Docker简述
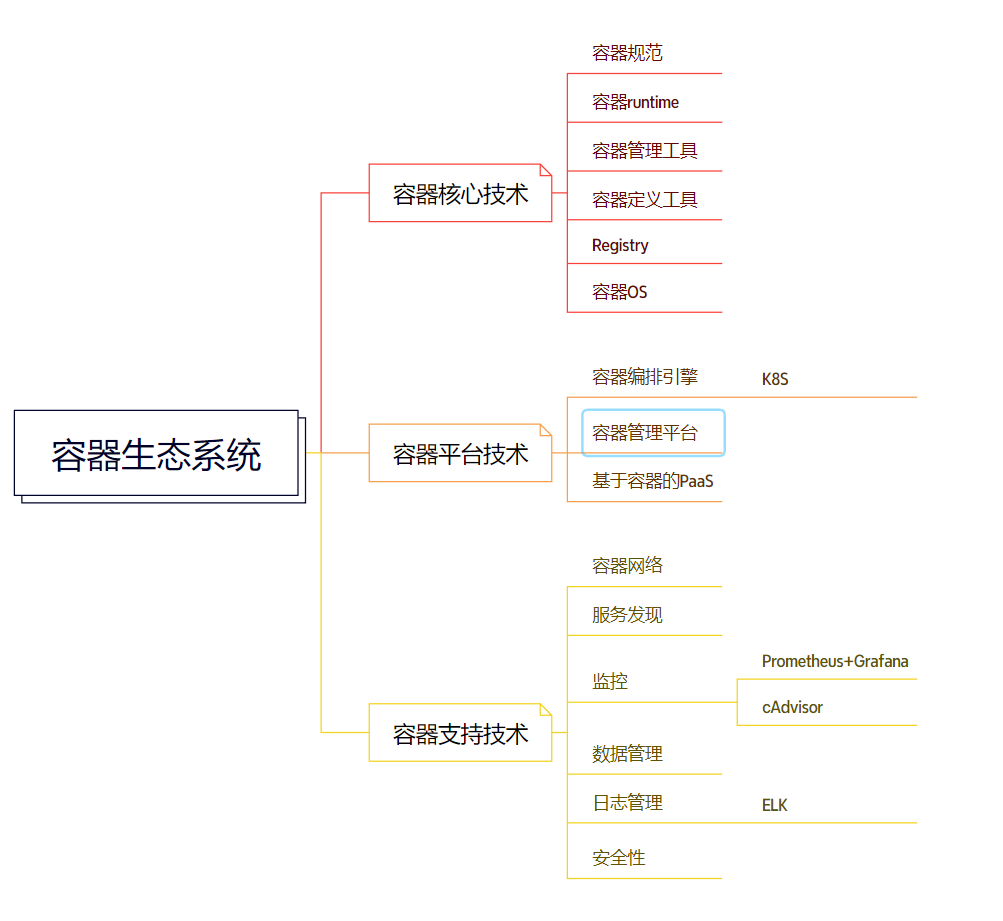
容器生态系统
容器生态系统包含核心技术、平台技术和支持技术
容器核心技术
容器核心技术是指能够让Container在host上运行起来的那些技术。
- 容器规范
- 容器runtime
- 容器管理工具
- 容器定义工具
- Registries
- 容器OS
容器规范
容器不光是Docker,还有其他容器,比如CoreOS的rkt。为了保证容器生态的健康发展,保证不同容器之间能够兼容,包含Docker、CoreOS、Google在内的若干公司共同成立了一个叫Open Container Initiative(OCI)的组织,其目的是制定开放的容器规范。目前OCI发布了两个规范:runtime spec和image format spec。
容器runtime
runtime是容器真正运行的地方。runtime需要跟操作系统kernel紧密协作,为容器提供运行环境。Java程序就好比是容器,JVM则好比是runtime, JVM为Java程序提供运行环境。同样的道理,容器只有在runtime中才能运行。
容器管理工具
光有runtime还不够,用户得有工具来管理容器。容器管理工具对内与runtime交互,对外为用户提供interface,比如CLI。这就好比除了JVM,还得提供Java命令让用户能够启停应用。
runc的管理工具是docker engine。docker engine包含后台deamon和cli两个部分。我们通常提到Docker,一般就是指的docker engine。
容器定义工具
容器定义工具允许用户定义容器的内容和属性,这样容器就能够被保存、共享和重建。
docker image是Docker容器的模板,runtime依据docker image创建容器。
dockerfile是包含若干命令的文本文件,可以通过这些命令创建出docker image。
ACI(App Container Image)与docker image类似,只不过它是由CoreOS开发的rkt容器的image格式。
Registry
容器是通过image创建的,需要有一个仓库来统一存放image,这个仓库就叫做Registry。
容器OS
容器OS是专门运行容器的操作系统。与常规OS相比,容器OS通常体积更小,启动更快。因为是为容器定制的OS,通常它们运行容器的效率会更高。
容器平台技术
容器平台技术包括容器编排引擎、容器管理平台和基于容器的PaaS
容器编排引擎
基于容器的应用一般会采用微服务架构。在这种架构下,应用被划分为不同的组件,并以服务的形式运行在各自的容器中,通过API对外提供服务。为了保证应用的高可用,每个组件都可能会运行多个相同的容器。这些容器会组成集群,集群中的容器会根据业务需要被动态地创建、迁移和销毁。
所谓编排(orchestration),通常包括容器管理、调度、集群定义和服务发现等。通过容器编排引擎,容器被有机地组合成微服务应用,实现业务需求。
- docker swarm是Docker开发的容器编排引擎。
- kubernetes是Google领导开发的开源容器编排引擎,同时支持Docker和CoreOS容器。
- mesos是一个通用的集群资源调度平台,mesos与marathon一起提供容器编排引擎功能。
容器管理平台
容器管理平台是架构在容器编排引擎之上的一个更为通用的平台。通常容器管理平台能够支持多种编排引擎,抽象了编排引擎的底层实现细节,为用户提供更方便的功能,比如application catalog和一键应用部署等。Rancher和ContainerShip是容器管理平台的典型代表。
基于容器的PaaS
基于容器的PaaS为微服务应用开发人员和公司提供了开发、部署和管理应用的平台,使用户不必关心底层基础设施而专注于应用的开发。Deis、Flynn和Dokku都是开源容器PaaS的代表。
容器支持技术
容器网络
容器的出现使网络拓扑变得更加动态和复杂。用户需要专门的解决方案来管理容器与容器、容器与其他实体之间的连通性和隔离性。docker network是Docker原生的网络解决方案。除此之外,我们还可以采用第三方开源解决方案,例如flannel、weave和calico。
服务发现
动态变化是微服务应用的一大特点。当负载增加时,集群会自动创建新的容器;负载减小,多余的容器会被销毁。容器也会根据host的资源使用情况在不同host中迁移,容器的IP和端口也会随之发生变化。服务发现会保存容器集群中所有微服务最新的信息,比如IP和端口,并对外提供API,提供服务查询功能。etcd、consul和zookeeper是服务发现的典型解决方案
监控
docker ps/docker top/docker stats是Docker原生的命令行监控工具。除了命令行,Docker也提供了stats API,用户可以通过HTTP请求获取容器的状态信息。sysdig、cAdvisor/Heapster和Weave Scope是其他开源的容器监控方案。
数据管理
容器经常会在不同的host之间迁移,如何保证持久化数据也能够动态迁移,是Rex-Ray这类数据管理工具提供的能力
日志管理
docker logs是Docker原生的日志工具。而logspout对日志提供了路由功能,它可以收集不同容器的日志并转发给其他工具进行后处理。
安全性
OpenSCAP能够对容器镜像进行扫描,发现潜在的漏洞。
容器核心知识
容器概述
容器是一种轻量级、可移植、自包含的软件打包技术,使应用程序可以在几乎任何地方以相同的方式运行。
容器与虚拟机区别:
容器由两部分组成:(1)应用程序本身;(2)依赖:比如应用程序需要的库或其他软件容器在Host操作系统的用户空间中运行,与操作系统的其他进程隔离。这一点显著区别于的虚拟机。
传统的虚拟化技术,比如VMWare、KVM、Xen,目标是创建完整的虚拟机。为了运行应用,除了部署应用本身及其依赖(通常几十MB),还得安装整个操作系统(几十GB)。
容器解决的问题
容器使软件具备了超强的可移植能力。方便快捷。
容器的优势
容器意味着环境隔离和可重复性。开发人员只需为应用创建一次运行环境,然后打包成容器便可在其他机器上运行。另外,容器环境与所在的Host环境是隔离的,就像虚拟机一样,但更快更简单。
只需要配置好标准的runtime环境,服务器就可以运行任何容器。这使得运维人员的工作变得更高效、一致和可重复。容器消除了开发、测试、生产环境的不一致性。
容器是如何工作的
Docker架构
Docker的核心组件包括:
- Docker客户端:Client
- Docker服务器:Docker daemon
- Docker镜像:Image、
- Registry
- Docker容器:Container
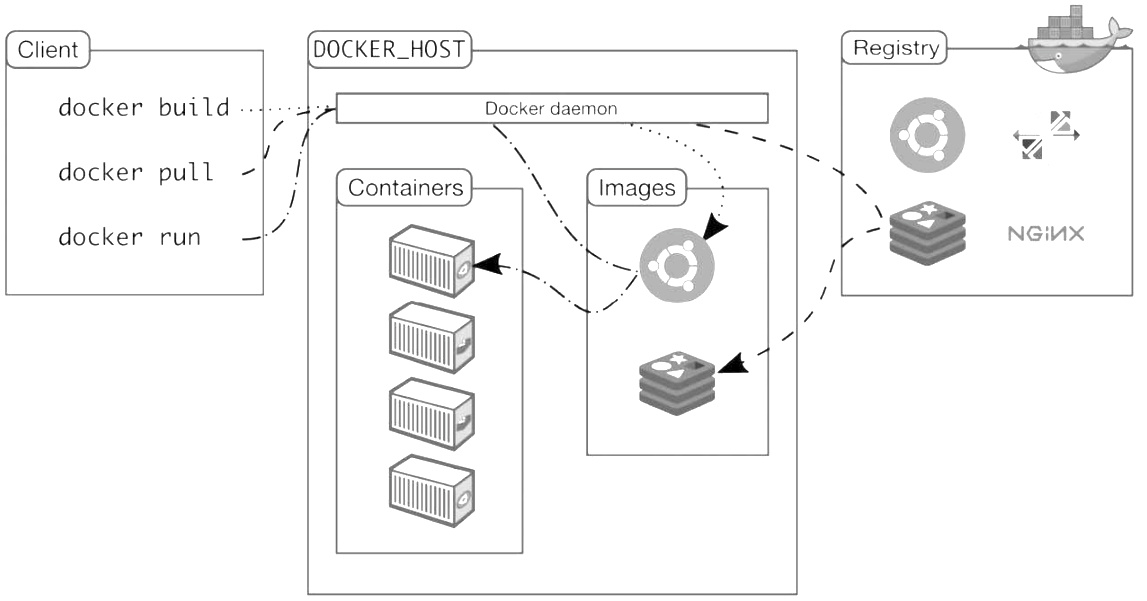
Docker采用的是Client/Server架构。客户端向服务器发送请求,服务器负责构建、运行和分发容器。客户端和服务器可以运行在同一个Host上,客户端也可以通过socket或REST API与远程的服务器通信。
Docker客户端
最常用的Docker客户端是docker命令。通过docker我们可以方便地在Host上构建和运行容器。
除了docker命令行工具,用户也可以通过REST API与服务器通信。
Docker服务器
Docker daemon是服务器组件,以Linux后台服务的方式运行。Docker daemon运行在Docker host上,负责创建、运行、监控容器,构建、存储镜像。
默认配置下,Docker daemon只能响应来自本地Host的客户端请求。如果要允许远程客户端请求,需要在配置文件中打开TCP监听,步骤如下:
- 编辑配置文件 /etc/systemd/system/multi-user.target.wants/docker.service,在环境变量ExecStart后面添加 -H tcp://0.0.0.0,允许来自任意IP的客户端连接。
- 重启Docker daemon。systemctl daemon-reload/systemctl restart docker.service
- 服务器IP为192.168.56.102,客户端在命令行里加上 -H参数,即可与远程服务器通信。 docker -H 192.168.56.102 info
Docker镜像
可将Docker镜像看成只读模板,通过它可以创建Docker容器。
镜像有多种生成方法:
(1)从无到有开始创建镜像;
(2)下载并使用别人创建好的现成的镜像;
(3)在现有镜像上创建新的镜像。
可以将镜像的内容和创建步骤描述在一个文本文件中,这个文件被称作Dockerfile,通过执行docker build
Docker容器
Docker容器就是Docker镜像的运行实例。用户可以通过CLI(Docker)或是API启动、停止、移动或删除容器。
Registry
Registry是存放Docker镜像的仓库,Registry分私有和公有两种。
docker pull命令可以从Registry下载镜像。docker run命令则是先下载镜像(如果本地没有),然后再启动容器。
