
如何使用psql中的变量
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《PostgreSQL数据库内核分析》
2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》
3、PostgreSQL数据库仓库链接,点击前往
4、日本著名PostgreSQL数据库专家 铃木启修 网站主页,点击前往
5、参考书籍:《PostgreSQL中文手册》
6、参考书籍:《PostgreSQL指南:内幕探索》,点击前往
7、参考书籍:《事务处理 概念与技术》
8、Variables in psql, how to use them?,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
5、本文内容基于PostgreSQL 16.0源码开发而成

文章快速说明索引
学习目标:
做数据库内核开发久了就会有一种 少年得志,年少轻狂 的错觉,然鹅细细一品觉得自己其实不算特别优秀 远远没有达到自己想要的。也许光鲜的表面掩盖了空洞的内在,每每想到于此,皆有夜半临渊如履薄冰之感。为了睡上几个踏实觉,即日起 暂缓其他基于PostgreSQL数据库的兼容功能开发,近段时间 将着重于学习分享Postgres的基础知识和实践内幕。
学习内容:(详见目录)
1、深入理解PostgreSQL数据库如何使用psql中的变量
学习时间:
2024-02-28 10:07:27 星期三
学习产出:
1、PostgreSQL数据库基础知识回顾 1个
2、CSDN 技术博客 1篇
3、PostgreSQL数据库内核深入学习
注:下面我们所有的学习环境是Centos8+PostgreSQL16.0+Oracle19C+MySQL8.0
postgres=# select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 16.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-21), 64-bit
(1 row)
postgres=#
#-----------------------------------------------------------------------------#
SQL> select * from v$version;
BANNER Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
BANNER_FULL Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production Version 19.17.0.0.0
BANNER_LEGACY Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
CON_ID 0
#-----------------------------------------------------------------------------#
mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.27 |
+-----------+
1 row in set (0.06 sec)
mysql>
参数使用背景说明
在开始之前,需要先把log_checkpoints关掉,否则 如下:
postgres=# 2024-02-28 23:17:16.840 PST [28326] LOG: checkpoint starting: time
2024-02-28 23:17:18.365 PST [28326] LOG: checkpoint complete: wrote 18 buffers (0.1%); 0 WAL file(s) added, 0 removed, 0 recycled; write=1.519 s, sync=0.002 s, total=1.525 s; sync files=10, longest=0.002 s, average=0.001 s; distance=27 kB, estimate=27 kB; lsn=0/14ED1C0, redo lsn=0/14ED188
postgres=#
postgres=# show log_checkpoints;
log_checkpoints
-----------------
on
(1 row)
postgres=#
app-psql,PostgreSQL 的数据库客户端,从始至终都支持变量。这些可以让您以安全的方式编写某些查询,即使从outside获取参数也是如此。
要使用它们,我们首先需要知道如何设置它们。为此,我们有多种方法:
- 您可以将变量作为参数传递给 psql:
psql -v var=value(可以使用–set=x=y或–variable=x=y代替-v x=y) - 您可以使用
\set元命令设置它们 - 您还可以使用
\gset将它们设置为查询中的值,可以选择使用前缀
要使用它们,通常使用 :var 查询或元命令。但有时您可能需要对其执行其他操作。那么,举个例子吧。 您可以做的最简单的事情是:
[postgres@localhost:~/test/bin]$ ./psql -X -v a=b
psql (16.0)
Type "help" for help.
postgres=# \echo VALUE OF var-a IS :a
VALUE OF var-a IS b
postgres=#
这很简单。 当然,如果您想通过内部复杂的事物传递值,则必须考虑引用 shell 中的事物。例如,如果我想将 hubert depesz lubaczewski 作为变量传递,它实际上不会轻易工作,因为:
[postgres@localhost:~/test/bin]$ ./psql -X -v a=hubert depesz lubaczewski
2024-02-29 01:46:25.498 PST [30813] FATAL: role "lubaczewski" does not exist
psql: error: connection to server on socket "/tmp/.s.PGSQL.5432" failed: FATAL: role "lubaczewski" does not exist
[postgres@localhost:~/test/bin]$
这只是因为参数以空格分隔。 为了将整个字符串作为值传递,我需要引用它。 例如这样:
[postgres@localhost:~/test/bin]$ ./psql -X -v a='hubert depesz lubaczewski'
psql (16.0)
Type "help" for help.
postgres=# \echo VALUE OF var-a IS :a
VALUE OF var-a IS hubert depesz lubaczewski
postgres=#
对于更复杂的值(例如,同时包含"和'字符),您可能需要将值放入文件中并加载它,例如使用以下内容:
[postgres@localhost:~/test/bin]$ ./psql -X -v a="$( cat file.txt )"
cat: file.txt: 没有那个文件或目录
psql (16.0)
Type "help" for help.
postgres=# \echo VALUE OF var-a IS :a
VALUE OF var-a IS
postgres=# \q
[postgres@localhost:~/test/bin]$ echo 1 > file.txt
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ ./psql -X -v a="$( cat file.txt )"
psql (16.0)
Type "help" for help.
