临床文档架构CDA(Clinical Document Architecture)
第1章 CDA标准简介
1.1 临床文档的属性
临床文档有两个关键功能,支持临床医疗服务提供者之间的临床信息的通讯, 以及对当地政策、法律法规的遵从。支持这些功能的关键特征是可靠性和完整性。
临床文档必须被证明是可信的。这就意味着,它常常是由可信的机构产生, 本身被提供了作为医疗的一个可信记录。
临床文档也必须是不遗漏重要细节的医疗完整记录,这是因为当我们查看临 床文档中某些重要信息的时候,可能恰恰在当时书写时被医生所遗漏。当我们了 解更多信息,昨天重要的信息可能现在却不再重要,但是那些当时看来似乎无关 紧要的信息在今天看来可能是重要的。
这些功能和特点是交织在一起的。如果文档不完整,将难以提供可靠的且符 合法律要求的文档。同样,一个不完整的或不可靠的的文档可能会导致沟通失败, 从而可能对患者造成伤害。
1.2 HL7 CDA 的历史
1997 年- HL7 SGML SIG (Special Interest Group)开始病历架构的工作
1998 年- 发布病历架构草案 1999 年- CDA 1.0 版被 HL7 会员批准
2000 年- CDA 1.0 版被采用为美国国家标准
2000 年- HL7 XML SIG 升级为结构化文档技术委员会
2005 年- 临床文档架构第 2 版被采纳
2006 年- 发布 CCR(Care Record Summary)实施指南
2007 年- 发布 CCD (Contunuity of Care Document)实施指南
2008 年- 美国 HHS 的秘书处认可 HL7 CDA
2008 年- 向 ISO TC- 215 提交 CDA
2009 年- ISO TC- 215 批准 CDA 作为 ISO 标准
2010 年- CDA 被 HL7 和 ANSI 重申为美国国家标准
从 1997 年开始, HL7 组织的 HL7 SGML 特别兴趣小组(SIG)开始了 CDA 标 准的开发。当 XML 取代 SGML 标准后,SGML 的 SIG 后来成为 SGML/XML SIG,进而 成为一个 XML SIG,结构化文档技术委员会(SDTC),到今天成为大家所熟知的 结构化文档工作组(SDWG)。
在早期,CDA 也被叫做病历架构(Patient Record Architecture, PRA)。该标准的第一版本是在 1999 年由 HL7 成员批准,为了得到 ANSI 批准,作为 ANSI 认可的标准组织,HL7 按照 ANSI 的流程进行了投票,并将结果通知给 ANSI 组 织,然后在所有障碍被清除后,于 2000 年被 ANSI 正式批准成为一个美国国家标 准(American National Standard, ANS)。CDA 1.0 版基于 HL7 的 RIM、数据 类型和术语的早期草案。事实上,CDA 1.0 版是 HL7 第 3 版第一批发布的标准之 一,比 HL7 第 3 版的 RIM,数据类型和术语标准发布早 3-4 年。
在 2005 年 1 月, HL7 成员批准了 CDA 2.0 版,在当年稍晚些时候,被批准 为 ANSI 标准。这一次,CDA 标准的基础– HL7 第 3 版标准被 HL7 和 ANSI 分别 于 2003 年和 2004 年批准。
为了推进 HL7 CDA 2.0 版标准的使用,工作组开始制定医护记录摘要应用指 南。这是采用 CDA 来记录提供给患者的医护摘要信息。这个标准的出现导致了 HL7 与 ASTM 现有其他标准间的冲突,但最终以友好的方式解决。双方共同协作 开发了连续医护记录应用指南(Continuity of Care Document Implementation Guide,CCD),HL7 在 2006 年批准了该实施指南。
2008 年 7 月,CDA 2.0 版被提交给国际标准化组织(ISO)215 技术委员会(TC - 215),并于 2009 年 11 月被批准为 ISO 标准 ISO/HL7 27932:2009,Data Exchange Standards -- HL7 Clinical Document Architecture, Release 2 (https://www.iso.org/standard/44429.html)。
在成为美国国家标准 5 年后,按照 ANSI 要求,CDA 标准不断进行修改,删除 或完善。
1.3 使用 XML 标准实现 CDA 标准
CDA 使用 XML 的元素和属性表达临床文档。但是,CDA 的语法表达并不仅仅限 定于 XML。在将来,如果有其他可替代 XML 的实现方式,相应的符合性需求也会发布。与其他 HL7 第 3 版标准不同,CDA Schema 是一个规范的组件。因此,如 果文档通不过 CDA schema 的验证,则表示这个 XML 文档报告没有完全遵守 CDA 标准。如果需要对部分内容进行扩展,也需要按 CDA 标准来扩展(见第 4 章,详细介绍了如何对 CDA 进行本地化扩展和验证)。 HL7 第 3 版通常使用标准的规范定义的通信模型,以及 XML Schemas 信息。 不管是 CDA 1.0 版和 2.0 版都声明一个有效的 CDA 文档必须通过被 HL7 第 3 版所支持的 Schema 验证,因 此 HL7 CDA Schema,也是 CDA 格式规范定义的一部分。
CDA 标准允许医疗机构和患者交换不同格式的临床文档,例如扫描的、口授 的、计算机录入或电子方式生成的报告。这些报告能够使用 CDA 标准的不同层次 来进行互操作。
1.4 CDA 文档结构
一个 CDA 文档逻辑上由两部分组成:文档头和文档体。文档头包含了临床文 档的上下文,以方便一个临床文档能够在不同组织中被交换,或者方便形成一个 患者的长期电子健康档案。它包含的信息包括文档何时写的,是谁写的,来自哪 个医疗机构,适用于哪个患者,与就诊相关的医疗保健服务描述等。文档体可以 是一个非结构化的文件,例如扫描的图像,也可以是使用 XML 的结构化表达。它 表达了人可读的叙事文本。在这里“人可读”是指一个系统能够将其内容转化为 人可以理解或者阅读的方式,这并不要求该文件本身在不借助其它应用程序的帮 助下达到“人可读”。
CDA 1.0 版引入了层次的概念。每个级别都包括了临床文档交换中语义互操 作性的更高程度。第 1 层,用于描述临床文档的元数据集合,以及应用程序特定 或专有格式的与人可读的内容。第 2 层,引入结构以类似于 HTML 的形式表达人 可读的内容,并使用编码方式来表达章节的内容。最后,第 3 层中,不仅要求提 供人可读的语义,更要提供机器可读的语义内容。在标准中对这些层次没有硬性 规定。
1.5 临床文档基本结构
CDA 标准使用基于 UML 的 HL7 建模来描述临床文档的结构。下图是一个 CDA R-MIM 的微型图表。在 HL7 第 3 版中,R-MIM 表 示受限制的消息信息模型。当然 CDA 描述的是文档,不是消息,因此有时你会听 到它被叫做受限制的元信息模型(Restricted Meta-Information model)。

1.5.1 临床文档元素<ClinicalDocument>
<ClinicalDocument>元素是所有 CDA 文档的 XML 根元素。这个元素代表性的 包含了临床文档所需要的所有命名空间的声明,可以声明文档的适用范围,说明所使用的 CDA 版本,并可以声明此文档的一致性交换规则。下面一个<ClinicalDocument>元素的例子体现了所有这些特性。
<ClinicalDocument xmlns='urn:hl7-org:v3' xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance' classCode='DOCCLIN' moodCode='EVN'> <realmCode code='…'/> <typeId root='2.16.840.1.113883.1.3' extension='POCD_HD000040'/> <templateId root='2.16.840.1.113883.10.20.1'/> : </ClinicalDocument>
- 空间声明
在 CDA XML 描述中有两个常用的命名空间声明,如下表所示。
| 命令空间 | 前缀 | 描述 |
| urn:hl7-org:v3 | Default | 这个命令空间声明在所有 HL7 第 3 版的标准中是必须 的,包括 CDA。我推荐使用它作为默认的命名空间,因 为这将使阅读 CDA 实例变得更容易。 |
| http://www.w3.org/200 1/ XMLSchema-instance | xsi | 这个命令空间是必须的,用来声明在元素 中 元素使用的数据类型,或者用于覆盖 CDA Schema 所使用的默认数据类型。 |
- classCode='DOCCLIN'
在 HL7 第 3 版 XML 表述中,classCode 属性用来说明所描述的 RIM 类的类 型。由于<ClinicalDocument>元素通常代表 RIM 中临床文档行为的一个实例,因 此 CDA Schema 给classCode 属性设定了一个定值 DOCCLIN。
- moodCode='EVN'
HL7 第 3 版中一个行为(ACT)的情态属性(MoodCode)既可以表示行为发生 的进展,也可以表示它所使用的方式。这是借鉴了语言中动词的情态概念。元素通常表示一个已经发生的行为,因此 moodCode 属性被 CDA Schema 设置成固定值 EVN。
1.5.2 基础元素(Infrastructure Elements)
之所以叫做基础元素,是因为它们是 CDA 使用的 XML 基本结构的一部分。不只是 CDA,对于常用的 HL7 第 3 版 XML 表述的 XML 实施技术规范中都需要这些基本元素。这些 XML 元素可以出现在 CDA 文档中的任何 RIM 类中,不只是<ClinicalDocument>元素。它们通常以下面的顺序首先出现在这些 XML 元素中。
- <realmCode>
<realmCode>元素是可选的,它用来说明所写内容的适用领域。这个元素的值 域通常用于说明哪个领域政策适用于这个内容。很多 HL7 实施指南是为全体领域“Universal Realm”写的,代码是 UV。其他文档,如连续医护文档实施指南,是专门为一个国家的特定领域写的(如为 CCD、US 领域)。
- <typeId>
<typeId> 元 素 说 明 了 XML 描述的 HL7 标 准 模 型 的 版 本 。 CDA 的<clinicalDocument>元素需要一个<typeId>元素。此<typeId>元素为 root 和 extension XML 属性设定固定的值。<typeId>元素也会出现在其他描述 CDA RIM 类的 XML 元素中,但并不是必须的。
- <templateId>
<templatId>元素用来说明应用于它所在的 XML 元素的一个模板。本质上来说,一个模板是一套被认同的业务规则,其关联 CDA XML 和业务规则的强大能力已经得到证明,因此它已经成为 CDA 标准中最重要的基本元素之一。多个<templateId>元素可以出现在同一个 RIM 类的 XML 描述中。<templatId>元素的存在声明了特定模板所制定的相关业务规则的一致性。这个元素是可以重复的,而且经常被重复,因为一个 RIM 类可以应用多个业务规则的集合。在卫健委发布的一系列共享文档规范,也相当于文档的模板。
1.6 CDA 与 OID
1.6.1 OID 简介
OID(Object identifier)是全球唯一标识符,其创建和管理的规则非常简 单。OID 值根据 ISO9834 标准由权威注册机构创建,注册机构是被授权能够创建 OID 的实体,其权力由之前存在的权威注册机构授予。最权威注册机构由 ISO 标 准定义 , 如 中 国 国 家 OID 注 册 管 理 中 心 ( 2.16.156 或 1.2.156 ) (http://www.china-oid.org.cn/)。
