
Android 4.4 Init进程分析三:init.rc脚本文件的解析
****************************************************************************
Android 4.4 init进程分析文章链接
Android 4.4 Init进程分析一 :Android init进程概述
Android 4.4 Init进程分析二 :Android初始化语言
Android 4.4 Init进程分析三:init.rc脚本文件的解析
Android 4.4 Init进程分析四 :init.rc脚本文件的执行
Android 4.4 Init进程分析五 :进程的终止与再启动
***************************************************************************
1 概述
Android启动后,在Init进程中分析init.rc启动脚本文件,并根据相关文件中包含的内容,执行相应的功能。比如设置系统环境变量、记录待执行的进程。
此外,系统中还存在着init.${ro.hardware}.rc等文件,其作用类似于init.rc文件,init进程按照init.rc的处理方式处理init.${ro.hardware}.rc文件。
init.rc文件解析完后会得到action list 和 service list两个链表,记录需要执行的动作或服务。
接下来我们就通过源码来看具体的解析过程。
2 init.rc文件的解析过程
国际惯例,我们先看一下源码:
2.1 init main中开始
init是一个可执行档,所以启动时会先从main()函数开始执行,如下代码中开始对.rc文件的解析
http://androidxref.com/4.4_r1/xref/system/core/init/init.c#1039
1 init_parse_config_file("/init.rc");
在init进程的main()函数里,会调用init_parse_config_file()方法解析init.rc脚本,注意这里传递的参数是根目录下的 "/init.rc"文件路径。
2.2 init_parse_config_file()函数
init_parse_config_file()方法定义如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#404
1 int init_parse_config_file(const char *fn) 2 { 3 char *data; 4 data = read_file(fn, 0); //读取/init.rc文件内容到内存,并返回起始地址存入data 5 if (!data) return -1; 6 7 parse_config(fn, data); //解析读入的字符内容 8 DUMP(); 9 return 0; 10 }
read_file()方法的定义非常简单,作用就是把指定的文件以字符的形式读入到内存中,并返回起始地址及读入的数据大小。
其源码如下:
http://androidxref.com/4.4_r1/xref/system/core/init/util.c#142


1 /* reads a file, making sure it is terminated with \n \0 */ 2 3 //该方法接收两个参数: 4 // fn: 要读取的文件路径 5 // _sz:unsigned int类型的指针,用于返回读入的字符个数 6 // 该方法返回读取的字符内容的起始地址,如果读取失败则返回 0 7 8 void *read_file(const char *fn, unsigned *_sz) 9 { 10 char *data; 11 int sz; 12 int fd; 13 struct stat sb; 14 15 data = 0; 16 fd = open(fn, O_RDONLY); //以只读的方式打开文件 17 if(fd < 0) return 0; 18 19 // for security reasons, disallow world-writable 20 // or group-writable files 21 if (fstat(fd, &sb) < 0) { 22 ERROR("fstat failed for '%s'\n", fn); 23 goto oops; 24 } 25 if ((sb.st_mode & (S_IWGRP | S_IWOTH)) != 0) { 26 ERROR("skipping insecure file '%s'\n", fn); 27 goto oops; 28 } 29 30 sz = lseek(fd, 0, SEEK_END); // 获取文件长度,有多少个字节 31 if(sz < 0) goto oops; 32 33 if(lseek(fd, 0, SEEK_SET) != 0) goto oops; // 定位到文件开头 34 35 data = (char*) malloc(sz + 2); //分配存储空间 36 if(data == 0) goto oops; 37 38 if(read(fd, data, sz) != sz) goto oops; // 读取文件内容 39 close(fd); // 关闭文件 40 data[sz] = '\n'; // 设置结尾字符 41 data[sz+1] = 0; 42 if(_sz) *_sz = sz; 43 return data; 44 45 oops: 46 close(fd); 47 if(data != 0) free(data); 48 return 0; 49 }
将文件的内容读入内存后,接下来就可以进行解析了,调用parse_config()方法来解析init.rc的内容。
2.3 parse_config()函数
parser_config函数接收已经读入的字符串数据开始解析
2.3.1 parse_state 结构体
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#347
在分析parse_config()方法前,我们先看一下parse_state 结构体的定义:
1 struct parse_state 2 { 3 char *ptr; // 待解析的字符数组的地址 4 char *text; 5 int line; 6 int nexttoken; 7 void *context; 8 void (*parse_line)(struct parse_state *state, int nargs, char **args);// 解析后续行的解析函数,parse_line_service() or parse_line_action() 9 const char *filename; // 待解析的文件名 10 void *priv; 11 };
结构体parse_state用于记录解析状态,包括:
> 待解析字符数组的起始地址:ptr
> 已解析的行数:line
> 待解析的文件的名字:filename
> 解析后续行的解析函数:parse_line
> 下一个标记的类型:nexttoken
> 解析出的string token的起始地址:text
2.3.2 parse_config()方法
parse_config()方法截取部分关键代码如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#347