postgres=# \echo VALUE OF var-a IS :a
VALUE OF var-a IS 1
postgres=# \q
[postgres@localhost:~/test/bin]$
现在,让我们使用变量进行查询。假设我想从 t 表中选择前 n 行,其中 n 和 t 都作为变量给出。所以,我可以想象有一个名为 show.sql 的 sql 文件,其中包含:
[postgres@localhost:~/test/bin]$ echo 'SELECT * FROM :t LIMIT :n;' > SHOW.sql
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ ./psql -X -v n=5 -v t=pg_depend -f SHOW.sql
classid | objid | objsubid | refclassid | refobjid | refobjsubid | deptype
---------+-------+----------+------------+----------+-------------+---------
1247 | 12002 | 0 | 1259 | 12000 | 0 | i
1247 | 12001 | 0 | 1247 | 12002 | 0 | i
2618 | 12003 | 0 | 1259 | 12000 | 0 | i
1247 | 12007 | 0 | 1259 | 12005 | 0 | i
1247 | 12006 | 0 | 1247 | 12007 | 0 | i
(5 rows)
[postgres@localhost:~/test/bin]$
这在理论上是很棒的。 但也存在问题。基本上,变量的值直接内联到查询。 因此,我放在那里的任何内容都将被传递给查询。 直接,没有任何改变。
这意味着我可以使用它进行 sql 注入:
[postgres@localhost:~/test/bin]$ ./psql -X -v n="1; select version()" -v t=pg_depend -f SHOW.sql
classid | objid | objsubid | refclassid | refobjid | refobjsubid | deptype
---------+-------+----------+------------+----------+-------------+---------
1247 | 12002 | 0 | 1259 | 12000 | 0 | i
(1 row)
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 16.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-21), 64-bit
(1 row)
[postgres@localhost:~/test/bin]$
这是第一个问题。 其次更奇怪——使用这种方法你无法从某些表中选择数据。
例如,让我们制作表:
[postgres@localhost:~/test/bin]$ ./psql
psql (16.0)
Type "help" for help.
postgres=# \d
Did not find any relations.
postgres=# CREATE TABLE "do it" AS SELECT generate_series(1,5) i;
SELECT 5
postgres=#
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+-------+-------+----------
public | do it | table | postgres
(1 row)
postgres=# \q
[postgres@localhost:~/test/bin]$
如果我用 t="do it" 运行我的 show.sql,我会得到:
[postgres@localhost:~/test/bin]$ ./psql -X -v n="1" -v t="do it" -f SHOW.sql
2024-02-29 02:01:48.269 PST [31587] ERROR: syntax error at or near "do" at character 15
2024-02-29 02:01:48.269 PST [31587] STATEMENT: SELECT * FROM do it LIMIT 1;
psql:SHOW.sql:1: ERROR: syntax error at or near "do"
LINE 1: SELECT * FROM do it LIMIT 1;
^
[postgres@localhost:~/test/bin]$
这是因为这些值再次被直接内联。 对此我们能做些什么呢? 使用正确的引号。
使用以下语法之一来执行此操作:
:'variable'
:"variable"
首先会将值放入查询中,但引用它,就好像应该是正常的文字值一样。 即使该值已经包含 ' 字符!
第二种语法将引用变量,就好像它是标识符一样。知道了这一点,我现在可以将我的 show.sql 更改为:
[postgres@localhost:~/test/bin]$ rm SHOW.sql -rf
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ vim SHOW.sql
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ cat SHOW.sql
SELECT * FROM :"t" LIMIT :'n';
[postgres@localhost:~/test/bin]$ ./psql -X -v n="1" -v t="do it" -f SHOW.sql
i
---
1
(1 row)
[postgres@localhost:~/test/bin]$
此外,我无法进行 sql 注入:
[postgres@localhost:~/test/bin]$ ./psql -X -v n="1; select version()" -v t=pg_depend -f SHOW.sql
2024-02-29 02:08:31.575 PST [32133] ERROR: invalid input syntax for type bigint: "1; select version()" at character 33
2024-02-29 02:08:31.575 PST [32133] STATEMENT: SELECT * FROM "pg_depend" LIMIT '1; select version()';
psql:SHOW.sql:1: ERROR: invalid input syntax for type bigint: "1; select version()"
LINE 1: SELECT * FROM "pg_depend" LIMIT '1; select version()';
^
[postgres@localhost:~/test/bin]$
一开始我提到你可以使用 \gset。 这太神奇了,而且非常有用。基本上,您可以获取任何查询,并将其输出放入变量中。 例如:
[postgres@localhost:~/test/bin]$ ./psql
psql (16.0)
Type "help" for help.
postgres=# SELECT now(), version() \gset
postgres=#
postgres=# \echo now IS [:now], AND pg version IS :version
now IS [2024-02-29 02:12:52.358736-08], AND pg version IS PostgreSQL 16.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-21), 64-bit
postgres=#
\gset 获取可选参数,该参数将作为将生成的变量名称的前缀:
postgres=# SELECT * FROM pg_am LIMIT 1;
oid | amname | amhandler | amtype
-----+--------+----------------------+--------
2 | heap | heap_tableam_handler | t
(1 row)
postgres=# SELECT * FROM pg_am LIMIT 1 \gset xxx_
postgres=#
postgres=# \echo :xxx_amhandler
heap_tableam_handler
postgres=#
如果您想从许多查询中获取结果并将它们存储为变量,这会很有帮助,因此您可以随时为它们的名称添加前缀以避免发生冲突。
但是,如果您编写一个返回多于 1 行的查询,会发生什么情况?
