)为k的满二叉树和同样深度的完全二叉树各有f个结点和c个结点,下列关系式不正确的是() A、f >= c B、c > f C、f=2^k+1 D、c>2k-1 24、关于引用和指针的区别,下列叙述错误的是() A、引用必须初始化,指针不必 B、指针初始化以后不能被改变,引用可以改变所指的对象 C、删除空指针是无害的,不能删除引用 D、不存在指向空值的引用,但是存在指向空值的指针 25、属于网络层协议的是() A、IP B、TCP C、ICMP D、X.25 26、STL中的哪种结构在增加成员时可能会引起原有数据成员的存储位置发生变动() A、map B、set C、list D、vector 27、windows消息调度机制是() A、指令队列 B、指令堆栈 C、消息队列 D、消息堆栈 28、在排序方法中,关键码比较次数和记录的初始排列无关的是() A、Shell排序 B、归并排序 C、直接插入排序 D、选择排序 29、假设A为抽象类,下列声明()是正确的 A、A fun(int ); B、A *p; C、int fun(A) D、A Obj; 抽象类不能定义对象。但是可以作为指针或者引用类型使用。 A、std::auto_ptr<Object> pObj(new Object); B、std::vector<std::auto_ptr<Object*>> object_vector; C、std::auto_ptr<Object*> pObj(new Object); D、std::vector<std::auto_ptr<Object>> object_vector; 二、填空题 1、写出float x 与零值比较的if语句。 不可将浮点变量用“==”或“!=”与数字比较,应该设法转化成“>=”或“<=”此类形式。 if(x>0.0000001 && x<-0.0000001) 2、在32位系统中,char str[]="xuelei"; char *p = str; sizeof(str)=() ,sizeof(p)=() ,sizeof(*p)=() 答案分别是: 7、4、1,分别对数组、指针和一个字符类型求大小。。 4、char a[2][2][3] = {{{1,6,3},{5,4,15}},{{3,5,33},{23,12,7}}}; for(int i = 0;i<12;i++) printf("%d", ); 在空格处填上合适的语句,顺序打印出a中的数字。 答案:a[i/6][(i/3)%2][i%3];这道题目是多维数组的输出问题,这里要考虑的是每维数字的取值顺序问题:第一维,前六次循环都取0,后六次取1,于是i/6可以满足要求;第二维,前3次为0,再3次为1,再3次为0,再3次为1,用量化的思想,i/3把12个数字分为4组每组3个,量化为0、1、2、3,为要得到0、1、0、1我们这里就需要对(0、1、2、3)%2=(0、1、0、1),于是(i/3)%2;最后一维我们需要的是(0、1、2;0、1、2;0、1、2;0、1、2;)我们就填上i%3。 5、以下函数查找一个整数数组中第二大的数,请填空。
const int MINNUMBER = -32767;
int find_sec_max(int data[],int count)
{
int maxnumber = data[0];
int sec_max = MINNUMBER;
for(int i = 1;i < count; i++)
{
if(data[i] > maxnumber)
{
}
else
{
if(data[i] > sec_max)
}
}
return sec_max;
}
上面的三个空格处依次应该填上:sec_max = maxnumber; maxnumber = data[i]; sec_max = data[i];
6、下面程序可从1....n中随机输出m个不重复的数,请填空。
knuth(int n,int m)
{
srand((unsigned)time(NULL));
for(int i = 0;i < n;i++)
{
if(_________)
{
cout<<i<<"\n";
______________
}
}
}
分别为:rand()%(n-i)<m 和 m--; 7、以下prim函数的功能是分解质因数,请填空。
void prim(int m,int n)
{
if(m>n)
{
while(_________) n++;
______________;
prim(m,n);
cout<<n<<endl;
}
}
void main()
{
int n = 435234;
prim(n,2);
}
答案分别为:m%n 和 m/=n8、程序改错。
int fun(vector<int>& val)
{
copy(val.begin() , val.end() , ostream_iterator<int>(cout,"\n"));
......
}
void main()
{
int a[5] = {1,2,3,4,5};
vector<int> v;
copy(a , a + 5 , v.begin());
fun(vector<int>(v));
prim(n,2);
}
错误的代码和改正后的代码分别为:9、C++中const有什么用途(至少说出三种):1、便于进行类型检查;2、可以节省空间避免不必要的内存分配,提高了效率;3、保护被修饰的对象,防止意外修改,增强程序的健壮性。 10、下面程序的功能是输出数组的全排列,请填空。
void perm(int list[],int k,int m)
{
if(_______)
{
copy(list,list+m,ostream_iterator<int>(cout," "));
cout<<endl;
return ;
}
for(int i = k ; i <= m ; ++i)
{
swap(&list[k] , &list[i]);
______________;
swap(&list[k] , &list[i]);
}
}
void main()
{
int list[] = {1,2,3,4,5};
perm(list,0,sizeof(list)/sizeof(int)-1);
}
答案分别是: k == m 和 perm(list , k+1 , m)
作者:Hackbuteer1 发表于2012-4-12 16:04:40 原文链接
阅读:495 评论:8 查看评论
|
||||
| [原]const 详解 | ||||
| 今天看了一下C++ Primer中关于const用法的介绍,讲得很好, 收益匪浅,于是做一个总结,方便以后再次查看。 但是c++在c的基础上新增加的几点优化也是很耀眼的,就const直接可以取代c中的#define以下几点很重要,学不好后果也也很严重。 一、const变量 1、限定符声明变量只能被读 6、可以通过函数对常量进行初始化 任何不会修改数据成员的函数都应该声明为const类型。如果在编写const成员函数时,不慎修改了数据成员,或者调用了其它非const成员函数,编译器将指出错误,这无疑会提高程序的健壮性。 以下程序中,类stack的成员函数GetCount仅用于计数,从逻辑上讲GetCount应当为const函数。编译器将指出GetCount函数中的错误。
class Stack
{
private:
int m_num;
int m_data[100];
public:
void Push(int elem);
int Pop(void);
int GetCount(void) const; //const成员函数
};
int Stack::GetCount(void) const
{
++m_num; //编译错误,企图修改数据成员m_num
Pop(); //编译错误,企图非const成员函数
return m_num;
}
const成员函数的声明看起来怪怪的:const关键字只能放在函数声明的尾部,大概是因为其它地方都已经被占用了。
作者:Hackbuteer1 发表于2012-4-13 20:58:33 原文链接
阅读:281 评论:3 查看评论
|
||||
| [原]C++中的单例模式 | ||||
| 单例模式也称为单件模式、单子模式,可能是使用最广泛的设计模式。其意图是保证一个类仅有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。有很多地方需要这样的功能模块,如系统的日志输出,GUI应用必须是单鼠标,MODEM的联接需要一条且只需要一条电话线,操作系统只能有一个窗口管理器,一台PC连一个键盘。 单例模式有许多种实现方法,在C++中,甚至可以直接用一个全局变量做到这一点,但这样的代码显的很不优雅。 使用全局对象能够保证方便地访问实例,但是不能保证只声明一个对象——也就是说除了一个全局实例外,仍然能创建相同类的本地实例。 《设计模式》一书中给出了一种很不错的实现,定义一个单例类,使用类的私有静态指针变量指向类的唯一实例,并用一个公有的静态方法获取该实例。 单例模式通过类本身来管理其唯一实例,这种特性提供了解决问题的方法。唯一的实例是类的一个普通对象,但设计这个类时,让它只能创建一个实例并提供对此实例的全局访问。唯一实例类Singleton在静态成员函数中隐藏创建实例的操作。习惯上把这个成员函数叫做Instance(),它的返回值是唯一实例的指针。 定义如下:
class CSingleton
{
private:
CSingleton() //构造函数是私有的
{
}
static CSingleton *m_pInstance;
public:
static CSingleton * GetInstance()
{
if(m_pInstance == NULL) //判断是否第一次调用
m_pInstance = new CSingleton();
return m_pInstance;
}
};
用户访问唯一实例的方法只有GetInstance()成员函数。如果不通过这个函数,任何创建实例的尝试都将失败,因为类的构造函数是私有的。GetInstance()使用懒惰初始化,也就是说它的返回值是当这个函数首次被访问时被创建的。这是一种防弹设计——所有GetInstance()之后的调用都返回相同实例的指针:CSingleton* p1 = CSingleton :: GetInstance(); CSingleton* p2 = p1->GetInstance(); CSingleton & ref = * CSingleton :: GetInstance(); 对GetInstance稍加修改,这个设计模板便可以适用于可变多实例情况,如一个类允许最多五个实例。 单例类CSingleton有以下特征: 它有一个指向唯一实例的静态指针m_pInstance,并且是私有的; 它有一个公有的函数,可以获取这个唯一的实例,并且在需要的时候创建该实例; 它的构造函数是私有的,这样就不能从别处创建该类的实例。 大多数时候,这样的实现都不会出现问题。有经验的读者可能会问,m_pInstance指向的空间什么时候释放呢?更严重的问题是,该实例的析构函数什么时候执行? 如果在类的析构行为中有必须的操作,比如关闭文件,释放外部资源,那么上面的代码无法实现这个要求。我们需要一种方法,正常的删除该实例。 可以在程序结束时调用GetInstance(),并对返回的指针掉用delete操作。这样做可以实现功能,但不仅很丑陋,而且容易出错。因为这样的附加代码很容易被忘记,而且也很难保证在delete之后,没有代码再调用GetInstance函数。 一个妥善的方法是让这个类自己知道在合适的时候把自己删除,或者说把删除自己的操作挂在操作系统中的某个合适的点上,使其在恰当的时候被自动执行。 我们知道,程序在结束的时候,系统会自动析构所有的全局变量。事实上,系统也会析构所有的类的静态成员变量,就像这些静态成员也是全局变量一样。利用这个特征,我们可以在单例类中定义一个这样的静态成员变量,而它的唯一工作就是在析构函数中删除单例类的实例。如下面的代码中的CGarbo类(Garbo意为垃圾工人): class CSingleton
