[AI应用基础学习-4] LangChain-Memory
模型本身是不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。在 LangChain 中,提供记忆功能的模块就称为 Memory(记忆) ,用于存储用户和模型交互的历史信息。
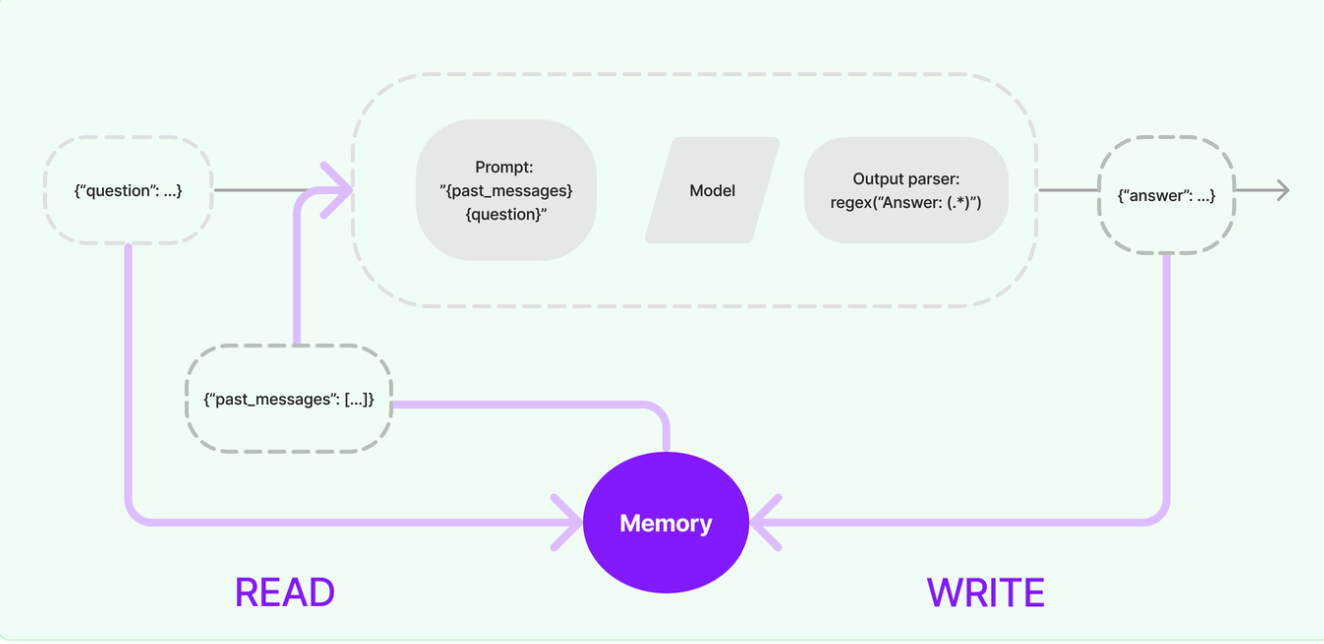
基础Memory模块的使用
基础Memory模块的使用
- 层次1(最直接的方式):保留一个聊天消息列表
- 层次2(简单的新思路):只返回最近交互的k条消息
- 层次3(稍微复杂一点):返回过去k条消息的简洁摘要
- 层次4(更复杂):从存储的消息中提取实体,并且仅返回有关当前运行中引用的实体的信息
ChatMessageHistory
ChatMessageHistory是一个用于存储和管理对话消息的基础类,它直接操作消息对象(如 HumanMessage, AIMessage 等),是其它记忆组件的底层存储工具。
