
Apache Amoro0.8.0数据湖管理和治理工具部署
问题1:
对比config.yaml、log4j2.xml配置文件,分析0.8.0默认配置和客户集群目前配置的差异,并说明新增参数含义。
config.yaml
和客户现有配置相比,0.8.0新增配置项及其默认值如下:
1. http服务器参数
http-server:
session-timeout: 7d # Session超时时间,用户登录 Dashboard 后,Session 的有效期为 7 天,7天内无需重新登录
2. 表刷新参数
refresh-tables:
max-pending-partition-count: 100 # 最大待处理分区数,当表的分区数量超过 100 时,不再使用分区过滤器,改为全表扫描的方式刷新元数据
3. 自优化
self-optimizing:
refresh-group-interval: 30s # Optimizer组刷新间隔,每30秒刷新一次Optimizer Group的状态,包括 Optimizer 的健康状态、资源使用情况等
4. 孤儿文件清理
clean-orphan-files:
interval: 1d # 清理间隔,即每天执行一次孤儿文件清理任务
5. 表清单io配置
table-manifest-io:
thread-count: 20 # 处理表清单文件(Manifest)的并发线程数
6. catalog缓存配置
catalog-meta-cache:
expiration-interval: 60s # 缓存过期时间,Catalog元数据在内存中的缓存有效期为60秒,失效后需要重新从数据库加载
7. 配置加密支持
shade:
identifier: default # 加密标识符
sensitive-keywords: admin-password;database.password # 敏感关键字
8. overview(概览)缓存配置
overview-cache:
refresh-interval: 3min # Dashboard概览页面的数据缓存,每3分钟刷新一次统计数据
max-size: 3360 # 最大缓存大小(即最近7天的历史数据,3360个数据点)
9. 数据库配置
database:
auto-create-tables: true # 自动创建表
10. 终端配置
terminal:
result:
limit: 1000 # 结果集行数限制,SQL Terminal查询结果最多显示1000行
stop-on-error: false # 出错时是否停止,执行多条SQL时,某条失败后是否继续执行后续语句
session:
timeout: 30min # Session超时,30分钟无操作后自动关闭连接
local:
using-session-catalog-for-hive: false # Hive使用session catalog
和0.7.0相比,已有参数默认值变化如下:
|
配置项 |
0.7.0 |
0.8.0 |
变更点 |
|
sync-hive-tables.enabled |
true |
false |
默认关闭Hive表同步 |
|
data-expiration.enabled |
false |
true |
默认开启数据过期 |
|
database.connection-pool-max-wait-millis |
1000 |
30000 |
连接超时从1秒增加到30秒 |
|
database.type |
未指定 |
derby |
默认使用Derby(0.7.0常用MySQL) |
|
interval |
180000 |
3min |
0.7.0支持毫秒,0.8.0支持s/min/h/d |
|
max-message-size |
104857600 |
100MB |
0.7.0支持字节,0.8.0支持 KB/MB/GB |
客户现有配置和默认值相比,做了以下改动:
● refresh-tables.interval从60000(1分钟)调到了600000 (10分钟),降低了表刷新频率
● self-optimizing.runtime-data-keep-days从30天调到了10天,将运行数据保留时长缩短,减少存储的占用
● rest-auth-type从token调成了basic认证
● 客户的hive表同步、数据过期参数配置和0.7.0默认配置保持一致
log4j2.xml

客户配置和0.8.0默认配置主要差异点集中在以下方面:
1. 客户配置:未设置 additivity="false",metric日志会同时写入 amoroMetricReporter 和 Root 的 appender,导致重复记录
2. 默认配置新增了Spark 日志配置,将 Spark 日志级别设置为 warn(减少冗余日志)
1. amoro.metric Logger
<logger name="amoro.metric" level="info">
<AppenderRef ref="amoroMetricReporter" />
</logger>
默认配置:
<logger name="amoro.metric" level="info" additivity="false">
<AppenderRef ref="amoroMetricReporter"/>
</logger>
2. 默认配置新增了Spark 日志配置
<logger name="org.apache.spark" level="warn" additivity="false">
<AppenderRef ref="infoFileAppender"/>
<AppenderRef ref="consoleAppender" level="${CONSOLE_LEVEL}"/>
</logger>
问题2:
ams.uri是否可以配置多个地址?如何配置?
