[AI应用基础学习-1] LangChain 使用概述
学习尚硅谷-宋红康老师的课记录。langchain 0.x 版本讲的课,目前是 1.0 版本了但是旧版本的内容还是兼容的,有些函数更换了位置,需要调整。
LangChain是 2022年10月 ,由哈佛大学的 Harrison Chase (哈里森·蔡斯)发起研发的一个开源框架, 用于开发由大语言模型(LLMs)驱动的应用程序。用于搭建“智能体”(Agent)、问答系统(QA)、对话机器人、文档搜索系统、企业私有知识库等。
在大语言模型(LLM)如 ChatGPT、Claude、DeepSeek 等快速发展的今天,开发者不仅希望能“使用”这些模型,还希望能将它们灵活集成到自己的应用中 ,实现更强大的对话能力、检索增强生成 (RAG)、工具调用(Tool Calling)、多轮推理等功能,如大模型默认不能联网,如果需要联网,用 langchain。当然还有其他工具。
架构设计
0.x版本
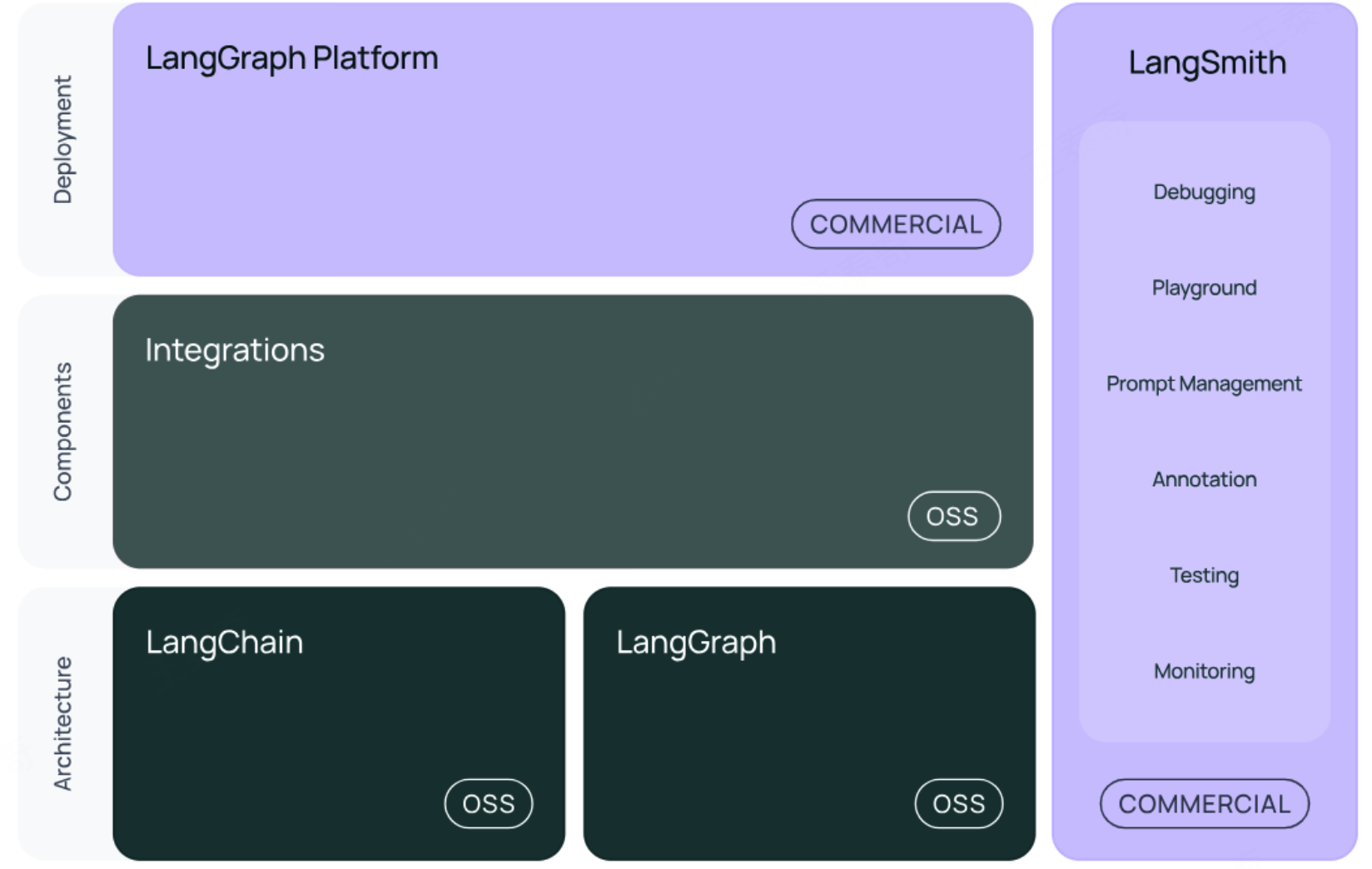
1.0 版本中的架构LangGraph Platform改为 Deep Agents,其他部分基本无变化。
结构1:LangChain
- langchain:构成应用程序认知架构的Chains,Agents,Retrieval strategies等
- langchain-community:第三方集成
- langchain-Core:基础抽象和LangChain表达式语言 (LCEL)
结构2:LangGraph
LangGraph可以看做基于LangChain的api的进一步封装,能够协调多个Chain、Agent、Tools完成更复杂的任务,实现更高级的功能。
结构3:LangSmith
链路追踪。提供了6大功能,涉及Debugging (调试)、Playground (沙盒)、Prompt Management (提示管理)、Annotation (注释)、Testing (测试)、Monitoring (监控)等。与LangChain无缝集成,从原型阶段过渡到生产阶段。
结构4:LangServe
将LangChain的可运行项和链部署为REST API,使得它们可以通过网络进行调用。
环境搭建
