deepfakes-FaceSwap使用笔记
安装过程
安装指南网址:https://github.com/deepfakes/faceswap/blob/master/INSTALL.md
需要魔法上网,有些包国内下载太慢了
conda环境
在Anaconda Prompt里,查看所有环境,两个命令都行
conda env list
conda info --envs
查看安装的包
conda list
更换环境,前面的conda不写好像也行
conda activate faceswap

提示no module named cv2
进入相应的环境,安装缺少的包
conda install opencv
提取人脸
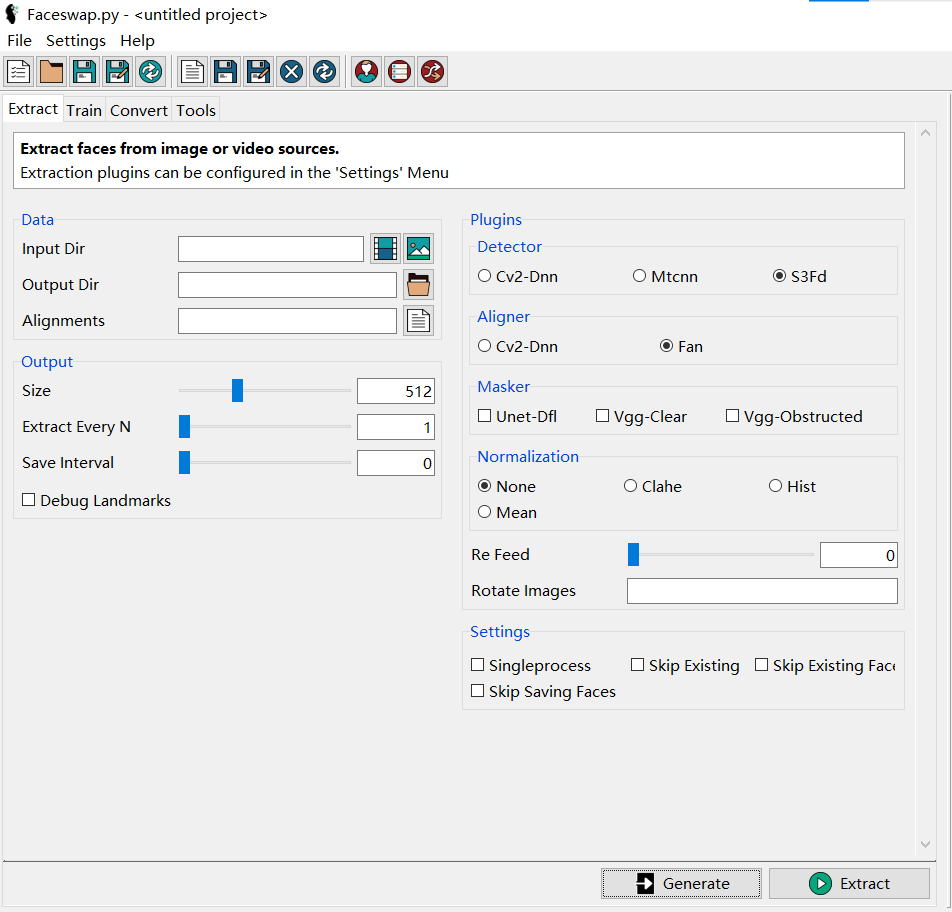
Input Dir可以是视频或者图片文件夹
Output Dir是输出的截取好的人脸图片文件夹
Alignments是对齐文件,用于标注人脸的位置信息,不填的话会默认生成在Input Dir。如果要自定义,需要新建一个.fsa后缀的空文件
下面的Extract Every N是每N张图片截取一张人脸,对视频就是每N帧截取一张人脸。官方建议视频是每半秒或一秒截取一张。比如,60帧的视频,半秒就填30
提取两个人脸的图片。
删除无关图片
提取的人脸图片有的可能不是要进行操作的那个人,比如视频里出现多个人,或者多个人的合照,其他人也会被提取。应该删除无关信息
为了便于操作,可以先进行分类,Data框里的三项都应填入
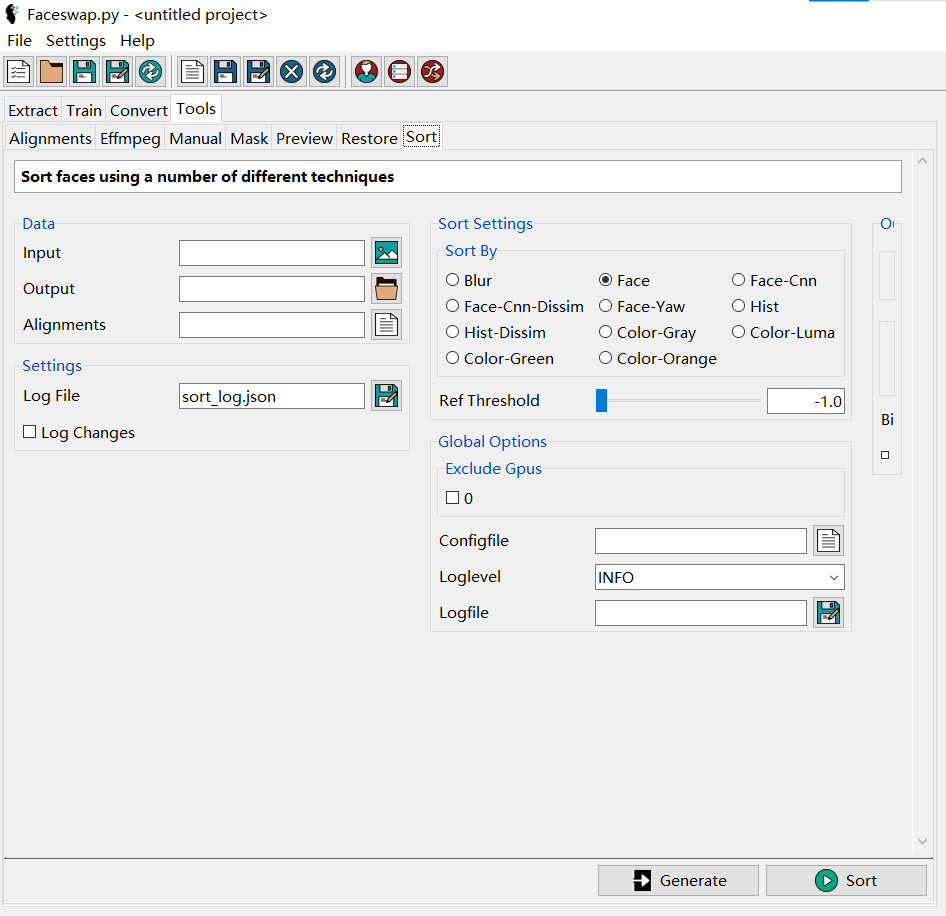
分类之后,将无关的图片文件删除。然后在Tools - Alignments - Job里选择 Remove-Faces,Data框里的Frames Folder不用填,另外两项需要填。完成后,alignments文件也就是.fsa文件会更新,同时会在同目录生成一个备份文件
合并多个alignments
Job选择Merge。Data框里,alignments文件放入一个文件夹,并在Alignments File选择时按Shift或Ctrl选择多个alignments文件。
将所有人脸图片放入一个文件夹,Faces Folder选择该文件夹。Frames Folder不填。合并后会生成一个新的alignments
训练模型
填入Input A/B,以及相应的alignmens文件(在Extract里生成的),然后新建一个模型目录并选择,模型将会存在该目录。显卡比较垃圾的话跑一会就会报错,在Trainer里选择Lightweight。根据预览的图片选择何时停止。我用GTX 1050 2G,训练了一个晚上,loss值看起来已经降不下去了,可能跟我的图片数量太少有关(A:100+张,B:1400+张),生成的视频也还凑合,有时清楚有时模糊。
训练可以随时停止,指向相同的文件夹可以继续接着之前的训练。
注意A是原始的脸,B是要换的脸,不要训练反了。
生成视频
注意这里的alignmens可能和之前Extract出来的不一样。
可以通过ffmpeg将视频每一帧都抽出来,然后对生成的所有图片进行换脸,然后再将帧合成为视频,再将原来的音频合并。
抽取视频的每一帧