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_community.chat_message_histories import ChatMessageHistory
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
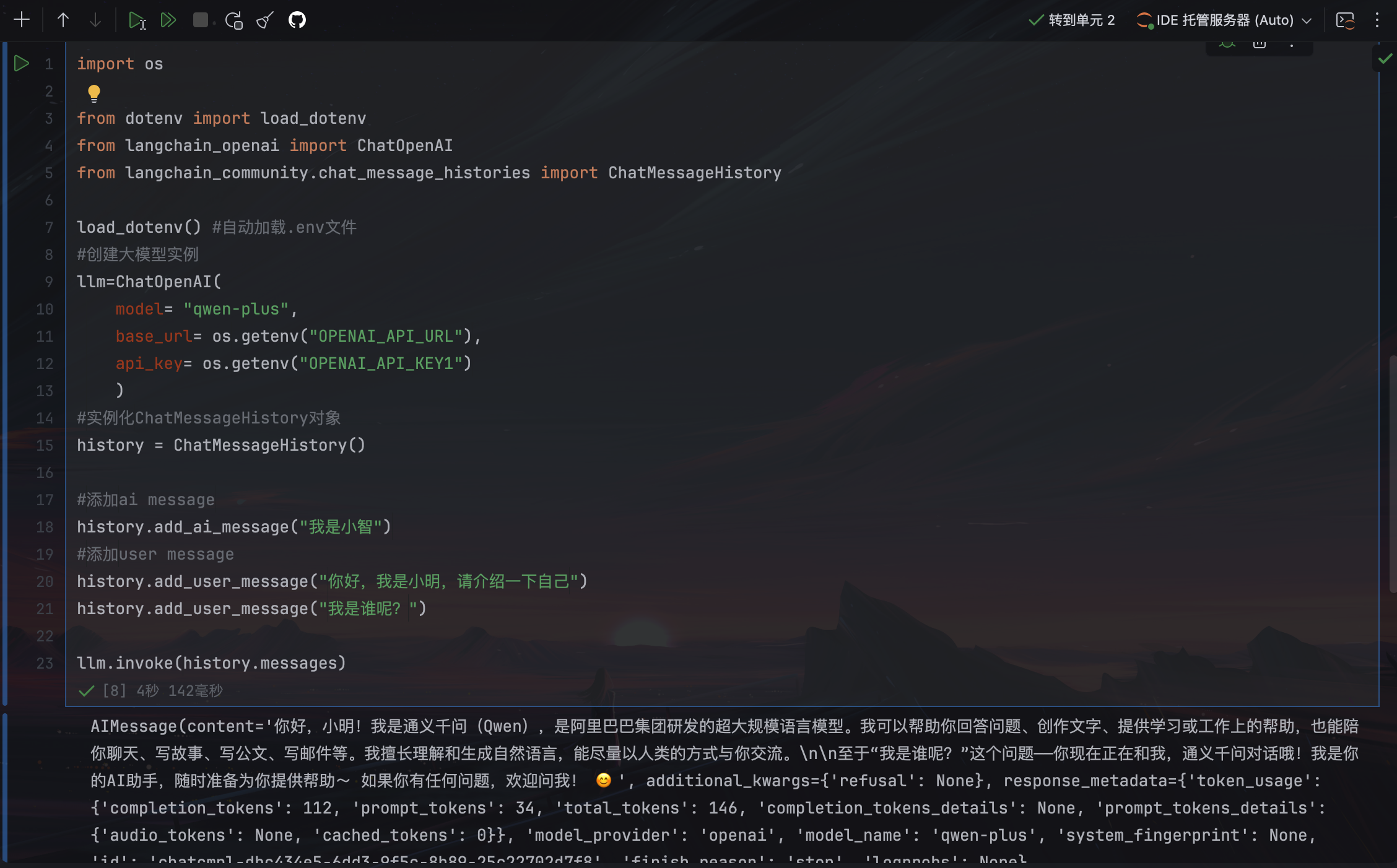
#实例化ChatMessageHistory对象
history = ChatMessageHistory()
#添加ai message
history.add_ai_message("我是小智")
#添加user message
history.add_user_message("你好,我是小明,请介绍一下自己")
history.add_user_message("我是谁呢?")