https://docs.langchain.com/oss/python/langchain/overview
用 venv 创建虚拟环境(推荐,Python 自带)
进入你的项目目录执行
# macOS / Linux
python3 -m venv .venv
# Windows(PowerShell)
py -m venv .venv
激活虚拟环境
# macOS / Linux (bash/zsh)
source .venv/bin/activate
# Windows (PowerShell)
.\.venv\Scripts\Activate.ps1
# Windows (cmd)
.\.venv\Scripts\activate.bat
安装依赖
python -m pip install -U pip
pip install requests
查看装了什么
pip list
安装 langchain
pip install -U langchain
# Requires Python 3.10+
# Installing the OpenAI integration
pip install -U langchain-openai
# Installing the Anthropic integration
pip install -U langchain-anthropic
大模型应用开发
基于RAG架构的开发
RAG精准解决大模型的知识冻结、大模型幻觉的问题。 注:Retrieval-Augmented Generation(检索增强生成)
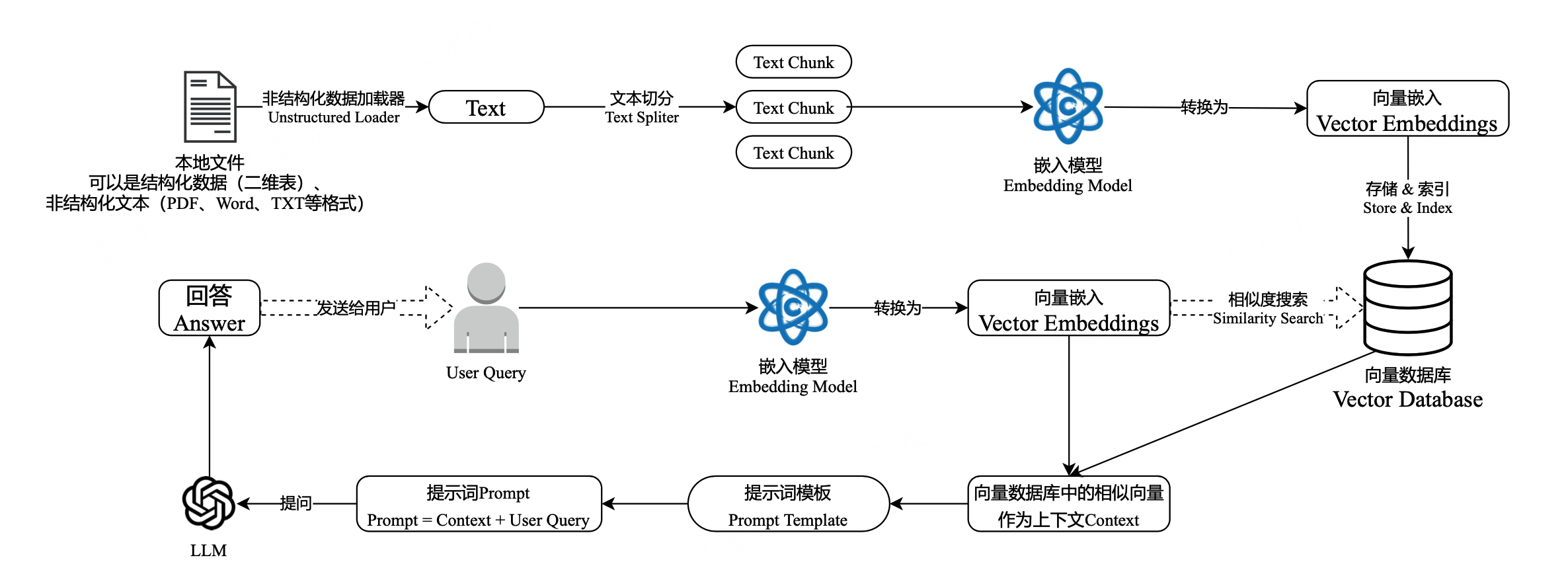
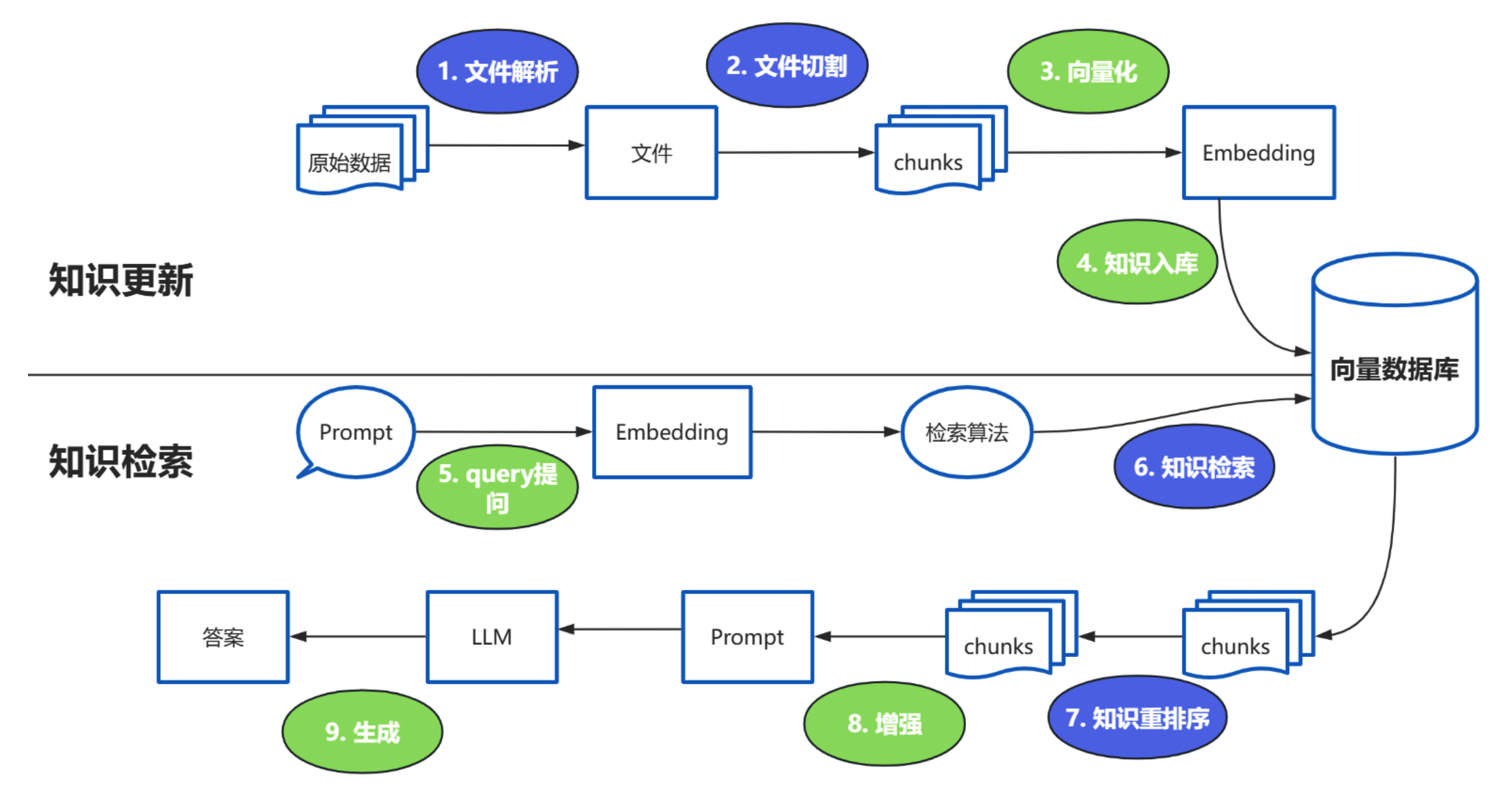
这些过程中的难点:1、文件解析 2、文件切割 3、知识检索 4、知识重排序
基于Agent架构的开发
充分利用 LLM 的推理决策能力,通过增加规划 、 记忆和工具调用的能力,构造一个能够独立思考、 逐步完成给定目标的智能体。
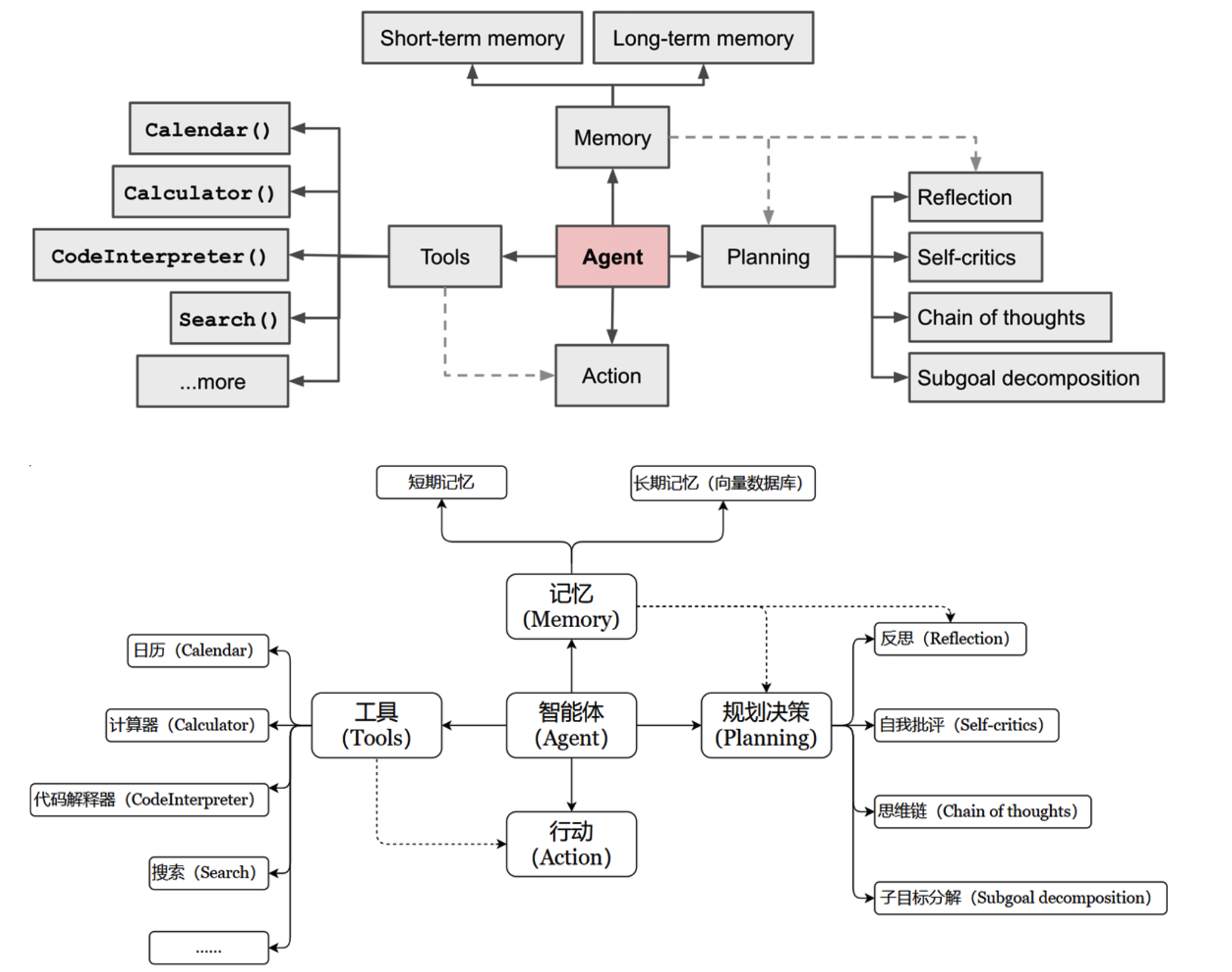
Agent = LLM + Memory + Tools + Planning + Action
-
大模型(LLM)作为大脑:提供推理、规划和知识理解能力,是AI Agent的决策中枢。