ams.uri参数支持两种配置格式,分别为普通模式(单点配置)和高可用模式(多地址配置)。
● 普通模式:
○ thrift://host:port/{catalogName}
○ 如thrift://1.0.1.1:1260
● 高可用模式:
○ zookeeper://host:port/{cluster}/{catalogName},其中{cluster}参数为必填项
# AMS 高可用配置示例,config.yaml文件中的配置
ams:
ha:
enabled: true
cluster-name: production
zookeeper-address: zk1:2181,zk2:2181,zk3:2181
# 相应的前端配置
ams.uri = zookeeper://zk1:2181,zk2:2181,zk3:2181/production/
问题3:
本次在测试环境同一台机子上部署了不同版本的amoro,目前没有调整optimizer group的扫描范围。两个amoro的扫描范围一样,担心旧版本amoro治理完一次新的又治理一次。客户在对新版本amoro的使用上,计划将旧版本中的表逐渐灰度到新版本中,每次迁移一部分,分批将表交由新版本amoro治理。
解决方案:
可以用database-filter参数/table-filter参数解决,使用哪个参数取决于迁移是数据库粒度还是表粒度。
数据库粒度
针对这个场景可以用database-filter参数进行过滤,在创建catalog的时候指定database-filter, 该参数通过正则表达式过滤catalog中的数据库,控制哪些数据库在AMS的tables菜单中显示,让不同版本amoro分别负责不同数据库内的表治理,实现了对表的优化操作的隔离。
