[AI应用基础学习-2] LangChain-Model I/O
https://docs.langchain.com/oss/python/langchain/models
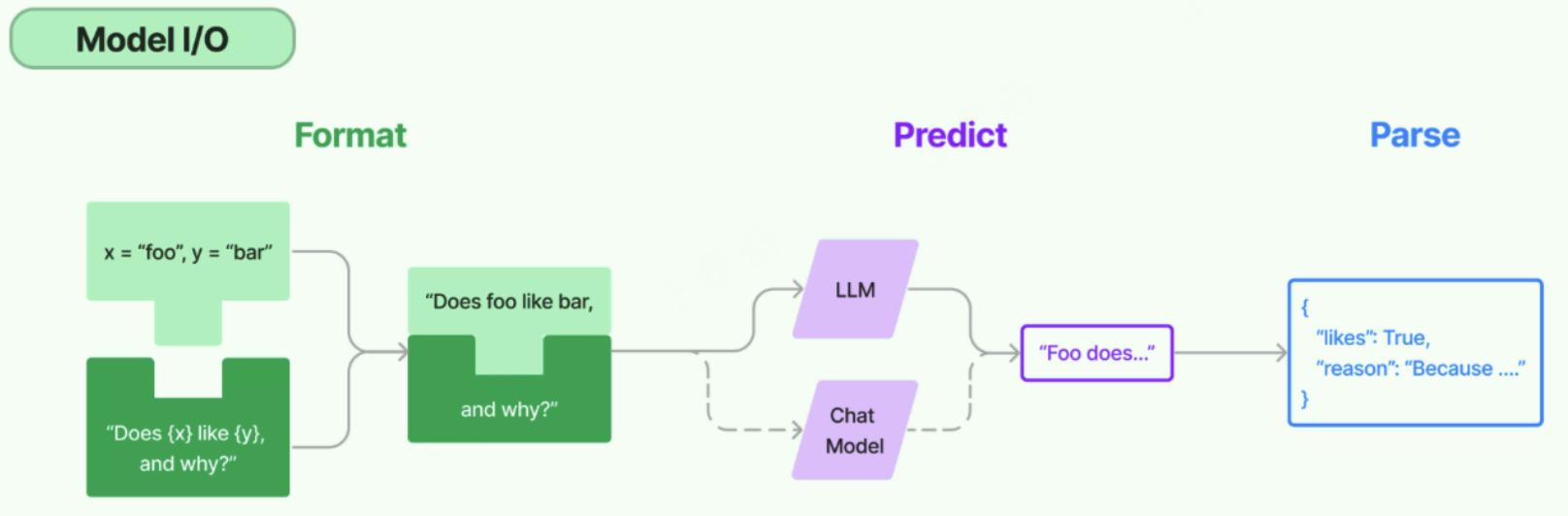
Model I/O 模块是与语言模型(LLMs)进行交互的核心组件 ,在整个框架中有着很重要的地位。 所谓的Model I/O,包括输入提示(Format)、调用模型(Predict)、输出解析(Parse)。分别对应着
Prompt Template , Model 和 Output Parser 。
Model I/O之调用模型1
LangChain作为一个“工具”,不提供任何 LLMs,而是依赖于第三方集成各种大模型。比如,将 OpenAI、Anthropic、Hugging Face 、LlaMA、阿里Qwen、ChatGLM等平台的模型无缝接入应用。
大模型分类:非对话模型(LLMs、Text Model)、对话模型(Chat Models)、嵌入模型(Embedding Models)
模型调用时,几个重要参数的书写位置的不同:
- 硬编码:写在代码文件中
- 使用环境变量
- 使用配置文件
具体调用的 API:
- OpenAI提供的API
- 其它大模型自家提供的API
- LangChain的统一方式调用API(推荐)
模型分类
类型1:LLMs(非对话模型)
LLMs,也叫Text Model、非对话模型,是许多语言模型应用程序的支柱。主要特点如下:
- 输入:接受
文本字符串 或PromptValue对象 - 输出:总是返回
文本字符串 - 适用场景:仅需单次文本生成任务(如摘要生成、翻译、代码生成、单次问答)或对接不支持消息结构的旧模型(如部分本地部署模型)
- 不支持多轮对话上下文。每次调用独立处理输入,无法自动关联历史对话(需手动拼接历史文本)。
- 局限性:无法处理角色分工或复杂对话逻辑。
#OpenAI
llm = OpenAI()
str = llm.invoke("写一首关于春天的诗")
print(str)
类型2:Chat Models(对话模型)
ChatModels,也叫聊天模型、对话模型,底层使用LLMs。大语言模型调用,以 ChatModel 为主!
- 输入:接收消息列表
List[BaseMessage]或PromptValue,每条消息需指定角色(如 SystemMessage、HumanMessage、AIMessage) - 输出:总是返回带角色的
消息对象 (BaseMessage子类),通常是AIMessage - 原生支持多轮对话。通过消息列表维护上下文(例如: [SystemMessage,HumanMessage,AIMessage,...]),模型可基于完整对话历史生成回复。
- 适用场景:对话系统(如客服机器人、长期交互的AI助手)
#ChatOpenAI
chat_model = ChatOpenAI(model="qwen-plus")
messages = [
SystemMessage(content= HumanMessage(content="我是智能助手,我叫小智"),
HumanMessage(content="你好,我是小明,很高兴认识你")]
response = chat_model.invoke(messages)
print(type(response))
print(response.content)
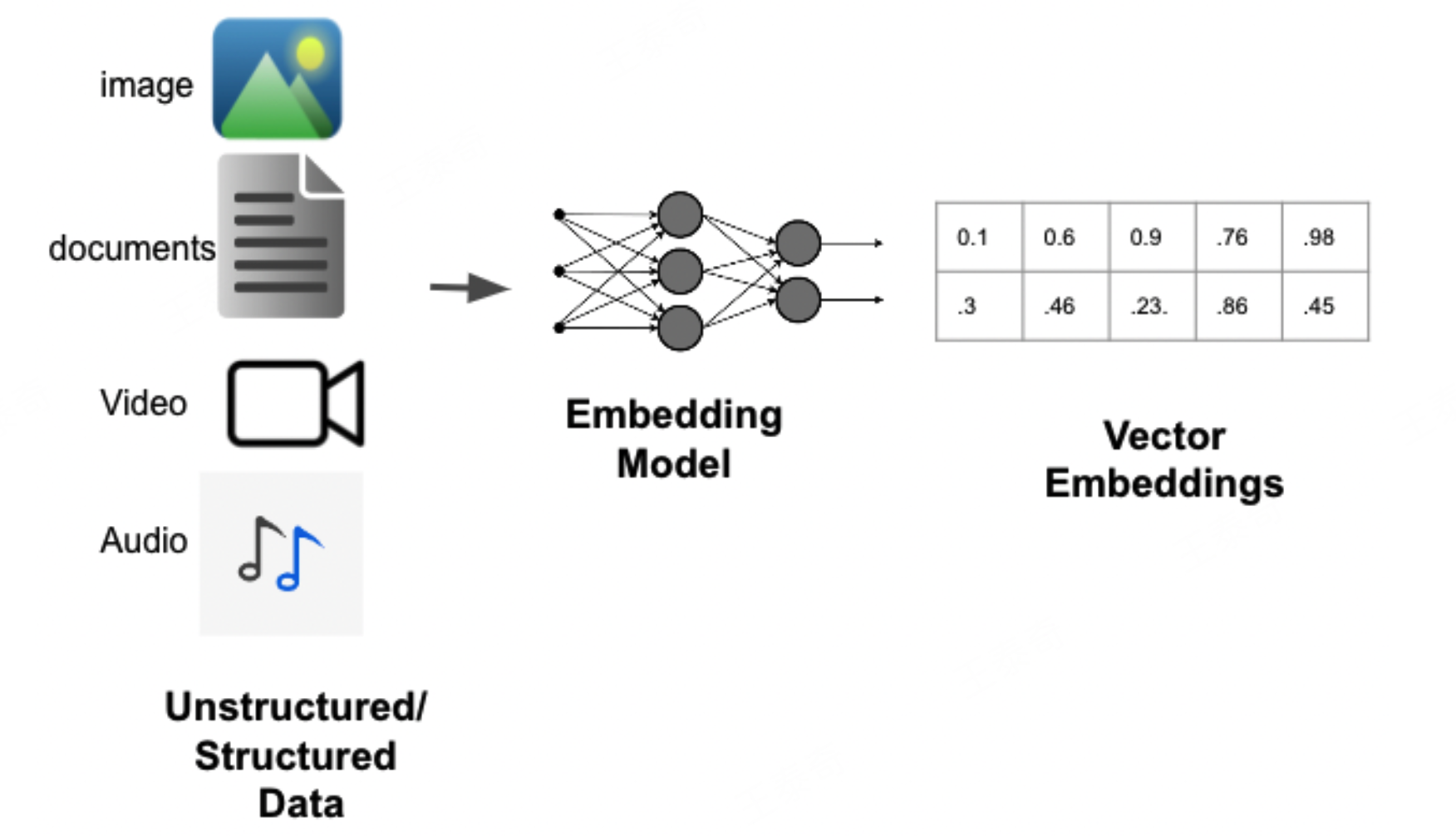
类型3:Embedding Model(嵌入模型)
Embedding Model:也叫文本嵌入模型,这些模型将文本作为输入并返回浮点数列表,也就是Embedding。
#调用嵌入模型 OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(
model= "text-embedding-v4",
)
res1 = embeddings_model.embed_query('我是文档中的数据')
print(res1)
连接模型
连接参数
模型调用的主要方法及参数:
OpenAI() /ChatOpenAI():创建模型model.invoke(xxx):调用,将用户输入发送给模型response.content:提取模型返回的内容
必须设置的参数:
base_url:API 服务地址api_key:身份认证密钥model/model_name:指定模型
其他参数:
-
temperature:温度,控制模型的随机性,0-1。值越低越保守。- 精确模式 0.5。生成的文本更加安全可靠,但可能缺乏创意和多样性。
- 平衡模式 0.8。生成的文本通常既有一定的多样性,又能保持较好的连贯性和准确性。
- 创意模式 1。生成的文本更有创意,但也更容易出现语法错误或不合逻辑的内容。
-
max_tokens:限制生成文本的最大长度,防止输出过长。 -
max_tokens设置建议:- 客服短回复:128-256。
- 常规对话、多轮对话:512-1024
- 长内容生成:1024-4096。
token是什么?