-
记忆(Memory):让智能体在处理重复工作时调用以前的经验,避免用户进行大量重复交互。
- 短期记忆:存储单次对话周期的上下文信息,属于临时信息存储机制。受限于模型的上下文窗口长度。
- 长期记忆:可以横跨多个任务或时间周期,可存储并调用核心知识,非即时任务。
-
工具使用(Tool Use):调用外部工具(如API、数据库)扩展能力边界。
-
规划决策(Planning):通过任务分解、反思与自省框架实现复杂任务处理。例如,利用思维链 (Chain of Thought)将目标拆解为子任务,并通过反馈优化策略。
大模型应用开发的4个场景
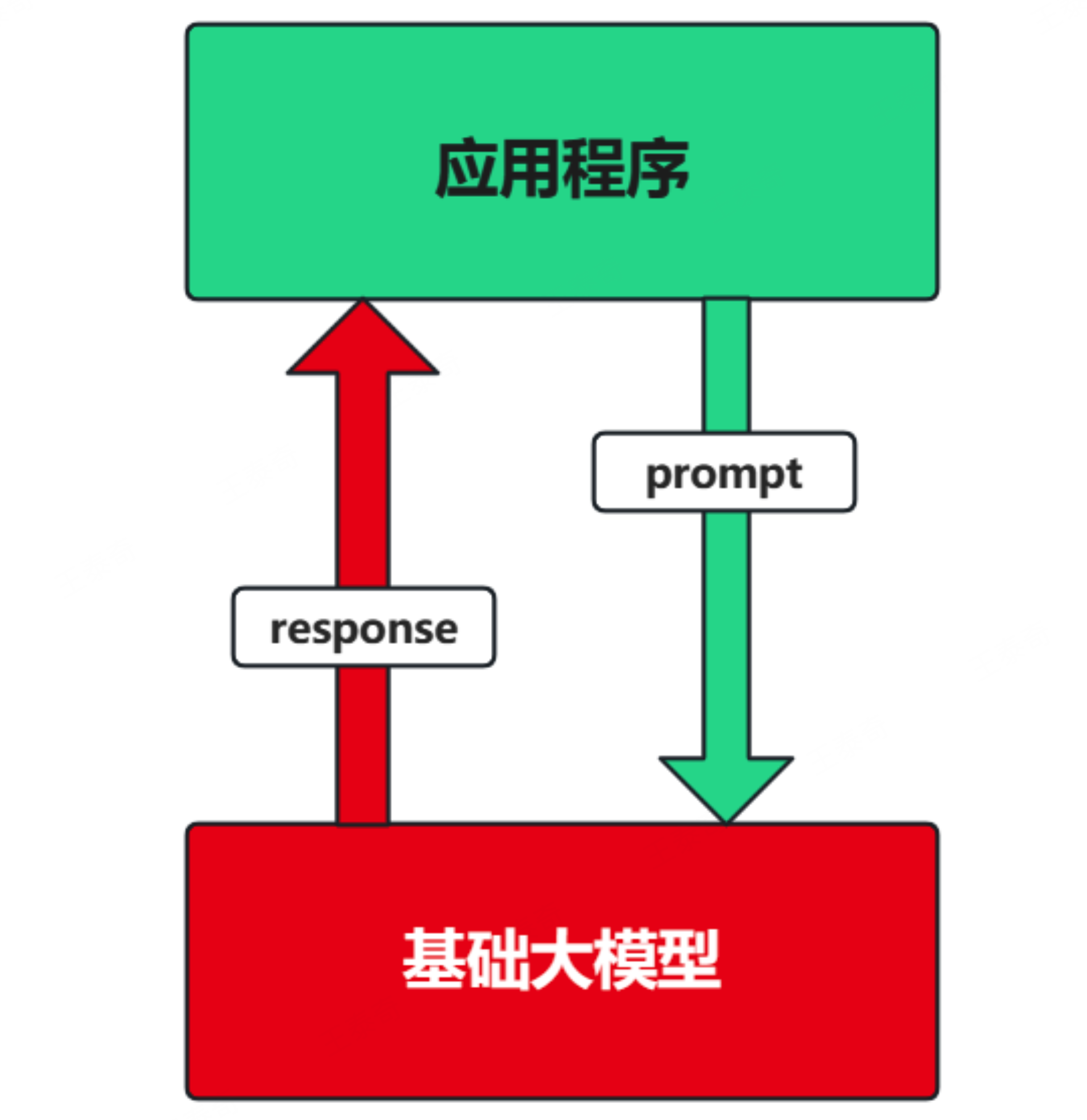
场景1:纯 Prompt
Prompt是操作大模型的唯一接口
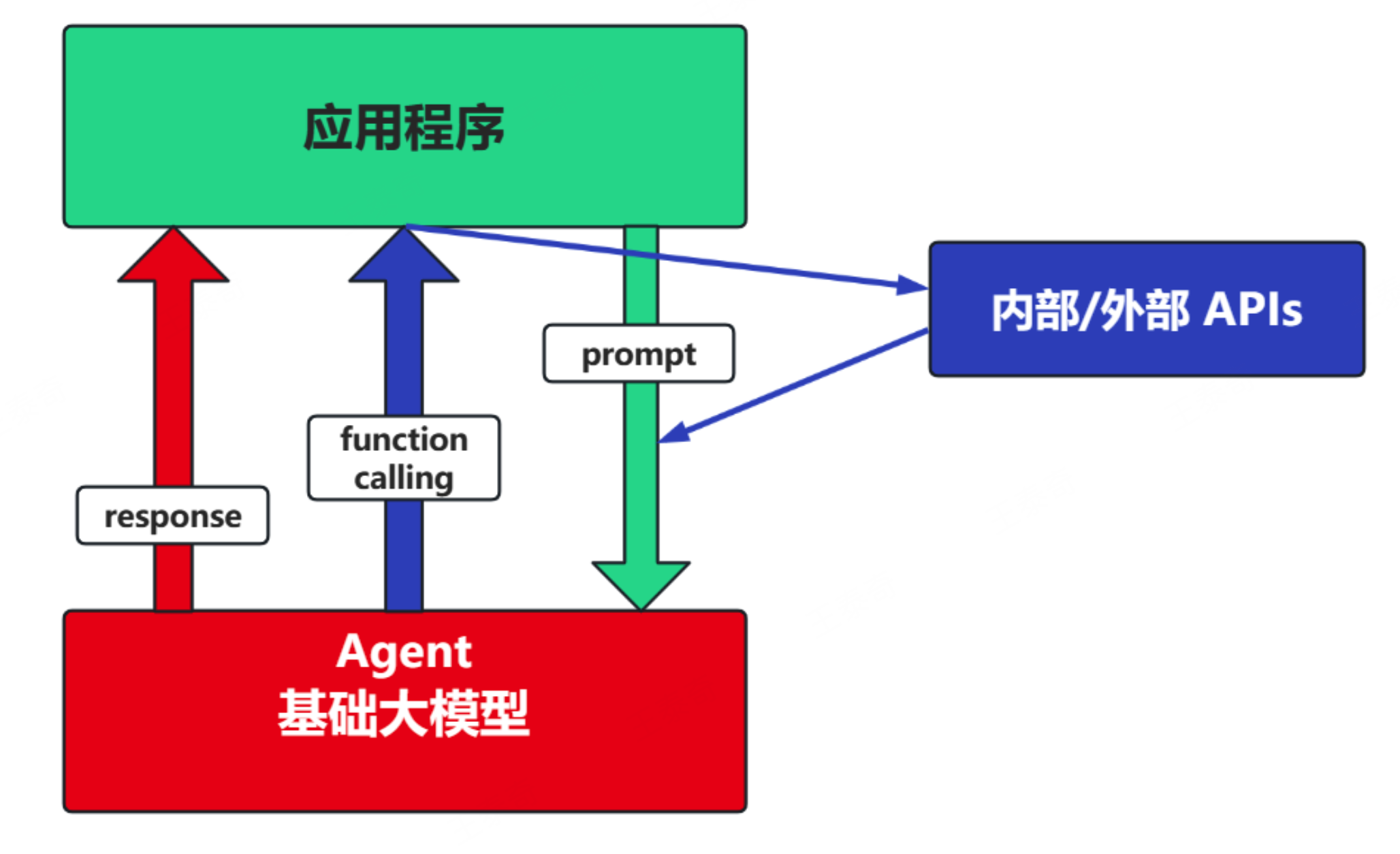
场景2:Agent + Function Calling
Agent:AI 主动提要求
Function Calling:需要对接外部系统时,AI 要求执行某个函数
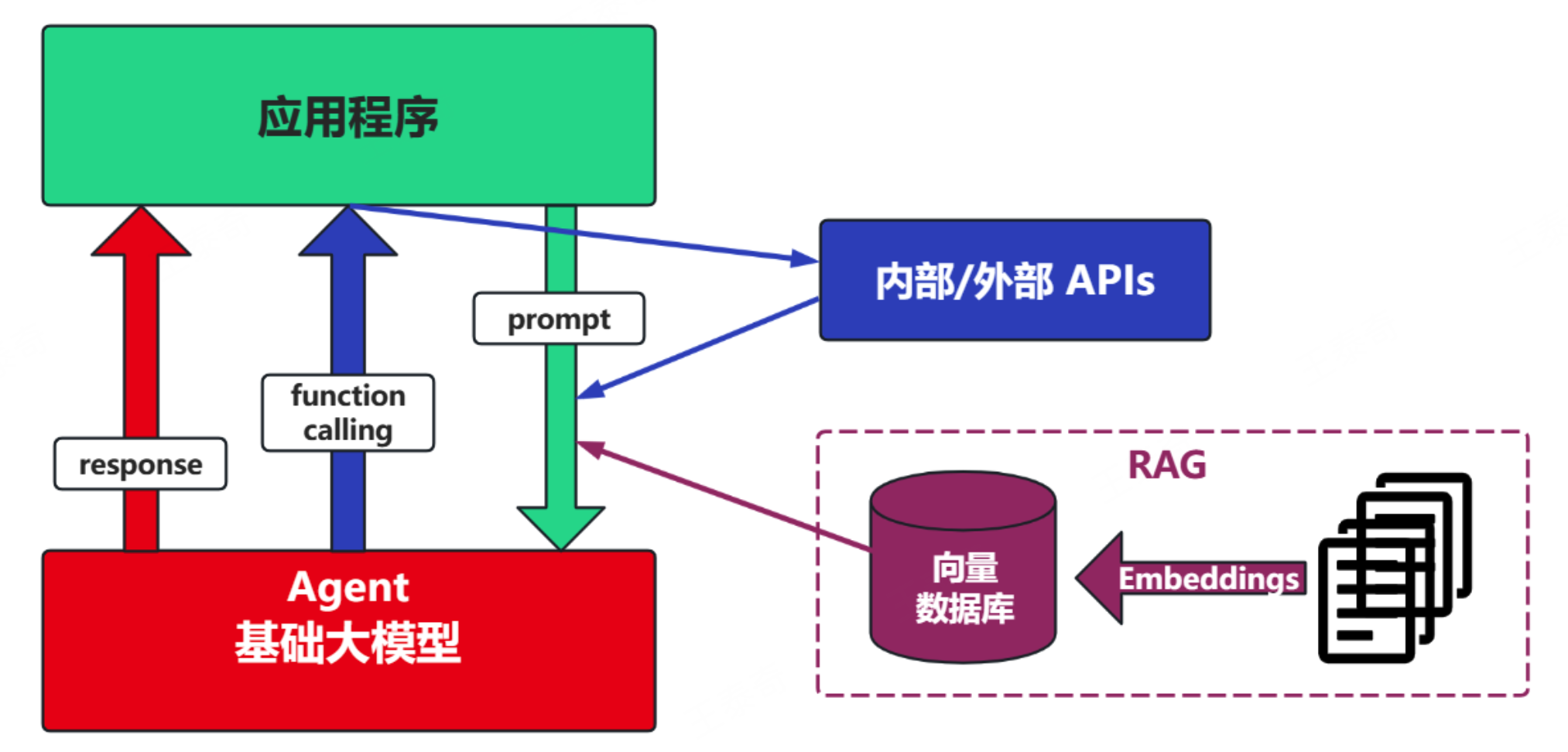
场景3:RAG (Retrieval-Augmented Generation)
Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫向量
向量数据库:把向量存起来,方便查找
向量搜索:根据输入向量,找到最相似的向量
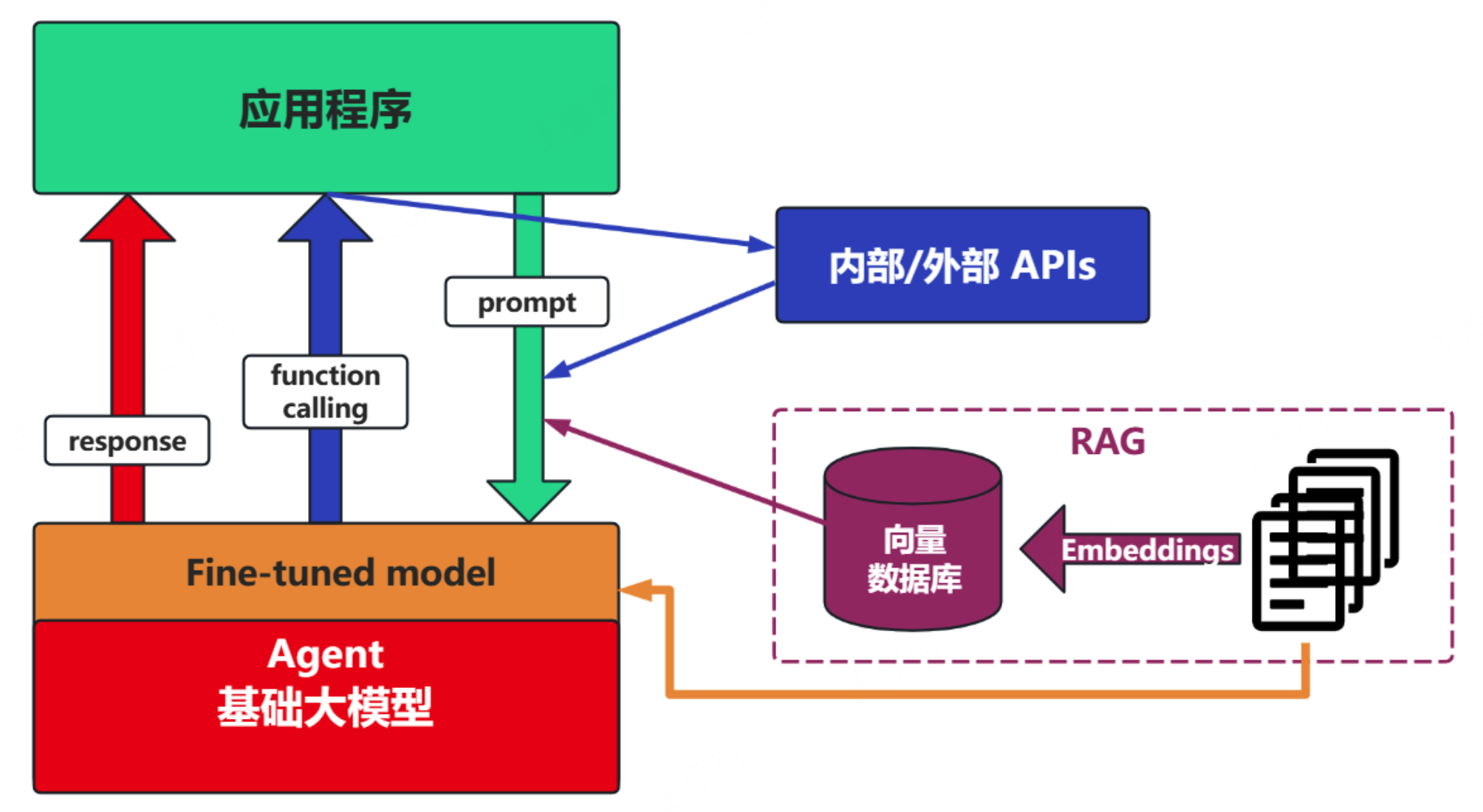
场景4:Fine-tuning(精调/微调)
面对一个需求,如何开始,如何选择技术方案?下面是个常用思路:
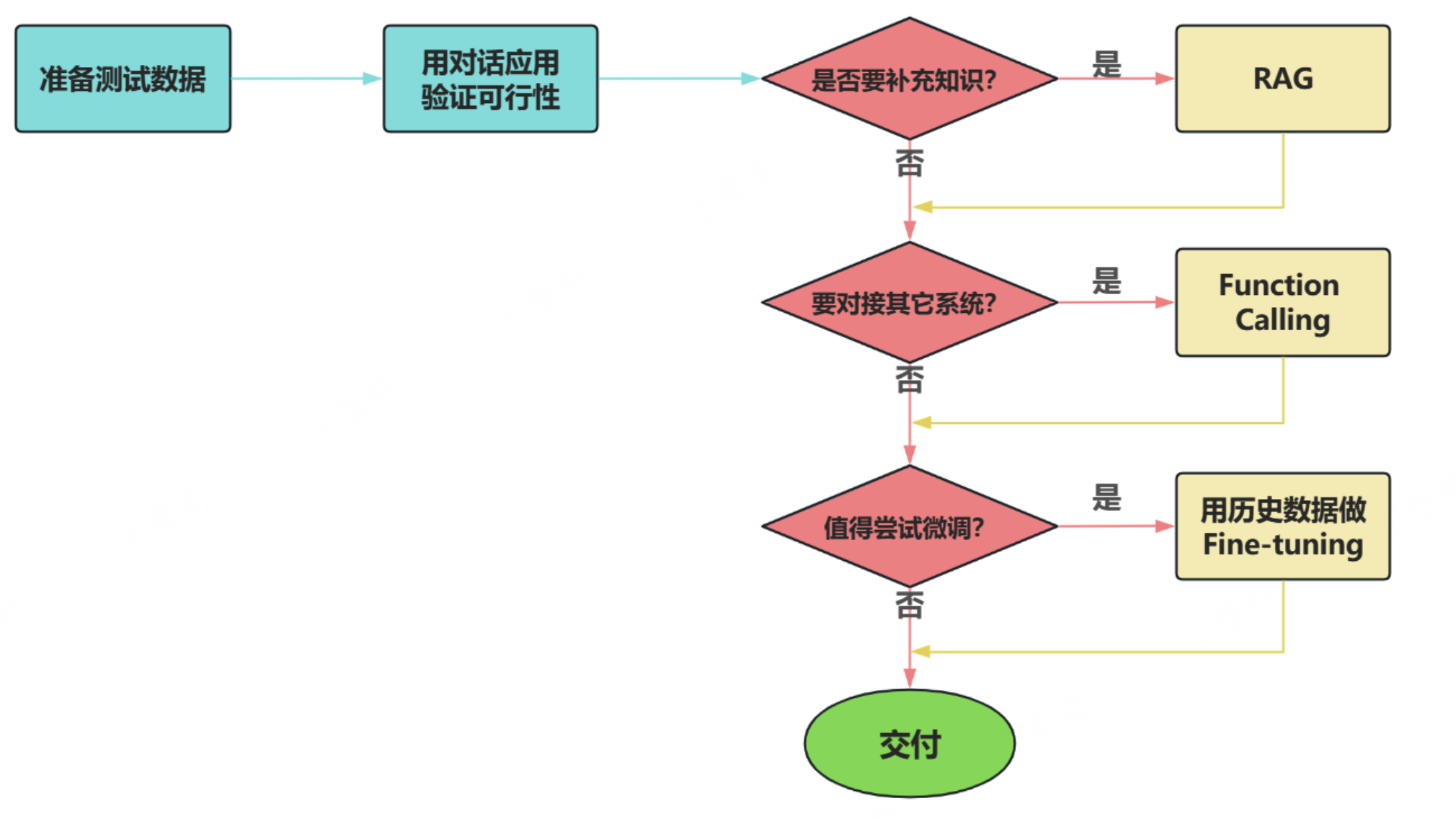
LangChain的核心组件
核心组件1:Model I/O
Model I/O:标准化各个大模型的输入和输出,包含输入模版,模型本身和格式化输出。 以下是使用语言模型从输入到输出的基本流程。
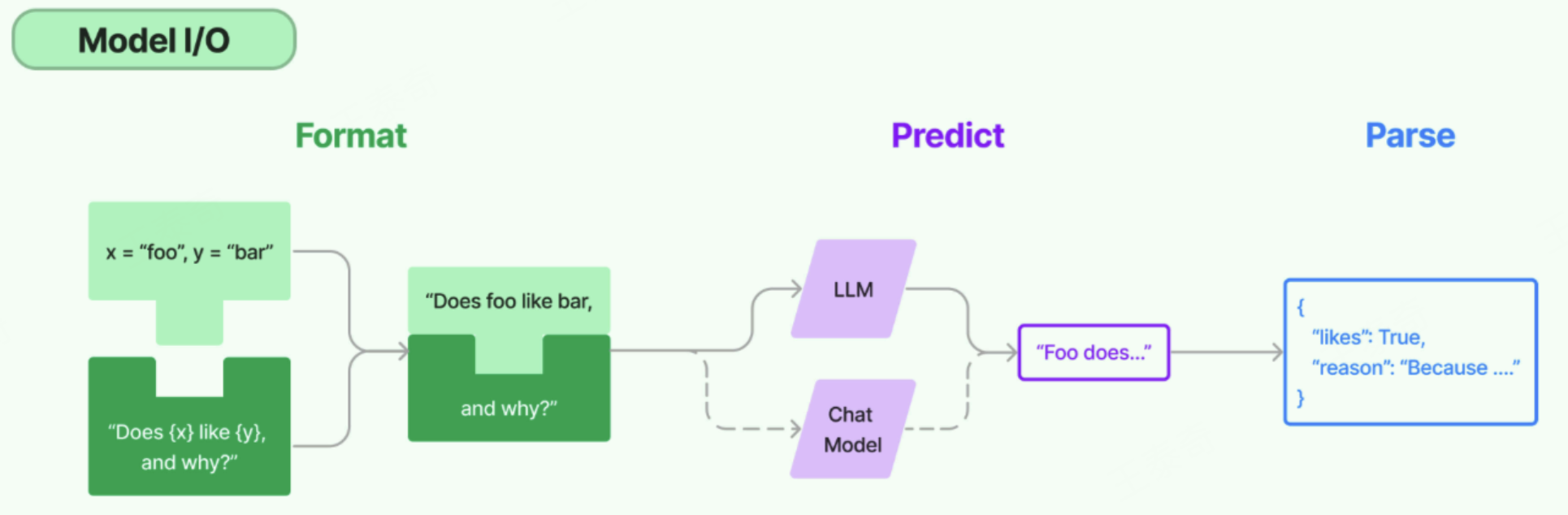
Format(格式化) :即指代Prompts Template,通过模板管理大模型的输入。将原始数据格式化成模型可以处理的形式,插入到一个模板问题中,然后送入模型进行处理。