Docker镜像
hello-world是Docker官方提供的一个镜像,通常用来验证Docker是否安装成功。用docker images命令查看镜像的信息。
Dockerfile是镜像的描述文件,定义了如何构建Docker镜像。Dockerfile的语法简洁且可读性强。
base镜像
base镜像有两层含义:(1)不依赖其他镜像,从scratch构建;(2)其他镜像可以以之为基础进行扩展。
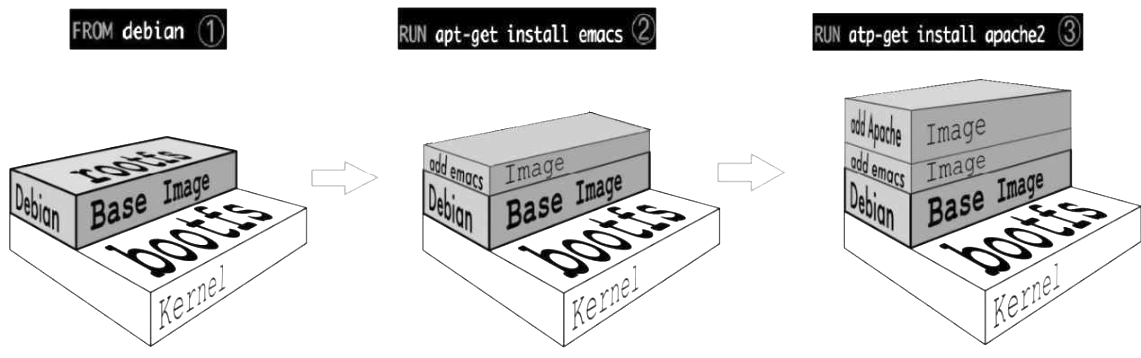
镜像的分层结构
Docker Hub中99%的镜像都是通过在base镜像中安装和配置需要的软件构建出来的。
如Dockerfile
FROM debian
RUN apt-get install emacs
RUN apt-get install apache2
CMD ["/bin/bash"]
① 新镜像不再是从scratch开始,而是直接在Debian base镜像上构建
② 安装emacs编辑器。
③ 安装apache2。
④ 容器启动时运行bash。
新镜像是从base镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层。分层结构最大的一个好处就是:共享资源
构建镜像
(1)找不到现成的镜像,比如自己开发的应用程序。
(2)需要在镜像中加入特定的功能,比如官方镜像几乎都不提供ssh。
Docker提供了两种构建镜像的方法: docker commit命令与Dockerfile构建文件。
-
docker commit命令是创建新镜像最直观的方法,其过程包含三个步骤:
- 运行容器。
- 修改容器。
- 将容器保存为新的镜像。
-
Dockerfile 使用docker build -t imagename -f Dockerfile文件目录
- 通过docker images查看镜像信息
- 查看镜像分层结构 docker history imagename。docker history会显示镜像的构建历史,也就是Dockerfile的执行过程。
-
镜像的缓存特性
- Docker会缓存已有镜像的镜像层,构建新镜像时,如果某镜像层已经存在,就直接使用,无须重新创建。如果我们希望在构建镜像时不使用缓存,可以在docker build命令中加上--no-cache参数。交换命令也算是新的过程,缓存失效。
-
调试Dockerfile
-
Dockerfile构建镜像的过程
- 从base镜像运行一个容器。
- 执行一条指令,对容器做修改。
- 执行类似docker commit的操作,生成一个新的镜像层。
- Docker再基于刚刚提交的镜像运行一个新容器。
- 重复2~4步,直到Dockerfile中的所有指令执行完毕。
-
如果Dockerfile由于某种原因执行到某个指令失败了,我们也将能够得到前一个指令成功执行构建出的镜像。执行docker build -it id进行调试。
-
-
Dockerfile常用指令
FROM #指定base镜像。
MAINTAINER #设置镜像的作者,可以是任意字符串。
COPY #将文件从build context复制到镜像。COPY src dest
ADD #与COPY类似,不同的是,如果src是归档文件(tar、zip、tgz、xz等)文件会被自动解压到dest。
ENV #设置环境变量,环境变量可被后面的指令使用。
EXPOSE #指定容器中的进程会监听某个端口,Docker可以将该端口暴露出来。
VOLUME #将文件或目录声明为volume。
WORKDIR #为后面的RUN、CMD、ENTRYPOINT、ADD或COPY指令设置镜像中的当前工作目录。
RUN #在容器中运行指定的命令。
CMD #容器启动时运行指定的命令。Dockerfile中可以有多个CMD指令,但只有最后一个生效。CMD可以被dockerrun之后的参数替换。
ENTRYPOINT # 设置容器启动时运行的命令。Dockerfile中可以有多个ENTRYPOINT指令,但只有最后一个生效。CMD或docker run之后的参数会被当作参数传递给ENTRYPOINT。
(1)RUN:执行命令并创建新的镜像层,RUN经常用于安装软件包。(2)CMD:设置容器启动后默认执行的命令及其参数,但CMD能够被docker run后面跟的命令行参数替换。
(3)ENTRYPOINT:配置容器启动时运行的命令。
分发镜像
(1)用相同的Dockerfile在其他host构建镜像。
(2)将镜像上传到公共Registry(比如Docker Hub), Host直接下载使用。
(3)搭建私有的Registry供本地Host使用。
为镜像命名
当我们执行docker build命令时已经为镜像取了个名字。docker build -t imagename:tag
使用公共Registry
Docker Hub是Docker公司维护的公共Registry。用户可以将自己的镜像保存到Docker Hub免费的repository中。如果不希望别人访问自己的镜像,也可以购买私有repository。
搭建本地Registry
使用的镜像registry:2
docker push registry:2
Docker容器
运行容器
可用三种方式指定容器启动时执行的命令:
(1)CMD指令。(2)ENTRYPOINT指令。(3)在docker run命令行中指定。
执行docker ps或docker container ls可以查看Docker host中当前运行的容器
-a会显示所有状态的容器,可以看到,之前的容器已经退出了,状态为Exited。
让容器长期运行
因为容器的生命周期依赖于启动时执行的命令,只要该命令不结束,容器也就不会退出。
docker run -d ubantu /bin/bash -c "while ture;do sleep 1; done"
可以加上参数 -d以后台方式启动容器
两种进入容器的方法
1、docker attach 通过docker attach可以attach到容器启动命令的终端,可通过Ctrl+p,然后Ctrl+q组合键退出attach终端。
docker attach containerID
2、docker exec
docker exec -it containerID
-it以交互模式打开pseudo-TTY,执行bash,其结果就是打开了一个bash终端。
进入到容器中,容器的hostname就是其“短ID”。
可以像在普通Linux中一样执行命令。ps -elf显示了容器启动进程while以及当前的bash进程。
执行exit退出容器,回到docker host
attach与exec主要区别如下
- attach直接进入容器启动命令的终端,不会启动新的进程。
- exec则是在容器中打开新的终端,并且可以启动新的进程。
- 如果想直接在终端中查看启动命令的输出,用attach,也可以使用docker logs -f containerID命令;其他情况使用exec。
stop/start/restart容器
通过docker stop可以停止运行的容器,docker stop命令本质上是向该进程发送一个SIGTERM信号。如果想快速停止容器,可使用docker kill命令,其作用是向容器进程发送SIGKILL信号
对于处于停止状态的容器,可以通过docker start重新启动
容器可能会因某种错误而停止运行。对于服务类容器,我们通常希望在这种情况下容器能够自动重启。启动容器时设置 --restart就可以达到这个效果
--restart=always意味着无论容器因何种原因退出(包括正常退出),都立即重启;该参数的形式还可以是 --restart=on-failure:3,意思是如果启动进程退出代码非0,则重启容器,最多重启3次。
docker stop
docker kill
docker start
--restart=always
--restart=on-failure:3
pause / unpause容器
有时我们只是希望让容器暂停工作一段时间,比如要对容器的文件系统打个快照,或者dcoker host需要使用CPU,这时可以执行docker pause 。处于暂停状态的容器不会占用CPU资源,直到通过docker unpause恢复运行
删除容器
host上可能会有大量已经退出了的容器,这些容器依然会占用host的文件系统资源,如果确认不会再重启此类容器,可以通过docker rm删除
docker rm -v $(doker ps -aq -f status=exited)
docker rm #删除容器
docker rmi #删除镜像
State Machine
docker create创建的容器处于Created状态。docker start将以后台方式启动容器。docker run命令实际上是docker create和docker start的组合。
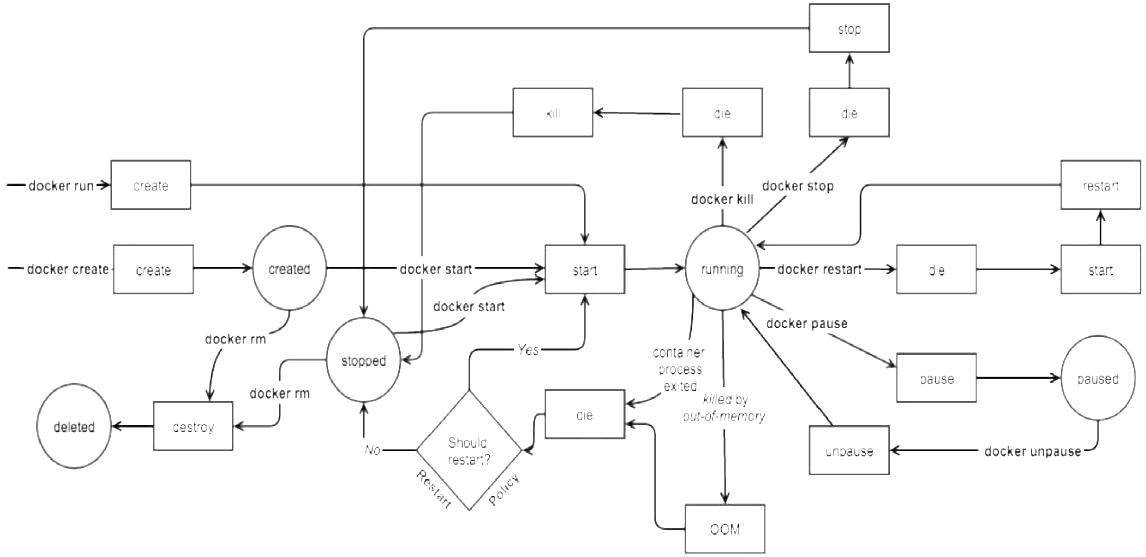