{
private:
CSingleton()
{
}
static CSingleton *m_pInstance;
class CGarbo //它的唯一工作就是在析构函数中删除CSingleton的实例
{
public:
~CGarbo()
{
if(CSingleton::m_pInstance)
delete CSingleton::m_pInstance;
}
};
static CGarbo Garbo; //定义一个静态成员变量,程序结束时,系统会自动调用它的析构函数
public:
static CSingleton * GetInstance()
{
if(m_pInstance == NULL) //判断是否第一次调用
m_pInstance = new CSingleton();
return m_pInstance;
}
};
类CGarbo被定义为CSingleton的私有内嵌类,以防该类被在其他地方滥用。程序运行结束时,系统会调用CSingleton的静态成员Garbo的析构函数,该析构函数会删除单例的唯一实例。 使用这种方法释放单例对象有以下特征: 在单例类内部定义专有的嵌套类; 在单例类内定义私有的专门用于释放的静态成员; 利用程序在结束时析构全局变量的特性,选择最终的释放时机; 使用单例的代码不需要任何操作,不必关心对象的释放。 进一步的讨论 但是添加一个类的静态对象,总是让人不太满意,所以有人用如下方法来重现实现单例和解决它相应的问题,代码如下:
class CSingleton
{
private:
CSingleton() //构造函数是私有的
{
}
public:
static CSingleton & GetInstance()
{
static CSingleton instance; //局部静态变量
return instance;
}
};
使用局部静态变量,非常强大的方法,完全实现了单例的特性,而且代码量更少,也不用担心单例销毁的问题。但使用此种方法也会出现问题,当如下方法使用单例时问题来了, Singleton singleton = Singleton :: GetInstance(); 这么做就出现了一个类拷贝的问题,这就违背了单例的特性。产生这个问题原因在于:编译器会为类生成一个默认的构造函数,来支持类的拷贝。 最后没有办法,我们要禁止类拷贝和类赋值,禁止程序员用这种方式来使用单例,当时领导的意思是GetInstance()函数返回一个指针而不是返回一个引用,函数的代码改为如下:
class CSingleton
{
private:
CSingleton() //构造函数是私有的
{
}
public:
static CSingleton * GetInstance()
{
static CSingleton instance; //局部静态变量
return &instance;
}
};
但我总觉的不好,为什么不让编译器不这么干呢。这时我才想起可以显示的生命类拷贝的构造函数,和重载 = 操作符,新的单例类如下:
class CSingleton
{
private:
CSingleton() //构造函数是私有的
{
}
CSingleton(const CSingleton &);
CSingleton & operator = (const CSingleton &);
public:
static CSingleton & GetInstance()
{
static CSingleton instance; //局部静态变量
return instance;
}
};
关于Singleton(const Singleton);和 Singleton & operate = (const Singleton&);函数,需要声明成私有的,并且只声明不实现。这样,如果用上面的方式来使用单例时,不管是在友元类中还是其他的,编译器都是报错。不知道这样的单例类是否还会有问题,但在程序中这样子使用已经基本没有问题了。
作者:Hackbuteer1 发表于2012-4-14 10:08:40 原文链接
阅读:313 评论:2 查看评论
|
||||
| [原]字符串的全排列和组合算法 | ||||
| 全排列在笔试面试中很热门,因为它难度适中,既可以考察递归实现,又能进一步考察非递归的实现,便于区分出考生的水平。所以在百度和迅雷的校园招聘以及程序员和软件设计师的考试中都考到了,因此本文对全排列作下总结帮助大家更好的学习和理解。对本文有任何补充之处,欢迎大家指出。 首先来看看题目是如何要求的(百度迅雷校招笔试题)。 一、字符串的排列 用C++写一个函数, 如 Foo(const char *str), 打印出 str 的全排列, 如 abc 的全排列: abc, acb, bca, dac, cab, cba 一、全排列的递归实现 为方便起见,用123来示例下。123的全排列有123、132、213、231、312、321这六种。首先考虑213和321这二个数是如何得出的。显然这二个都是123中的1与后面两数交换得到的。然后可以将123的第二个数和每三个数交换得到132。同理可以根据213和321来得231和312。因此可以知道——全排列就是从第一个数字起每个数分别与它后面的数字交换。找到这个规律后,递归的代码就很容易写出来了:
#include<iostream>
using namespace std;
#include<assert.h>
void Permutation(char* pStr, char* pBegin)
{
assert(pStr && pBegin);
if(*pBegin == '\0')
printf("%s\n",pStr);
else
{
for(char* pCh = pBegin; *pCh != '\0'; pCh++)
{
swap(*pBegin,*pCh);
Permutation(pStr, pBegin+1);
swap(*pBegin,*pCh);
}
}
}
int main(void)
{
char str[] = "abc";
Permutation(str,str);
return 0;
}
另外一种写法:
//k表示当前选取到第几个数,m表示共有多少个数
void Permutation(char* pStr,int k,int m)
{
assert(pStr);
if(k == m)
{
static int num = 1; //局部静态变量,用来统计全排列的个数
printf("第%d个排列\t%s\n",num++,pStr);
}
else
{
for(int i = k; i <= m; i++)
{
swap(*(pStr+k),*(pStr+i));
Permutation(pStr, k + 1 , m);
swap(*(pStr+k),*(pStr+i));
}
}
}
int main(void)
{
char str[] = "abc";
Permutation(str , 0 , strlen(str)-1);
return 0;
}
如果字符串中有重复字符的话,上面的那个方法肯定不会符合要求的,因此现在要想办法来去掉重复的数列。二、去掉重复的全排列的递归实现 由于全排列就是从第一个数字起每个数分别与它后面的数字交换。我们先尝试加个这样的判断——如果一个数与后面的数字相同那么这二个数就不交换了。如122,第一个数与后面交换得212、221。然后122中第二数就不用与第三个数交换了,但对212,它第二个数与第三个数是不相同的,交换之后得到221。与由122中第一个数与第三个数交换所得的221重复了。所以这个方法不行。 换种思维,对122,第一个数1与第二个数2交换得到212,然后考虑第一个数1与第三个数2交换,此时由于第三个数等于第二个数,所以第一个数不再与第三个数交换。再考虑212,它的第二个数与第三个数交换可以得到解决221。此时全排列生成完毕。 这样我们也得到了在全排列中去掉重复的规则——去重的全排列就是从第一个数字起每个数分别与它后面非重复出现的数字交换。下面给出完整代码: #include<iostream>
using namespace std;
#include<assert.h>
//在[nBegin,nEnd)区间中是否有字符与下标为pEnd的字符相等
bool IsSwap(char* pBegin , char* pEnd)
{
char *p;
for(p = pBegin ; p < pEnd ; p++)
{
if(*p == *pEnd)
return false;
}
return true;
}
void Permutation(char* pStr , char *pBegin)
{
assert(pStr);
if(*pBegin == '\0')
{
static int num = 1; //局部静态变量,用来统计全排列的个数
printf("第%d个排列\t%s\n",num++,pStr);
}
else
{
for(char *pCh = pBegin; *pCh != '\0'; pCh++) //第pBegin个数分别与它后面的数字交换就能得到新的排列
{
if(IsSwap(pBegin , pCh))
{
swap(*pBegin , *pCh);
Permutation(pStr , pBegin + 1);
swap(*pBegin , *pCh);
}
}
}
}
int main(void)
{
char str[] = "baa";
Permutation(str , str);
return 0;
}
OK,到现在我们已经能熟练写出递归的方法了,并且考虑了字符串中的重复数据可能引发的重复数列问题。那么如何使用非递归的方法来得到全排列了?三、全排列的非递归实现 要考虑全排列的非递归实现,先来考虑如何计算字符串的下一个排列。如"1234"的下一个排列就是"1243"。只要对字符串反复求出下一个排列,全排列的也就迎刃而解了。 如何计算字符串的下一个排列了?来考虑"926520"这个字符串,我们从后向前找第一双相邻的递增数字,"20"、"52"都是非递增的,"26 "即满足要求,称前一个数字2为替换数,替换数的下标称为替换点,再从后面找一个比替换数大的最小数(这个数必然存在),0、2都不行,5可以,将5和2交换得到"956220",然后再将替换点后的字符串"6220"颠倒即得到"950226"。 对于像“4321”这种已经是最“大”的排列,采用STL中的处理方法,将字符串整个颠倒得到最“小”的排列"1234"并返回false。 这样,只要一个循环再加上计算字符串下一个排列的函数就可以轻松的实现非递归的全排列算法。按上面思路并参考STL中的实现源码,不难写成一份质量较高的代码。值得注意的是在循环前要对字符串排序下,可以自己写快速排序的代码(请参阅《白话经典算法之六 快速排序 快速搞定》),也可以直接使用VC库中的快速排序函数(请参阅《使用VC库函数中的快速排序函数》)。下面列出完整代码:
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
#include<assert.h>
//反转区间
void Reverse(char* pBegin , char* pEnd)
{
while(pBegin < pEnd)
swap(*pBegin++ , *pEnd--);
}
//下一个排列
bool Next_permutation(char a[])
{
assert(a);
char *p , *q , *pFind;