1.6.2 OID 在 HL7 中的用途
在 HL7 的 CDA 文档和 V3 消息中需要大量标识符(Identifier),用于唯一的 标识患者、位置、医生、机构或者其他事物,HL7 中这些事物使用实体标识符类 型 II。
<id root="2.16.840.1.113883.19.3.933.2" extension="MRN009"/ >
实体标识符有两个属性,root 和 extension,例子中的标识符由这两部分构 成。extension 属性中的值也可以用于其他地方某患者的医疗记录,因此需要额 外的用于标识环境或者上下文的标识符,上下文由 root 属性标识。
一个标识符集合的上下文环境由名字空间唯一标识。在 root 属性中标识名 字空间的方法有两种,第一种方法是使用 OID,或者 ISO 对象标识符,另一种方 法是使用 UUID(这也是 HL7 所允许的),另一种称呼是 GUID。如果 OID 或者 UUID 定义了名字空间时,extension 用于存储标识符剩余的部分。(UUID 是 128 位二 进制字符串),通常用 16 进制标识,中间用横杠隔开。
在 II 数据类型的定义中,root 属性是必须出现的,而 extension 是可选的。 root 属性通常限制了其表示形式,而 extension 则可以是任意字符串,存放标 识符中确保本地唯一性的部分。只有 root 和 extension 都相同,标识的才是相 同的对象,但是如果标识符不同,并不能确定所标识的对象不是同一对象。
OID 用于 HL7 消息和文档中的实体标识符,也用于标识消息和文档中用到的 术语系统。HL7 中的 OID 分配机制是不透明的,也就是说应用程序没有必要分析 OID 的结构,其结构仅仅表示其分配机制。
OID 的分配形成树形结构,每个分支被注册机构或者分配机构所有。ISO 设 置了一些规则,哪些数字可以用于第一个分支,以及谁拥有他们。每个分支也有 名称,但是 HL7 中不使用。
良好的 OID 策略和实现指南有助于共享信息、降低可能的错误。尽管 ISO 没 有限制 OID 的长度和数字的大小,但是实际操作中有些限制。
1)标识 OID 的字 符串的长度:很多医院中的 DICOM 标准使用 OID 用于标识影像对象(称 OID 为 UID),DICOM 标准要求 OID 不超过 64 个字符。
2)每个部分当作整数处理,因此 受限于计算机整数的取值限制。
1.6.3 OID 在 CDA 中的应用
- 文档/模板/类型
CDA 文档中的第一个 id 元素,标识该 CDA 文档。没有两个 CDA 文档的 id 相 同,即使同一文档的不同版本,其文档的 id 也不同。在 HL7 中允许 II 数据类型没有 extension 属性,便于适用于那些只使用 OID 标识对象的标准,例如 DICOM, 与 HL7 CDA 标准间交换信息。推荐的做法是每个模板有独立的 OID,而不是用 extension 属性。
<ClinicalDocument xmlns="urn:hl7-org:v3" xmlns:voc="urn:hl7-org:v3/voc" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:hl7-org:v3 CDA.xsd"> <typeId root="2.16.840.1.113883.1.3" extension="POCD_HD000040"/> <templateId root="2.16.840.1.113883.10.20.1"/> <id root=“2.16.840.1.113883.19.3.933.1.2219000"/> <code code="34133-9" codeSystem="2.16.840.1.113883.6.1" displayName="Summarization of episode note"/> <title>Discharge Summary</title> <effectiveTime value="20120304130000+0500"/> <confidentialityCode code="N" codeSystem="2.16.840.1.113883.5.25"/> <languageCode code="en-US"/> <setId extension=“999021“ root=“2.16.840.1.113883.19.3.933.1"/> </ClinicalDocument>
- 患者
医疗机构需要使用多个患者的标识符,例如医疗记录编码、财务账号标识符、 社保账号标识符,患者主标识符等。不同种类的标识符有不同的 OID。例如在美 国,每类公共标识符(例如社会保险号码 SSN)均有与 OID 关联的名字空间,并 且注册在 HL7 OID 注册表中。HL7 分配的 OID 用于表达公共标识符,便于多种组 织间的互操作。 不同的组织应该有各自的根 OID,它们会为个人分配 id。这些标识符在 patientRole 中的 id 元素,表示这个人的患者角色。每个患者最终有多个 id 关 联,OID 的管理方案需要考虑到这一点。它们也可以为 CDA 的文档作者分配 id。 另外,所有就诊信息也应该使用这些 OID。
<recordTarget> <patientRole> <id extension="103029190" root="2.16.840.1.113883.19.5" /> <addr>… </addr> <patient> <name>… </name> <administrativeGenderCode code="M" codeSystem="2.16.840.1.113883.5.1" displayName="Male" /> <birthTime value="19670513"/> <id root=“2.16.840.1.113883.4.3.24" extension="0000000"/> </patient> <providerOrganization>…</providerOrganization> </patientRole> </recordTarget>
- 组织/人员
<author> <time value="20120304130000+0500" /> <assignedAuthor> <id extension="10928" root="2.16.840.1.113883.19.5" /> <assignedPerson> <name>…</name> </assignedPerson> <representedOrganization> <id root="2.16.840.1.113883.19.5" /> <name>北京好医院</name> </representedOrganization> </assignedAuthor> </author>
- 就诊/地点
<encompassingEncounter> <id root="2.16.840.113883.19.3.933.7" extension="9937012"/> <effectiveTime>…</effectiveTime> <location> <healthCareFacility classCode="SDLOC"> <!--ID of facility and location within facility --> <id root="2.16.840.1.113883.19.5" extension="A10" /> </healthCareFacility> </location> </encompassingEncounter>
- 章节/条目/医嘱
<section> <id root="2.16.840.1.113883.19.3.933.1.999021.1.9" extension="1"/> <entry> <act classCode="ACT" modeCode="EVN"> <id root="2.16.840.1.113883.19.3.933.1.999021.1.10" extension="1"/>
- 术语和编码系统
OID 也被用于唯一的标识 CD 数据类型元素中的术语或者编码系统,OID 出现 在元素的 codeSystem 属性中。
<component> <section> <code code="10154-3" codeSystemName="LOINC" codeSystem="2.16.840.1.113883.6.1" displayName="CHIEF COMPLAINT"/> <title>主诉</title> <text> 转移性右下腹痛伴发热一天 </text> </section> </component>
我们想获取 OID,主要有两个渠道,一是使用 OID 作为名字空间,二是成为 OID 的注册机构。两个渠道的区别在于,注册机构能够创建新的 OID 供自己和他 人使用,也可以授权其他实体作为注册机构。机构可以从多个渠道获得 OID,例 如 HL7。HL7 并没有要求获得 OID 的组织在文档和消息中必须使用来自哪里的 OID。 但是一旦机构获得 OID,就需要在 HL7 注册表中注册,使得其他机构知道 OID 的 所有者是谁。OID 一旦被分配,就不能改变,从而标识不同的对象,即使是注册 机构也不行,也就是说 OID 绝不可以循环使用。旧的 OID 不再使用后,需要申请 或者创建新的 OID。
可以通过网址 http://www.hl7.org/oid/index.cfm 从 HL7 注册和获取 OID, 从 HL7 获得 OID 后,自动注册,HL7 总会的 OID 根为“2.16.840.1.113883”。有 内部 OID 和外部 OID 之分,内部 OID 是指从 HL7 申请得到的 OID,外部 OID 是指 从其他渠道获得的 OID,在 HL7 注册。
在中国,需要向官方机构申请注册 OID。
第2章 CDA文档头
CDA 文档头是 CDA 文档的第一部分。它包括除了包含文档体的元 素以外的所有内容。 CDA 文档头表示了临床文档的内容的语境。
<ClinicalDocument xmlns='urn:hl7-org:v3' xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance' classCode='DOCCLIN' moodCode='EVN'> <realmCode code='…'/> <typeId root='2.16.840.1.113883.1.3' extension='POCD_HD000040'/> <templateId root=' 2.16.840.1.113883.10.20.1'/> <id root='…' extension='…'/> <code code='…' displayName='…' codeSystem='…' codeSystemName='…'/> <title>…</title> <effectiveTime value='…'/> <confidentialityCode code='…' displayName='…' codeSystem='…' codeSystemName='…'/> <languageCode code='…'/> <setId root='…' extension='…'/> <versionNumber value='…'/> <copyTime value='…'/> : </ClinicalDocument>
CDA 文档头是由 3 种不同的元素组成,按照下列顺序:
1.ClinicalDocument 类的 RIM 属性