postgres=# SELECT * FROM pg_am LIMIT 2 \gset am_
more than one row returned for \gset
postgres=#
它会立即失败,所以你知道发生了什么。
使用变量,您可以轻松地从文件加载更大的值,并将其用作普通文本值,即使它有多行或奇怪的字符:
## 时刻需要注意大小写:
[postgres@localhost:~/test/bin]$ cat SHOW.sql
SELECT * FROM :"t" LIMIT :'n';
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ ./psql
psql (16.0)
Type "help" for help.
postgres=# \set SHOW `cat SHOW.sql`
postgres=#
postgres=# SELECT :'show';
2024-02-29 02:18:02.976 PST [32674] ERROR: syntax error at or near ":" at character 8
2024-02-29 02:18:02.976 PST [32674] STATEMENT: SELECT :'show';
ERROR: syntax error at or near ":"
LINE 1: SELECT :'show';
^
postgres=# SELECT :'SHOW';
?column?
--------------------------------
SELECT * FROM :"t" LIMIT :'n';
(1 row)
postgres=#
如何在函数中使用这些变量,如 SQL、pl/PgSQL 函数或 DO 块。这些人试图做这样的事情,但这立即失败:
postgres=# \df
List of functions
Schema | Name | Result data type | Argument data types | Type
--------+------+------------------+---------------------+------
(0 rows)
postgres=# CREATE OR REPLACE FUNCTION testit() RETURNS INT8 AS $$
postgres$# DECLARE
postgres$# v_int INT4;
postgres$# BEGIN
postgres$# SELECT COUNT(*) INTO v_int FROM pg_class WHERE relkind = :'kind';
postgres$# RETURN v_int;
postgres$# END;
postgres$# $$ LANGUAGE plpgsql;
2024-02-29 18:34:35.179 PST [7101] ERROR: syntax error at or near ":" at character 147
2024-02-29 18:34:35.179 PST [7101] STATEMENT: CREATE OR REPLACE FUNCTION testit() RETURNS INT8 AS $$
DECLARE
v_int INT4;
BEGIN
SELECT COUNT(*) INTO v_int FROM pg_class WHERE relkind = :'kind';
RETURN v_int;
END;
$$ LANGUAGE plpgsql;
ERROR: syntax error at or near ":"
LINE 5: ...T COUNT(*) INTO v_int FROM pg_class WHERE relkind = :'kind';
^
postgres=#
问题是,psql 在将查询传递给 postgresql 之前处理变量,并且它不能只替换部分字符串 - 整个函数体是一个字符串,因此不能通过值替换来修改它。
解决这个问题的方法是对函数进行参数化:
postgres=# CREATE OR REPLACE FUNCTION testit(IN p_relkind TEXT) RETURNS INT8 AS $$
postgres$# DECLARE
postgres$# v_int INT4;
postgres$# BEGIN
postgres$# SELECT COUNT(*) INTO v_int FROM pg_class WHERE relkind = p_relkind;
postgres$# RETURN v_int;
postgres$# END;
postgres$# $$ LANGUAGE plpgsql;
CREATE FUNCTION
postgres=#
postgres=# \set relkind r
postgres=#
postgres=# SELECT * from testit(:'relkind');
testit
--------
69
(1 row)
postgres=#
对于 DO 块,情况有点复杂,因为它们没有参数。 在这种情况下,我可以使用以下方法滥用/使用配置系统:
postgres=# SET depesz.some_name = :'relkind';
SET
postgres=#
然后在 DO 块中,使用 current_setting('depesz.some_name')。如下:
postgres=# select current_setting('depesz.some_name');
current_setting
-----------------
r
(1 row)
postgres=#
但需要注意的是,您不能在 psql -c ... 中使用 psql 变量。 如果你尝试,你会得到错误:
[postgres@localhost:~/test/bin]$ ./psql -X -v a=b -c "select :'a'"
2024-02-29 18:41:03.823 PST [7496] ERROR: syntax error at or near ":" at character 8
2024-02-29 18:41:03.823 PST [7496] STATEMENT: select :'a'
ERROR: syntax error at or near ":"
LINE 1: select :'a'
^
[postgres@localhost:~/test/bin]$
如果你想将变量传递给简单的东西,只需使用重定向:
[postgres@localhost:~/test/bin]$ ./psql -X -v a=b <<< "select :'a'"
?column?
