
基于神经网络的实体识别和关系抽取联合学习
基于神经网络的实体识别和关系抽取联合学习
联合学习(Joint Learning)一词并不是一个最近才出现的术语,在自然语言处理领域,很早就有研究者使用基于传统机器学习的联合模型(Joint Model)来对一些有着密切联系的自然语言处理任务进行联合学习。例如实体识别和实体标准化联合学习,分词和词性标注联合学习等等。最近,研究者们在基于神经网络方法上进行实体识别和关系抽取联合学习,我阅读了一些相关工作,在此和大家一起分享学习。(本文中引用了一些论文作者Suncong Zheng的PPT报告)
1 引言
本文关注的任务是从无结构的文本中抽取实体以及实体之间的关系(实体1-关系-实体2,三元组),这里的关系是我们预定义好的关系类型。例如下图,

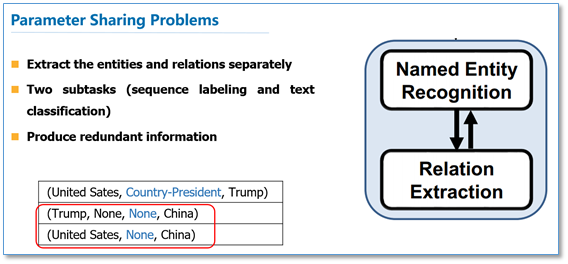
目前有两大类方法,一种是使用流水线的方法(Pipelined Method)进行抽取:输入一个句子,首先进行命名实体识别,然后对识别出来的实体进行两两组合,再进行关系分类,最后把存在实体关系的三元组作为输入。流水线的方法存在的缺点有:1)错误传播,实体识别模块的错误会影响到下面的关系分类性能;2)忽视了两个子任务之间存在的关系,例如图中的例子,如果存在Country-President关系,那么我们可以知道前一个实体必然属于Location类型,后一个实体属于Person类型,流水线的方法没法利用这样的信息。3)产生了没必要的冗余信息,由于对识别出来的实体进行两两配对,然后再进行关系分类,那些没有关系的实体对就会带来多余信息,提升错误率。

理想的联合学习应该如下图:输入一个句子,通过实体识别和关系抽取联合模型,直接得到有关系的实体三元组。这种可以克服上面流水线方法的缺点,但是可能会有更复杂的结构。

2 联合学习
这里我主要关注的基于神经网络方法的联合学习,我把目前的工作主要分为两大类:1)参数共享(Parameter Sharing)和2)标注策略(Tagging Scheme)。主要涉及到下面一些相关工作。

2.1 参数共享
论文《Joint Entity and Relation Extraction Based on A Hybrid Neural Network》,Zheng等人利用共享神经网络底层表达来进行联合学习。具体的,对于输入句子通过共用的word embedding层,然后接双向的LSTM层来对输入进行编码。然后分别使用一个LSTM来进行命名实体识别(NER)和一个CNN来进行关系分类(RC)。相比现在主流的NER模型BiLSTM-CRF模型,这里将前一个预测标签进行了embedding再传入到当前解码中来代替CRF层解决NER中的标签依赖问题。在进行关系分类的时候,需要先根据NER预测的结果对实体进行配对,然后将实体之间的文本使用一个CNN进行关系分类。所以该模型主要是通过底层的模型参数共享,在训练时两个任务都会通过后向传播算法来更新共享参数来实现两个子任务之间的依赖。
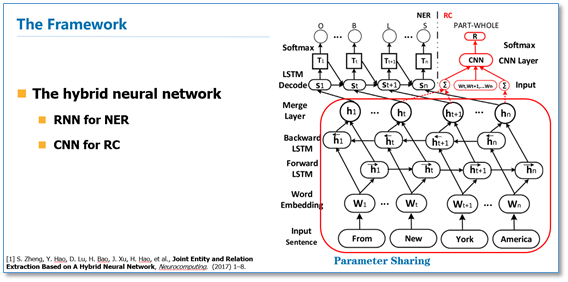
论文《End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures》也是类似的思想,通过参数共享来联合学习。只是他们在NER和RC的解码模型上有所区别。这篇论文Miwa等人同样是通过参数共享,NER使用的是一个NN进行解码,在RC上加入了依存信息,根据依存树最短路径使用一个BiLSTM来进行关系分类。