1 static void parse_config(const char *fn, char *s) 2 { 3 struct parse_state state; 4 struct listnode import_list; 5 struct listnode *node; 6 char *args[INIT_PARSER_MAXARGS]; 7 int nargs; 8 9 nargs = 0; 10 state.filename = fn; 11 state.line = 0; 12 state.ptr = s; 13 state.nexttoken = 0; 14 state.parse_line = parse_line_no_op; 15 16 list_init(&import_list); 17 state.priv = &import_list; 18 19 for (;;) { 20 switch (next_token(&state)) { 21 case T_EOF: // 解析到文件尾,结束 22 state.parse_line(&state, 0, 0); 23 goto parser_done; 24 case T_NEWLINE: // 新的一行 25 state.line++; 26 if (nargs) { 27 int kw = lookup_keyword(args[0]); // 判断每行首个单词的类型 28 if (kw_is(kw, SECTION)) { 29 state.parse_line(&state, 0, 0); 30 parse_new_section(&state, kw, nargs, args); 31 } else { 32 state.parse_line(&state, nargs, args); 33 } 34 nargs = 0; 35 } 36 break; 37 case T_TEXT: // 一行中分割出新的 单词(string) 38 if (nargs < INIT_PARSER_MAXARGS) { 39 args[nargs++] = state.text; 40 } 41 break; 42 } 43 } 44 45 parser_done: 46 list_for_each(node, &import_list) { 47 struct import *import = node_to_item(node, struct import, list); 48 int ret; 49 50 INFO("importing '%s'", import->filename); 51 ret = init_parse_config_file(import->filename); // 继续解析import进来的其他.rc文件 52 if (ret) 53 ERROR("could not import file '%s' from '%s'\n", 54 import->filename, fn); 55 } 56 }
几点说明:
该函数逐行分析init.rc脚本,判断每一行的第一个参数是什么类型的。
如果是action或service类型的,就表示要创建一个新的section节点了
如果是section节点,此时它会设置一下解析后续行的解析函数,也就是给state->parse_line赋值。
针对service类型,解析后续行的函数是parse_line_service()。
针对action类型,解析后续行的函数则是parse_line_action()。
2.3.3 next_token()函数
首先next_token()函数是以行为单位分割参数传递过来的字符串,而后调用lookup_keyword()函数,next_token()代码如下:
http://androidxref.com/4.4_r1/xref/system/core/init/parser.c#68
1 int next_token(struct parse_state *state) 2 { 3 char *x = state->ptr; // 字符数组起始地址 4 char *s; 5 6 if (state->nexttoken) { 7 int t = state->nexttoken; 8 state->nexttoken = 0; 9 return t; 10 } 11 12 for (;;) { 13 switch (*x) { 14 case 0: // 0: 表示解析到了字符数组尾(文件尾),返回EOF标记 15 state->ptr = x; 16 return T_EOF; 17 case '\n': // '\n': 表示遇到新的一行 18 x++; 19 state->ptr = x; 20 return T_NEWLINE; 21 case ' ': 22 case '\t': 23 case '\r': 24 x++; //' '、'\t'、'\r': 表示该行未结束,继续解析下一个字符 25 continue; 26 case '#': // '#': 表示遇到注释行,继续查找新的一行 27 while (*x && (*x != '\n')) x++; 28 if (*x == '\n') { 29 state->ptr = x+1; 30 return T_NEWLINE; 31 } else { 32 state->ptr = x; 33 return T_EOF; 34 } 35 default: // 其他字符: 跳转到text标记, 36 goto text; 37 } 38 } 39 40 textdone: // 解析到一个完整的string token,可以看多一个单词 41 state->ptr = x; 42 *s = 0; 43 return T_TEXT; 44 text: 45 state->text = s = x; // 记录这个text的起始地址 46 textresume: 47 for (;;) { 48 switch (*x) { 49 case 0: 50 goto textdone; 51 case ' ': 52 case '\t': 53 case '\r': 54 x++; 55 goto textdone; 56 case '\n': 57 state->nexttoken = T_NEWLINE; 58 x++; 59 goto textdone; 60 case '"': // 双引号内的字符作为一个string token 61 x++; 62 for (;;) { 63 switch (*x) { 64 case 0: 65 /* unterminated quoted thing */ 66 state->ptr = x; 67 return T_EOF; 68 case '"': 69 x++; 70 goto textresume; 71 default: 72 *s++ = *x++; 73 } 74 } 75 break; 76 case '\\': 77 x++; 78 switch (*x) { 79 case 0: 80 goto textdone; 81 case 'n': 82 *s++ = '\n'; 83 break; 84 case 'r': 85 *s++ = '\r'; 86 break; 87 case 't': 88 *s++ = '\t'; 89 break; 90 case '\\': 91 *s++ = '\\'; 92 break; 93 case '\r': 94 /* \ <cr> <lf> -> line continuation */ 95 if (x[1] != '\n') { 96 x++; 97 continue; 98 } 99 case '\n': 100 /* \ <lf> -> line continuation */ 101 state->line++; 102 x++; 103 /* eat any extra whitespace */ 104 while((*x == ' ') || (*x == '\t')) x++; 105 continue; 106 default: 107 /* unknown escape -- just copy */ 108 *s++ = *x++; 109 } 110 continue; 111 default: 112 *s++ = *x++; 113 } 114 } 115 return T_EOF; 116 }
分析:
