[AI应用基础学习-7] LangChain-Retrieval
Retrieval模块的设计意义
RAG 检索增强生成(Retrieval-augmented Generation)
-
解决大模型幻觉的问题。LLM无法学习到所有的专业知识细节,因此在
面向专业领域的提问时,无法给出可靠准确的回答,甚至会“胡言乱语”。 -
优点:
- 相比提示词工程,RAG有
更丰富的上下文和数据样本,可以不需要用户提供过多的背景描述,就能生成比较符合用户预期的答案。 - 相比于模型微调,RAG可以提升问答内容的
时效性和可靠性。 - 在一定程度上保护了业务数据的
隐私性。
- 相比提示词工程,RAG有
-
缺点:
- 由于每次问答都涉及外部系统数据检索,因此RAG的
响应时延相对较高。 - 引用的外部知识数据会消耗大量的模型
Token资源。
- 由于每次问答都涉及外部系统数据检索,因此RAG的
Retrieval流程
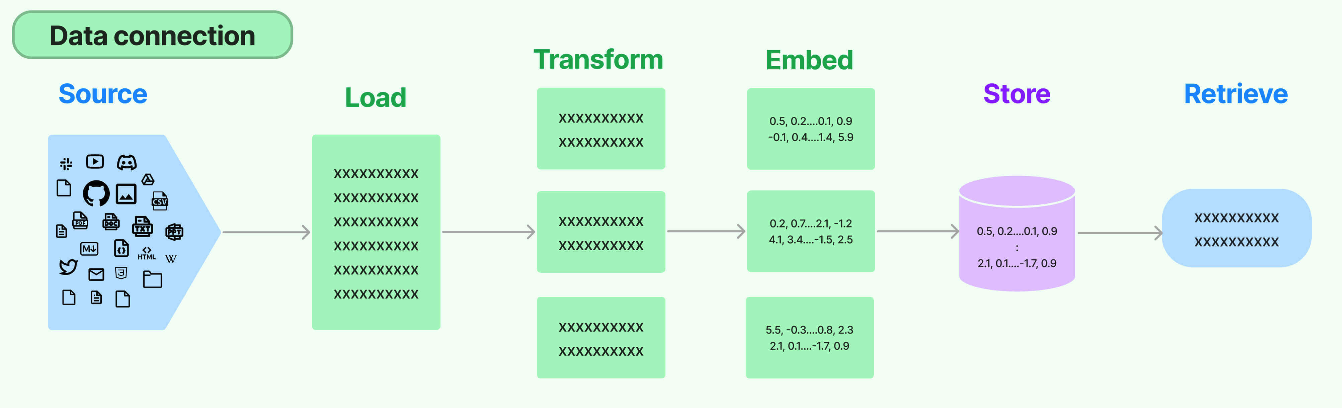
环节1:Source(数据源)
指的是RAG架构中所外挂的知识库。原始数据源类型多样:如:视频、图片、文本、代码、文档等
- 可以是上百个.csv文件,可以是上千个.json文件,也可以是上万个.pdf文件
- 可以是某一个业务流程外放的API,可以是某个网站的实时数据等
环节2:Load(加载)
文档加载器(Document Loaders)负责将来自不同数据源的非结构化文本,加载到内存 ,成为文档(Document)对象。
文档对象包含文档内容和相关的元数据,例如TXT、CSV、HTML、JSON、Markdown、PDF,甚至YouTube 视频转录等。
文档加载器还支持延迟加载模式,以缓解处理大文件时的内存压力。 文档加载器的编程接口使用起来非常简单,以下给出加载TXT格式文档的例子。
from langchain_community.document_loaders import TextLoader
text_loader = TextLoader("./test.txt")
docs = text_loader.load()
print(docs)
环节3:Transform(转换)
文档转换器(Document Transformers):负责对加载的文档进行转换和处理,以便更好地适应下游任务的需求。
文档转换器提供了一致的接口(工具)来操作文档,主要包括以下几类:
文本拆分器(Text Splitters):将长文本拆分成语义上相关的小块,以适应语言模型的上下文窗口限制。冗余过滤器(Redundancy Filters):识别并过滤重复的文档。元数据提取器(Metadata Extractors):从文档中提取标题、语调等结构化元数据。多语言转换器(Multi-lingual Transformers):实现文档的机器翻译。对话转换器(Conversational Transformers):将非结构化对话转换为问答格式的文档。
环节3.1:Text Splitting(文档拆分)
-
拆分/分块的必要性:前一个环节加载后的文档对象可以直接传入文档拆分器进行拆分,而文档切块后才能向量化并存入数据库中。 -
文档拆分器的多样性:LangChain提供了丰富的文档拆分器,不仅能够切分普通文本,还能切分 Markdown、JSON、HTML、代码等特殊格式的文本。 -
拆分/分块的挑战性:实际拆分操作中需要处理许多细节问题,不同类型的文本 、不同的使用场景都需要采用不同的分块策略。- 可以按照
数据类型进行切片处理,比如针对文本类数据,可以直接按照字符、段落进行切片;代码类数据则需要进一步细分以保证代码的功能性; - 可以直接根据 token 进行切片处理
- 可以按照
在构建RAG应用程序的整个流程中,拆分/分块是最具挑战性的环节之一,它显著影响检索效果。目前还没有通用的方法可以明确指出哪一种分块策略最为有效。不同的使用场景和数据类型都会影响分块策略的选择。
环节4:Embed(嵌入)
文档嵌入模型(Text Embedding Models)负责将文本转换为向量表示 ,即模型赋予了文本计算机可理解的数值表示,使文本可用于向量空间中的各种运算,大大拓展了文本分析的可能性。