根据这两篇论文的实验,使用参数共享来进行联合学习比流水线的方法获得了更好的结果在他们的任务上F值约提升了1%,是一种简单通用的方法。论文《A Neural Joint Model for Entity and Relation Extraction from Biomedical Text》将同样的思想用到了生物医学文本中的实体关系抽取任务上。
2.2 标注策略
但是我们可以看到,参数共享的方法其实还是有两个子任务,只是这两个子任务之间通过参数共享有了交互。而且在训练的时候还是需要先进行NER,再根据NER的预测信息进行两两匹配来进行关系分类。仍然会产生没有关系的实体对这种冗余信息。出于这样的动机,Zheng等人在论文《Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme》中提出了一种新的标注策略来进行关系抽取,该论文发表在2017 ACL上,并入选了Outstanding Paper。
他们通过提出了一种新的标注策略把原来涉及到序列标注任务和分类任务的关系抽取完全变成了一个序列标注问题。然后通过一个端对端的神经网络模型直接得到关系实体三元组。

他们提出的这种新的标注策略主要由下图中三部分组成:1)实体中词的位置信息{B(实体开始),I(实体内部),E(实体结尾),S(单个实体)};2)关系类型信息{根据预先定义的关系类型进行编码};3)实体角色信息{1(实体1),2(实体2)}。注意,这里只要不是实体关系三元组内的词全部标签都为"O"。

根据标签序列,将同样关系类型的实体合并成一个三元组作为最后的结果,如果一个句子包含一个以上同一类型的关系,那么就采用就近原则来进行配对。目前这套标签并不支持实体关系重叠的情况。

然后该任务就变成了一个序列标注问题,整体模型如下图。首先使用了一个BiLSTM来进行编码,然后使用了在参数共享中提到的LSTM来进行解码。
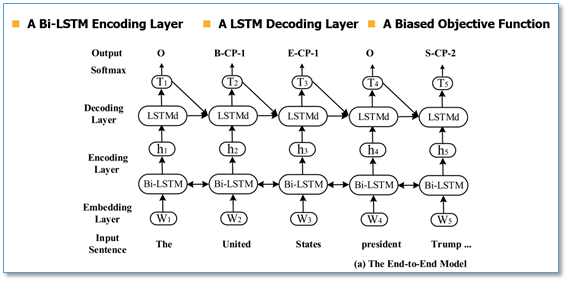
和经典模型不同的地方在于他们使用了一个带偏置的目标函数。当标签为"O"时,就是正常的目标函数,当标签不是"O"时,即涉及到了关系实体标签,则通过α来增大标签的影响。实验结果表明,这个带偏置的目标函数能够更准确的预测实体关系对。

3 总结
基于神经网络的实体识别和关系抽取联合学习主要由两类方法。其中参数共享的方法简单易实现,在多任务学习中有着广泛的应用。Zheng等人提出的新的标注策略,虽然目前还存在一些问题(例如无法识别重叠实体关系),但是给出了一种新的思路,真正的做到了两个子任务合并成了一个序列标注问题,在这套标注策略上也可以进行更多的改进和发展来进一步完善端到端的关系抽取任务。

参考文献
[1] S. Zheng, Y. Hao, D. Lu, H. Bao, J. Xu, H. Hao, et al., Joint Entity and Relation Extraction Based on A Hybrid Neural Network, Neurocomputing. (2017) 1–8.
[2] M. Miwa, M. Bansal, End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures, ACL, (2016).
[3] F. Li, M. Zhang, G. Fu, D. Ji, A Neural Joint Model for Entity and Relation Extraction from Biomedical Text, BMC Bioinformatics. 18 (2017).
[4] S. Zheng, F. Wang, H. Bao, Y. Hao, P. Zhou, B. Xu, Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme, Acl. (2017).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号