软件构造学习笔记4 set和map
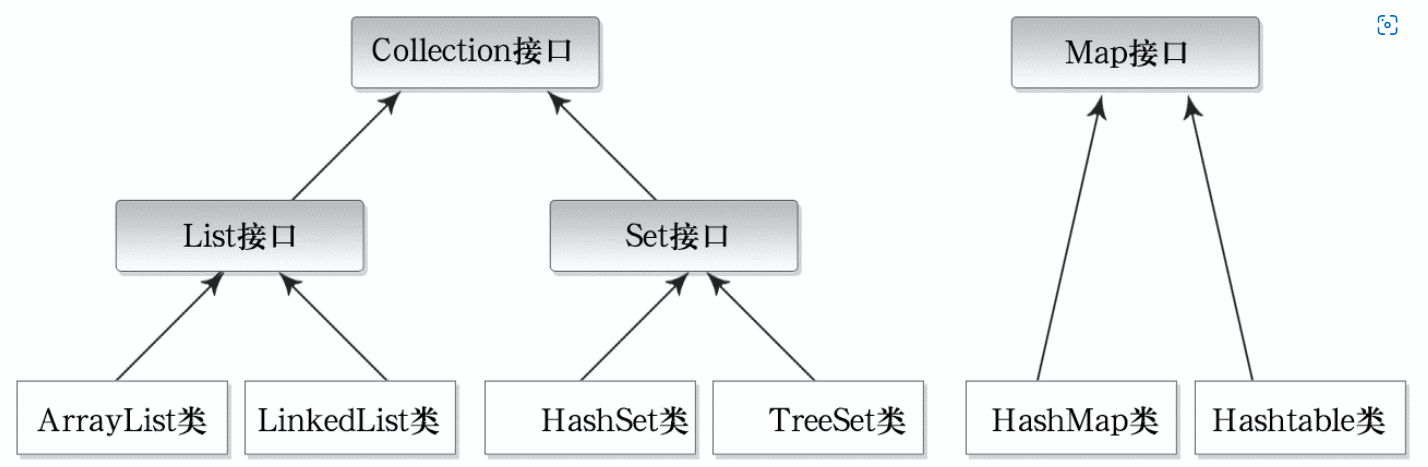
1.Set
Set 表示唯一对象的集合。集合中元素的排序是不相关的。
Set继承于Collection接口,是一个不允许出现重复元素,并且无序的集合,主要有HashSet和TreeSet两大实现类。
在判断重复元素的时候,Set集合会调用hashCode()和equal()方法来实现。
HashSet是哈希表结构,主要利用HashMap的key来存储元素,计算插入元素的hashCode来获取元素在集合中的位置;
TreeSet是红黑树结构,每一个元素都是树中的一个节点,插入的元素都会进行排序;
Set集合框架结构:
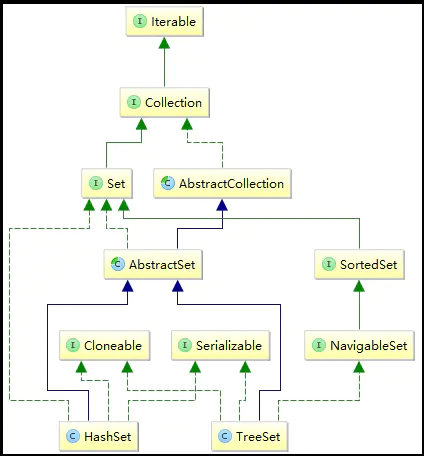
与List接口一样,Set接口也提供了集合操作的基本方法。
但与List不同的是,Set还提供了equals(Object o)和hashCode(),供其子类重写,以实现对集合中插入重复元素的处理;
public interface Set<E> extends Collection<E> { A:添加功能 boolean add(E e); boolean addAll(Collection<? extends E> c); B:删除功能 boolean remove(Object o); boolean removeAll(Collection<?> c); void clear(); C:长度功能 int size(); D:判断功能 boolean isEmpty(); boolean contains(Object o); boolean containsAll(Collection<?> c); boolean retainAll(Collection<?> c); E:获取Set集合的迭代器: Iterator<E> iterator(); F:把集合转换成数组 Object[] toArray(); <T> T[] toArray(T[] a); //判断元素是否重复,为子类提高重写方法 boolean equals(Object o); int hashCode(); }
HashSet实现Set接口,底层由HashMap来实现,为哈希表结构,新增元素相当于HashMap的key,value默认为一个固定的Object。在我看来,HashSet相当于一个阉割版的HashMap;
当有元素插入的时候,会计算元素的hashCode值,将元素插入到哈希表对应的位置中来;
它继承于AbstractSet,实现了Set, Cloneable, Serializable接口。
(1)HashSet继承AbstractSet类,获得了Set接口大部分的实现,减少了实现此接口所需的工作,实际上是又继承了AbstractCollection类;
(2)HashSet实现了Set接口,获取Set接口的方法,可以自定义具体实现,也可以继承AbstractSet类中的实现;
(3)HashSet实现Cloneable,得到了clone()方法,可以实现克隆功能;
(4)HashSet实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
具有如下特点:
-
不允许出现重复因素;
-
允许插入Null值;
-
元素无序(添加顺序和遍历顺序不一致);
-
线程不安全,若2个线程同时操作HashSet,必须通过代码实现同步;
public class HashSetTest { public static void main(String[] agrs){ //创建HashSet集合: Set<String> hashSet = new HashSet<String>(); System.out.println("HashSet初始容量大小:"+hashSet.size()); //元素添加: hashSet.add("my"); hashSet.add("name"); hashSet.add("is"); hashSet.add("rmaa"); hashSet.add(","); hashSet.add("hello"); hashSet.add("world"); hashSet.add("!"); System.out.println("HashSet容量大小:"+hashSet.size()); //迭代器遍历: Iterator<String> iterator = hashSet.iterator(); while (iterator.hasNext()){ String str = iterator.next(); System.out.println(str); } //增强for循环 for(String str:hashSet){ System.out.println(str); } //元素删除: hashSet.remove("rmaa"); System.out.println("HashSet元素大小:" + hashSet.size()); hashSet.clear(); System.out.println("HashSet元素大小:" + hashSet.size()); //集合判断: boolean isEmpty = hashSet.isEmpty(); System.out.println("HashSet是否为空:" + isEmpty); boolean isContains = hashSet.contains("hello"); System.out.println("HashSet是否为空:" + isContains); } }