2.与 ClinicalDocument 类关联的参与者
3.与 ClinicalDocument 类相关联的相关活动。
RIM 的属性按他们出现在 CDA R-MIM 中的次序出现。参与者及相关活动按用 于 CDA 标准开发的 XML ITS 和 HL7 工具中预定的次序出现。
2.1 文档头的 RIM 属性
ClinicalDocument 类的 RIM 属性的按下面图表的次序出现,这来自于 CDA RMIM。
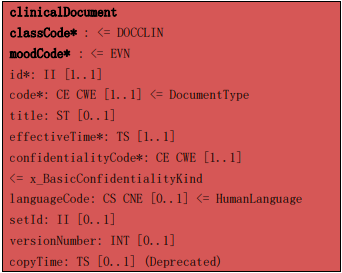
ClinicalDocument 类相关的类属性用于标识文档,描述包含的内容是什么, 指示有关的日期和时间,并帮助决定哪些政策应尊重患者的隐私。
2.1.1 临床文档唯一标识符(id) ClinicalDocument.id 标识符[1..1]
ID 类属性提供了一个临床文档的唯一身份。两个具有相同的 ID 的文档,其 内容必须完全相同。用于表示 XML 的字节可以是不同的(例如,一个存储为 EBCDIC 和另一个存储为 UCS- 16)的,但内容必须是相同的。
2.1.2 临床文档集合标识符(setId) ClinicalDocument.setId 集合标识符[0..1]
临床文档集合标识符用来表示所有文档修订的一个通用的标识符。
2.1.3 临床文档版本号(versionNumber) ClinicalDocument.versionNumber 版本号[0..1]
每一个临床文档描述了在医疗过程中发生的一系列医疗事件。在临床文档中 描述这些事件通常只需要一个版本。然而在有些情况,文档可能需要被修改。文 档版本号是一个整型数值,表示成功替换的文档的版本,用于文档版本依次更替 的控制。
2.1.4 临床文档概念代码(供机读)(code) ClinicalDocument.code 代码[1..1]
code 类属性使用一个机器能理解的编码值来描述临床文档类型,例如:体格 检查,出院小结,病程记录等。虽然 CDA 文档可以使用任何编码系来描述,但首 选的编码集是 LOINC 术语标准,也允许采用 HL7 之外的编码系统。 LOINC 从 2003 年 5 月的 2.09 版本开始,LOINC 数据库中的文档类型代码对 应的 Scale 组分的值为“DOC”。
2.1.5 临床文档标题(供人读)(title) ClinicalDocument.title 标题[0..1]
title 类属性提供一个人可读的字符串。title 的目的是作为文档的人可读 的通用名,例如既往史和体格检查记录或出院小结,描述文档中所述的服务类型。 这意味着,如果存在标题,必须在 CDA 内容中渲染为人可读的形式。 你会注意到,title 类属性是可选的。强烈建议在所有的临床文档使用标题。 这是因为标题最常见在用户界面上显示临床文档所对应的内容。 title 和 code 属性的使用,是你将在 section 中所看到的一个模式。从人 可读的标题对应机器可读的编码的这种分离能带来很大的好处。 标题是一个是临床文档的可选组件,但编码不是。当产生临床文档时,没有 真正的原因能省略了标题,因为人可读的标题至少可以把人可读的文档标题与文 档的编码相关联起来。因此,强烈建议,每一个临床文档应包含一个标题。
2.1.6 临床文档语言(语种)代码(languageCode) ClinicalDocument.languageCode 语言代码[0..1]
类属性 languageCode 描述临床文档的首选语言。languageCode 的数据类型 是 CE。在 HL7 中使用的语言编码与其它系统的编码是相同的。这些在 RFC-3066 中描述了细节,使用了 ISO-639 语言编码和 ISO-3166 国家编码。 需要注意的是 ISO-3166 有三个部分。第 1 部分国家编码,第 3 部分,包括被国家所使用的语言编码。在 HL7 第 3 版中使用的语言只接受第 1 部分和第 3 部 分的内容。第 2 部分包括国家细分(如国家,省和地区),以及不会使用的语言 编码。
2.1.8 临床文档保密性代码(confidentialityCode) ClinicalDocument.confidentialityCode 密级代码[1..1]
在临床医疗活动中,信息的保密性引起了人们的极大关注。然而,文档保密 性的处理规则完全由患者同意、当地政策、法律法规等决定。 在 CDA2.0 版本中,用一个且只有一个编码来描述文档内容的保密性。不幸 的是,这个值存储在类属性 confidentialityCode 中。言下之意是,这个类属性 描述了保密政策要求。而现实情况是,CDA 推荐的值域简单地描述信息的敏感性。 一般来讲,保密性是按保密水平来描述的,就象文档的保密等级一样,从最 低到最严格(就象在间谍电影中看到的绝密)。CDA 的三个推荐值是:Normal(正 常)、Restricted(受限制的)和 Very Restricted(严格受限制的)。推荐使用 这一套推荐值,或者使用相似的值。
<confidentialityCode code='N' displayName='Normal' codeSystem='2.16.840.1.113883.5.25' codeSystemName='Confidentiality'/>
注意:文档的保密性至少是基于其内容中最敏感的数据元素来定的,但是也 允许根据文档内容中所包含的数据所组合表达的内容来定。比如最常见的例子, 出生日期、邮递区号、性别通常是不足以标识一个人的身份(也不一定,一些用 于住宅的邮政编码能够非常容易地识别由个人组成的小团体)。但是当这三个信 息组全到一起时,可能就足以确定一个人了。
2.2 关联的参与者
文档的语境(Context)包括了许多在创建文档时不同的参与者。这些参与 者包括负责创建文档的人、组织、甚至是医疗设备或应用程序。每一个参与者与 文档中的角色相关联。
在这一章节中,参与关联按作用类分组,因为这两个部分协同工作。参与关 联描述了功能角色,角色类描述了结构角色。
本节将描述这些参与者,包括记录对象、作者、数据录入者、信息提供者, 保持文档真实和完整的组织,文档的收受者,审核者,以及许多其他可选的参与者。
2.2.1 审核者(authenticator) authenticator 审核者[0…∞]
描述文档的审核者,一个临床文档可以有 0 到多个审核者。临床文档审核者 是可以为文档的正确性作证的参与者,但是没有从法律上鉴证的权利(参考 legalAuthenticator ),比如住院医师看完患者后写了一个记录并签字。
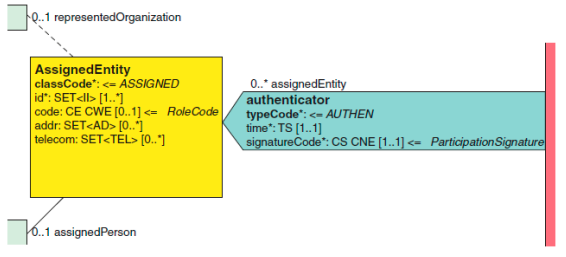
审核者签名时间记录在 authenticator 类的 time 属性中。signatureCode 属性使用一个 S 编码,以表明已经带有电子签名。另外两个编码的允许值是,X 编码表示这个参与者签名是必需的(但尚未附上),I 的编码表明,参与者打算签 署该文档。这两个编码值的出现表明,该文档尚未由参与者签署。只有值 S 是常见的,因为如果尚未签署该文档时,authenticator 关联通常不出现。
X 和 I 的编码支持文档的签署工作流程,但此元数据通常不会在 CDA 内容 中。相反,它是通过工作流程程序来管理。这些类属性可用于应用程序保存 CDA 形式的中间阶段内容(非最终),并存储相应的签名状态。
authenticator 关联使用 assignedEntity 角色来以确定该文档的审核者。
下面的示例演示了在 CDA 文档中以 XML 表达文档的审核者。
<authenticator> <time value='…'/> <signatureCode code="S"/> <assignedEntity>…</assignedEntity> </authenticator>
2.2.2 作者(author) author 作者[1…∞]
一个临床文档的作者可以是人或设备。 作者描述了出现在 CDA 中 HL7 RIM 类的三个不同种类的信息来源中的第一 种,而且无疑是最重要的,因为在 CDA 实例中必须有至少一名作者。在临床文档 中创造信息的作者是以自己的知识或技能的应用为基础的。向他们提供的信息记 录的其它各方可能会或可能不包括作者的判断在临床文档中。

下面的例子展示如何在 CDA 文档中用 XML 记录个人或设备的作者。
<author> <functionCode code='…' codeSystem='…' codeSystemName='…' displayName='…'/> <time value='…'/> <assignedAuthor> <id root='…' extension='…'/> <code code='…' codeSystem='…' codeSystemName='…' displayName='…'/> <addr>…</addr> <telecom value='…'/> <assignedPerson> <name>…</name> </assignedPerson> </assignedAuthor> <representedOrganization>…</representedOrganization> </author>
2.2.3 保管者(custodian) custodian 保管者[1…1]
按照标准,每个有效的 CDA 文档必须有一个保管者。保管者是根据当地的政 策要求负责维护文档副本真实性、完整性的组织。保管者是通过保管者参与类与 临床文档关联。
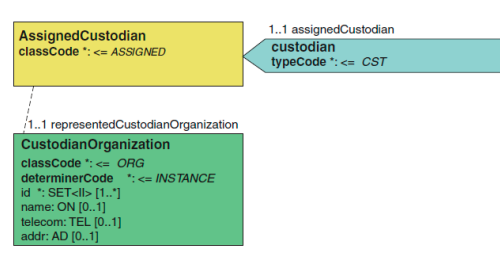
保管者关联临床文档到分配保管人。指定的保管者是被分配负责保管临床文档的组织。
<custodian> <assignedCustodian> <representedCustodianOrganization> <id root='…' extension='…'/> <name>…</name> <telecom value='…'/> <addr>…</addr> </representedCustodianOrganization> </assignedCustodian> </custodian>
2.2.4 数据录入者(dataEnterer) dataEnterer 数据录入者[0…1]
数据录入者的角色,是三个不同种类的信息来源的第二个。这个人负责录入 这些信息到临床文档中,通过从其他来源,纸面、音频听写等方式。数据录入者 通常不创建新的信息。最简单的形式是从一个形式转移到另一个。根据 CDA2.0 版标准,记录这些参与者的目的是用于支持质量控制。
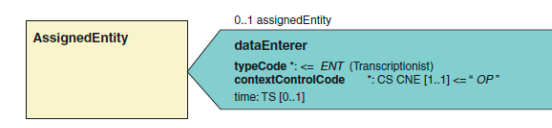
Time 类属性记录了数据录入者的开始时间。
负责的实体角色(AssignedEntity Role)
dataEnterer 关联类创建了临床文档与负责数据录入者之间的联系。如果你 比较 assignedEntity 类与以上提供的作者的 assignedAuthor 类之间的区别,你 会注意到只有一处不同。 assignedEntity 类的角色扮演者只能有一个 assignedPerson,而 assignedAuthor 而言,它既可以是人或设备。这两者之间 的微小差别,是他们使用不同名称的不同类的原因。 下面的例子演示了如何在 CDA 文档中用 XML 表述一个数据录入者。
<dataEnterer> <time value='…/> <assignedEntity> <id root='…' extension='…'/> <code code='…' codeSystem='…' codeSystemName='…' displayName='…'/> <addr>…</addr> <telecom value='…'/> <assignedPerson> <name>…</name> </assignedPerson> <representedOrganization>…</representedOrganization> </assignedEntity> </dataEnterer>