启动进程正常退出或发生OOM,此时Docker会根据 --restart的策略判断是否需要重启容器。但如果容器是因为执行docker stop或docker kill退出,则不会自动重启。
资源限制
一个docker host上会运行若干容器,每个容器都需要CPU、内存和IO资源。对于KVM、VMware等虚拟化技术,用户可以控制分配多少CPU、内存资源给每个虚拟机。对于容器,Docker也提供了类似的机制避免某个容器因占用太多资源而影响其他容器乃至整个host的性能。
内存限额
物理内存和swap。Docker通过下面两组参数来控制容器内存的使用量。(1)-m或 --memory:设置内存的使用限额,例如100MB,2GB。
(2)--memory-swap:设置内存+swap的使用限额。
docker run -m 200M --menmory-swap=300M ubantu
CPU限额
默认设置下,所有容器可以平等地使用host CPU资源并且没有限制。
Docker可以通过 -c或 --cpu-shares设置容器使用CPU的权重。如果不指定,默认值为1024。与内存限额不同,通过 -c设置的cpu share并不是CPU资源的绝对数量,而是一个相对的权重值。某个容器最终能分配到的CPU资源取决于它的cpu share占所有容器cpu share总和的比例。换句话说:通过cpu share可以设置容器使用CPU的优先级。
docker run --name A -c 1024 ubantu
docker run --name B -c 512 ubantu
Block IO带宽限额
Block IO是另一种可以限制容器使用的资源。Block IO指的是磁盘的读写,docker可通过设置权重、限制bps和iops的方式控制容器读写磁盘的带宽。
block IO权重
默认情况下,所有容器能平等地读写磁盘,可以通过设置 --blkio-weight参数来改变容器block IO的优先级。也是权重
限制bps和iops
bps是byte per second,每秒读写的数据量。
iops是io per second,每秒IO的次数。
可通过以下参数控制容器的bps和iops:
- --device-read-bps:限制读某个设备的bps。
- --device-write-bps:限制写某个设备的bps。
- --device-read-iops:限制读某个设备的iops。
- --device-write-iops:限制写某个设备的iops。
#限制容器写 /dev/sda的速率为30 MB/s
docker run -it --device-write-bps /dev/sda:30MB ubantu
实现容器的底层技术
cgroup和namespace是最重要的两种技术。cgroup实现资源限额,namespace实现资源隔离。
cgroup
cgroup全称Control Group。Linux操作系统通过cgroup可以设置进程使用CPU、内存和IO资源的限额。--cpu-shares、-m、--device-write-bps实际上就是在配置cgroup。可以在 /sys/fs/cgroup中找到它
启动一个容器,设置 --cpu-shares=512
docker run -it --cpu-shares 512 progrium/stress -c 1
在 /sys/fs/cgroup/cpu/docker目录中,Linux会为每个容器创建一个cgroup目录,以容器长ID命名。目录中包含所有与cpu相关的cgroup配置,文件cpu.shares保存的就是 --cpu-shares的配置,值为512。

/sys/fs/cgroup/memory/docker和 /sys/fs/cgroup/blkio/docker中保存的是内存以及Block IO的cgroup配置
namespace
在每个容器中,我们都可以看到文件系统、网卡等资源,这些资源看上去是容器自己的。拿网卡来说,每个容器都会认为自己有一块独立的网卡,即使host上只有一块物理网卡。
Linux实现这种方式的技术是namespace。namespace管理着host中全局唯一的资源,并可以让每个容器都觉得只有自己在使用它。换句话说,namespace实现了容器间资源的隔离。
Linux使用了6种namespace,分别对应6种资源:Mount、UTS、IPC、PID、Network和User
Mount namespace
Mount namespace让容器看上去拥有整个文件系统。容器有自己的/目录,可以执行mount和umount命令。当然我们知道这些操作只在当前容器中生效,不会影响到host和其他容器。
UTS namespace
UTS namespace让容器有自己的hostname。默认情况下,容器的hostname是它的短ID,可以通过 -h或 --hostname参数设置
IPC namespace
IPC namespace让容器拥有自己的共享内存和信号量(semaphore)来实现进程间通信,而不会与host和其他容器的IPC混在一起。
PID namespace
容器在host中以进程的形式运行。例如当前host中运行了两个容器。通过ps axf可以查看容器进程。所有容器的进程都挂在dockerd进程下,同时也可以看到容器自己的子进程。
Network namespace
Network namespace让容器拥有自己独立的网卡、IP、路由等资源。
User namespace
User namespace让容器能够管理自己的用户,host不能看到容器中创建的用户。
Docker网络
Docker网络从覆盖范围可分为单个host上的容器网络和跨多个host的网络,本章重点讨论前一种。
Docker安装时会自动在host上创建三个网络,我们可用docker network ls命令查看
none网络
none网络就是什么都没有的网络。挂在这个网络下的容器除了lo,没有其他任何网卡。容器创建时,可以通过 --network=none指定使用none网络。
docker run -it --network=none busybox
封闭意味着隔离,一些对安全性要求高并且不需要联网的应用可以使用none网络。
host网络
连接到host网络的容器共享Docker host的网络栈,容器的网络配置与host完全一样。可以通过 --network=host指定使用host网络
docker run -it --network=host busybox
直接使用Docker host的网络最大的好处就是性能,如果容器对网络传输效率有较高要求,则可以选择host网络。Docker host的另一个用途是让容器可以直接配置host网路,比如某些跨host的网络解决方案,其本身也是以容器方式运行的,这些方案需要对网络进行配置,比如管理iptables
bridge网络
Docker安装时会创建一个命名为docker0的Linux bridge。如果不指定--network,创建的容器默认都会挂到docker0上。 brctl show可以看网卡
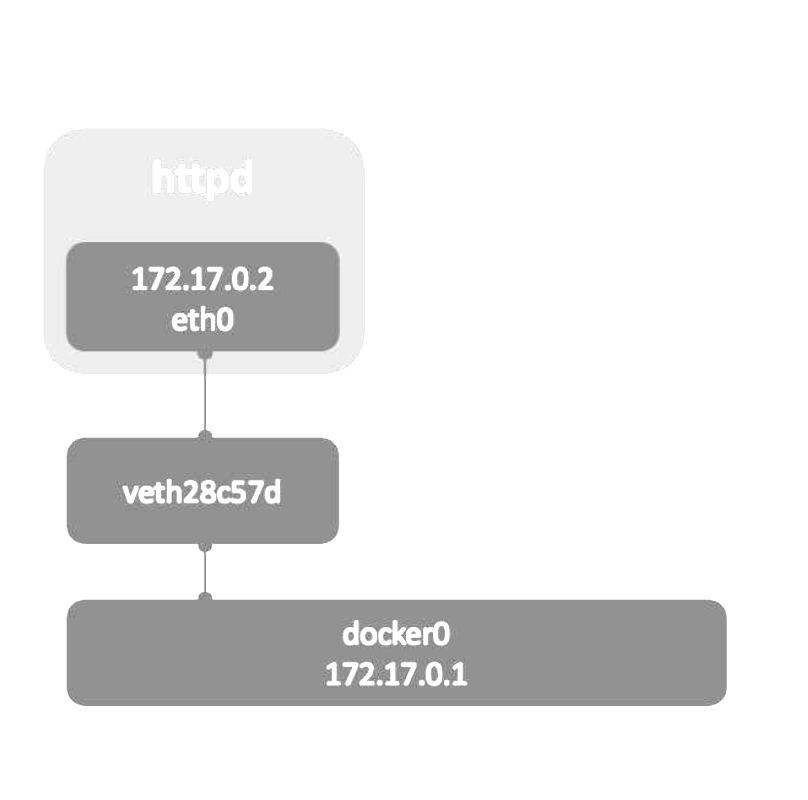
容器创建时,docker会自动从172.17.0.0/16中分配一个IP
通过docker network inspect bridge看一下bridge网络的配置信息
user-defined网络
除了none、host、bridge这三个自动创建的网络,用户也可以根据业务需要创建user-defined网络。
Docker提供三种user-defined网络驱动:bridge、overlay和macvlan。overlay和macvlan用于创建跨主机的网络。这里创建bridge
docker network create --driver bridge my_net
docker network inspect my_net #查看
#设置网络
--subnet 172.22.16.0/24
--gateway 172.22.16.1
#使用 --ip 指定IP 只有使用 --subnet创建的网络才能指定静态IP。
docker network create --driver bridge my_net2 --subnet 172.22.16.0/24 --gateway 172.22.16.1
docker run -it --network=my_net2 --ip 172.22.16.8 busybox
不同的网卡 host 的iptables 默认DROP 无法连通。
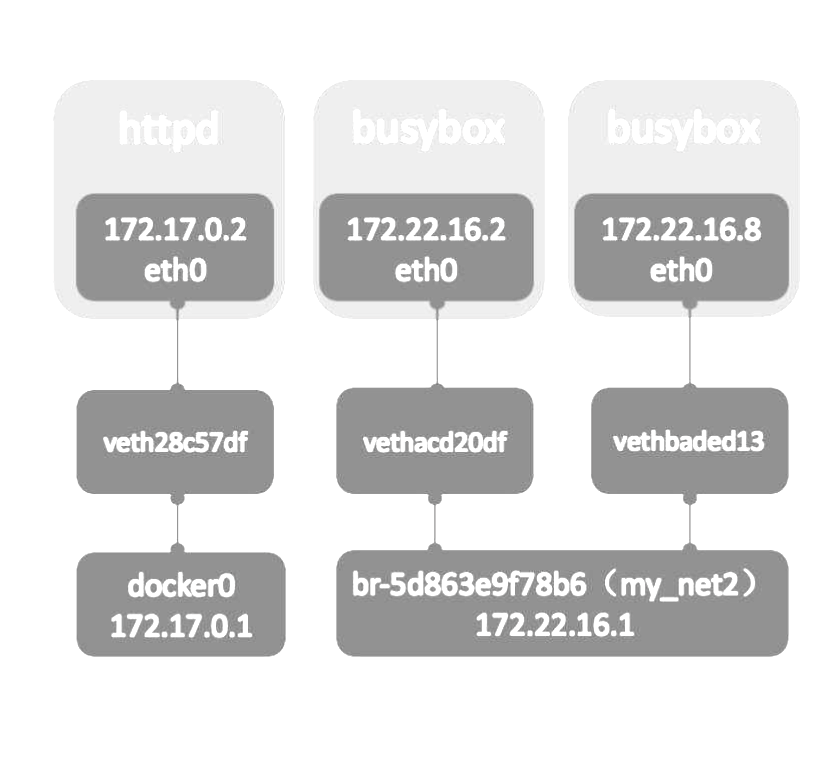
为httpd容器添加一块net_my2的网卡。
docker network connect my_net2 httpd容器ID

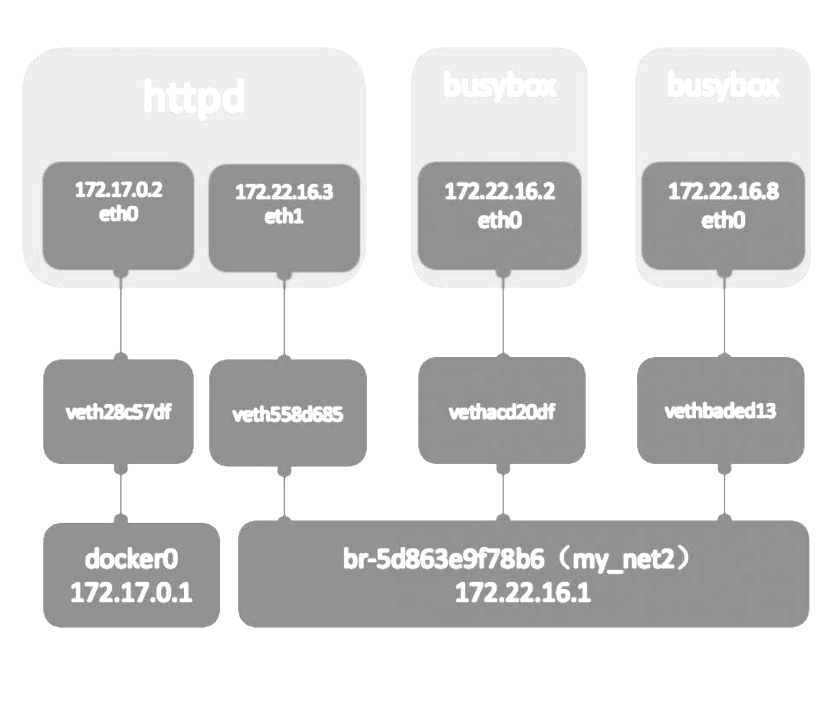
容器间通信
容器之间可通过IP, Docker DNS Server或joined容器三种方式通信。两个容器要能通信,必须要有属于同一个网络的网卡。满足这个条件后,容器就可以通过IP交互了。
IP