// 第一个for循环的作用主要是查找新的一行或到达文件尾或一个单词的起始
// 第二个for循环主要是对一行中的字符串以空格、'\r'、'\t'进行分割
例如:init.rc文件中 “service console /system/bin/sh” 这样一行字符串就会被分割为三个部分:
第一部分:“service”
第二部分:“console”
第三部分:“/system/bin/sh”
这三部分被存储在 parse_config()方法中定义的 args 字符数组中,同时nargs=3,即该行解析出3个单词:
1 args[0] = "service" 2 args[1] = "console" 3 args[2] = "/system/bin/sh" 4 nargs = 3
经过上面next_token()的解析,我们已经找到了一行并且分割出了若干个单词,存到了args中,接下下就是调用lookup_keyword(args[0])来判断每行首个单词的类型了。
2.3.4 lookup_keyword()函数
先看lookup_keyword()函数的源码:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#79
1 int lookup_keyword(const char *s) 2 { 3 switch (*s++) { 4 case 'c': 5 if (!strcmp(s, "opy")) return K_copy; 6 if (!strcmp(s, "apability")) return K_capability; 7 if (!strcmp(s, "hdir")) return K_chdir; 8 if (!strcmp(s, "hroot")) return K_chroot; 9 if (!strcmp(s, "lass")) return K_class; 10 if (!strcmp(s, "lass_start")) return K_class_start; 11 if (!strcmp(s, "lass_stop")) return K_class_stop; 12 if (!strcmp(s, "lass_reset")) return K_class_reset; 13 if (!strcmp(s, "onsole")) return K_console; 14 if (!strcmp(s, "hown")) return K_chown; 15 if (!strcmp(s, "hmod")) return K_chmod; 16 if (!strcmp(s, "ritical")) return K_critical; 17 break; 18 case 'd': 19 if (!strcmp(s, "isabled")) return K_disabled; 20 if (!strcmp(s, "omainname")) return K_domainname; 21 break; 22 case 'e': 23 if (!strcmp(s, "xec")) return K_exec; 24 if (!strcmp(s, "xport")) return K_export; 25 break; 26 case 'g': 27 if (!strcmp(s, "roup")) return K_group; 28 break; 29 case 'h': 30 if (!strcmp(s, "ostname")) return K_hostname; 31 break; 32 case 'i': 33 if (!strcmp(s, "oprio")) return K_ioprio; 34 if (!strcmp(s, "fup")) return K_ifup; 35 if (!strcmp(s, "nsmod")) return K_insmod; 36 if (!strcmp(s, "mport")) return K_import; 37 break; 38 case 'k': 39 if (!strcmp(s, "eycodes")) return K_keycodes; 40 break; 41 case 'l': 42 if (!strcmp(s, "oglevel")) return K_loglevel; 43 if (!strcmp(s, "oad_persist_props")) return K_load_persist_props; 44 break; 45 case 'm': 46 if (!strcmp(s, "kdir")) return K_mkdir; 47 if (!strcmp(s, "ount_all")) return K_mount_all; 48 if (!strcmp(s, "ount")) return K_mount; 49 break; 50 case 'o': 51 if (!strcmp(s, "n")) return K_on; 52 if (!strcmp(s, "neshot")) return K_oneshot; 53 if (!strcmp(s, "nrestart")) return K_onrestart; 54 break; 55 case 'p': 56 if (!strcmp(s, "owerctl")) return K_powerctl; 57 case 'r': 58 if (!strcmp(s, "estart")) return K_restart; 59 if (!strcmp(s, "estorecon")) return K_restorecon; 60 if (!strcmp(s, "mdir")) return K_rmdir; 61 if (!strcmp(s, "m")) return K_rm; 62 break; 63 case 's': 64 if (!strcmp(s, "eclabel")) return K_seclabel; 65 if (!strcmp(s, "ervice")) return K_service; 66 if (!strcmp(s, "etcon")) return K_setcon; 67 if (!strcmp(s, "etenforce")) return K_setenforce; 68 if (!strcmp(s, "etenv")) return K_setenv; 69 if (!strcmp(s, "etkey")) return K_setkey; 70 if (!strcmp(s, "etprop")) return K_setprop; 71 if (!strcmp(s, "etrlimit")) return K_setrlimit; 72 if (!strcmp(s, "etsebool")) return K_setsebool; 73 if (!strcmp(s, "ocket")) return K_socket; 74 if (!strcmp(s, "tart")) return K_start; 75 if (!strcmp(s, "top")) return K_stop; 76 if (!strcmp(s, "wapon_all")) return K_swapon_all; 77 if (!strcmp(s, "ymlink")) return K_symlink; 78 if (!strcmp(s, "ysclktz")) return K_sysclktz; 79 break; 80 case 't': 81 if (!strcmp(s, "rigger")) return K_trigger; 82 break; 83 case 'u': 84 if (!strcmp(s, "ser")) return K_user; 85 break; 86 case 'w': 87 if (!strcmp(s, "rite")) return K_write; 88 if (!strcmp(s, "ait")) return K_wait; 89 break; 90 } 91 return K_UNKNOWN; 92 }