2.2.5 就医过程参与方(encounterParticipant) encounterParticipant 就医过程参与方[0…∞]
就医过程参与方包括对就医承担责任的各方和其他可能参加到就医过程的 各方。 HL7 标准中允许的参与方值集见在下面的表格中。
| Code | Print name | 描述 |
| ADM | Admitter | 负责接诊的医护人员 |
| ATND | Attender | 在整个医疗过程中对患者诊疗负责的医护人员 |
| CON | Consultant | 负责为患者特殊要求提供建议的医护人员 |
| DIS | Discharger | 负责出院的医护人员 |
| REF | Referring | 负责患者转诊的人(通常是医护人员,但有时不是) |
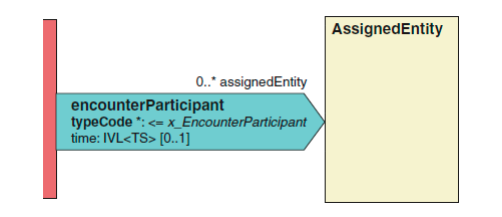
下面的例子演示了如何在 CDA 文档中用 XML 表述一个就医过程参与方。请注意,必须在<encounterParticipant>元素中指定 TypeCode XML 属性。
<encounterParticipant typeCode='ATND'> <time>
<low value='…'/>
<high value='…'/>
</time> <assignedEntity>…</assignedEntity> </encounterParticipant>
2.2.6 信息提供者(informant) informant 信息提供者[0…∞]
信息提供者是第三类 CDA 文档的信息源。这些人提供有关患者的信息,并可 以包括患者本人、父母或监护人、其他照顾者,甚至干脆目睹了事件发生的人。 informant 关联类链接 CDA 文档到提供有关患者信息的人。
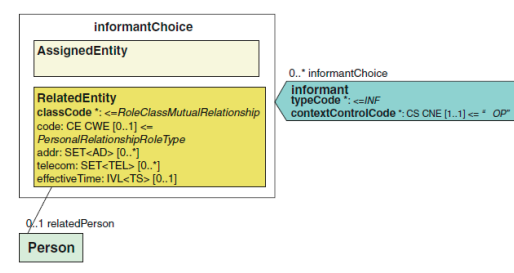
其主要目的是用来标识提供这些信息的人,与患者的关系,以及所提供信息 的进一步评估。所以参与时间不会出现在该模型中。
assignedEntity 类人能够用于提供的信息时,可以使用其他医疗服务提供者 或组织提供护理服务的员工。
relatedEntity 类是用来提供的信息,有一些明确的关系,患者当人。这些 关系可以是正式的,如患者和他们的合法授权代理(例如医保代理),或者保姆、 家庭成员或朋友之间的非正式的关系。
relatedEntity 类 classCode 进一步细化关系见使用的 HL7 RoleClassMutualRelationship 值设置的值的类型 RoleClass 术语。在 CDA 实例 中 relatedEntity 类中最常使用的编码是 PRS,它代表了个人与患者的关系(通 常是一个家族之一)的人。此编码将通常用于儿科护理,婴儿的母亲或父亲报告 的症状和体征,或在住院治疗过程中,家庭成员报告患者的情况。在这种情况下 编 码 的 类 属 性 进 一 步 指 定 样 的 关 系 , 通 常 会 来 自 HL7 的 PersonalRelationshipRole 类型值设置的 HL7 RoleCode 术语。
当相关实体不是一个人在与患者的个人关系,其他值集编码的类属性更合适。
下面的例子演示了如何在 CDA 文档用 XML 表示一个信息提供者。
<informant typeCode="INF"> <relatedEntity classCode="PRS"> <code code='…' codeSystem='…' codeSystemName='…' displayName='…'/> <addr>…</addr> <telecom value='…'/> <effectiveTime value='…'/> <relatedPerson> <name>…</name> </relatedPerson> </relatedEntity> </informant>
2.2.7 信息接受者(informationRecipient) informationRecipient 信息接受者[0…∞]
正如信息有来源,信息也有接受者。用来描述一个应该收到一个拷贝的接受 者。信息接受者是在文档创作的时候就需要直接指向的。这些都通过 informationRecipient 关联的 intendedRecipient 类来记录。
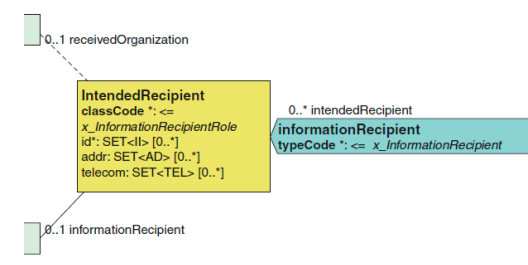
informationRecipient 参与不包括 time 类属性,因为这个人的参与时间不 能提前预测。预期的收件人可以是指定的实体,或与一个组织相关的健康图表。 在实际操作中,最经常使用指定的实体类编码(“ASSIGNED”)。在CDA模式(或在XML例子)中这个角色的扮演者被命名informationRecipient。recievedOrganization 限制了角色的范围,通常是雇用 informationRecipient 的组织。
下面的例子演示了如何在 CDA 文档用 XML 表示一个信息接受者。
<informationRecipient> <intendedRecipient classCode="ASSIGNED"> <id root='…' extension='…'/> <addr>…</addr> <telecom value='…'/> <informationRecipient> <name>…</name> </informationRecipient> <receivedOrganization>…</receivedOrganization> </intendedRecipient> </informationRecipient>
2.2.8 法定审核者(legalAuthenticator) legalAuthenticator 法定审核者[0…1]
法定审核者用来描述一个具有法律鉴定权利的参与者。一个 CDA 文档的认证 状态包括未认证(unauthenticated)、已认证(authenticated)和法律上认证 (legally authenticated)。当一个 CDA 文档是从一个本地文档中转换过来用来 交换用的情况下,发生在本地文档中的认证也需要反映在交换的 CDA 文档中。
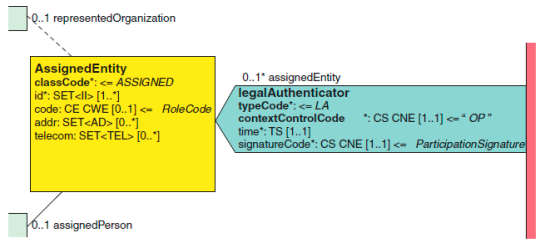
法定审核者签名时间记录在 legalAuthenticator 类的 time 属性中,用来描 述认证的时间。signatureCode 属性使用一个 S 编码,以表明已经带有电子签名。其他编码允许值参见 authenticator 。如果尚未签署该文档时, legalAuthenticator 关联通常不出现。
legalAuthenticator 关联使用 assignedEntity 角色来以确定该文档的审核 者。
下面的示例演示了在 CDA 文档中以 XML 表达文档的法定审核者。
<legalAuthenticator> <time value='…'/> <signatureCode code="S"/> <assignedEntity>…</assignedEntity> </legalAuthenticator>
2.2.9 其他参与者(participant) participant 其他参与者[0…∞]
这是 CDA 文档支持的最后一个通用的参与者。这个参与者允许 CDA 记录与临 床文档相关的其他角色,以支持原先没有预计到的用例。
participant 关联类允许 functionCode 用来记录参与者的职能作用。在 CDA 文档头中,仅有 participation 允许记录参与时间,并使用时间间隔(IVL_TS) 来记录。
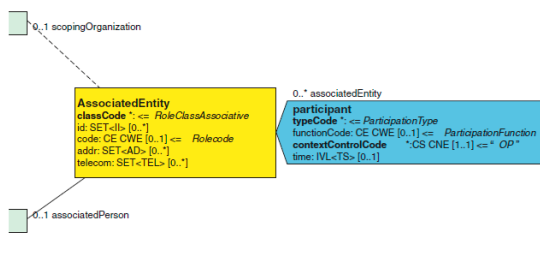
一般参与类使用关联实体角色。这是用于表达两个实体的关联的非常通用的 角色。然而,CDA 也约束了人之间的关联(见 associatedPerson 类)和组织间的 关联(scopingOrganization 类)。
在 CDA 中,通用 participation 类导致在 CDA 文档中的多重陈述的含义是相 等的。能够使用 participation 来记录作者,并且内容可以按照 RIM 语法来纠 正,参与者是“Used to represent other participants not explicitly mentioned by other classes…...”
在 CDA 模式中,participant 类禁止用来表达已经表达过任何类。这也是 CDA 实施中常见的用法。一些实施已经使用 participant 类的更多的扩展功能(例如, 关于 functionCode 和时间),以增加超过预期类允许的临床文档的内容。当这个 类试图表达的信息,在其他参与者类已经存在或者是其他参与者类表达信息的复 制,这是无害的。这是因为如果标准的参与者已经在其他地方指定了,CDA 实施 过程中通常不会再看 participant 类。
<participant typeCode="IND"> <functionCode code='…' codeSystem='…' codeSystemName='…' displayName='…'/> <time value='…'/> <associatedEntity classCode="NOK"> <id root='…' extension='…'/> <code code="MTH" codeSystem="2.16.840.1.113883.5.111" codeSystemName="RoleCode" displayName="Mother"/> <addr>…</addr> <telecom value='…'/> <associatedPerson> <name>…</name> </associatedPerson> <scopingOrganization>…</scopingOrganization> </associatedEntity> </participant>
2.2.10 执行者(performer) performer 执行者[0…∞]
每个服务事件是由扮演一些医疗服务提供者组织分配的角色的一个或多个 人来执行。下面的图形说明了这一点。

CDA 允许执行者(PRF)的标识符,而且你还可以通过 TypeCode 类属性进一 步区分主执行者(PPRF)和副执行者(SPRF)。执行者所执行的功能是描述在 functionCode 类属性中,和执行这个功能的时间可以记录在 time 类属性中。 functionCode 类属性描述了执行者的功能角色。
下面的例子显示了 CDA 文档中服务事件的执行者的 XML 表示。
<performer typeCode='PRF'> <functionCode code='…' codeSystem='…' codeSystemName='…' displayName='…'/> <time> <low value='…'/> <high value='…'/> </time> <assignedEntity> <id extension='…' root='…'/> <code code='…' codeSystem='…' codeSystemName='…' displayName='…'/> </assignedEntity> </performer>
2.2.11 记录对象(recordTarget) recordTarget 记录对象[1…∞]
记录对象可以说是与临床文档关联的最重要的人。其参与关联和角色类见下 图。必须注意到,每一个 CDA 文档需要至少有一个记录对象。 有人希望记录对象在 CDA 模型中使用一个名为患者的参与者来标识,但需记 得的是,临床文档通常出现在病历中。