----------
b
(1 row)
[postgres@localhost:~/test/bin]$
或文件,就像我在上面的示例中多次所做的那样,例如:psql -X -v n=5 -v t=pg_depend -f show.sql。
最后,一点提示。 虽然您可以使用 as 查询的一部分,但您也可以使用它们来代替查询。
例如,我的 ~/.psqlrc 中有这么长的一行:
\set replag 'SELECT format(''%s : Last TXN: %s, lag: %s'', now()::timestamp(0), pg_last_xact_replay_timestamp()::timestamp(0), (now() - pg_last_xact_replay_timestamp())::INTERVAL(3));'
[postgres@localhost:~/test/bin]$ vim ~/.psqlrc
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ cat ~/.psqlrc
\set replag 'SELECT format(''%s : Last TXN: %s, lag: %s'', now()::timestamp(0), pg_last_xact_replay_timestamp()::timestamp(0), (now() - pg_last_xact_replay_timestamp())::INTERVAL(3));'
[postgres@localhost:~/test/bin]$
多亏了这一点,在 psql 中,我可以简单地输入 :replag 并从当前服务器获取复制延迟:
=$ :replag
format
════════════════════════════════════════════════════════════════════════
2023-05-28 13:49:59 : LAST TXN: 2023-05-28 13:49:59, lag: 00:00:00.064
(1 ROW)
## 因为我这里没有做主备,如下:
postgres=# :replag
format
-----------------------------------------
2024-02-29 18:49:22 : Last TXN: , lag:
(1 row)
postgres=#
源码解析内部实现
[postgres@localhost:~/test/bin]$ ./psql --help
psql is the PostgreSQL interactive terminal.
Usage:
psql [OPTION]... [DBNAME [USERNAME]]
General options:
-c, --command=COMMAND run only single command (SQL or internal) and exit
-d, --dbname=DBNAME database name to connect to (default: "postgres")
-f, --file=FILENAME execute commands from file, then exit
-l, --list list available databases, then exit
-v, --set=, --variable=NAME=VALUE
set psql variable NAME to VALUE
(e.g., -v ON_ERROR_STOP=1)
-V, --version output version information, then exit
-X, --no-psqlrc do not read startup file (~/.psqlrc)
-1 ("one"), --single-transaction
execute as a single transaction (if non-interactive)
-?, --help[=options] show this help, then exit
--help=commands list backslash commands, then exit
--help=variables list special variables, then exit
Input and output options:
-a, --echo-all echo all input from script
-b, --echo-errors echo failed commands
-e, --echo-queries echo commands sent to server
-E, --echo-hidden display queries that internal commands generate
-L, --log-file=FILENAME send session log to file
-n, --no-readline disable enhanced command line editing (readline)
-o, --output=FILENAME send query results to file (or |pipe)
-q, --quiet run quietly (no messages, only query output)
-s, --single-step single-step mode (confirm each query)
-S, --single-line single-line mode (end of line terminates SQL command)
Output format options:
-A, --no-align unaligned table output mode
--csv CSV (Comma-Separated Values) table output mode
-F, --field-separator=STRING
field separator for unaligned output (default: "|")
-H, --html HTML table output mode
-P, --pset=VAR[=ARG] set printing option VAR to ARG (see \pset command)
-R, --record-separator=STRING
record separator for unaligned output (default: newline)
-t, --tuples-only print rows only
-T, --table-attr=TEXT set HTML table tag attributes (e.g., width, border)
-x, --expanded turn on expanded table output
-z, --field-separator-zero
set field separator for unaligned output to zero byte
-0, --record-separator-zero
set record separator for unaligned output to zero byte
Connection options:
-h, --host=HOSTNAME database server host or socket directory (default: "local socket")
-p, --port=PORT database server port (default: "5432")
-U, --username=USERNAME database user name (default: "postgres")
-w, --no-password never prompt for password
-W, --password force password prompt (should happen automatically)
For more information, type "\?" (for internal commands) or "\help" (for SQL
commands) from within psql, or consult the psql section in the PostgreSQL
documentation.
Report bugs to <pgsql-bugs@lists.postgresql.org>.
PostgreSQL home page: <https://www.postgresql.org/>
[postgres@localhost:~/test/bin]$
下面我将详细介绍一下上面的源码实现,如下:
.psqlrc是否加载
-X, --no-psqlrc do not read startup file (~/.psqlrc)
// src/bin/psql/startup.c
...
if (options.list_dbs)
{
int success;
if (!options.no_psqlrc)
process_psqlrc(argv[0]); // here
success = listAllDbs(NULL, false);
PQfinish(pset.db);
exit(success ? EXIT_SUCCESS : EXIT_FAILURE);
}
...
#ifndef WIN32
#define SYSPSQLRC "psqlrc"
#define PSQLRC ".psqlrc"
#else
#define SYSPSQLRC "psqlrc"
#define PSQLRC "psqlrc.conf"
#endif
/*
* Load .psqlrc file, if found.