具体做法是在容器创建时通过 --network指定相应的网络,或者通过docker network connect将现有容器加入到指定网络。
Docker DNS Server
通过IP访问容器虽然满足了通信的需求,但还是不够灵活。因为在部署应用之前可能无法确定IP,部署之后再指定要访问的IP会比较麻烦。
docker daemon实现了一个内嵌的DNS server,使容器可以直接通过“容器名”通信。方法很简单,只要在启动时用 --name为容器命名就可以了。
docker run -d -it --network=my_net2 --name box1 busybox
docker run -it --network=my_net2 --name box2 busybox
ping -c 3 box1
使用docker DNS有个限制:只能在user-defined网络中使用。也就是说,默认的bridge网络是无法使用DNS的。
joined容器
joined容器非常特别,它可以使两个或多个容器共享一个网络栈,共享网卡和配置信息,joined容器之间可以通过127.0.0.1直接通信。
docker run -d -it --name=web1 httpd
docker run -it --network=container:web1 busybox
#两个容器使用相同的网卡
joined容器非常适合以下场景:
(1)不同容器中的程序希望通过loopback高效快速地通信,比如Web Server与App Server。
(2)希望监控其他容器的网络流量,比如运行在独立容器中的网络监控程序。
将容器与外部世界连接
容器访问外部世界
通过NAT, docker实现了容器对外网的访问。
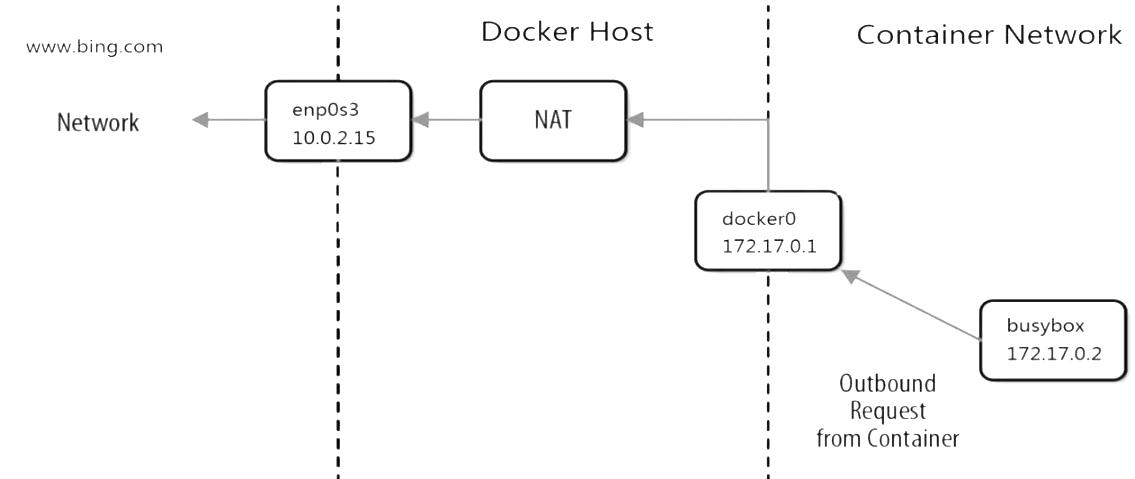
(1)busybox发送ping包:172.17.0.2 > www.bing.com。
(2)docker0收到包,发现是发送到外网的,交给NAT处理。
(3)NAT将源地址换成enp0s3的IP:10.0.2.15 > www.bing.com。
(4)ping包从enp0s3发送出去,到达www.bing.com。
外部世界访问容器
端口映射
docker可将容器对外提供服务的端口映射到host的某个端口,外网通过该端口访问容器。容器启动时通过-p参数映射端口。
docker run -d -p [host port]:[container port] httpd
docker run -d -p 8080:80 httpd
每一个映射的端口,host都会启动一个docker-proxy进程来处理访问容器的流量。
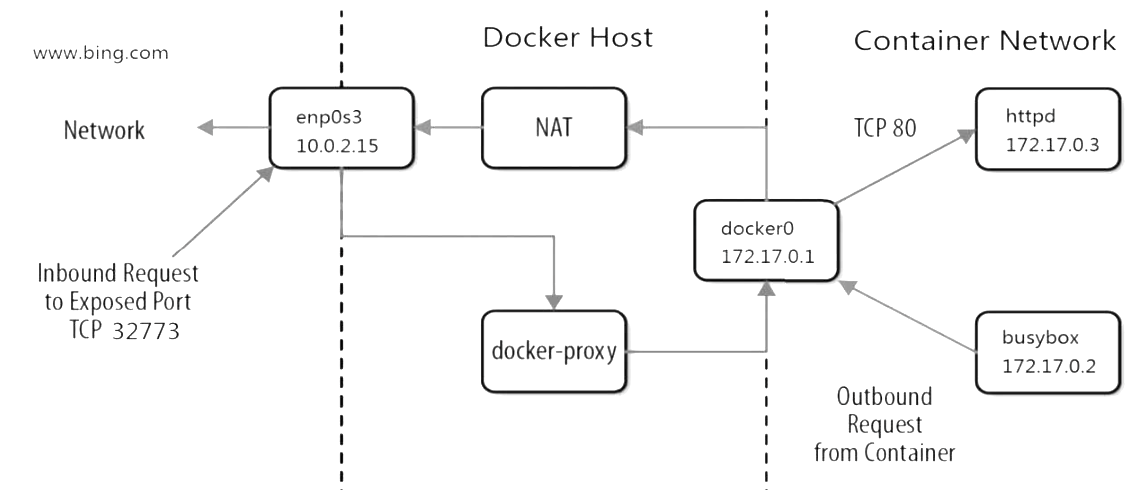
(1)docker-proxy监听host的32773端口。
(2)当curl访问10.0.2.15:32773时,docker-proxy转发给容器172.17.0.2:80。
(3)httpd容器响应请求并返回结果。
Docker存储
Docker为容器提供了两种存放数据的资源:
(1)由storage driver管理的镜像层和容器层。(2)Data Volume。
Storage driver
storage driver实现了多层数据的堆叠并为用户提供一个单一的合并之后的统一视图。
Docker支持多种storage driver,有AUFS、Device Mapper、Btrfs、OverlayFS、VFS和ZFS。优先使用Linux发行版默认的storage driver。
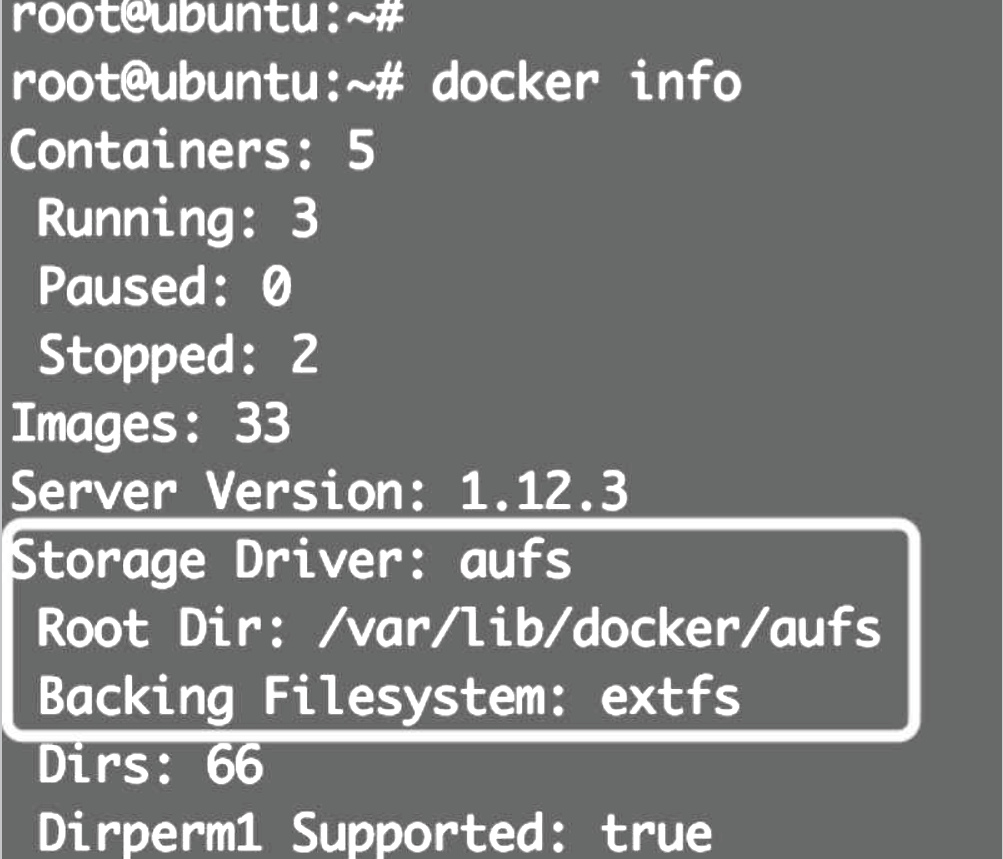
Ubuntu默认driver用的是AUFS,底层文件系统是extfs
Redhat/CentOS的默认driver是Device Mapper, SUSE则是Btrfs
容器没有需要持久化的数据,随时可以从镜像直接创建。使用storage driver即可。
Data Volume
Data Volume本质上是Docker Host文件系统中的目录或文件,能够直接被mount到容器的文件系统中。
(1)Data Volume是目录或文件,而非没有格式化的磁盘(块设备)。
(2)容器可以读写volume中的数据。
(3)volume数据可以被永久地保存,即使使用它的容器已经销毁。
因为volume实际上是docker host文件系统的一部分,所以volume的容量取决于文件系统当前未使用的空间,目前还没有方法设置volume的容量。
在具体的使用上,docker提供了两种类型的volume:bind mount和docker managed volume。
bind mount
bind mount是将host上已存在的目录或文件mount到容器。
docker run -d -p 80:80 -v ~/htdocs:/usr/local/apache2/htdocs httpd
-v的格式为
即使容器没有了,bind mount也还在。bind mount时还可以指定数据的读写权限,默认是可读可写,可指定为只读
docker run -d -p 80:80 -v ~/htdocs:/usr/local/apache2/htdocs:ro httpd
ro=Read-only 只有host有权修改数据,提高了安全性。
docker managed volume
docker managed volume与bind mount在使用上的最大区别是不需要指定mount源
docker run -d -p 80:80 -v /usr/local/apache2/htdocs httpd
docker inspect 容器长ID #查看存储源位置

数据共享
数据共享是volume的关键特性。
容器与host共享数据
有两种类型的data volume,它们均可实现在容器与host之间共享数据。
-
对于bind mount是非常明确的:直接将要共享的目录mount到容器。
-
docker managed volume就要麻烦点。由于volume位于host中的目录,是在容器启动时才生成,所以需要将共享数据复制到volume中。
-
docker run -d -p 80:80 -v /usr/local/apache2/htdocs httpd docker cp ~/htdocs/index.html 容器ID:/usr/local/apache2/htdocs //也可以直接通过Linux的cp命令复制到 /var/lib/docker/volumes/xxx。
-
容器之间共享数据
bind mount
第一种方法是将共享数据放在bind mount中,然后将其mount到多个容器。
docker run --name web1 -d -p 80 -v ~/htdocs:/usr/local/apache2/htdocs httpd
docker run --name web2 -d -p 80 -v ~/htdocs:/usr/local/apache2/htdocs httpd
volume container
另一种在容器之间共享数据的方式是使用volume container。volume container是专门为其他容器提供volume的容器。它提供的卷可以是bind mount,也可以是docker managed volume。
docker create vc_data \
-v ~/htdocs:/usr/local/apache2/htdocs \
-v /other/useful/tools httpd
docker run --name web1 -d -p 80 -v ~/htdocs:/usr/local/apache2/htdocs httpd
容器命名为vc_data,docker create命令,这是因为volume container的作用只是提供数据,它本身不需要处于运行状态。
(1)bind mount,存放Web Server的静态文件。
(2)docker managed volume,存放一些实用工具
其他容器可以通过--volumes-from使用vc_data这个volume container
docker run --name web1 -d -p 80 --volumes-from vc_data httpd
docker run --name web2 -d -p 80 --volumes-from vc_data httpd
data-packed volume container
将数据完全放到volume container中,同时又能与其他容器共享。原理是将数据打包到镜像中,然后通过docker managed volume共享。
build新镜像datapacked
FROM busybox:latest
ADD htdocs /usr/local/apache2/htdocs
VOLUME /usr/local/apache2/htdocs
//build新镜像datapacked
docker build -t datapacked .
