

Uipath 调用python
Uipath调用python可以有两种方法:
1.可以安装官方的包来调用python
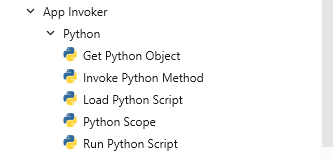
2. 直接运行cmd命令行,或powershell命令来触发python脚本文件
使用官方activity时,外层用python scope,配置如下:
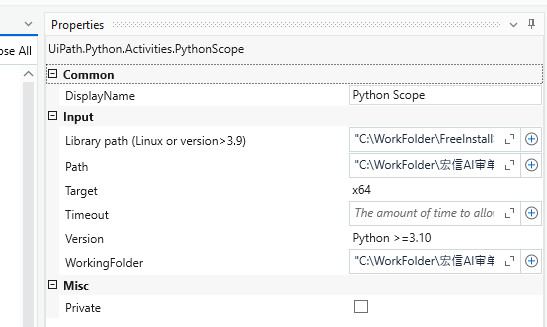
Library Path:配置主环境而不是虚拟环境里的dll文件,举例: "C:\WorkFolder\FreeInstallSoftware\Python\Python313\python313.dll"
Path: 是python.exe所在的目录,如果是虚拟环境,可以是"C:\WorkFolder\宏信AI审单\RPA\transfer_data_to_bdh.venv"
WorkingFolder: 表示python运行的当前目录,相当于import os os.getcwd()里看到的目录。 通常如果做一些文件操作使用相对路径时会受到这个属性的影响,模块导入可能也会受到影响。举例:"C:\WorkFolder\宏信AI审单\RPA\transfer_data_to_bdh"
使用官方组件时,一般是外层用一个Python Scope,内层套一个Load Python Script来导入python代码文件。 一般在代码文件里定义一些函数, 然后再用Invoke Python Method组件调用这些函数,返回的结果使用Get Python Object转换成.net支持的数据类型。
但是即便以上属性都配置正确了,仍然会经常报 Load Python Script: One or more errors occurred. (Error loading Python script) 错误。
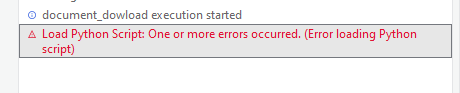
原因可能是这种方式对虚拟环境的支持不好,一旦用到了虚拟环境里安装的第三方包就可能出问题。
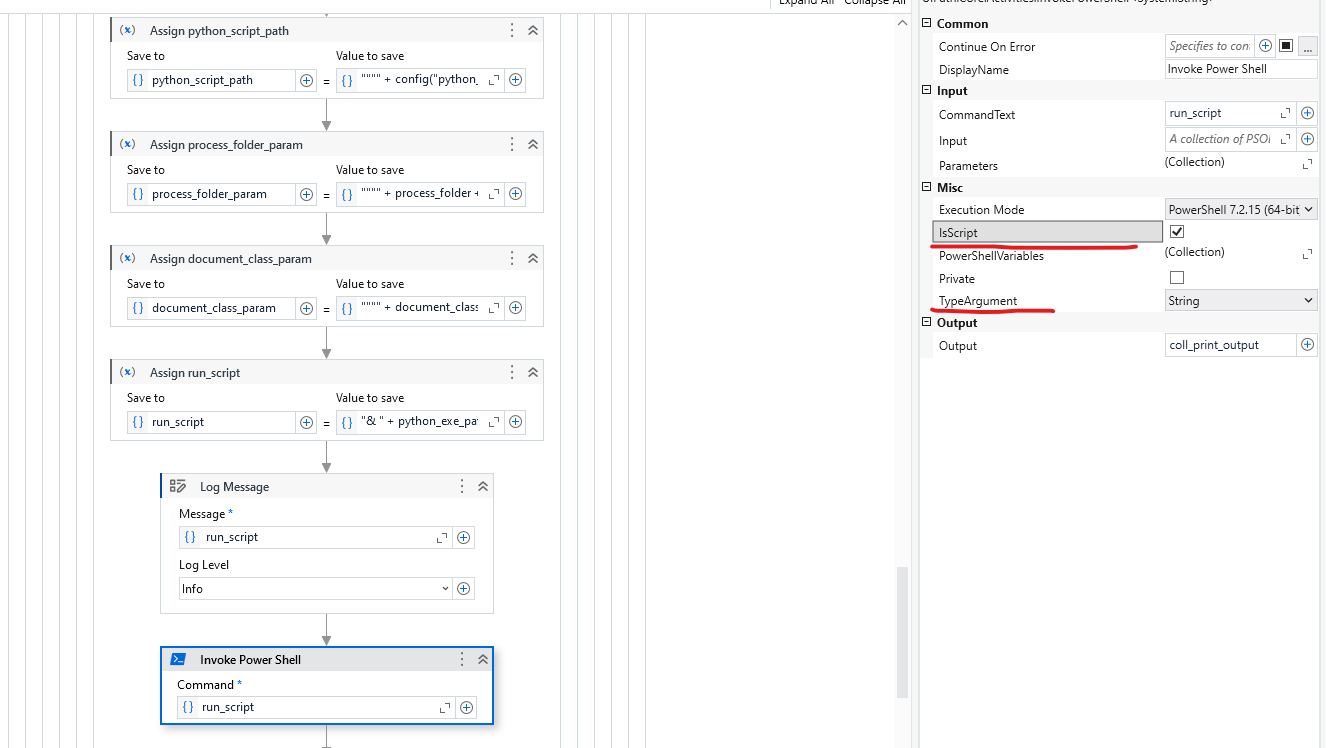
最稳妥的办法还是在uipath中调用powershell,让python脚本在powershell中执行。
注意,属性里将IsScript选中,TypeArgument选择string,接收的Output参数将是一个collection(string),里面是python script里使用print函数输出的内容。就类似于我们在命令行执行python脚本时看到的东西。
放在命令行中运行的脚本如下面示例,涉及到路径的都用双引号包裹起来。python脚本中使用argparse模块来解析传入的参数。
& "C:\WorkFolder\宏信AI审单\RPA\transfer_data_to_bdh\.venv\Scripts\python.exe" "C:\WorkFolder\宏信AI审单\RPA\transfer_data_to_bdh\main.py" -p "C:\WorkFolder\宏信AI审单\RPA\files\20251604_151650" -c "公司费用报账单"
if __name__ == '__main__':
import argparse
argp = argparse.ArgumentParser()
argp.add_argument("--process_folder", "-p", help="process folder", required=True)
argp.add_argument("--document_class", "-c", help="document class", required=True)