*/
static void
process_psqlrc(char *argv0)
{
char home[MAXPGPATH];
char rc_file[MAXPGPATH];
char my_exec_path[MAXPGPATH];
char etc_path[MAXPGPATH];
char *envrc = getenv("PSQLRC");
if (find_my_exec(argv0, my_exec_path) < 0)
pg_fatal("could not find own program executable");
get_etc_path(my_exec_path, etc_path);
snprintf(rc_file, MAXPGPATH, "%s/%s", etc_path, SYSPSQLRC);
process_psqlrc_file(rc_file);
if (envrc != NULL && strlen(envrc) > 0)
{
/* might need to free() this */
char *envrc_alloc = pstrdup(envrc);
expand_tilde(&envrc_alloc);
process_psqlrc_file(envrc_alloc);
}
else if (get_home_path(home))
{
snprintf(rc_file, MAXPGPATH, "%s/%s", home, PSQLRC);
process_psqlrc_file(rc_file);
}
}
// 真正的处理函数,如下:
static void
process_psqlrc_file(char *filename)
{
char *psqlrc_minor,
*psqlrc_major;
#if defined(WIN32) && (!defined(__MINGW32__))
#define R_OK 4
#endif
psqlrc_minor = psprintf("%s-%s", filename, PG_VERSION);
psqlrc_major = psprintf("%s-%s", filename, PG_MAJORVERSION);
/* check for minor version first, then major, then no version */
// 首先检查小版本,然后检查大版本,然后检查无版本
if (access(psqlrc_minor, R_OK) == 0)
(void) process_file(psqlrc_minor, false);
else if (access(psqlrc_major, R_OK) == 0)
(void) process_file(psqlrc_major, false);
else if (access(filename, R_OK) == 0)
(void) process_file(filename, false);
free(psqlrc_minor);
free(psqlrc_major);
}
变量设置及清除 -v
-v, --set=, --variable=NAME=VALUE