- 实现原理:通过
特定算法(如Word2Vec)将语义信息编码为固定维度的向量,具体算法细节需后续深入。 - 关键特性:相似的词在向量空间中距离相近,例如"猫"和"犬"的向量夹角小于"猫"和"汽车"。
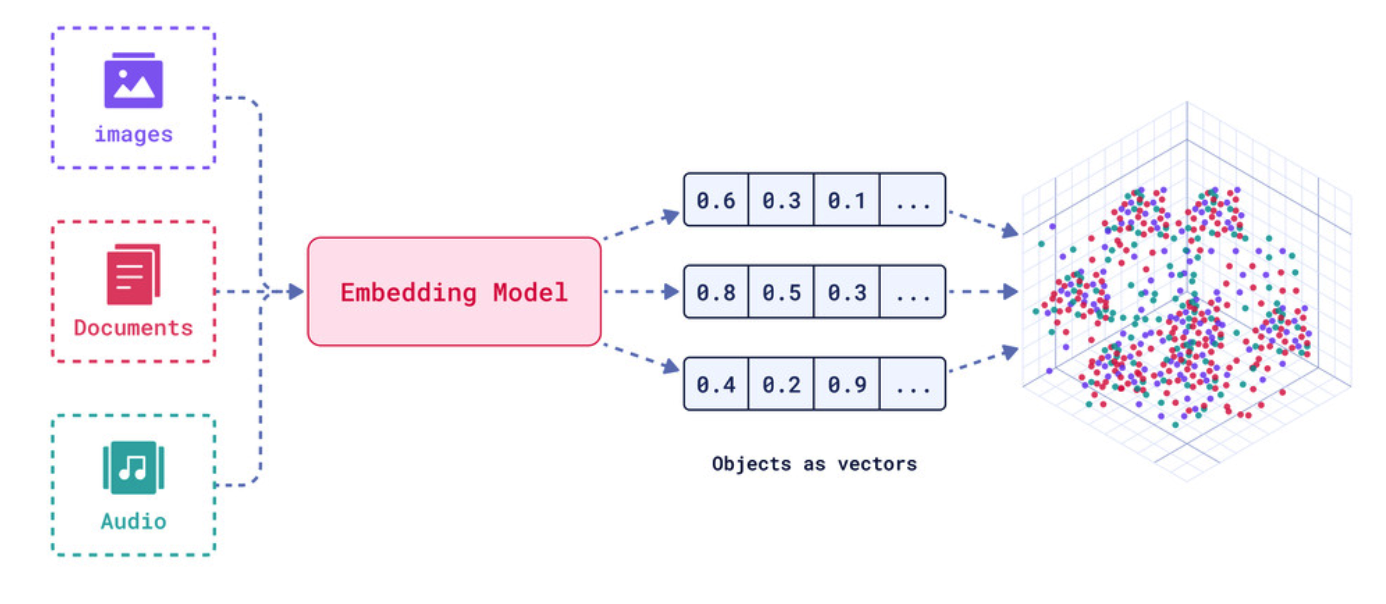
文本嵌入为 LangChain 中的问答、检索、推荐等功能提供了重要支持。具体为:
- 语义匹配 :通过计算两个文本的向量余弦相似度,判断它们在语义上的相似程度,实现语义匹配。
- 文本检索 :通过计算不同文本之间的向量相似度,可以实现语义搜索,找到向量空间中最相似的文本。
- 信息推荐 :根据用户的历史记录或兴趣嵌入生成用户向量,计算不同信息的向量与用户向量的相似度,推荐相似的信息。
- 知识挖掘 :可以通过聚类、降维等手段分析文本向量的分布,发现文本之间的潜在关联,挖掘知识。
- 自然语言处理 :将词语、句子等表示为稠密向量,为神经网络等下游任务提供输入。
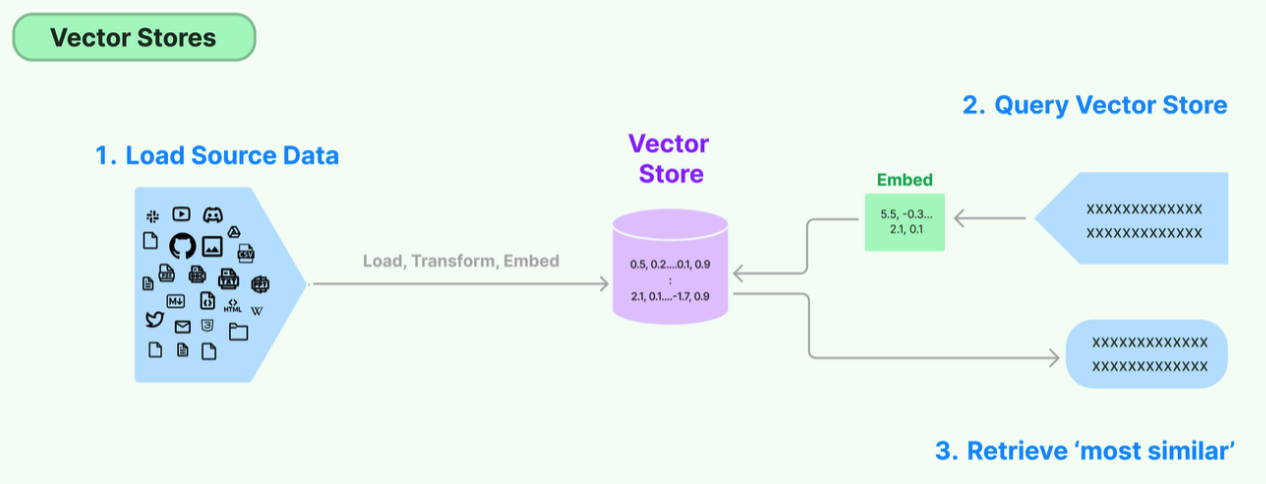
环节5:Store(存储)
LangChain 还支持把文本嵌入存储到向量存储或临时缓存,以避免需要重新计算它们。这里就出现了数据库,支持这些嵌入的高效存储和搜索的需求。
环节6:Retrieve(检索)
检索器(Retrievers)是一种用于响应非结构化查询的接口,它可以返回符合查询要求的文档。
LangChain 提供了一些常用的检索器,如向量检索器 、文档检索器 、网站研究检索器等。通过配置不同的检索器,LangChain 可以灵活地平衡检索的精度、召回率与效率。检索结果将为后续的问答生成提供信息支持,以产生更加准确和完整的回答。
文档加载器 Document Loaders
LangChain的设计:对于 中多种不同的数据源,我们可以用一种统一的形式读取、调用。
Documment对象中有两个重要的属性:
- page_content:真正的文档内容
- metadata:文档内容的原数据
#txt
from langchain_community.document_loaders import TextLoader
text_loader = TextLoader("./test.txt")
docs = text_loader.load()
print(docs)
print(type(docs[0]))
print(docs[0].page_content)
print(docs[0].metadata)
#pdf
from langchain_community.document_loaders import PyPDFLoader
pdfLoader = PyPDFLoader(file_path="./test.pdf")
docs = pdfLoader.load()
print(docs)
#CSV
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader(file_path="./test.csv")
data = loader.load()
print(data)
#json pip install jq
from langchain_community.document_loaders import JSONLoader
json_loader=JSONLoader(
file_path="./test.json",
jq_schema=".messages[].content"
)
docs = json_loader.load()
print(docs)
##test.json
{
"messages": [
{ "content": "hello" },
{ "content": "world" }
]
}
#html pip install unstructured
from langchain_community.document_loaders import UnstructuredHTMLLoader
html_loader = UnstructuredHTMLLoader(