Predict(预测) :即指代Models,使用通用接口调用不同的大语言模型。接受被送进来的问题,然后基于这个问题进行预测或生成回答。
Parse(生成) :即指代Output Parser 部分,用来从模型的推理中提取信息,并按照预先设定好的模版来规范化输出。比如,格式化成一个结构化的JSON对象。
核心组件2:Chains
Chain:用于将多个模块串联起来组成一个完整的流程,是 LangChain 框架中最重要的模块。
例如,一个 Chain 可能包括一个 Prompt 模板、一个语言模型和一个输出解析器,它们一起工作以处理 用户输入、生成响应并处理输出。
常见的Chain类型:
- LLMChain:最基础的模型调用链
- SequentialChain:多个链串联执行
- RouterChain:自动分析用户的需求,引导到最适合的链
- RetrievalQA :结合向量数据库进行问答的链
核心组件3:Memory
Memory:记忆模块,用于保存对话历史或上下文信息,以便在后续对话中使用。
常见的 Memory 类型:
- ConversationBufferMenmory:保存完整的对话历史
- ConversationSummaryMenmory:保存对话内容的精简摘要(适合长对话)
- ConversationSummaryBufferMenmory:混合型记忆机制,兼具上面两个类型的特
- VectorStoreRetrieverMemory :保存对话历史存储在向量数据库中
核心组件4:Agents
Agents,对应着智能体,是 LangChain 的高阶能力,它可以自主选择工具并规划执行步骤。
Agent 的关键组成:
- AgentType :定义决策逻辑的工作流模式
- Tool :是一些内置的功能模块,如API调用、搜索引擎、文本处理、数据查询等工具。Agents通过这些工具来执行特定的功能。
- AgentExecutor :用来运行智能体并执行其决策的工具,负责协调智能体的决策和实际的工具执行。
核心组件5:Retrieval
Retrieval:对应着RAG,检索外部数据,然后在执行生成步骤时将其传递到 LLM。步骤包括文档加载、 切割、Embedding等