set psql variable NAME to VALUE
(e.g., -v ON_ERROR_STOP=1)
// src/bin/psql/startup.c
{"set", required_argument, NULL, 'v'},
{"variable", required_argument, NULL, 'v'},
...
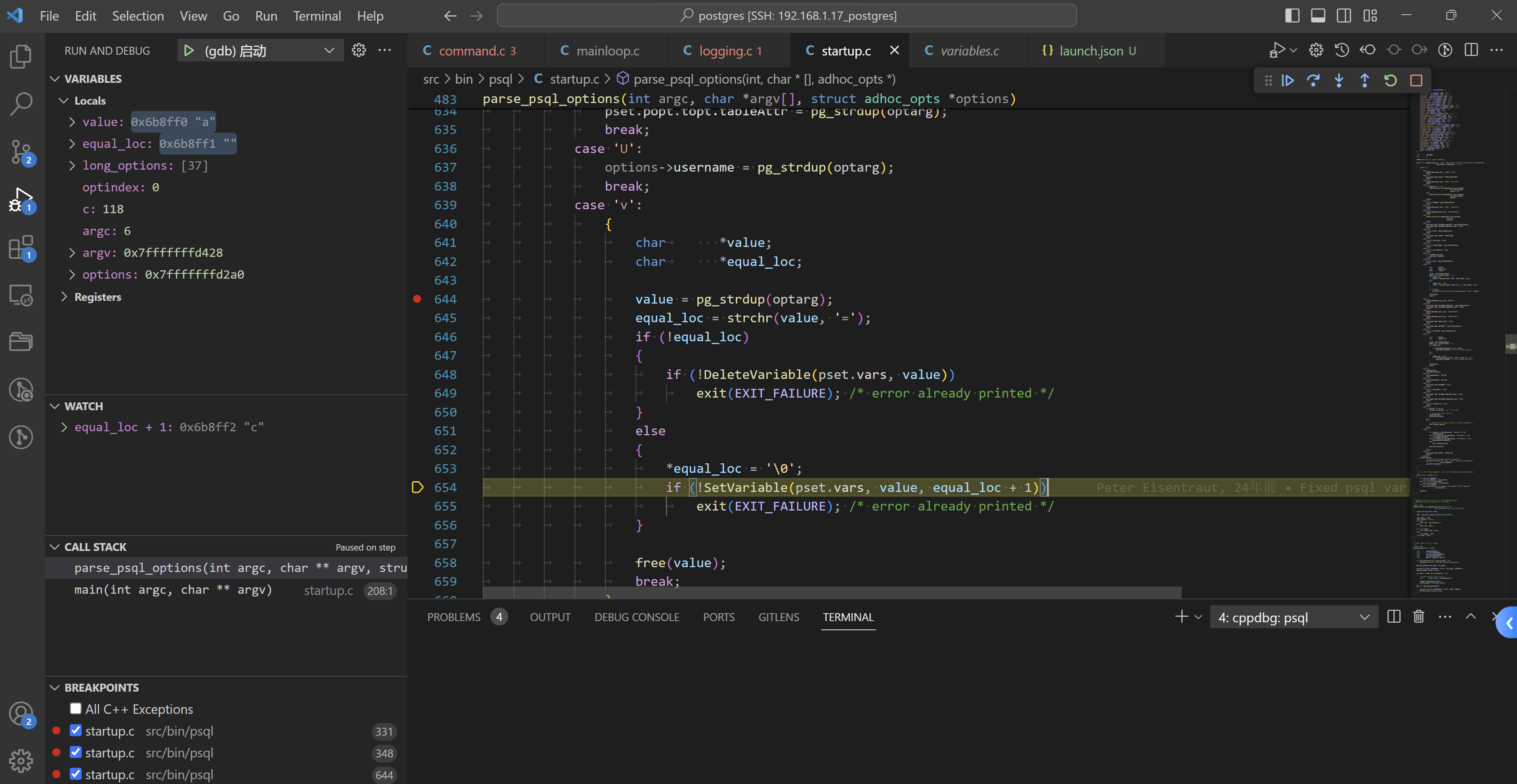
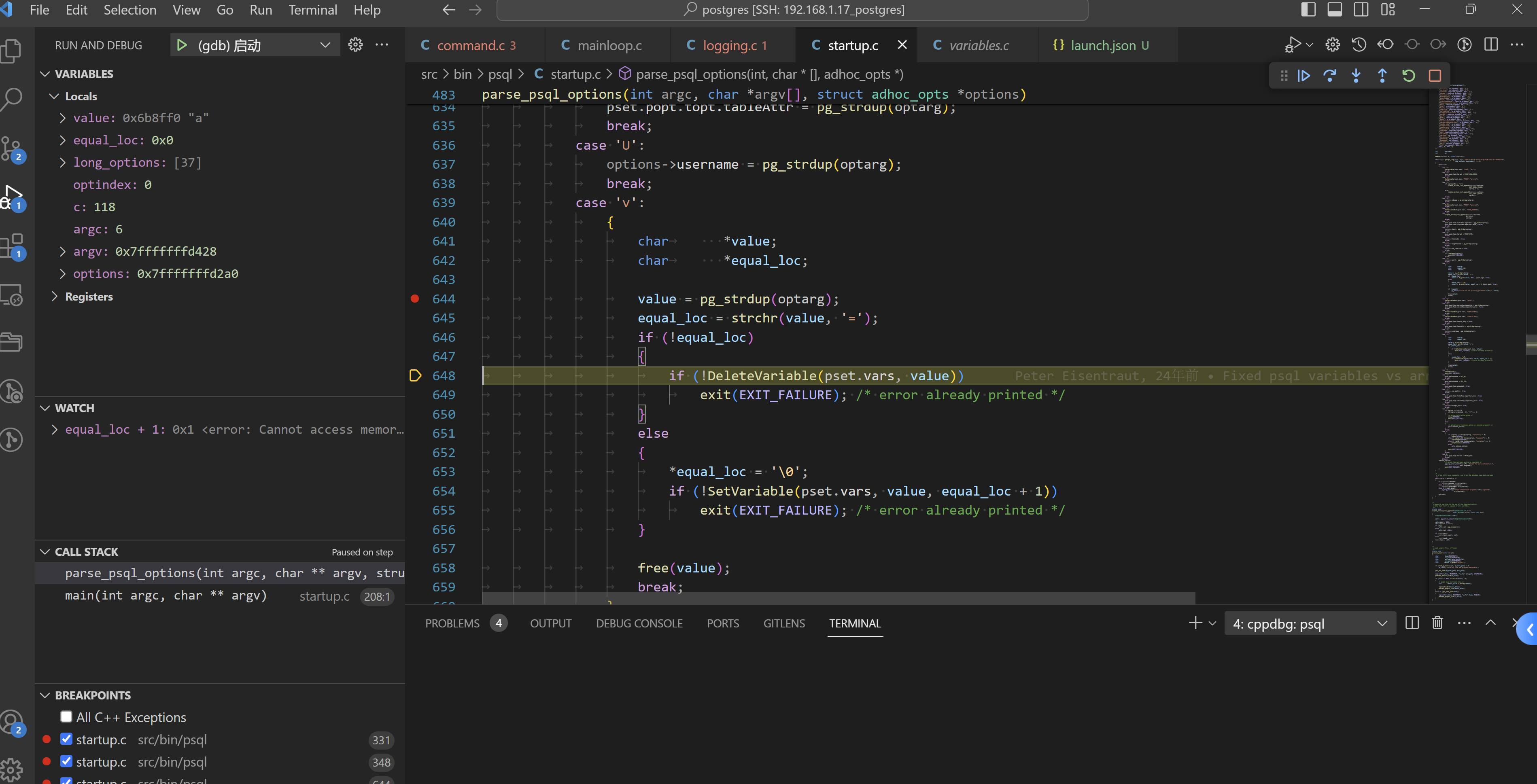
case 'v':
{
char *value;
char *equal_loc;
value = pg_strdup(optarg);
equal_loc = strchr(value, '=');
if (!equal_loc)
{
if (!DeleteVariable(pset.vars, value))
exit(EXIT_FAILURE); /* error already printed */
}
else
{
*equal_loc = '\0';
if (!SetVariable(pset.vars, value, equal_loc + 1))
exit(EXIT_FAILURE); /* error already printed */
}
free(value);
break;
}
...
示例,如下:
[postgres@localhost:~/test/bin]$ ./psql
psql (16.0)
Type "help" for help.
postgres=# \echo :a
b
postgres=# \q
[postgres@localhost:~/test/bin]$ ./psql -X -v a=c -v a
psql (16.0)
Type "help" for help.
postgres=# \echo :a
:a
postgres=# \q
[postgres@localhost:~/test/bin]$ cat ~/.psqlrc
\set a b
[postgres@localhost:~/test/bin]$
调试,如下:
变量set,如下:
变量清除,如下:
\set
这里仍然使用的是函数SetVariable,如下:
// src/bin/psql/command.c
/*
* \set -- set variable
*/
static backslashResult
exec_command_set(PsqlScanState scan_state, bool active_branch)
{
bool success = true;
if (active_branch)
{
char *opt0 = psql_scan_slash_option(scan_state,
OT_NORMAL, NULL, false);
if (!opt0)
{
/* list all variables */
PrintVariables(pset.vars);
success = true;
}
else
{
/*
* Set variable to the concatenation of the arguments.