char *pEnd = a + strlen(a) - 1;
if(a == pEnd)
return false;
p = pEnd;
while(p != a)
{
q = p;
p--;
if(*p < *q) //找降序的相邻2数,前一个数即替换数
{
//从后向前找比替换点大的第一个数
pFind = pEnd;
while(*pFind < *p)
--pFind;
swap(*p , *pFind);
//替换点后的数全部反转
Reverse(q , pEnd);
return true;
}
}
Reverse(a , pEnd); //如果没有下一个排列,全部反转后返回false
return false;
}
int cmp(const void *a,const void *b)
{
return int(*(char *)a - *(char *)b);
}
int main(void)
{
char str[] = "bac";
int num = 1;
qsort(str , strlen(str),sizeof(char),cmp);
do
{
printf("第%d个排列\t%s\n",num++,str);
}while(Next_permutation(str));
return 0;
}
至此我们已经运用了递归与非递归的方法解决了全排列问题,总结一下就是:1、全排列就是从第一个数字起每个数分别与它后面的数字交换。 2、去重的全排列就是从第一个数字起每个数分别与它后面非重复出现的数字交换。 3、全排列的非递归就是由后向前找替换数和替换点,然后由后向前找第一个比替换数大的数与替换数交换,最后颠倒替换点后的所有数据。 二、字符串的组合 题目:输入一个字符串,输出该字符串中字符的所有组合。举个例子,如果输入abc,它的组合有a、b、c、ab、ac、bc、abc。 上面我们详细讨论了如何用递归的思路求字符串的排列。同样,本题也可以用递归的思路来求字符串的组合。假设我们想在长度为n的字符串中求m个字符的组合。我们先从头扫描字符串的第一个字符。针对第一个字符,我们有两种选择:第一是把这个字符放到组合中去,接下来我们需要在剩下的n-1个字符中选取m-1个字符;第二是不把这个字符放到组合中去,接下来我们需要在剩下的n-1个字符中选择m个字符。这两种选择都很容易用递归实现。下面是这种思路的参考代码: #include<iostream>
#include<vector>
#include<cstring>
using namespace std;
#include<assert.h>
void Combination(char *string ,int number,vector<char> &result);
void Combination(char *string)
{
assert(string != NULL);
vector<char> result;
int i , length = strlen(string);
for(i = 1 ; i <= length ; ++i)
Combination(string , i ,result);
}
void Combination(char *string ,int number , vector<char> &result)
{
assert(string != NULL);
if(number == 0)
{
static int num = 1;
printf("第%d个组合\t",num++);
vector<char>::iterator iter = result.begin();
for( ; iter != result.end() ; ++iter)
printf("%c",*iter);
printf("\n");
return ;
}
if(*string == '\0')
return ;
result.push_back(*string);
Combination(string + 1 , number - 1 , result);
result.pop_back();
Combination(string + 1 , number , result);
}
int main(void)
{
char str[] = "abc";
Combination(str);
return 0;
}
由于组合可以是1个字符的组合,2个字符的字符……一直到n个字符的组合,因此在函数void Combination(char* string),我们需要一个for循环。另外,我们一个vector来存放选择放进组合里的字符。 字符串全排列扩展----八皇后问题
这就是有名的八皇后问题。解决这个问题通常需要用递归,而递归对编程能力的要求比较高。因此有不少面试官青睐这个题目,用来考察应聘者的分析复杂问题的能力以及编程的能力。
#include<iostream>
using namespace std;
int g_number = 0;
void Permutation(int * , int , int );
void Print(int * , int );
void EightQueen( )
{
const int queens = 8;
int ColumnIndex[queens];
for(int i = 0 ; i < queens ; ++i)
ColumnIndex[i] = i; //初始化
Permutation(ColumnIndex , queens , 0);
}
bool Check(int ColumnIndex[] , int length)
{
int i,j;
for(i = 0 ; i < length; ++i)
{
for(j = i + 1 ; j < length; ++j)
{
if( i - j == ColumnIndex[i] - ColumnIndex[j] || j - i == ColumnIndex[i] - ColumnIndex[j]) //在正、副对角线上
return false;
}
}
return true;
}
void Permutation(int ColumnIndex[] , int length , int index)
{
if(index == length)
{
if( Check(ColumnIndex , length) ) //检测棋盘当前的状态是否合法
{
++g_number;
Print(ColumnIndex , length);
}
}
else
{
for(int i = index ; i < length; ++i) //全排列
{
swap(ColumnIndex[index] , ColumnIndex[i]);
Permutation(ColumnIndex , length , index + 1);
swap(ColumnIndex[index] , ColumnIndex[i]);
}
}
}
void Print(int ColumnIndex[] , int length)
{
printf("%d\n",g_number);
for(int i = 0 ; i < length; ++i)
printf("%d ",ColumnIndex[i]);
printf("\n");
}
int main(void)
{
EightQueen();
return 0;
}
转载:http://zhedahht.blog.163.co
作者:Hackbuteer1 发表于2012-4-15 11:24:26 原文链接
阅读:1544 评论:5 查看评论
|
||||
| [原]C++经典面试题 | ||||
|
1、以下三条输出语句分别输出什么?
char str1[] = "abc"; char str2[] = "abc"; const char str3[] = "abc"; const char str4[] = "abc"; const char* str5 = "abc"; const char* str6 = "abc"; cout << boolalpha << ( str1==str2 ) << endl; // 输出什么? cout << boolalpha << ( str3==str4 ) << endl; // 输出什么? cout << boolalpha << ( str5==str6 ) << endl; // 输出什么? 答:分别输出false,false,true。str1和str2都是字符数组,每个都有其自己的存储区,它们的值则是各存储区首地址,不等;str3和str4同上,只是按const语义,它们所指向的数据区不能修改。str5和str6并非数组而是字符指针,并不分配存储区,其后的“abc”以常量形式存于静态数据区,而它们自己仅是指向该区首地址的指针,所以相等。 2、下面代码的输出是什么?
float a = 1.0f; cout<< (int)a <<endl; cout<< (int&)a <<endl; cout << boolalpha << ( (int)a==(int&)a ) << endl; // 输出什么? float b = 0.0f; cout<< (int)b <<endl; cout<< (int&)b <<endl; cout << boolalpha << ( (int)b==(int&)b ) << endl; // 输出什么? 浮点数的 1.0f 在内存里是这样表示的: 3、以下代码中的两个sizeof用法有问题吗?
void UpperCase( char str[] ) // 将str 中的小写字母转换成大写字母
{
for( size_t i=0; i<sizeof(str)/sizeof(str[0]); ++i )
{
if( 'a'<=str[i] && str[i]<='z' )
{
str[i] -= ('a'-'A' );
}
}
}
int main(void)
{
char str[] = "aBcDe";
cout << "str字符长度为: " << sizeof(str)/sizeof(str[0]) << endl;
UpperCase( str );
cout << str << endl;
return 0;
}
4、非C++内建型别A和B,在哪几种情况下B能隐式转化为A?5、以下代码有什么问题?
struct Test
{
Test(int ) { }
Test() { }
void fun() { }
};
int main(void)
{
Test a(1);
a.fun();
Test b();
b.fun();
return 0;
}
6、以下代码有什么问题?
cout<< (true?1:"0") <<endl; 7、以下代码能够编译通过吗,为什么?
int main(void)
{
unsigned int const size1 = 2;
char str1[ size1 ];
unsigned int temp = 0;
cin >> temp;
unsigned int const size2 = temp;
char str2[ size2 ];
return 0;
}
8、以下反向遍历array数组的方法有什么错误?int main(void)
{
vector array;
array.push_back( 1 );
array.push_back( 2 );
array.push_back( 3 );
for( vector::size_type i=array.size()-1; i>=0; --i ) // 反向遍历array数组
{
cout << array[i] << endl;
}
return 0;
}
9、以下代码中的输出语句输出吗,为什么?