lookup_keyword()函数代码非常简单:
1. 接收一个字符指针,也就是每行的首个单词的地址;
2. switch/case语句判断类型并返回;
lookup_keyword()返回值K_copy、K_capability值,其实就是表项的索引号,本质就是对应到keyword_info结构体数组中的数据编号(index)。
keyword_info结构体数组及K_copy等常量的定义如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#58
1 #include "keywords.h" 2 3 #define KEYWORD(symbol, flags, nargs, func) \ 4 [ K_##symbol ] = { #symbol, func, nargs + 1, flags, }, 5 6 struct { 7 const char *name; 8 int (*func)(int nargs, char **args); 9 unsigned char nargs; 10 unsigned char flags; 11 } keyword_info[KEYWORD_COUNT] = { 12 [ K_UNKNOWN ] = { "unknown", 0, 0, 0 }, 13 #include "keywords.h" 14 }; 15 #undef KEYWORD
这里用到了一点儿宏定义的小技巧,两次include了keywords.h头文件,
第一次#include "keywords.h"
其实keywords.h中会先定义一次KEYWORD宏,其主要目的是为了形成一个顺序排列的enum,而后就#undef KEYWORD了。
展开后代码如下:
1 int do_chroot(int nargs, char **args); 2 int do_chdir(int nargs, char **args); 3 int do_class_start(int nargs, char **args); 4 int do_class_stop(int nargs, char **args); 5 int do_class_reset(int nargs, char **args); 6 int do_domainname(int nargs, char **args); 7 int do_exec(int nargs, char **args); 8 int do_export(int nargs, char **args); 9 int do_hostname(int nargs, char **args); 10 int do_ifup(int nargs, char **args); 11 int do_insmod(int nargs, char **args); 12 int do_mkdir(int nargs, char **args); 13 int do_mount_all(int nargs, char **args); 14 int do_mount(int nargs, char **args); 15 int do_powerctl(int nargs, char **args); 16 int do_restart(int nargs, char **args); 17 int do_restorecon(int nargs, char **args); 18 int do_rm(int nargs, char **args); 19 int do_rmdir(int nargs, char **args); 20 int do_setcon(int nargs, char **args); 21 int do_setenforce(int nargs, char **args); 22 int do_setkey(int nargs, char **args); 23 int do_setprop(int nargs, char **args); 24 int do_setrlimit(int nargs, char **args); 25 int do_setsebool(int nargs, char **args); 26 int do_start(int nargs, char **args); 27 int do_stop(int nargs, char **args); 28 int do_swapon_all(int nargs, char **args); 29 int do_trigger(int nargs, char **args); 30 int do_symlink(int nargs, char **args); 31 int do_sysclktz(int nargs, char **args); 32 int do_write(int nargs, char **args); 33 int do_copy(int nargs, char **args); 34 int do_chown(int nargs, char **args); 35 int do_chmod(int nargs, char **args); 36 int do_loglevel(int nargs, char **args); 37 int do_load_persist_props(int nargs, char **args); 38 int do_wait(int nargs, char **args); 39 #define __MAKE_KEYWORD_ENUM__ 40 #define KEYWORD(symbol, flags, nargs, func) K_##symbol, 41 enum { 42 K_UNKNOWN, 43 K_capability, 44 K_chdir, 45 K_chroot, 46 K_class, 47 K_class_start, 48 K_class_stop, 49 K_class_reset, 50 K_console, 51 K_critical, 52 K_disabled, 53 K_domainname, 54 K_exec, 55 K_export, 56 K_group, 57 K_hostname, 58 K_ifup, 59 K_insmod, 60 K_import, 61 K_keycodes, 62 K_mkdir, 63 K_mount_all, 64 K_mount, 65 K_on, 66 K_oneshot, 67 K_onrestart, 68 K_powerctl, 69 K_restart, 70 K_restorecon, 71 K_rm, 72 K_rmdir, 73 K_seclabel, 74 K_service, 75 K_setcon, 76 K_setenforce, 77 K_setenv, 78 K_setkey, 79 K_setprop, 80 K_setrlimit, 81 K_setsebool, 82 K_socket, 83 K_start, 84 K_stop, 85 K_swapon_all, 86 K_trigger, 87 K_symlink, 88 K_sysclktz, 89 K_user, 90 K_wait, 91 K_write, 92 K_copy, 93 K_chown, 94 K_chmod, 95 K_loglevel, 96 K_load_persist_props, 97 K_ioprio, 98 KEYWORD_COUNT, 99 }; 100 #undef __MAKE_KEYWORD_ENUM__ 101 #undef KEYWORD
第二次#include "keywords.h"
接着上面代码中再次定义了KEYWORD宏,这次的主要目的是为了形成一个struct数组,即keyword_info数组。
展开后代码如下:
