Pointer-network的tensorflow实现-1
pointer-network是最近seq2seq比较火的一个分支,在基于深度学习的阅读理解,摘要系统中都被广泛应用。
感兴趣的可以阅读原paper 推荐阅读
https://medium.com/@devnag/pointer-networks-in-tensorflow-with-sample-code-14645063f264
这个思路也是比较简单 就是解码的预测限定在输入的位置上 这在很多地方有用
比如考虑机器翻译的大词典问题,词汇太多了很多词是长尾的,词向量训练是不充分的,那么seq2seq翻译的时候很难翻译出这些词 另外专名什么的 很多是可以copy到 解码输出的
另外考虑文本摘要,很多时候就是要copy输入原文中的词,特别是长尾专名 更好的方式是copy而不是generate
网络上有一些pointer-network的实现,比较推荐
https://github.com/ikostrikov/TensorFlow-Pointer-Networks
这个作为入门示例比较好,使用简单的static rnn 实现更好理解,当然 dynamic速度更快,但是从学习角度
先实现static更好一些。
Dynamic rnn的 pointer network实现
https://github.com/devsisters/pointer-network-tensorflow
这里对static rnn实现的做了一个拷贝并做了小修改,改正了其中的一些问题 参见 https://github.com/chenghuige/hasky/tree/master/applications/pointer-network/static
这个小程序对应的应用是输入一个序列 比如,输出排序结果
我们的构造数据
python dataset.py
EncoderInputs: [array([[ 0.74840968]]), array([[ 0.70166106]]), array([[ 0.67414996]]), array([[ 0.9014052]]), array([[ 0.72811645]])]
DecoderInputs: [array([[ 0.]]), array([[ 0.67414996]]), array([[ 0.70166106]]), array([[ 0.72811645]]), array([[ 0.74840968]]), array([[ 0.9014052]])]
TargetLabels: [array([[ 3.]]), array([[ 2.]]), array([[ 5.]]), array([[ 1.]]), array([[ 4.]]), array([[ 0.]])]
训练过程中的eval展示:
2017-06-07 22:35:52 0:28:19 eval_step: 111300 eval_metrics:
['eval_loss:0.070', 'correct_predict_ratio:0.844']
label--: [ 2 6 1 4 9 7 10 8 5 3 0]
predict: [ 2 6 1 4 9 7 10 8 5 3 0]
label--: [ 1 6 2 5 8 3 9 4 10 7 0]
predict: [ 1 6 2 5 3 3 9 4 10 7 0]
大概是这样 第一个我们认为是预测完全正确了, 第二个预测不完全正确
原程序最主要的问题是 Feed_prev 设置为True的时候 原始代码有问题的 因为inp使用的是decoder_input这是不正确的因为
预测的时候其实是没有decoder_input输入的,原代码预测的时候decoder input强制copy/feed了encoder_input
这在逻辑是是有问题的。 实验效果也证明修改成训练也使用encoder_input来生成inp效果好很多。
那么关于feed_prev我们知道在预测的时候是必须设置为True的因为,预测的时候没有decoder_input我们的下一个输出依赖
上一个预测的输出。
训练的时候我们是用decoder_input序列训练(feed_prev==False)还是也使用自身预测产生的结果进行下一步预测feed_prev==True呢
参考tensorflow官网的说明
In the above invocation, we set feed_previous to False. This means that the decoder will use decoder_inputstensors as provided. If we set feed_previous to True, the decoder would only use the first element of decoder_inputs. All other tensors from this list would be ignored, and instead the previous output of the decoder would be used. This is used for decoding translations in our translation model, but it can also be used during training, to make the model more robust to its own mistakes, similar to Bengio et al., 2015 (pdf).