struct CLS
{
int m_i;
CLS(int i): m_i( i ) { }
CLS()
{
CLS( 0 );
}
};
int main(void)
{
CLS obj;
cout << obj.m_i << endl;
return 0;
}
10、C++中的空类,默认产生哪些类成员函数?11、 以下代码有什么问题吗?
int main(void)
{
typedef vector IntArray;
IntArray array;
array.push_back( 1 );
array.push_back( 2 );
array.push_back( 2 );
array.push_back( 3 );
// 删除array数组中所有的2
for( IntArray::iterator itor=array.begin(); itor!=array.end(); ++itor )
{
if( 2 == *itor )
{
array.erase( itor );
}
}
return 0;
}
12、 写一个函数,完成内存之间的拷贝。[考虑问题是否全面]
答案: 2、分别输出false和true。注意转换的应用。(int)a实际上是以浮点数a为参数构造了一个整型数,该整数的值是,(int&)a则是告诉编译器将a当作整数看(并没有做任何实质上的转换)。因为以整数形式存放和以浮点形式存放其内存数据是不一样的,因此两者不等。对b的两种转换意义同上,但是的整数形式和浮点形式其内存数据是一样的,因此在这种特殊情形下,两者相等(仅仅在数值意义上)。 3、答:函数内的sizeof有问题。根据语法,sizeof如用于数组,只能测出静态数组的大小,无法检测动态分配的或外部数组大小。函数外的str是一个静态定义的数组,因此其大小为,函数内的str实际只是一个指向字符串的指针,没有任何额外的与数组相关的信息,因此sizeof作用于上只将其当指针看,一个指针为个字节,因此返回。
int main(void)
{
vector<int> array;
array.push_back(1);
array.push_back(2);
array.push_back(3);
for(int i = array.size() - 1 ; i >= 0 ; --i)
cout<<array[i]<<endl;
return 0;
}
9、答:不能。在默认构造函数内部再调用带参的构造函数属用户行为而非编译器行为,亦即仅执行函数调用,而不会执行其后的初始化表达式。只有在生成对象时,初始化表达式才会随相应的构造函数一起调用。10、
class Empty
{
public:
Empty(); //缺省构造函数
Empty(const Empty &); //拷贝构造函数
~Empty(); //析构函数
Empty & operator=(const Empty &); //赋值运算符
Empty* operator&(); //取址运算符
const Empty* operator&() const; //取址运算符const
};
11、答:同样有缺少类型参数的问题。另外,每次调用“array.erase(itor);”,被删除元素之后的内容会自动往前移,导致迭代漏项,应在删除一项后使itor--,使之从已经前移的下一个元素起继续遍历。int main(void)
{
typedef vector<int> IntArray;
IntArray array;
array.push_back( 1 );
array.push_back( 2 );
array.push_back( 2 );
array.push_back( 3 );
// 删除array数组中所有的2
for( IntArray::iterator itor=array.begin(); itor!=array.end(); ++itor )
{
if( 2 == *itor )
{
itor = array.erase( itor );
itor--;
}
}
return 0;
}
12、
// 功能:由src所指内存区域复制count个字节到dest所指内存区域。
// 说明:src和dest所指内存区域可以重叠,但复制后dest内容会被更改。函数返回指向dest的指针
void *memmove(void *dest , const void *src , size_t count)
{
assert( (dest != NULL) && (src != NULL)); //安全检查
assert( count > 0 );
char *psrc = (char *) src;
char *pdest = (char *) dest;
//检查是否有重叠问题
if( pdest < psrc )
{
//正向拷贝
while( count-- )
*pdest++ = *psrc++;
}
else if( psrc < pdest )
{
//反向拷贝
psrc = psrc + count - 1;
pdest = pdest + count - 1;
while( count-- )
*pdest-- = *psrc--;
}
return dest;
}
// 功能:由src指向地址为起始地址的连续n个字节的数据复制到以dest指向地址为起始地址的空间内。
// 说明:src和dest所指内存区域不能重叠,函数返回指向dest的指针
void *memmcpy(void *dest , const void *src , size_t count)
{
assert( (dest != NULL) && (src != NULL)); //安全检查
assert( count > 0 );
char *psrc = (char *) src;
char *pdest = (char *) dest;
while( count-- )
*pdest++ = *psrc++;
return dest;
}
作者:Hackbuteer1 发表于2012-4-16 20:02:43 原文链接
阅读:350 评论:0 查看评论
|
||||
| [原]浅谈C++多态性 | ||||
| C++编程语言是一款应用广泛,支持多种程序设计的计算机编程语言。我们今天就会为大家详细介绍其中C++多态性的一些基本知识,以方便大家在学习过程中对此能够有一个充分的掌握。 多态性可以简单地概括为“一个接口,多种方法”,程序在运行时才决定调用的函数,它是面向对象编程领域的核心概念。多态(polymorphisn),字面意思多种形状。 C++多态性是通过虚函数来实现的,虚函数允许子类重新定义成员函数,而子类重新定义父类的做法称为覆盖(override),或者称为重写。(这里我觉得要补充,重写的话可以有两种,直接重写成员函数和重写虚函数,只有重写了虚函数的才能算作是体现了C++多态性)而重载则是允许有多个同名的函数,而这些函数的参数列表不同,允许参数个数不同,参数类型不同,或者两者都不同。编译器会根据这些函数的不同列表,将同名的函数的名称做修饰,从而生成一些不同名称的预处理函数,来实现同名函数调用时的重载问题。但这并没有体现多态性。 多态与非多态的实质区别就是函数地址是早绑定还是晚绑定。如果函数的调用,在编译器编译期间就可以确定函数的调用地址,并生产代码,是静态的,就是说地址是早绑定的。而如果函数调用的地址不能在编译器期间确定,需要在运行时才确定,这就属于晚绑定。 那么多态的作用是什么呢,封装可以使得代码模块化,继承可以扩展已存在的代码,他们的目的都是为了代码重用。而多态的目的则是为了接口重用。也就是说,不论传递过来的究竟是那个类的对象,函数都能够通过同一个接口调用到适应各自对象的实现方法。 最常见的用法就是声明基类的指针,利用该指针指向任意一个子类对象,调用相应的虚函数,可以根据指向的子类的不同而实现不同的方法。如果没有使用虚函数的话,即没有利用C++多态性,则利用基类指针调用相应的函数的时候,将总被限制在基类函数本身,而无法调用到子类中被重写过的函数。因为没有多态性,函数调用的地址将是一定的,而固定的地址将始终调用到同一个函数,这就无法实现一个接口,多种方法的目的了。 笔试题目:
#include<iostream>
using namespace std;
class A
{
public:
void foo()
{
printf("1\n");
}
virtual void fun()
{
printf("2\n");
}
};
class B : public A
{
public:
void foo()
{
printf("3\n");
}
void fun()
{
printf("4\n");
}
};
int main(void)
{
A a;
B b;
A *p = &a;
p->foo();
p->fun();
p = &b;
p->foo();
p->fun();
return 0;
}
第一个p->foo()和p->fuu()都很好理解,本身是基类指针,指向的又是基类对象,调用的都是基类本身的函数,因此输出结果就是1、2。第二个输出结果就是1、4。p->foo()和p->fuu()则是基类指针指向子类对象,正式体现多态的用法,p->foo()由于指针是个基类指针,指向是一个固定偏移量的函数,因此此时指向的就只能是基类的foo()函数的代码了,因此输出的结果还是1。而p->fun()指针是基类指针,指向的fun是一个虚函数,由于每个虚函数都有一个虚函数列表,此时p调用fun()并不是直接调用函数,而是通过虚函数列表找到相应的函数的地址,因此根据指向的对象不同,函数地址也将不同,这里将找到对应的子类的fun()函数的地址,因此输出的结果也会是子类的结果4。 笔试的题目中还有一个另类测试方法。即 B *ptr = (B *)&a; ptr->foo(); ptr->fun(); 问这两调用的输出结果。这是一个用子类的指针去指向一个强制转换为子类地址的基类对象。结果,这两句调用的输出结果是3,2。 并不是很理解这种用法,从原理上来解释,由于B是子类指针,虽然被赋予了基类对象地址,但是ptr->foo()在调用的时候,由于地址偏移量固定,偏移量是子类对象的偏移量,于是即使在指向了一个基类对象的情况下,还是调用到了子类的函数,虽然可能从始到终都没有子类对象的实例化出现。 而ptr->fun()的调用,可能还是因为C++多态性的原因,由于指向的是一个基类对象,通过虚函数列表的引用,找到了基类中fun()函数的地址,因此调用了基类的函数。由此可见多态性的强大,可以适应各种变化,不论指针是基类的还是子类的,都能找到正确的实现方法。 //小结:1、有virtual才可能发生多态现象