基本单位:大模型处理文本的最小单位是token(相当于自然语言中的词或字),输出时逐个token 依次生成。模型提供商算钱的依据。
连接方式
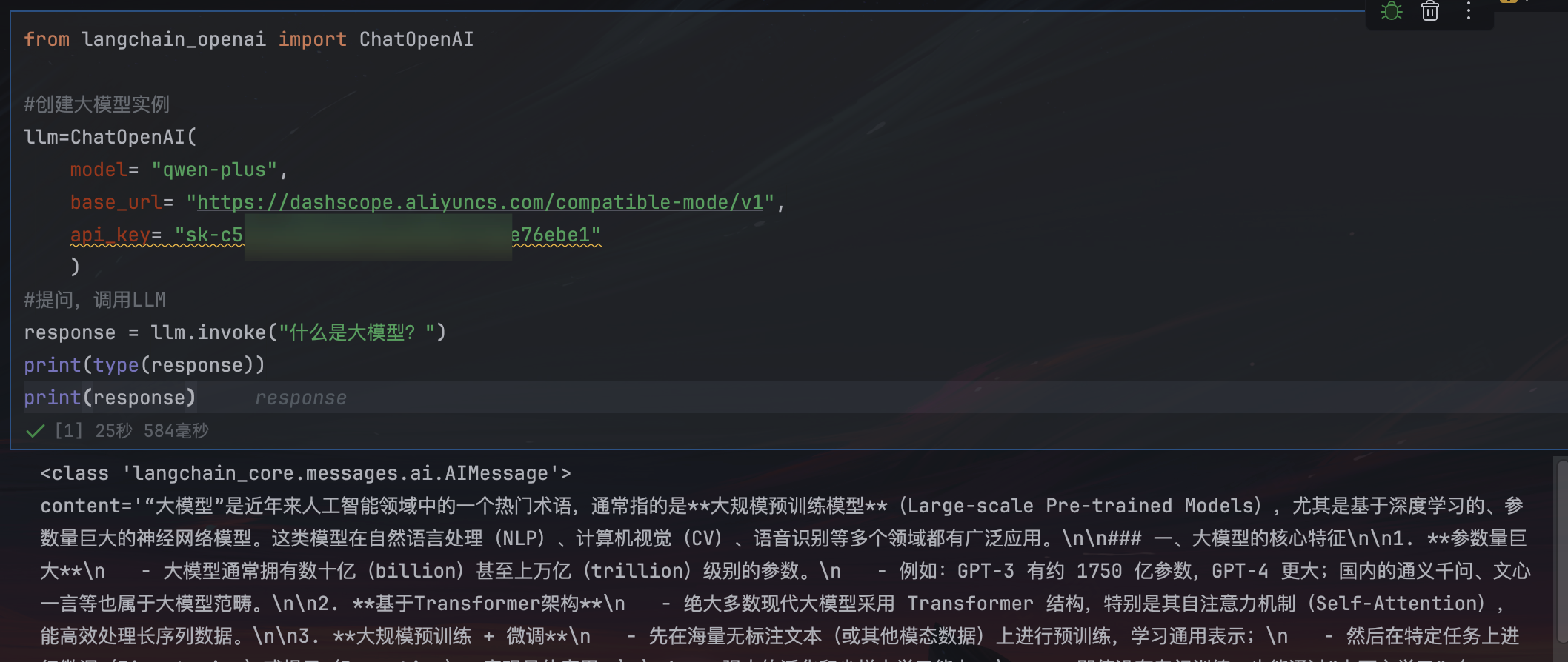
方式1:硬编码
直接将 API Key 和模型参数写入代码,仅适用于临时测试,存在密钥泄露风险。
from langchain_openai import ChatOpenAI
#创建大模型实例,硬编码连接大模型
llm=ChatOpenAI(
model= "qwen-plus",
base_url= "https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key= "sk-xxxxxxx"
)
#提问,调用LLM
response = llm.invoke("什么是大模型?")
print(type(response))
print(response)
方式2:配置环境变量
通过系统环境变量存储密钥,避免代码明文暴露。
#直接终端设置(临时生效)
export OPENAI_API_KEY= "sk-xxxx" #linux/mac
set OPENAI_API_KEY= "sk-xxxx" #windows
从 PyCharm中设置
配置环境变量后,需要在 py文件中执行,jupyter不合适使用环境变量执行
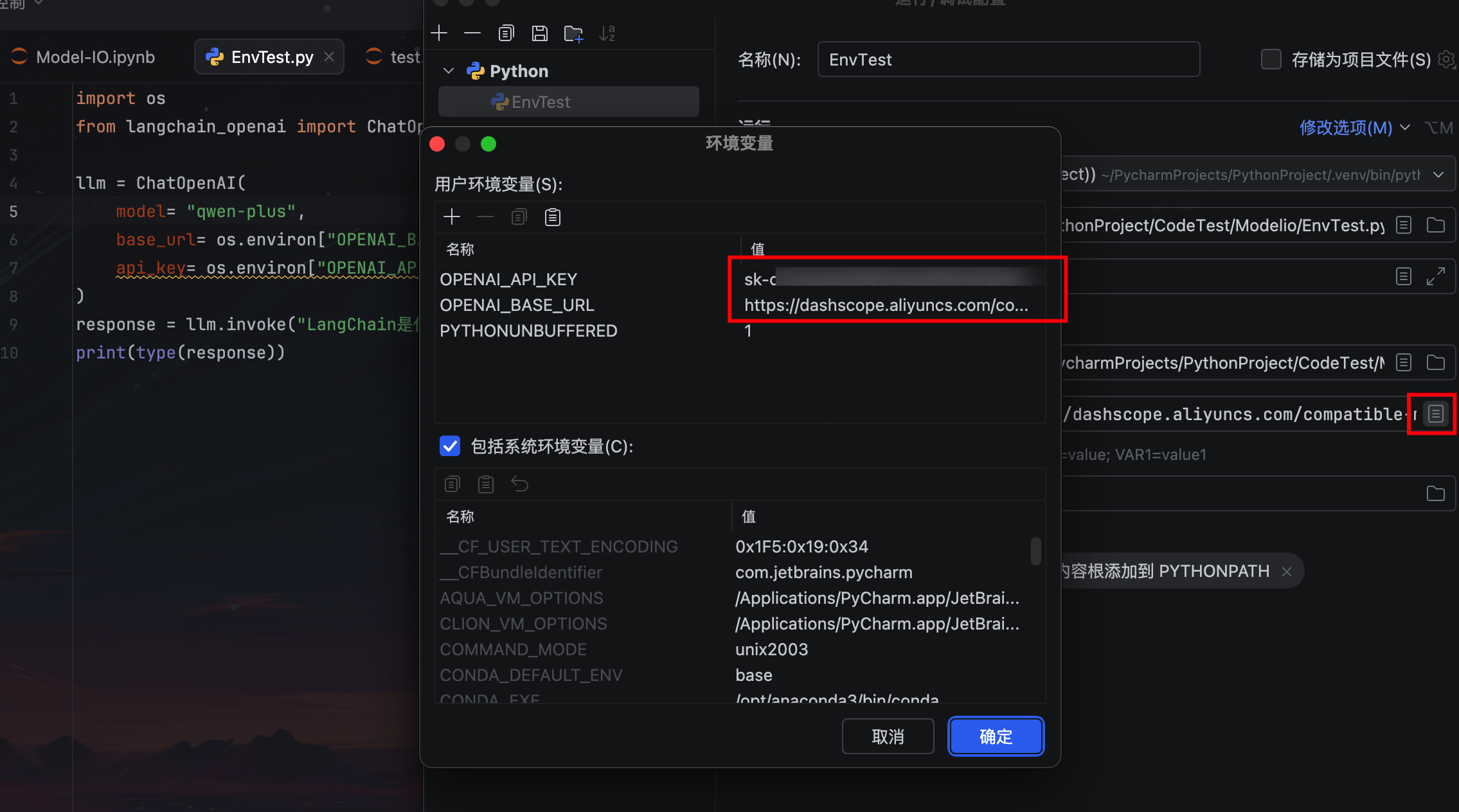
import os
from langchain_openai import ChatOpenAI
print(os.environ.get("OPENAI_API_KEY"))
print(os.environ.get("OPENAI_BASE_URL"))
llm = ChatOpenAI(
model= "qwen-plus",
base_url= os.environ["OPENAI_BASE_URL"],
api_key= os.environ["OPENAI_API_KEY"]
)
response = llm.invoke("LangChain是什么?")