file_path="./test.html",
mode="elements",
strategy="fast"
)
docs = html_loader.load()
print(docs)
print("----------")
for doc in docs:
print(doc)
#Markdown pip install markdown
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from pprint import pprint
md_loader = UnstructuredMarkdownLoader(
file_path="./test.md",
strategy="fast"
)
docs = md_loader.load()
print(len(docs))
for doc in docs:
pprint(doc)
#目录加载
from langchain_community.document_loaders import PythonLoader, DirectoryLoader
directory_loader = DirectoryLoader(
path="./",
glob="*.txt",
use_multithreading=True,
show_progress=True,
loader_cls=PythonLoader
)
# 3.加载
docs = directory_loader.load()
print(len(docs))
for doc in docs:
pprint(doc)
文档拆分器 Text Splitters
拆分/分块/切分
当拿到统一的一个Document对象后,接下来需要切分成Chunks。如果不切分,而是考虑作为一个整体的Document对象,会存在两点问题:
- 假设提问的Query的答案出现在某一个Document对象中,那么将检索到的整个Document对象直接放入Prompt中并不是最优的选择 ,因为其中一定会包含非常多无关的信息 ,而无效信息越多,对大模型后续的推理影响越大。
- 任何一个大模型都存在最大输入的Token限制 ,如果一个Document非常大,比如一个几百兆的PDF,那么大模型肯定无法容纳如此多的信息。
Chunking拆分的策略
- 方法1:根据句子切分:这种方法按照自然句子边界进行切分,以保持语义完整性。
- 方法2:按照固定字符数来切分:这种策略根据特定的字符数量来划分文本,但可能会在不适当的位置切断句子。
- 方法3:按固定字符数来切分,结合重叠窗口(overlapping windows):此方法与按字符数切分相似,但通过重叠窗口技术避免切分关键内容,确保信息连贯性。
- 方法4:递归字符切分方法:通过递归字符方式动态确定切分点,这种方法可以根据文档的复杂性和内容密度来调整块的大小。
- 方法5:根据语义内容切分:这种高级策略依据文本的语义内容来划分块,旨在
保持相关信息的集中和完整,适用于需要高度语义保持的应用场景。
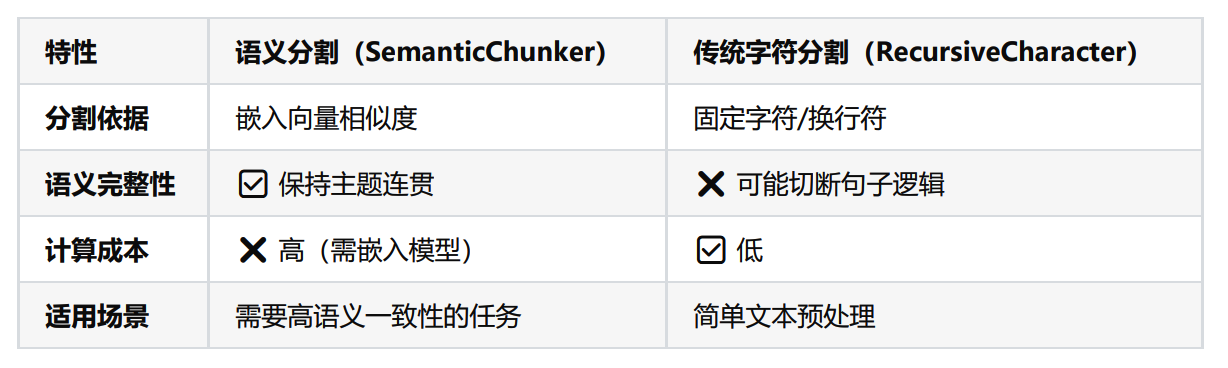
第2种⽅法(按照字符数切分)和第3种⽅法(按固定字符数切分结合重叠窗口)主要基于字符进⾏⽂本的切分,而不考虑⽂章的实际内容和语义。这种⽅式虽简单,但可能会导致主题或语义上的断裂 。
相对而⾔,第4种递归⽅法更加灵活和⾼效,它结合了固定⻓度切分和语义分析。通常是首选策略 ,因为它能够更好地确保每个段落包含⼀个完整的主题。
而第5种⽅法,基于语义的分割虽然能精确地切分出完整的主题段落,但这种⽅法效率较低。它需要运⾏复杂的分段算法(segmentation algorithm), 处理速度较慢 ,并且段落长度可能极不均 匀 (有的主题段落可能很⻓,而有的则较短)。因此,尽管它在某些需要⾼精度语义保持的场景下有其应⽤价值,但并不适合所有情况 。
Chunking具体实现
LangChain提供了许多不同类型的文档切分器
https://reference.langchain.com/python/langchain_text_splitters/