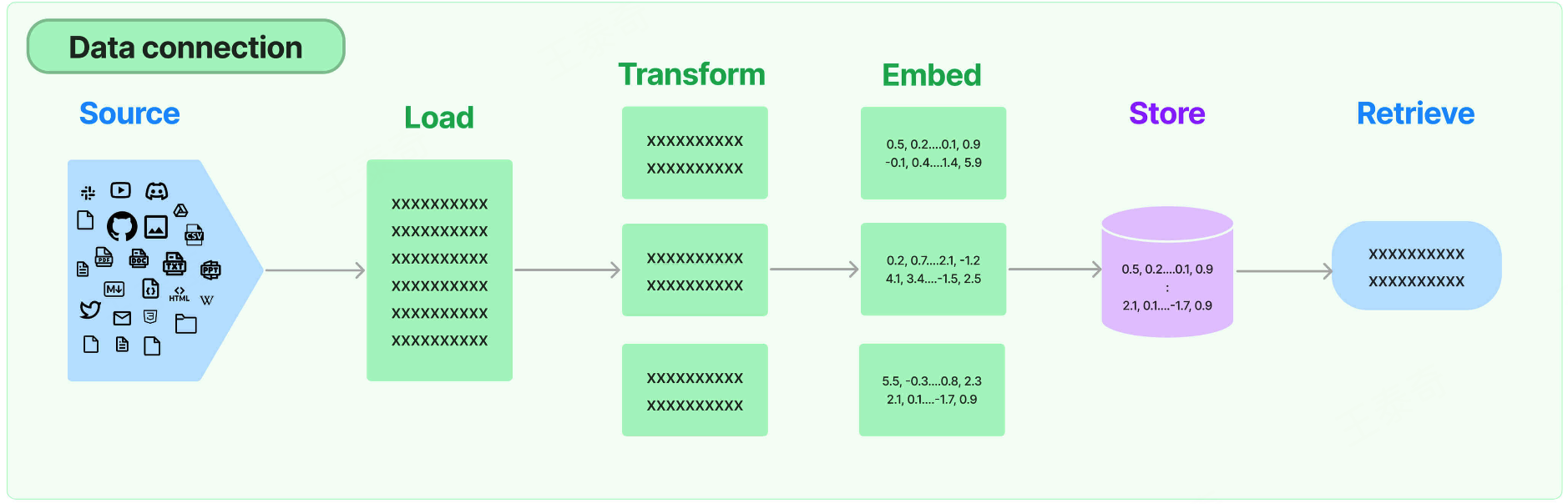
- Source :数据源,即大模型可以识别的多种类型的数据:视频、图片、文本、代码、文档等。
- Load :负责将来自不同数据源的非结构化数据,加载为文档(Document)对象
- Transform:负责对加载的文档进行转换和处理,比如将文本拆分为具有语义意义的小块。
- Embed :将文本编码为向量的能力。一种用于嵌入文档,另一种用于嵌入查询
- Store :将向量化后的数据进行存储
- Retrieve :从大规模文本库中检索和查询相关的文本段落
核心组件6:Callbacks
Callbacks:回调机制,允许连接到 LLM 应用程序的各个阶段,可以监控和分析LangChain的运行情况,比如日志记录、监控、流传输等,以优化性能。
LangChain的helloworld
获取大模型
使用阿里百炼平台生成 key(免费 100W)
开启模型
from langchain_openai import ChatOpenAI
#创建大模型实例
llm=ChatOpenAI(
model= "qwen-plus",
base_url= "https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key= "sk-xxxxx"
)
#提问,调用LLM
response = llm.invoke("什么是大模型?")
print(response)
使用提示词模板
我们也可以创建prompt template, 并引入一些变量到prompt template中,这样在应用的时候更加灵活。
#指明角色,结合上面的代码
prompt = ChatPromptTemplate.from_messages([
("system","你是世界级技术文档编写者"),
("user","{input}")#设置变量
])
#把prompt和 llm调用合在一起
chain = prompt | llm
message = chain.invoke({"input":"大模型中的 LangChain是什么?"})
print(message)
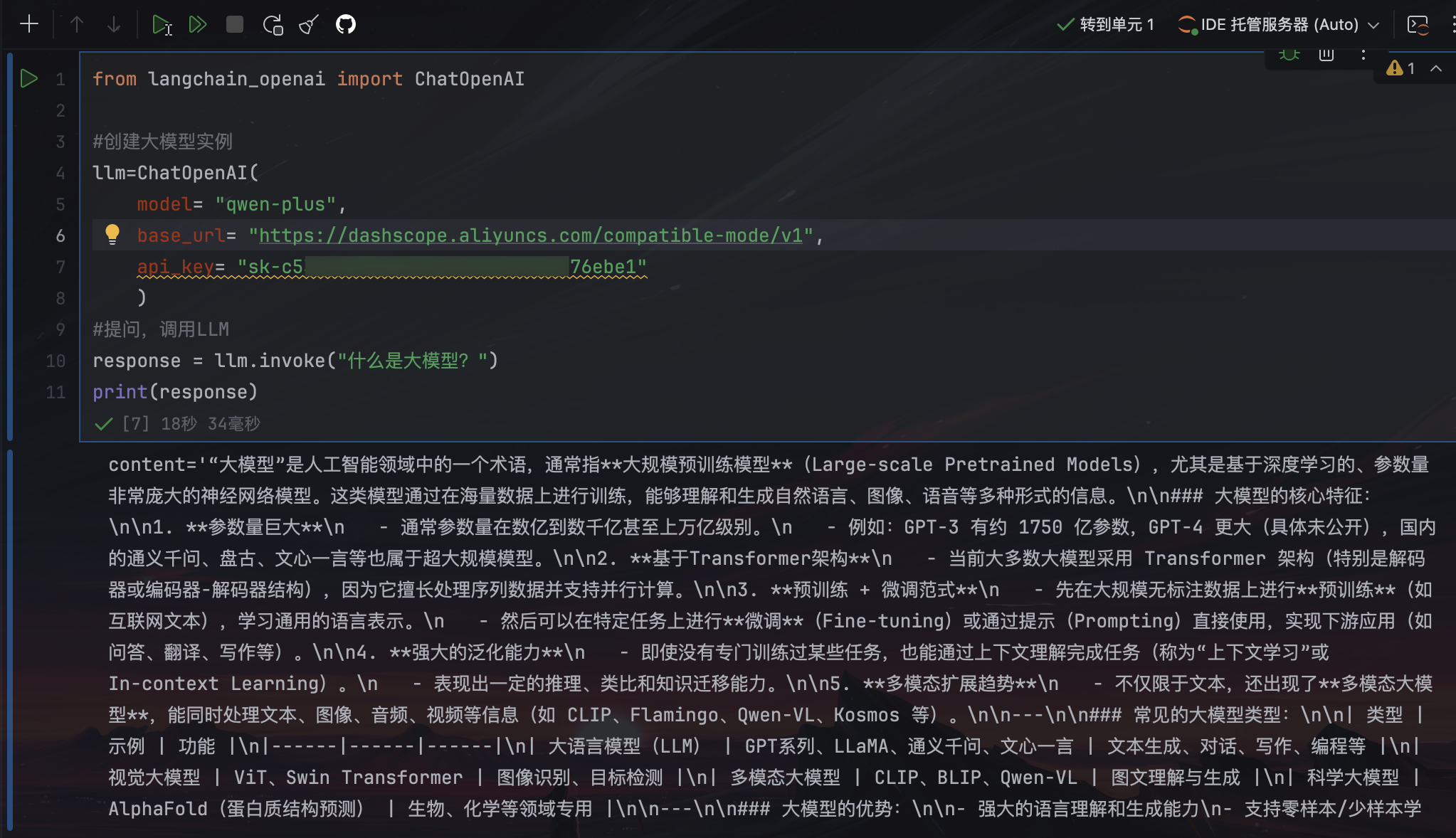
使用输出解析器