print(type(response))
print(response)

方式3:使用.env配置文件
使用python-dotenv加载本地配置文件,支持多环境管理(开发/生产)。(推荐)
pip install python-dotenv
创建 .env 文件(项目根目录)
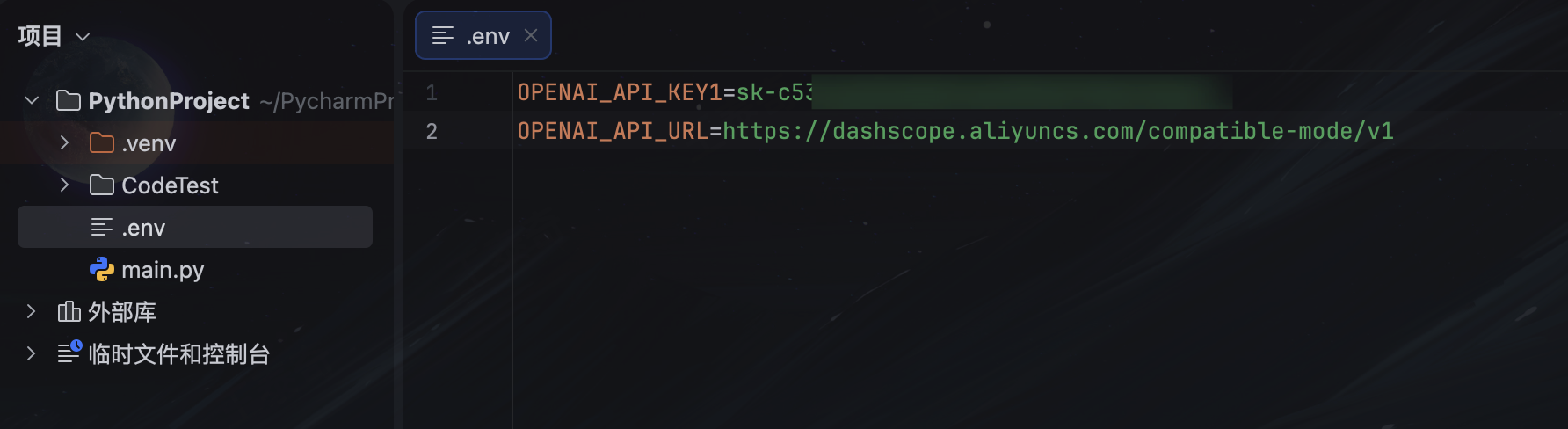
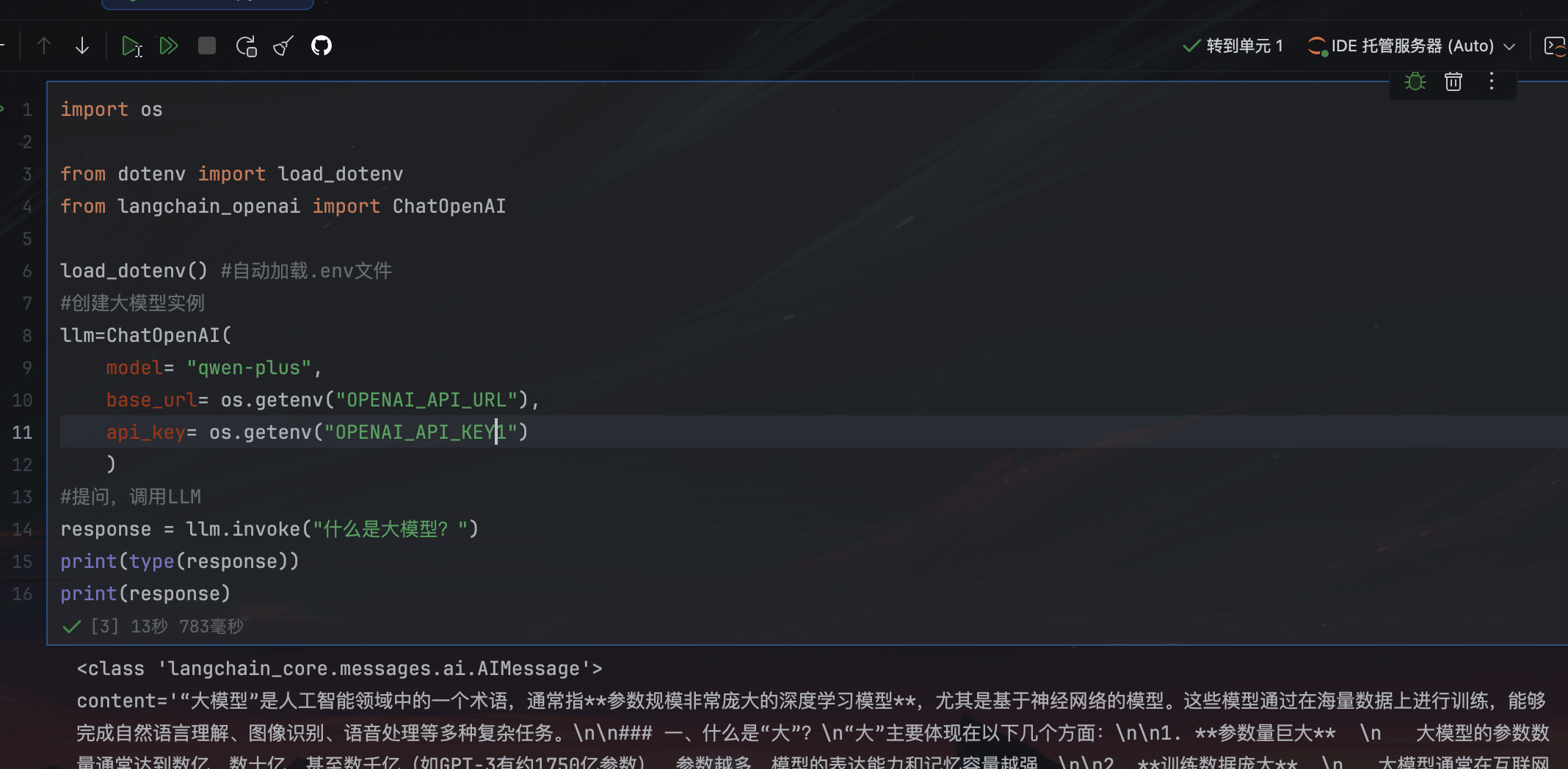
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
#提问,调用LLM
response = llm.invoke("什么是大模型?")
