Scala实现网站流量实时分析
之前已经完成zookeeper集群、Hadoop集群、HBase集群、Flume、Kafka集群、Spark集群的搭建:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),且离线分析模块已经在之前的模块中实现(网站日志流量分析系统之数据清洗处理(离线分析)),这次基于Docker搭建的spark集群,本地编写Scala代码实现网站日志流量实时分析模块,最终提交于spark集群。
一、本机环境
系统:win10 64位
Scala版本:2.13
JDK版本:1.8
IDE工具:IDEA2018
Maven版本:3.6.1
二、实时分析模块实现
之前已经完成zookeeper集群、Hadoop集群、HBase集群、Flume、Kafka集群、Spark集群的搭建:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),且离线分析模块已经在之前的模块中实现(网站日志流量分析系统之数据清洗处理(离线分析)),这次基于Docker搭建的spark集群,本地编写Scala代码实现网站日志流量实时分析模块,最终提交于spark集群。
一、本机环境
系统:win10 64位
Scala版本:2.13
JDK版本:1.8
IDE工具:IDEA2018
Maven版本:3.6.1
二、目前状况
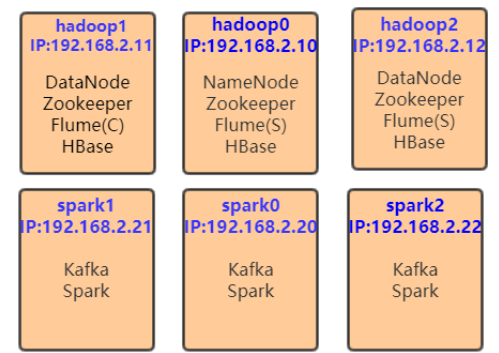
基于之前搭建的Spark集群:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),目前集群运行环境如下:
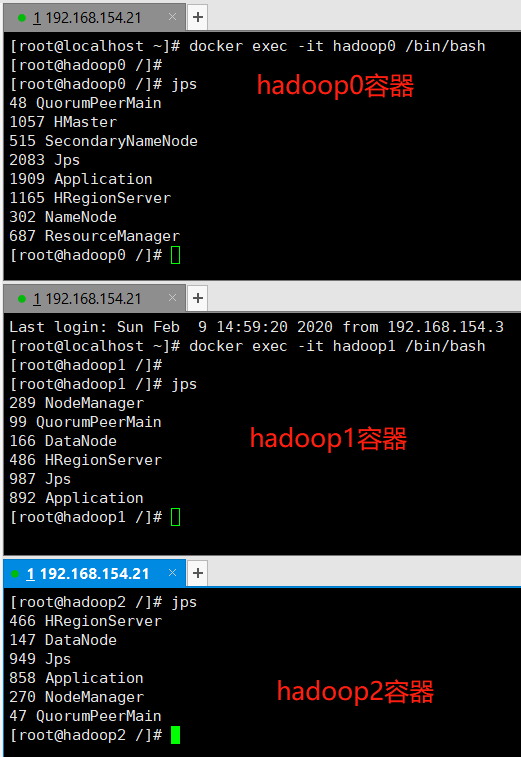
1、hadoop0、hadoop1、hadoop2容器角色