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
llm = ChatOpenAI(
model= "qwen-plus",
base_url= "https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key= "sk-xxxxxxxxx"
)
prompt = ChatPromptTemplate.from_messages([
("system","你是世界级技术文档编写者。输出格式要求:{format_instructions}"),
("user","{input}")
])
output_parser = JsonOutputParser()
chain = prompt | llm | output_parser
chain.invoke({"input":"LangChain是什么?","format_instructions":output_parser.get_format_instructions()})
使用向量存储
使用一个简单的本地向量存储 FAISS,首先需要安装它
pip install faiss-cpu
pip instlal langchain_community
from langchain_community.document_loaders import WebBaseLoader
import bs4
#使用Webloader
loader = WebBaseLoader(
web_path= "https://www.gov.cn/zhengce/zhengceku/2008-09/19/content_6630.htm",
bs_kwargs= dict(parse_only=bs4.SoupStrainer(id="UCAP-CONTENT"))
)
docs = loader.load()
#print(docs)
from langchain_openai import OpenAIEmbeddings
#调用嵌入模型
embeddings = OpenAIEmbeddings(
model= "text-embedding-v4",
base_url= "https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key= "sk-xxxxxxxxxx",
check_embedding_ctx_length=False, #避免内部把文本转成 token 数组再发给兼容接口
chunk_size=10 #每次最多发 10 条 input
)
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
#使用分割器分割文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)
documents = text_splitter.split_documents(docs)
#print(len(documents))
#向量存储embeddings会将documents的每个文本片段转换成向量,存储在 FAISS 向量数据库中
vectors = FAISS.from_documents(documents,embeddings)
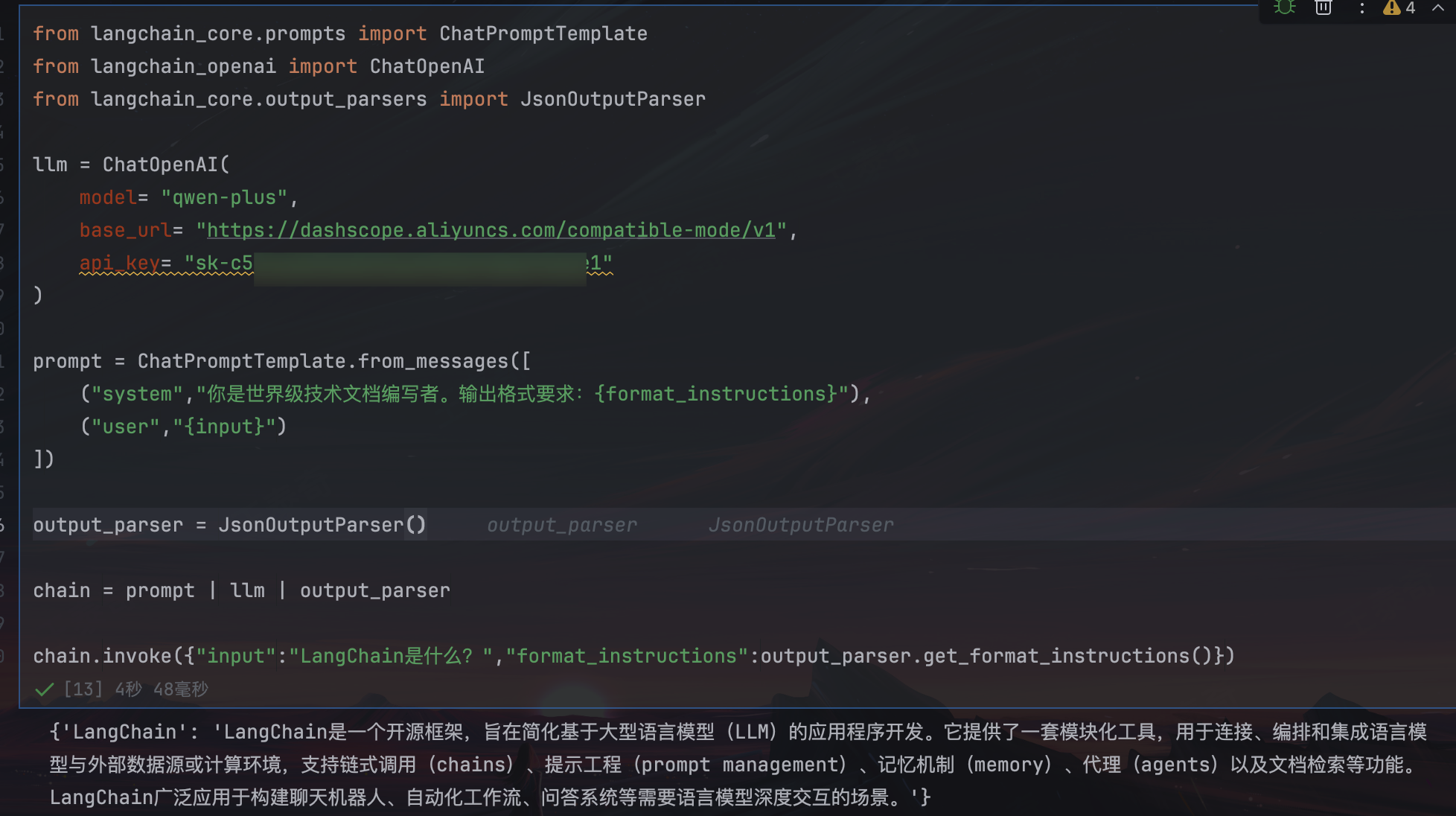
RAG(检索增强生成)
基于外部知识,增强大模型回复
from langchain_core.prompts import PromptTemplate
retriever = vectors.as_retriever()
retriever.search_kwargs = {"k":3}
docs = retriever.invoke("劳动合同法是什么?")
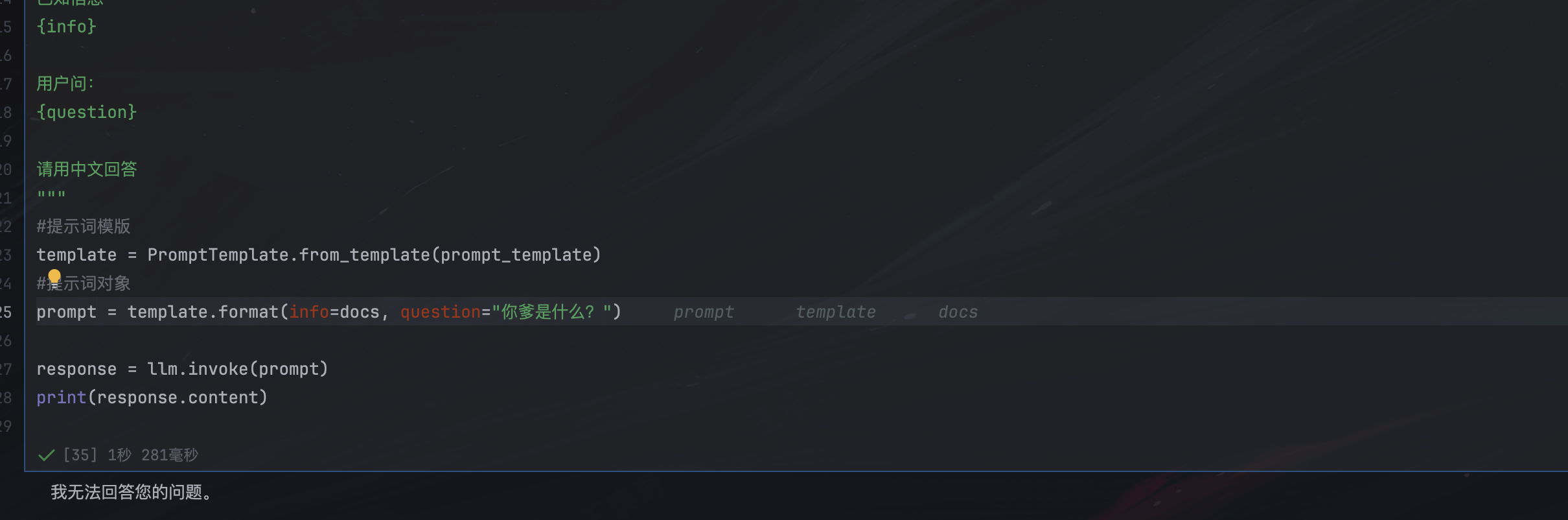
prompt_template = """
你是一个问答机器人。
你的任务是根据下述已知信息回答用户问题。
确保你的回答完全依据下述已知信息,不要编造答案。
如果下述已知信息不足以回答用户问题,请直接回复“我无法回答您的问题”。
已知信息
{info}
用户问:
{question}
请用中文回答
"""
#提示词模版
template = PromptTemplate.from_template(prompt_template)
#提示词对象
prompt = template.format(info=docs, question="劳动合同法是什么?")
