02-python基础之数据类型详解
进制
1. 基本概念:位是最基本的单位,一个字节由8个位组成
如下所示:
0 1010010100101001
# 0表示1位
01010010 100101001
#010100101表示字节
2. 字符编码和字节(位)的关系
01010010 01010010 +
Unicode(也称为万国码):为了支持更多的语言:用至少2个字节(即至少16位)来表示一个字符
UTF-8: 自己对应关系(3个字节24位表示一个汉字)
李 ----> 01010010 01010010 01010010
GBK: 自己对应关系(2个字节16位表示一个汉字)
李 ----> 11010010 01110011
3. 二级制、八进制、十进制、十六进制的介绍
二进制:0 1 10 11 100 101
八进制:0 1 2 3 4 5 6 7 10
十进制:0 1 2 3 4 5 6 7 8 9 10 ...... 15
十六进制:0 1 2 3 4 5 6 7 8 9 A B C D E F 10
理解:分别是逢二进一、逢八进一、逢十进一、逢十六进一,只不过我们对逢十进一比较熟悉。
十进制转二进制:

二进制转十进制:

以上参考:http://www.360doc.com/content/11/0308/14/5327079_99222581.shtml
4. 进制和文件存储及读取的关系
a. 计算机硬盘上保存数据都是二进制数据(0和1),例如:01010101010101010101
b. 读取数据的时候把二进制的数据根据指定的字符编码转换成对应的信息:01010101010101010101 -> 根据指定的字符编码(UTF-8) --> 好好学习,吃饱不饿。
c. 肉眼看到的结果:
-1 如b中所述,根据指定的字符编码,看到转换完成的字符串
-2 如果没有指定,默认展示以十六进制展示的01010101(十六进制最节省空间,要标识一长串的二进制01,十六进制用的位数最少)
举例:
转换文本到二进制(http://www.5ixuexiwang.com/str/binary.php)
美 -----> 111111110001110
转换文本到十六进制(http://www.5ixuexiwang.com/str/hex.php)
美 -----> 7f8e
十六进制到二进制(http://tool.lu/hexconvert/)
7f8e -----> 111111110001110
第二个 + 第三个 = 第一个
下面的例子,打印中文却输出了3个十六进制的字符。
root@dx:/tmp# cat aa
美
root@dx-:/tmp# python
Python 2.7.3 (default, Feb 27 2014, 19:58:35)
[GCC 4.6.3] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
>>> f=open('aa','r') ##
>>> f.read()
'\xe7\xbe\x8e\n'
>>>
原因:通过sys.getdefaultencoding() 可知此时默认的编码是ascii,理论上应该打印二进制0和1 ,但是因为比较显示比长,如果没有指定,默认展示以十六进制展示的01010101(十六进制最节省空间,要标识一长串的二进制01,十六进制用的位数最少),显示3个16进制的字节是因为utf8有自己对应关系(3个字节24位表示一个汉字)
数据类型- 字符串
字符串函数列表:
***********
***********
***********
函数详解:
1. capitalize(self) 字符串首字母大写,自身不变,会生成一个新的值
name = 'alex' # str类的对象 v = name.capitalize() # 自动找到name关联的str类,并执行类中的capitalize方法 print(name) print(v)
执行结果:
alex Alex
2. casefold(self) 将所有大小变小写,casefold更高级,可以将德语...等其他语种的的大写变小写
name = 'AleX' v = name.casefold() # 更高级,德语... print(name) print(v)
执行结果:
AleX alex
3. lower(self) 将所有大小变小写,只支持英文字母的大写变小写
name = 'AleX' v = name.lower() print(v)
执行结果:
alex
4. center(self, width, fillchar=None) 文本居中
# 参数1: 表示总长度
# 参数2:空白处填充的字符(字符长度为1,比如 * 可以 ** 不可以。注意区分字符长度和字节长度)
name = 'alex' v = name.center(20) print(v) v = name.center(20,'#') print(v)
执行结果:
alex ########alex########
5. count(self, sub, start=None, end=None) 表示传入值在字符串中出现的次数
# 参数1: 要查找的值(子序列)
# 参数2: 起始位置(索引)
# 参数3: 结束位置(索引)
# startswith函数和endswith函数也和count函数一样可以加start 和end 参数
# start和end的包含关系:包含start,不包含end(start<< 范围 <end)即:左闭右开
name = "alexasdfdsafsdfasdfaaaaaaaa"
v = name.count('a')
print(v)
v = name.count('df')
print(v)
执行结果:
12 3
带参数的例子
name = "alexasdfdsafsdfasdfaaaaaaaa"
v = name.count('df',12)
print(v)
v = name.count('df',0,15)
print(v)
执行结果:
2 2
6. endswith(self, suffix, start=None, end=None) 是否以xx结尾
name = 'alex'
v1 = name.endswith('ex')
print(v1)
执行结果:
True
7. startswith(self, prefix, start=None, end=None) 是否以xx开头
name = 'alex'
v2 = name.startswith('al')
print(v2)
执行结果:
True
8.encode(self, encoding='utf-8', errors='strict') 转换成字节
name = "李杰" v1 = name.encode(encoding='utf-8') # 字节类型 print(v1) v2 = name.encode(encoding='gbk') # 字节类型 print(v2)
执行结果:
b'\xe6\x9d\x8e\xe6\x9d\xb0' b'\xc0\xee\xbd\xdc'
备注:
a. print的输出结果:b---------> bytes
b. python3中没有Unicode。??