print(type(response))
print(response)
核心优势:
- 配置文件可加入 .gitignore 避免泄露
- 结合 LangChain 可扩展其它模型(如 DeepSeek、阿里云)
大模型平台
CloseAI :https://www.closeai-asia.com/
百度千帆:https://cloud.baidu.com/doc/qianfan-docs/s/Mm8r1mejk
阿里百炼:https://bailian.console.aliyun.com/#/home
智谱GLM:https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys
硅基流动:https://www.siliconflow.cn/
Model I/O之调用模型2
对话模型的Message(消息)
聊天模型,除了将字符串作为输入外,还可以使用聊天消息作为输入,并返回聊天消息作为输出。
消息类型:
SystemMessage:设定AI行为规则或背景信息。比如设定AI的初始状态、行为模式或对话的总 体目标。比如“作为一个代码专家”,或者“返回json格式”。通常作为输入消息序列中的第一个 传递。HumanMessage:表示来自用户输入。比如“实现 一个快速排序方法”AIMessage:存储AI回复的内容。这可以是文本,也可以是调用工具的请求ChatMessage:可以自定义角色的通用消息类型FunctionMessage /ToolMessage:函数调用/工具消息,用于函数调用结果的消息类型
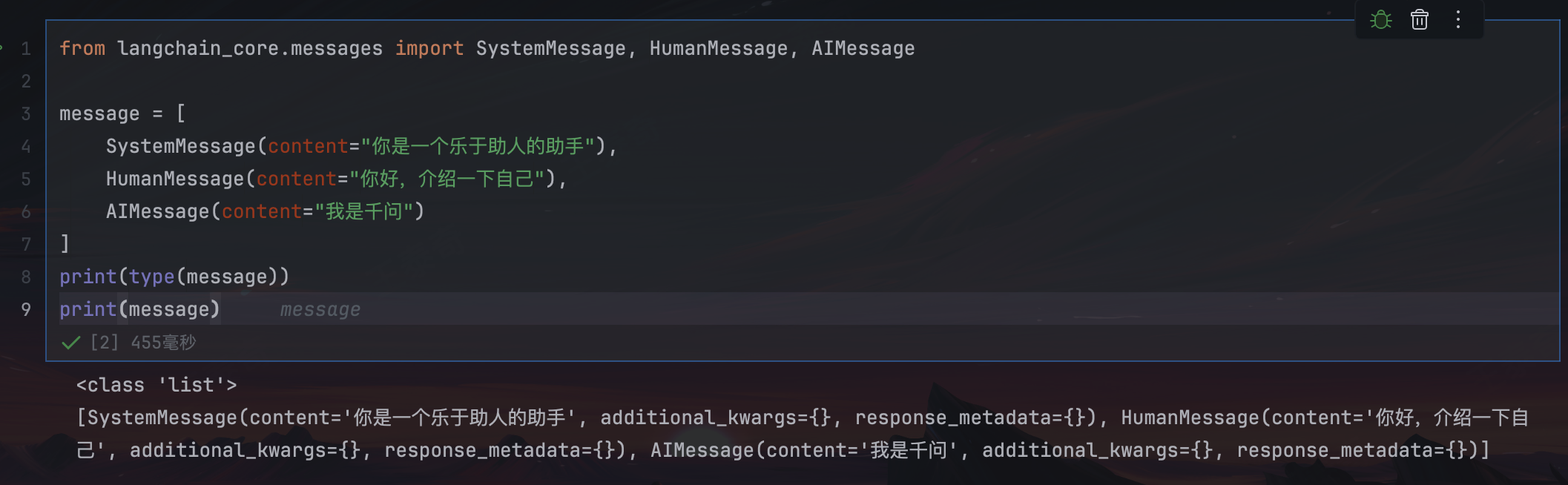
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
message = [
SystemMessage(content="你是一个乐于助人的助手"),
HumanMessage(content="你好,介绍一下自己"),
AIMessage(content="我是千问")
]
print(type(message))
print(message)
结合大模型
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
message = [
SystemMessage(content="你是一个人工智能专家"),
HumanMessage(content="解释一下机器学习是什么?")
]
#提问,调用LLM
response = llm.invoke(message)
print(type(response))
print(response.content)

多轮对话与上下文记忆
大模型默认没有记忆上下文的能力,第二个问题还是回答千问。
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
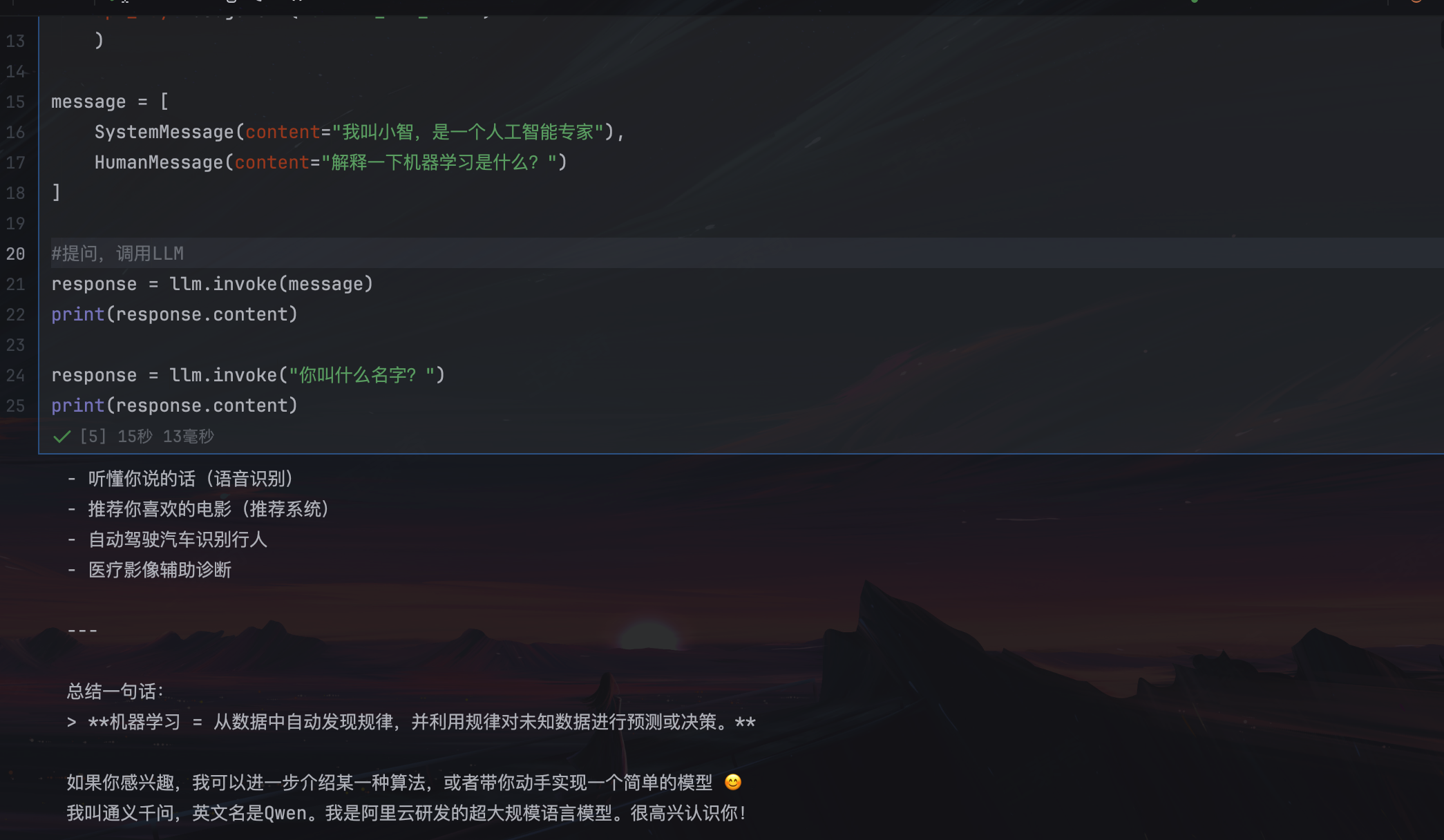
message = [
SystemMessage(content="我叫小智,是一个人工智能专家"),
HumanMessage(content="解释一下机器学习是什么?")
]
#提问,调用LLM
response = llm.invoke(message)
print(response.content)
response = llm.invoke("你叫什么名字?")
print(response.content)
#测试二
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
sys_message = SystemMessage(content="我叫小智,是一个人工智能专家")
human_message = HumanMessage(content="解释一下机器学习是什么?")
human_message1 = HumanMessage(content="你叫什么名字?")
message = [sys_message, human_message,human_message1]
#提问,调用LLM
response = llm.invoke(message)
print(response.content)
#输出只会回答第一个human_message
#测试三
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
sys_message = SystemMessage(content="我叫小智,是一个人工智能专家")
human_message = HumanMessage(content="解释一下机器学习是什么?")
sys_message1 = SystemMessage(content="我可以做很多事情,有需要可以找我")
human_message1 = HumanMessage(content="你叫什么名字?")
message = [sys_message, human_message, sys_message1, human_message1]
#提问,调用LLM
response = llm.invoke(message)
print(response.content)
#同样最后一个human_message1 没有响应
模型调用的方法
为了尽可能简化自定义链的创建,我们实现了一个"Runnable"协议。许多LangChain组件实现了 Runnable 协议,包括聊天模型、提示词模板、输出解析器、检索器、代理(智能体)等。
Runnable 定义的公共的调用方法如下:
- invoke:处理单条输入,等待LLM完全推理完成后再返回调用结果
- stream:流式响应,逐字输出LLM的响应结果
- batch:处理批量输入
流式输出与非流式输出
非流式输出:这是Langchain与LLM交互时的默认行为,是最简单、最稳定的语言模型调用方式。 当用户发出请求后,系统在后台等待模型生成完整响应,然后 一次性将全部结果返回。
流式输出:一种更具交互感的模型输出方式,用户不再需要等待完整答案,而是能看到模型逐个 token 地实时返回内容。
#
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1"),
streaming=True #开启流式输出
)
messages = [HumanMessage(content= "你叫什么名字?")]