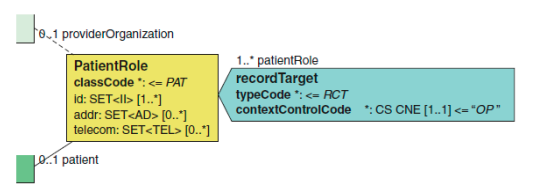
由于它标识这个文档出现在病历中,参与关联类的名称是 recordTarget。 一个单一的临床文档可以出现在一个以上的病历中,因此可以出现超过一个 recordTarget 关联。这种情况虽然少见,但也有一些用例,如新生儿分娩,就在 分娩记录中记载了母亲和新生儿的医疗记录或者联合治疗。
2.2.12 责任方(responsibleParty) responsibleParty 责任方[0…∞]
责任方是在 HL7 ParticipationType 术语表中描述的对就诊行为负主要责任 的人或组织。确定谁是就诊责任方往往由政策决定。由于主要关注就诊的责任, 所以参与的时间不包括在参与关联中,因为它是指其他就诊参与者。因为假定是 整个就诊的责任。所以责任方的参与时间与就诊的有效时间是相同的。
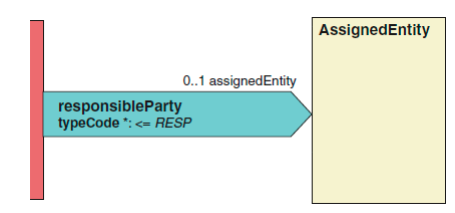
对于一个典型的门诊就诊而言,责任方是患者就诊时的医疗服务提供者,但 它也可能是对这些行为负责的一个提供者。比如婴儿经常找一个护士看病,但她 受一名儿科医生管理,所以儿科医生可能被认为是责任方。在住院时,最常指的 是患者的主治医生。在其他类型的临床文档中,就诊的负责方可能会有所不同。 在实验室报告中,这可能是发出报告的实验室主任。
但在其他诊断测试,它可能是那些解释结果的医疗服务提供者,或者管理他 们的工作的负责人。再次申明,政策法规决定谁负有最终的责任。
下面的例子演示了如何在 CDA 文档中用 XML 表述一个责任方。
<responsibleParty> <assignedEntity>…</assignedEntity> </responsibleParty>
2.2.13 位置(Location) Location 位置[0…1]
与就诊相关联的可以是就诊位置以及就诊的其它部分。
就诊的位置模型描述如下。
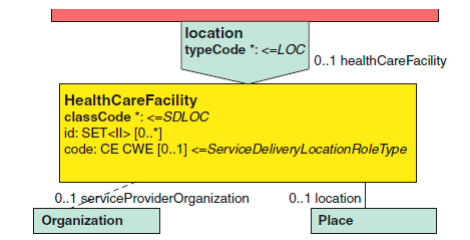
位置(location)关联完全由 CDA 标准规定的。 healthcareFacility 类使 用 id 和 code 类属性来记录与机构相关的类标识符,并说明机构的类型。place 类提供了位置的地址,是位置角色的 player(扮演者)。如果一个组织有多个设 施,其中一个特定的设施可以是位置,那么组织应包含这个位置。当只有一个设 施与组织关联,组织的地址和位置的地址是一致的。由于这些类都不是必需的, 实施时可以选择使用一种或另一种方式来记录位置的详细信息。
放在哪里的选择应取决于如何实施,预计接收到这个数据的使用。一个共同 使用的情况下,设施的位置数据是可以联系个人在那个特定的位置。在使用的情 况下,该组织类可以提供的地址和联系电话号码等信息。下面的例子显示了 XML 用于表示一个包含一个组织和一个地方的位置。
<location> <healthcareFacility> <id root='…' extension='…'/> <code code='…' codeSystem='…' codeSystemName='…' displayName='…'/> <location> <name>…</name> <addr>…</addr> </location> <serviceProviderOrganization> <id root='…' extension='…'/> <name>…</name> <telecom value='…'/> <addr>…</addr> <standardIndustryClassCode code='…' codeSystem='…' codeSystemName='…' displayName='…'/> </serviceProviderOrganization> </healthcareFacility> </location>
2.3 相关联的相关活动
有几个与 CDA 文档有关的活动也能够被记录在 CDA 文档头中,来进一步标识 文档的语境。这包括先前的文档(或相关的文档)、被执行的特定服务、就诊、 文档相关的医嘱、患者提供的与这些服务相关的知情同意书等。
2.3.1 父文档/上级文档(ParentDocument)
文档可以被替换(RPLC),作为其它文档的附件(APND)或是其他文档的格式 转换(XFRM)。转换可以自动执行(例如从 CDA XML 到 PDF 格式),或手动执行 (例如提取数据)。 CDA 标准允许使用活动关系中的 relatedDocument 来来记录 这些关系,以及在 parentDocument 类中记录相关文档的细节。
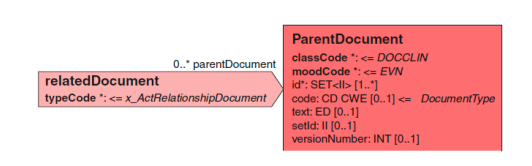
关系的类型记录在 relatedDocument 类的 typeCode 类属性中。在这里对有 可能记录关系的类型和数量进行了限制。 CDA 文档仅能记录它被转换、增补或 替换的唯一一个前文档。因此,单个文档不能替换、增补、转换到两个或两个以 上的其他文档。同样它也不能既替换一个文档同时又增加到另一个文档。但一个 文档的转换可以用来增加到或替换另一个文档,这是 CDA 标准的复杂性所允许 的。
下面的 XML 例子分别用到替换、增补和转换。
<relatedDocument typeCode='REPL'> <parentDocument> <id root='…' extension='…'/> </parentDocument> </relatedDocument>
<relatedDocument typeCode='APND'> <parentDocument> <id root='…' extension='…'/> </parentDocument> </relatedDocument>
<relatedDocument typeCode='XFRM'> <parentDocument> <id root='…' extension='…'/> </parentDocument> </relatedDocument>
可以想像一下,将一个特定的情节下所有相关的文档转换到一个摘要中。 CDA 标准不禁止这么做,但是它禁止在 parentDocument 类中记录所有的源文档。 幸运的是,在这种情况下,你可以记录在接下来的章节中描述中所引用的信息源。
父文档是一个文档产生之前发生的,所以 classCode 和 moodCode 由 CDA 标 准分别固定为 DOCCLIN 和 EVN。该文档的标识是最起码必须记录的 ID 类属性(可 能是 setId 和 versionNumber 属性)。
父文档的引文可以记录在 text 属性中。虽然这个属性是 ED 数据类型的属性, 它被 CDA 标准限制为允许唯一链接到在元素所提供的内容。这是那 些不符合 CDA Schema 的 CDA 约束之一。
2.3.2 服务事件(ServiceEvent)
每一个 CDA 文档都记录了为患者提供的各种各样的不同服务。这些服务能够 在较粗的粒度上描述(例如病史、体格检查或会诊),或较细的粒度上记录(询 问病史,详细的身体检查,免疫接种等)。
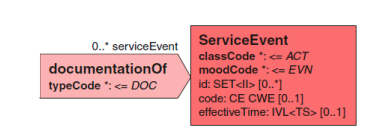
documentationOf 关联完全由 CDA 标准指定。它的详细信息可记录在 serviceEvent 类或与它相关连的 performer 中。
在 serviceEvent 类中的 classCode 类属性可以是在 HL7 活动类层次结构中 所表现的任意类型,就诊、程序、观察(如一个诊断检查),它是 CDA 文档所描 述的服务事件。
一些文档类型约束服务事件只是一个事件,是文档中所表达的最重要的事件。 HL7 CCD 应用指南就描述了这样一个文档。CCD 的目的是描述一段时间内所提供 的医疗护理,所以限制了 serviceEvent 的数量和内容。
HL7 CCD 应用指南(CCD)要求把 classCode 取值设置为“PCPR”。这是因为 CCD 的本质是记录基于一段时间内提供给患者的所有医疗服务所产生的摘要数 据。
<documentationOf> <serviceEvent classCode='PCPR'> <effectiveTime> <low value='…'/> <high value='…'/> </effectiveTime> </serviceEvent> </documentationOf>
服务事件的 code 类属性提供了更多的细节。它通常完全使用一些操作编码 (如 CPT,ICD-9-CM 操作,或从 SNOMED CT 操作层来的编码)来描述所记录的事 件。但是,当 CDA 文档用于记录检验结果时,它也可以是实验室检查的医嘱编码。
effectiveTime 类属性表达了服务事件的临床有效时间。它并不包括准备相 关的所有时间(如果它被允许,在 RIM activityTime 类属性表达)。再次以 CCD 为例,effectiveTime 类属性用来记录产生 CCD 文档的时间。在出院小结中,相同的类属性往往把住院时长作为 effectiveTime,因为出院小结提供了住院期间 所发生的事情的概述。
CDA 文档可以提供任意服务事件数量的记录(只要该文档的业务规则允许)。 在大多数情况下,CDA 文档中所提供的每一个行为是某种服务事件。有些人会奇 怪为什么 serviceEvent 的存在,这是在标准中使用替代方法来描述相同的信息。
在医疗系统中,使用非结构化的叙述往往有与该叙述相关的服务编码。在 CDA 文档头中的 serviceEvent 允许这些应用程序来描述服务,而无需使用 CDA 叙述 XML 格式来描述。
在旁观者看来,在 CDA 文档头中的 serviceEvent 类预计用来记录与应用程 序工作流相关的重要事件。这些事件可能是需要付费,或提供某些临床活动的记 录(如药物配伍)。把这些信息记录在文档头中使得它为应用程序快速访问。但 是请注意,这些使用往往根据产生的 CDA 文档的系统所在的本地业务规则而定。 这是建立 serviceEvent 使用上的最佳实践,以及它应该完成的详细程度。
2.3.3 医嘱(Order)
CDA 文档可以记录医嘱服务所产生的结果。例如影像检查,实验室检验或转 诊请求。结果可以使用 CDA 标准来反馈。医疗工作流程希望能够把结果链接到发 出申请的医嘱。所以 CDA 模式允许这些被记录下来。
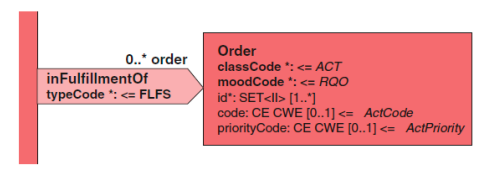
inFulfillmentOf 关联连接到最后导致该文档创建的医嘱。该关联完全由 CDA 标准来指定。
该医嘱的详细信息显示在 Order 类中。该医嘱至少需要一个 id 标识符。这 个标识符是由医嘱下达者、或医嘱执行者产生的,或者两者都能产生。如果有两 个,最佳做法是把两个都包括进去。
Order 类的 code 类属性将用于记录什么服务被请求(如实验室检验,影像, 或就诊类型)。当知晓时,这个类属性应该提供。
最后,priorityCode 类属性表示医嘱的优先级(例如立即、尽快、常规)。 此编码可被用于接收者如何提醒收到该文档的医疗机构。
下面的例子显示 infulfillmentOf 关联用于标识医嘱的数量和医嘱下达的类 型。这种医嘱被 CDA 文档填充。
<infulfillmentOf> <order> <id root='…' extension='…'/> <code code='…' codeSystem='…' codeSystemName='…' displayName='…'/> </order> </infulfillmentOf>
2.3.4 同意/知情同意(Consent)
一个 CDA 文档记录了被执行一个特定的服务。在许多情况下,这些服务的提 供者被要求在执行这些服务之前需要获得患者的知情同意。