llm.invoke(history.messages)
ConversationBufferMemory
ConversationBufferMemory是一个基础的对话记忆组件,专门用于按原始顺序存储完整的对话历史。
适用场景:对话轮次较少、依赖完整上下文的场景(如简单的聊天机器)
return_messages=True:返回消息对象列表
return_messages=False(默认):返回拼接的纯文本字符串
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_classic.memory import ConversationBufferMemory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_classic.chains.llm import LLMChain
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
#创建prompt
prompt = ChatPromptTemplate.from_messages([
("system","你是一个与人类对话的机器人"),
MessagesPlaceholder(variable_name="history"),
("human","问题:{question}")
])
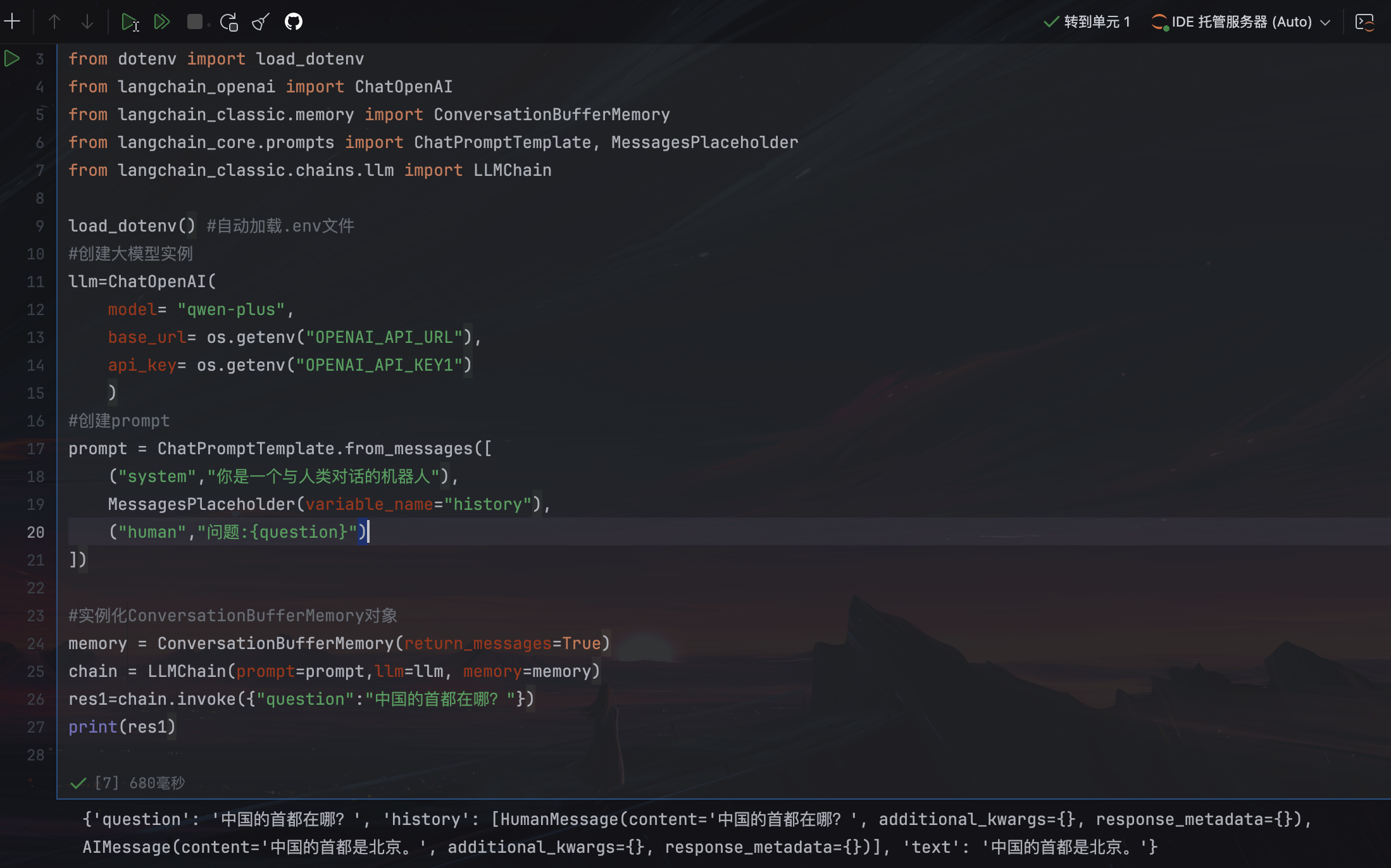
#实例化ConversationBufferMemory对象
memory = ConversationBufferMemory(return_messages=True)
#使用chain连接
chain = LLMChain(prompt=prompt,llm=llm, memory=memory)
res1=chain.invoke({"question":"中国的首都在哪?"})
print(res1)
普通 PromptTemplate:仅执行后存储,首次调用仅显示问题,内部消息类型拼接字符串
ChatPromptTemplate:执行前存储用户输入 + 执行后存储输出,首次调用显示问题+答案,内部消息类型List[BaseMessage]
ConversationChain
ConversationChain实际上是就是对 ConversationBufferMemory 和LLMChain进行了封装,并且提供一个默认格式的提示词模版,从而简化了初始化ConversationBufferMemory的步骤。
使用PromptTemplate
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_classic.chains.conversation.base import ConversationChain