#流式输出
for chunk in llm.stream(messages):
print(chunk.content, end="", flush = True)
批量调用
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1"),
)
messages1 = [
SystemMessage(content= "你是一个只能助手"),
HumanMessage(content= "机器学习是什么")]
messages2 = [
SystemMessage(content= "你是一个只能助手"),
HumanMessage(content= "AIGC是什么")]
messages3 = [
SystemMessage(content= "你是一个只能助手"),
HumanMessage(content= "大模型是什么")]
messages = [messages1, messages2, messages3]
response = llm.batch(messages)
print(type(response))
print(response)
同步调用:正常函数调用。
异步调用:函数前async
Prompt Template
Prompt Template,通过模板管理大模型的输入。
有几种不同类型的提示模板:
PromptTemplate:LLM提示模板,用于生成字符串提示。它使用 Python 的字符串来模板提示。ChatPromptTemplate:聊天提示模板,用于组合各种角色的消息模板,传入聊天模型。
xxxMessagePromptTemplate:消息模板词模板,包括:SystemMessagePromptTemplate、 HumanMessagePromptTemplate、AIMessagePromptTemplate、
ChatMessagePromptTemplate等FewShotPromptTemplate:样本提示词模板,通过示例来教模型如何回答PipelinePrompt:管道提示词模板,用于把几个提示词组合在一起使用。自定义模板:允许基于其它模板类来定制自己的提示词模板。
python的 str.format()方法
info = "Name:{0},Age:{1}".format("Jerry,25")
print(info)
#其他写法
info = "Name:{name},Age:{age}".format(name="Jerry",age="25")
print(info)
person={"name":"David","age":40}
info = "Name:{name},Age:{age}".format(**person)
print(info)
PromptTemplate
PromptTemplate类,用于快速构建包含变量的提示词模板,并通过传入不同参数值生成自定义的提示词。
主要参数:
- template:定义提示词模板的字符串,其中包含
文本和变量站位符(如{name}) - input_variables: 列表,指定了模板中使用的变量名称,在调用模板时被替换;
- partial_variables:字典,用于定义模板中一些固定的变量名。这些值不需要再每次调用时被替换。
- format():给input_variables变量赋值,并返回提示词。利用format() 进行格式化时就一定要赋
值,否则会报错。当在template中未设置input_variables,则会自动忽略。
单个模板
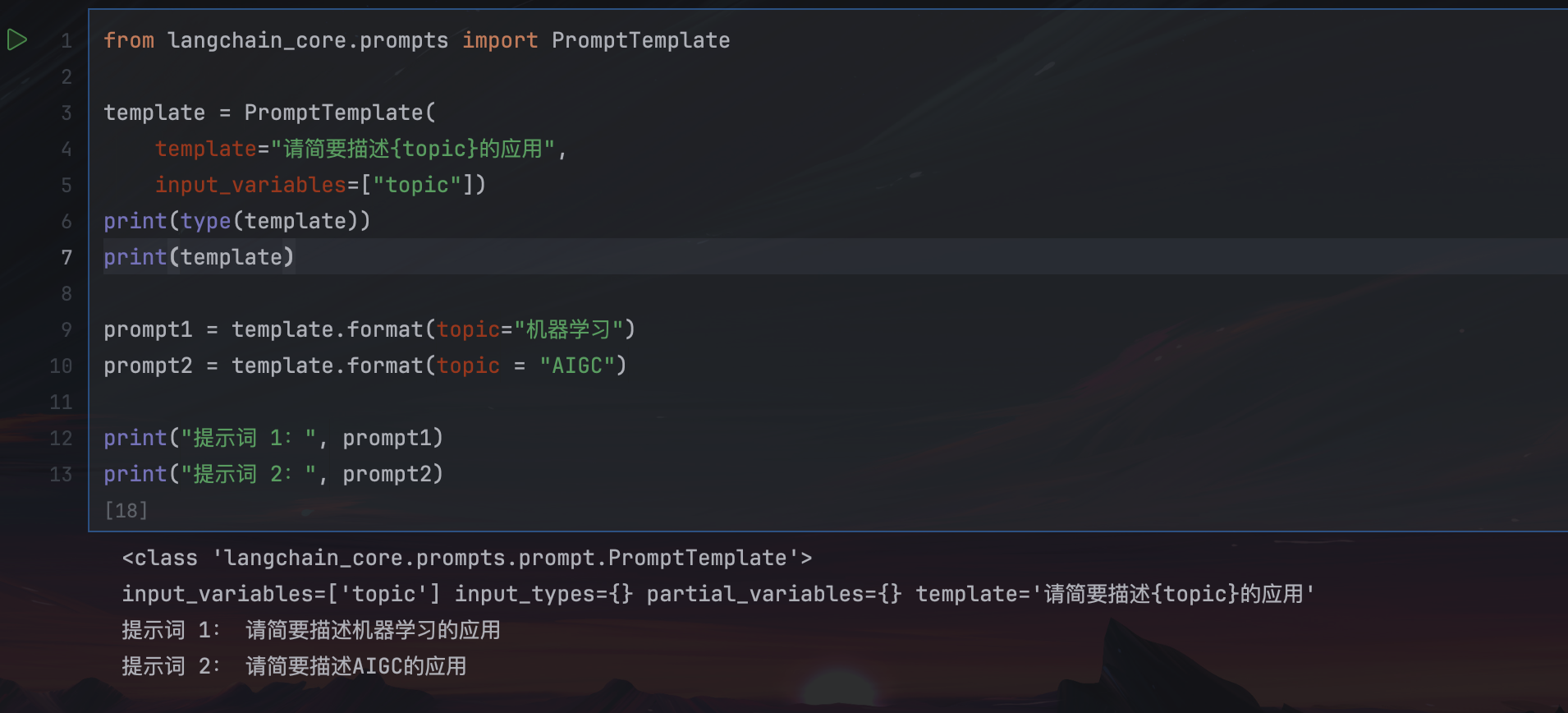
from langchain_core.prompts import PromptTemplate
template = PromptTemplate(
template="请简要描述{topic}的应用",
input_variables=["topic"])
print(type(template))
print(template)
prompt1 = template.format(topic="机器学习")
prompt2 = template.format(topic = "AIGC")
print("提示词 1:", prompt1)
print("提示词 2:", prompt2)
定义多变量模板
from langchain_core.prompts import PromptTemplate
template = PromptTemplate(
template="请评价{product}的优缺点,包括{aspect1}和{aspect2}",
input_variables=["product", "aspect1", "aspect2"])
prompt1 = template.format(product = "智能手机", aspect1 = "电池续航", aspect2 = "拍照质量")
prompt2 = template.format(product = "笔记本电脑", aspect1 = "处理数速度", aspect2 = "便携性")
print("提示词 1:", prompt1)
print("提示词 2:", prompt2)
#调用from_template()
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"请给我一个关于{topic}的{type}解释"
)
prompt = prompt_template.format(topic ="量子力学", type= "详细")
print(prompt)
#不含变量
from langchain_core.prompts import PromptTemplate
text= """
Tell me a joke
"""
prompt_template = PromptTemplate.from_template(text)