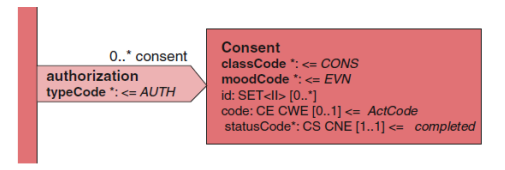
authorization 关联类是完全由 CDA 定义,并链接此文档到知情同意书。 consent 类允许医疗机构记录获得了一个知情同意书,并指出什么类型的知情同 意被提供。最起码,consent 类表示已经获得知情同意书,并没有提供进一步的 细节。id 类属性被用于记录与知情同意书相关的任何标识符(例如签署知情同 意书的标识符)。code 类属性记录所获得的知情同意的类型。
<authorization> <consent> <id root='…' extension='…'/> <code code='…' codeSystem='…' codeSystemName='…' displayName='…'/> <statusCode code='completed'/> </consent> </authorization>
2.3.5 所处就医过程(EncompassingEncounter)
记录在 CDA 实例中的服务事件通常被作为临床就诊的一部分被提供。就诊的 模型如下图所示。
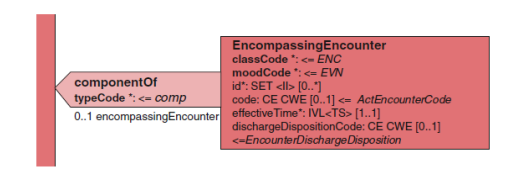
componentOf 关联链接该文档到它记录的就诊。它完全由指定的 CDA 标准。 encompassingEncounter 类描述就诊事件。
effectiveTime 类属性是必需的,用于记录就诊时间。它使用 IVL_TS 的数据 类型以便记录就诊的持续时间。
就诊的标识符和就诊类型分别由 id 和 code 类属性来记录。在不同的医疗机 构中,就诊就诊标识符可以是多种多样的,如门诊号码、就诊号码、预约号码, 有时甚至是帐户号码。
code 类属性通常用于记录就诊的类型。在美国,通常会使用象 CPT-4 类似的 编码集。也可以使用 HL7 ActEncounterCode 来描述,还可以使用 SNOMED CT 术 语。 dischargeDisposition 类属性记录了在就诊完成后,对患者而言发生了什 么事。这往往记录患者是否出院回家,转移到另外一家医院,或者住院治疗。
下图显示了使用 componentOf 关联的 XML。
<componentOf> <encompassingEncounter> <id root='…' extension='…'/> <code code='…' codeSystem='…' codeSystemName='…' displayName='…'/> <statusCode code='completed'/> <effectiveTime> <low value='…'/> <high value='…'/> </effectiveTime> <dischargeDispositionCode code='…' codeSystem='…' codeSystemName='…' displayName='…'/> </encompassingEncounter> </componentOf>
第3章 CDA文档体
3.1 CDA 文档体概述
一个 CDA 文档由文档头和文档体组成。CDA 文档头确定了文档的分类,提供 了鉴定信息、受访数据、患者、提供者等信息。CDA 文档体包括了临床报告。它 可以是一个非结构化的大型二进制对象,也可是结构化对象。可以使用多个可以 递归的文档章节,每个章节可以包含一个单独的叙述块,以及任意数量的条目和 外部引用。
CDA 文档体表示了临床文档的叙述内容。文档体仅仅是一个临床文档的一部 分,并通过组件相关类来存取。
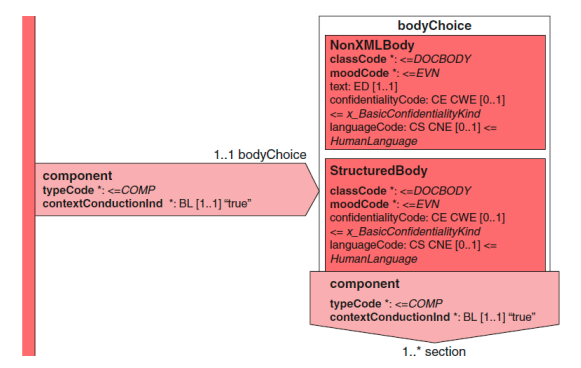
对文档体内容有两种选择:它可以使用非结构化格式的 NonXMLBody 类来存储,也可以使用结构化的 structuredBody 类来存储。
这两种活动的类的属性几乎是相同的。该 confidentialityCode 类属性与在 ClinicalDocument 中相同名称的类属性在本质上目的是相同。唯一的区别是, 它用于标识文档体中内容的保密性,并没有涉及在文件头中信息的保密性。由于 临床文档的保密度已经与大部分内容保密性相当,这个类属性很少使用。
languageCode 的类属性标识了叙述内容中使用的首选语言。同样,这与 ClinicalDocument 中的类属性相重复,也很少被使用。
这两个类之间的主要区别在于他们如何交换叙事内容。NonXMLBody 类交换文 本类属性中的内容。而 StructuredBody 类使用与 StructuredBody 其它组件相关 联的的 section 来交换内容。
CDA 文档体结构图:
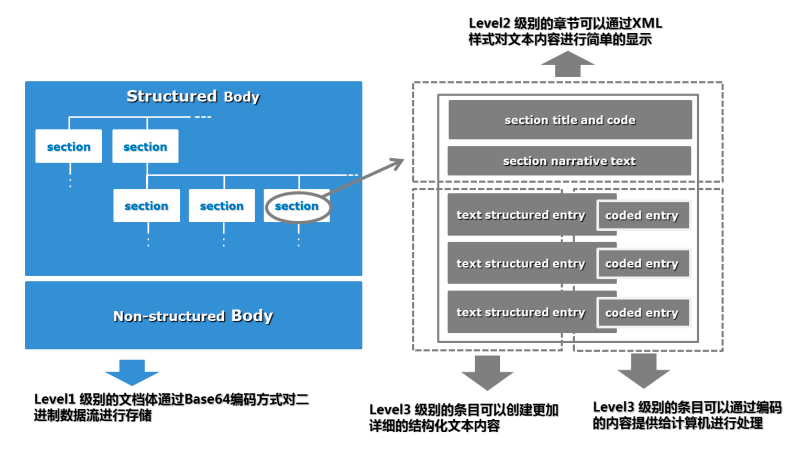
按照文档体的结构化程度,我们将 CDA 文档划分为三个层次,分别为 Level 1、Level 2、Level 3。Level 1 级别的文档体的内容是一个没有结构的整体,其 内容仅为自然文本,也可通过 Base64 编码方式对二进制数据流进行存储,不包 括任何章节和条目的信息;Level 2 级别将文档体部分划分章节,但每一个章节 内容是一个没有进一步结构化的整体,章节内容都是自然文本,可以通过 XML 样 式对文本内容进行简单的显示;Level 3 级别的文档体既有章节,也有章节下面 的条目,条目可以创建更加详细的结构化文本内容,给出每个条目的编码及其结果值,并指定值的表示方式,条目通过编码的内容就能够让计算机自动识别和处 理相应信息。
3.1.1 非结构化文档体
NonXMLBody 类通过文本类属性来交换叙事内容。一个第一层 CDA 文档将使 用 NonXMLBody 类发送文本。
非结构化文档体通过 text 元素来容纳非结构化数据,文本类属性使用 ED (封装的数据)数据类型,这意味着,它可以有效地包含任何二进制内容,它可 以在任意文本格式中直接包含内容,或使用 base64 编码来进行编码,或引用外 部数据源。
- 文本方式
下面的例子显示如何在 CDA 文档包含纯文本内容。使用<![CDATA[]]>分隔 符来使 XML 解析器忽略在内容中的任何特殊字符。这允许纯文本包含&、<、>等 符号,而不用担心内容的表达错误。
<component> <nonXMLBody> <text mediaType='text/plain'> <![CDATA[This is a narrative text report.]]> </text> </nonXMLBody> </component>
与 XML 一样,也可以用来包含如文本 RTF 或 HTML 等其他格式的内容。
- 二进制方式
下一个例子显示了如何将一个二进制数据格式包含在 CDA 文档内,如便携式 文档格式(PDF)。二进制数据是简单的 Base 64 编码,如何在元素中存储, 如下图所示。
<component> <nonXMLBody> <text mediaType='application/pdf' representation='B64'> JVBERi0xLjMKJcfsj6IKOCAwIG9iago8PC9MZW5ndGggOSAwIFIvRmlsdGVyIC9G … eHJlZgo0OTkzNAolJUVPRgo= </text> </nonXMLBody> </component>
在这一块中,也可能对数据进行压缩(在 Base 64 编码之前),以减少 XML 的存储空间。
- 引用方式
最后,文本内可以简单地引用 URL。在下面的例子,一个相对 URL 路径标识 了与 CDA 文档存储在一起的 sample.pdf 文件。
<component> <nonXMLBody> <text mediaType='application/pdf'> <reference value='sample.pdf'/> </text> </nonXMLBody> </component>
CDA 文档的叙述内容的分离,破坏了 CDA 标准的其中一个目的,但也带来了 一些好处。使用 nonXMLBody 的 CDA 文档使阅读更困难,因为其中的内容不得不 被解压缩,解码,并交给了一个外部的阅读程序(例如,一个字处理器或浏览器 应用程序)。这些操作是比简单地转换内容到 Web 浏览器中显示更困难,能够分 离内容使这些操作更容易被执行,以从文档中分离内容为代价。
其中一种机制就是 CDA 标准建议使用 MIME 多媒体包,提供了把所有的组件 放在一起的功能。CDA 文档的第三节描述了一个 CDA 文档能够在 MIME 多媒体包 中发送。辅助文件被包含在这个包中,并且在 MIME 部分包括了内容定位的头部, 给出的“文件名”用来引用在 CDA 文档中的内容。
NonXMLBody 意味着非 XML 内容
使用 NonXMLBody 这个类名是因为 CDA 标准进一步规定约束的内容不会出现 在 XML 中。CDA 的标准规定:“NonXMLBody 类表示其他一些非 XML 文档的格式。”这个约束限制,因为有人认为,如果你有一个 XML 文档,它可 以改组为通过 XSL 转换,有没有必要允许任意 XML 内容的 CDA StructuredBody 类。
一方面基于 XML 格式的文档,可能很容易地转换到 CDA 叙事块格式,但使用 基于 XML 格式的图形就没有那么容易转换。它也完全不能被表述为 HTML 格式。 HTML 是很容易转化的格式,但不是一个 XML 格式(使用旧的 SGML 标准)。在此 约束下,依据这个标准,在心电图报告中使用可缩放矢量图形(SVG,Scalable Vector Graphics)标准的渲染是不允许。可以把文件格式从 SVG 改到 SVGZ(压 缩的 SVG)使结果变成是一个二进制文件,以满足非 XML 内容的要求。
NonXMLBody 的 text 类属性的内容可以使用除了“text/xml”MIME 类型以外 的内容,这样看起来更好。这将允许在 CDA 文档中使用 SVG(它的 MIME 类型为 “image/svg+xml”),但将禁止使用其它 XML 格式来表述文本内容。
3.1.2 结构化文档体
使用 CDA 标准的主要好处之一是,它可以使应用程序减少由于使用专有的文 件格式导致的读取失败,因为万一更换电子病历系统,原有的电子病历就可能不 能被新的系统所识别。而采用 CDA 标准格式的病历,使得它可以在存储数十年后 忠实地再现文本。structuredBody 类是此内容的起点。由许多不同 section 类 实例简单地组成。
<component> <structuredBody> <!-- one or more sections --> <component> <section>…</section> </component> </structuredBody> </component>
3.2 CDA 章节
本 Section 类包含一个 CDA 文档的一部分的信息。部分 section 类模型如下 图所示。


3.2.1 章节的属性(Section Attributes)
- Section.id
每一个章节(section)能使用 ID 类属性来唯一地标识。这个属性的使用, 允许整个章节被其它内容所引用的。
- Section.code
code 类属性标识了章节的类型,可用于机器处理。code 类属性的目的是计 算机程序能处理,正如 title 类属性是用于人可读。它允许章节的内容进行快速分类。CDA 的标准更喜欢使用 LOINC 代码来表达 code 类属性的内容,但也允许 其他术语标准,并且在一些地区甚至需要本地化的标准。CDA 的 level 1 和 level 2 之间的区别在于,后者使用 structuredBody 类和每一个章节使用 code 类属性。 下面的例子显示了一个叙述章节的 XML。