ADD将静态文件添加到容器目录 /usr/local/apache2/htdocs。
VOLUME的作用与 -v 等效,用来创建docker managed volume, mount point为/usr/local/apache2/htdocs,因为这个目录就是ADD添加的目录,所以会将已有数据复制到volume中。
//build新镜像datapacked
docker create --name vc_data datapacked
因为在Dockerfile中已经使用了VOLUME指令,这里就不需要指定volume的mount point了,启动httpd容器并使用data-packed volume container。和volume container其实一样。
docker run --name web2 -d -p 80:80 --volumes-from vc_data httpd
容器能够正确读取volume中的数据。data-packed volume container是自包含的,不依赖host提供数据,具有很强的移植性,非常适合只使用静态数据的场景,比如应用的配置信息、Web server的静态文件等。
Data Volume生命周期管理
备份、恢复、迁移和销毁volume。
备份
因为volume实际上是host文件系统中的目录和文件,所以volume的备份实际上是对文件系统的备份。
恢复
volume的恢复也很简单,如果数据损坏了,直接用之前备份的数据复制到对应的目录就可以了。
迁移
如果我们想使用更新版本的Registry,这就涉及数据迁移,方法是:(1)docker stop当前Registry容器。(2)启动新版本容器并mount原有volume。
docker run -d -p 5000:5000 /myregistry:/var/lib/registry registry:latest
在启用新容器前要确保新版本的默认数据路径是否发生变化。
销毁
可以删除不再需要的volume,但一定要确保知道自己正在做什么,volume删除后数据是找不回来的。
docker不会销毁bind mount,删除数据的工作只能由host负责。对于docker managed volume,在执行docker rm删除容器时可以带上 -v参数,docker会将容器使用到的volume一并删除。
docker volume ls //查询docker managed volume
docker rm box //无法直接删除需要 -v
或者
docker volume rm xxxID
docker volume rm $(docker volume ls -q) //批量删除孤儿volume
容器进阶知识
多主机管理
Docker给出的解决方案是Docker Machine,用Docker Machine可以批量安装和配置docker host,这个host可以是本地的虚拟机、物理机,也可以是公有云中的云主机。Docker Machine为这些环境起了一个统一的名字:provider
官方安装文档在https://docs.docker.com/machine/install-machine/
host1 安装Docker Machine,然后通过docker-machine命令在其他host上部署docker
创建Machine,Machine就是运行docker daemon的主机。创建machine要求能够无密码登录远程主机,所以需要先通过如下命令将ssh key复制到192.168.56.104:
ssh-copy-id 192.168.56.104
执行docker-machine create命令创建host1
docker-machine create --driver generic --generic-ip-address=192.168.56.104 host1
直接通过docker-machine管理其他host
docker -H tcp://192.168.56.104:2376 ps //之前
docker-machine env host1 //现在
容器网络
Docker的几种网络方案:none、host、bridge和joined容器,它们解决了单个Docker Host内容器通信的问题。
跨主机网络方案包括:(1)docker原生的overlay和macvlan;(2)第三方方案:常用的包括flannel、weave和calico。如此众多的方案是如何与docker集成通过libnetwork、container network model
libnetwork & CNM
libnetwork是docker容器网络库,最核心的内容是其定义的Container Network Model(CNM)
- Sandbox(类存储interface、路由表和DNS设置的表)
Sandbox是容器的网络栈,包含容器的interface、路由表和DNS设置。LinuxNetwork Namespace是Sandbox的标准实现。Sandbox可以包含来自不同Network的Endpoint。
- Endpoint(类网卡)
Endpoint的作用是将Sandbox接入Network。Endpoint的典型实现是veth pair,一个Endpoint只能属于一个网络,也只能属于一个Sandbox。
- Network(类交换机)
Network包含一组Endpoint,同一Network的Endpoint可以直接通信。Network的实现可以是Linux Bridge、VLAN等。
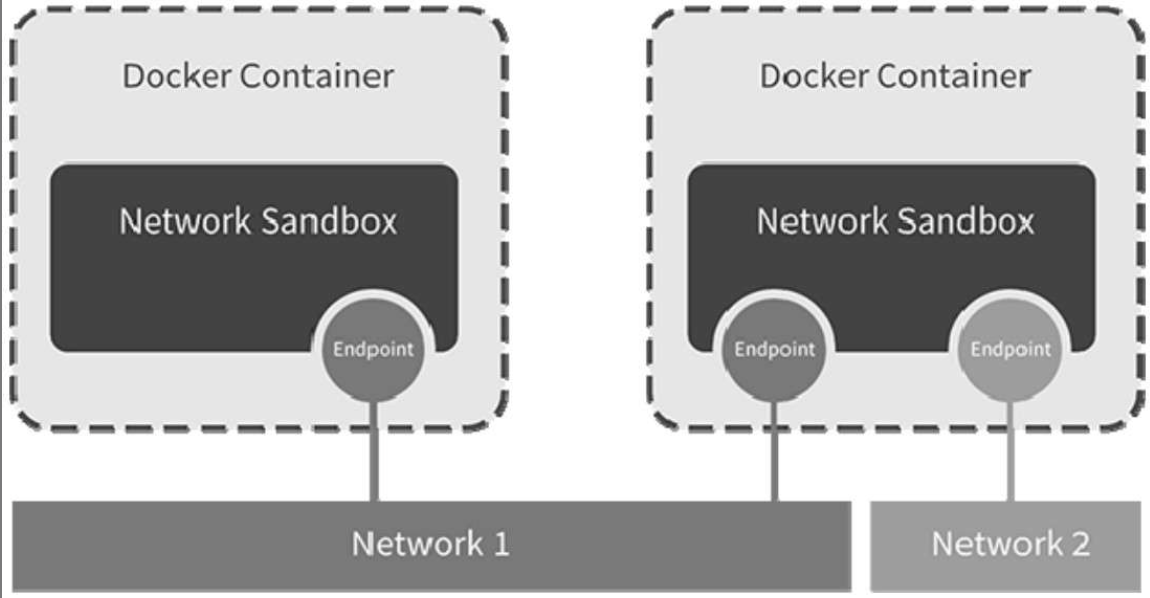
libnetwork CNM定义了docker容器的网络模型,按照该模型开发出的driver就能与docker daemon协同工作,实现容器网络。
overlay
为支持容器跨主机通信,Docker提供了overlay driver,使用户可以创建基于VxLAN的overlay网络。VxLAN可将二层数据封装到UDP进行传输,VxLAN提供与VLAN相同的以太网二层服务,但是拥有更强的扩展性和灵活性。(就是新建了桥接网卡,容器可添加变为双网卡)
#创建 docker network ls
docker networl create -d overlay ov_net1
macvlan
macvlan本身是linux kernel模块,其功能是允许同一个物理网卡配置多个MAC地址,即多个interface,每个interface可以配置自己的IP。macvlan本质上是一种网卡虚拟化技术
docker network create -d macvlan --subnet=172.16.86.0/24 \
--gateway=172.16.86.1 -o parent=eth1 mac_net1
① -d macvlan指定driver为macvlan。
② macvlan网络是local网络,为了保证跨主机能够通信,用户一般需要自己管理IPsubnet。
③ 与其他网络不同,docker不会为macvlan创建网关,这里的网关应该是真实存在的,否则容器无法路由。
④ -o parent指定使用的网络interface。
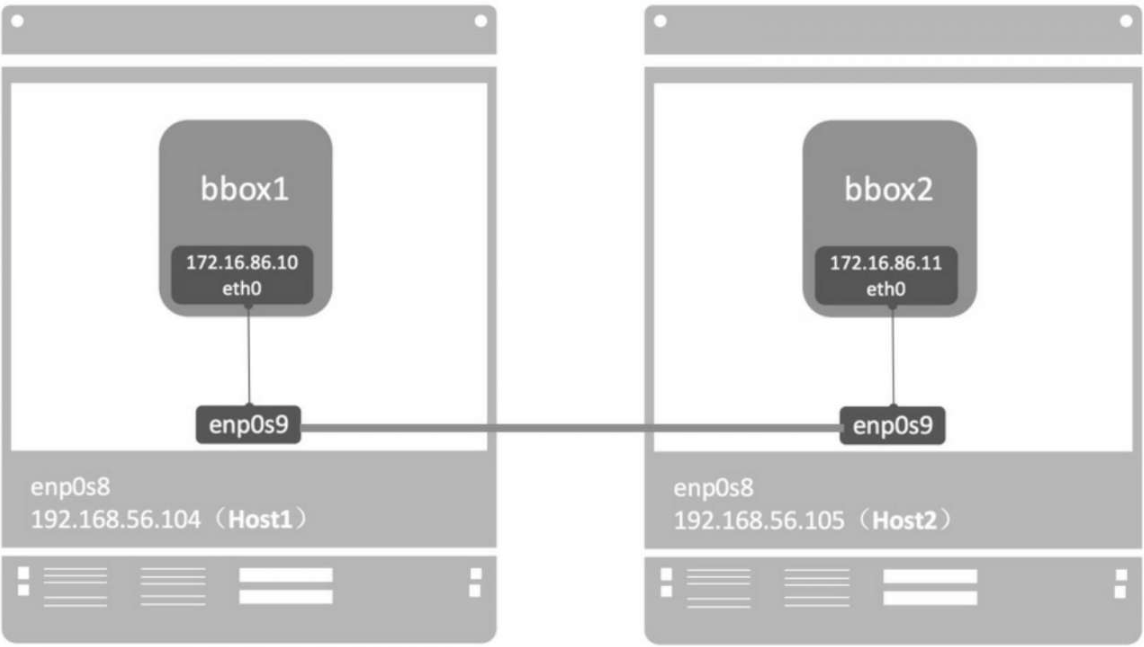
由于host1中的mac_net1与host2中的mac_net1本质上是独立的,为了避免自动分配造成IP冲突,我们通过 --ip指定bbox1地址为172.16.86.10。
docker run -itd --name bbox1 --ip=172.16.86.10 --network nac_net1 busybox
docker run -itd --name bbox2 --ip=172.16.86.11 --network nac_net1 busybox
docker没有为macvlan提供DNS服务,这点与overlay网络是不同的。无法ping bbox1
macvlan网络结构分析
macvlan不依赖Linux bridge, brctl show可以确认没有创建新的bridge
用sub-interface实现多macvlan网络