在向HashMap中添加元素时,先判断key的hashCode值是否相同,如果相同,则调用equals()、==进行判断,若相同则覆盖原有元素;如果不同,则直接向Map中添加元素。
2.TreeSet
从名字上可以看出,此集合的实现和树结构有关。与HashSet集合类似,TreeSet也是基于Map来实现,具体实现TreeMap,其底层结构为红黑树(特殊的二叉查找树);
与HashSet不同的是,TreeSet具有排序功能,分为自然排序(123456)和自定义排序两类,默认是自然排序;在程序中,我们可以按照任意顺序将元素插入到集合中,等到遍历时TreeSet会按照一定顺序输出--倒序或者升序;
它继承AbstractSet,实现NavigableSet, Cloneable, Serializable接口。
(1)与HashSet同理,TreeSet继承AbstractSet类,获得了Set集合基础实现操作;
(2)TreeSet实现NavigableSet接口,而NavigableSet又扩展了SortedSet接口。这两个接口主要定义了搜索元素的能力,例如给定某个元素,查找该集合中比给定元素大于、小于、等于的元素集合,或者比给定元素大于、小于、等于的元素个数;简单地说,实现NavigableSet接口使得TreeSet具备了元素搜索功能;
(3)TreeSet实现Cloneable接口,意味着它也可以被克隆;
(4)TreeSet实现了Serializable接口,可以被序列化,可以使用hessian协议来传输;
具有如下特点:
-
对插入的元素进行排序,是一个有序的集合(主要与HashSet的区别);
-
底层使用红黑树结构,而不是哈希表结构;
-
允许插入Null值;
-
不允许插入重复元素;
-
线程不安全;
Java 自带了各种 Map 类。这些 Map 类可归为三种类型:
1. 通用Map,用于在应用程序中管理映射,通常在 java.util 程序包中实现
HashMap、Hashtable、Properties、LinkedHashMap、IdentityHashMap、TreeMap、WeakHashMap、ConcurrentHashMap
2. 专用Map,通常我们不必亲自创建此类Map,而是通过某些其他类对其进行访问
java.util.jar.Attributes、javax.print.attribute.standard.PrinterStateReasons、java.security.Provider、java.awt.RenderingHints、javax.swing.UIDefaults
3. 一个用于帮助我们实现自己的Map类的抽象类
AbstractMap
HashMap
最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为Null(多条会覆盖);允许多条记录的值为 Null。非同步的。
TreeMap
能够把它保存的记录根据键(key)排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
Hashtable
与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
LinkedHashMap
保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.在遍历的时候会比HashMap慢。key和value均允许为空,非同步的。
hashmap的基本操作:
Map<String, String> map = new HashMap<>();//创建 map.put("key1", "value1");//添加 map.get("key1")//获得 map.remove("key1");移除 map.clear();//清空
遍历方法
//使用key遍历 for(String key : map.keySet()){ System.out.println(key+":" +map.get(key)); //使用entrySet()遍历 for (Map.Entry<String, String> entry : map.entrySet()) { System.out.println(entry.getKey() + " :" + entry.getValue()); } //使用value遍历 for(String value: map.values()){ System.out.println(value); } //使用迭代器 //使用keySet()遍历 Iterator<String> iterator =map.keySet().iterator(); while(iterator.hasNext()){ String key = iterator.next(); System.out.println(key+":"+map.get(key)); } //使用entrySet()遍历 Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<String, String> entry = iterator.next(); System.out.println(entry.getKey() + " :" + entry.getValue()); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号