<component> <section> <id root='…' extension='…'/> <code code='…' displayName='…' codeSystem='2.16.1.113883.6.1' codeSystemName='LOINC' /> <title>…</title> <text>…</text> <subject>…</subject> <author>…</author> <informant>…</informant> <!-- See Clinical Statements --> <entry>…</entry> <!-- Optional subsections --> <component>
<section>…</section>
</component> </section> </component>
- Section.title
title(标题)类的属性提供人可读的章节标题。这通常是医疗服务提供者希 望看到的作为临床医疗实践一部分的章节标题。title 类属性从 code 类属性中 分离出来似乎是重复的。尤其是当 code 类属性包含了一个能够用来描述这个章 节的显示名称时。然而,从不同的角度来讲这种分离是合理的。医务工作者往往 被训练来以某一种方式工作,而试图改变他们的工作习惯是破坏性的。这样, title 类属性能够被用来表达医生们习惯的章节标题,而 code 类属性则包含需 要被计算机处理所需要的标题,这样就避免了医务工作者为了使计算机更容易处 理内容而不得不作出一些改变。
- Section.text
text 类属性是被 CDA 标准限制用来仅能包含使用 CDA 叙事块格式的内容
- Section.confidentialityCode
confidentialityCode 类 属 性 标 识 了 章 节 中 内 容 的 保 密 等 级 。 就 像 ClinicalDocument 和 structuredBody 类中所使用的那样。与 structuredBody 类一样,这些类属性也很少被使用。
- Section.languageCode
languageCode 类属性标识了章节中内容的被使用的首选语言。就像 ClinicalDocument 和 structuredBody 类中所使用的那样。与 structuredBody 类一样,这些类属性也很少被使用。
3.2.2 章节的参与者(Section Participants)
- 作者(author)
CDA 文档的每个章节都可以包含与文档的其它部分不一样的创建者。author关联类能够被用于联系章节的其它参与者。类的定义和表述与在前一章 CDA 文档 头中所描述的相同类名是一样的。
- 提供者(informant)
CDA 文档的每个章节都可以包含与文档的其它部分不一样的提供者。 informant 关联类能够被用于联系章节的其它参与者。类的定义和表述与在前一 章 CDA 文档头中所描述的相同类名是一样的。
- 对象参与者(Subject Participation)
在 CDA 文档体的作者和报告者的关系类与 CDA 文档头中的类结构相同。但是 subject(对象)关联类是一个新类。这一个部分,其作用是关联章节到在 relatedSubject 类中被记录那个扮演角色的人。subject 关联连接章节到除了患 者外的个人。

角色扮演者在 subjectPerson 类中描述。这个角色 classCode 的属性是被限 制为两个值。当值是 PAT 的,则对象是另一位患者。当值是 PRS 时,则对象是与 患者相关的个人。
subject 参与者通常用于在章节中描述与患者的家庭史相关的家庭成员。最 常见的,用于临产和分娩时在新生儿的的文档中记录有关母亲的信息,或者反之。 在这种情况下,classCode 的值是 PRS。
这种参与者也可以用来记录两个人之间的疾病传播,比如在同一医院的两个 患者,或组织配型的患者,等等。在这种情况下,classCode 的代码值是 PAT。
subject 关联类 awarenessCode 类属性标明章节对象的人是否对这些内容知 情。此属性的首选值见下面的表格。此属性是可选的并且不经常使用,但当遇到一些敏感信息如重要疾病风险被记录在案时,该属性就很重要。例如,在遗传咨 询时,患者的疾病风险往往是基于对提供家庭病史的患者家庭成员来计算的。这 些风险被记录在患者的遗传风险评估中。记录这些信息是否被传达给评估对象是 非常重要的,因为可能往往家庭成员对评估情况并不知情。
relatedSubject 类在 code 类属性中标明在 subject 和 patient 之间的关系。 属性代码应从 HL7 PersonalRelationship RoleType 值集中选择。值集包含大多 数的家庭关系,如包括通过血缘和婚姻的第一层、第二层和第三层关系,还包括 朋友、邻居、室友和家庭伙伴。此值集来自 HL7 RoleCode 术语表。
subjectPerson 类则提供章节中对象人的一些详细基本情况。这些详细信息 包括他们的姓名、性别和出生日期,分别记录在 name、administrativeGender 和 birthTime 类属性中。
下面的例子显示使用 subject 来表达在待产和分娩期间一个母亲所生的一个 亲生子女。
<section> … <subject awarenessCode='I'> <relatedSubject classCode='PRS'> <code code='NCHILD' displayName='Natural Child' codeSystem='2.16.840.1.113883.5.111' codeSystemName='RoleCode'/> <subject> <name>…</name> <administrativeGenderCode code='F' displayName='Female' codeSystem='2.16.840.1.113883.5.1' codeSystemName='AdministrativeGender'/> <birthTime value='…'/> </subject> </relatedSubject> <subject> </section>
3.2.3 章节的关联(Section Relationships)
- component
章节可以嵌套。子章节能够通过 component 关联类连接到它的父章节。一个 章节能够包含文本和子章节,但不是很常见的。当被渲染的章节既包含文本也包 含子章节时,文本应该出现子章节之前。
- entry
每一章节也可以包含多个机器可读的条目。这些条目使用条目关联类与章节 相关联。
3.3 CDA 条目
文档体中描述的是临床信息,主要有两部分组成:一是文本,为人可读的自 然语言描述;二是条目,为机器可互操作的编码信息。
临床陈述模型的 7 个核心类是 : 观察( observation )、 物 资 管 理 (substanceAdministration)、供应(supply)、操作(procedure)、就诊 (encounter)、组织(organizer)和活动(act)。这些都出现在 CDA XML 的 的元素中,用于记录机器可读的临床数据。他们都可以使用 元素互相连接来建立更大的临床陈述。 以下章节从最基础的活动开始,描述了这些类,逐渐向上构建更复杂的陈述。 在这样做时,它指出了不同类的相似结构,而不一定反映 RIM 的类层次架构。这 里有 2 种主要视角,要么是通过软件工程师看这些类如何工作,要么是从临床信 息模型的角度看。

条目的通用属性
| 属性 | 注释 |
| classCode | 条目的类型。 |
| moodCode |
条目的语境,枚举类型,常用如下: PRP - 提议,建议 PRMS - 承诺 ARQ - 约定请求 APT - 约定 INT - 决定要执行但还未发生的事件 RQO - 医嘱 DEF - 定义 EVN - 实际的已发生的事件 |
| negationInd | 否定标识。Bool 类型,通常置为 false,表示对条目描述事件的肯定。 |
条目的通用元素
| 元素 | 注释 |
| templeteId | 条目的模板标示符 |
| id | 条目的唯一标识 |
| code | 条目所描述事件的编码 |
| text | 条目所描述事件的内容文本 |
| statusCode | 条目所描述事件的状态 |
| effectiveTime | 条目所描述事件的相关时间 |
| priorityCode | 条目的优先级 |
| subject|specimen | 条目中可能涉及到的关注主题或者标本 |
| author|performer informant|participant | 条目中涉及到的所有参与者,包括作者、执行者、提供信息者 和其它类型的参与者 |
| reference | 条目对外的引用 |
| precondition | 条目所描述事件的前提或者先决条件 |
| entryRelationship | 条目与条目的关联 |
第4章 CDA本地化与共享文档规范
4.1 CDA 本地化方法学
4.1.1 CDA 本地化的背景
首先,CDA 中文本地化并不是从零开始,在国外,都能找到许多可供借鉴参 考的标准,如前述 CCD、PCC、Consolidated CDA 等,特别是 HL7 Consolidated CDA,是美国在前一阶段各家分别制定自己的应用指南,导致内容表达不一致的 情况下,以 HL7、IHE 为主联合各方参与者,共同制定的一个合集,具有重要参 考意义。
其次,标准制定中,遵循“统一规范、复用优先”的原则,将标准主要内容 的复用性提高到重要层次,将各个章节(Section)和条目(Entry)单独拿出来 组成一个构件库,提高各应用指南间的一致性,降低标准工作量。
第三,应用指南的结构化层次适度,既尽量实现内容的完全结构化表达,又 充分考虑实际的可实现性,在保证文档的人可读性的前提下,在机器可读性上适 度。
4.1.2 CDA 本地化原则
- 直接引用
如果内容合适,直接使用国际标准,比如 HL7 CCD 可用于多个医疗数据摘 要的场景。
- 借鉴与继承
对于类似的用例,从标准文档模板中继承成本地化模板;
在文档规范模板中使用标准的章节和条目模板;
借助标准模板开发本地化需要的新模板;
重用标准模板中 RIM 模型的模式。
- 使用标准术语和词表
在 CDA 标准中,大量使用了已经国际标准和中国国家标准(SNOMED CT, LOINC, 卫计委数据集标准等);
尽量简化新开发的模板。
- 制定新章节和条目模板的原则
制定新的章节和条目模板,应坚持以下原则,
原则 1:尽量利用现有章节模板
原则 2:尽量继承现有章节模板
原则 3:不增加不符合 CDA 原则的内容
4.1.3 CDA 本地化模板的规范
CDA 的本地化过程中,主要引入了模板(Template),通过模板来加强对本地 化 CDA 文档的约束。
CDA 模板包括以下几个方面的定义:
(1)一组规则表达施加于 RIM 元素图的约束;
(2)模板 XML Schema;
(3)模板可以引用其他模板作为它定义的一部分;
(4)开放性:如果不加以专门说明,模板并不限制超出其约束但符合 CDA 标准的内容;
(5)模板可以继承另一个模板(父模板):其规范等于父模板的所有约束加 上新模板中定义的所有约束;
(6)模板的定义包括了相应的语义; 在重用的时候,其语义必须得到尊重。
4.1.4 CDA 标准本地化的工作流程
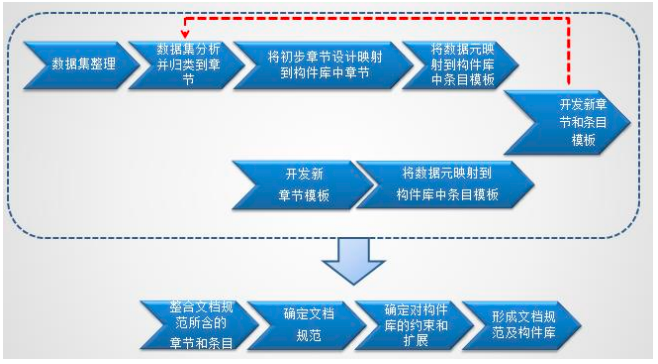
明确制定具体的 CDA 中文本地化应用指南后,具体流程如下:
- 需求调研,明确 CDA 文档规范的应用场景和需求范围
需要明确该 CDA 文档规范的应用场景,寻找与该文档规范场景中的文档实 例,并调研该文档是否存在国家数据集标准?是否已经存在相应的文档规范?是 否有相应的国际规范?