// 2、不发生多态(无virtual)调用就按原类型调用
#include<iostream>
using namespace std;
class Base
{
public:
virtual void f(float x)
{
cout<<"Base::f(float)"<< x <<endl;
}
void g(float x)
{
cout<<"Base::g(float)"<< x <<endl;
}
void h(float x)
{
cout<<"Base::h(float)"<< x <<endl;
}
};
class Derived : public Base
{
public:
virtual void f(float x)
{
cout<<"Derived::f(float)"<< x <<endl; //多态
}
void g(int x)
{
cout<<"Derived::g(int)"<< x <<endl; //覆盖
}
void h(float x)
{
cout<<"Derived::h(float)"<< x <<endl; //复制
}
};
int main(void)
{
Derived d;
Base *pb = &d;
Derived *pd = &d;
// Good : behavior depends solely on type of the object
pb->f(3.14f); // Derived::f(float) 3.14
pd->f(3.14f); // Derived::f(float) 3.14
// Bad : behavior depends on type of the pointer
pb->g(3.14f); // Base::g(float) 3.14
pd->g(3.14f); // Derived::g(int) 3
// Bad : behavior depends on type of the pointer
pb->h(3.14f); // Base::h(float) 3.14
pd->h(3.14f); // Derived::h(float) 3.14
return 0;
}
C++纯虚函数一、定义 纯虚函数是在基类中声明的虚函数,它在基类中没有定义,但要求任何派生类都要定义自己的实现方法。在基类中实现纯虚函数的方法是在函数原型后加“=0” virtual void funtion()=0 二、引入原因 1、为了方便使用多态特性,我们常常需要在基类中定义虚拟函数。 2、在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。 为了解决上述问题,引入了纯虚函数的概念,将函数定义为纯虚函数(方法:virtual ReturnType Function()= 0;),则编译器要求在派生类中必须予以重写以实现多态性。同时含有纯虚拟函数的类称为抽象类,它不能生成对象。这样就很好地解决了上述两个问题。 三、相似概念 1、多态性 指相同对象收到不同消息或不同对象收到相同消息时产生不同的实现动作。C++支持两种多态性:编译时多态性,运行时多态性。 a、编译时多态性:通过重载函数实现 b、运行时多态性:通过虚函数实现。 2、虚函数 虚函数是在基类中被声明为virtual,并在派生类中重新定义的成员函数,可实现成员函数的动态覆盖(Override) 3、抽象类 包含纯虚函数的类称为抽象类。由于抽象类包含了没有定义的纯虚函数,所以不能定义抽象类的对象。
作者:Hackbuteer1 发表于2012-4-18 22:45:14 原文链接
阅读:253 评论:2 查看评论
|
||||
| [原]N*N匹马,N个赛道,求出最快N匹马的解法 | ||||
| 入门级:81匹马,9个赛道,不计时,最少要赛几场可以求出最快四匹马? 首先:分为9组分别进行比赛后得到每一组的比赛名次,比赛场次:9; 然后:将9组的每组第一名比赛,得到第一名,肯定是所有马的第一名;比赛场次:1 最后:剩下马中有资格角逐前四名的马有A2、A3、A4、B1、B2、B3、C1、C2、D1,刚好有9匹马,在进行一场比赛就可以了,比赛场次:1 所以最少进行11场比赛。 提高级:问题是这样的:一共有25匹马,有一个赛场,赛场有5个赛道,就是说最多同时可以有5匹马一起比赛。假设每匹马都跑的很稳定,不用任何其他工具,只通过马与马之间的比赛,试问最少 得比多少场才能知道跑得最快的5匹马。 作者:Hackbuteer1 发表于2012-4-20 14:40:08 原文链接
阅读:182 评论:0 查看评论
|
||||
| [原]分治算法求最近点对 | ||||
|
http://acm.hdu.edu.cn/showproblem.php?pid=1007 先说下题意,很简单,给n个点的坐标,求距离最近的一对点之间距离的一半。第一行是一个数n表示有n个点,接下来n行是n个点的x坐标和y坐标,实数。
// 分治算法求最近点对
#include<iostream>
#include<algorithm>
#include<cmath>
using namespace std;
struct point
{
double x , y;
}p[100005];
int a[100005]; //保存筛选的坐标点的索引
int cmpx(const point &a , const point &b)
{
return a.x < b.x;
}
int cmpy(int &a , int &b) //这里用的是下标索引
{
return p[a].y < p[b].y;
}
inline double dis(point &a , point &b)
{
return sqrt( (a.x-b.x)*(a.x-b.x) + (a.y-b.y)*(a.y-b.y));
}
inline double min(double a , double b)
{
return a < b ? a : b;
}
double closest(int low , int high)
{
if(low + 1 == high)
return dis(p[low] , p[high]);
if(low + 2 == high)
return min(dis(p[low] , p[high]) , min( dis(p[low] , p[low+1]) , dis(p[low+1] , p[high]) ));
int mid = (low + high)>>1;
double ans = min( closest(low , mid) , closest(mid + 1 , high) ); //分治法进行递归求解
int i , j , cnt = 0;
for(i = low ; i <= high ; ++i) //把x坐标在p[mid].x-ans~p[mid].x+ans范围内的点取出来
{
if(p[i].x >= p[mid].x - ans && p[i].x <= p[mid].x + ans)
a[cnt++] = i; //保存的是下标索引
}
sort(a , a + cnt , cmpy); //按y坐标进行升序排序
for(i = 0 ; i < cnt ; ++i)
{
for(j = i+1 ; j < cnt ; ++j)
{
if(p[a[j]].y - p[a[i]].y >= ans) //注意下标索引
break;
ans = min(ans , dis(p[a[i]] , p[a[j]]));
}
}
return ans;
}
int main(void)
{
int i,n;
while(scanf("%d",&n) != EOF)
{
if(!n)
break;
for(i = 0 ; i < n ; ++i)
scanf("%lf %lf",&p[i].x,&p[i].y);
sort(p , p + n , cmpx);
printf("%.2lf\n",closest(0 , n - 1)/2);
}
return 0;
}
按照y值进行升序排列后,还可以进一步进行优化的,就是每次选取7个点就OK了,具体原因编程之美上面有介绍的。
for(i = 0 ; i < cnt ; ++i)
{
int k = (i+7) > cnt ? cnt :(i+7); //只要选取出7个点(证明过程没看懂)
for(j = i+1 ; j < k ; ++j)
{
if(p[a[j]].y - p[a[i]].y >= ans) //注意下标索引
break;
ans = min(ans , dis(p[a[i]] , p[a[j]]));
}
}
作者:Hackbuteer1 发表于2012-4-20 17:19:15 原文链接
阅读:212 评论:0 查看评论
|
||||
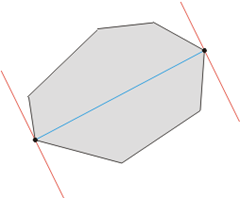
| [原]寻找最远点对 | ||||
| 问题 给定平面上N个点的坐标,找出距离最远的两个点。 分析 类似于“最近点对问题”,这个问题也可以用枚举的方法求解,时间复杂度O(n^2)。 “寻找最近点对”是用到分治策略降低复杂度,而“寻找最远点对”可利用几何性质。注意到:对于平面上有n个点,这一对最远点必然存在于这n个点所构成的一个凸包上(证明略),那么可以排除大量点,如下图所示: 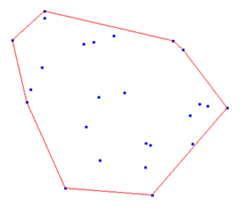 在得到凸包以后,可以只在顶点上面找最远点了。同样,如果不O(n^2)两两枚举,可以想象有两条平行线, “卡”住这个凸包,然后卡紧的情况下旋转一圈,肯定就能找到凸包直径,也就找到了最远的点对。或许这就是为啥叫“旋转卡壳法”。
总结起来,问题解决步骤为:
逆向思考,如果qa,qb是凸包上最远两点,必然可以分别过qa,qb画出一对平行线。通过旋转这对平行线,我们可以让它和凸包上的一条边重合,如图中蓝色直线,可以注意到,qa是凸包上离p和qb所在直线最远的点。于是我们的思路就是枚举凸包上的所有边,对每一条边找出凸包上离该边最远的顶点,计算这个顶点到该边两个端点的距离,并记录最大的值。直观上这是一个O(n2)的算法,和直接枚举任意两个顶点一样了。但是注意到当我们逆时针枚举边的时候,最远点的变化也是逆时针的,这样就可以不用从头计算最远点,而可以紧接着上一次的最远点继续计算,于是我们得到了O(n)的算法。 http://poj.org/problem?id=2187
// 求最远点对
#include<iostream>
#include<algorithm>
using namespace std;
struct point
{
int x , y;
}p[50005];