response = llm.invoke(prompt)
print(response.content)
使用Agent
API 变化很多,很多库找不到对应的方法,直接提示导入。
pip install -U langsmith
from langsmith import Client
#使用提示词模版 https://smith.langchain.com/hub
client = Client()
prompt = client.pull_prompt("hwchase17/openai-functions-agent")
from langchain_core.tools import create_retriever_tool
#检索器工具
retriever_tool = create_retriever_tool(
retriever,
"LaborContractLawRetriever",
"搜索有关《中华人民共和国劳动合同法》的内容。回答前必须使用该工具检索。"
)
tools = [retriever_tool]
from langsmith import Client
from langchain_classic.agents import create_openai_functions_agent
from langchain_classic.agents import AgentExecutor
#使用提示词模版 https://smith.langchain.com/hub
client = Client()
prompt = client.pull_prompt("hwchase17/openai-functions-agent")
agent = create_openai_functions_agent(llm=llm, tools=tools, prompt=prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
#运行代理
res = agent_executor.invoke({"input": "劳动合同法是什么?"})
print(res["output"])
输出
> Entering new AgentExecutor chain...
Invoking: `LaborContractLawRetriever` with `{'query': '劳动合同法 定义'}`
中华人民共和国主席令
第 六十五 号
《中华人民共和国劳动合同法》已由中华人民共和国第十届全国人民代表大会常务委员会第二十八次会议于2007年6月29日通过,现予公布,自2008年1月1日起施行。
中华人民共和国主席 xxx
二〇〇七年六月二十九日
中华人民共和国劳动合同法
(2007年6月29日第十届全国人民代表大会常务委员会第二十八次会议通过)
目 录
第一章 总 则
第二章 劳动合同的订立
第三章 劳动合同的履行和变更
第四章 劳动合同的解除和终止
第五章 特别规定
第一节 集体合同
第二节 劳务派遣
第三节 非全日制用工
第六章 监督检查
第七章 法律责任
第八章 附 则
第一章 总 则
第一条 为了完善劳动合同制度,明确劳动合同双方当事人的权利和义务,保护劳动者的合法权益,构建和发展和谐稳定的劳动关系,制定本法。
第二条 中华人民共和国境内的企业、个体经济组织、民办非企业单位等组织(以下称用人单位)与劳动者建立劳动关系,订立、履行、变更、解除或者终止劳动合同,适用本法。
国家机关、事业单位、社会团体和与其建立劳动关系的劳动者,订立、履行、变更、解除或者终止劳动合同,依照本法执行。
第三条 订立劳动合同,应当遵循合法、公平、平等自愿、协商一致、诚实信用的原则。
依法订立的劳动合同具有约束力,用人单位与劳动者应当履行劳动合同约定的义务。
第四条 用人单位应当依法建立和完善劳动规章制度,保障劳动者享有劳动权利、履行劳动义务。
用人单位在制定、修改或者决定有关劳动报酬、工作时间、休息休假、劳动安全卫生、保险福利、职工培训、劳动纪律以及劳动定额管理等直接涉及劳动者切身利益的规章制度或者重大事项时,应当经职工代表大会或者全体职工讨论,提出方案和意见,与工会或者职工代表平等协商确定。
在规章制度和重大事项决定实施过程中,工会或者职工认为不适当的,有权向用人单位提出,通过协商予以修改完善。
已建立劳动关系,未同时订立书面劳动合同的,应当自用工之日起一个月内订立书面劳动合同。
用人单位与劳动者在用工前订立劳动合同的,劳动关系自用工之日起建立。
第十一条 用人单位未在用工的同时订立书面劳动合同,与劳动者约定的劳动报酬不明确的,新招用的劳动者的劳动报酬按照集体合同规定的标准执行;没有集体合同或者集体合同未规定的,实行同工同酬。
第十二条 劳动合同分为固定期限劳动合同、无固定期限劳动合同和以完成一定工作任务为期限的劳动合同。
第十三条 固定期限劳动合同,是指用人单位与劳动者约定合同终止时间的劳动合同。
用人单位与劳动者协商一致,可以订立固定期限劳动合同。
第十四条 无固定期限劳动合同,是指用人单位与劳动者约定无确定终止时间的劳动合同。
用人单位与劳动者协商一致,可以订立无固定期限劳动合同。有下列情形之一,劳动者提出或者同意续订、订立劳动合同的,除劳动者提出订立固定期限劳动合同外,应当订立无固定期限劳动合同:
(一)劳动者在该用人单位连续工作满十年的;《中华人民共和国劳动合同法》是为了完善劳动合同制度,明确劳动合同双方当事人的权利和义务,保护劳动者的合法权益,构建和发展和谐稳定的劳动关系而制定的法律。该法于2007年6月29日由第十届全国人民代表大会常务委员会第二十八次会议通过,并自2008年1月1日起施行。
### 主要内容包括:
1. **适用范围**:适用于中华人民共和国境内的企业、个体经济组织、民办非企业单位等组织与劳动者建立劳动关系的情形;国家机关、事业单位、社会团体和与其建立劳动关系的劳动者也依照本法执行。
2. **基本原则**:订立劳动合同应当遵循合法、公平、平等自愿、协商一致、诚实信用的原则。依法订立的劳动合同具有约束力,双方需履行约定义务。
3. **劳动合同的订立**:
- 建立劳动关系时,应当订立书面劳动合同。
- 已建立劳动关系但未同时订立书面合同的,应在用工之日起一个月内补签。
- 劳动合同分为固定期限、无固定期限以及以完成一定工作任务为期限三种类型。
- 在特定情况下(如连续工作满十年),劳动者有权要求签订无固定期限劳动合同。
4. **劳动者的权益保障**:
- 用人单位应依法建立和完善规章制度,保障劳动者享有劳动权利并履行相应义务。
- 涉及劳动者切身利益的重大事项(如薪酬、工时、休息休假等)的规章制度,需经职工代表大会或全体职工讨论,并与工会或职工代表协商确定。
这部法律旨在规范用人单位与劳动者之间的劳动关系,确保劳动者的基本权益得到保护,同时促进社会和谐稳定。
> Finished chain.
《中华人民共和国劳动合同法》是为了完善劳动合同制度,明确劳动合同双方当事人的权利和义务,保护劳动者的合法权益,构建和发展和谐稳定的劳动关系而制定的法律。该法于2007年6月29日由第十届全国人民代表大会常务委员会第二十八次会议通过,并自2008年1月1日起施行。
### 主要内容包括:
1. **适用范围**:适用于中华人民共和国境内的企业、个体经济组织、民办非企业单位等组织与劳动者建立劳动关系的情形;国家机关、事业单位、社会团体和与其建立劳动关系的劳动者也依照本法执行。
2. **基本原则**:订立劳动合同应当遵循合法、公平、平等自愿、协商一致、诚实信用的原则。依法订立的劳动合同具有约束力,双方需履行约定义务。
3. **劳动合同的订立**:
- 建立劳动关系时,应当订立书面劳动合同。
- 已建立劳动关系但未同时订立书面合同的,应在用工之日起一个月内补签。
- 劳动合同分为固定期限、无固定期限以及以完成一定工作任务为期限三种类型。
- 在特定情况下(如连续工作满十年),劳动者有权要求签订无固定期限劳动合同。
4. **劳动者的权益保障**:
- 用人单位应依法建立和完善规章制度,保障劳动者享有劳动权利并履行相应义务。
- 涉及劳动者切身利益的重大事项(如薪酬、工时、休息休假等)的规章制度,需经职工代表大会或全体职工讨论,并与工会或职工代表协商确定。
这部法律旨在规范用人单位与劳动者之间的劳动关系,确保劳动者的基本权益得到保护,同时促进社会和谐稳定。
本文来自博客园,作者:Rodericklog,转载请注明原文链接:https://www.cnblogs.com/rodericklog/articles/19452514

 浙公网安备 33010602011771号
浙公网安备 33010602011771号