1 #define KEYWORD("symbol, flags, nargs, func) \ 2 [ K_##symbol ] = { #symbol, func, nargs + 1, flags, }, 3 4 struct { 5 const char *name; 6 int (*func)(int nargs, char **args); 7 unsigned char nargs; 8 unsigned char flags; 9 } keyword_info[KEYWORD_COUNT] = { 10 [ K_UNKNOWN ] = { "unknown", 0, 0, 0 }, 11 [ K_capability ] = { "capability", 0, 0, OPTION) }, 12 [ K_chdir ] = { "chdir", do_chdir, 1, COMMAND) }, 13 [ K_chroot ] = { "chroot", do_chroot, 1, COMMAND) }, 14 [ K_class ] = { "class", 0, 0, OPTION) }, 15 [ K_class_start ] = { "class_start", do_class_start, 1, COMMAND) }, 16 [ K_class_stop ] = { "class_stop", do_class_stop, 1, COMMAND) }, 17 [ K_class_reset ] = { "class_reset", do_class_reset, 1, COMMAND) }, 18 [ K_console ] = { "console", 0, 0, OPTION) }, 19 [ K_critical ] = { "critical", 0, 0, OPTION) }, 20 [ K_disabled ] = { "disabled", 0, 0, OPTION) }, 21 [ K_domainname ] = { "domainname", do_domainname, 1, COMMAND) }, 22 [ K_exec ] = { "exec", do_exec, 1, COMMAND) }, 23 [ K_export ] = { "export", do_export, 2, COMMAND) }, 24 [ K_group ] = { "group", 0, 0, OPTION) }, 25 [ K_hostname ] = { "hostname", 1, do_hostname, COMMAND) }, 26 [ K_ifup ] = { "ifup", do_ifup, 1, COMMAND) }, 27 [ K_insmod ] = { "insmod", do_insmod, 1, COMMAND) }, 28 [ K_import ] = { "import", 0, 1, SECTION) }, 29 [ K_keycodes ] = { "keycodes", 0, 0, OPTION) }, 30 [ K_mkdir ] = { "mkdir", do_mkdir, 1, COMMAND) }, 31 [ K_mount_all ] = { "mount_all", do_mount_all, 1, COMMAND) }, 32 [ K_mount ] = { "mount", do_mount, 3, COMMAND) }, 33 [ K_on ] = { "on", 0, 0, SECTION) }, 34 [ K_oneshot ] = { "oneshot", 0, 0, OPTION) }, 35 [ K_onrestart ] = { "onrestart", 0, 0, OPTION) }, 36 [ K_powerctl ] = { "powerctl", do_powerctl, 1, COMMAND) }, 37 [ K_restart ] = { "restart", do_restart, 1, COMMAND) }, 38 [ K_restorecon ] = { "restorecon", do_restorecon, 1, COMMAND) }, 39 [ K_rm ] = { "rm", do_rm, 1, COMMAND) }, 40 [ K_rmdir ] = { "rmdir", do_rmdir, 1, COMMAND) }, 41 [ K_seclabel ] = { "seclabel", 0, 0, OPTION) }, 42 [ K_service ] = { "service", 0, 0, SECTION) }, 43 [ K_setcon ] = { "setcon", do_setcon, 1, COMMAND) }, 44 [ K_setenforce ] = { "setenforce", do_setenforce, 1, COMMAND) }, 45 [ K_setenv ] = { "setenv", 0, 2, OPTION) }, 46 [ K_setkey ] = { "setkey", do_setkey, 0, COMMAND) }, 47 [ K_setprop ] = { "setprop", do_setprop, 2, COMMAND) }, 48 [ K_setrlimit ] = { "setrlimit", do_setrlimit, 3, COMMAND) }, 49 [ K_setsebool ] = { "setsebool", do_setsebool, 2, COMMAND) }, 50 [ K_socket ] = { "socket", 0, 0, OPTION) }, 51 [ K_start ] = { "start", do_start, 1, COMMAND) }, 52 [ K_stop ] = { "stop", do_stop, 1, COMMAND) }, 53 [ K_swapon_all ] = { "swapon_all", do_swapon_all, 1, COMMAND) }, 54 [ K_trigger ] = { "trigger", do_trigger, 1, COMMAND) }, 55 [ K_symlink ] = { "symlink", do_symlink, 1, COMMAND) }, 56 [ K_sysclktz ] = { "sysclktz", do_sysclktz, 1, COMMAND) }, 57 [ K_user ] = { "user", 0, 0, OPTION) }, 58 [ K_wait ] = { "wait", do_wait, 1, COMMAND) }, 59 [ K_write ] = { "write", do_write, 2, COMMAND) }, 60 [ K_copy ] = { "copy", do_copy, 2, COMMAND) }, 61 [ K_chown ] = { "chown", do_chown, 2, COMMAND) }, 62 [ K_chmod ] = { "chmod", do_chmod, 2, COMMAND) }, 63 [ K_loglevel ] = { "loglevel", do_loglevel, 1, COMMAND) }, 64 [ K_load_persist_props ] = { "load_persist_props", do_load_persist_props, 0, COMMAND) }, 65 [ K_ioprio ] = { "ioprio", 0, 0, OPTION) }, 66 67 }; 68 #undef KEYWORD
注意:keyword_info结构体数组中只有3个元素的flags是SECTION :
[ K_import ] = { "import", 0, 1, SECTION) },
[ K_on ] = { "on", 0, 0, SECTION) },