CharacterTextSplitter:Split by character
- chunk_size :每个切块的最大token数量,默认值为4000。
- chunk_overlap :相邻两个切块之间的最大重叠token数量,默认值为200。
- separator :分割使用的分隔符,默认值为"\n\n"。
- length_function :用于计算切块长度的方法。默认赋值为父类TextSplitter的len函数。
from langchain_text_splitters import CharacterTextSplitter
text = """test"""
splitter = CharacterTextSplitter(
chunk_size=50, # 每块大小
chunk_overlap=5,# 块与块之间的重复字符数
separator="" # 设置为空字符串时,表示禁用分隔符优先,也可以指定如 。
)
texts = splitter.split_text(text)
for i, chunk in enumerate(texts):
print(f"块 {i+1}:长度:{len(chunk)}")
print(chunk)
print("-" * 50)
RecursiveCharacterTextSplitter:最常用
文档切分器中较常用的是 RecursiveCharacterTextSplitter (递归字符文本切分器) ,遇到特定字符时进行分割。默认情况下,它尝试进行切割的字符包括 ["\n\n", "\n", " ", ""] 。 具体为:根据第一个字符进行切块,但如果任何切块太大,则会继续移动到下一个字符继续切块,以此类推。此外,还可以考虑添加,。等分割字符。
特点:
- 保留上下文:优先在自然语言边界(如段落、句子结尾)处分割, 减少信息碎片化 。
- 智能分段:通过递归尝试多种分隔符,将文本分割为大小接近chunk_size的片段。
- 灵活适配:适用于多种文本类型(代码、Markdown、普通文本等),是LangChain中 最通用的文本拆分器。
参数:
- chunk_size :每个 chunk 的目标最大长度。
- chunk_overlap :相邻两个 chunk 之间重叠的长度,用来保留上下文,避免切断导致语义丢失。
- length_function :用来计算文本长度的函数
- add_start_index :是否在切分结果里附带每个 chunk 在原文中的起始位置索引
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=10,
chunk_overlap=0,
add_start_index=True,
)
text = "LangChain框架特性\n\n多模型集成(GPT/Claude)\n记忆管理功能\n链式调用设计。文档分析场景示例:需要处理PDF/Word等格式。"
paragraphs = text_splitter.split_text(text) # text_splitter.create_documents():形参是字符串列表,返回值是Document的列表
for para in paragraphs:
print(para)
print('-------')
#此外还有text_splitter.split_documents(docs)对文档的内容用递归切割器切割
#自定义切割符用separators=["\n\n","\n"," ",.....]
TokenTextSplitter/CharacterTextSplitter:Split by tokens
当我们将文本拆分为块时,除了字符以外,还可以:按Token的数量分割(而非字符或单词数),将长文本切分成多个小块。
什么是Token?
对模型而言,Token是文本的最小处理单位。例如:
- 英文: "hello" → 1个Token, "ChatGPT" → 2个Token( "Chat" + "GPT" )。
- 中文: "人工智能" → 可能拆分为2-3个Token(取决于分词器)。
为什么按Token分割?