9. expandtabs(self, tabsize=8) 找到制表符\t,进行替换(包含前面的值)
备注:\n 标识换行符
name = "al\te\tx\nalex\tuu\tkkk" v = name.expandtabs(20) print(v)
执行结果:
al e x alex uu kkk
10. find(self, sub, start=None, end=None)
index(self, sub, start=None, end=None)
rfind(self, sub, start=None, end=None) #从右向左
rindex(self, sub, start=None, end=None) #从右向左
find找到指定子序列的索引位置:不存在返回-1
index找到指定子序列的索引位置:不存在报异常
name = 'alex'
v = name.find('o')
print(v)
v = name.index('o')
print(v)
执行结果:
-1
File "D:/obpy17/day02/s17/day02/s1.py", line 103, in <module>
v = name.index('o')
ValueError: substring not found
11. format(*args, **kwargs) 字符串格式化
format_map(self, mapping) 字符串格式化
print字符串格式化例子:
tpl = "我是:%s;年龄:%s;性别:%s" % ('robin',18,'man') ##注意,robin 和 man 要加引号
print(tpl)
执行结果:
我是:robin;年龄:18;性别:man
format形式一: 固定顺序的传入值给占位符
tpl = "我是:{0};年龄:{1};性别:{2}"
v = tpl.format("李杰",19,'都行')
print(v)
执行结果:
我是:李杰;年龄:19;性别:都行
format形式二:传入key=value给{key}
tpl = "我是:{name};年龄:{age};性别:{gender}"
v = tpl.format(name='李杰',age=19,gender='随意')
print(v)
执行结果:
我是:李杰;年龄:19;性别:随意
format_map形式: 传入的是字典
tpl = "我是:{name};年龄:{age};性别:{gender}"
v = tpl.format_map({'name':"李杰",'age':19,'gender':'中'})
print(v)
执行结果:
我是:李杰;年龄:19;性别:中
12. isalnum(self) 和 isalpha(self) 是否是数字、汉子
name = 'alex8汉子' v1 = name.isalnum() # 数字,字 print(v1) # True v2 = name.isalpha()# 数字 print(v2)# False
执行结果:
True False
13. 判断是否是数字
isdecimal(self) 这个最常用,只有这个才可以转int
isdigit(self)
isnumeric(self)
num = '②' v1 = num.isdecimal() # '123' 认为是Ture v2 = num.isdigit() # '123','②' 认为是Ture v3 = num.isnumeric() # '123','二','②' 认为是Ture print(v1,v2,v3)
执行结果:
False True True
14. isidentifier(self) 判断是否是有效标识符,不会判断关键字(关键字被认为是有效的)
n = 'name' v = n.isidentifier() print(v)
执行结果:
True
15. islower(self) 是否全部是小写
isupper(self) 是否全部是大写
name = "ALEX" v1 = name.islower() print(v1) v2 = name.isupper() print(v2)
执行结果:
False True
16. upper(self) 全部变大写
lower(self) 全部变小写
应用场景:验证码不区分大小写的实现,是通过这两个函数转换到统一的形式
如果用户输入q或者Q则退出:
if chosen.upper() == Q: 变成统一可控制的,然后再比较,节省代码量
pass
name = 'alex' v = name.upper() # lower() print(v)
执行结果:
ALEX
17. isprintable(self) 是否包含隐含的xx(打印不出来的字符比如换行符\n)
name = "钓鱼要钓刀鱼,\n刀鱼要到岛上钓" v = name.isprintable() print(v)
执行结果:
False
18. isspace(self) 是否全部是空格
name = ' ' v = name.isspace() print(v)
执行结果:
True
19. join(self, iterable) 元素拼接(元素字符串) *****
join 可以连接列表,但是不能有666的整数,如:['alex','eric',666] ,for循环拿到的必须要是字符串或者字符!!!!