- CDA 本地化构件库的数据集整理
首先收集文档规范所需数据集,如果有国家卫生和计划生育委员会发布的正 式标准数据集,则尽量参考,在此基础上,添加确实需要的数据项。如果没有可参考数据集,需要做充分的调研和讨论,确定其内容。其主要原则是:1)优先 采用卫生部基本数据集标准,2)通用文档数据集等。 值得注意的是,往往标准的数据集不能完全反映实际需求,我们只能尽量采 用法定标准,并根据需要作出适当调整。
- CDA 章节归并与数据集映射
将确定的数据集根据其临床概念进行归类到章节,将初步章节映射到可参考 的模板库中的章节,这里的构件库初期可以参考 Consolidated CDA 的内容,后 期先考虑已经形成的模板库内容。 将各个章节中数据源映射到模板库中的条目模板。 如果找不到合适的章节 或条目模板,则需从已有的模板中抽取相似的模板进行修改或完全开发新的模板, 并将新的章节和条目模板归类到模板库中。
- 新的文档模板、章节模板和条目模板的制定
如果确定需要新建文档模板、章节模板或条目模板,则首先文档模板、章节 模板和条目模板中的具体数据元素和元素属性,按 CDA 标准制定模板的文档结 构,并明确每一个元素所对应术语的编码,以及相应的值域,以及所有的 OID 值。 并按 HL7 中国的规定或自定义的 OID,指定每一个模板的 OID。
文档模板主要约束文档头及在文档中对章节和条目的约束,而章节模板则约 束其本身及包含的条目信息。条目模板则约束本自身以及其关联的条目。
这里的编码系统的选择尤其值得注意,编码系统必须优先选用是国家标准、 LOINC、SNOMED CT、ICD-10 等公认标准,对于确实找不到编码的,也尽量在标准 组织框架下来增加新的编码。并且不一定要找到所有项目的编码,如果只做到 Level2,则查到分组的编码就可以了。
由于 HL7 中国使用 Trifolia 来管理 CDA 模板,所以模板的 OID 应在 Trifolia 中赋值。
- 确定文档规范的内容,及导出约束文档
将从模板库中抽取需要整合的章节模板和条目模板,加上新制定的章节模板 和条目模板,通过 Trifolia,可自动生成文档规范的初稿,以及文档规范所对应 的 Schematron。
- 模板库的更新
确定在文档规范中对模板库的约束和扩展,在整合过程中发现元素的约束或 需扩展的问题及时对模板库进行更新,最后导出规范的本地化文档规范和模板库。
总之,文档规范和模板库的形成工作是相辅相成的,可以通过文档规范的 本地化制定过程形成模板库,也可以通过模板库来加快文档规范的制定,从模板 库中整合所需的章节和条目模板来形成文档规范。
4.2 CDA 的中国本地化特殊要求
CDA 中文本地化首先要准确表达中文的内容,必须对 CDA 内容进行本地化。
- 文档语言标识
在 ClinicalDocument.languageCode 中使用”Zh-cn”表示本文档采用中文 语言。
- 文档头内容本地化
文档头用于表达患者的信息,如何完整表达患者信息,特别是一些中国本地 的数据项如姓名、住址、婚姻、民族等,比如姓名,中国人并没有分开表达,则 姓名表达在元素名,不再划分姓和名。
- 模板的本地化
主要体现在:
(1)模板标识的本地化
(2)内容的本地化 为了体现中文本地化的内容,需要根据实际需要添加很多本地化的模板,比如病案首页中,存在大量中国所独有的数据项,这些数据项最后要被模板所表达。
(3)术语与编码本地化
为了将模板内容准确表达,CDA 中大量使用了的国际标准编码化编码和术语 集。而尽管大部分模板中用到的术语和编码都可以找到,但仍有不少术语编码无 法获取。如何处理好术语和编码的本地化,是 CDA 本地化的核心问题。
4.3 中国医疗健康信息共享文档规范
4.3.1 概述
国家卫生健康委健康档案和电子病历共享文档规范是针对卫生行业电子交 换文档而制定的一套文档标记语言及规范,借鉴了国际上已有的成熟文档架构标 准 ISO/HL7 CDA R2(Clinical Document Architecture R2)三层架构,同时结合 我国医疗卫生实际,对 CDA R2 文档架构进行本土化约束和适当扩展,以适合和 规范我国医疗卫生环境下的卫生信息共享文档的共享和交换。而卫生信息共享文 档作为本规范的关键概念,是指以满足医疗卫生服务机构互联互通、信息共享为 目的的科学、规范的卫生信息记录,其以结构化的方式表达卫生业务共享信息内 容,是对文档架构的具体化。其由文档头、文档体组成,其中文档体又由文档章 节和文档条目组成。同时,在具体的共享文档研制上,首先,结合中国卫生业务 信息共享实际需要,构建可重用的章节模板和条目模板;其次,以城乡居民健康 档案基本数据集和电子病历基本数据集等规范为基础,选择确定共享文档的章节、 条目结合数据集的内容进一步规范约束共享文档的数据元素。模板构成,并将数 据元素映射到共享文档的文档头、文档体中。
卫生信息共享文档规范总则概述如下:
《卫生信息共享文档规范 总则》内容包括引言、前言、范围、规范性引用 文件、术语和定义、文档分类体系、文档架构规范(涉及文档架构、模板约束、 文档等级)、业务文档制定的基本规则(涵盖中国卫生信息开放系统互连对象标 识符设计与分配、文档信息模块与数据元素的约束性描述、数据元素的层次规范 和值域规范)以及实际业务应用文档标准的内容结构设计。
同时,总则中还包括三个规范性附录,即卫生信息共享文档分类编码系统、 中国卫生信息开放系统互连 OID 设计与分配表、扩展的中国卫生信息数据元值域 OID 分配表。四个资料性附录,即 ISO/HL7 CDA R2 文档结构、ISO/HL7 CDA R2 文档头、ISO/HL7 CDA R2 文档体、ISO/HL7 CDA R2 的层次结构说明。
每一部分的内容涵盖引言、前言、规范性依据、术语与定义、文档内容构成、文档头规范、文档体规范及文档示例附录。
每一部分的内容设置同样涵盖引言、前言、规范性依据、术语与定义、文档 内容构成、文档头规范、文档体规范及文档示例附录。值得说明的是,电子病历 共享文档规范其他部分的研制正在有序推进过程中,并已取得重要的阶段性成果, 将在年度前完成征求意见稿。
在这一系列标准中,《卫生信息共享文档规范 总则》是整个文档规范的总 纲,明确规范涉及的基本概念、文档架构、基本描述规则等方面的内容;《健康 档案共享文档规范》和《电子病历共享文档规范》各部分是在《卫生信息共享文 档规范总则》指导下结合业务实际所做的细化和落地。
随着我国经济的快速发展和人民生活水平的不断提高,人民群众对医疗卫 生服务提出了更高要求。同时,我国医疗体制改革的不断推进和深入,基于电子 健康档案的区域卫生信息平台、基于电子病历的医院信息平台的产品研发及系统 建设越来越广泛。
《文档规范》的制定为医疗卫生机构互联互通、信息共享提供 重要支撑,给居民健康服务、医疗卫生服务机构、医疗卫生软件厂商以及政府及 卫生行政部门等各方面均将带来显著效益。
《文档规范》的制定可以促进卫生信息数据标准在医疗卫生信息化建设的 应用,加快推进区域医疗互联互通、信息共享进程,推动跨区域医疗医保协同服 务、农民工异地医疗保健协同服务、依托第三方的个人健康管理服务,实现卫生 信息的跨区域共享及数据交换,实现居民跨区域就诊、实现跨区域社保、农保实 时结算,方便老百姓异地就诊,缓解“看病难、看病贵”问题,造福于民。规范 的建立是保障向居民提供连续性、综合性服务的前提和基础。
《文档规范》的制定为医疗卫生服务机构进行卫生信息化建设软件招标提 供指导,以正确的选择符合标准规范的软件产品,使各类系统能够方便的接入区 域卫生信息平台实现卫生信息共享、数据交换,同时能够实现跨区域互联互通, 节约信息化建设成本。
卫生信息数据标准包含了个人基本信息、儿童保健、妇女保健、疾病控制、 疾病管理、医疗服务、卫生监督等几大方面,是一个非常复杂、庞大的标准体系, 软件厂商在开发医疗卫生业务系统、区域平台、跨区域协同产品时往往不能系统、 全面的研究和分析卫生信息数据标准,在产品的需求分析、系统设计、软件编码和软件测试上不能很好的把握卫生信息数据标准的规范,开发的产品与标准会有 偏差,有些甚至完全不符合标准,这将导致产品在实施的过程中因不符合标准不 能进行卫生信息的共享及数据交换,二次修改使软件厂商增加了额外的技术支持 及工程实施成本。通过规范的制定可以给软件厂商提供卫生信息共享文档建设指 导,减少软件厂商产品研发及工程实施的成本,给企业带来经济效益。
《文档规范》的制定可以帮助政府及卫生行政部门对医疗卫生软件厂商提 供的产品进行认证,规范医疗卫生行业信息化市场,扶植一批具有竞争实力的软 件厂商,淘汰落后企业;同时可以增强政府及卫生行政部门对各医疗卫生机构信 息化建设进行监督的力度,使其按照规范的要求推进信息化建设。另外通过规范 的制定可以促进卫生信息数据标准的修订工作,使标准不断的扩充及完善。
《文档规范》的制定不仅可实施动态管理,而且更全面收集到患者的各种 健康信息,从而为医学研究提供科学重要的资料。另外,规范完整的个人健康档 案是宝贵的科研资料和供司法工作参考的重要资料。
4.3.2 电子病历共享文档规范
2016 年正式发布《WS/T 500-2016 电子病历共享文档规范》,这 一部分的内容已经完成了 53 个部分:
电子病历共享文档规范 第 1 部分:住院病案首页
电子病历共享文档规范 第 2 部分:处方记录
电子病历共享文档规范 第 3 部分:急诊留观病历
电子病历共享文档规范 第 4 部分:西药处方
电子病历共享文档规范 第 5 部分:中药处方
电子病历共享文档规范 第 6 部分:检查报告
电子病历共享文档规范 第 7 部分:检验报告
电子病历共享文档规范 第 8 部分:治疗记录
电子病历共享文档规范 第 9 部分:一般手术记录
电子病历共享文档规范 第 10 部分:麻醉术前访视记录
电子病历共享文档规范 第 11 部分:麻醉记录
电子病历共享文档规范 第 12 部分:麻醉术后访视记录
电子病历共享文档规范 第 13 部分:输血记录
电子病历共享文档规范 第 14 部分:待产记录
电子病历共享文档规范 第 15 部分:阴道分娩记录
电子病历共享文档规范 第 16 部分:剖宫产记录
电子病历共享文档规范 第 17 部分:一般护理记录
电子病历共享文档规范 第 18 部分:病重(病危)护理记录
电子病历共享文档规范 第 19 部分:手术护理记录
电子病历共享文档规范 第 20 部分:生命体征测量记录
电子病历共享文档规范 第 21 部分:出入量记录
电子病历共享文档规范 第 22 部分:高值耗材使用记录
电子病历共享文档规范 第 23 部分:入院评估
电子病历共享文档规范 第 24 部分:护理计划
电子病历共享文档规范 第 25 部分:出院评估与指导
电子病历共享文档规范 第 26 部分:手术知情同意书
电子病历共享文档规范 第 27 部分:麻醉知情同意书
电子病历共享文档规范 第 28 部分:输血治疗同意书
电子病历共享文档规范 第 29 部分:特殊检查及特殊治疗同意书
电子病历共享文档规范 第 30 部分:病危(重)通知书
电子病历共享文档规范 第 31 部分:其他知情同意书
电子病历共享文档规范 第 32 部分:住院病案首页
电子病历共享文档规范 第 33 部分:中医住院病案首页
电子病历共享文档规范 第 34 部分:入院记录
电子病历共享文档规范 第 35 部分:24 小时内入出院记录
电子病历共享文档规范 第 36 部分:24 小时内入院死亡记录
电子病历共享文档规范 第 37 部分:住院病程记录 首次病程记录
电子病历共享文档规范 第 38 部分:住院病程记录 日常病程记录
电子病历共享文档规范 第 39 部分:住院病程记录 上级医师查房记录
电子病历共享文档规范 第 40 部分:住院病程记录 疑难病例讨论记录
电子病历共享文档规范 第 41 部分:住院病程记录 交接班记录
电子病历共享文档规范 第 42 部分:住院病程记录 转科记录
电子病历共享文档规范 第 43 部分:住院病程记录 阶段小结
电子病历共享文档规范 第 44 部分:住院病程记录 抢救记录
电子病历共享文档规范 第 45 部分:住院病程记录 会诊记录
电子病历共享文档规范 第 46 部分:住院病程记录 术前小结
电子病历共享文档规范 第 47 部分:住院病程记录 术前讨论
电子病历共享文档规范 第 48 部分:住院病程记录 术后首次病程记录
电子病历共享文档规范 第 49 部分:住院病程记录 出院记录
电子病历共享文档规范 第 50 部分:住院病程记录 死亡记录
电子病历共享文档规范 第 51 部分:住院病程记录 死亡病例讨论记录
电子病历共享文档规范 第 52 部分:住院医嘱
电子病历共享文档规范 第 53 部分:出院小结
4.3.3 健康档案共享文档规范
2016 年正式发布《WS/T 483-2016 健康档案共享文档规范》, 这一部分主要包括 20 个业务文档规范:
健康档案共享文档规范 第 1 部分:个人基本健康信息登记
健康档案共享文档规范 第 2 部分:出生医学证明
健康档案共享文档规范 第 3 部分:新生儿家庭访视
健康档案共享文档规范 第 4 部分:儿童健康体检
健康档案共享文档规范 第 5 部分:首次产前随访服务
健康档案共享文档规范 第 6 部分:产前随访服务
健康档案共享文档规范 第 7 部分:产后访视
健康档案共享文档规范 第 8 部分:产后 42 天健康体检
健康档案共享文档规范 第 9 部分:传染病报告
健康档案共享文档规范 第 10 部分:预防接种报告
健康档案共享文档规范 第 11 部分:死亡医学证明
健康档案共享文档规范 第 12 部分:高血压患者随访服务
健康档案共享文档规范 第 13 部分:2 型糖尿病患者随访服务
健康档案共享文档规范 第 14 部分:重性精神疾病患者个人信息登记
健康档案共享文档规范 第 15 部分:重性精神病患者随访服务
健康档案共享文档规范 第 16 部分:成人健康体检
健康档案共享文档规范 第 17 部分:会诊记录
健康档案共享文档规范 第 18 部分:转诊记录
健康档案共享文档规范 第 19 部分:病历摘要
健康档案共享文档规范 第 20 部分:转诊(院)记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号