prompt = prompt_template.format()
print(prompt)
定义一些固定变量
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
template= "请评价{product}的优缺点,包括{aspect1}和{aspect2}",
partial_variables={"aspect1":"电池", "aspect2":"屏幕"}
)
prompt = prompt_template.format(product = "笔记本电脑")
print(prompt)
format() 与 invoke()
只要对象是RunnableSerializable接口类型,都可以使用invoke(),替换前面使用format()的调用式。
- format(),返回值为字符串类型;
- invoke(),返回值为PromptValue类型,接着调用to_string()返回字符串。
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"请评价{product}的优缺点,包括{aspect1}"
)
prompt = prompt_template.invoke({"product":"笔记本电脑","aspect1":"电池"})
print(type(prompt))
print(prompt)
#output
<class 'langchain_core.prompt_values.StringPromptValue'>
text='请评价笔记本电脑的优缺点,包括电池'
结合LLM调用
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
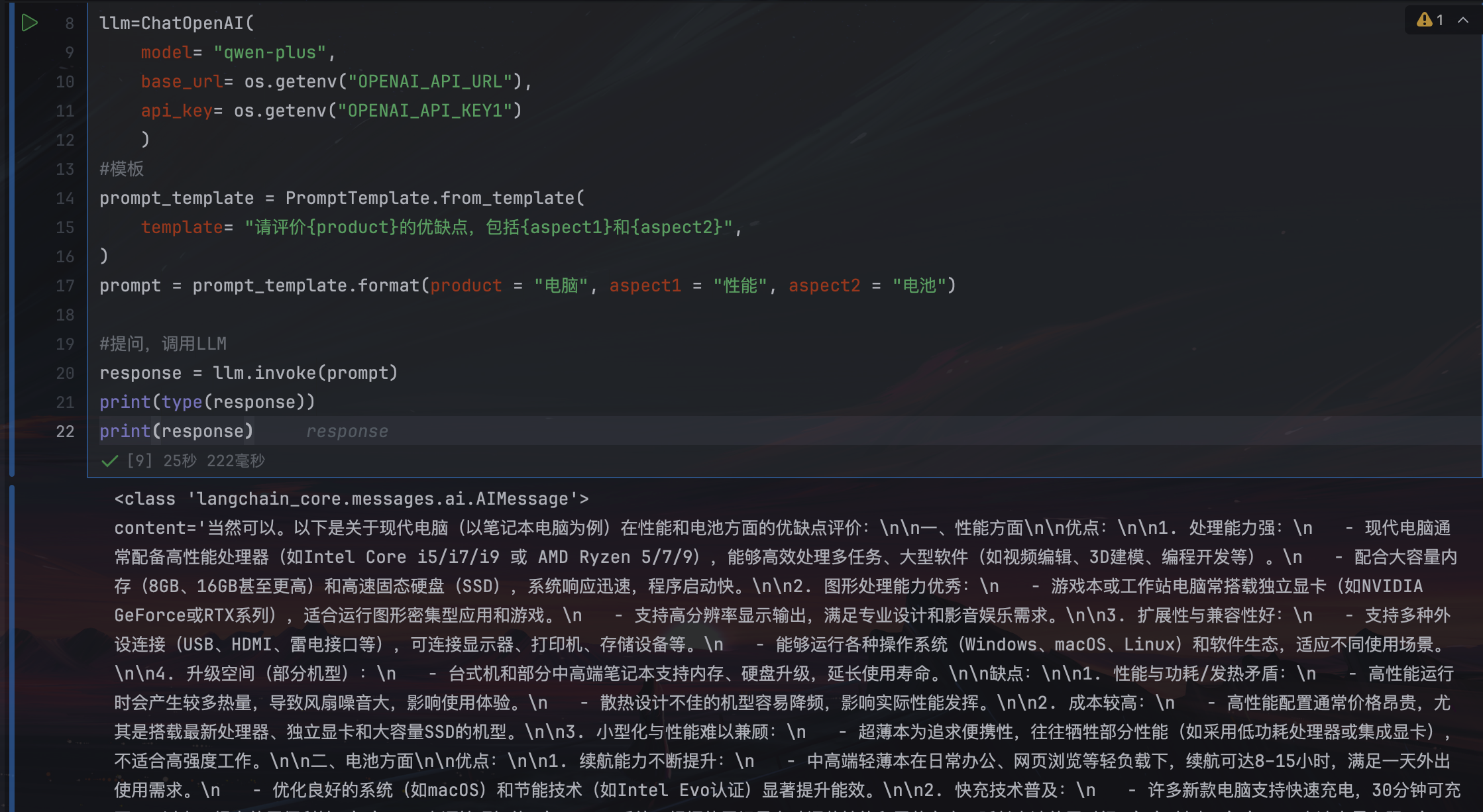
#模板
prompt_template = PromptTemplate.from_template(
template= "请评价{product}的优缺点,包括{aspect1}和{aspect2}",
)
prompt = prompt_template.format(product = "电脑", aspect1 = "性能", aspect2 = "电池")
#提问,调用LLM
response = llm.invoke(prompt)
print(type(response))
print(response)
ChatPromptTemplate
ChatPromptTemplate是创建聊天消息列表的提示模板。它比普通 PromptTemplate 更适合处理多角色、多轮次的对话场景。
- 支持 System / Human / AI 等不同角色的消息模版
- 对话历史维护
参数类型
- role:str (role有 system、human 、ai)
- content:str
from langchain_core.prompts import ChatPromptTemplate
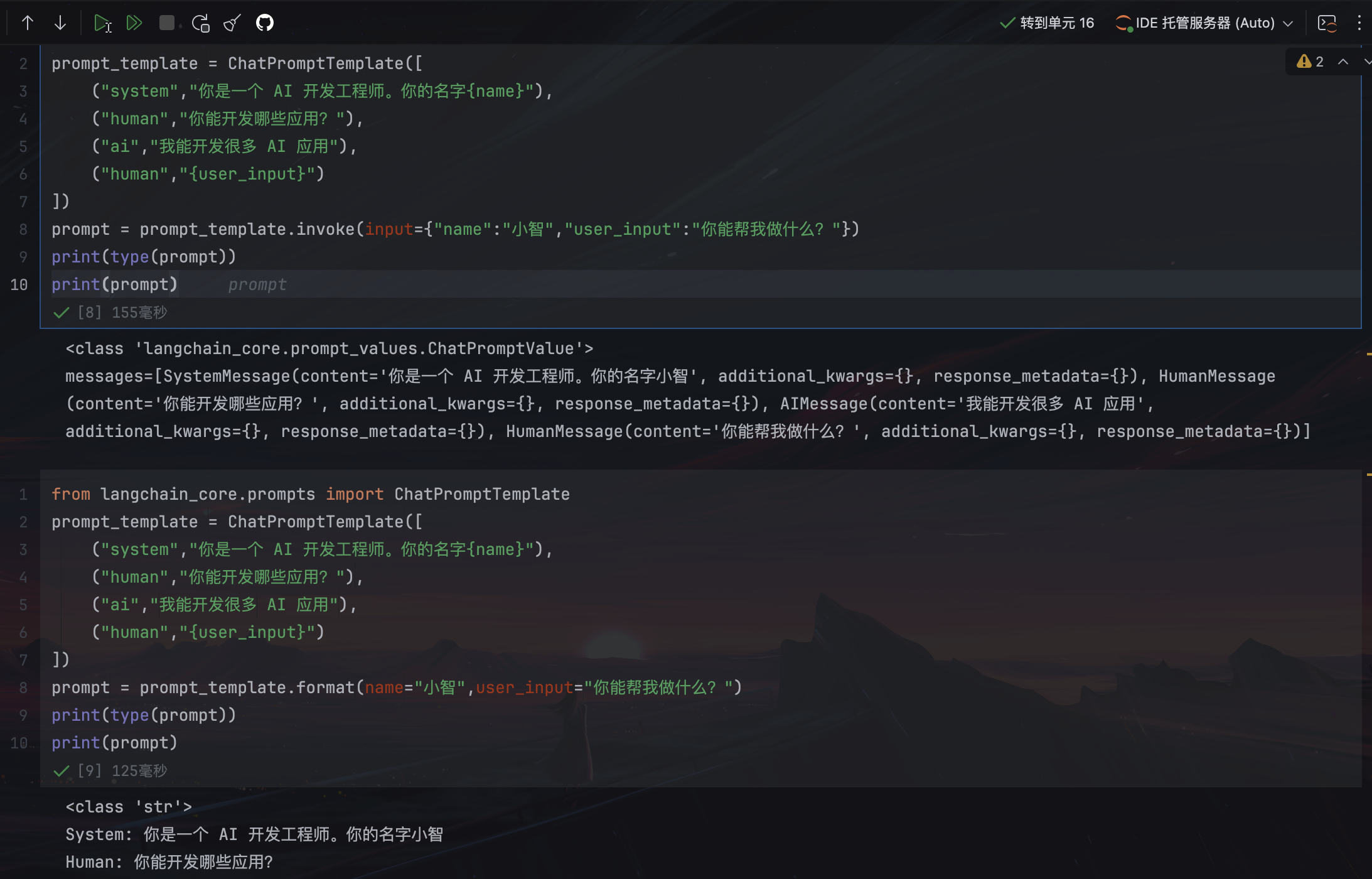
prompt_template = ChatPromptTemplate([
("system","你是一个 AI 开发工程师。你的名字{name}"),
("human","你能开发哪些应用?"),
("ai","我能开发很多 AI 应用"),
("human","{user_input}")
])
prompt = prompt_template.invoke(input={"name":"小智","user_input":"你能帮我做什么?"})
print(type(prompt))
print(prompt)
调用from_messages()
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages([
("system","你是一个 AI 开发工程师。你的名字{name}"),
("human","你能开发哪些应用?"),
("ai","我能开发很多 AI 应用"),
("human","{user_input}")
])
prompt = prompt_template.invoke({"name":"小智","user_input":"你能帮我做什么?"})
print(type(prompt))
print(prompt)
模板创建
- str类型
prompt_template = ChatPromptTemplate.from_messages([
"hello,{name}"
])
- dict类型
prompt_template = ChatPromptTemplate.from_messages([
("system","你是一个 AI 开发工程师。你的名字{name}"),
("human","你能开发哪些应用?"),
("ai","我能开发很多 AI 应用"),
("human","{user_input}")
])
- Message类型
from langchain_core.messages import SystemMessage,HumanMessage
prompt_template = ChatPromptTemplate.from_messages([
SystemMessage(content="我是一个智能助手"),
HumanMessage(content="AI是什么?"),
])
- BaseChatPromptTemplate类型
nested_prompt_template1 = ChatPromptTemplate.from_messages([("system","你是一个 AI 开发工程师。你的名字{name}")])
nested_prompt_template2 = ChatPromptTemplate.from_messages([("human","你能开发哪些应用?")])