int top , stack[50005]; // 凸包的点存在于stack[]中
inline double dis(const point &a , const point &b)
{
return (a.x - b.x)*(a.x - b.x)+(a.y - b.y)*(a.y - b.y);
}
inline int max(int a , int b)
{
return a > b ? a : b;
}
inline int xmult(const point &p1 , const point &p2 , const point &p0)
{ //计算叉乘--线段旋转方向和对应的四边形的面积--返回(p1-p0)*(p2-p0)叉积
//if叉积为正--p0p1在p0p2的顺时针方向; if(x==0)共线
return (p1.x-p0.x)*(p2.y-p0.y) - (p1.y-p0.y)*(p2.x-p0.x);
}
int cmp(const void * a , const void * b) //逆时针排序 返回正数要交换
{
struct point *p1 = (struct point *)a;
struct point *p2 = (struct point *)b;
int ans = xmult(*p1 , *p2 , p[0]); //向量叉乘
if(ans < 0) //p0p1线段在p0p2线段的上方,需要交换
return 1;
else if(ans == 0 && ( (*p1).x >= (*p2).x)) //斜率相等时,距离近的点在先
return 1;
else
return -1;
}
void graham(int n) //形成凸包
{
qsort(p+1 , n-1 , sizeof(point) , cmp);
int i;
stack[0] = 0 , stack[1] = 1;
top = 1;
for(i = 2 ; i < n ; ++i)
{
while(top > 0 && xmult( p[stack[top]] , p[i] , p[stack[top-1]]) <= 0)
top--; //顺时针方向--删除栈顶元素
stack[++top] = i; //新元素入栈
}
int temp = top;
for(i = n-2 ; i >= 0 ; --i)
{
while(top > temp && xmult(p[stack[top]] , p[i] , p[stack[top-1]]) <= 0)
top--;
stack[++top] = i; //新元素入栈
}
}
int rotating_calipers() //卡壳
{
int i , q=1;
int ans = 0;
stack[top]=0;
for(i = 0 ; i < top ; i++)
{
while( xmult( p[stack[i+1]] , p[stack[q+1]] , p[stack[i]] ) > xmult( p[stack[i+1]] , p[stack[q]] , p[stack[i]] ) )
q = (q+1)%(top);
ans = max(ans , max( dis(p[stack[i]] , p[stack[q]]) , dis(p[stack[i+1]] , p[stack[q+1]])));
}
return ans;
}
int main(void)
{
int i , n , leftdown;
while(scanf("%d",&n) != EOF)
{
leftdown = 0;
for(i = 0 ; i < n ; ++i)
{
scanf("%d %d",&p[i].x,&p[i].y);
if(p[i].y < p[leftdown].y || (p[i].y == p[leftdown].y && p[i].x < p[leftdown].x)) //找到最左下角的点
leftdown = i;
}
swap(p[0] , p[leftdown]);
graham(n);
printf("%d\n",rotating_calipers());
}
return 0;
}
作者:Hackbuteer1 发表于2012-4-21 17:28:38 原文链接
阅读:196 评论:0 查看评论
|
||||
| [原]随机数范围扩展方法总结 | ||||
| 题目: 已知有个rand7()的函数,返回1到7随机自然数,让利用这个rand7()构造rand10() 随机1~10。 分析:要保证rand10()在整数1-10的均匀分布,可以构造一个1-10*n的均匀分布的随机整数区间(n为任何正整数)。假设x是这个1-10*n区间上的一个随机整数,那么x%10+1就是均匀分布在1-10区间上的整数。由于(rand7()-1)*7+rand7()可以构造出均匀分布在1-49的随机数(原因见下面的说明),可以将41~49这样的随机数剔除掉,得到的数1-40仍然是均匀分布在1-40的,这是因为每个数都可以看成一个独立事件。 下面说明为什么(rand7()-1)*7+rand7()可以构造出均匀分布在1-49的随机数: 首先rand7()-1得到一个离散整数集合{0,1,2,3,4,5,6},其中每个整数的出现概率都是1/7。那么(rand7()-1)*7得到一个离散整数集合A={0,7,14,21,28,35,42},其中每个整数的出现概率也都是1/7。而rand7()得到的集合B={1,2,3,4,5,6,7}中每个整数出现的概率也是1/7。显然集合A和B中任何两个元素组合可以与1-49之间的一个整数一一对应,也就是说1-49之间的任何一个数,可以唯一确定A和B中两个元素的一种组合方式,反过来也成立。由于A和B中元素可以看成是独立事件,根据独立事件的概率公式P(AB)=P(A)P(B),得到每个组合的概率是1/7*1/7=1/49。因此(rand7()-1)*7+rand7()生成的整数均匀分布在1-49之间,每个数的概率都是1/49。 程序:
int rand_10()
{
int x = 0;
do
{
x = 7 * (rand7() - 1) + rand7();
}while(x > 40);
return x % 10 + 1;
}
注:由朋友问为什么用while(x>40)而不用while(x>10)呢?原因是如果用while(x>10)则有40/49的概率需要循环while,很有可能死循环了。问题描述 已知random3()这个随机数产生器生成[1, 3]范围的随机数,请用random3()构造random5()函数,生成[1, 5]的随机数? 问题分析 如何从[1-3]范围的数构造更大范围的数呢?同时满足这个更大范围的数出现概率是相同的,可以想到的运算包括两种:加法和乘法 考虑下面的表达式: 3 * (random3() – 1) + random3(); 可以计算得到上述表达式的范围是[1, 9] 而且数的出现概率是相同的,即1/9 下面考虑如何从[1, 9]范围的数生成[1, 5]的数呢? 可以想到的方法就是 rejection sampling 方法,即生成[1, 9]的随机数,如果数的范围不在[1, 5]内,则重新取样 解决方法
int random5()
{
int val = 0;
do
{
val = 3 * (random3() - 1) + random3();
}while(val > 5);
return val;
}
归纳总结将这个问题进一步抽象,已知random_m()随机数生成器的范围是[1, m] 求random_n()生成[1, n]范围的函数,m < n && n <= m *m 一般解法:
int random_n()
{
int val = 0;
int t; //t为n的最大倍数,且满足t<m*m
do
{
val = m * (random_m() - 1) + random_m();
}while(val > t);
return val;
}
作者:Hackbuteer1 发表于2012-4-22 15:40:08 原文链接
阅读:145 评论:0 查看评论
|
||||
| [原]等概率随机函数的实现 | ||||
|
题目:已知随机函数rand(),以p的概率产生0,以1-p的概率产生1,现在要求设计一个新的随机函数newRand(), 使其以1/n的等概率产生1~n之间的任意一个数。 int Rand()
{
int i1 = rand();
int i2 = rand();
if(i1==0 && i2==1)
return 1;
else if(i1==1 && i2==0)
return 0;
else
return Rand();
return -1;
}
第二步:计算整数n的二进制表示所拥有的位数k,k = 1 +log2n(log以2为底n)第三步:调用k次Rand()产生随机数。
int newRand()
{
int result = 0;
for(int i = 0 ; i < k ; ++i)
{
if(Rand() == 1)
result |= (1<<i);
}
if(result > n)
return newRand();
return result;
}
题目:
int rand7()
{
int x = 0;
do
{
x = 5 * (rand5() - 1) + rand5();
}while(x > 21);
return 1 + x%7;
}
我的备注:这种思想是基于,rand()产生[0,N-1],把rand()视为N进制的一位数产生器,那么可以使用rand()*N+rand()来产生2位的N进制数,以此类推,可以产生3位,4位,5位...的N进制数。这种按构造N进制数的方式生成的随机数,必定能保证随机,而相反,借助其他方式来使用rand()产生随机数(如 rand5() + rand()%3 )都是不能保证概率平均的。 此题中N为5,因此可以使用rand5()*5+rand5()来产生2位的5进制数,范围就是1到25。再去掉22-25,剩余的除3,以此作为rand7()的产生器。 给定一个函数rand()能产生0到n-1之间的等概率随机数,问如何产生0到m-1之间等概率的随机数? int random(int m , int n)
{
int k = rand();
int max = n-1;
while(k < m)
{
k = k*n + rand();
max = max*n + n-1;
}
return k/(max/n);
}
如何产生如下概率的随机数?0出1次,1出现2次,2出现3次,n-1出现n次?