macvlan会独占主机的网卡,也就是说一个网卡只能创建一个macvlan网络.好在macvlan不仅可以连接到interface(如enp0s9),也可以连接到sub-interface(如enp0s9.xxx)。
VLAN是现代网络常用的网络虚拟化技术,它可以将物理的二层网络划分成最多4094个逻辑网络,这些逻辑网络在二层上是隔离的,每个逻辑网络(即VLAN)由VLAN ID区分,VLAN ID的取值为1~4094。Linux的网卡也能支持VLAN(apt-get install vlan),同一个interface可以收发多个VLAN的数据包,不过前提是要创建VLAN的sub-interface。
macvlan网络间的隔离和连通
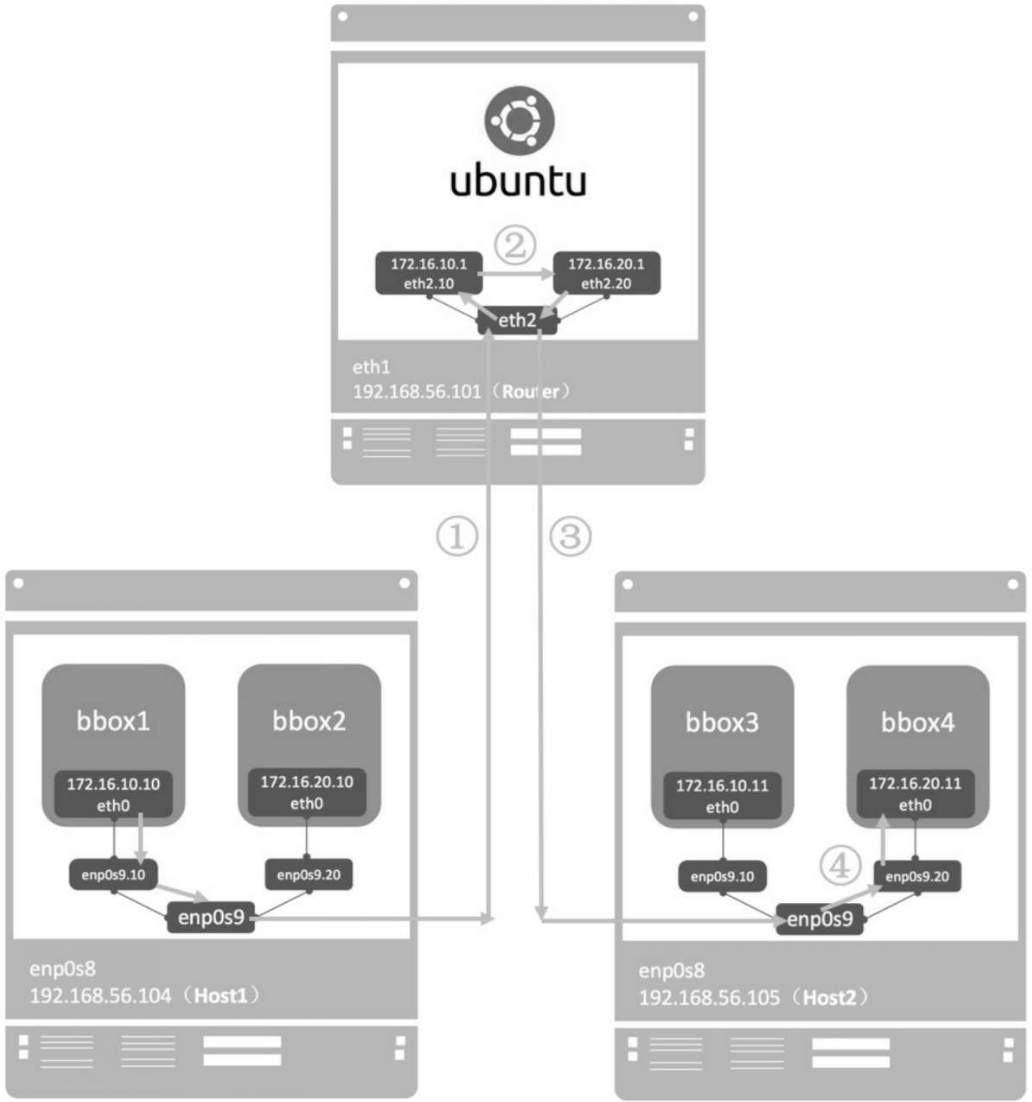
不同macvlan网络之间不能通信。但准确的说法应该是:不同macvlan网络不能在二层上通信。在三层上可以通过网关将macvlan连通。
可以借助中间网关连通。可以是物理路由,可以是某台主机配置的sub-interface网关IP。开启ip forward,以及iptables来充当虚拟路由器。
将Host 192.168.56.101配置成一个虚拟路由器,设置网关并转发VLAN10和VLAN20的流量。
//ip forward开启
sysctl -w net.ipv4.ip_forward=1
在 /etc/network/interfaces中配置vlan sub-interface
auto eth2 iface eth2 inet manual
auto eth2.10 iface eth2.10 inet manual vlan-raw-device eth2
auto eth2.20 iface eth2.20 inet manual vlan-raw-device eth2
启用sub-interface:
ifup eth2.10 ifup eth2.20
将网关IP配置到sub-interface:
ifconfig eth2.10 172.16.10.1 netmask 255.255.255.0 up
ifconfig eth2.20 172.16.20.1 netmask 255.255.255.0 up
添加iptables规则,转发不同VLAN的数据包。
iptables -t nat -A POSTROUTING -o eth2.10 -j MASQUERADE
iptables -t nat -A POSTROUTING -o eth2.20 -j MASQUERADE
iptables -A FORWARD -i eth2.10-o eth2.20 -m state --state RELATED, ESTABLISHED -j ACCEPT
iptables -A FORWARD -i eth2.20-o eth2.10 -m state --state RELATED, ESTABLISHED -j ACCEPT
iptables -A FORWARD -i eth2.10-o eth2.20 -j ACCEPT
iptables -A FORWARD -i eth2.20-o eth2.10 -j ACCEPT
flannel
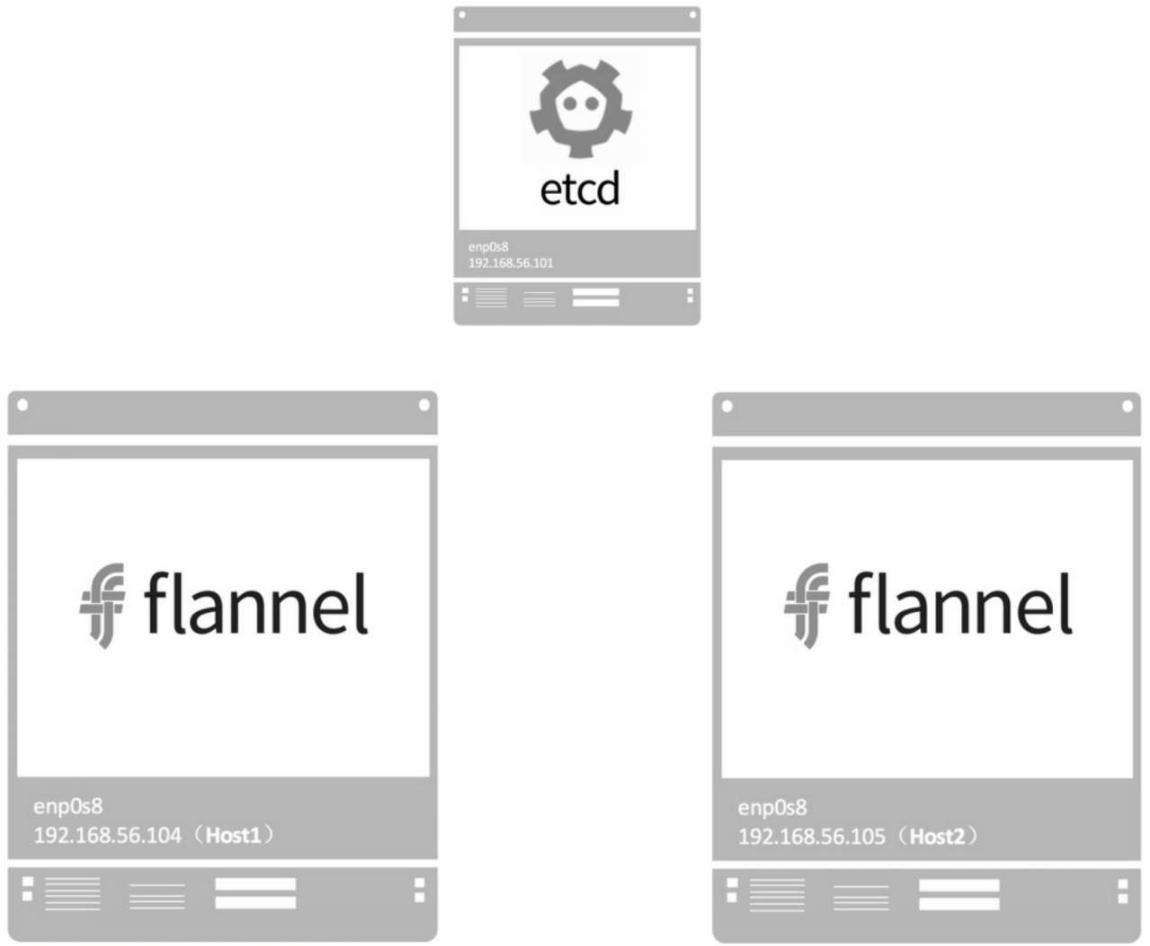
flannel是CoreOS开发的容器网络解决方案。flannel为每个host分配一个subnet,容器从此subnet中分配IP,这些IP可以在host间路由,容器间无须NAT和portmapping就可以跨主机通信。
每个subnet都是从一个更大的IP池中划分的,flannel会在每个主机上运行一个叫flanneld的agent,其职责就是从池子中分配subnet。为了在各个主机间共享信息,flannel用etcd(与consul类似的key-value分布式数据库)存放网络配置、已分配的subnet、host的IP等信息。
启动etcd并打开2379监听端口。
etcd -listen-client-urls http://192.168.56.101:2379-advertise-client-urls http://192.168.56.101:2379
先将配置信息写到文件flannel-config.json中
{ "Network": "10.2.0.0/16", "SubnetLen": 24, "Backend": { "Type":
"vxlan" } }
(1)Network定义该网络的IP池为10.2.0.0/16。
(2)SubnetLen指定每个主机分配到的subnet大小为24位,即10.2.X.0/24。
(3)Backend为vxlan,即主机间通过vxlan通信
etcdctl --endpoints=192.168.56.101:2379 set /docker-test/network/config < flannel-config.json
在host1和host2上执行如下命令:
flanneld -etcd-endpoints=http://192.168.56.101:2379 -iface=enp0s8-etcd-prefix=/docker-test/network
- -etcd-endpoints:指定etcd url。
- -iface:指定主机间数据传输使用的interface。
- -etcd-prefix:指定etcd存放flannel网络配置信息的key。
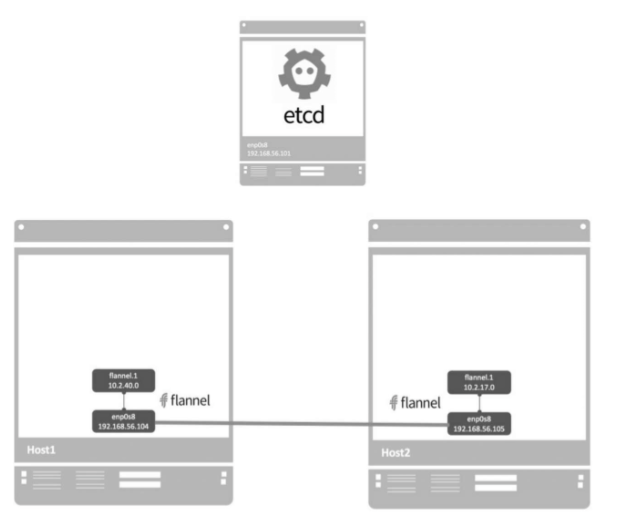
- enp0s8被选作与外部主机通信的interface。
- 识别flannel网络池10.2.0.0/16。
- 分配的subnet为10.2.40.0/24。
flanneld启动后,host1内部网络会发生变化
(1)一个新的interface flannel.1被创建,而且配置上subnet的第一个IP10.2.40.0/32
(2)host1添加了一条路由(ip route):目的地址为flannel网络10.2.0.0/16的数据包都由flannel.1转发
配置Docker连接flannel
编辑host1的Docker配置文件 /etc/systemd/system/docker.service,设置 --bip和 --mtu
这两个参数的值必须与/run/flannel/subnet.env中FLANNEL_SUBNET和FLANNEL_MTU一致
--bip=10.2.40.1/24 --mtu=1450
重启Docker daemon,Docker会将10.2.40.1配置到Linux bridge docker0上,并添加10.2.40.0/24的路由。host2同理
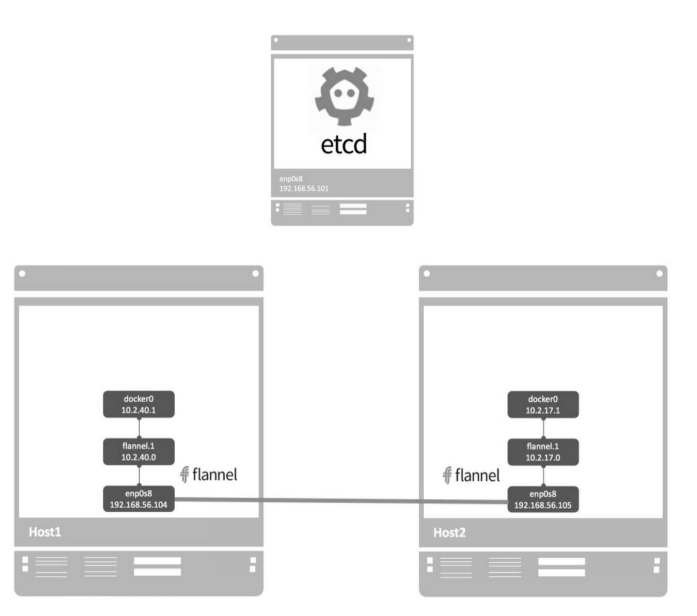
将容器连接到flannel网络
在host1中运行容器bbox1:
docker run -itd --name bbox1 busybox
在host2中运行容器bbox2:
docker run -itd --name bbox2 busybox
bbox1能够ping到位于不同subnet的bbox2,通过traceroute分析一下bbox1到bbox2的路径
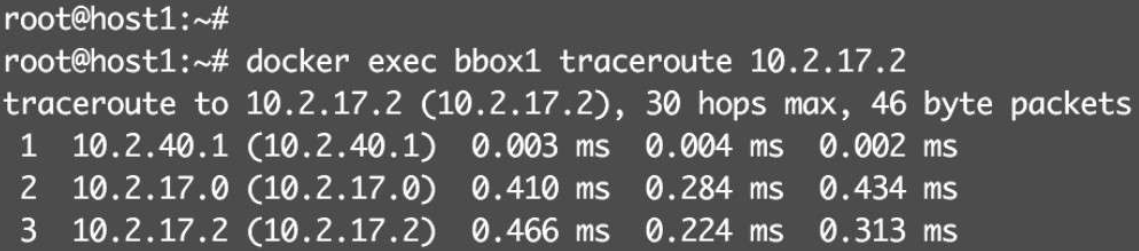
(1)bbox1与bbox2不是一个subnet,数据包发送给默认网关10.2.40.1(docker0)。
(2)根据host1的路由表,数据包会发给flannel.1
(3)flannel.1将数据包封装成VxLAN,通过enp0s8发送给host2。
(4)host2 _收到包解封装,发现数据包目的地址为10.2.17.2,根据路由表将数据包发送给flannel.1,并通过docker0到达bbox2。
(5)flannel是没有DNS服务的,容器无法通过hostname通信
flannel网络隔离
flannel为每个主机分配了独立的subnet,但flannel.1将这些subnet连接起来了,相互之间可以路由。本质上,flannel将各主机上相互独立的docker0容器网络组成了一个互通的大网络,实现了容器跨主机通信。flannel没有提供隔离。