name = 'alex' v1 = "_".join(name) # 内部循环每个元素 print(v1) name_list = ['海峰','杠娘','李杰','李泉'] v2 = "搞".join(name_list) print(v2)
执行结果:
a_l_e_x 海峰搞杠娘搞李杰搞李泉
20. ljust(self, width, fillchar=None) 左填充
rjust(self, width, fillchar=None) 右填充
center(self, width, fillchar=None) 文本居中填充
name = 'alex' v1 = name.ljust(20,'*') print(v1) v1 = name.rjust(20,'*') print(v1) v3 = name.center(20,'*') print(v3)
执行结果:
alex**************** ****************alex ********alex********
21. maketrans(self, *args, **kwargs) 指定的对应关系
translate(self, table) 根据指定的对应关系,进行翻译
m = str.maketrans('aeiou','12345') # 对应关系
name = "akpsojfasdufasdlkfj8ausdfakjsdfl;kjer09asdf"
print(name)
v = name.translate(m)
print(v)
执行结果:
akpsojfasdufasdlkfj8ausdfakjsdfl;kjer09asdf 1kps4jf1sd5f1sdlkfj815sdf1kjsdfl;kj2r091sdf
22. partition(self, sep) 分割且保留分割符
rpartition(self, sep) 从右边开始分隔,类似于rsplit,默认都是从左向右
split 和 partition 区别:是否保留分隔的元素 应用场景:写计算机器的时候可以用到
content = "李泉SB刘康SB刘一"
v1 = content.partition('SB') # partition
print(v1)
v2 = content.rpartition('SB')
print(v2)
执行结果:
('李泉', 'SB', '刘康SB刘一')
('李泉SB刘康', 'SB', '刘一')
23. replace(self, old, new, count=None) 替换
replace 默认全部替换,可以使用第3个参数指定替换的次数
content = "李泉SB刘康SB刘浩SB刘一"
v1 = content.replace('SB','Love')
print(v1)
v2 = content.replace('SB','Love',1)
print(v2)
执行结果:
李泉Love刘康Love刘浩Love刘一 李泉Love刘康SB刘浩SB刘一
24. 移除空白,\n,\t,或者移除自定义子序列
strip(self, chars=None) #去除左右两边的空格,\n,\t
rstrip(self, chars=None)#去除右边的空格,\n,\t
lstrip(self, chars=None)#去除左边的空格,\n,\t
name = 'alex\t'
print(name)
v1 = name.strip() # 空白,\n,\t
print(v1)
v2 = v1.strip('ex')
print(v2)
执行结果:
alex alex al
25. swapcase(self) 大写转换成小写,同时小写转换成大写
name = "Alex" print(name) v = name.swapcase() print(v)
执行结果:
Alex aLEX
26. zfill(self, width) 填充0(用ljust也可以实现相同的效果)
name = "alex" v = name.zfill(20) print(v)
执行结果:
0000000000000000alex
27. split(self, sep=None, maxsplit=-1) 通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串
rsplit(self, sep=None, maxsplit=-1)
- str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num -- 分割次数。
#!/usr/bin/python3
str = "this is string example....wow!!!"
print (str.split( ))
print (str.split('i',1))
print (str.split('w'))
执行结果:
['this', 'is', 'string', 'example....wow!!!'] ['th', 's is string example....wow!!!'] ['this is string example....', 'o', '!!!']
28. splitlines(self, keepends=None)
默认splitelines参数keepends为False,意思是不保留每行结尾的/n, 而keepends为True时,分割的每 一行里尾部会有/n。
splitlines是按行分割字符串(相当于以换行符进行split),返回值也是个列表。
info = "this is \nstring example....\nwow!!!" v1 = info.splitlines() print(v1) v2 = info.splitlines(keepends=True) print(v2)
执行结果:
['this is ', 'string example....', 'wow!!!'] ['this is \n', 'string example....\n', 'wow!!!']