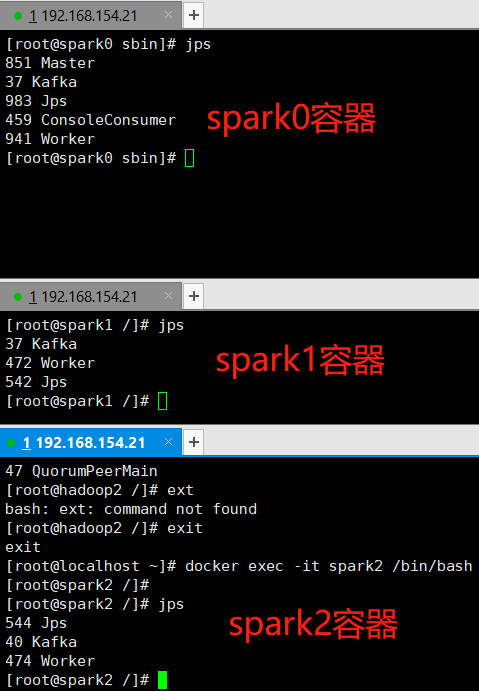
2、spark0、spark1、spark2容器
3、测试
app应用服务器通过js采集用户信息,发送至日志服务器,日志服务器分发至flume,flume分别落地至HDFS与Kafka,Kafka目前是以console模式消费消息,并未与spark对接
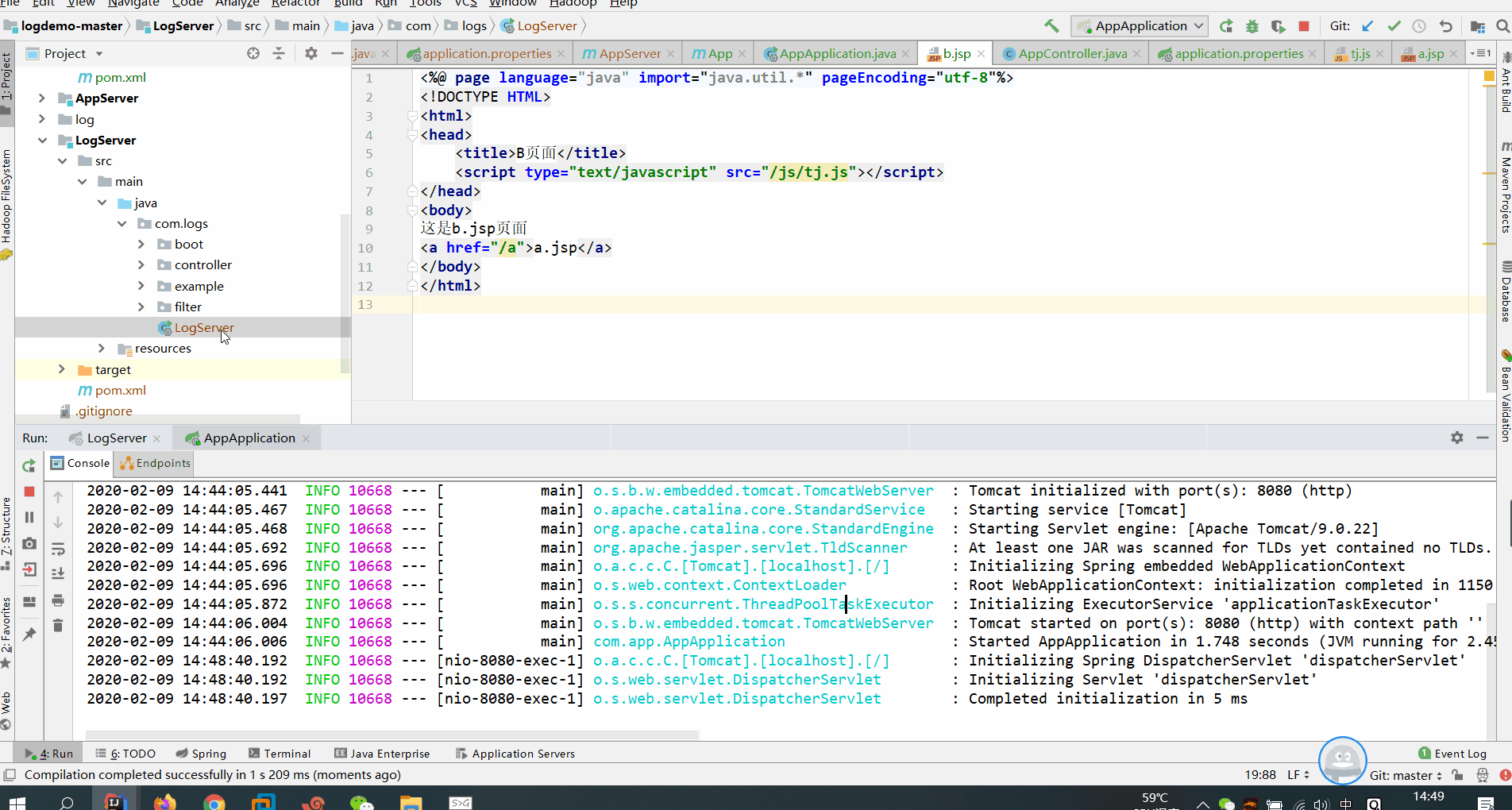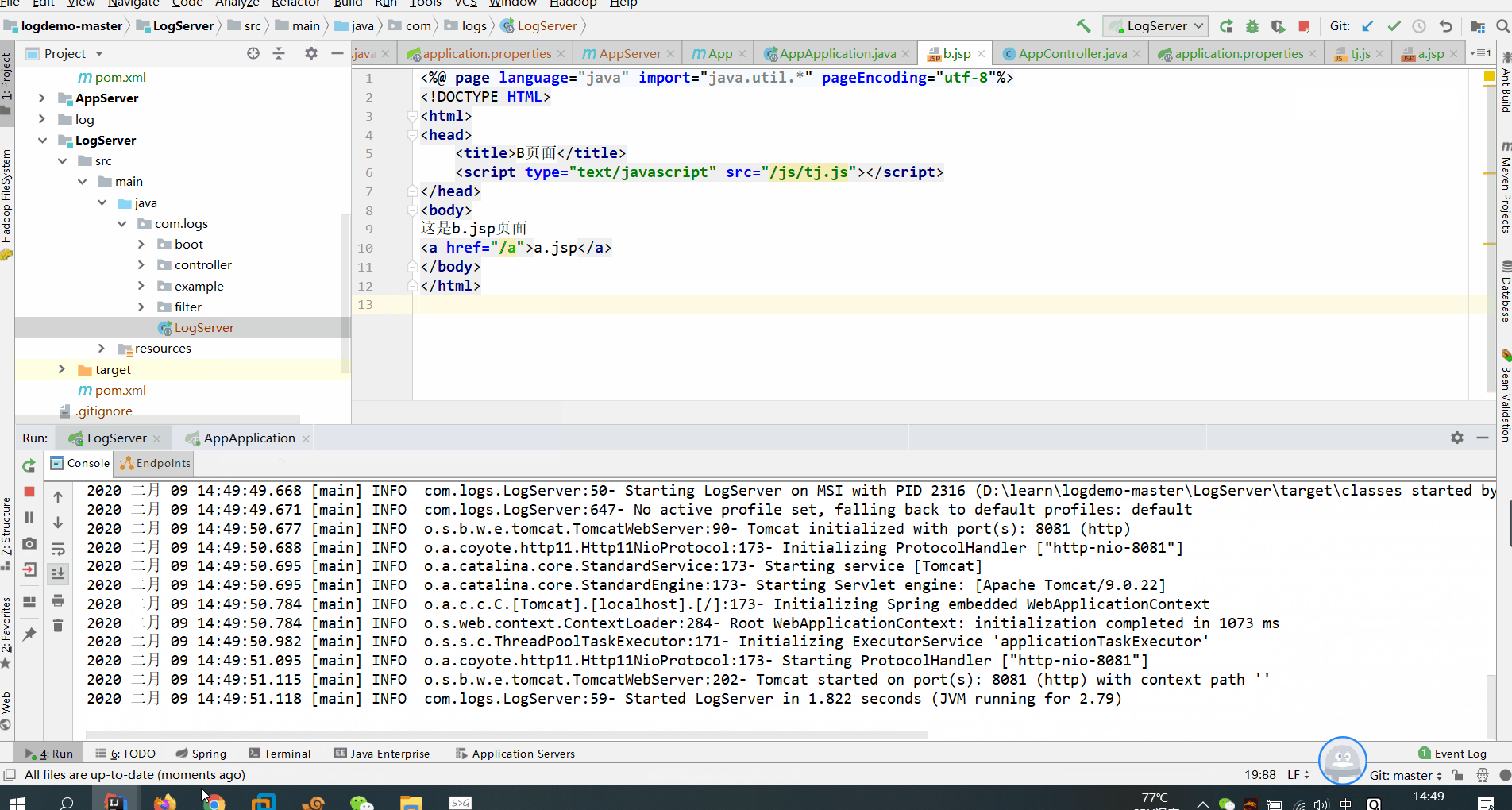