weave
weave是Weaveworks开发的容器网络解决方案。weave创建的虚拟网络可以将部署在多个主机上的容器连接起来。对容器来说,weave就像一个巨大的以太网交换机,所有容器都被接入这个交换机,容器可以直接通信,无须NAT和端口映射。除此之外,weave的DNS模块使容器可以通过hostname访问。
weave不依赖分布式数据库(例如etcd和consul)交换网络信息,每个主机上只需运行weave组件就能建立起跨主机容器网络。
weave安装非常简单,在host1和host2上执行如下命令:
curl -L git.io/weave -o /usr/local/bin/weave
chmod a+x /usr/local/bin/weave
在host1中执行weave launch命令,启动weave相关服务。weave的所有组件都是以容器方式运行的,weave会从docker hub下载最新的image并启动容器
weave运行了三个容器:
- weave:是主程序,负责建立weave网络,收发数据,提供DNS服务等。
- Weaveplugin:是libnetwork CNM driver,实现Docker网络。
- Weaveproxy:提供Docker命令的代理服务,当用户运行Docker CLI创建容器时,它会自动将容器添加到weave网络。
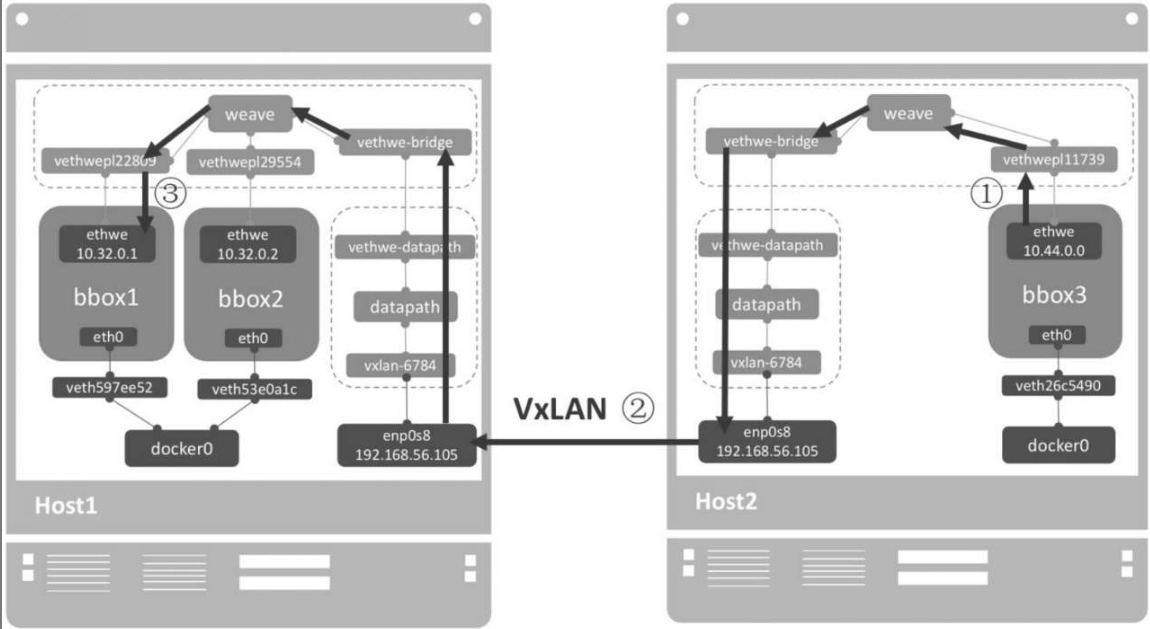
在host1中运行容器bbox1,bbox2
eval $(weave env) docker run --name bbox1-itd busybox
docker run --name bbox2-itd busybox
weave DNS为容器创建了默认域名weave.local, bbox1能够直接通过hostname与bbox2通信
在host2中启动weave并运行容器bbox3
weave launch 192.168.56.104
eval $(weave env) docker run --name bbox3-itd busybox
这里必须指定host1的IP 192.168.56.104,这样host1和host2才能加入到同一个weave网络。bbox3能够直接ping bbox1和bbox2。实际上这三个IP位于同一个subnet 10.32.0.0/12。通过host1和host2之间的VxLAN隧道,三个容器逻辑上是在同一个LAN中的,当然能直接通信了
weave网络隔离
默认配置下,weave使用一个大subnet(例如10.32.0.0/12),所有主机的容器都从这个地址空间中分配IP,因为同属一个subnet,容器可以直接通信。如果要实现网络隔离,可以通过环境变量WEAVE_CIDR为容器分配不同subnet的IP
docker run -e WEAVE_CIDR=net:10.32.2.0/24 busybox
weave是一个私有的VxLAN网络,默认与外部网络隔离。连通需要(1)首先将主机加入到weave网络。(2)然后把主机当作访问weave网络的网关。
要将主机加入到weave,执行
weave expose
这个IP为10.32.0.3,会被配置到host1的weave网桥上,host1
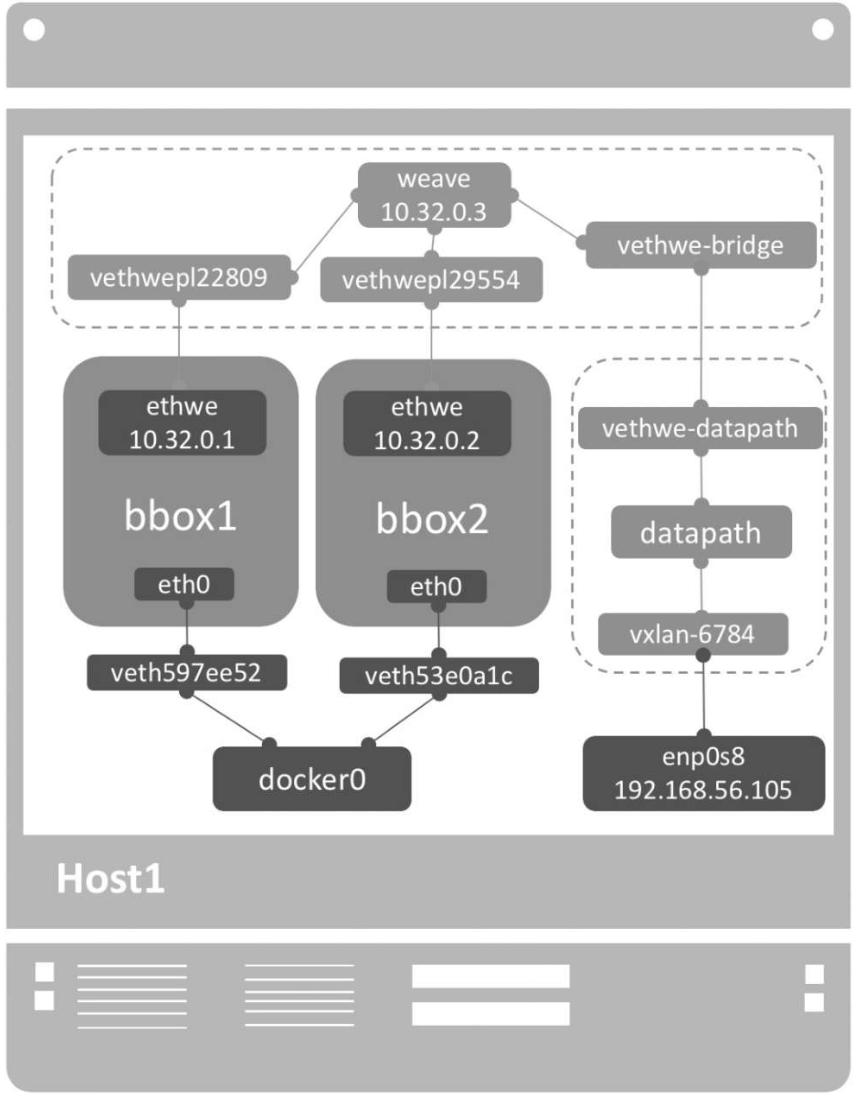
weave网桥位于root namespace,它负责将容器接入weave网络。给weave配置同一subnet的IP,其本质就是将host1接入weave网络。host1现在已经可以直接与同一weave网络中的容器通信了,无论容器是否位于host1。
0.32.0.0/12是weave网络使用的默认subnet,如果此地址空间与现有IP冲突,可以通过 --ipalloc-range分配特定的subnet。
weave launch --ipalloc-range 10.2.0.0/16
calico
Calico是一个纯三层的虚拟网络方案,Calico为每个容器分配一个IP,每个host都是router,把不同host的容器连接起来。与VxLAN不同的是,Calico不对数据包做额外封装,不需要NAT和端口映射,扩展性和性能都很好。
Calico依赖etcd在不同主机间共享和交换信息,存储Calico网络状态。host192.168.56.101负责运行etcd。Calico网络中的每个主机都需要运行Calico组件,实现容器interface管理、动态路由、动态ACL、报告状态等。

启动etcd
在host 192.168.56.101上运行如下命令启动etcd:
etcd -listen-client-urls http://192.168.56.101:2379-advertise-client-urls http://192.168.56.101:2379
修改host1和host2 Docker daemon配置文件/etc/systemd/system/docker.service,连接etcd
--cluster-store=etcd://192.168.56.101:2379
重启Docker daemon
systemctl daemon-reload systemctl restart docker.service
部署calico
wget -O /usr/local/bin/calicoctl https://github.com/projectcalico/calicoctl/releases/download/v1.0.2/calicoctl
chmod +x calicoctl
//在host1和host2上启动calico
calicoctl node run
① 设置主机网络,例如 enable IP forwarding
② 下载并启动calico-node容器,calico会以容器的形式运行
③ 连接etcd
④ calico启动成功
创建calico网络
在host1或host2上执行如下命令创建calico网络cal_net1
docker network create --driver calico --ipam-driver calico-ipam cal_net1
-
--driver calico:指定使用calico的 libnetwork CNM driver。
-
--ipam-driver calico-ipam:指定使用calico的 IPAM driver管理 IP。
-
calico为global网络,etcd会将cal_net同步到所有主机
在calico中运行容器
在host1中运行容器bbox1并连接到cal_net1
docker container run --net cal_net1--name bbox1-tid busybox
cali0是calico interface,分配的IP为192.168.119.2
在host2中运行容器bbox2,也连接到cal_net1,IP为192.168.183.65
docker container run --net cal_net1--name bbox2-tid busybox
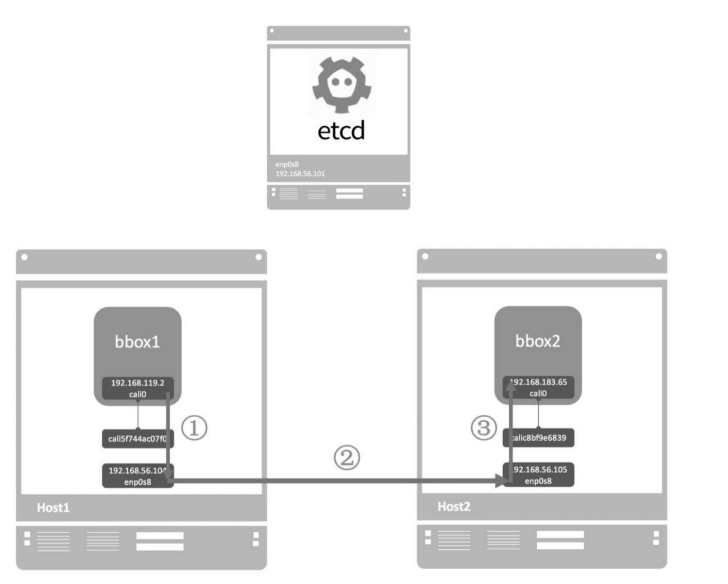
不同的calico网络,默认不能通行。calico默认的policy规则是:容器只能与同一个calico网络中的容器通信。
容器监控
监控子命令:ps、top和stats,然后是几个功能更强的开源监控工具sysdig、Weave Scope、cAdvisor和Prometheus
docker container ps
docker container top 容器ID //某个容器中运行了哪些进程
docker container stats //用于显示每个容器各种资源的使用情况
sysdig
sysdig是一个轻量级的系统监控工具,同时它还原生支持容器。通过sysdig我们可以近距离观察Linux操作系统和容器的行为。Linux上有很多常用的监控工具,比如strace、tcpdump、htop、iftop、lsof ……而sysdig则是将这些工具的功能集成到一个工具中,并且提供一个友好统一的操作界面。