29. istitle(self) 判断英文字母首字母是否全部全部大写
title(self) 英文字母首字母全部变大写
info = 'this is a title example' print(info) v1 = info.title() print(v1) v2 = v1.istitle() print(v2)
执行结果:
this is a title example This Is A Title Example True
30. 其他以__开头,以__结尾的方法为内部特殊方法,如:__add__
v1 = 'alex' v2 = 'eric' v = v1 + v2 # 执行v1的__add__功能 print(v)
执行结果:
alexeric
31.字符串功能总结:
name = 'alex'
name.upper()
name.lower()
name.split()
name.find()
name.strip()
name.startswith()
name.format()
name.replace()
"alex".join(["aa",'bb'])
#字符串的额外功能:
name = "alex"
name[0]
name[0:3]
name[0:3:2]
len(name)
for循环,每个元素是字符
数据类型- 整数
1. bit_length(self) 给定的整数如果用二进制表示,最少需要几位
age = 4 # 100 print(age.bit_length())
执行结果:
3
2. to_bytes(self, length, byteorder, *args, **kwargs) 获取当前数据的字节表示
age = 15 #二进制:00000000 00001111 十六进制:0f v1 = age.to_bytes(10,byteorder='big') v2 = age.to_bytes(10,byteorder='little') print(v1) print(v2)
执行结果:
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x0f' b'\x0f\x00\x00\x00\x00\x00\x00\x00\x00\x00'
备注:示为十六进制0f为15, little为从右边补0, big为从左边补0
数据类型- 布尔值
在python中如果内容为空,则为False,所以:
v1 = ""
v2 = []
v3 = 0 #非0即为True
v4 = {}
v5 = ()
v6 = False
print(bool(v1))
print(bool(v2))
print(bool(v3))
print(bool(v4))
print(bool(v5))
print(bool(v6))
执行结果:
False
False
False
False
False
False
数据类型- 列表
备注:1,python中定义变量的时候不要用list 、dict关键字。
2,字符串不可变类型,不能修改其中的值,只能创建新的值来使用,元组也是不可变类型。列表是可变类型
1. append(self, p_object) 追加
user_list = ['李泉','刘一','刘康','豆豆','小龙'] # 可变类型
v = user_list.append('aa')
print(v)
user_list.append('刘铭')
print(user_list)
执行结果:
None ['李泉', '刘一', '刘康', '豆豆', '小龙', 'aa', '刘铭']
备注:列表是可变类型所以append是修改自身,so,v返回的是None
2. clear(self) 清空
user_list = ['李泉','刘一','刘康','豆豆','小龙'] # 可变类型 user_list.clear() print(user_list)
结果:
[]
3. copy(self) 拷贝(浅拷贝)
user_list = ['李泉','刘一','刘康','豆豆','小龙'] # 可变类型 v = user_list.copy() print(v) print(user_list)
结果:
['李泉', '刘一', '刘康', '豆豆', '小龙'] ['李泉', '刘一', '刘康', '豆豆', '小龙']
4. count(self, value) 计数
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙'] # 可变类型
v = user_list.count('李泉')
print(v)
结果:
2
5. extend(self, iterable)扩展原列表(传入的参数是列表)
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙'] # 可变类型 user_list.extend(['郭少龙','郭少霞']) print(user_list)
结果:
['李泉', '刘一', '李泉', '刘康', '豆豆', '小龙', '郭少龙', '郭少霞']
6. index(self, value, start=None, stop=None) 查找元素索引,没有则报错
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙'] # 可变类型
v = user_list.index('李海')
print(v)
结果:
Traceback (most recent call last):
File "D:/obpy17/day02/s17/day02/s1.py", line 363, in <module>
v = user_list.index('李海')
ValueError: '李海' is not in list
7. insert(self, index, p_object) 插入元素
- index -- 对象 obj 需要插入的索引位置。
- obj -- 要插入列表中的对象。
aList = [123, 'xyz', 'zara', 'abc'] aList.insert( 3, 2009) print(aList)
结果:
[123, 'xyz', 'zara', 2009, 'abc']
8. pop(self, index=None) 删除元素并且获取元素值(通过索引删除)
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙'] # 可变类型 v = user_list.pop(1) print(v) print(user_list)
结果:
刘一 ['李泉', '李泉', '刘康', '豆豆', '小龙']