[ K_service ] = { "service", 0, 0, SECTION) },
2.3.5 解析section小节
kw_is(kw, SECTION)判断该行是一个sectio小节时,即分析出某句脚本是以on或者service或者import开始,就说明一个新的小节要开始了。此时,会调用到parse_new_section(),该函数的代码如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#parse_new_section
1 void parse_new_section(struct parse_state *state, int kw, 2 int nargs, char **args) 3 { 4 printf("[ %s %s ]\n", args[0], 5 nargs > 1 ? args[1] : ""); 6 switch(kw) { 7 case K_service: 8 state->context = parse_service(state, nargs, args); 9 if (state->context) { 10 state->parse_line = parse_line_service; 11 return; 12 } 13 break; 14 case K_on: 15 state->context = parse_action(state, nargs, args); 16 if (state->context) { 17 state->parse_line = parse_line_action; 18 return; 19 } 20 break; 21 case K_import: 22 parse_import(state, nargs, args); 23 break; 24 } 25 state->parse_line = parse_line_no_op; 26 }
代码很清晰,解析的小节就是那三类:
action小节(以on开头的)
service小节(以service)
import小节(以import开头)
最核心的部分当然是service小节和action小节,具体解析的地方在上面代码中的parse_service()和parse_action()函数里。
至于import小节,parse_import()函数只是把脚本中的所有import语句先汇总成一个链表,记入state结构中,待回到parse_config()后再做处理。
2.3.6 解析service section
parse_service()的代码如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#613
1 static void *parse_service(struct parse_state *state, int nargs, char **args) 2 { 3 struct service *svc; 4 5 .... 6 7 nargs -= 2; 8 svc = calloc(1, sizeof(*svc) + sizeof(char*) * nargs); // 申请一个service节点 9 if (!svc) { 10 parse_error(state, "out of memory\n"); 11 return 0; 12 } 13 svc->name = args[1]; // 填入service name 14 svc->classname = "default"; // 填入service class 15 memcpy(svc->args, args + 2, sizeof(char*) * nargs); 16 svc->args[nargs] = 0; 17 svc->nargs = nargs; 18 svc->onrestart.name = "onrestart"; 19 list_init(&svc->onrestart.commands); 20 list_add_tail(&service_list, &svc->slist); //加入service_list 21 22 return svc; 23 }
解析service section时,首先会调用calloc()申请一个service节点,然后填入name / class等信息,并加入到service_list链表。
parse_service()函数的返回值是新建立的service节点的指针,该指针会存在state->context中(即parse_config函数中的struct parse_state state;),再解析这个service section的后续option行时可以把信息存入对应的节点。
注意,此时该service节点的onrestart.commands部分还是个空链表,因为我们还没有分析该service的后续脚本行。
parse_new_section()中为service明确指定了解析后续行的函数parse_line_service()。
如此,在parse_config()函数的for循环中,再解析新的一行时,就会调用state.parse_line(&state, nargs, args);来解析,
并将解析的信息存入 state->context 指向的section 节点中
parse_config()函数部分代码:
1 static void parse_config(const char *fn, char *s) 2 { 3 for (;;) { 4 switch (next_token(&state)) { 5 6 case T_NEWLINE: 7 state.line++; 8 if (nargs) { 9 int kw = lookup_keyword(args[0]); 10 if (kw_is(kw, SECTION)) { 11 // 解析到一个section开始 12 state.parse_line(&state, 0, 0); 13 parse_new_section(&state, kw, nargs, args); 14 } else { 15 // 解析一个service section中的option信息 or action section的command信息 16 state.parse_line(&state, nargs, args); 17 } 18 nargs = 0; 19 } 20 break; 21 } 22 } 23 }
parse_line_service()函数的截选代码如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#parse_line_service
1 static void parse_line_service(struct parse_state *state, int nargs, char **args) 2 { 3 struct service *svc = state->context; // 指向service节点的指针 4 struct command *cmd; 5 . . . . . . 6 kw = lookup_keyword(args[0]); // 解析具体的service option也是要查关键字表的 7 switch (kw) { 8 case K_capability: 9 break; 10 case K_class: 11 if (nargs != 2) { 12 parse_error(state, "class option requires a classname\n"); 13 } else { 14 svc->classname = args[1]; // 填入信息 15 } 16 break; 17 case K_console: 18 svc->flags |= SVC_CONSOLE; // 填入信息 19 break; 20 case K_disabled: 21 . . . . . . 22 . . . . . .