docker container run -it --rm --name=sysdig --privileged=true \ --
volume=/var/run/docker.sock:/host/var/run/docker.sock \ --
volume=/dev:/host/dev \ --volume=/proc:/host/proc:ro \ --
volume=/boot:/host/boot:ro \ --volume=/lib/modules:/host/lib/modules:ro
\ --volume=/usr:/host/usr:ro \ sysdig/sysdig
sysdig容器是以privileged方式运行,而且会读取操作系统/dev、/proc等数据
通过docker container exec -it sysdig bash进入容器,执行csysdig命令,将以交互方式启动sysdig。这是一个类似Linux top命令的界面,但要强大太多。sysdig按不同的View来监控不同类型的资源,单击底部Views菜单(或者按F2键),显示View选择列表
如果想看某个容器运行的进程,将光标移到目标容器,然后回车或者双击
Weave Scope
Weave Scope的最大特点是会自动生成一张Docker Host地图,让我们能够直观地理解、监控和控制容器。

curl -L git.io/scope -o /usr/local/bin/scope
chmod a+x /usr/local/bin/scope
scope launch
Weave Scope的访问地址为http://[Host IP]:4040
cAdvisor
cAdvisor是google开发的容器监控工具,在host中运行cAdvisor容器。
docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ -
-publish=8080:8080 \ --detach=true \ --name=cadvisor \
google/cadvisor:latest
通过http://[Host IP]:8080访问cAdvisor。
Prometheus
Prometheus提供了监控数据搜集、存储、处理、可视化和告警一套完整的解决方案。
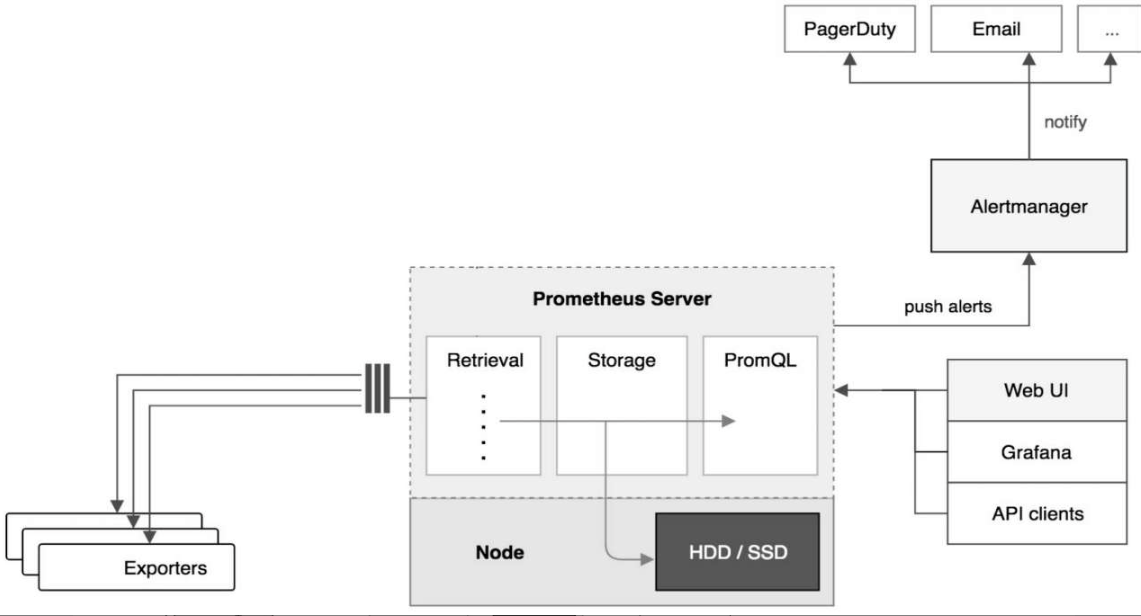
Prometheus架构
-
Prometheus Server
Prometheus Server负责从Exporter拉取和存储监控数据,并提供一套灵活的查询语言(PromQL)供用户使用。
-
Exporter
Exporter负责收集目标对象(host、container等)的性能数据,并通过HTTP接口供Prometheus Server获取。
-
可视化组件
Grafana能够与Prometheus无缝集成,提供完美的数据展示能力。
-
Alertmanager
用户可以定义基于监控数据的告警规则,规则会触发告警。一旦Alertmanager收到告警,会通过预定义的方式发出告警通知。支持的方式包括Email、PagerDuty、Webhook等。
日志管理
Docker logs
(1)attach到该容器。退出attach状态比较麻烦(按Ctrl+p键,然后再按Ctrl+q键)
(2)用docker logs命令查看日志。docker logs能够打印出自容器启动以来完整的日志,并且 -f参数可以继续打印出新产生的日志,效果与Linux命令tail -f一样。
docker attach 容器ID //只能记录attach执行后的日志
docker logs -f 容器ID
Docker logging driver
将容器日志发送到STDOUT和STDERR是Docker的默认日志行为。实际上,Docker提供了多种日志机制帮助用户从运行的容器中提取日志信息,这些机制被称作logging driver。Docker的默认logging driver是json-file
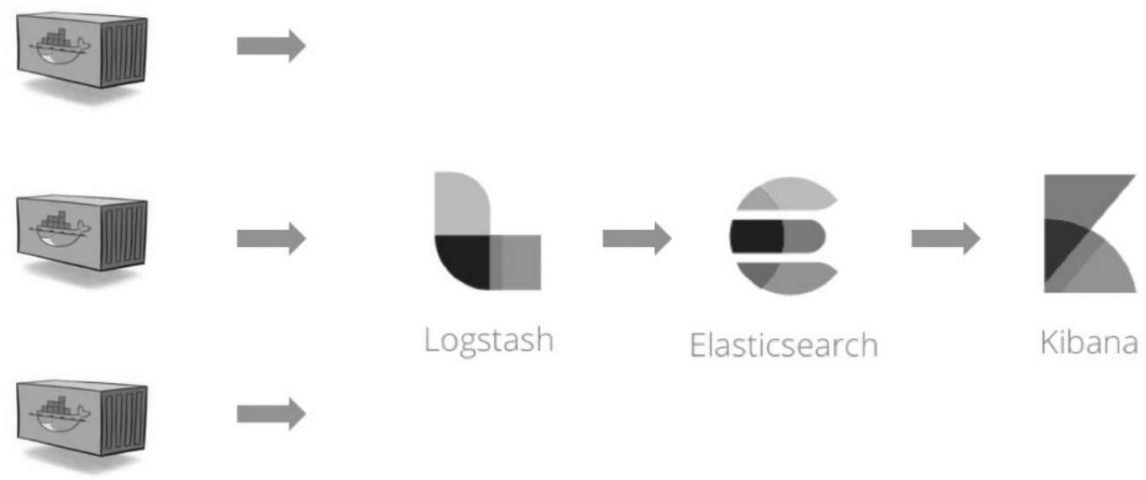
ELK
ELK是三个软件的合称:Elasticsearch、Logstash、Kibana。
-
Elasticsearch
一个近乎实时查询的全文搜索引擎。Elasticsearch的设计目标就是要能够处理和搜索巨量的日志数据。
-
Logstash
读取原始日志,并对其进行分析和过滤,然后将其转发给其他组件(比如Elasticsearch)进行索引或存储。Logstash支持丰富的Input和Output类型,能够处理各种应用的日志。
-
Kibana
一个基于JavaScript的Web图形界面程序,专门用于可视化Elasticsearch的数据。Kibana能够查询Elasticsearch并通过丰富的图表展示结果。用户可以创建Dashboard来监控系统的日志。
docker run -p 5601:5601-p 9200:9200-p 5044:5044-it --name elk sebp/elk
- 5601:Kibana web接口
- 9200:Elasticsearch JSON接口
- 5044:Logstash日志接收接口
Filebeat
几乎所有的软件和应用都有自己的日志文件,容器也不例外。Docker会将容器日志记录到 /var/lib/docker/containers/
Filebeat的配置文件为 /etc/filebeat/filebeat.yml,我们需要告诉Filebeat两件事:
- 监控哪些日志文件?
- 将日志发送到哪里?
Fluentd
Fluentd是一个开源的数据收集器,它目前拥有超过500种plugin,可以连接各种数据源和数据输出组件。Fluentd会负责收集容器日志,然后发送给Elasticsearch。
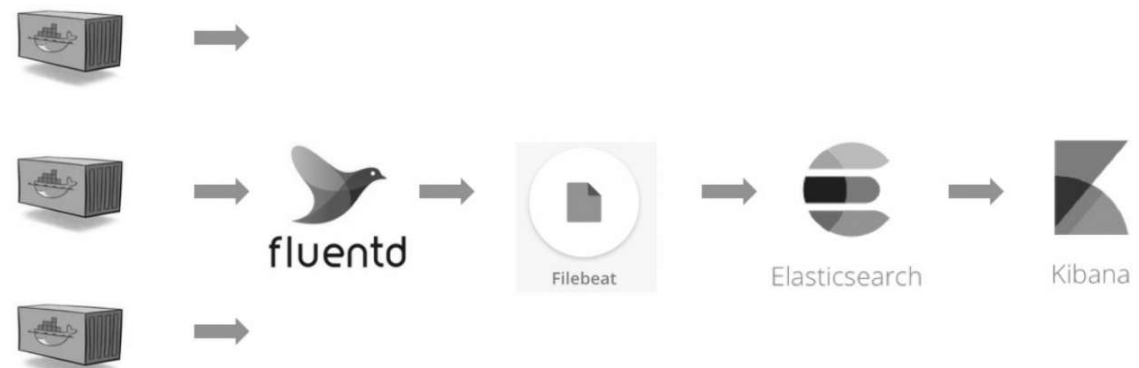
用Filebeat将Fluentd收集到的日志转发给Elasticsearch
Graylog
Graylog是与ELK可以相提并论的一款集中式日志管理方案,支持数据收集、检索、可视化Dashboard。
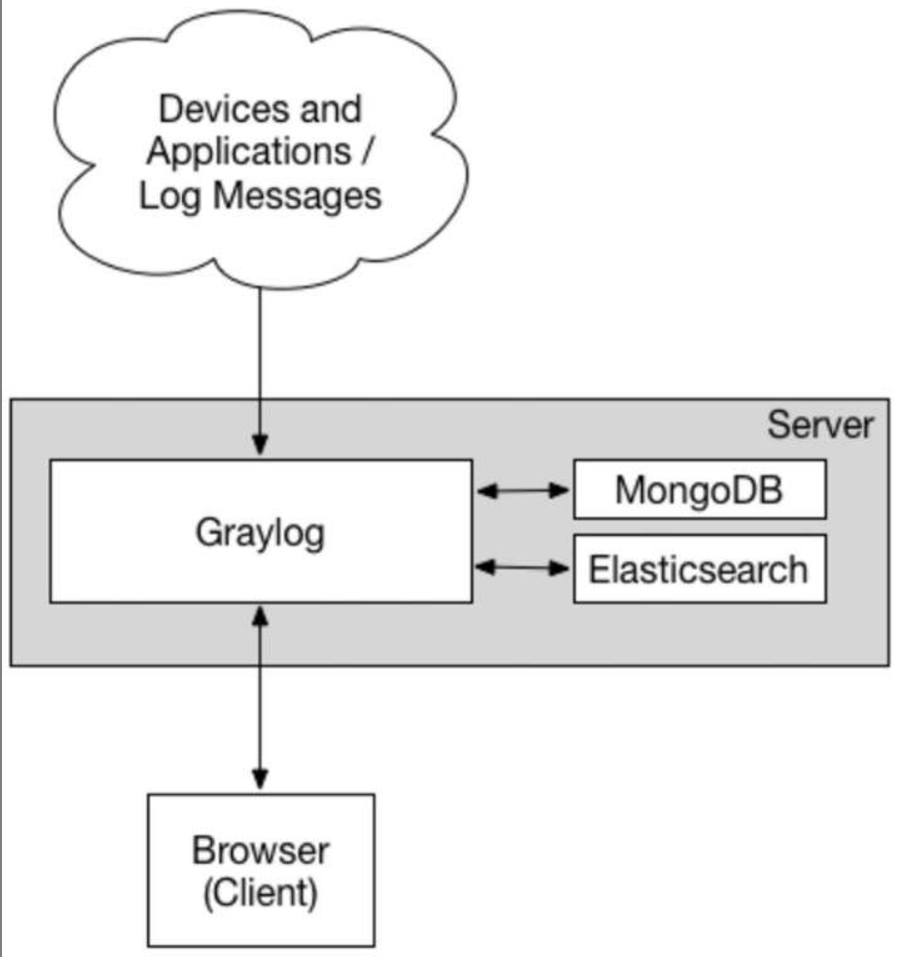
Graylog负责接收来自各种设备和应用的日志,并为最终用户提供Web访问接口。
Elasticsearch用于索引和保存Graylog接收到的日志。
MongoDB负责保存Graylog自身的配置信息。
数据管理
从业务数据的角度看,容器可以分为两类:无状态(stateless)容器和有状态(stateful)容器。无状态是指容器在运行过程中不需要保存数据,每次访问的结果不依赖上一次访问,比如提供静态页面的Web服务器。有状态是指容器需要保存数据,而且数据会发生变化,访问的结果依赖之前请求的处理结果,最典型的就是数据库服务器。
Docker是通过volume driver跨主机管理data volume。Host1运行了一个MySQL容器,为了保护数据,datavolume由storage provider提供,当Host1发生故障,我们会在Host2上启动相同的MySQL镜像,并挂载data volume。
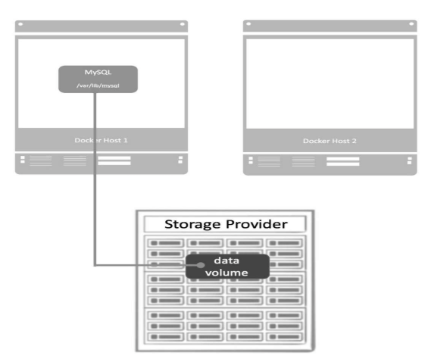
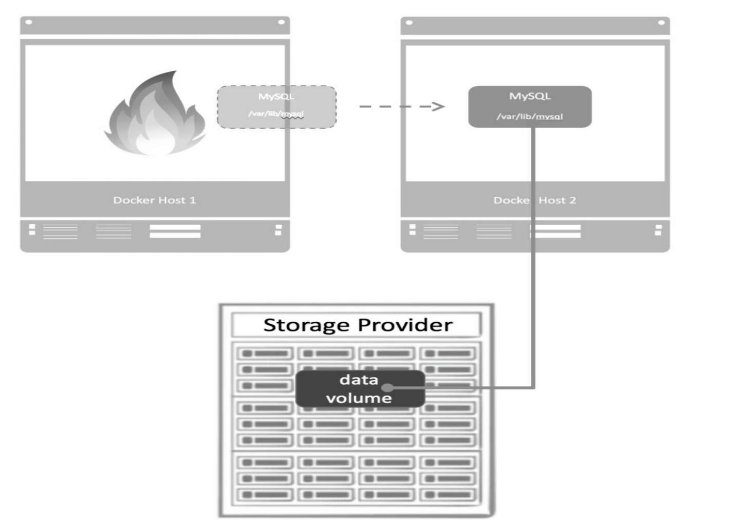
任何一个data volume都是由driver管理的,创建volume时如果不特别指定,将使用local类型的driver,即从Docker Host的本地目录中分配存储空间。如果要支持跨主机的volume,则需要使用第三方driver。Azure File Storage的driver、GlusterFS的driver、Rex-Ray driver
本文来自博客园,作者:Rodericklog,转载请注明原文链接:https://www.cnblogs.com/rodericklog/articles/19444686

 浙公网安备 33010602011771号
浙公网安备 33010602011771号