- 语言模型对输入长度的限制是基于Token数(如GPT-4的8k/32k Token上限),直接按字符或单词分割可能导致实际Token数超限。(确保每个文本块不超过模型的Token上限)
- 大语言模型(LLM)通常是以token的数量作为其计量(或收费)的依据,所以采用token分割也有助于我们在使用时更方便的
控制成本。
TokenTextSplitter 使用说明:
-
核心依据:Token数量 + 自然边界。(TokenTextSplitter 严格按照 token 数量进行分割,但同时会优先在自然边界(如句尾)处切断,以尽量保证语义的完整性。)
-
优点:与LLM的Token计数逻辑一致,能尽量保持语义完整
-
缺点:对非英语或特定领域文本,Token化效果可能不佳
-
典型场景:需要精确控制Token数输入LLM的场景
from langchain_text_splitters import TokenTextSplitter
text_splitter = TokenTextSplitter(
chunk_size=33, #最大 token 数为 32
chunk_overlap=0, #重叠 token 数为 0
encoding_name="cl100k_base", # 使用 OpenAI 的编码器,将文本转换为 token 序列
)
# 3.定义文本
text = "人工智能是一个强大的开发框架。它支持多种语言模型和工具链。人工智能是指通过计算机程序模拟人类智能的一门科学。自20世纪50年代诞生以来,人工智能经历了多次起伏。"
# 4.开始切割
texts = text_splitter.split_text(text)
# 打印分割结果
print(f"原始文本被分割成了 {len(texts)} 个块:")
for i, chunk in enumerate(texts):
print(f"块 {i+1}: 长度:{len(chunk)} 内容:{chunk}")
print("-" * 50)
其他分割器
SemanticChunker:语义分块
SemanticChunking(语义分块)是 LangChain 中一种更高级的文本分割方法,它超越了传统的基于字符或固定大小的分块方式,而是根据文本的语义结构进行智能分块,使每个分块保持语义完整性 ,从而 提高检索增强生成(RAG)等应用的效果。
HTMLHeaderTextSplitter:Split by HTML header
HTMLHeaderTextSplitter是一种专门用于处理HTML文档的文本分割方法,它根据HTML的 标题标签 (如<h1>、<h2>等) 将文档划分为逻辑分块,同时保留标题的层级结构信息。
CodeTextSplitter:Split code
CodeTextSplitter是一个专为代码文件设计的文本分割器(Text Splitter),支持代码的语言包括['cpp', 'go', 'java', 'js', 'php', 'proto', 'python', 'rst', 'ruby', 'rust', 'scala', 'swift', 'markdown', 'latex', 'html', 'sol']。它能够根据编程语言的语法结构(如函数、类、代码块等)智能地拆分代码,保持代码逻辑的完整性。 与递归文本分割器(如RecursiveCharacterTextSplitter)不同,CodeTextSplitter 针对代码的特性进行了优化, 避免在函数或类的中间截断 。
MarkdownTextSplitter:md数据类型
因为Markdown格式有特定的语法,一般整体内容由 h1、h2、h3 等多级标题组织,所以 MarkdownHeaderTextSplitter的切分策略就是根据标题来分割文本内容 。
文档嵌入模型 Text Embedding Models
Text Embedding Models:文档嵌入模型,提供将文本编码为向量的能力,即文档向量化。 文档写入和用户查询匹配前都会先执行文档嵌入编码,即向量化。
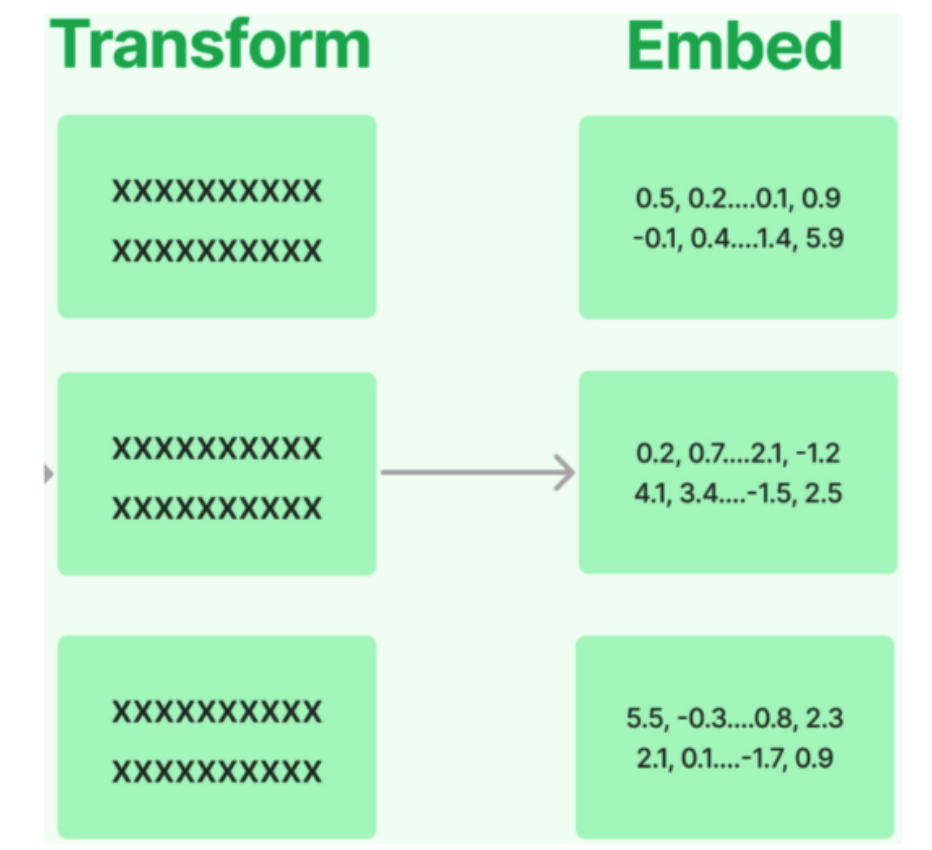
LangChain中针对向量化模型的封装提供了两种接口:
- 一种针对句子的向量化(embed_query)。
- 一种针对文档的向量化(embed_documents)。
句子的向量化(embed_query)
# 初始化嵌入模型
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
# 待嵌入的文本句子
text = "What was the name mentioned in the conversation?"