*/
char *newval;
char *opt;
opt = psql_scan_slash_option(scan_state,
OT_NORMAL, NULL, false);
newval = pg_strdup(opt ? opt : "");
free(opt);
while ((opt = psql_scan_slash_option(scan_state,
OT_NORMAL, NULL, false)))
{
newval = pg_realloc(newval, strlen(newval) + strlen(opt) + 1);
strcat(newval, opt);
free(opt);
}
if (!SetVariable(pset.vars, opt0, newval))
success = false;
free(newval);
}
free(opt0);
}
else
ignore_slash_options(scan_state);
return success ? PSQL_CMD_SKIP_LINE : PSQL_CMD_ERROR;
}
\gset
调试如下:
{
"name": "(gdb) 附加",
"type": "cppdbg",
"request": "attach",
"program": "/home/postgres/test/bin/psql",
"MIMode": "gdb",
"setupCommands": [
{
"description": "为 gdb 启用整齐打印",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "将反汇编风格设置为 Intel",
"text": "-gdb-set disassembly-flavor intel",
"ignoreFailures": true
}
]
}
/*
* \gset [prefix] -- send query and store result into variables
*/
static backslashResult
exec_command_gset(PsqlScanState scan_state, bool active_branch)
{
backslashResult status = PSQL_CMD_SKIP_LINE;
if (active_branch)
{
char *prefix = psql_scan_slash_option(scan_state,
OT_NORMAL, NULL, false);
if (prefix)
pset.gset_prefix = prefix;
else
{