9. remove(self, value) 删除元素(通过元素值删除)
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙'] # 可变类型
user_list.remove('刘一')
print(user_list)
结果:
['李泉', '李泉', '刘康', '豆豆', '小龙']
10. reverse(self) 翻转(在原列表操作)
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙'] # 可变类型 user_list.reverse() print(user_list)
结果:
['小龙', '豆豆', '刘康', '李泉', '刘一', '李泉']
11. sort(self, key=None, reverse=False) 排序(欠参数:还可以根据条件排序,传入2+参数 )
nums = [11,22,3,3,9,88] print(nums) #排序,从小到大 nums.sort() print(nums) #排序,从大到小 nums.sort(reverse=True) print(nums)
结果:
[11, 22, 3, 3, 9, 88] [3, 3, 9, 11, 22, 88] [88, 22, 11, 9, 3, 3]
12. del删除,根据所以删除(可以根据索引范围进行批量删除)
aList = [123, 'xyz', 'zara', 'abc'] del aList[0] print(aList) aList = [123, 'xyz', 'zara', 'abc'] del aList[0:3] print(aList)
结果:
['xyz', 'zara', 'abc'] ['abc']
备注:索引范围是左闭右开 python2中的range范围也是左闭右开
# 额外:
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙']
user_list[0] #列表索引获取
user_list[1:5:2] #列表索引范围获取 + 步长
del user_list[3] #del 删除列表值
for i in user_list: #列表循环
print(i)
user_list[1] = '姜日天' #修改至
user_list = ['李泉','刘一','李泉','刘康','豆豆',['日天','日地','泰迪'],'小龙'] #列表可以嵌套列表和字典
数据类型- 元组
备注:元组,不可被修改的列表(不能增加,修改,删除);是不可变类型。
****** 元组最后,加逗号 ****** 例如:li = ('alex',)
1. count(self, value) 获取个数
2. index(self, value, start=None, stop=None)获取第一个值的索引位置
user_tuple = ('alex','eric','seven','alex')
v1 = user_tuple.count('alex')
print(v1)
v2 = user_tuple.index('alex')
print(v2)
结果:
2 0
备注:
元组的元素不能被修改,但是元素内部能被修改
元组的儿子不能被修改,孙子如果是可变的,那么孙子可以修改
user_tuple = ('alex','eric','seven',['陈涛','刘浩','赵芬芬'],'alex')
# user_tuple[0] = 123 #儿子不可以被修改
# user_tuple[3] = [11,22,33] #儿子不可以被修改
user_tuple[3][1] = '刘一' #孙子如果是可变的,那么孙子可以修改
print(user_tuple)
result:
('alex', 'eric', 'seven', ['陈涛', '刘一', '赵芬芬'], 'alex')
#额外:
可循环 & 可通过索引取值
user_tuple = ('alex','eric','seven','alex')
for i in user_tuple:
print(i)
v1 = user_tuple[0]
print(v1)
v2 = user_tuple[0:2]
print(v2)
result:
alex
eric
seven
alex
alex
('alex', 'eric')
需求
1,将字符串'wuxiaoyu' 转换成元组('wuxiaoyu')
>>> a='wuxiaoyu'
>>> type(a)
<type 'str'>
>>> tuple(a)
('w', 'u', 'x', 'i', 'a', 'o', 'y', 'u')
>>> b=[]
>>> b.append(a)
>>> tuple(b)
('wuxiaoyu',)
>>>
字符串、列表、元组相互转化 http://www.cnblogs.com/zknublx/p/6042266.html
数据类型- 字典
备注:字典是无序的。
1. clear(self) 清空
dic = {'k1':'v1','k2':'v2'}
dic.clear()
print(dic)
result:
{}
2. copy(self) 浅拷贝
dic = {'k1':'v1','k2':'v2'}
v = dic.copy()
print(v)
result:
{'k2': 'v2', 'k1': 'v1'}
3. get(self, k, d=None) 根据key获取指定的value,存在则获取,不存在则把参数作为默认的返回值;通过key取值的时候,不存在的时候报错
dic = {'k1':'v1','k2':'v2'}
v = dic.get('k1111',1111)
print(v)
v = dic['k1111']
print(v)
result:
1111
Traceback (most recent call last):
File "D:/obpy17/day02/s17/day02/s1.py", line 546, in <module>
v = dic['k1111']
KeyError: 'k1111'
4. pop(self, k, d=None) 根据key删除,并获取key对应的value值,key不存在则把参数作为默认的返回值
dic = {'k1':'v1','k2':'v2'}
v1 = dic.pop('k1')
print(dic)
print(v1)
v2 = dic.pop('k666',888)
print(v2)
result:
{'k2': 'v2'}
v1
888
备注:通过del dic['k1']的时候也能删除k1和v1,但是如果key不存在,则报错
dic = {'k1':'v1','k2':'v2'}