来自 <https://www.tensorflow.org/tutorials/seq2seq>
这里使用
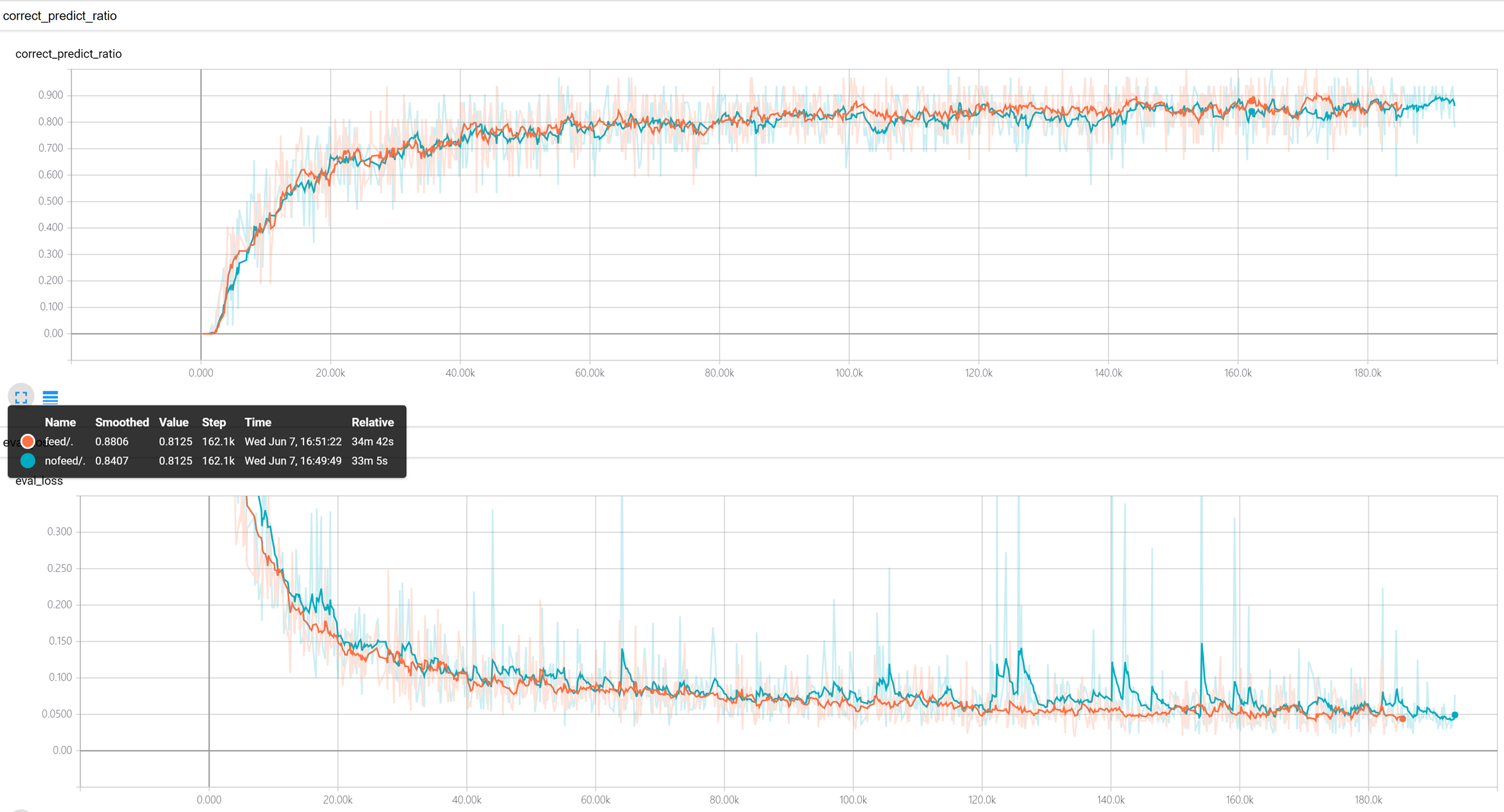
train.sh 和 train-no-feed-prev.sh 做了对比实验
训练时候使用feed_prev==True效果稍好(红色) 特别是稳定性方差小一些

 浙公网安备 33010602011771号
浙公网安备 33010602011771号