# 生成一个嵌入向量
embedded_query = embeddings_model.embed_query(text = text)
print(len(embedded_query))
print(embedded_query[:5])
文档的向量化(embed_documents)
# 初始化嵌入模型
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
# 待嵌入的文本列表
texts = [
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
# 生成嵌入向量
embeddings = embeddings_model.embed_documents(texts)
for i in range(len(texts)):
print(f"{texts[i]}:{embeddings[i][:3]}",end="\n\n")
embeddings_model = OpenAIEmbeddings(
model="text-embedding-3-large",
)
# 情况1:
loader = CSVLoader("./test.csv", encoding="utf-8")
docs = loader.load_and_split()
# 存放的是每一个chrunk的embedding。
embeded_docs = embeddings_model.embed_documents([doc.page_content for doc in docs])
print(len(embeded_docs))
# 表示的是每一个chrunk的embedding的维度
print(len(embeded_docs[0]))
print(embeded_docs[0][:10])
向量存储(Vector Stores)
将文本向量化之后,下一步就是进行向量的存储。这部分包含两块:
- 向量的存储 :将非结构化数据向量化后,完成存储
- 向量的查询 :查询时,嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。即具有相似性检索能力
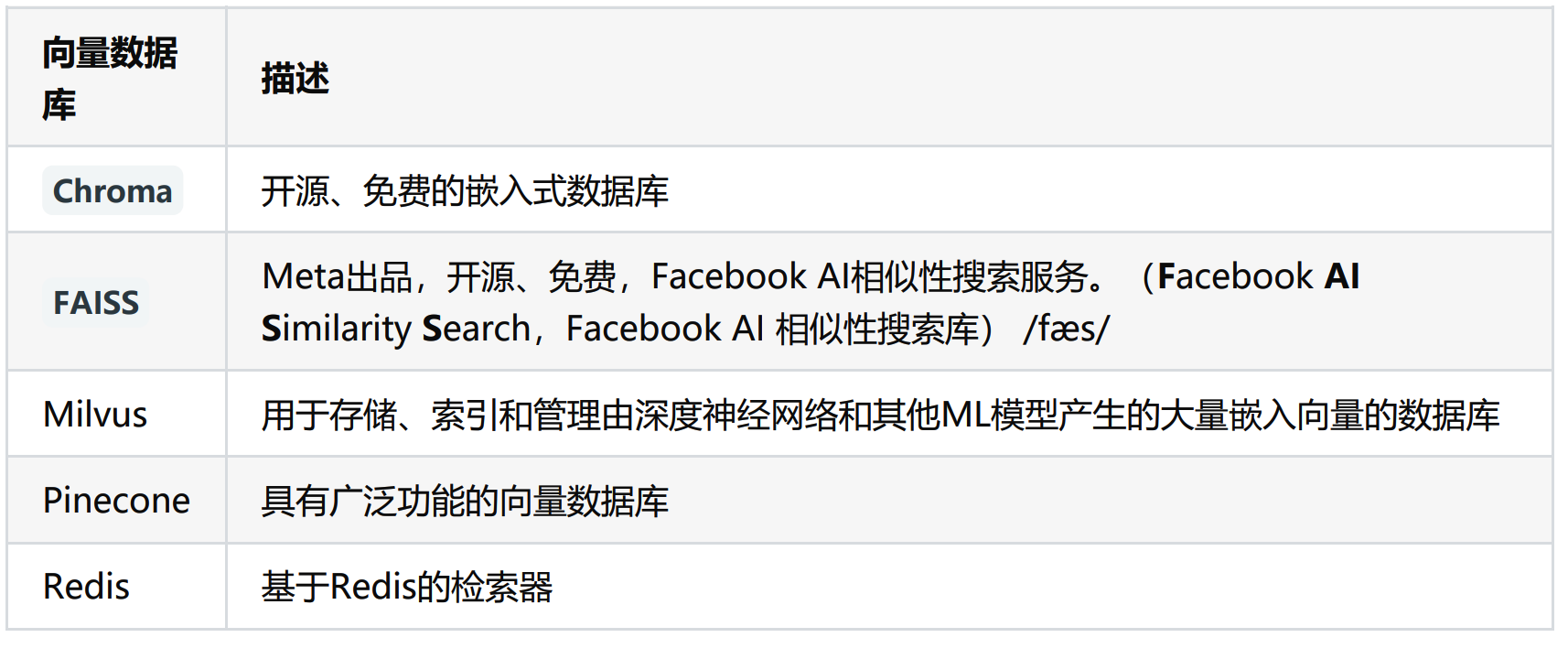
常用的向量数据库
LangChain提供了超过 50种 不同向量存储(Vector Stores)的集成,从开源的本地向量存储到云托管的私有向量存储,允许你选择最适合需求的向量存储。 LangChain支持的向量存储参考 VectorStore 接口和实现。
传统的关系型数据库 (如 MySQL、PostgreSQL 等)可以帮助你存储照片的元数据 ,比如拍摄时间、地点、相机型号等。但是,当你想要根据 照片的内容(如颜色、纹理、物体等) 进行搜索时,传统数据库将无法满足你的需求,因为它们通常以数据表的形式存储数据,并使用查询语句进行精确搜索。
向量数据库:构建一个多维的空间使得每张照片特征都存在于这个空间内,并用已有的维度进行表示,比如时间、地点、相机型号、颜色....此照片的信息将作为一个点,存储于其中。以此类推,即可在该空间中构建出无数的点,而后我们将这些点与空间坐标轴的原点相连接,就成为了一条条向量,当这些点变为向量之后,即可利用向量的计算进一步获取更多的信息。当要进行照片的检索时,也会变得更容易更快捷。
在向量数据库中进行检索时,检索并不是唯一的、精确的 ,而是查询和目标向量最为相似的一些向量 ,具有模糊性。
代码实现:
数据存储
使用向量数据库组件时需要同时传入包含 文本块的Document类对象 以及 文本向量化组件 ,向量数据库组件会自动完成将文本向量化的工作,并写入数据库中。
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 获取嵌入模型
my_embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
# 创建TextLoader实例,并加载指定的文档
loader = TextLoader("./test.txt", encoding='utf-8')
documents = loader.load()
# 创建文本拆分器
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
# 拆分文档
docs = text_splitter.split_documents(documents)