/* we must set a non-NULL prefix to trigger storing */
pset.gset_prefix = pg_strdup("");
}
/* gset_prefix is freed later */
status = PSQL_CMD_SEND;
}
else
ignore_slash_options(scan_state);
return status;
}
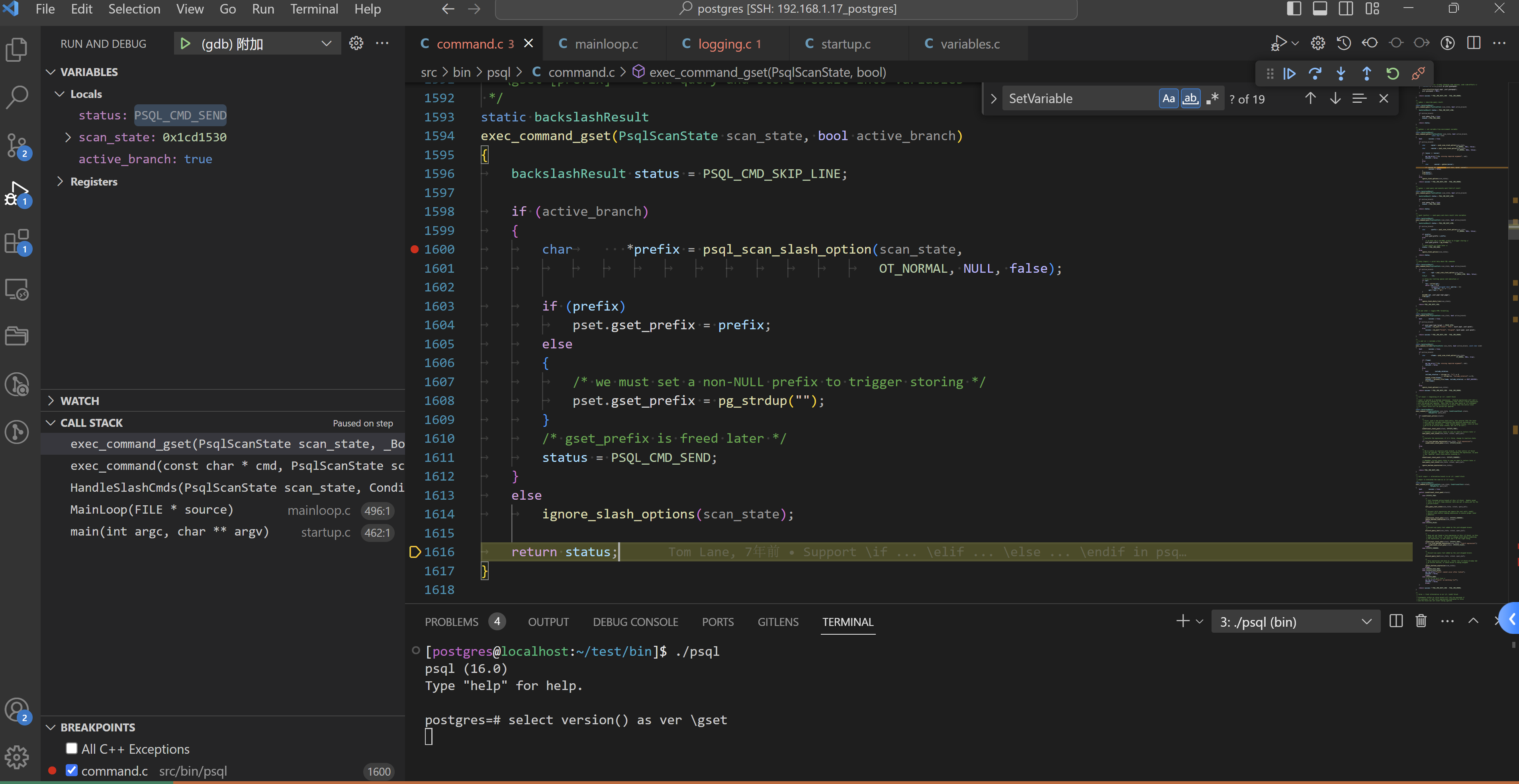
接下来的处理,(处理变量)如下:
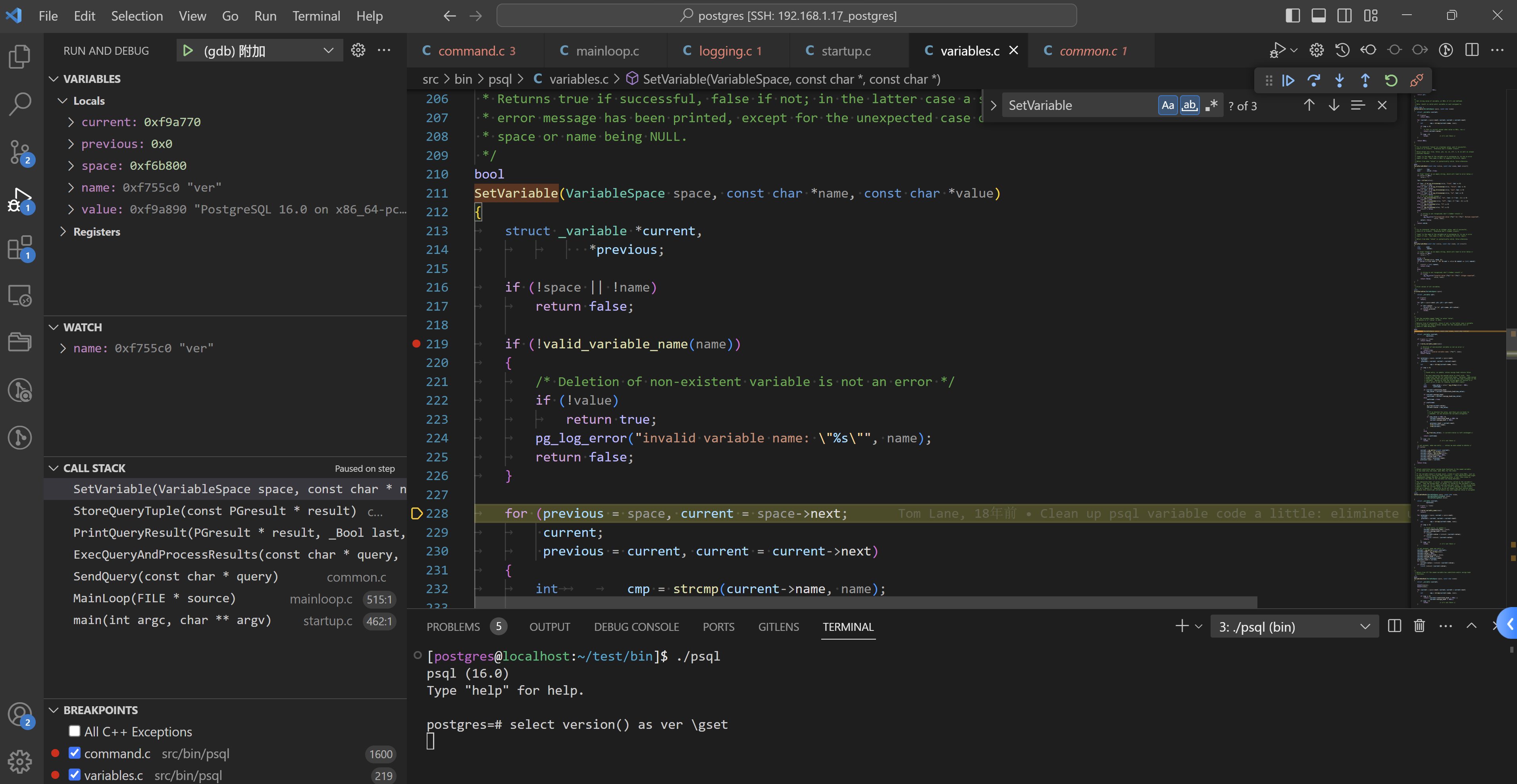
此时的函数堆栈,如下:
SetVariable(VariableSpace space, const char * name, const char * value) (\home\postgres\postgres\src\bin\psql\variables.c:228)
StoreQueryTuple(const PGresult * result) (\home\postgres\postgres\src\bin\psql\common.c:764)
PrintQueryResult(PGresult * result, _Bool last, const printQueryOpt * opt, FILE * printQueryFout, FILE * printStatusFout) (\home\postgres\postgres\src\bin\psql\common.c:975)
ExecQueryAndProcessResults(const char * query, double * elapsed_msec, _Bool * svpt_gone_p, _Bool is_watch, const printQueryOpt * opt, FILE * printQueryFout) (\home\postgres\postgres\src\bin\psql\common.c:1652)
SendQuery(const char * query) (\home\postgres\postgres\src\bin\psql\common.c:1137)
MainLoop(FILE * source) (\home\postgres\postgres\src\bin\psql\mainloop.c:515)
main(int argc, char ** argv) (\home\postgres\postgres\src\bin\psql\startup.c:462)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号