# v1 = dic.pop('k1')
# print(dic)
# print(v1)
# v2 = dic.pop('k666',888)
# print(v2)
del dic['k1']
print(dic)
del dic['k88']
print(dic)
result:
{'k2': 'v2'}
File "D:/obpy17/day02/s17/day02/s1.py", line 558, in <module>
del dic['k88']
KeyError: 'k88'
5. popitem(self) 随机删除键值对,并获取到删除的键值对(取到的是元组)
方式一:
dic = {'k1':'v1','k2':'v2'}
v = dic.popitem()
print(dic)
print(v)
restult:
{'k2': 'v2'}
('k1', 'v1')
方式二(推荐使用):
dic = {'k1':'v1','k2':'v2'}
k,v = dic.popitem()
print(dic)
print(k,v)
result:
{'k2': 'v2'}
k1 v1
方式三:
dic = {'k1':'v1','k2':'v2'}
v = dic.popitem() # ('k2', 'v2')
print(dic)
print(v[0],v[1])
result:
{'k1': 'v1'}
k2 v2
6. setdefault(self, k, d=None)增加键值对,如果key存在,则不操作
dic = {'k1':'v1','k2':'v2'}
dic.setdefault('k3','v3')
print(dic)
dic.setdefault('k1','1111111')
print(dic)
result:
{'k2': 'v2', 'k3': 'v3', 'k1': 'v1'}
{'k2': 'v2', 'k3': 'v3', 'k1': 'v1'}
7. update(self, E=None, **F) 批量修改
dic = {'k1':'v1','k2':'v2'}
dic.update({'k3':'v3','k1':'v24'})
print(dic)
result:
{'k1': 'v24', 'k2': 'v2', 'k3': 'v3'}
8. fromkeys(*args, **kwargs) 也用作批量修改(类的静态方法,由类直接调用)
dic = {'k1': 'v24', 'k2': 'v2', 'k3': 'v3'}
dic = dict.fromkeys(['k1','k2','k3'],123)
print(dic)
result:
{'k2': 123, 'k1': 123, 'k3': 123}
第二个参数实质是内存地址,如果是可变类型(如列表),改一个key。则所有的都会生效;如果是不可变类型(如字符串),则只有对应的单个值修改。
参数二是字符串:
dic = dict.fromkeys(['k1','k2','k3'],123) dic['k1'] = 'asdfjasldkf' print(dic)
result:
{'k1': 'asdfjasldkf', 'k2': 123, 'k3': 123}
参数二是列表:
dic = dict.fromkeys(['k1','k2','k3'],[123,])
# {
# k1: 123, # [1,2]
# k2: 123, # [1,]
# k3: 123, # [1,]
# }
dic['k1'].append(222)
print(dic)
result:
{'k1': [123, 222], 'k2': [123, 222], 'k3': [123, 222]}
keys(self) 循环键
for k in dic.keys(): print(k)
values(self)循环值
for v in dic.values(): print(v)
items(self)循环键值对
for k,v in dic.items(): print(k,v)
额外:
字典可以嵌套
字典的key,必须是不可变类型(以下的key都支持)
dic = {
'k1': 'v1',
'k2': [1,2,3,],
(1,2): 'lllll',
1: 'fffffffff',
111: 'asdf',
}
print(dic)
result:
{(1, 2): 'lllll', 'k1': 'v1', 111: 'asdf', 1: 'fffffffff', 'k2': [1, 2, 3]}
备注:字典会把key转换成hash值,内部生成表格,第一列是hash值,第二列是真正的值,只有不可变类型才可以被hash,语法检测的时候会递归查,只要有可变类型就不可以作为key
python字典中如何根据value值取对应的key值
In [26]: a = {1:"a",2:"b"}
In [27]: a
Out[27]: {1: 'a', 2: 'b'}
In [28]: list(a.keys())[list(a.values()).index('a')]
Out[28]: 1
参考:https://blog.csdn.net/ywx1832990/article/details/79145576
取出该字典所有的键
key_list = my_dict.keys() 返回的是列表
my_dict = dict(name="lowman", age=45, money=998, hourse=None) key_list = my_dict.keys() print(list(key_list))
输出:
['hourse', 'name', 'age', 'money']
取出字典所有的键,这里其实还有一个方法, 就是使用内置函数set(), 将其转换为集合数据结构. 集合,其实可以理解为只有键的字典:
item = {"name": "lowman", "age": 27}
data = set(item)
print(data)
输出:
{'age', 'name'}
注意,这样输出的是集合类型
取出该字典所有的值
value_list = my_dict.values() 返回的是列表
my_dict = dict(name="lowman", age=45, money=998, hourse=None) value_list = my_dict.values() print(list(value_list))
输出:
[None, 45, 'lowman', 998]
注意:在python2环境中这两个方法返回的是列表,但是在python3环境下返回的却是迭代器,如果希望通过下标直接取到需要的元素,可以通过list()方法将其先转化为列表,再进行取值.