# 存储:将文档和数据存储到向量数据库中
db = Chroma.from_documents(docs, my_embedding)
# 查询:使用相似度查找
query = "人工智能的核心技术都有啥?"
docs = db.similarity_search(query)
print(docs[0].page_content)
Chroma主要有两种存储模式:内存模式 和 持久化模式。
当使用persist_directory参数时,数据会保存到指定目录;如果没有指定,则默认使用内存存储。
数据的检索
raw_documents= [
Document(
page_content="葡萄是一种常见的水果,属于葡萄科葡萄属植物。它的果实呈圆形或椭圆形,颜色有绿色、紫色、红色等多种。葡萄富含维生素C和抗氧化物质,可以直接食用或酿造成葡萄酒。",
metadata={"source": "水果", "type": "植物"}
),
Document(
page_content="白菜是十字花科蔬菜,原产于中国北方。它的叶片层层包裹形成紧密的球状,口感清脆微甜。白菜富含膳食纤维和维生素K,常用于制作泡菜、炒菜或煮汤。",
metadata={"source": "蔬菜", "type": "植物"}
)]
# 创建嵌入模型
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
# 创建向量数据库
db = Chroma.from_documents(
documents=raw_documents,
embedding=embedding,
persist_directory="./chroma-3",
)
# 检索示例(返回前3个最相关结果)
query = "哺乳动物"
docs = db.similarity_search(query, k=3) # k=3表示返回3个最相关文档
print(f"查询: '{query}' 的结果:")
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
相似性检索(similarity_search)
接收字符串作为参数
query = "哺乳动物"
docs = db.similarity_search(query, k=3) # k=3表示返回3个最相关文档
print(f"查询: '{query}' 的结果:")
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
支持直接对问题向量查询(similarity_search_by_vector)
搜索与给定嵌入向量相似的文档,它接受嵌入向量作为参数,而不是字符串
query = "哺乳动物"
embedding_vector = embedding.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector, k=3)
print(f"查询: '{query}' 的结果:")
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
相似性检索,支持过滤元数据(filter)
query = "哺乳动物"
docs = db.similarity_search(
query=query,
k=3,
filter={"source": "动物"})
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
通过L2距离分数进行搜索(similarity_search_with_score)
分数值越小,检索到的文档越和问题相似。分值取值范围:[0,正无穷]
docs = db.similarity_search_with_score(
"量子力学是什么?"
)
for doc, score in docs:
print(f" [L2距离得分={score:.3f}] {doc.page_content} [{doc.metadata}]")
通过余弦相似度分数进行搜索(_similarity_search_with_relevance_scores)
分数值越接近1(上限),检索到的文档越和问题相似。
docs = db._similarity_search_with_relevance_scores(
"量子力学是什么?"