service的各个option会影响service节点的不同域,比如flags域、classname域、onrestart域等等。
其中onrestart域的解析稍有不同,因为onrestart本身是个action节点,会带有多个command。
service section中常见的options有:
1) K_capability
2) K_class -- 服务所属的类,当一个类启动或退出时,其所包含的所有服务可以一同启动或退出。若为指定该option,服务默认属于“default”类
3) K_console
4) K_disabled -- init进程启动的所有进程被包含在名称为“类”的运行组中。进程所属的类被启动时,若指定进程为disable,该进程将不会被执行,只有按照名称明确指定后才可以启动。
5) K_ioprio
6) K_group -- 执行服务前改变组,默认组为 root
7) K_user -- 执行服务前改变用户名,若为设定,则默认为root
8) K_keycodes --
9) K_oneshot -- 服务退出后不再重启
10) K_onrestart -- 当服务重启时执行一个命令
11) K_critical
12) K_setenv
13) K_socket -- 创建socket
14) K_seclabel
在service小节解析完毕后,我们应该能得到类似下图这样的service节点:
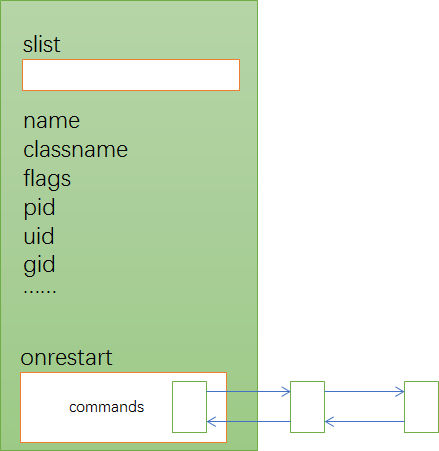
2.3.7 解析action section
解析action小节与上述service的解析过程类似,代码也很简单。
解析时会调用parse_action()函数,该函数中会用calloc()申请一个action节点,然后填入action名等信息,再加入action_list总表中。
当然,此时action的commands部分也是空的,等待后续解析
parse_action()函数的代码如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#821
1 static void *parse_action(struct parse_state *state, int nargs, char **args) 2 { 3 struct action *act; 4 if (nargs < 2) { 5 parse_error(state, "actions must have a trigger\n"); 6 return 0; 7 } 8 if (nargs > 2) { 9 parse_error(state, "actions may not have extra parameters\n"); 10 return 0; 11 } 12 act = calloc(1, sizeof(*act)); 13 act->name = args[1]; 14 list_init(&act->commands); 15 list_init(&act->qlist); 16 list_add_tail(&action_list, &act->alist); 17 /* XXX add to hash */ 18 return act; 19 }
对于action小节而言,我们指定了不同的解析后续行的函数,也就是parse_line_action()。该函数的代码截选如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#841
1 static void parse_line_action(struct parse_state* state, int nargs, char **args) 2 { 3 struct command *cmd; 4 struct action *act = state->context; 5 . . . . . . 6 kw = lookup_keyword(args[0]); // 解析具体的action command也是要查关键字表的 7 if (!kw_is(kw, COMMAND)) { 8 parse_error(state, "invalid command '%s'\n", args[0]); 9 return; 10 } 11 12 n = kw_nargs(kw); 13 if (nargs < n) { 14 parse_error(state, "%s requires %d %s\n", args[0], n - 1, 15 n > 2 ? "arguments" : "argument"); 16 return; 17 } 18 cmd = malloc(sizeof(*cmd) + sizeof(char*) * nargs); 19 cmd->func = kw_func(kw); 20 cmd->nargs = nargs; 21 memcpy(cmd->args, args, sizeof(char*) * nargs); 22 list_add_tail(&act->commands, &cmd->clist); 23 }
既然action的后续行可以包含多条command,那么parse_line_action()就必须先确定出当前分析的是什么command,这一点和parse_line_service()是一致的,都是通过调用lookup_keyword()来查询关键字的。
另外,command子行的所有参数经过next_token()分割,其实已被记入传进来的args参数,现在这些参数会记入command节点的args域中,而且这个command节点会链入action节点的commands链表尾部。
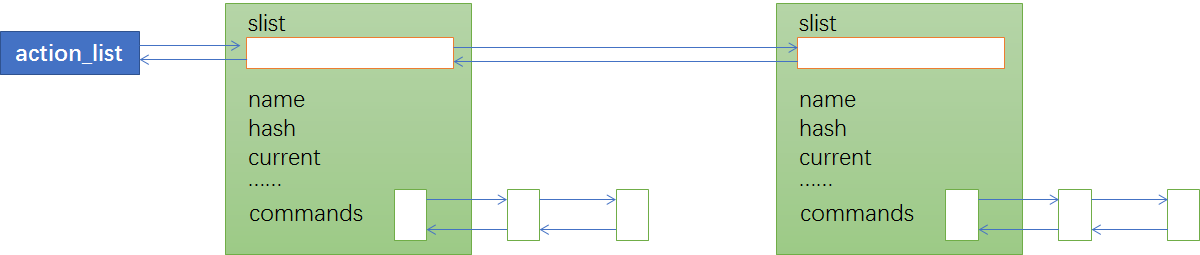
在action小节解析完毕后,我们应该能得到类似下图这样的action节点:
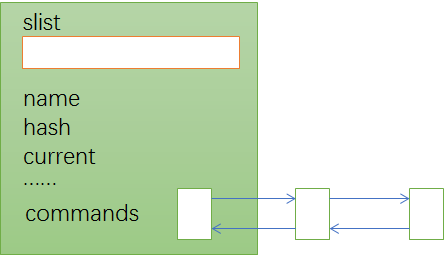
2.3.8 解析import section