args = argp.parse_args()
print(args.process_folder)
print(args.document_class)
upload_documents_byclass(args.process_folder, args.document_class)
write range workbook与pandas to_excel兼容性问题
UiPath的write range workbook在回写pandas to_excel方法回写过的excel时,会报错:
Write Range Workbook: Error in implicit conversion. Cannot convert null object.
在使用pandas的dataframe.to_excel方法保存或生成的excel数据后,表面看起来excel文件都很正常,uipath使用read range workbook读取后看datatable里的列名,列类型,数据都正常, 但就是在使用write range workbook再回写到原excel文件时就会报错。

现象:
-
在uipath中,循环打印所有列的类型,显示都是System.Object,但这其实是正常的。
write line组件输出 "列名: " + currentDataColumn.ColumnName + ", 列类型: " + currentDataColumn.DataType.ToString -
循环所有行,打印数据值的真实类型,都是System.String, 这就更没问题了。
write line组件输出 "列名: " + currentDataColumn.ColumnName + ", 列值:" + CurrentRow(currentDataColumn).ToString + ",实际值类型:" + CurrentRow(currentDataColumn).GetType.ToString -
write range workbook如果回写到一个不存在的excel文件(相当于自动创建),则不会出错。 只是在回写到由pandas to_excel方法回写过的文件才出错。 如果excel文件是由write range workbook回写,那么使用read range workbook读取,再用write range workbook回写,则也不会出错。
-
如果使用uipath的excel application scope里的write datatable to excel组件,则不会出错,但之所以不想用这个组件,一个是性能差,另一个是总把日期字符串搞成时间类型,再读取的时候字符串格式就可能变
-
报错情况使用pandas回写excel时是用的默认引擎openpyxl,尝试在回写前使用df.fillna("")和df.astype(str)都无效。 而换成xlxswriter引擎的话,uipath虽然使用write range workbook不报错了,但是因为pandas把空单元格都回写成了"nan",uipath在读取excel时没有空值了,所以回写时就也不报错了。 并且,在使用xlsxwriter引擎的时候,尝试df.fillna("")和df.astype(str)都无法改变回写空行列值时是"nan"的情况。
总结,pandas的to_excel在回写excel时,肯定对于空值的处理跟uipath的read range workbook以及wirte range workbook有不同的处理方式,可以理解为不兼容, 但却无法显示出来这种差异,因为在uipath中打印datable的行,列,值,数据类型等都无法看出有任何问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号