)
for doc, score in docs:
print(f"* [余弦相似度得分={score:.3f}] {doc.page_content} [{doc.metadata}]")
MMR(最大边际相关性,max_marginal_relevance_search)
MMR 是一种平衡 相关性 和 多样性 的检索策略,避免返回高度相似的冗余结果。
lambda_mult 参数值介于 0 到 1 之间,用于确定结果之间的多样性程度,其中 0 对应最大多样性,1 对应最小多样性。默认值为 0.5。
docs = db.max_marginal_relevance_search(
query="量子力学是什么",
lambda_mult=0.8, # 侧重相似性
)
print("关于【量子力学是什么】的搜索结果:")
print("=" * 50)
for i, doc in enumerate(docs):
print(f"\n 结果 {i+1}:")
print(f"内容: {doc.page_content}")
print(f"标签: {', '.join(f'{k}={v}' for k, v in doc.metadata.items())}")
检索器(召回器) Retrievers
向量数据库本身已经包含了实现召回功能的函数方法 ( similarity_search )。该函数通过计算原始查询向量与数据库中存储向量之间的相似度来实现召回。
LangChain还提供了更加复杂的召回策略 ,这些策略被集成在Retrievers(检索器或召回器)组件中。 Retrievers(检索器)是一种用于从大量文档中检索与给定查询相关的文档或信息片段的工具。检索器不需要存储文档 ,只需要返回(或检索)文档即可。
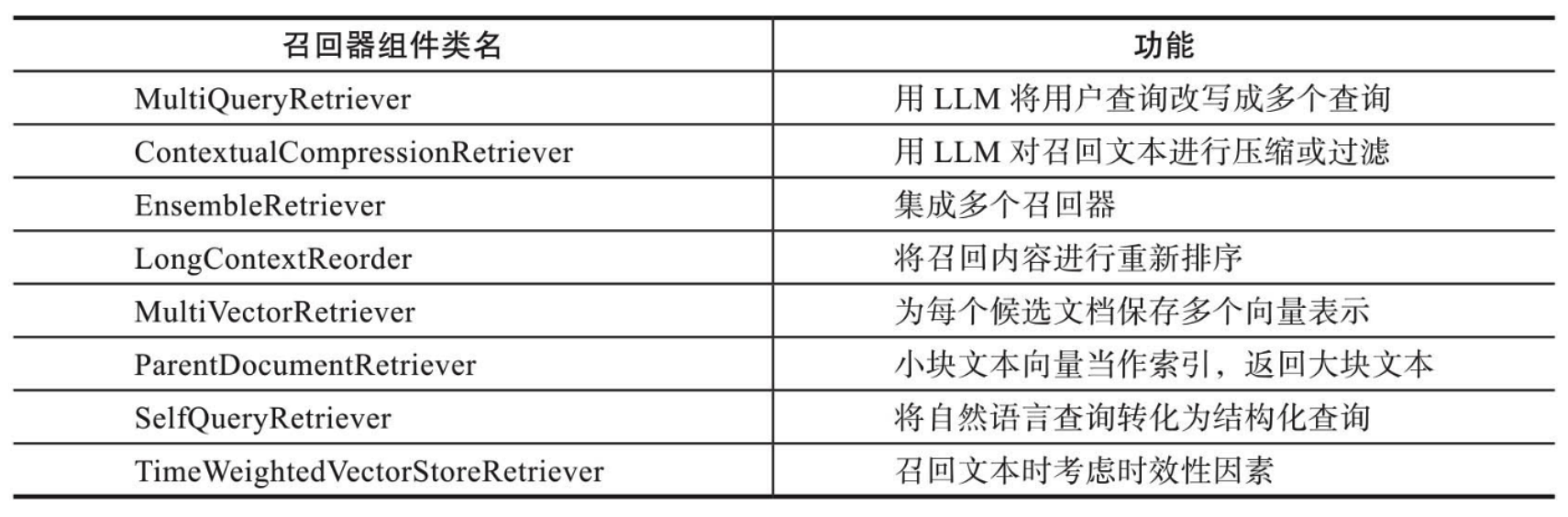
Retrievers 的执行步骤:
- 步骤1:将输入查询转换为向量表示。
- 步骤2:在向量存储中搜索与查询向量最相似的文档向量(通常使用余弦相似度或欧几里得距离等度量方 法)。
- 步骤3:返回与查询最相关的文档或文本片段,以及它们的相似度得分。
代码实现
# Retriever 一般和 VectorStore 配套实现,通过 as_retriever() 方法获取。
#从向量数据库中得到检索器
retriever = db.as_retriever()
# 使用检索器检索
docs = retriever.invoke("深度学习是什么?")
# 得到结果
for doc in docs:
print(f"⭐{doc}")
使用相关检索策略
默认检索器使用相似性搜索
# 获取检索器
retriever = db.as_retriever(search_kwargs={"k": 4}) #这里设置返回的文档数
docs = retriever.invoke("经济政策")
for i, doc in enumerate(docs):
print(f"\n结果 {i+1}:\n{doc.page_content}\n")
分数阈值查询
只有相似度超过这个值才会召回
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.1}
)
docs = retriever.invoke("经济政策")
for doc in docs:
print(f"📌 内容: {doc.page_content}")
MMR搜索
MMR(Maximal Marginal Relevance)通过优化评分函数实现相关性与多样性的权衡
retriever = db.as_retriever(
search_type="mmr",
# search_kwargs={"fetch_k":2}
)
docs = retriever.invoke("经济政策")
print(len(docs))
for doc in docs:
print(f"内容: {doc.page_content}")
结合LLM
# 获取检索器
retriever = vectorstore.as_retriever()
docs = retriever.invoke("北京有什么著名的建筑?")
# 创建Runnable链 结合LLM
chain = prompt | llm
# 提问
result = chain.invoke(input={"question":"北京有什么著名的建筑?","context":docs})
print("\n回答:", result.content)
本文来自博客园,作者:Rodericklog,转载请注明原文链接:https://www.cnblogs.com/rodericklog/articles/19457014

 浙公网安备 33010602011771号
浙公网安备 33010602011771号