ffmpeg -i /path/to/my/video.mp4 /path/to/output/video-frame-%d.png
将帧合并为视频
ffmpeg -r 60 -f image2 -s 1920x1080 -i video-frame-%0d.png -vcodec libx264 -crf 25 -pix_fmt yuv420p test.mp4
%04d 表示用零来填充直到长度为4,i.e 0001…0020…0030…2000 and so on. 如果没有填充,需要相应更改,如 pic%d.png or %d.png
-r 帧率(fps)
-f image2 图像合成视频默认设置
-crf 画质,数值小意味着画质高,通常设置为15-25
-s 分辨率(1920x1080)
-pix_fmt yuv420p 像素格式
test.mp4 输出在当前文件夹,输出结果为test.mp4
video-frame-%0d.png,这里的%0d是对齐长度。
如果使用这种自行抽帧的方法,需要对抽出的所有图片进行Extract,并且Extract Every N设置为1,这里生成的alignments文件可以用于Convert
或者直接在Input Dir里输入视频文件,并对视频文件进行Extract,且Extract Every N设置为1,生成的alignments文件可以用于Convert。当Input Dir里输入视频文件时,Output Dir里生成的还是图片,是已经换过脸的每一帧的图片,仍然需要用ffmpeg进行合并。
说的好像有点乱,总之就是每一帧都应该有一个有alignment,需要先有这个alignments文件才能Convert。
【2021-06-28】实际上是这样,原始的图片被Extract后会生成只有头像的图片以及alignments文件,在Convert时要输入原始图片而不是Extract的头像图片。
conda env备份
1、进入虚拟环境后,输入以下命令进行备份:
conda env export > environment.yaml
该虚拟环境的信息便被保存在了 environment.yaml 文件中
2、重装该环境
conda env create -f environment.yaml
离线备份:
直接在conda的envs目录下找到要备份的环境目录,复制一份目录保存下来。用conda env list查看环境目录
离线恢复安装
conda create --name env_name --clone env_path --offline
参考链接
官方USAGE(简略):https://github.com/deepfakes/faceswap/blob/master/USAGE.md
Extract详细解释:https://forum.faceswap.dev/viewtopic.php?f=5&t=27
其他教程:https://forum.faceswap.dev/app.php/tag/Guide
ffmpeg文档:https://ffmpeg.org/ffmpeg.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号