解析import section的代码非常简单,就是将import进来的.rc文件名加入到import list中,以便后续进行解析。
parse_import()函数的代码如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#295
1 void parse_import(struct parse_state *state, int nargs, char **args) 2 { 3 struct listnode *import_list = state->priv; 4 struct import *import; 5 char conf_file[PATH_MAX]; 6 int ret; 7 8 if (nargs != 2) { 9 ERROR("single argument needed for import\n"); 10 return; 11 } 12 13 ret = expand_props(conf_file, args[1], sizeof(conf_file)); 14 if (ret) { 15 ERROR("error while handling import on line '%d' in '%s'\n", 16 state->line, state->filename); 17 return; 18 } 19 20 import = calloc(1, sizeof(struct import)); 21 import->filename = strdup(conf_file); 22 list_add_tail(import_list, &import->list); 23 INFO("found import '%s', adding to import list", import->filename); 24 }
首先调用expand_props()函数获取import进来的.rc文件的扩展名,也就是去解析这样的语句中的file name: import /init.${ro.hardware}.rc,需要根据property name值来得到实际的文件名
然后调用calloc创建一个import节点,并填入filename信息
最后加入到import_list链表中等待后续使用
在import小节解析完毕后,我们应该能得到类似下图这样的import节点:
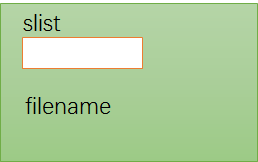
2.3.9 解析完毕
至此,当init.rc文件解析完成后,我们得到了三个list链表:
首先要清楚,在/system/core/init/init_parser.c中定义:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#39
1 static list_declare(service_list); 2 static list_declare(action_list); 3 static list_declare(action_queue);
service_list 及 action_list均是全局static变量,也就是链表的头节点。
另外在parse_config()函数中还定义了局部变量import_list (http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#350),import进来的.rc文件最终也是会被解析并将action and service加入service_list or action_list.
1. service服务列表
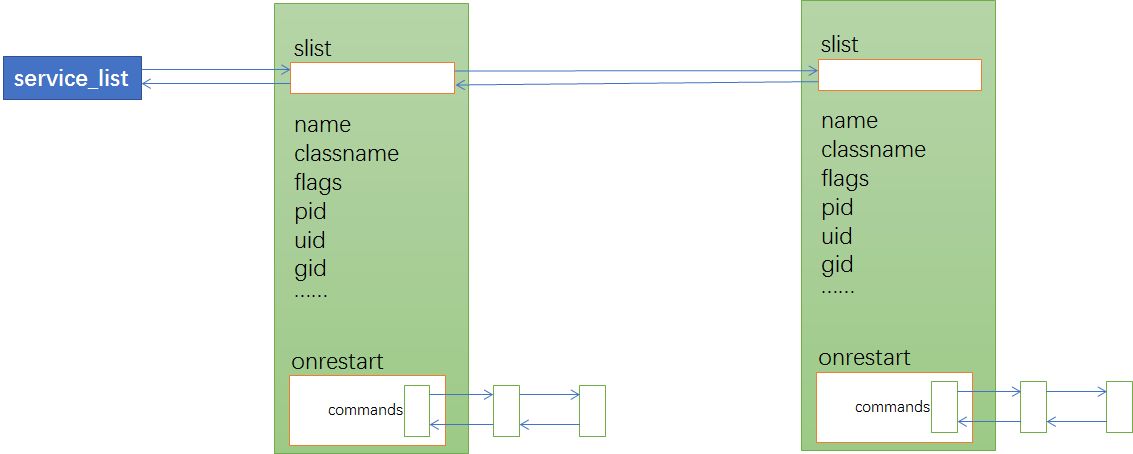
2. action动作列表
3. import 导入列表

还有一点要注意的是 import_list 在parse_config()函数的最后还是会去调用init_parse_config_file(import->filename)函数对所有import进来的.rc文件进行解析。
代码如下:
http://androidxref.com/4.4_r1/xref/system/core/init/init_parser.c#391
1 static void parse_config(const char *fn, char *s) 2 { 3 4 ..... 5 6 parser_done: 7 list_for_each(node, &import_list) { 8 struct import *import = node_to_item(node, struct import, list); 9 int ret; 10 11 INFO("importing '%s'", import->filename); 12 ret = init_parse_config_file(import->filename); 13 if (ret) 14 ERROR("could not import file '%s' from '%s'\n", 15 import->filename, fn); 16 } 17 }
最终:
把所有的action 都加入到action_list。
把所有的service 都加入到service_list。
3 总结:
init.rc文件的解析流程大体如下图:

Init进程一启动就会读取并解析init.rc脚本文件,把其中的元素整理成自己的数据结构(链表)。
具体情况可参考system\core\init\init.c文件。
Init进程的main()函数会先调用init_parse_config_file(“/init.rc”)来解析init.rc脚本,分析出应该执行的语义,并且把脚本中描述的action和service信息分别组织成双向链表,然后执行之。
=========
到这里,我们就解析完所有的rc文件,并且得到了之后需要操作两个list(action_list and service_list),之后就可以准备执行了。
---------
*********
---------


 浙公网安备 33010602011771号
浙公网安备 33010602011771号