prompt_template = ChatPromptTemplate.from_messages([
nested_prompt_template1,nested_prompt_template2
])
- BaseMessagePromptTemplate类型
#导入消息类模版
from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate
system_template = "你是一个专家{role}"
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template = "给我解释{concept}, 用浅显易懂的语言"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
#组合
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
formatted_messages = chat_prompt.format_messages(
role= "物理学家"
concept= "相对论"
)
- 综合使用
from langchain_core.prompts import (
ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate,
)
from langchain_core.messages import SystemMessage, HumanMessage
#示例1 使用BaseMessagePromptTemplate
system_prompt = SystemMessagePromptTemplate.from_template("你是一个{role}")
human_prompt = HumanMessagePromptTemplate.from_template("{user_input}")
#示例2 使用BaseMessage
system_msg = SystemMessage(content= "你是一个 AI 工程师")
human_msg = HumanMessage(content= "你好!")
#示例3 使用BaseChatPromptTemplate
nested_prompt = ChatPromptTemplate.from_messages([("system", "嵌套提示词")])
prompt = ChatPromptTemplate.from_messages([
system_prompt,
human_prompt,
system_msg,
human_msg,
nested_prompt
])
prompt.format_messages(role="人工智能专家",user_input = "介绍大模型应用场景")
#ouput
[SystemMessage(content='你是一个人工智能专家', additional_kwargs={}, response_metadata={}),
HumanMessage(content='介绍大模型应用场景', additional_kwargs={}, response_metadata={}),
SystemMessage(content='你是一个 AI 工程师', additional_kwargs={}, response_metadata={}),
HumanMessage(content='你好!', additional_kwargs={}, response_metadata={}),
SystemMessage(content='嵌套提示词', additional_kwargs={}, response_metadata={})]
模版调用
- invoke()
#返回类型 <class 'langchain_core.prompt_values.ChatPromptValue'>
prompt = prompt_template.invoke({"name":"小智","user_input":"你能帮我做什么?"})
- format()
#返回类型<class 'str'>
prompt = prompt_template.format(name="小智",user_input="你能帮我做什么?")
- format_messages()
#返回类型 <class 'list'>
#针对ChatPromptTemplate 给占位符优先使用format_messages()
prompt = prompt_template.format_messages(name="小智",user_input="你能帮我做什么?")
- format_prompt
#返回类型 <class 'langchain_core.prompt_values.ChatPromptValue'>
prompt = prompt_template.format_prompt(name="小智",user_input="你能帮我做什么?")
结合 LLM
#和之前的一样,创建大模型实例后
output = llm.invoke(prompt)
print(output.prompt)
少量样本示例的提示词模板
在构建prompt时,可以通过构建一个少量示例列表去进一步格式化prompt,这是一种简单但强大的指导生成的方式,在某些情况下可以显著提高模型性能。
少量示例提示模板可以由一组示例或一个负责从定义的集合中选择一部分示例的示例选择器构建。
- 前者:
FewShotPromptTemplate 或者FewShotChatMessagePromptTemplate - 后者:使用
Example selectors(示例选择器)
FewShotPromptTemplate
from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import FewShotPromptTemplate
examples = [
{"input":"北京天气怎么样", "output":"北京市"},
{"input":"南京下雨吗", "output":"南京市"},
{"input":"武汉热吗", "output":"武汉市"},
]
example_prompt = PromptTemplate.from_template(
template= "Input:{input}\nOutput:{output}"
)
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Input:{input}\nOutput:",
input_variables=["input"]
)
prompt = prompt.invoke({"input":"长沙多少度"})
print(prompt)
调用 LLM
from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import FewShotPromptTemplate
#创建集合
examples = [
{"input":"北京天气怎么样", "output":"北京市"},
{"input":"南京下雨吗", "output":"南京市"},
{"input":"武汉热吗", "output":"武汉市"},
]
#创建PromptTemplate实例
example_prompt = PromptTemplate.from_template(
template= "Input:{input}\nOutput:{output}"
)
#创建FewShotPromptTemplate实例
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Input:{input}\nOutput:",
input_variables=["input"]
)
prompt = prompt.invoke({"input":"长沙多少度"})
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
response = llm.invoke(prompt)
print(response.content)
FewShotChatMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import FewShotChatMessagePromptTemplate
examples = [
{"input":"1+1=?","output":"1+1=2"},
{"input":"法国首都是?","output":"巴黎"}
]
msg_example_prompt = ChatPromptTemplate.from_messages([
("human","{input}"),
("ai","{output}")
])
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=msg_example_prompt,
examples=examples
)
print(type(few_shot_prompt))
print(few_shot_prompt)
前面FewShotPromptTemplate的特点是,无论输入什么问题,都会包含全部示例。在实际开发中,我们可以根据当前输入,使用示例选择器,从大量候选示例中选取最相关的示例子集。
Example selectors(示例选择器)
pip install chromadb
示例选择策略:语义相似选择、长度选择、最大边际相关示例选择等
import os
from dotenv import load_dotenv
from langchain_community.vectorstores import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
load_dotenv() #自动加载.env文件
#创建大模型实例
embedding=OpenAIEmbeddings(
model= "text-embedding-v4",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1"),
)
#定义示例组
examples = [
{
"question":"谁活得更久,穆罕默德还是图灵",
"answer":"""
接下来还需要问什么问题吗?
追问:穆罕默德去世多大年纪?
中间答案:穆罕默德去世时 74岁
""",
},
{
"question":"craigslist创始人是什么时候出生的?",
"answer":"""
接下来还需要问什么问题吗?
追问:谁是craigslist创始人?
中间答案:craigslis是克雷格·纽马克创立的。
""",
},
{
"question":"谁是乔治的外祖父?",
"answer":"""
接下来还需要问什么问题吗?
追问:谁是乔治的母亲?
中间答案:乔治的目前是玛丽。
""",
}
]
example_selector = SemanticSimilarityExampleSelector.from_examples(
#可供选择的示例
examples,
#用于生成嵌入的嵌入类,衡量语意相似性
embedding,
#用于存储嵌入并进行相似性搜索的 VectorStore类
Chroma,
#生成示例数量
k=1
)
question = "玛丽的父亲是谁?"