例如全部的数据库如下:
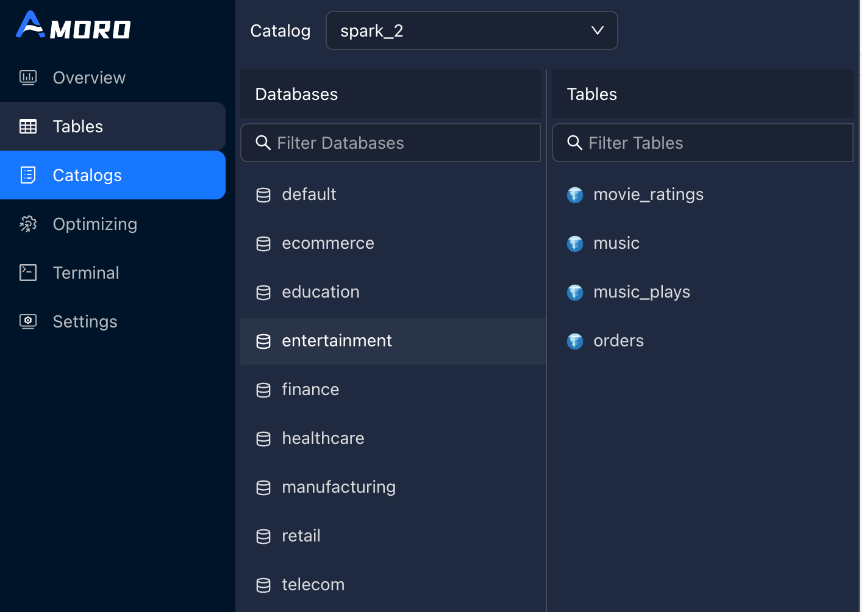
设置database-filter = entertainment|ecommerce,前端catalogs只显示该db及其中的表,只对这些表进行治理。

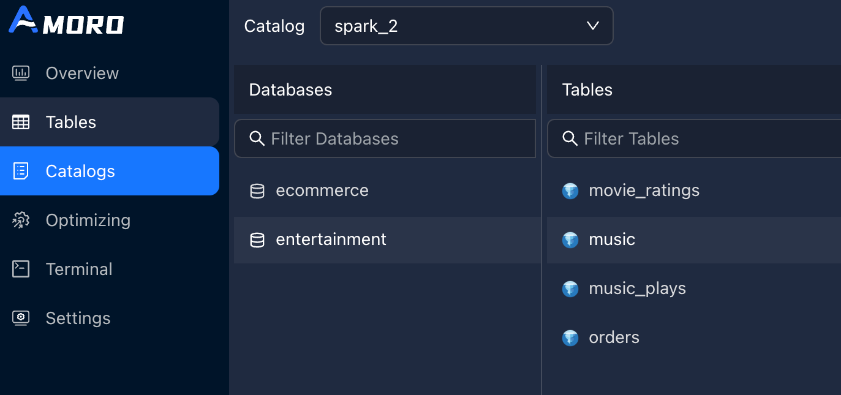
表粒度
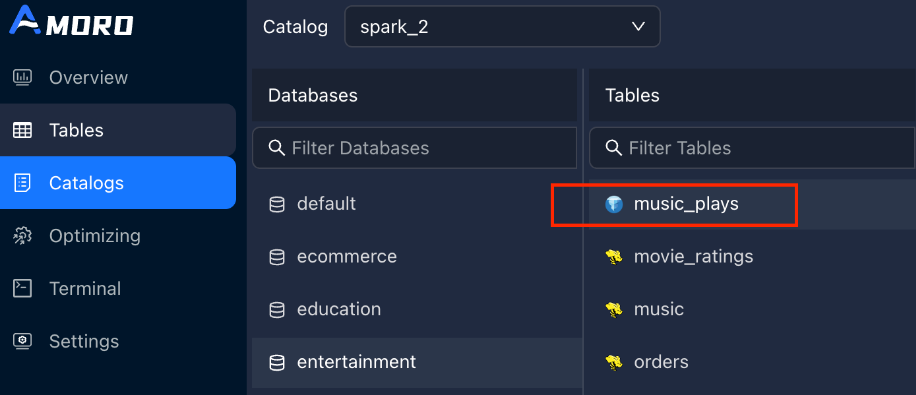
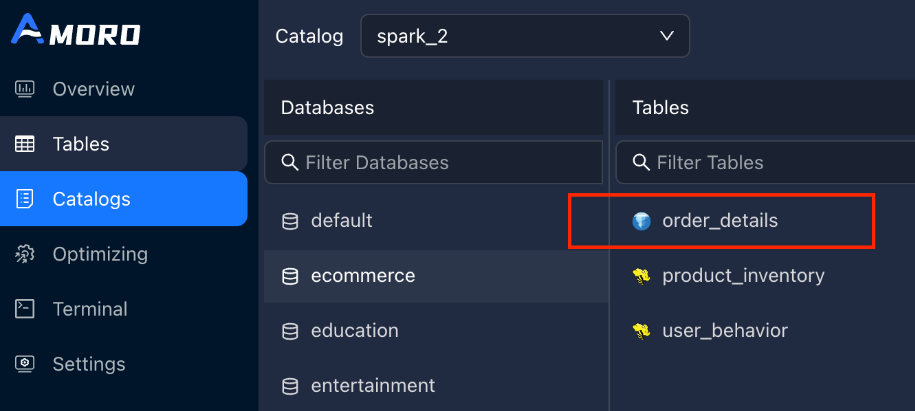
同理,可以使用table-filter对catalog中的表进行过滤,该参数是表级别的过滤,通过正则表达式来控制哪些表在 AMS Dashboard 中可见、可以被治理。比如设置:table-filter = (ecommerce\.order_details)|(entertainment\.music_plays),其他黄色标识的表会被隐藏。
问题4:
希望借这次升级机会进行资源拆分,针对治理频繁地大表给一个单独的组,其他稳定治理频率的表放在默认组。
这种场景可以通过self-optimizing.group 参数实现,在表的粒度指定该表用哪个Optimizer Group(优化器资源组)来执行自优化任务,同一optimizer group 下的表共享优化器资源。
配置方式:
-- 在表级别配置
ALTER TABLE spark_catalog.iceberg_1 SET TBLPROPERTIES (
'self-optimizing.group' = 'spark'
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号