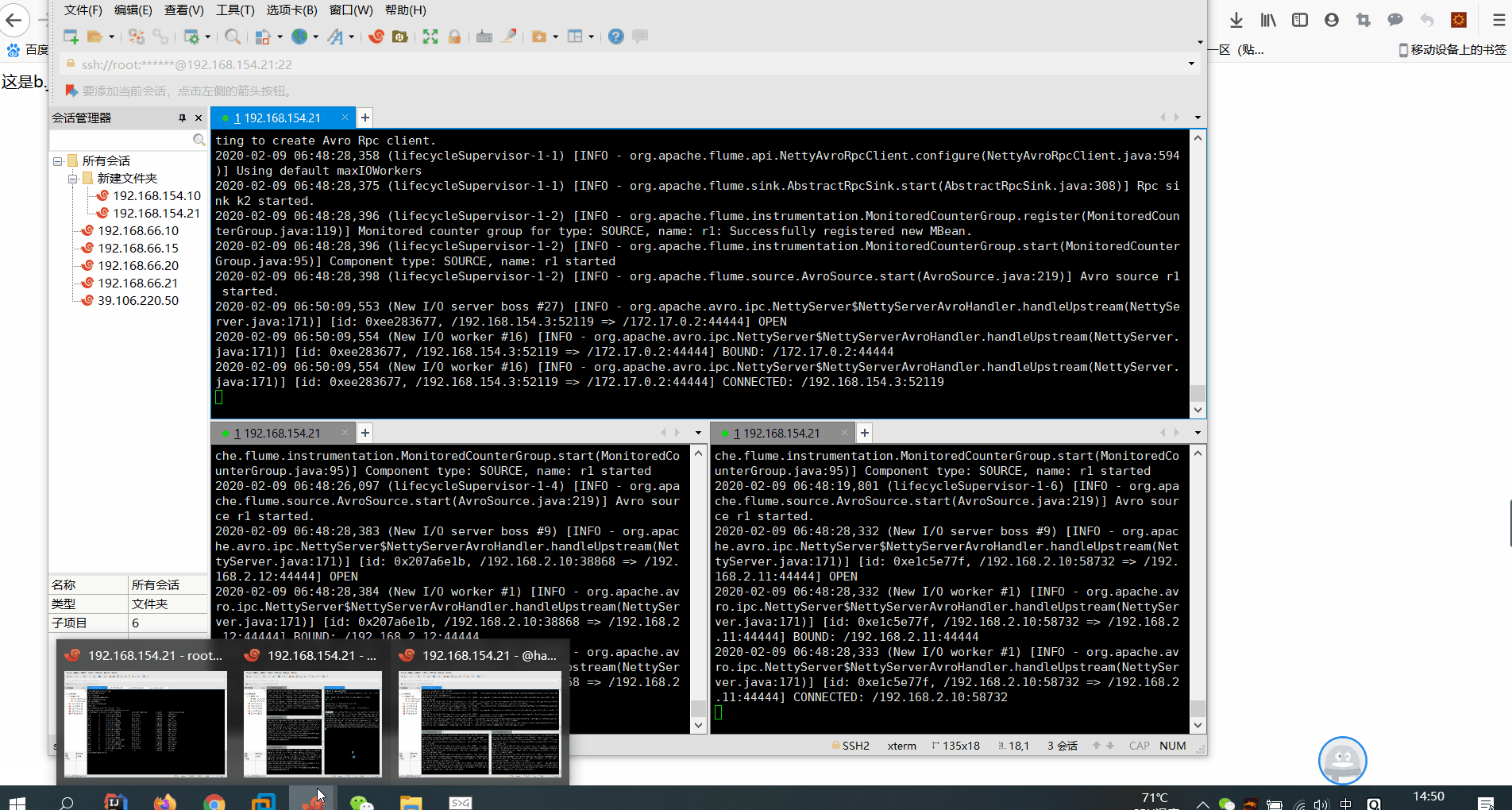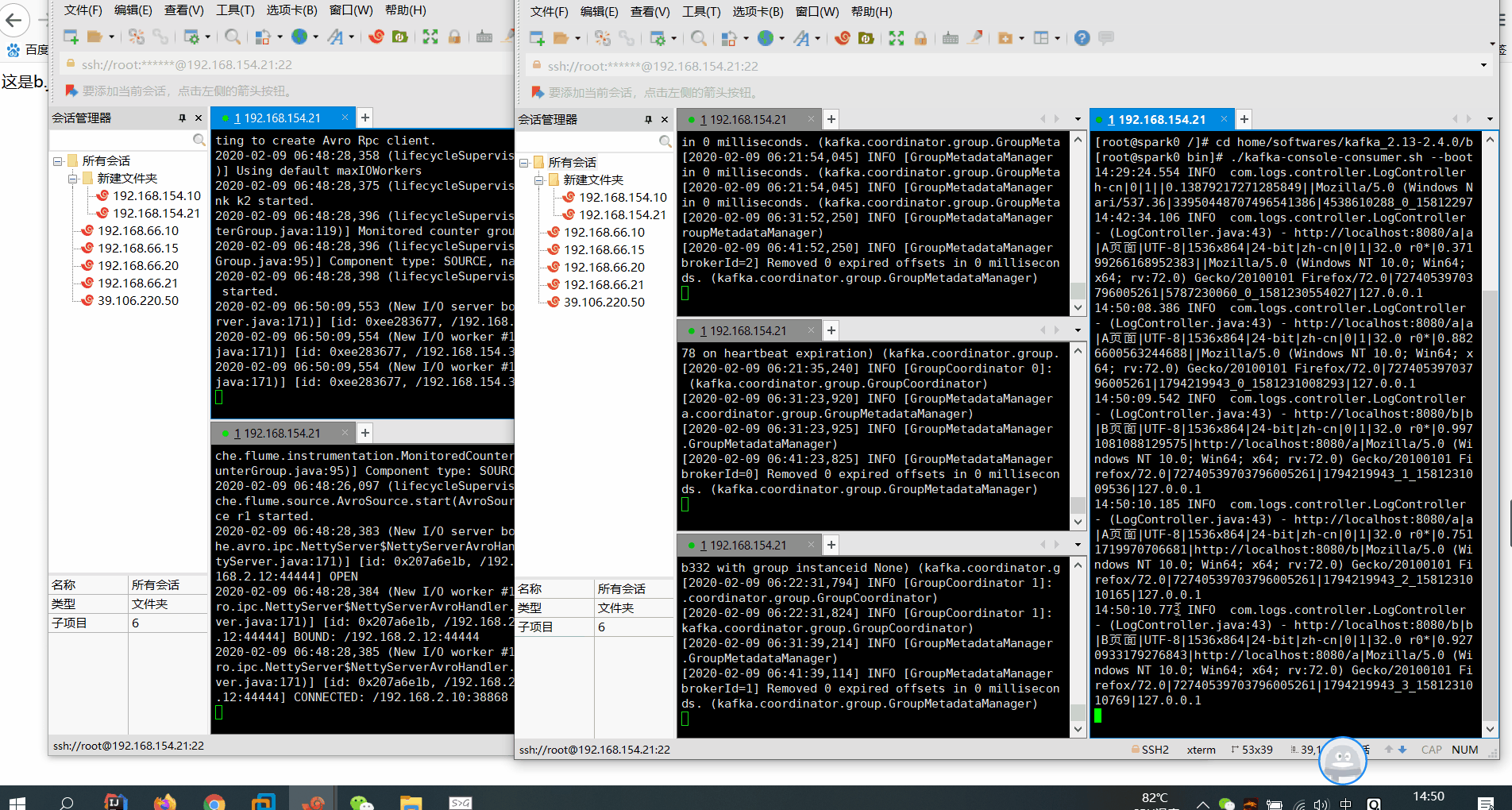
flume写入kafka的同时也落地至HDFS,供以离线分析
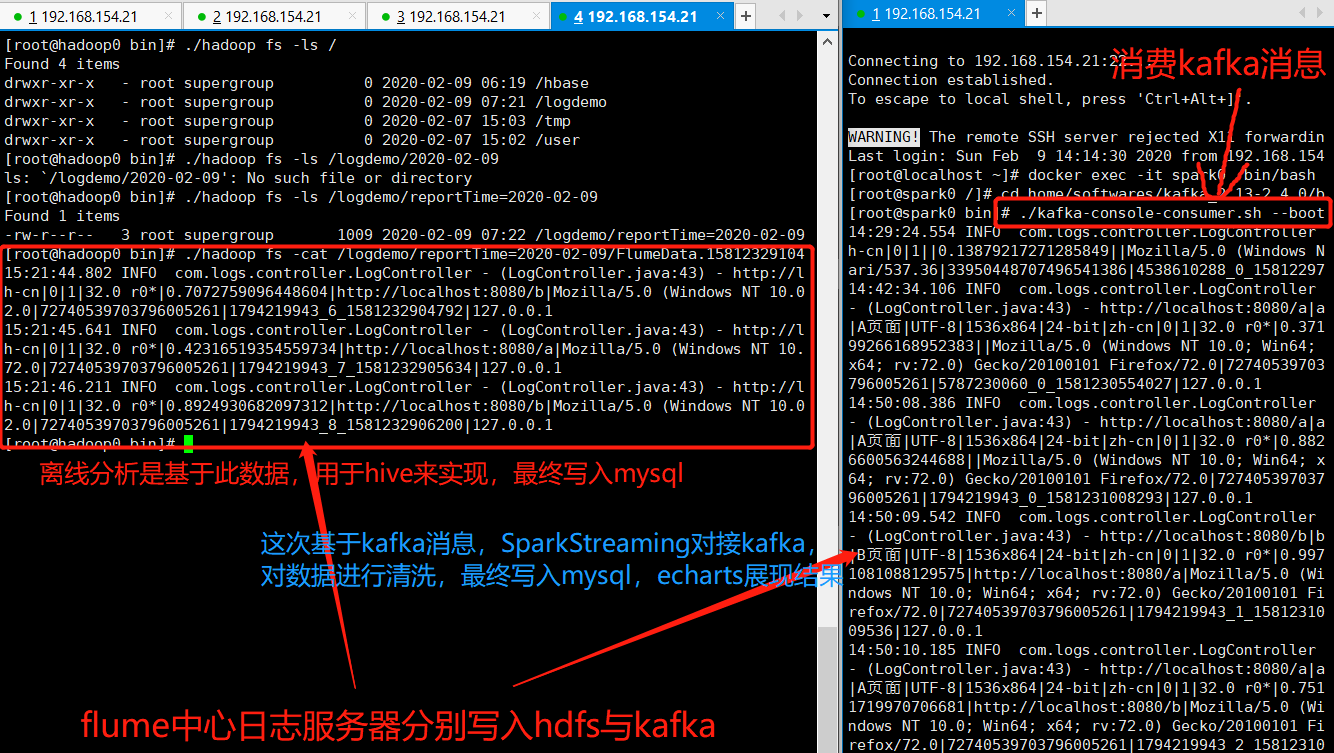
二、实时分析模块实现
以上部分,数据已经写入kafka,只需spark消费其中数据,进行清洗,落地至Mysql即可,最终以echarts展现
代码地址:https://github.com/Simple-Coder/log-demo
1、Maven代码

2、实现效果
用户通过点击页面,JS代码采集信息,发送至日志服务器,日志服务器转而发送至Flume,Flume分别落地HDFS(离线分析)与Kafka(实时分析),SparkStreaming消费Kafka消息,对数据进行清洗,HBase用于存放中间数据,最终落地至Mysql(基于Docker容器启动)

至此、架构图内容已经全部实现,最后一步:数据可视化--------网站日志流量分析系统之数据可视化展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号