selcted_example = example_selector.from_examples({"question":question})
print(selcted_example)
此外还有PipelinePromptTemplate、自定义提示词模版、从文档中加载Prompt(yaml\json)
从文档中加载Prompt
Output Parsers
语言模型返回的内容通常都是字符串的格式(文本格式),但在实际AI应用开发过程中,往往希望 model可以返回更直观、更格式化的内容,以确保应用能够顺利进行后续的逻辑处理。LangChain提供以下输出解析器
字符串解析器StrOutputParser
to string
import os
from langchain_core.output_parsers import StrOutputParser
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
messages = [
SystemMessage(content="将以下内容翻译成中文"),
HumanMessage(content="it's a nice day today")
]
result = llm.invoke(messages)
print(type(result))
print(result)
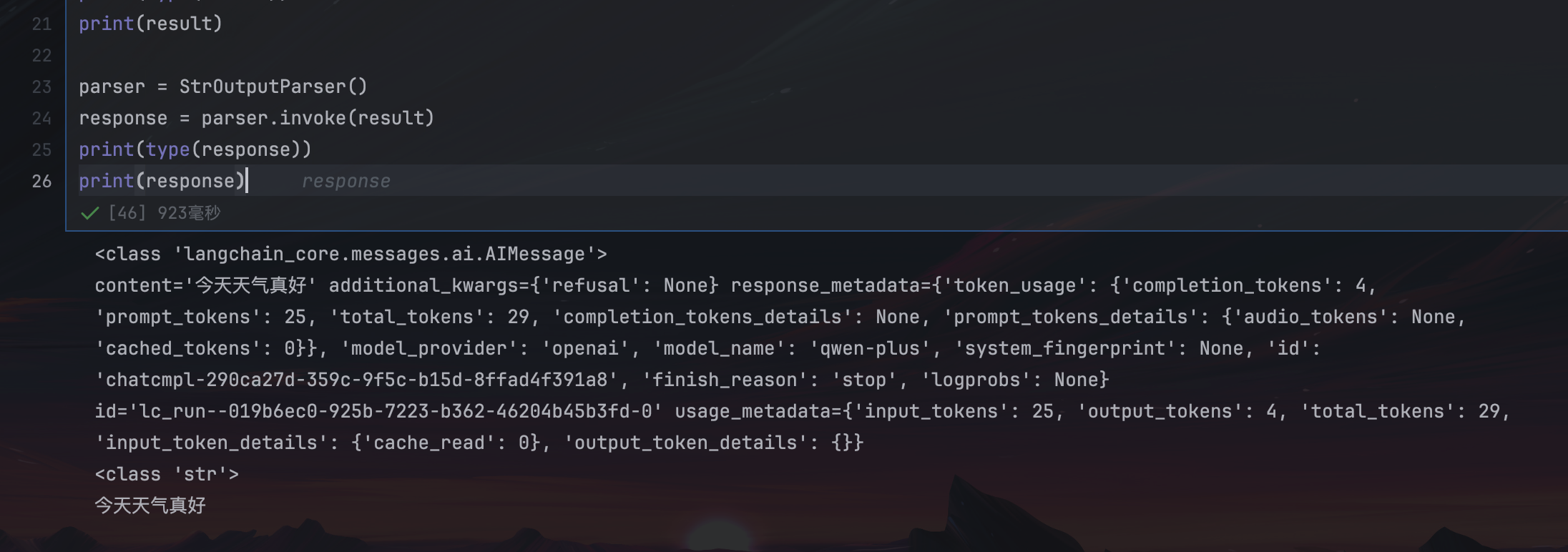
parser = StrOutputParser()
response = parser.invoke(result)
print(type(response))
print(response)
JSON解析器JsonOutputParser
to json
import os
from langchain_core.output_parsers import JsonOutputParser
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
chat_prompt = ChatPromptTemplate.from_messages([
("system","你是一个靠谱的{role}"),
("human","{question}")
])
parser = JsonOutputParser()
response = llm.invoke(chat_prompt.format_prompt(role="人工智能专家",question="人工智能用英文怎么说,问题用 q表示,答案用 a表示,返回一个 json格式"))
print(type(response))
print(response)
parser.invoke(response)
使用指定的Json格式
import os
from langchain_core.output_parsers import JsonOutputParser
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
joke_query = "告诉我一个笑话"
parser = JsonOutputParser()
prompt = PromptTemplate(
template="回答用户的查询。\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions":parser.get_format_instructions()}
)
chain = prompt | llm | parser
optput = chain.invoke(joke_query)
print(optput)

XML解析器XMLOutputParser
to xml
#不使用XMLOutputParser,通过大模型的能力,返回xml格式数据
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
actor_query = "生成汤姆·汉克斯的简短电影记录"
output = llm.invoke(f"""{actor_query}请将影片附在<movie></movie>标签中""")
print(type(output))
print(output.content)
XMLOutputParser
import os
from langchain_core.output_parsers import XMLOutputParser
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
actor_query = "生成汤姆·汉克斯的简短电影记录,使用中文回复"
parser = XMLOutputParser()
#定义模版对象
prompt_template = PromptTemplate.from_template("{query}\n{format_instructions}")
prompt_template1 = prompt_template.partial(format_instructions=parser.get_format_instructions())
response = llm.invoke(prompt_template1.format(query=actor_query))
print(response.content)
列表解析器CommaSeparatedListOutputParser
列表解析器:利用此解析器可以将模型的文本响应转换为一个用逗号分隔的列表
import os
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv() #自动加载.env文件
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= os.getenv("OPENAI_API_URL"),
api_key= os.getenv("OPENAI_API_KEY1")
)
#创建解析器
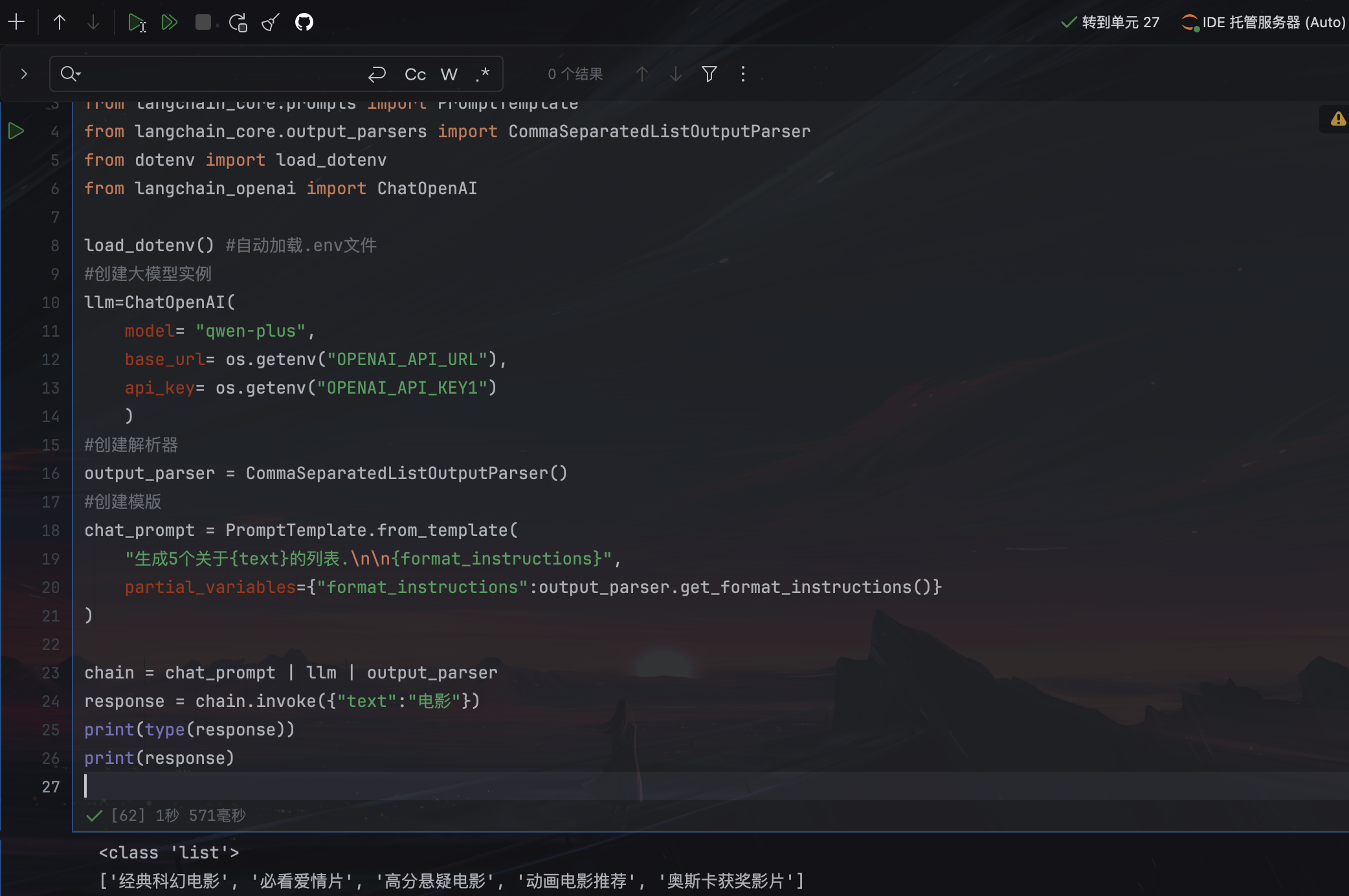
output_parser = CommaSeparatedListOutputParser()
#创建模版
chat_prompt = PromptTemplate.from_template(
"生成5个关于{text}的列表.\n\n{format_instructions}",
partial_variables={"format_instructions":output_parser.get_format_instructions()}
)
chain = chat_prompt | llm | output_parser
response = chain.invoke({"text":"电影"})
print(type(response))
print(response)
本文来自博客园,作者:Rodericklog,转载请注明原文链接:https://www.cnblogs.com/rodericklog/articles/19453017

 浙公网安备 33010602011771号
浙公网安备 33010602011771号