int random(int size)
{
while(true)
{
int m = rand(size);
int n = rand(size);
if(m + n < size)
return m+n;
}
}
作者:Hackbuteer1 发表于2012-4-22 15:55:31 原文链接
阅读:191 评论:1 查看评论
|
||||
| [原]Google面试题——及答案 | ||||
1、 村子里有100对夫妻,其中每个丈夫都瞒着自己的妻子偷情。。。村里的每个妻子都能立即发现除自己丈夫之外的其他男人是否偷情,唯独不知道她自己的丈夫到底有没有偷情。村里的规矩不容忍通奸。任何一个妻子,一旦能证明自己的男人偷情,就必须当天把他杀死。村里的女人全都严格照此规矩办事。一天,女头领出来宣布,村里至少有一个丈夫偷情。请问接下来会发生什么事? 答案:这是一个典型的递归问题。一旦所有的妻子都知道至少有一个男人出轨,我们就可以按递归方式来看待这个流程。先让我们假设只有一个丈夫偷情。则他的妻子见不到任何偷情的男人,因此知道这个人就是自己丈夫,她当天就会杀了他。假如有两个丈夫偷情,则他俩的妻子只知道不是自己丈夫的那一个男人偷情。因此她会等上一天看那个人有没有被杀死。假如第一天没人被杀死,她就能确定她自己的丈夫也偷了情。依此类推,假如有100个丈夫偷情,则他们能安全活上99天,直到100天时,所有妻子把他们全都杀死。 应聘职位:产品经理 2、假设在一段高速公路上,30分钟之内见到汽车经过的概率是0.95。那么,在10分钟内见到汽车经过的概率是多少?(假设缺省概率固定) 答案:这题的关键在于0.95是见到一辆或多辆汽车的概率,而不是仅见到一辆汽车的概率。在30分钟内,见不到任何车辆的概率为0.05。因此在10分钟内见不到任何车辆的概率是这个值的立方根,而在10分钟内见到一辆车的概率则为1减去此立方根,也就是大约63%。 应聘职位:产品经理  答案:7.5度。时钟上每一分钟是6度(360度/60分钟)。时针每小时从一个数字走到下一个数字(此例中为从3点到4点),也就是30度。因为此题中时间刚好走过1/4小时,因此时针走完30度的1/4,也就是7.5度。 应聘职位:产品经理 6、将一根木条折成3段之后,可以形成一个三角形的概率有多大?  答案:因为题目中没有说要求木条必须首尾相连的做成三角形,因此答案是100%。任何长度的三根木条都可以形成一个三角形。 应聘职位:产品经理 7、南非有个延时问题。请对其加以分析。  答案:这显然是个非常模糊的问题,因此没有唯一的正确答案。比较好的回答应该是由被面试者展示自己对“延时”概念的熟悉程度以及发挥自己的想象力,构想出一个有趣的延时问题并对其提供一个有趣的解决方案。 应聘职位:产品经理 8、在一个两维平面上有三个不在一条直线上的点。请问能够作出几条与这些点距离相同的线? 作者:Hackbuteer1 发表于2012-4-22 16:27:06 原文链接
阅读:342 评论:0 查看评论
|
||||
| [原]C++中的static关键字 | ||||
| C++的static有两种用法:面向过程程序设计中的static和面向对象程序设计中的static。前者应用于普通变量和函数,不涉及类;后者主要说明static在类中的作用。 一、面向过程设计中的static 1、静态全局变量 在全局变量前,加上关键字static,该变量就被定义成为一个静态全局变量。我们先举一个静态全局变量的例子,如下:
#include<iostream>
using namespace std;
static int n; //定义静态全局变量
void fn()
{
n++;
cout<<n<<endl;
}
int main(void)
{
n = 20;
cout<<n<<endl;
fn();
return 0;
}
静态全局变量有以下特点:
一般程序的由new产生的动态数据存放在堆区,函数内部的自动变量存放在栈区。自动变量一般会随着函数的退出而释放空间,静态数据(即使是函数内部的静态局部变量)也存放在全局数据区。全局数据区的数据并不会因为函数的退出而释放空间。细心的读者可能会发现,Example 1中的代码中将
static int n; //定义静态全局变量改为
int n; //定义全局变量程序照样正常运行。 的确,定义全局变量就可以实现变量在文件中的共享,但定义静态全局变量还有以下好处: 静态全局变量不能被其它文件所用; 其它文件中可以定义相同名字的变量,不会发生冲突; 您可以将上述示例代码改为如下: //File1
#include<iostream>
using namespace std;
void fn();
static int n; //定义静态全局变量
int main(void)
{
n = 20;
cout<<n<<endl;
fn();
return 0;
}
//File2
#include<iostream>
using namespace std;
extern int n;
void fn()
{
n++;
cout<<n<<endl;
}
编译并运行这个程序,您就会发现上述代码可以分别通过编译,但运行时出现错误。试着将
static int n; //定义静态全局变量改为
int n; //定义全局变量再次编译运行程序,细心体会全局变量和静态全局变量的区别。 2、静态局部变量 在局部变量前,加上关键字static,该变量就被定义成为一个静态局部变量。 我们先举一个静态局部变量的例子,如下: #include<iostream>
using namespace std;
void fn();
int main(void)
{
fn();
fn();
fn();
return 0;
}
void fn()
{
static int n = 10;
cout<<n<<endl;
n++;
}
通常,在函数体内定义了一个变量,每当程序运行到该语句时都会给该局部变量分配栈内存。但随着程序退出函数体,系统就会收回栈内存,局部变量也相应失效。但有时候我们需要在两次调用之间对变量的值进行保存。通常的想法是定义一个全局变量来实现。但这样一来,变量已经不再属于函数本身了,不再仅受函数的控制,给程序的维护带来不便。 静态局部变量正好可以解决这个问题。静态局部变量保存在全局数据区,而不是保存在栈中,每次的值保持到下一次调用,直到下次赋新值。 静态局部变量有以下特点: 该变量在全局数据区分配内存; 静态局部变量在程序执行到该对象的声明处时被首次初始化,即以后的函数调用不再进行初始化; 静态局部变量一般在声明处初始化,如果没有显式初始化,会被程序自动初始化为0; 它始终驻留在全局数据区,直到程序运行结束。但其作用域为局部作用域,当定义它的函数或语句块结束时,其作用域随之结束; 3、静态函数 在函数的返回类型前加上static关键字,函数即被定义为静态函数。静态函数与普通函数不同,它只能在声明它的文件当中可见,不能被其它文件使用。 静态函数的例子: #include<iostream>
using namespace std;
static void fn(); //声明静态函数
int main(void)
{
fn();
return 0;
}
void fn() //定义静态函数
{
int n = 10;
cout<<n<<endl;
}
定义静态函数的好处:静态函数不能被其它文件所用; 其它文件中可以定义相同名字的函数,不会发生冲突; 二、面向对象的static关键字(类中的static关键字) 1、静态数据成员 在类内数据成员的声明前加上关键字static,该数据成员就是类内的静态数据成员。先举一个静态数据成员的例子。 #include<iostream>
using namespace std;
class Myclass
{
private:
int a , b , c;
static int sum; //声明静态数据成员
public:
Myclass(int a , int b , int c);
void GetSum();
};
int Myclass::sum = 0; //定义并初始化静态数据成员
Myclass::Myclass(int a , int b , int c)
{
this->a = a;
this->b = b;
this->c = c;
sum += a+b+c;
}
void Myclass::GetSum()
{
cout<<"sum="<<sum<<endl;
}
int main(void)
{
Myclass M(1 , 2 , 3);
M.GetSum();
Myclass N(4 , 5 , 6);
N.GetSum();
M.GetSum();
return 0;
}
可以看出,静态数据成员有以下特点:
与静态数据成员一样,我们也可以创建一个静态成员函数,它为类的全部服务而不是为某一个类的具体对象服务。静态成员函数与静态数据成员一样,都是类的内部实现,属于类定义的一部分。普通的成员函数一般都隐含了一个this指针,this指针指向类的对象本身,因为普通成员函数总是具体的属于某个类的具体对象的。通常情况下,this是缺省的。如函数fn()实际上是this->fn()。但是与普通函数相比,静态成员函数由于不是与任何的对象相联系,因此它不具有this指针。从这个意义上讲,它无法访问属于类对象的非静态数据成员,也无法访问非静态成员函数,它只能调用其余的静态成员函数。下面举个静态成员函数的例子。
#include<iostream>
using namespace std;
class Myclass
{
private:
int a , b , c;
static int sum; //声明静态数据成员
public:
Myclass(int a , int b , int c);
static void GetSum(); //声明静态成员函数
};
int Myclass::sum = 0; //定义并初始化静态数据成员
Myclass::Myclass(int a , int b , int c)
{
this->a = a;
this->b = b;
this->c = c;
sum += a+b+c; //非静态成员函数可以访问静态数据成员
}
void Myclass::GetSum() //静态成员函数的实现
{
//cout<<a<<endl; //错误代码,a是非静态数据成员
cout<<"sum="<<sum<<endl;
}
int main(void)
{