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
template = """
以下是人类与AI之间的友好对话描述。Al表现得很健谈,并提供了大量来自其上下立的具体细节。如果AI不知道问题的答案,它会真诚地表示不知道。
当前对话:
{history}
Human:{input}
AI:
"""
prompt = PromptTemplate.from_template(template)
chain = ConversationChain(llm=llm, prompt=prompt,verbose=True)
chain.invoke({"input":"你好,你的名字是小智"})

ConversationBufferWindowMemory
在了解了ConversationBufferMemory记忆类后,我们知道了它能够无限的将历史对话信息填充到 History中,从而给大模型提供上下文的背景。但这会导致内存量十分大,并且消耗token数非常多的,此外,每个大模型都存在最大输入的Token限制。
LangChain 给出的解决方式是: ConversationBufferWindowMemory模块。该记忆类会保存一段时间内的对话交互的列表,仅使用最近的K个交互。这样就使缓存区不会变得太大。
return_messages=True:返回消息对象列表
return_messages=False(默认):返回拼接的纯文本字符串
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_classic.chains.conversation.base import ConversationChain
from langchain_classic.memory import ConversationBufferWindowMemory
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
template = """
以下是人类与AI之间的友好对话描述。Al表现得很健谈,并提供了大量来自其上下立的具体细节。如果AI不知道问题的答案,它会真诚地表示不知道。
当前对话:
{history}
Human:{input}
AI:
"""
prompt = PromptTemplate.from_template(template)
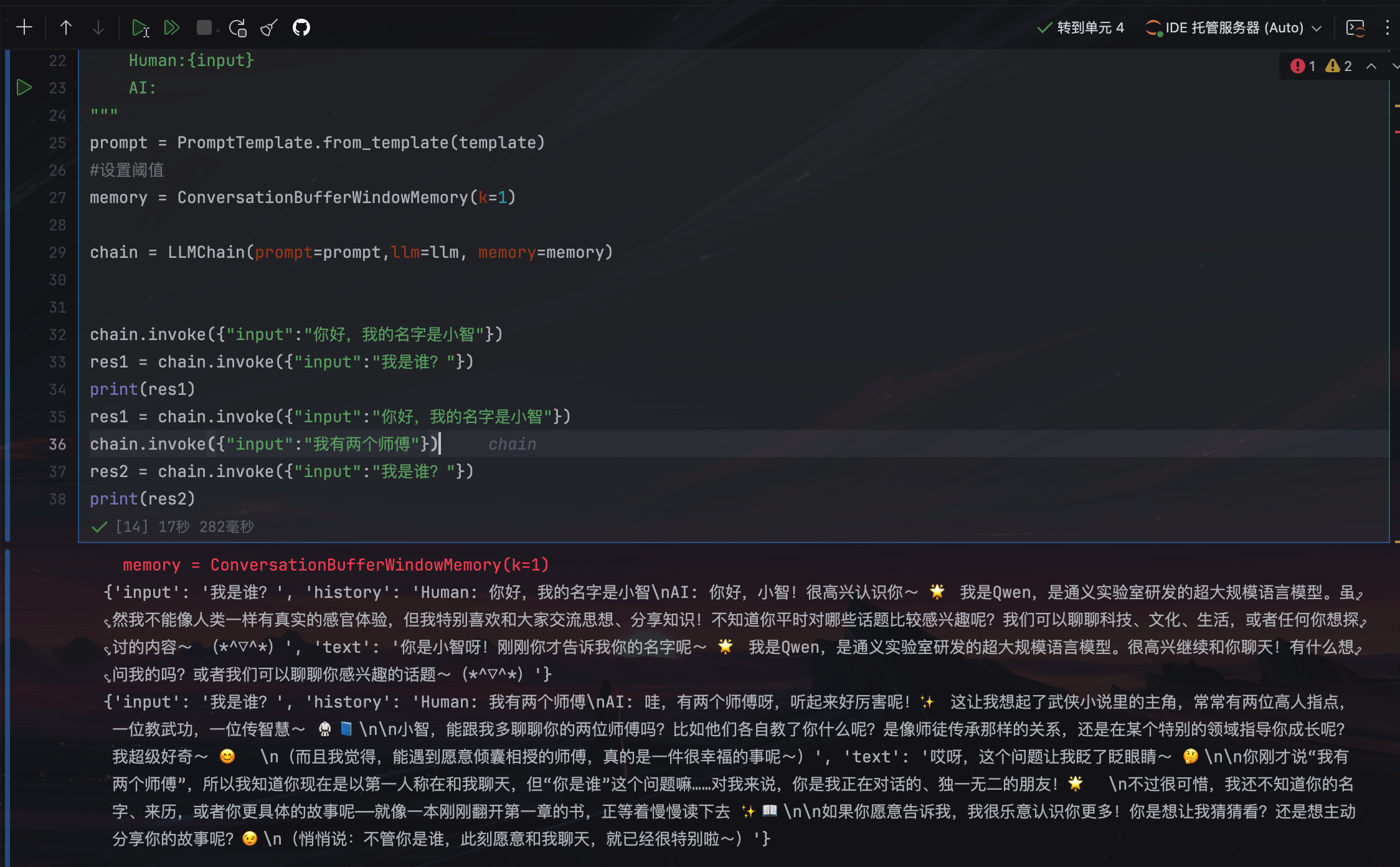
#设置阈值1,只记录上一个对话
memory = ConversationBufferWindowMemory(k=1)