有序字典
参考:https://www.cnblogs.com/lowmanisbusy/p/10257360.html
Python 的基础数据类型中的字典类型分为:无序字典 与 有序字典 两种类型
1.无序字典(普通字典):
my_dict = dict()
my_dict["name"] = "lowman"
my_dict["age"] = 26
my_dict["girl"] = "Tailand"
my_dict["money"] = 80
my_dict["hourse"] = None
for key, value in my_dict.items():
print(key, value)
输出:
money 80 girl Tailand age 26 hourse None name lowman
可以看见,遍历一个普通字典,返回的数据和定义字典时的字段顺序是不一致的。
2.有序字典
import collections my_order_dict = collections.OrderedDict()
my_order_dict["name"] = "lowman"
my_order_dict["age"] = 45
my_order_dict["money"] = 998
my_order_dict["hourse"] = None for key, value in my_order_dict.items(): print(key, value)
输出:
name lowman
age 45
money 998
hourse None
有序字典可以按字典中元素的插入顺序来输出。
注意:
有序字典的作用只是记住元素插入顺序并按顺序输出。如果有序字典中的元素一开始就定义好了,后面没有插入元素这一动作,那么遍历有序字典,其输出结果仍然是无序的,因为缺少了有序插入这一条件,所以此时有序字典就失去了作用,所以有序字典一般用于动态添加并需要按添加顺序输出的时候。
如下面这个列子:
import collections
my_order_dict = collections.OrderedDict(name="lowman", age=45, money=998, hourse=None)
for key, value in my_order_dict.items():
print(key, value)
输出:
hourse None age 45 money 998 name lowman
发现输出还是无序的,因为在定义有序字典的同时也定义了初始值,没有存在按序添加的操作,所以有序字典是没有记录插入字段的顺序,最后遍历时,得到数据的顺序仍然是无序的。
数据类型- 集合
备注:不可重复的列表,集合是可变类型
分类:单集合操作 & 多集合操作
1.difference(self, *args, **kwargs)
v = A.difference(B) 返回值v是在集合A中存在,不在集合B中存在的元素
eg:
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
# 1.s1中存在,s2中不存在
v1 = s1.difference(s2)
print("v1 is %s" % v1)
# 2.s2中存在,s1中不存在
v2 = s2.difference(s1)
print("v2 is %s" % v2)
result:
v1 is {'李泉11', '李泉'}
v2 is {'刘一'}
2. difference_update(self, *args, **kwargs)
v = A.difference_update(B) # 取在A中存在,在B中不存在的值的集合,然后对A清空,然后在重新赋值给A
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
# 取在s1中存在,在s2中不存在的值的集合,然后对s1清空,然后在重新赋值给s1
s1.difference_update(s2)
print(s1)
result:
s1 is {'李泉', '李泉11'}
同理,带_update的都会把方法前的s1重新赋值:
intersection_update(self, *args, **kwargs)
symmetric_difference_update(self, *args, **kwargs)
3. symmetric_difference(self, *args, **kwargs)
v = A.symmetric_difference(B)#
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
#s2中存在,s1中不存在的元素 + s1中存在,s2中不存在的元素
v = s1.symmetric_difference(s2)
print(v)
result:
{'刘一', '李泉', '李泉11'}
4. intersection(self, *args, **kwargs) 交集
v = A.intersection(B) #
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
#s1 和 s2 的交集
v = s1.intersection(s2)
print(v)
result:
{'tony', 'alex', 'eric'}
5. union(self, *args, **kwargs) 并集
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
#s1 和 s2 的交集
v = s1.union(s2)
print(v)
result:
{'tony', 'eric', '李泉11', 'alex', '李泉', '刘一'}
6. discard(self, *args, **kwargs) 移除
s1 = {"alex",'eric','tony','李泉','李泉11'}
s1.discard('alex')
print(s1)
result:
{'李泉11', '李泉', 'eric', 'tony'}
7. update(self, *args, **kwargs) 更新操作,没有则添加,存在则忽略
s1 = {"alex",'eric','tony','李泉','李泉11'}
s1.update({'alex','123123','fff'})
print(s1)
result:
{'eric', '李泉', 'tony', '李泉11', 'alex', 'fff', '123123'}
8. isdisjoint(self, *args, **kwargs) 判断是否有交集
9. issubset(self, *args, **kwargs) 判断是否是子集
10. issuperset(self, *args, **kwargs) 判断是否是父集
11. pop(self, *args, **kwargs)
12. remove(self, *args, **kwargs)
13. add(self, *args, **kwargs)
14. clear(self, *args, **kwargs)
15. copy(self, *args, **kwargs)
备注:
set 不支持index索引取值
但是支持for循环
s1 = {"alex",'eric','tony','李泉','李泉11'}
for i in s1:
print(i)
不能嵌套列表、字典、集合 ,能嵌套元组(除特殊的),也就是说集合的元素是不可变类型。
s1 = {"alex",'eric','tony','李泉','李泉11',(11,22,33)}
for i in s1:
print(i)
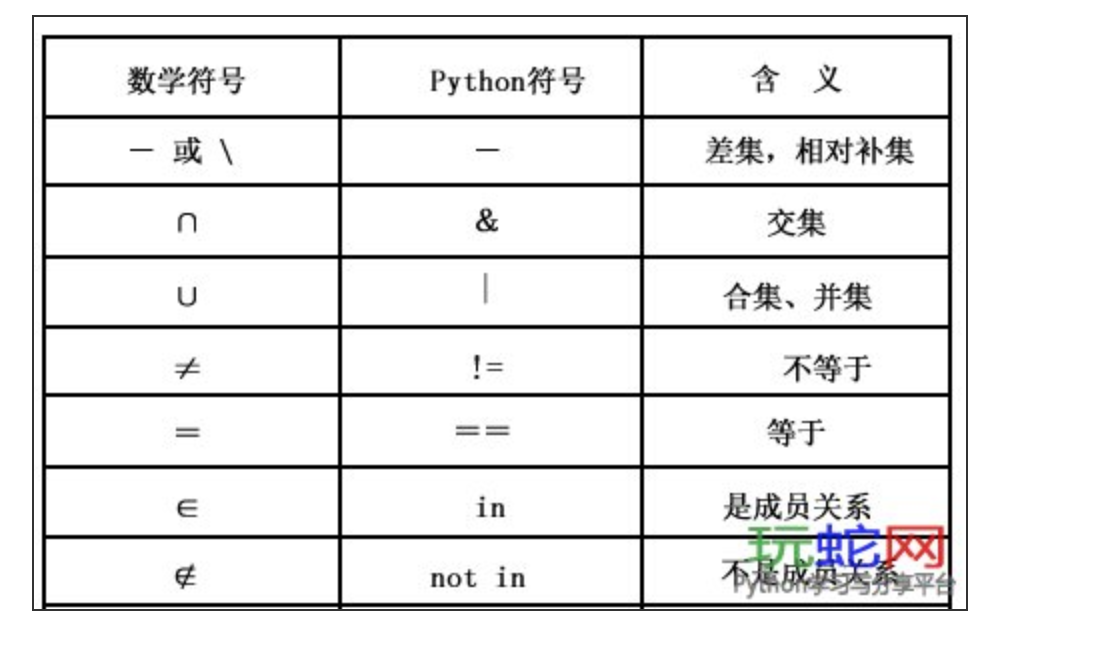

功能补充:range,enumrate
range
1. 请输出1-10
python2.7:用range函数立即生成范围内的所有数字,如:range(1,11) 生成:1,2,3,4,5,6,7,8,9,10
python3:不会立即生成所有数字,而是生成一个迭代器,只有循环迭代的时候,才一个个的生成(优,因为如果数字访问特别特别大的时候节省内存)
for i in range(1,11): #
print(i)
结果:
1 2 3 4 5 6 7 8 9 10
2. 请输出1-10内的奇数
for i in range(1,11,2): #
print(i)
结果:
1 3 5 7 9
3. 输出10到1
for i in range(10,0,-1): #
print(i)
结果:
10 9 8 7 6 5 4 3 2 1
总结:
"""
- 2.7:
range()
xrange() 不会立生成,迭代之后才一个一个创建;2.7 中的xrange 就是 3中的 range
- 3.x
range() 不会立生成,迭代之后才一个一个创建;
- range 有三个参数,起点,结束,步长
"""
练习:
1,循环列表:
li = ['eric','alex','tony']
# range,len,li循环
for i in range(0,len(li)):
ele = li[i]
print(ele)
结果:
eric alex tony
等价于下面的代码:
li = ['eric','alex','tony']
for i in li:
print(i)
2. 输出序号和对应的元素
li = ['eric','alex','tony']
for i in range(0,len(li)):
print(i+1,li[i])
结果:
1 eric 2 alex 3 tony
备注:python中没有被变量引用的值就被回收了(垃圾回收机制)
enumrate 额外生成一列有序的数字
li = ['eric','alex','tony']
for i,ele in enumerate(li,1):
print(i,ele)
v = input('请输入商品序号:')
v = int(v)
item = li[v-1] ##这块要减1,才等于列表的索引
print(item)
结果:
1 eric
2 alex
3 tony
请输入商品序号:3
tony
作业:
1.功能要求:
v = 2000
要求用户输入总资产,例如:2000
显示商品列表,让用户根据序号选择商品,加入购物车
购买,如果商品总额大于总资产,提示账户余额不足,否则,购买成功。
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
num = input('>>>') # 1
num = int(num)
goods[num]['price']
# # ################################### 本周作业 ###################################
# """
# # 1. 练习题两个试卷:readme
# # 2. 购物系统
# - 个人账户,文件: user,pwd,3,余额
# - 商品,文件
# - 查看商品分页显示:
# li = [
# {...}
# {...}
# {...}
# {...}
# {...}
# {...}
# {...}
# ]
# p = int(input('请输入页码:'))
# start = (p -1) * 10
# end = p * 10
# v1 = li[start:end]
# for i v1:
# print(i)
# - 个人购物记录,文件
# 查看:娃娃
# if "al" in "alex":
# pass
# """
备注:
1.输入后去掉左右两边的空格 strip()
2.for line in f: 一行一行读
for line in f.readlines: 一下读到列表中,如果文件大,比较耗内存
3.作业参考:# https://github.com/oldboy123/oldboy_practice/tree/master/day02

 浙公网安备 33010602011771号
浙公网安备 33010602011771号