Myclass M(1 , 2 , 3);
M.GetSum();
Myclass N(4 , 5 , 6);
N.GetSum();
Myclass::GetSum();
return 0;
}
关于静态成员函数,可以总结为以下几点:
作者:Hackbuteer1 发表于2012-4-22 22:06:46 原文链接
阅读:302 评论:0 查看评论
|
||||
| [原]百度2012实习生校园招聘笔试题 | ||||
| 1、给一个单词a,如果通过交换单词中字母的顺序可以得到另外的单词b,那么b是a的兄弟单词,比如的单词army和mary互为兄弟单词。 现在要给出一种解决方案,对于用户输入的单词,根据给定的字典找出输入单词有哪些兄弟单词。请具体说明数据结构和查询流程,要求时间和空间效率尽可能地高。 字典树的典型应用 2、系统中维护了若干数据项,我们对数据项的分类可以分为三级,首先我们按照一级分类方法将数据项分为A、B、C......若干类别,每个一级分类方法产生的类别又可以按照二级分类方法分为a、b、c......若干子类别,同样,二级分类方法产生的类别又可以按照是三级分类方法分为i、ii、iii......若干子类别,每个三级分类方法产生的子类别中的数据项从1开始编号。我们需要对每个数据项输出日志,日志的形式是key_value对,写入日志的时候,用户提供三级类别名称、数据项编号和日志的key,共五个key值,例如,write_log(A,a,i,1,key1),获取日志的时候,用户提供三级类别名称、数据项编号,共四个key值,返回对应的所有的key_value对,例如get_log(A,a,i,1,key1), 请描述一种数据结构来存储这些日志,并计算出写入日志和读出日志的时间复杂度。 3、C和C++中如何动态分配和释放内存?他们的区别是什么? malloc/free和new/delete的区别 4、数组al[0,mid-1]和al[mid,num-1]是各自有序的,对数组al[0,num-1]的两个子有序段进行merge,得到al[0,num-1]整体有序。要求空间复杂度为O(1)。注:al[i]元素是支持'<'运算符的。
/*
数组a[begin, mid] 和 a[mid+1, end]是各自有序的,对两个子段进行Merge得到a[begin , end]的有序数组。 要求空间复杂度为O(1)
方案:
1、两个有序段位A和B,A在前,B紧接在A后面,找到A的第一个大于B[0]的数A[i], A[0...i-1]相当于merge后的有效段,在B中找到第一个大于A[i]的数B[j],
对数组A[i...j-1]循环右移j-k位,使A[i...j-1]数组的前面部分有序
2、如此循环merge
3、循环右移通过先子段反转再整体反转的方式进行,复杂度是O(L), L是需要循环移动的子段的长度
*/
#include<iostream>
using namespace std;
void Reverse(int *a , int begin , int end ) //反转
{
for(; begin < end; begin++ , end--)
swap(a[begin] , a[end]);
}
void RotateRight(int *a , int begin , int end , int k) //循环右移
{
int len = end - begin + 1; //数组的长度
k %= len;
Reverse(a , begin , end - k);
Reverse(a , end - k + 1 , end);
Reverse(a , begin , end);
}
// 将有序数组a[begin...mid] 和 a[mid+1...end] 进行归并排序
void Merge(int *a , int begin , int end )
{
int i , j , k;
i = begin;
j = 1 + ((begin + end)>>1); //位运算的优先级比较低,外面需要加一个括号,刚开始忘记添加括号,导致错了很多次
while(i <= end && j <= end && i<j)
{
while(i <= end && a[i] < a[j])
i++;
k = j; //暂时保存指针j的位置
while(j <= end && a[j] < a[i])
j++;
if(j > k)
RotateRight(a , i , j-1 , j-k); //数组a[i...j-1]循环右移j-k次
i += (j-k+1); //第一个指针往后移动,因为循环右移后,数组a[i....i+j-k]是有序的
}
}
void MergeSort(int *a , int begin , int end )
{
if(begin == end)
return ;
int mid = (begin + end)>>1;
MergeSort(a , begin , mid); //递归地将a[begin...mid] 归并为有序的数组
MergeSort(a , mid+1 , end); //递归地将a[mid+1...end] 归并为有序的数组
Merge(a , begin , end); //将有序数组a[begin...mid] 和 a[mid+1...end] 进行归并排序
}
int main(void)
{
int n , i , a[20];
while(cin>>n)
{
for(i = 0 ; i < n ; ++i)
cin>>a[i];
MergeSort(a , 0 , n - 1);
for(i = 0 ; i < n ; ++i)
cout<<a[i]<<" ";
cout<<endl;
}
return 0;
}
5、线程和进程的区别及联系?如何理解“线程安全”问题?答案:进程和线程都是由操作系统所体会的程序运行的基本单元,系统利用该基本单元实现系统对应用的并发性。 1、简而言之,一个程序至少有一个进程,一个进程至少有一个线程. 2、线程的划分尺度小于进程,使得多线程程序的并发性高。 3、另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。 4、线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。 5、从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。 算法与程序设计一、 网页爬虫在抓取网页时,从指定的URL站点入口开始爬取这个站点上的所有URL link,抓取到下一级link对应的页面后,同样对页面上的link进行抓取从而完成深度遍历。为简化问题,我们假设每个页面上至多只有一个link,如从www.baidu.com/a.html链接到 www.baidu.com/b.html再链到www.baidu.com/x.html,当爬虫抓取到某个页面时,有可能再链回www.baidu.com/b.html,也有可能爬取到一个不带任何link的终极页面。当抓取到相同的URL或不包含任何link的终极页面时即完成爬取。爬虫在抓取到这些页面后建立一个单向链表,用来记录抓取到的页面,如:a.html->b.html->x.html...->NULL。 问:对于爬虫分别从www.baidu.com/x1.html和www.baidu.com/x2.html两个入口开始获得两个单向链表,得到这两个单向链表后,如何判断他们是否抓取到了相同的URL?(假设页面URL上百亿,存储资源有限,无法用hash方法判断是否包含相同的URL) 请先描述相应的算法,再给出相应的代码实现。(只需给出判断方法代码,无需爬虫代码) 两个单向链表的相交问题。 算法与程序设计二、 4、有一种结构如下图所示,它由层的嵌套组成,一个父层中只能包含垂直方向上或者是水平方向上并列的层,例如,层1可以包含2、3、4三个垂直方向上的层,层2可以包含5和6两个水平方向的层,在空层中可以包含数据节点,所谓的空层是指不包含子层的层,每个空层可以包含若干个数据节点,也可以一个都不包含。 在这种结构上面,我们从垂直方向上划一条线,我们约定每一个子层中我们只能经过一个数据节点,在这种情况下,每条线可以经过多个数据节点,也可以不经过任何数据节点,例如,线1经过了3、5、8三个数据节点,线2只经过了14个数据节点。 (1)给出函数,实现判断两个数据节点,是否可能同时被线划中,给出具体的代码。 (2)给出函数,输出所有一条线可以划中的数据节点序列, 可以给出伪代码实现。 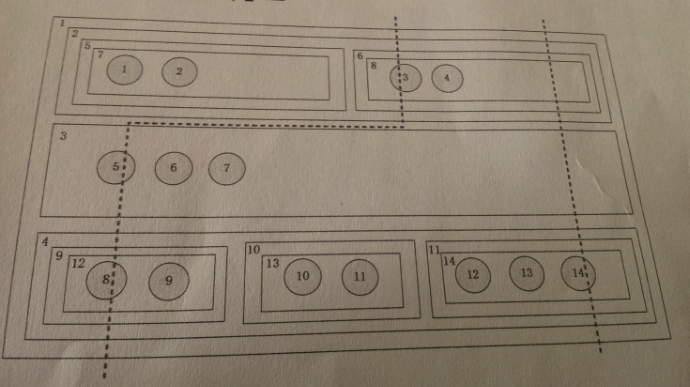
思路:(1)判断两个数所属的同一层次的相同矩形框的下一层次矩形框是水平排列的还是垂直排列的,垂直排列在能在一条线上,水平排列则不能。 (2)用回溯算法求出所有在一条直线上的字符串,用两字符串是否在同一直线上进行剪枝操作。 系统设计题 1、相信大家都使用过百度搜索框的suggestion功能,百度搜索框中的suggestion提示功能如何实现?请给出实现思路和主要的数据结构、算法。有什么优化思路可以使得时间和空间效率最高? 应用字典树来求前缀和TOP K对热词进行统计排序 2、两个200G大小的文件A和B,AB文件里内容均为无序的一行一个正整数字(不超过2^63),请设计方案,输出两个文件中均出现过的数字,使用一台内存不超过16G、磁盘充足的机器。 方案中指明使用java编程时使用到的关键工具类,以及为什么? 作者:Hackbuteer1 发表于2012-5-7 16:21:53 原文链接
阅读:592 评论:6 查看评论
|











==============================================================================
本博客已经废弃,不在维护。新博客地址:http://wenchao.ren
我喜欢程序员,他们单纯、固执、容易体会到成就感;面对压力,能够挑灯夜战不眠不休;面对困难,能够迎难而上挑战自我。他
们也会感到困惑与傍徨,但每个程序员的心中都有一个比尔盖茨或是乔布斯的梦想“用智慧开创属于自己的事业”。我想说的是,其
实我是一个程序员
==============================================================================


 浙公网安备 33010602011771号
浙公网安备 33010602011771号