chain = LLMChain(prompt=prompt,llm=llm, memory=memory)
chain.invoke({"input":"你好,我的名字是小智"})
res1 = chain.invoke({"input":"我是谁?"})
print(res1)
res1 = chain.invoke({"input":"你好,我的名字是小智"})
chain.invoke({"input":"我有两个师傅"})
res2 = chain.invoke({"input":"我是谁?"})
print(res2)
其他Memory模块
ConversationTokenBufferMemory 是 LangChain 中一种基于Token数量限制的对话记忆机制。如果 字符数量超出指定数目,它会切掉这个对话的早期部分,以保留与最近的交流相对应的字符数量。
ConversationSummaryMemory是 LangChain 中一种智能压缩对话历史的记忆机制,它通过大语言模型(LLM)自动生成对话内容的精简摘要,而不是存储原始对话文本。
ConversationSummaryBufferMemory 是 LangChain 中一种混合型记忆机制,它结合了 ConversationBufferMemory(完整对话记录)和 ConversationSummaryMemory(摘要记忆)的优点,在保留最近对话原始记录的同时,对较早的对话内容进行智能摘要。
memory = ConversationSummaryBufferMemory(
llm=llm, max_token_limit=40, return_messages=True
)
ConversationEntityMemory 是一种基于实体的对话记忆机制,它能够智能地识别、存储和利用对话中 出现的实体信息(如人名、地点、产品等)及其属性/关系,并结构化存储,使 AI 具备更强的上下文理 解和记忆能力。
ConversationKGMemory是一种基于知识图谱(Knowledge Graph)的对话记忆模块,它比 ConversationEntityMemory 更进一步,不仅能识别和存储实体,还能捕捉实体之间的复杂关系,形成结构化的知识网络。
VectorStoreRetrieverMemory是一种基于向量检索的先进记忆机制,它将对话历史存储在向量数据库中,通过语义相似度检索相关信息,而非传统的线性记忆方式。每次调用时,就会查找与该记忆关联最高的k个文档。
本文来自博客园,作者:Rodericklog,转载请注明原文链接:https://www.cnblogs.com/rodericklog/articles/19455069

 浙公网安备 33010602011771号
浙公网安备 33010602011771号